
基于非参贝叶斯的网络文档链接模型研究
2020-09-16 02:43:36黄大君王大刚
合肥师范学院学报 2020年3期
黄大君,王大刚,吴 昊
(合肥师范学院 计算机学院,安徽 合肥 230601)
1 概述
文档链接分析在社交网络、搜索引擎、超链接网络方面有着广泛的应用。利用预测模型可以将网络成员指向新朋友,将科学论文指向相关引用,并将网页指向其他相关页面。国内外学者在这个领域相继提出了许多模型,比较具有代表性的模型是Airoldi等人2008年提出的MMSB[1]模型和主题模型[2-3](Laten Dirichlet Allocation,LDA)。主题模型为这个领域奠定了一个理论框架,为文档之间的相似性引入主题语义层次奠定了基础。LDA话题模型可以通过推断的隐藏结构来组成文档的主题结构。LDA和其他一些话题模型从属于概率建模领域之下。概率建模领域下生成过程定义了一个在已观测随机变量和隐藏随机变量之上的联合概率分布,通过使用联合概率分布来计算给定观测变量值下的隐藏变量的条件分布。
在LDA模型中,假定文档看成是在主题上的分布,而主题又看成是在相应单词上的分布。LDA是一个层次概率模型,主题分布在一个固定的词汇表上来描述一个文档的语料库。在其生成过程中,每个文档都被赋予一个Dirichlet[4-6]分布的主题比例向量,文档中的每个单词都是通过从这些比例绘制主题分配,然后从相应的主题分布中绘制出单词来绘制的。基于LDA模型的视角,科研人员将该模型的各种变种加以扩展,MMSB模型是应用于社交网络、超链接网络中的一个典型基本框架,该框架基于LDA的理论基础框架,定义社区中节点的交互关系与概率生成关系。MMSB模型为了促进节点与社区之间的一对多关系,每个节点都有自己的“混合成员分布”,其中与所有其他节点的关系由其分布向量来表征,这个方法描述了扮演多个角色的对象之间的交互。在MMSB框架下,描述性统计可以揭示网络数据集隐藏的社区结构。
在这之后的研究中,针对文本挖掘、超链接网络领域中又涌现出很多的具体的概率模型结构。关系主题模型[7](Relational topic model,RTM)由M. BLE于2010年提出用于文档挖掘的模型,该模型兼顾文档的属性信息和链接信息,对新文档可能的链接进行预测,针于每一对文件,RTM将其链接建模为一个二进制随机变量,并以其内容为条件,预测它们之间的联系,并预测其中的文字。RTM是网络和每节点属性数据的分层模型。 RTM用于分析链接的语料库,如引用网络,链接的网页,社交网络与用户配置文件,以及地理标记的新闻。“Pairwise Link-LDA”是Nallapati[8]等人2008年提出的模型,它是混合隶属随机块模型的扩展,来建模网络结构和节点属性。模型假定每个链接都是根据两个单独的主题生成的从与链接的端点关联的主题比例向量中选择,因为潜在的话题和链接是在这个模型中独立绘制的,所以不能保证发现的话题同时代表了话语和链接,模型结合了LDA和MMSB(Mixed Membership Stochastic Block )随机模型的思想,并允许建模任意链接结构,提出了一个新的折中方案,它结合了这两个模型的最佳性质,也明确地模拟了引用文献和被引用文献之间的依赖关系。此外,该模型为每个链路引入了附加的变化参数,增加了计算复杂度。
以上模型都建立在固定主题数为K的基本假定上,但实际上文档的主题是很难预先确定的,固定主题的假定与事实是不相符合的。以上模型要么侧重利用内容信息预测链接信息,要么利用链接信息预测内容。在RTM模型中利用主题信息和链接共同建模,但建模过程比较复杂,需要假定预测数据的形态分布信息,实际匹配过程往往也很难做到。
本文重点关注网络文档链接预测和主题分析,假定文档结构基于混合成员文件模型的基础,每个文档都是相关主题上的混合成员分布,都展示了多项分布或主题的潜在混合。最后我们推导出基于M-H[16-23]的推理和估计算法。并利用实验评估NTM在科学摘要网络,网络文件上的预测性能。
2 概率图模型和生成模型
2.1 非参贝叶斯模型分层Dirichlet过程(HDP)
基于LDA模型的简单参数设定,模型中的主题和单词的分布均是简单的概率分布。HDP 过程是Dirichlet过程混合模型的多层形式,HDP模型相比较LDA 不仅能实现聚类和推断等功能,而且能够自动生成聚类数目,比如我们在使用聚类方法k-means时,需要指定k的值(聚成k个簇);在使用LDA时需要指定主题的数目k,但通过HDP这种非参方法,可以不指定k,而是通过数据学习,自动获取k值,这样能够大大增强算法的鲁棒性。HDP是一种非参贝叶斯模型,是随机过程的应用。HDP从一个随机测度[22]空间中抽样,首先以基分布H和Concentration 参数λ构成Dirichlet过程,G0~DP(λ,H),而后以G0为基分布,以α0为Concentration 参数,对每对数据构造Dirichlet过程混合模型,Gj~DP(α0,G0)。依据该层Dirichlet过程为先验分布,构造Dirichlet过程混合模型。从Dirichlet过程的定义中很难采样,通常可以通过Stick-breaking 过程和Chinese restaurant franchise(CRF)两种方法进行构造, DP 过程的定义:β|γ~GEM(γ),πj|α0,β~DP(α0,β)
(1)
2.2 关系主题模型(RTM)
在RTM中,每个文档首先由LDA中的主题生成。 然后将文档之间的链接建模为二进制变量,每对文档一个。 这些二进制变量分配取决于用于生成每个构成文档的主题。 由于这种依赖性,文档的内容在统计上与它们之间的链接结构相关。 因此,每个文档的混合成员都取决于文档的内容以及链接的模式。 反过来,其成员资格相似的文件将更有可能在模型下链接。该模型在MMSB块的基础上,把文档的结构和文档的主题内容结合在一起,共同训练模型,以达到更好的预测未知文档的链接情况。在RTM模型中,作者使用一般广义指数分布簇建立主题和分布之间的关系。建立如下关系:yd,d′|zd,zd'∝φ(.|zd,zd',η) 。其中φ定义为链接密度函数,该函数根据不同数据集的分布形态分别用正态、指数、对数等概率密度来表达。节点d和d’模如果存在链接关系,则yd,d′=1。η用于构造一般指数分布族。模型的概率过程和实际的训练采样过程都比较复杂,且实际操作过程中很难根据待预测的未知数据源来确定具体的指数簇分布类型。
3 基于非参贝叶斯的文档关系模型( NTM)
3.1 NTM模型概率图和生成模型
HDP是DP过程的两层形式,本文之所以选择两层HDP作为先验概率分布,考虑到网络文档中任意两个节点共享原子节点,即同一文档可能属于不同的文档集,不同文档集共享文档原子节点,所以从HDP模型的第二层采样,以便文档能够共享原子主题。假定分布不再从一个有限的的主题数为K的分布中采样,从HDP的第二层采样,进而引入非参假定。为了使得模型能够针对一般的未知的数据源进行预测,还需要对模型进行一定程度的简化和假设。基于采样得到的主题分布向量,计算文档之间向量的余弦夹角。利用这个相似值作为链接文档之间相似性的基本度量单位,该值大小能够从语义上表示文档间的相似性大小的相关关系。该值作为文档间链接的语义关联依据,我们认为相似度大的文档之间,链接的可能性越大,随后在概率图的基础上,利用贝叶斯关系,通过数据来学习分布参数。
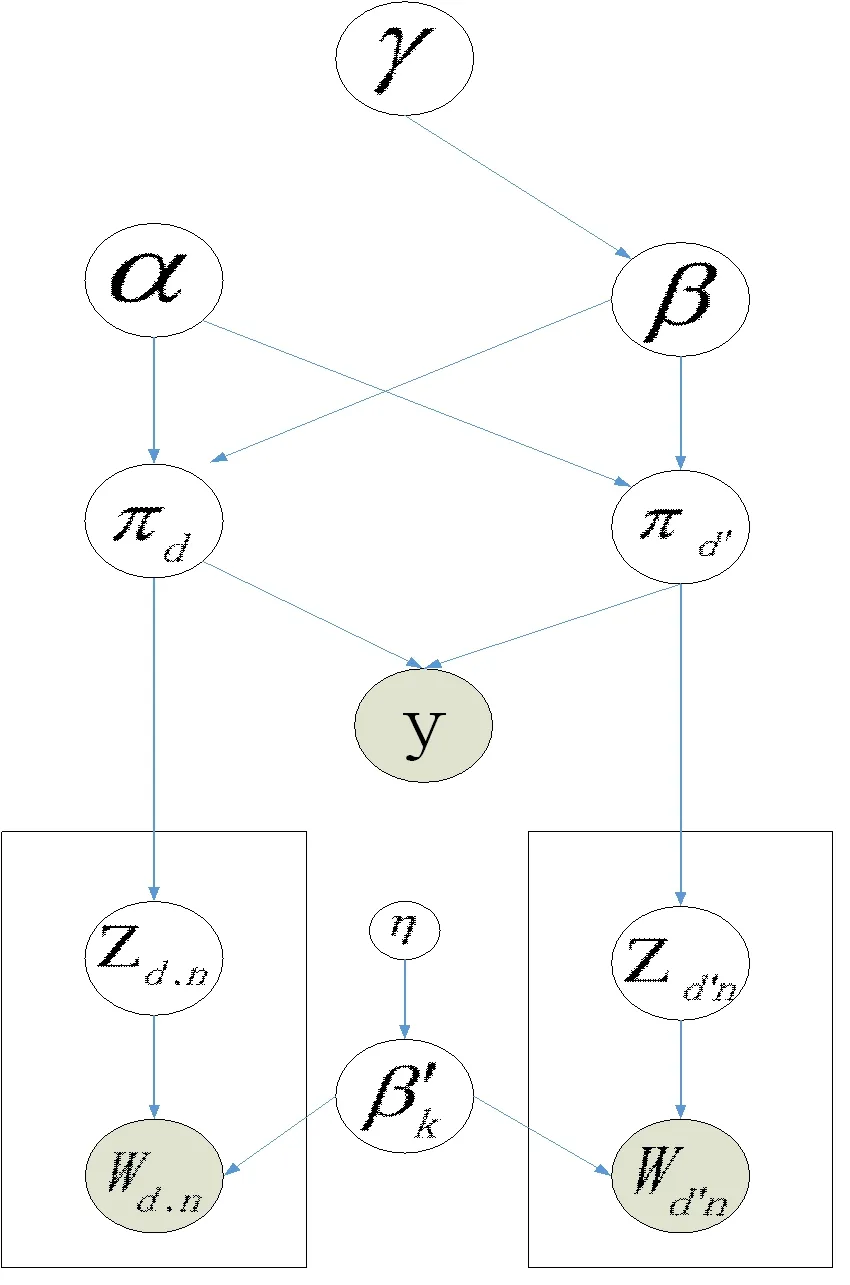
图1 NTM概率图模型
此处的{πi}1:n为混合成员分布,网络中单个文档可能具有属于多个文档集的属性,如同一个人可以参加多个社区活动,即同时具有属于多个社区的属性。其中{πi}1:n的先验概率分布存在以下关系:
(2)
从随机侧度中采样出来的{πi}1:n是个K维的Dirichlet向量,反映网络数据集中的文档的主题分布,对向量求余弦夹角得到它们之间的相似度,这个值大小与未来两个文档间可能存在的链接关系存在某种程度的正相关,定义函数f,对f进行二值采样,利用数据来学习模型。
NTM生成模型表示如下:
β~GEM(γ)
Zd,n|πd~mul(πd)
y|πd,πd′~bernoulli(f)
cos(πd,πd′)∈(0,1)
(3)
3.2 NTM模型的参数采样
3.2.1 采样πi
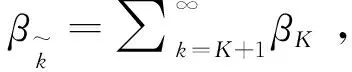
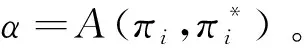
定义转移概率为独立链方式
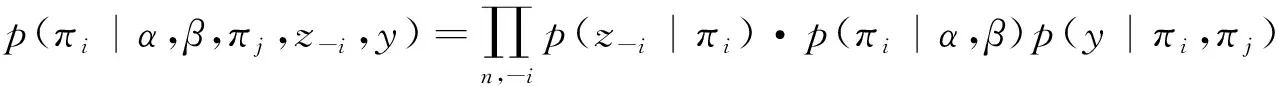
经整合后,消元
(4)
3.2.2 采样
β的先验p(β/γ)=GEM(γ), 在文献[14]中指出,通过增加辅助变量得到:
可以增加接下来的接受率:
其中p(mik=m|Nik,α,βk)∝S(Nik,m)(αβk)m
S(Nik,m)为第一类Stirling 数。
定义:Α(β,β*)=min(1,a)
提议分布采样独立链方式得到:
(5)
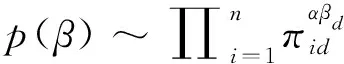
这样得到采样β的接受率:
(6)
3.2.3 采样Ζd,n,Ζd′n
推导出Ζd,n,Ζd′n的适合Gibbs采样的条件概率。
p(zd,n=k,zd′,n=l|Z{zd,n=k,zd′,n=l},W,α,β,η,y)=p(zd,n=k,zd′,n=l|Z{zd,n=k,zd′,n=l},α,β)
p(zd,n=k,zd′,n=l|Z{zd,n=k,zd′,n=l},W,α,β,η,y)=p(zd,n=k,zd′,n=l|Z{zd,n=k,zd′,n=l},α,β)
*p(Wd,n,Wd′,n|W{Wd,n,Wd′,n},(zd,n=k,zd′,n=l),Z{zd,n=k,zd′,n=l},η}
*p(yd,d'|(zd,n=k,zd′,n=l),Z{zd,n=k,zd′,n=l},α,β,y{yd,d′})
p(Wd,n,Wd′,n|W{Wd,n,Wd′,n},(zd,n=k,zd′,n=l),Z{zd,n=k,zd′,n=l},η}
p(yd,d'|(zd,n=k,zd′,n=l),α,β)
∝p(yd,d'|(πd=k,πd′=l),α,β)
(7)
4 实验结果与分析
4.1 RTM模型和NTM模型比较
本文采用基于链接与文本属性的数据集CiteSeer来发现和对比UTM和RTM模型的链接结果和链接质量。CiteSeer数据集由3312种科学出版物组成,分为六类中的一种。 引文网络由4732个链接组成。 数据集中的每个出版物由0/1值单词向量描述,指示字典中相应单词的不存在/存在。 该词典由3703个独特单词组成。该目录包含CiteSeer数据集的选择。这些论文集由六个类别组成,包括人工智能,数据挖掘 ,数据库,模式识别等。这些论文的选择方式使得在最终的语料库中,每篇论文引用或引用至少另一篇论文。整个语料库在阻止和删除停用词后,留下了3703个独特单词的词汇量。文档频率小于10的所有单词都被删除。在CiteSeer运行本文的模型和RTM模型,对数据集采用10倍交叉验证,对其中一个验证集,运行模型得到图3和表3的结果。
实验环是Win7系统,Python 2.7编程环境。采样过程的提议分布采用独立链的方法,所以必须选择合适的迭代次数和步长,经过对多次试验结果的观察和尝试,对迭代次数选择14000,迭代的步长设置为0.5,保证能够在有限次迭代次数和时间下得到比较好的仿真图,图2 是仿真的结果图。运行MCMC采样器过程中,一般而言,不希望宽度过窄,因为抽样效率不高,同时需要很长时间才能探索整个参数空间并显示典型的随机游动行为,但也不希望它太大,以至于永远不会接受跳跃。图2是RTM模型和NTM模型在似然函数上比较图,将提案宽度设置为0.5。可以看到NTM模型收敛的似然值要高于RTM模的似然值。
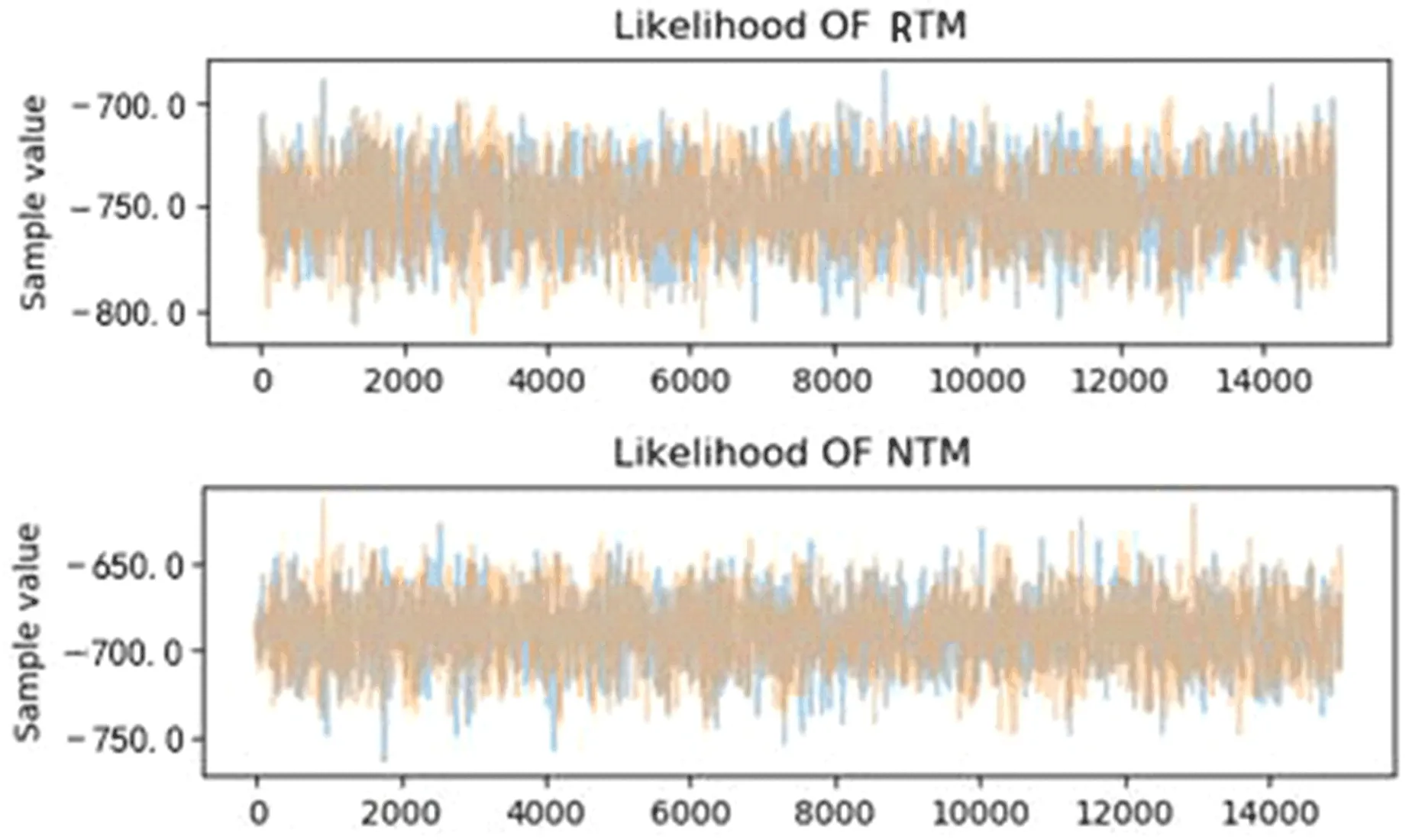
图2 RTM模型和NTM模型在似然函数上比较图

表1 RTM模型和NTM模型链接预测表现
在6大类文章类型中,其中10个主题作为模型比较范围,选择训练集中的Dynamic Infinite Mixed-Membership Stochastic Blockmodel文档,表3的结果是模型测试集上前6个链接预测表现,从表1中可以看出UTM模型识别出来的有效文档是3个,相比RTM模型识别的有效文档是2个。针对本次发现可以看出,UTM模型能够准确把握关键词Mixed-membership,能够在整个文本潜在空间上发现语义关联。注意观察RTM的部分结果,给出的建议链接是针对文档题目的字典单词相似度而非在整个引文数据库中的结构语义。一般而言,您不希望宽度过窄,因为您的抽样效率不高,因为需要很长时间才能探索整个参数空间并显示典型的随机游动行为,但你也不希望它太大以至于你永远不会接受跳跃。
4.2 多数据源综合实验
用不同的模型在相同的仿真数据集上做出了部分定性和定量的比较分析,在实际网络实验数据集中,需要对不同算法在不同数据集上的表现性能做全面的分析,从而判断算法的优越性。选择3个真实世界数据集进行基准测试。分别是 Cora、WebKB、PNAS。Cora数据包含来自Cora计算机科学研究论文搜索引擎的摘要,以及相互引用的文档之间的链接。WebKB数据包含来自不同的大学计算机科学系的网页,网页上的超链接关系标注了网页文档间的链接。PNAS数据包含来自美国国家科学院院刊的最新摘要,文件之间的链接是PNAS内部引用。
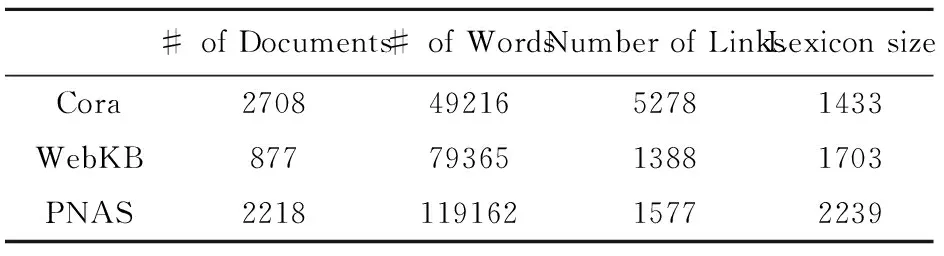
表2 数据集的统计摘要
将MMSB,RTM,本文的NTM算法,在三个实际数据集上验证,其中MMSB,RTM算法利用所给文献公布的代码进行仿真,三个数据集上检查了“和”“的”或“但是”这样的词,以及不经常出现的词被删除。定向链接转换为无向链接,没有链接的文档被删除。
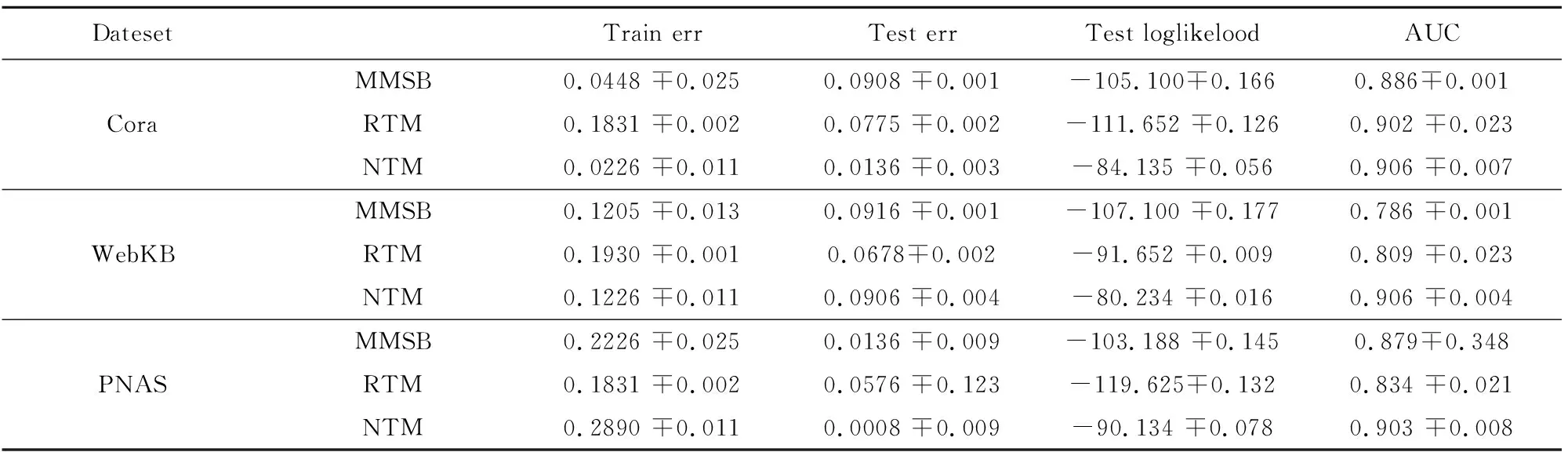
表3 各模型性能比较
其中Train err和Test err的值是1000迭代的结果的平均值,发现在迭代过程中,Train err的值随着发现聚类个数K的值有比较平稳的变化,Test err的值有降低的变化趋势。 算法在数据集WebKB 上的Train err 的值表现比其它算法较差,原因大概是由于WebKB在数据量较小时,部门之间的相关性表现较差,NTM的相关性发现不能充分有效。而我们的值是前1000次的平均,所以可看到整体表现较差。表3中NTM算法的Test loglikelood 相比其他算法有非常明显优势,原因应该是采用了非参的假定,数据根据自身的表现在迭代过程中自动发现聚类的K值,从而对数据集中的数据来说能够获得较大的数据似然值的支持,而其它三种算法都是基于固定值的假设,所以实际聚类值与假定的一定存在差距,从而导致较差的Test loglikelood(表中采用的是负对数值)。AUC 值通常小于0.7是比较差的,大于0.9是比较好的结果,从表3的结果来看,NTM在三个数据集上都取得了较好的效果。从训练误差,测试误差,测试用例的对数似然和AUC四个指标上对上述3种模型进行对比分析,从表3中可以看出整体上分析来看,在全部三个数据集上NTM比其它两个模型都有更好的性能表现。
5 总结
模型在社交网络和文本关系发现领域有重要的应用价值,本文定义了一个非参数的概率图模型,将非参数贝叶斯先验(即DP过程的先验假定)结合到模型中将允许它灵活地调整主题数量与数据。模型综合考虑节点的主题和链接信息,定义联合分布,给出了一个MCMC框架的参数推理算法,合成数据集和现实世界数据集实验证明了我们的方法能够推断出隐藏的主题及其数量,相比已有模型能够更好的进行未知文档和潜在链接结构的预测,提供有关网络潜在成员结构的新见解。在参数推理中,给出了具体的推理步骤和推理算法。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
国际眼科杂志(2021年9期)2021-09-15 03:24:42
中国新闻周刊(2021年26期)2021-07-27 04:02:12
装备制造技术(2020年2期)2020-12-14 03:09:16
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
信息安全研究(2016年4期)2016-12-01 06:06:54
现代防御技术(2016年1期)2016-06-01 12:13:27
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
