
用于特定目标情感分析的交互注意力网络模型
2020-09-15 04:47刘国利
计算机工程与应用 2020年18期
韩 虎,刘国利
1.兰州交通大学 电子与信息工程学院,兰州 730070
2.甘肃省人工智能与图形图像工程研究中心,兰州 730070
1 引言
特定目标情感分析是情感分析领域中的一项子任务[1]。给定一条评论和评论中出现的目标,特定目标情感分析的目的是确定每个目标的情感极性(如积极、中性或消极)。例如,在评论“The voice quality of this phone is amazing,but the price is ridiculous”中,有两个目标“voice quality”和“price”,其中目标“voice quality”由两个词组成,其所表达的情感极性是积极的,而目标“price”表达的情感则是消极的。Jiang等人对一个Twitter情绪分类器进行了手工评估,结果表明40%情感分析的错误是源于没有考虑句子中的目标信息[2]。因此,特定目标情感分析的任务也可以描述为预测一个“评论-目标”对的情感极性。
近年来,神经网络在各个研究邻域取得了显著的进展。Zhang 等人将海温预测问题转化为时间序列回归问题,首次利用长短时记忆网络(LSTM)来预测海面温度[3]。高雅等人通过神经网络挖掘移动对象轨迹数据中的隐含规律,在原始模型上加入LSTM 进行位置预测[4]。华冰涛等人基于深度学习的优势构建了用于意图识别和槽填充的神经网络模型,较传统模型获得较高的性能[5]。王凯等人提出了一种基于长短时记忆网络的动态图模型用于异常检测,提高了网络入侵事件检测的准确率[6]。同时,在情感分析邻域,神经网络也取得了比传统方法更好的结果。例如Dong 等人在2014 年提出基于递归神经网络来评估特定目标在上下文词中的情感倾向[7]。Vo 和Zhang 将整个句子分为三个部分,即,上文、目标和下文,并使用神经池化函数和情感词典来提取特定目标的特征向量[8]。Tang 等人将句子分为带目标的上文和带目标的下文,然后使用两个长短时记忆(LSTM)网络分别对这两部分进行建模,学习针对特定目标的句子表示[9]。为了进一步关注句子中特定目标情感的重要部分,Wang 等人将目标词嵌入计算平均值后与句子中的每个词向量表示进行拼接,使用LSTM网络和注意力机制(attention mechanism)生成最终的情感表示[10]。
虽然这些方法已经意识到特定目标在情感分析中的重要性,但是这些方法存在两个问题:(1)当目标由多个词组成时,目标中不同的词对情感分析的重要性也是不一样的,以上对目标中所有词的词向量求平均的方法会丢失评论中重要的情感信息;(2)以上方法只关注目标对上下文建模的影响。如何利用目标与上下文之间的交互作用,来分别对目标与上下文进行建模,已成为一个新的研究课题。针对以上问题,Ma 等人提出了一个IAN模型,该模型使用两个LSTM网络分别对句子和目标短语进行建模,然后利用句子的隐层表示生成目标短语的注意力向量,反之亦然[11]。在文献[11]的基础上,本文提出一种交互注意力网络模型(LT-T-TR)进一步提高目标和上下文的表示。首先,将评论分为三个部分:上文(包含目标)、目标短语、下文(包含目标),其中目标由一个或多个词组成,然后利用三个Bi-LSTMs 分别对上述三部分进行建模。其次,通过目标与上下文的交互学习,来计算目标与上下文的注意力权重,注意力权重的计算主要包括两部分:第一部分是目标-上文注意力权重和目标-下文注意权重的计算;第二部分是上文-目标注意力权重和下文-目标注意力权重的计算。计算这两部分注意力权重之后,得到了目标和左右上下文的最终表示。最后,将三部分最终表示进行拼接,形成最后的分类向量。本文模型较其他模型主要有以下几点优势:(1)本文对目标短语和上下文采用相同的方法(Bi-LSTM)进行建模,考虑了目标由多个词组成的情况。以往模型中只使用目标中所有词的词向量平均值来表示目标的方法不能准确区分目标中每个词的重要性。(2)本文利用交互注意力机制计算目标和上下文的表示。因为目标和上下文的表示是互相影响的,在计算上下文的注意力权重时引入目标短语的表示,可以更好地获取当前目标所对应的上下文中重要的部分,从而得到更好的上下文表示,提高模型性能,反之亦然。
2 相关工作
2.1 特定目标情感分析
一些早期的工作研究基于规则的目标情感分析模型。比如Nasukawa 等人[12]首先对句子进行依赖分析,然后使用预定义的规则来确定关于特定目标的情感倾向。近年来,许多特定目标情感分析任务中引入了基于神经网络的方法,并取得了比传统方法更好的结果。梁斌等人[13]将卷积神经网络和注意力机制结合用于特定目标情感分析中。Wang 等人[10]在LSTM 的基础上加入注意力机制,来计算一个注意力向量,提取句子中的不同重要部分,有效识别了句子中不同目标的情感倾向。在此基础上,Ma 等人[11]使用两个LSTM 网络分别对句子和目标进行建模,然后利用句子的隐层表示生成目标短语的注意力向量,反之亦然。因此,模型既能提取句子中的重要部分,又能提取目标中的重要信息。
研究表明,和评论一样,当目标由多个词组成时,目标中不同的词对情感分析的重要性是不一样的,但是很多研究都忽略了这一情况,只使用目标中所有词的词向量平均值来表示目标。此外,目标和上下文的表示是受对方影响的。例如在评论句“I am pleased with the life of battery,but the windows 8 operating system is so bad.”中,对于目标“the life of battery”,上文中的“pleased”比其他词对目标情感影响较大(比如“bad”),占权重比也大。同样地,目标中词“life”和“battery”比词“the”和“of”的权重大。因此,在文献[11]的基础上,本文提出一种交互注意力网络模型(LT-T-TR)用于特定目标情感分析,进一步提高目标和上下文的表示,解决不同目标在特定上下文时的情感倾向问题。
2.2 长短时记忆网络
在处理文本这种变长的序列信息时,长短时记忆网络(Long Short Term Memory,LSTM)可以避免梯度消失或爆炸问题[14],并且能够解决原始循环神经网络(RNN)中存在的长期依赖问题[15],从而可以提取文本中重要的情感特征信息。在LSTM的结构中,有三个门单元:输入门、遗忘门和输出门,以及一个记忆细胞用来对历史信息进行存储和更新。LSTM 中的每个单元可以计算如下:
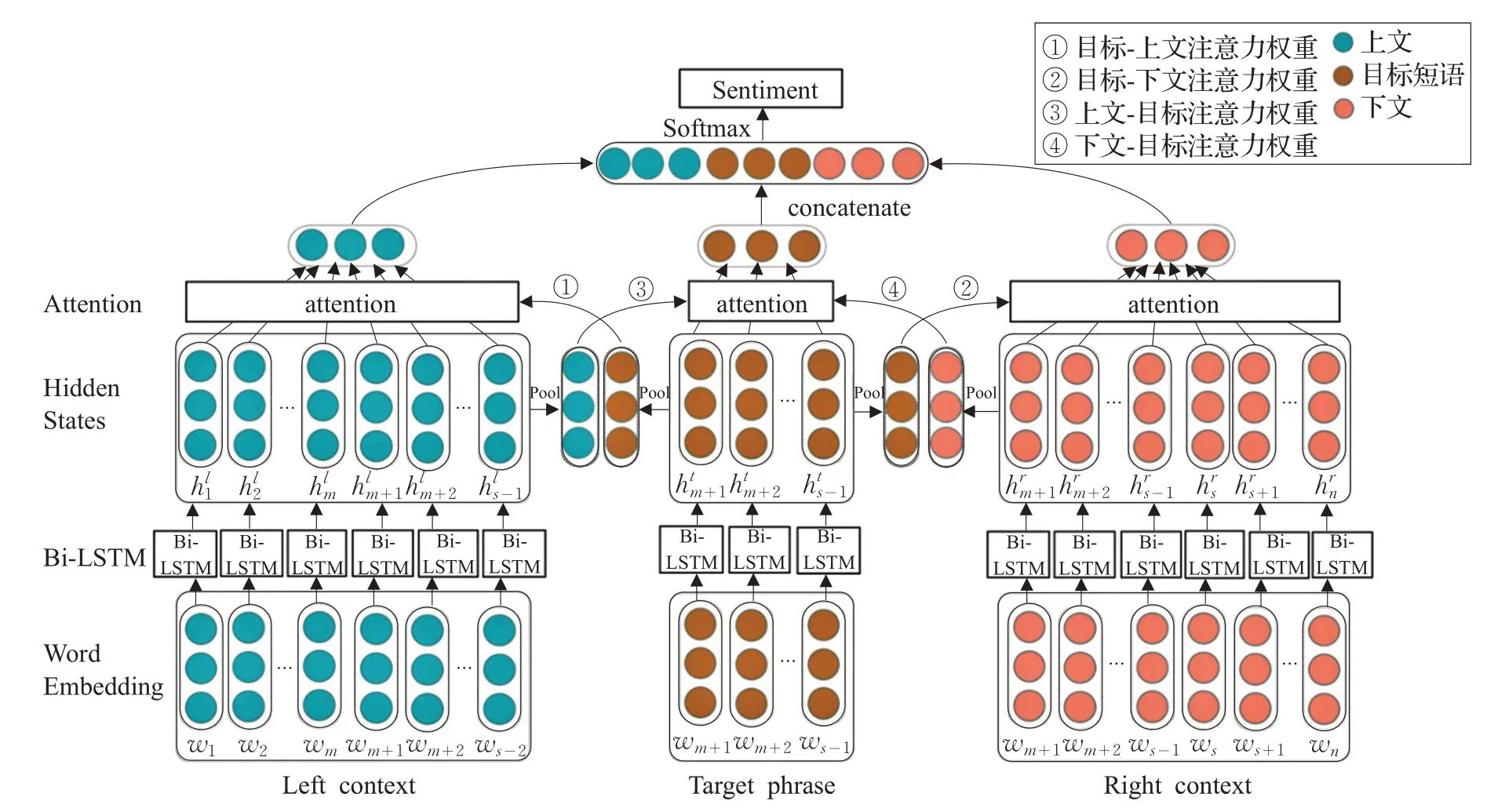
图1 交互注意力网络模型

其中σ是sigmoid函数,tanh是双曲正切函数,W和b分别是权重矩阵和偏置项。vk是LSTM的当前输入,hk-1是上一时刻的隐层状态。ik、fk、ok是输入门、遗忘门和输出门。
本文在标准LSTM 的基础上增加反向的LSTM,通过将正向LSTM 和反向LSTM 进行连接,形成双向的LSTM[16(]Bi-LSTM),来提取上下文中更多的情感特征信息。
3 基于交互注意力网络的特定目标情感分析模型
本文在文献[11]的基础上,提出一种基于Bi-LSTM和注意力机制的交互注意力网络模型,用于特定目标情感分析,模型结构如图1所示,主要包括三部分:
(1)词向量输入矩阵。输入矩阵中存储上文、目标短语和下文中所有词的词向量表示。
(2)Bi-LSTM 网络。对(1)中的三部分输入进行训练,提取情感特征信息,输出上文、目标短语和下文的隐层表示。
(3)交互注意力模型。对于Bi-LSTM 层得到的三部分隐层语义表示,利用注意力机制交互地提取目标短语和上下文中的重要情感信息。
3.1 任务定义
对于长度为n的评论R=[w1,…,wm,wm+1,…,ws-1,ws,…,wn],其中wm+1,wm+2,…,ws-1是评论中的某一个目标,由一个或多个词组成,w1,w2,…,wm是上文,ws,ws+1,…,wn是下文。如图2所示,将评论R根据目标在句中的位置进行重新划分,其中上文组成,目标组成。

图2 评论划分方法
特定目标情感分析的目标是确定评论R对于目标T的情感极性。比如在评论“The voice quality of this phone is amazing,but the price is ridiculous”towards target“voice quality”中,目标“voice quality”的情感极性是积极的,而目标“price”所对应的情感则是消极的。
3.2 词向量表示
给定一条评论R,首先将评论中的每个词映射到一个低维的实数向量,称为词嵌入[17],作为模型的输入向量。即对每个词wi∈R,可以得到向量vi∈ℝd。其中i是单词索引,d是词向量的维度。通过词嵌入操作,分别得到LT、T和RT这三部分的词向量表示:。
3.3 Bi-LSTM网络
在得到三部分词向量表示后,将其同时输入到三个Bi-LSTM网络中,学习上下文和目标短语中词的语义表示。其中每个Bi-LSTM 都是通过连接两个LSTM 网络得到的。
对于上文LT,Bi-LSTM 的输入是词向量序列[v1l,,可以得到如下的隐层表示:


3.4 交互注意力模型
注意力机制(Attention mechanism)可以使模型在训练时关注到文本中哪些信息是比较重要的,本文使用注意力机制来计算与目标相关的上下文的表示以及与受上下文影响的目标的表示。在得到三个Bi-LSTMs生成的上下文和目标的隐层语义表示之后,将上下文和目标的初始表示LTinitial、Tinitial以及TRinitial作为注意力层的输入,来交互计算上下文和目标中不同词的权重大小。
(1)目标-上下文注意力计算


其中,fatt是一个评分函数,用来计算上文中的每个词受目标的影响程度:
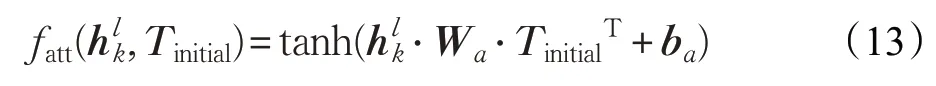
其中,Wa和ba分别是权重矩阵和偏置,tanh 是非线性激活函数,TinitialT是Tinitial的转置。
(2)上下文-目标注意力计算
首先,通过上文的最初表示LTinitial,得到注意力权重:
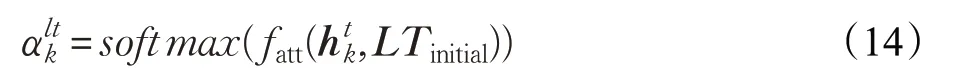
其中,fatt是计算受上文影响的目标中每个词的重要性的评分函数:

其中,WL是权重矩阵,bL是偏置项。
然后,通过加权求和,可以得到受上文影响的目标表示:

同样地,按照公式(14)~(16),可以根据下文的初始表示TRinitial和目标的隐层表示得到受下文影响的目标的表示。

3.5 模型训练
将上文、目标、下文三部分的最终表示LTfinal,Tfinal和TRfinal拼接为一个向量v做为文本最后的分类特征表示:

然后,用一个线性层将文本特征表示转换为与情感类别向量维度相同的向量,再通过softmax 函数将其转换为概率表示,取其中概率最大的值作为评论R中目标T的情感极性判断:

其中,W和b是softmax层的参数。在模型训练中使用交叉熵损失函数作为模型的优化目标:

其中,D是所有的训练数据。pc是模型输出的预测d的情感极性为c类的概率,是实际的情感类别。
4 实验
4.1 实验数据与实验平台
本文使用SemEval-2014[18]数据集进行实验验证,SemEval-2014 数据集包含 la ptop 和 r estaurant 两 个 领域的用户评论,数据样本的情感极性分为积极、消极和中性三种,数据集具体信息如表1所示。

表1 SemEval 2014数据集统计
本文实验平台信息如表2所示,实验基于Google的Tensorflow 深度学习框架,Tensorflow 集成了多种神经网络模型(卷积神经网络和LSTM等),并提供CPU/GPU并行计算能力,降低了模型构建代码的难度,提高了实验效率。因此,本文虽然利用三个Bi-LSTMs对上文、目标短语和下文进行建模,但运算效率并不低于其他的对比模型。

表2 实验平台设置
4.2 实验参数与评价指标
在实验中,使用GloVe[19]对上下文和目标短语中所有的词进行初始化。对于未登录词和权重矩阵,使用均匀分布U(-0.1,0.1)对其进行随机初始化,将所有的偏置初始化为0,将词向量的维度和LSTM 的隐层数设为300。其他的超参数设置如表3所示。

表3 实验参数设置
采用准确率作为评估本文模型的指标,计算公式如下:

其中,T表示LT-T-TR 模型正确预测评论类别的数量,N是样本总数。
4.3 对比实验
将本文提出的方法LT-T-TR 与以下几种目标情感分析方法进行比较。
(1)Majority:统计训练集中出现概率最大的标签值作为所以测试集样本最终的情感标签。
(2)LSTM:文献[6]提出的模型,使用一个单独的LSTM网络对评论进行建模,将LSTM的最后一个隐层状态输出作为最终分类的评论表示。
(3)TD-LSTM:将一条评论划分为包含目标的左半部分和包含目标的右半部分,然后使用两LSTM网络分别对这两部分进行建模,学习针对特定目标的句子表示[6]。
(4)AE-LSTM:文献[7]提出的基于LSTM和注意力机制的分类模型。首先通过LSTM对评论进行建模,然后将目标中所有词的平均向量和LSTM 的隐层表示进行拼接来计算每个词的注意力权重,最后以加权求和的方法得到评论的最终表示。
(5)ATAE-LSTM:在AE-LSTM 的基础上将目标中所有词的平均向量在输入层与每个词向量进行拼接形成新的输入向量。
(6)IAN:文献[11]提出的交互注意力模型,使用两个LSTM对句子和目标短语进行独立建模,然后利用句子和目标短语的隐层表示生成两个注意力向量用于最后的分类。
4.4 实验结果与分析
本文在SemEval-2014 数据集上进行7 组模型的实验对比,情感分类准确率如表4所示。
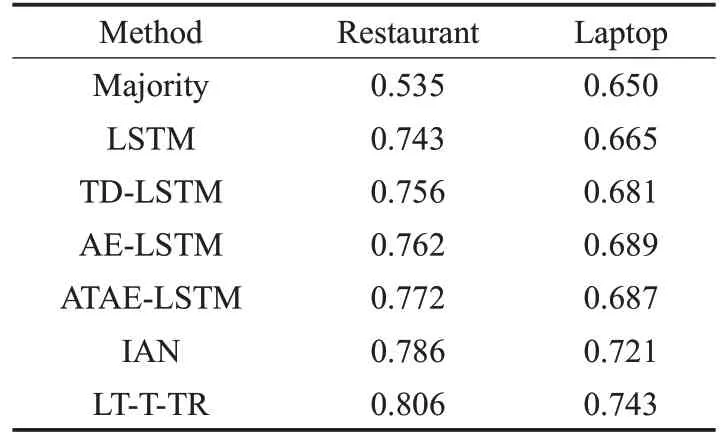
表4 不同模型的实验准确率
从表4的实验结果可以看出Majority方法的准确率是最差的,这是因为Majority没有提取到任何的文本信息,这证明好的文本表示对目标情感分析非常重要。其次在所有基于LSTM的方法中,基础的LSTM的准确率最差,这是因为LSTM模型将一条评论作为一个整体进行建模,而忽略了句子中不同目标的重要性,从而无法准确判断句子中不同目标的情感极性。因此在模型中加入了目标信息的情况下,TD-LSTM 在Restaurant 和Laptop 数据集上的准确率较基础的LSTM 提升了1.3%和1.6%。AE-LSTM和ATAE-LSTM在模型中引入了注意力机制,使得模型在训练过程中能够更好地提取句子中与情感分析结果相关的重要信息,准确率有了明显的提升。然后,与所有基于LSTM 的方法相比,交互模型IAN 在 Restaurant 和 Laptop 数据集上较 ATAE-LSTM 提升了1.4%和3.4%,这是因为IAN 在对整条评论进行建模的同时也考虑了目标中每个词的重要性,并且加强了目标短语和评论之间的交互学习。最后,LT-T-TR模型的性能明显优于IAN 和其他所有模型。这更加强了之前的假设,即能够交互式地捕获目标和上下文之间依赖关系的模型可以更好地预测文本信息的情感倾向,取得更好的分类效果。
为了进一步验证本文模型的有效性,选择不同的序列模型,包括RNN、LSTM 和GRU,分析其对实验结果的影响。表5为不同序列模型在Restaurant和Laptop评论数据集上的准确率对比结果。可以看出,GRU 的性能优于LSTM,而LSTM在精度指标上又优于RNN。这是因为GRU 和LSTM 具有更复杂的隐层单元,比RNN具有更好的组合能力。而与LSTM相比,GRU需要训练的参数更少,因此可以比LSTM更好地进行泛化。然后与GRU和LSTM相比,Bi-LSTM的性能稍好一些,因为Bi-LSTM较LSTM和GRU能够捕获更多的上下文情感信息。
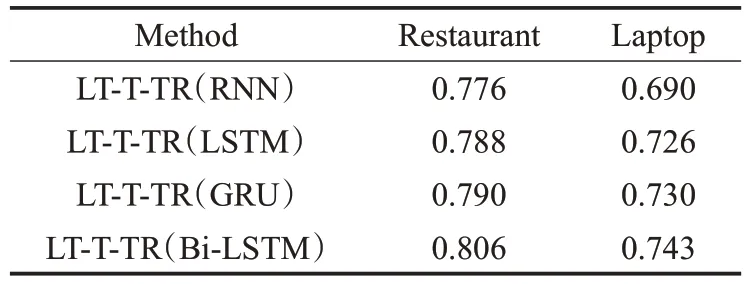
表5 不同序列模型的分类准确率
为了验证目标短语和左右上下文之间的划分方法以及交互注意力建模对实验结果的影响,设计下面的对比模型来验证LT-T-TR模型的有效性。首先,将评论作为一个整体而不是分为三个部分输入到Bi-LSTM中进行建模,然后使用注意机制计算每个词对最终情感类别的贡献度。这个模型称为No Separation 模型。其次,简化LT-T-TR模型,即使用目标短语的词向量的平均值作为目标短语的整体表示,而不是输入到Bi-LSTM 中进行独立学习(No Target-Learned模型)。进一步,比较目标和左右上下文之间的交互注意力建模对实验结果的影响。首先,通过去除目标与左右上下文之间的注意力交互,建立了一个没有注意力交互的模型(No Interaction模型),只学习目标和上下文他们自身的Bi-LSTM隐层输出下的注意力权重表示。然后,考虑了Target2Context 模型,它基于文献[11]中Ma 等人的设计思想。最后,通过将评论内容划分为不包含目标的上文、目标和不包含目标的下文三部分,建立L-T-R 模型,使用与LT-T-TR模型相同的方法建模。
各个模型的实验对比结果如表6 所示。可以看到No Separation模型的实验结果最差,No Target-Learned模型的实验准确率也低于No Interaction 模型和Target2Context模型,这验证了目标短语独立建模对情感极性判断的重要性。同时LT-T-TR模型和L-T-R模型优于Target2Context 模型,这表明目标短语和左右上下文之间的交互对于判断特定目标的情感极性是至关重要的。而L-T-R 模型的结果略差于LT-T-TR 模型,是因为目标短语不包含在上下文中,所以提取的情感信息比LT-T-TR模型要少。

表6 LT-T-TR模型分析结果
为了进一步分析注意力层的权重计算对目标和上下文表示的作用,设计下面的对比模型来验证LT-T-TR模型中注意力层的有效性。首先删除LT-T-TR模型中上文对应的Attention计算层,建立No-Left-Attention模型。然后以同样的方式删除下文和目标短语的Attention计算层,建立No-Right-Attention 模型和No-Target-Attention模型,最后将上下文中的Attention 计算层同时去除,建立No-Attention模型。三种模型中对于删掉Attention计算层的上/下文,直接以BI-LSTM 的隐层输出的平均值来表示。实验结果如表7所示。

表7 实验结果
从表7 可以看到,No-Attention 模型的实验准确度最低,这是因为上下文和目标短语中不同的词对分类结果的重要性不一样,而注意力机制可以通过给上下文和目标短语中不同的词分配不同大小的权重,对重要的词进行突出表示,所以删除了所有注意力层的No-Attention模型结果最差,其次是No-Left-Attention、No-Right-Attention和No-Target-Attention。
5 结束语
针对传统基于LSTM 的方法没有充分考虑到目标短语的独立建模问题以及目标短语与上下文之间存在相互影响的关系,提出了一个交互注意力网络模型用于特定目标情感分析。LT-T-TR 模型利用Bi-LSTM 和注意机制交互学习目标短语和上下文中的重要部分,生成最终的评论表示。在SemEval 2014数据集上的对比实验也表明,LT-T-TR 模型较传统的LSTM 方法有明显的提高,具有更好的性能。通过不同的序列模型和池化方法进行分析,实验结果表明不同的序列模型可以在上下文和目标短语中有区别地学习重要的部分,此外,结合平均池化和最大池化方法可以取得最佳准确率。最后从句子划分和注意力交互两方面出发,设计了不同的对比模型,也验证了LT-T-TR 模型的有效性。同样,由于实验训练样本较少,实验过程也会出现过拟合、分类错误等问题,之后会针对该问题继续改进。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
海峡姐妹(2016年2期)2016-02-27
新高考·高二数学(2015年11期)2015-12-23
