
基于YOLO算法的手势识别
2020-09-15 02:37王粉花黄超赵波张强
北京理工大学学报 2020年8期
王粉花,黄超,赵波, 张强
(1.北京科技大学 自动化学院,北京 100083; 2.北京科技大学 人工智能研究院,北京 100083;3.北京市工业波谱成像工程中心,北京 100083)
手势是聋哑人日常交流的主要方式. 据统计,在我国约有2 057万的聋哑人,占全国总人口的1.67%[1]. 手语是正常人与聋哑人交流的主要形式,手势识别的研究对于促进手语翻译的发展具有重大意义. 同时手势在人机交互方面也具有巨大的应用前景,例如:Kinect3D体感摄影机、引入手势识别功能的宝马iDrive系统等.
在早期的手势识别方法中,主要基于数据手套和视觉的手势识别方法. 基于数据手套的手势识别[2]其优点是识别率高,但不足之处是需要大量传感器辅助,佩戴繁琐,只借助计算机无法实现. 基于视觉的手势识别,主要通过手势的特征提取,如利用肤色、形态等特征将手势分割出来,然后通过支持向量机(SVM)等分类算法进行识别. 该方法的关键之处在于手势区域的提取,这是提高识别率的关键所在. Grobel等[3]使用基于隐马尔可夫模型的手势识别,对262个手语的识别达到了94 %的准确率. 识别效果很好,但是需要在测试者的手上佩戴颜色手套,辅助手势分割. 基于肤色的手势提取方法,成功摆脱了数据手套和颜色手套的繁琐,但是识别率不高,泛化能力不强,依然存在很多问题. 杨红玲等[4]使用骨架特征图像和边缘特征图像进行融合,实现石头、剪刀、布的识别,准确率达到98.57%. 其不足之处是识别的图像手势占主体,并不是一般的自然手势图像. Dominio等[5]提出的基于Kinect深度信息的手势识别方法,最高可以达到99.5%的准确率,其缺点是算法复杂,距离变换性差,设备装置要求高. 张晓燕[6]使用了基于肤色和已有的模板进行匹配的手势识别技术. 强彦等[7]提出基于栈式稀疏自编码多特征融合的快速手势识别方法.
随着目标检测的发展,使很多学者将手势识别的分类问题转换成目标检测问题. 2014年,Girshick等[8]在CVPR(computer vision and pattern recognition)大会上提出了R-CNN目标检测网络,随后又提出了Fast R-CNN[9]、Faster R-CNN[10]等两步检测的算法,将识别速度和识别准确度进一步提升. 同时Redmon等[11]在2016年的CVPR大会提出了一步检测的YOLO(you only look once)算法,其检测速度相较以前的算法得到很大的提高,能达到45 FPS(frames per second),从而受到更多人的青睐. Liu等[12]在ECCV2016上提出了SSD(single shot multibox detector)目标检测算法,随后张勋等[13]在SSD的基础改进上使用了轻量化的ASSD模型,实现手势的实时检测. Redmon等[14]在2017的CVPR大会上提出了YOLOv2算法,将识别率进一步提升. 随后在2018年提出了YOLOv3算法[15],对小目标的识别率进一步得到改善,同时也发布了YOLOv3的快速版本YOLOv3-tiny算法,检测速度可达220 FPS. Ni等[16]在改进YOLOv2算法,并且在此基础上进行了剪枝,提出了模型只有4 M的轻量化模型. 三维卷积的出现,出现了很多基于3D -CNN的手势识别方法,如Abavisani等[17]提出的多种模态的知识来训练单模3D -CNN. Nguyen等[18]利用手骨骼的3D坐标,实现手势识别.
1 YOLO算法模型
本文提出的YOLOv3-tiny-T算法可以到达220 FPS识别速度. 相对于其他深度学习模型具有较高的速度,这对于将手势识别应用到嵌入设备中具有重大意义. 本文的主要工作有:①提出的YOLOv3-tiny-T网络,利用不同通道的信息融合,提高了网络的识别率;②YOLOv3-tiny-T网络保持了YOLOv3-tiny算法识别速度;③研究为手语识别以及行为识别提供了很好的研究价值.
1.1 YOLO算法简介
YOLO算法模型有YOLOv1、YOLOv2和YOLOv3 3个系列的版本,同时还有一些快速版本. YOLOv1网络结构是在GoogleNet网络20层的基础上添加了4个卷积层和2个全连接层. YOLOv1算法将图像分成7×7的网格(grid cell),当物体中心落入某个网格中,这个网格就负责预测这个物体,每个网格分配2个边界框,最终输出的是7×7×30的张量. 其中30是通道数,包含2个边界框的5个坐标信息:中心点坐标x、y,预测框的长h,宽w和置信度cc,共10个通道. 中心点坐标x和y是相对每一个网格而言的,用坐标(0,0) 表示网格的左上角,用坐标(1,1)表示网格的右下角,宽和高是相对于整个图片而言的,取值在0到1之间. 置信度如式(1)所示
(1)

计算式为

(2)
剩下20个通道表示20类物体在网格中存在物体中心的情况下,是某个物体的概率,表示为P(ci|o). 预测物体的得分如式(3)所示
式中P(ci)为20个物体中第i个物体的概率.
YOLOv1将目标检测问题看成是回归问题,损失函数采用均方误差,如式(4)所示
从著作权的角度看,对非物质文化遗产的保护与知识产权制度的契合点存在于非物质文化遗产的特点。非物质文化遗产所具有的独创性和可复制性正切合了著作权所保护的客体,比如我们民间剪纸艺术作品,它是民间剪纸艺术家通过繁琐的体力和智力劳动所独家制造出的具有可复制性的智力成果。根据我国《著作权法》的规定,作品是指“文学、艺术和科学领域内具有独创性并能以某种有形形式复制的智力创造成果。”由此,作品应当是独创性的、可复制性的,并且是存在于文学、艺术和科学领域内的智力成果。民间剪纸艺术作品作为一种图案,具备作品所必须具有的要素,是我国著作权法的保护客体。
(4)
YOLOv2算法模型在YOLOv1的基础上进行了一些改进. YOLOv2使用Darknet19为基本结构. Darknet19网络结构与VGG网络结构类似,效果相当,都是采用小卷积核操作. YOLOv2中借鉴了Faster R-CNN算法,引入了锚点框(anchor boxes),为每个网格生成更多的候选框. 同时在锚点框的选择上,采用k-means聚类算法,选择更接近对象的锚点框,使网络收敛得更快,更容易学习. 其中k-means聚类算法的距离使用交并比来衡量,距离计算如式(5)所示
d(b,c)=1-U(b,c) ,
(5)
式中:c为聚类中心;U(b,c)为中心框和真实框的交并比.
YOLOv2还使用批量规范化(batch normalization),对每一层的输入进行处理,大大提高了训练速度,并防止过拟合,取代了原来的Dorpout层. YOLOv2借鉴SSD中的细粒度特征,将浅层特征链接到深层特征中. YOLOv2在训练的过程中,每训练10步就会在320~608以32为间隔,在这10个尺寸里随机更换一个尺寸,进行变换尺寸训练,提高对不同大小图片的泛化性能.
YOLOv3算法模型是在YOLOv2模型的基础上进行了改进,使用更深的网络结构Darknet53. Darknet53网络和ResNet101网络的效果相近,但是Darknet53网络的识别速度是RetinaNet101网络的2倍. Darknet53网络交替使用3×3、1×1的卷积和残差结构[19],同时使用FPN架构(feature pyramid networks for object detection)[20]来实现多尺度检测. YOLOv3使用9个锚点框,每个尺度对应3个锚点框,小尺度使用大的锚点框,大尺度使用小的锚点框,有利于小目标的检测.
1.2 YOLOv3-tiny算法简介
2 YOLO算法模型改进
本文对YOLOv3-tiny算法的主要改进在于添加了1×1的卷积层. 1×1的卷积核可以将不同维度的特征融合,得到预设的通道数. 当得到的通道数增加时,就起到了升维的作用;反之就起到了降维的作用. 本文使用1×1的卷积核的目的是进行降维处理,以便减少参数、降低计算量,同时利用不同通道的信息融合提高网络的识别率.
在YOLOv3算法中使用了大量的3×3和1×1的卷积核,并且使用残差网络. 3×3的卷积核负责寻找特征,1×1的卷积核负责压缩通道数. YOLOv3算法还使用步长为2,大小为3×3的卷积层,代替池化层,降低维度. 而在YOLOv3-tiny中除使用了少量的1×1的卷积核外,几乎没有使用其他比较好的网络结构. 本实验在YOLOv3-tiny网络结构的基础上提出了YOLOv3-tiny-T网络,YOLOv3-tiny-T是在YOLOv3-tiny的6个最大池化层后依次添加1×1×8,1×1×16,1×1×32,1×1×64,1×1×128,1×1×256的卷积层,将最大池化后的通道数缩减为原来的1/2,减少了参数量和计算量,其结构如图3所示.
3 实验及结果分析
3.1 实验平台
实验是在PC机上完成. PC的主要配置为Ubuntu16.04操作系统,CPU为 E5-2660 v4,显卡为TITAN Xp,内存32 G. 实现框架为DarkNet,并使用OpenCV进行图像显示.
3.2 实验数据
提出的UST数据集是通过计算机摄像头采集的1 203张图片,包括5种手势,分别定义为h0,h1,h2,h3和h4,如图4所示. 同时每一种手势中既有左手手势又有右手手势. 其中h0有231张,h1有249张,h2有240张,h3有234张,h4有249张. 利用图像标记软件labelimg进行人工标记,其中80%用于训练,20%用于测试. 测试图片一共有241张,为T1;另外又制作了122张图片,为T2,其中h0和h1各有20张,h2有25张,h3有23张,h4有34张.
3.3 评价标准
实验使用平均精度均值(mean average precision,mAP)作为评价标准,他综合考虑了查准率和查全率. 平均精度均值首先需要计算每一个物体类别的平均精度(AP). 平均精度表示为
(6)
式中ρi为在这一类别的P-R曲线(查准率-查全率曲线)上的点的纵坐标. 本文使用的是11点插值法,即在P-R曲线中取出11个数值,求解平均值.
平均精度均值为每一个类别的平均精度的均值,如式(7)所示
(7)
式中n为目标的类别数.
3.4 实验结果
实验对YOLOv1,YOLOv2,YOLOv3以及YOLOv3-tiny和YOLOv3-tiny-T算法的mAP值以及图片的检测时间进行对比,如表1所示. YOLOv1,YOLOv2和YOLOv3在Test2测试集上的漏检和误检个数对比如表2所示. YOLOv3-tiny和YOLOv3-tiny-T 2种算法在每一种手势的AP(average precision)值对比,如表3所示. 此外为了验证YOLOv3-tiny-T算法的快速性,本文中与Light YOLO进行了FPS(每秒传输帧数)对比,如表4所示.
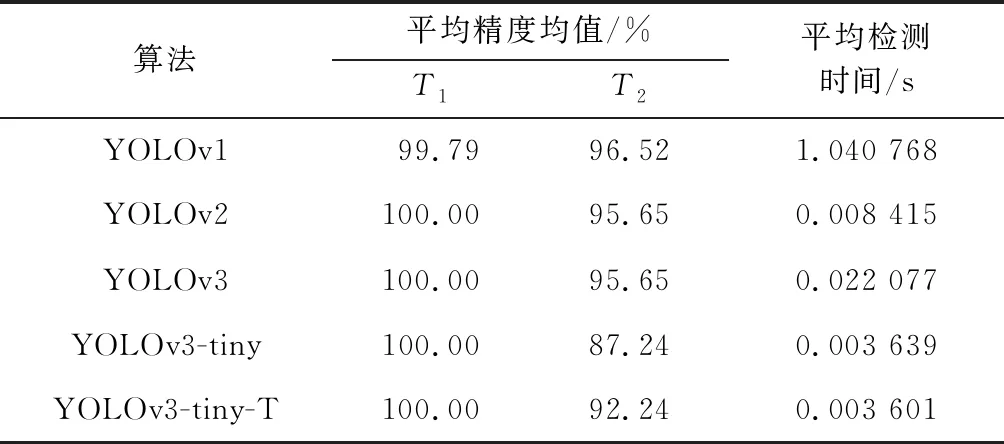
表1 YOLO系列算法mAP对比Tab.1 Comparison of experimental mAP
3.4.1平均精度均值对比
从表1的对比中可以看出,YOLOv1算法在T1测试集中的mAP值最低,而在T2测试集中的mAP值最高.T1测试集是在1 203张图片中随机划分的,与训练数据具有很高的相似性,而T2测试集与训练数据差异较大. 对比表明,YOLOv1的泛化能力较好. YOLOv1算法中使用2个边界框,对于多目标的识别定位误差较大,而本数据集一张图片中只有一个目标,具有较高的mAP值. 而YOLOv2和YOLOv3的很多改进针对的是小目标和一个网格中可能出现多目标的情况进行改进,但对于本数据集来说,可能会增加分类误差. YOLOv2和YOLOv3的网络较深,对于单一的目标容易导致过拟合. 从表2中的误检和漏检对比可以看出,YOLOv1算法存在漏检,YOLOv2和YOLOv3不存在漏检,但是有误检,证实了YOLOv1算法具有较大的定位误差,而YOLOv2和YOLOv3具有较大的分类误差.
3.4.2检测时间对比
从表1的检测时间对比表明,YOLOv1算法在本数据集上的检测速度最慢,其次是YOLOv3算法,YOLOv3-tiny-T算法和YOLOv3-tiny算法检测时间最快. YOLOv1算法的网络结构中使用了全连接层和大的卷积核,增加了网络的计算代价. 而在YOLOv2算法和YOLOv3算法使用小卷积核,用卷积层替代全连接,使用批量规范化取代Dropout层,大大加快了运算速度,降低了计算量. YOLOv3算法比YOLOv2慢,是由于YOLOv3使用Darknet53网络,具有更深的网络结构. YOLOv3-tiny-T算法和YOLOv3-tiny算法识别速度最高是由于网络结构比YOLOv2简单.
3.4.3YOLOv3-tiny-T和YOLOv3-tiny对比
从表3的对比可以看出,在T1测试集上YOLOv3-tiny-T算法和YOLOv3-tiny算法没有差别,但在T2测试集上,除了在h2上前者的AP值比后者低以外,其他均高于后者. 综合各项来看YOLOv3-tiny-T算法的mAP值为92.24%,YOLOv3-tiny的mAP值为87.24%. 从表2的对比可以看出,YOLOv3-tiny算法与YOLOv3-tiny-T算法的识别速度几乎没有什么差别. 图5为YOLOv3-tiny-T算法在较暗、模糊图以及近肤色背景下的检测以及近肤色背景下的检测效果图. 图6为YOLOv3-tiny-T算法检测出现的重框和漏检情况.
3.4.4YOLOv3-tiny-T和Light YOLO对比
Light YOLO模型是基于YOLOv2模型的改进,在结构上去掉了YOLOv2模型第6个卷积块,添加了空间增强模块. Light YOLO模型对小目标的识别率更高,并对模型进行剪枝. Light YOLO模型的识别率较高,但是识别速度比本文的模型要慢. 而YOLOv3-tiny-T中添加的1×1的卷积旨在保持高速性,来提高性能. 表4中YOLOv3-tiny-T和Light YOLO的FPS对比可以发现,YOLOv3-tiny-T的FPS在速度上相当于Light YOLO模型的2倍. 在模型的实时性上具有比较大的优势.
4 结 论
将YOLO算法应用到手势识别中,取得了非常不错的效果,在模糊图像、背景近肤色和光线较暗等多种情况下,识别的准确率都较高. 通过YOLO系列算法的对比实验,得出了在目标比较单一的情况下,YOLOv1算法具有较高的平均精度均值,但速度较慢,YOLOv3-tiny算法和YOLOv3-tiny-T算法具有较快的速度. 同时在YOLOv3-tiny算法的基础上提出的YOLOv3-tiny-T算法在保证了识别速度的情况下,平均精度均值获得了5%左右的提升. 实验表明,YOLOv3-tiny-T具有较好的综合性能. 此外,YOLOv3-tiny-T速度上虽然可以达到Light YOLO快2倍的速度,但是在精度和小目标识别上还有研究的空间.
猜你喜欢
西安邮电大学学报(2020年1期)2020-12-17
红领巾·萌芽(2019年9期)2019-10-09
计算机系统应用(2019年9期)2019-09-24
小学阅读指南·低年级版(2017年6期)2017-06-12
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
汽车文摘(2016年2期)2016-12-09
电脑知识与技术(2016年24期)2016-11-14
软科学(2014年8期)2015-01-20
