
融合多层特征SENet 和多尺度宽残差的高光谱图像地物分类
2020-09-14 08:32于慧伶霍镜宇张怡卓
实验室研究与探索 2020年7期
于慧伶, 霍镜宇, 张怡卓
(东北林业大学a.信息与计算机工程学院;b.机电工程学院,哈尔滨150040)
0 引 言
高光谱图像具有较高的光谱分辨率、丰富的光谱信息以及空间分布信息,常应用于很多不同的领域,例如矿业、天文学、化学成像、精确农业、环境监测和公共安全等方面[1]。近年来,高光谱图像分类成为国内外的研究热点,其中对地物进行详细分类是高光谱图像处理的主要研究问题[2]。
目前,高光谱图像分类主要分为非监督分类方法、半监督分类方法和监督分类方法,非监督分类方法主要包括k-均值方法、非监督模糊聚类以及相应的改进算法等;半监督分类方法主要包括自训练、基于图的方法以及相应的改进算法等;监督分类方法主要包括支持向量机、人工神经网络以及相应的改进算法等。岳江等[3]提出了一种基于空间一致性降元的高光谱图像非监督分类的方法,但这种方法对含有多材质、多目标的复杂场景的高光谱图像分类效果不是很理想;Salem等[4]提出了一种基于模糊C-均值的非监督光谱-空间SVM高光谱图像分类方法,但是这种方法需要对大规模的样本进行标注;王君言等[5]提出了基于DL1图和KNN图叠加图的高光谱图像半监督分类的算法,但是这种方法在处理大样本数据的分类中分类精度不是很高;Samiappan等[6]提出了一种结合半监督协同训练和主动学习的框架。但是由于标签数据过少,高光谱图像的分类精度依旧不是很高;冉琼等[7]提出了结合超像元和子空间投影支持向量机的高光谱图像分类的方法,但是这种方法中超像元的个数无法准确确定;Shamsolmoali等[8]提出了一种网络卷积神经网络的高光谱图像分类的方法,但是这种方法的分类精度还有待提升。
以上分类方法虽然取得了较好的效果,但在性能和准确率上仍有进一步提升的空间。为此,本文提出了一种全新的应用于高光谱图像分类的深度学习网络结构SE-Inception-Resnet-MSWideResnet(SEIRMSWR)。首先,利用主成分分析法(Principal Component Analysis,PCA)对原始的高光谱图像进行降维处理。其次,提出两个深度学习网络结构,①引入一个新的结构单元,称之为“挤压和激励模块”(Squeeze-and-Excitation,SENet),将其分别嵌入到Inception-Resnet-A、 Inception-Resnet-B、 Inception-Resnet-C中,通过学习网络中各个特征通道的重要程度,提升有用的特征并抑制对当前任务用处不大的特征。另外,由于SENet模块在网络结构的不同层上会有不同的作用,为了增强网络的泛化性能,将网络结构的低层特征、中间层特征以及高层特征结合组成更具有表征能力的特征信息。最后,通过Softmax层实现对高光谱图像的分类。②为每一个宽残差网络模块增加更多并行的卷积层。将经过同一输入层映射出的多种不同的输出结果最后连接到一个输出,更精确地获取高光谱图像的特征,实现对高光谱图像的分类。最后,通过结果加权平均模型融合的方式获得高光谱图像的类别。
1 深度学习网络架构
针对高光谱图像分类的问题,提出了一种融合多层特征SENet和多尺度宽残差的深度学习网络结构SEIR-MSWR,该结构不仅能同时提取高光谱图像的光谱和空间特征,而且能提高高光谱图像的分类精度,如图1所示。
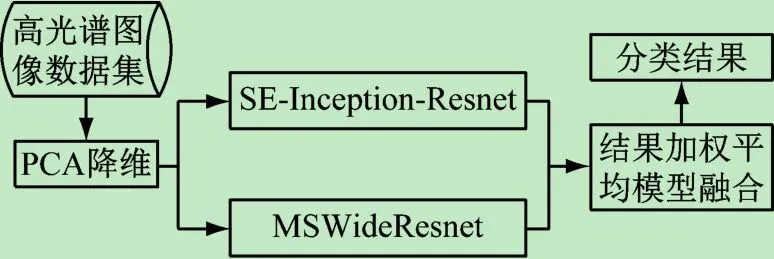
图1 融合多层特征SENet和多尺度宽残差网络结构模型
首先,利用PCA算法对高光谱图像进行降维处理;其次,分别利用多层特征SENet网络结构模型(SEInception-Resnet)和多尺度宽残差网络结构模型(MSWideResnet)对高光谱图像进行分类;最后,利用结果加权平均模型融合的方式输出高光谱图像的类别。
1.1 多层特征SENet网络模型
1.1.1 SENet结构
Hu 等[9]提出了Squeeze-and-Excitation Networks(SENet)架构,该结构由Squeeze、Excitation、Reweight三部分组成,它允许网络通过学习全局信息实现对特征的重新校准,构建特征通道之间的相互依赖关系,激励对分类有用的特征,抑制对分类不太有用的特征[10],如图2所示。首先是Squeeze操作,顺着空间维度对输入特征图进行全局平均池化,得到大小为C×1×1的特征图(C为特征图通道数)。其次是Excitation操作,经过两个全连接层后由Sigmoid函数激活,得到大小为C×1×1的权重。最后一个是Reweight的操作,在对应位置与原输入特征图相乘,得到输出。

图2 SENet模型结构
1.1.2 构建多层特征SENet网络模型
如图3所示,参照InceptionV2-Resnet网络结构,将SENet模块分别嵌入到Inception-Resnet-A,Inception-Resnet-B,Inception-Resnet-C中,同时将网络的多层特征进行融合。各模块设计如图4所示。
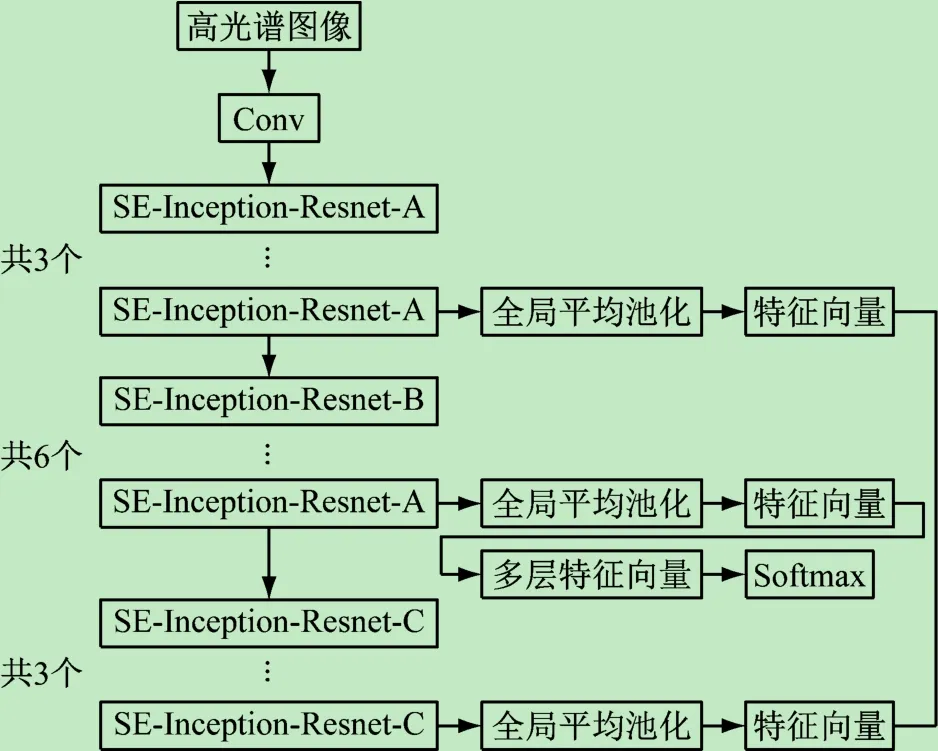
图3 多层特征SENet网络模型
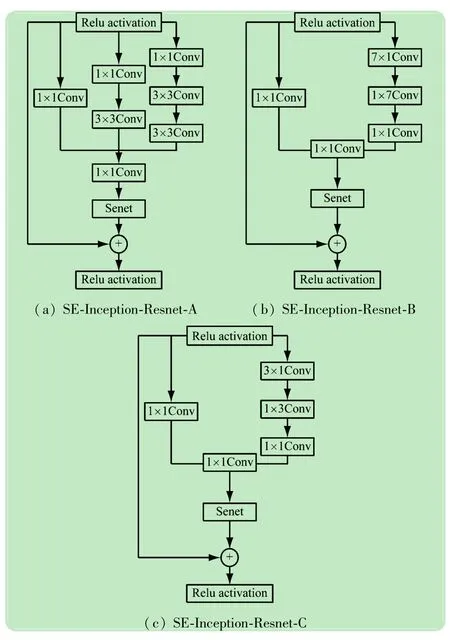
图4 各模块设计
网络结构具体参数如下:
(1)第1层卷积层中卷积核数目为16,卷积核大小为3×3,步长stride为1。
(2)在SE-Inception-Resnet-A模块中,首先进入3个卷积分组,在这3个卷积分组中,卷积核数目都为16,步长stride均为1。其次,3个卷积分组经合并后输入到卷积核数目为32、步长stride为1的1×1卷积层中。此模块共计3个。
(3)在SE-Inception-Resnet-B模块中,首先进入两个卷积分组,在这两个卷积分组中,卷积核数目都为16,步长stride均为1。其次,两个卷积分组经合并后输入到卷积核数目为64、步长stride为1的1×1卷积层中。此模块共计6个。
(4)在SE-Inception-Resnet-C模块中,首先进入两个卷积分组,在这两个卷积分组中,卷积核数目都为16,步长stride均为1。其次,两个卷积分组经合并后输入到卷积核数目为128、步长stride为1的1×1卷积层中。此模块共计3个。
(5)分别将经3个SE-Inception-Resnet-A、6个SE-Inception-Resnet-B、3个SE-Inception-Resnet-C 后输出的特征图进行全局平均池化。
(6)因为高层和中间层还会有一定的信息,所以将低层、中间层以及高层的特征图经全局平均池化得到的特征向量进行特征融合,组成更具有表达能力的特征信息。
(7)将特征向量输入到Softmax进行分类。
1.2 多尺度宽残差网络
1.2.1 宽残差网络
理论上说,模型架构的容量和特征判别能力会随着网络层数的增加而不断提高,然而经大量实验证明,只增加网络的深度会出现梯度弥散问题[11]。针对该问题,何凯明等提出了使用捷径连接(Shortcut Connection,SC)搭建深度残差网络结构[12]。然而,随着残差网络模型深度的不断加深,实验发现只有少数的残差块可以学习到有用的特征。因此,Sergey等[13]提出了宽残差网络模块思想,使用浅而宽的残差网络模块代替原有深而窄的残差网络模块,让网络结构更浅更轻量级[14]。经后续实验证明,适当增加残差网络模块的宽度的确比只增加网络的深度更能提高残差网络的性能,原因是更宽的网络增加了特征的选择范围,从而增加了特征的耦合能力[15]。
各种残差块如图5所示。假设H(x)表示深度神经网络在输入样本x后的最优解映射,传统的卷积神经网络是直接拟合,即

而深度残差网络期望拟合残差映射,即
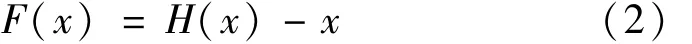
因为x是输入的源图像,所以可以验证拟合F(x)与拟合H(x)的目标是等价的。在此条件下,原来的最优解映射被表示为:
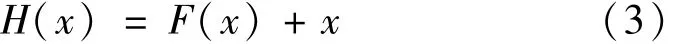
(1)基础残差块。通过跨越性连接,使用两个卷积核大小为3×3的卷积层;
(2)Bottleneck残差块。在两个卷积核大小为1×1的卷积层中间增加卷积核大小为3×3的卷积层,同时为了减少模型的参数、增加网络结构的宽度,使用了比卷积核3×3更多的通道数;
(3)基础宽残差块。在基础残差块的基础上,通过增加卷积层的通道数来增加残差块的宽度;
(4)Dropout宽残差块。为了提升测试结果,体现宽残差网络的泛化性,在2个卷积核大小为1×1的卷积层中间添加Dropout机制。
综上所述,宽残差网络在残差块基础上的改进的确能够提高残差块的表达能力。
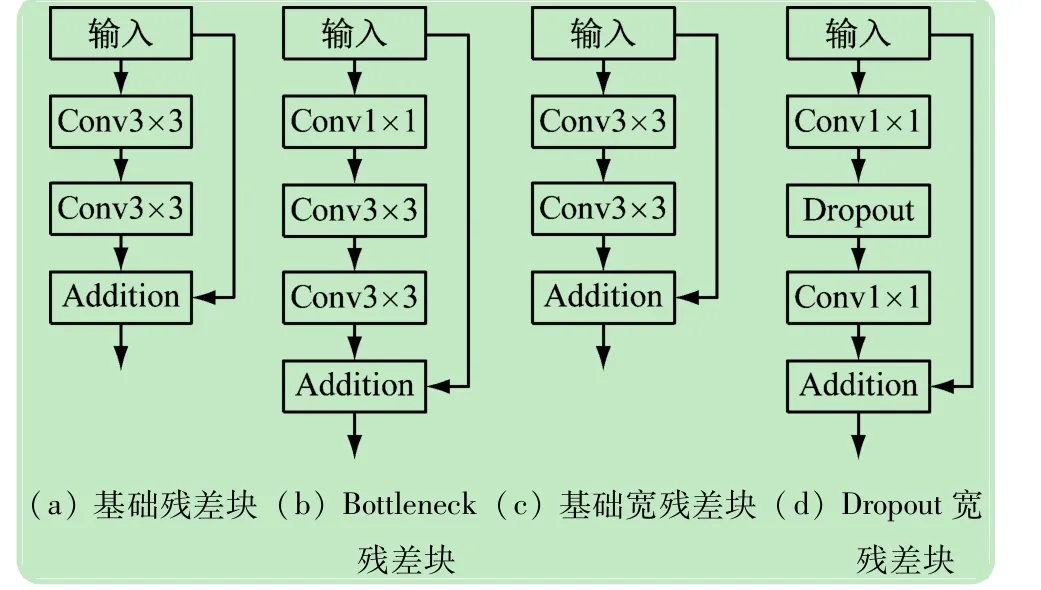
图5 各种残差块
1.2.2 多尺度宽残差网络
本文结合Rubin等[16]提出的Inception模块思想,为实现多尺度的特征学习,适当增加了宽残差块的分支。此外,为了降低网络模型的参数,在新增加的并行连接的卷积层上,没有使用较大的7×7的卷积核,而是使用了1×1、3×3和5×5的卷积核形成多尺度宽残差网络,同时在每个卷积层之前都有相应的BatchNorm和ReLU层。
如图6所示,本文的宽残差模块有6个分支,为了提高网络的表达能力,在除shortcut连接的分支上都有一个1×1卷积,因为1×1卷积不仅可以对通道数进行升维和降维、跨通道组织信息,还可以用很小的计算量就能够增加特征变换和非线性变换。具体结构如下:第1个分支为1×1卷积;第2个分支先用1×1卷积,然后进行3×3卷积;第3个分支先用3×3卷积,然后进行1×1卷积;第4个分支先用1×1卷积,然后进行5×5卷积;第5个分支是使用5×5卷积后再执行1×1卷积;最后1个分支是shortcut连接;最后通过连接操作合并。
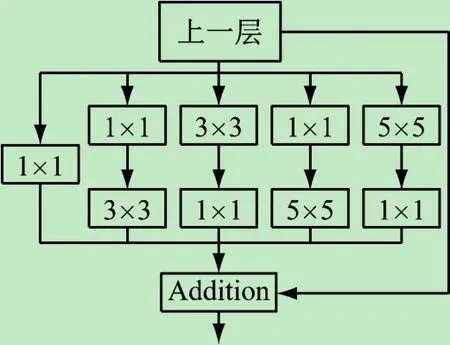
图6 多尺度宽残差学习块
本文的多尺度宽残差网络结构MSWideResnet如图7所示,宽残差模块的总层数为16,残差块的宽度由加宽系数k决定,其中k=4。
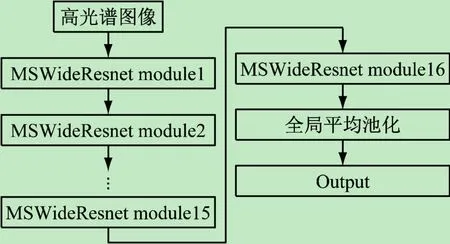
图7 多尺度宽残差网络模型
2 实验结果和分析
实验采用的计算机配置是i7-6700 CPU,20 GB RAM,软件为Spyder(3.2.6)。
2.1 实验数据集
为了比较本文算法的分类效果,选取Indian Pines数据和Pavia University数据进行实验。Indian Pines是由AVIRIS传感器获得,高光谱图像大小为145×145像素,其空间分辨率能够达到20 m,采用的光谱范围为0.4 ~2.5 μm,共包含了200 个波段。Pavia University是由ROSIS传感器获得,高光谱图像大小为610×340像素,其空间分辨率能够达到1.3 m。采用光谱覆盖范围为0.43 ~0.86 μm,共包含103 个波段。
2.2 数据预处理
高光谱图像的数据量往往很大,如果直接对原始图像进行处理,不仅会造成很大的计算量而且会造成分类精度较低。为了加快训练和分类的过程,采用PCA算法降低高光谱图像的维数。虽然利用该方法降维会导致光谱信息的损失,但空间信息仍保持完整。经过PCA算法降维后,主要信息容易集中在少数几个波段,如表1 Indian Pines主成分,表2 Pavia University主成分所示。

表1 Indian Pines主成分

表2 Pavia University主成分
在本实验中,选取累计贡献率大于或等于98%的主成分来取代原始图像,进而压缩数据。从表1、2可以看出,图像的主要成分主要集中在前3个主分量上,后面大部分的分量都是噪声。
2.3 对比算法和评价指标
为了验证本文中SEIR-MSWR模型在高光谱图像分类中的效果,将其与其他常见的分类算法做对比实验。主要包括支持向量机(Support Vector Machine,SVM)、K-最近邻法(K-NearestNeighbor,KNN)、宽残差网络(Wide Resnet Network,WRN)以及InceptionV2-Resnet。
在进行高光谱图像降维前,首先对输入的原始高光谱图像数据进行归一化,令每一个数值位于区间[0 1]。在完成高光谱图像分类后,依照地面真实数据,采用4个常见的高光谱图像分类精度指标(整体分类精度(Overall Accuracy,OA)、平均分类精度(Average Accuracy,AA)、每类分类精度(Class Accuracy,CA)以及Kappa系数)对高光谱图像的分类结果进行客观评价,评估分类结果的准确程度。
2.4 实验结果分析
将经PCA算法降维后的3维高光谱图像分别输入到5种网络结构中,为保证不同分类算法的训练数据、测试数据均相同,即从每个地物类别中随机选取70%的标记样本作为训练样本,另外30%的标记样本为测试样本。此外,为更精确地实现高光谱图像的分类,均选取在训练数据上分类精度最高的模型对测试数据进行分类,并与真实的地物标记对比评价分类精度。网络结构确定后,利用均值为0、方差为0.1的截断正态分布对卷积层和全连接层的权重进行随机初始化,设置偏置为0.1,Dropout为0.5。采用Adam 优化器对网络进行训练,在SVM算法中,通过gridsearch方法找到最优参数c和gamma的值,分别为c=0.01,gamma=100;在KNN算法中,通常采用交叉验证的方法来选取合适的k值,即k=1;在WRN网络模型中的初始学习率设置为0.001,batchsize设置为128,最大迭代次数为12 000次;InceptionV2-Resnet网络模型的初始学习率设置为0.01,batchsize设置为200,最大迭代次数为12 000次;本实验的SEIR-MSWR网络模型的初始学习率设置为0.000 1,batchsize设置为200,最大迭代次数为12 000次。采用结果加权平均模型融合时,SE-Inception-Resnet网络模型以及MSWideResnet网络模型的权值分别为0.6,0.4。
(1)Indian Pines数据集。图8给出了训练过程中损失函数的变化情况。可以看出,随着迭代次数的增加,损失函数呈下降趋势。当迭代次数增加到一定范围时,损失函数的下降趋于平缓。同时,InceptionV2-Resnet和SEIR-MSWR损失函数的下降趋势明显陡于WRN。
图9给出了3种深度学习网络结构在训练过程中总体分类精度的变化情况。从中可以看出,随着迭代次数的增加,总体分类精度呈上升趋势。同时,InceptionV2-Resnet和SEIR-MSWR总体分类精度的增长速度较强于WRN。

图8 Indian Pines在训练过程中损失函数的变化情况
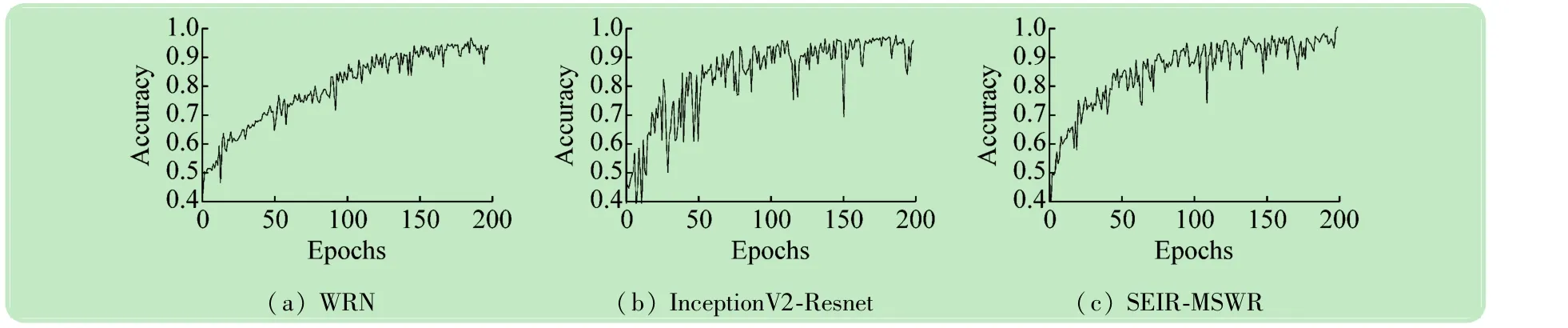
图9 Indian Pines在训练过程中总体分类精度的变化情况
图10 给出了Indian Pines数据集上不同算法的分类图,SEIR-MSWR分类噪声相比于其他方法更少,获得了更好的分类效果。但是对于数据集中易于区分的地物类别,SEIR-MSWR分类效果于其他方法相当,如Wheat、Hay-windrowed。对于特征相近的地物类别,SEIR-MSWR能很明显地提高分类精度,从而改善总体的分类效果。
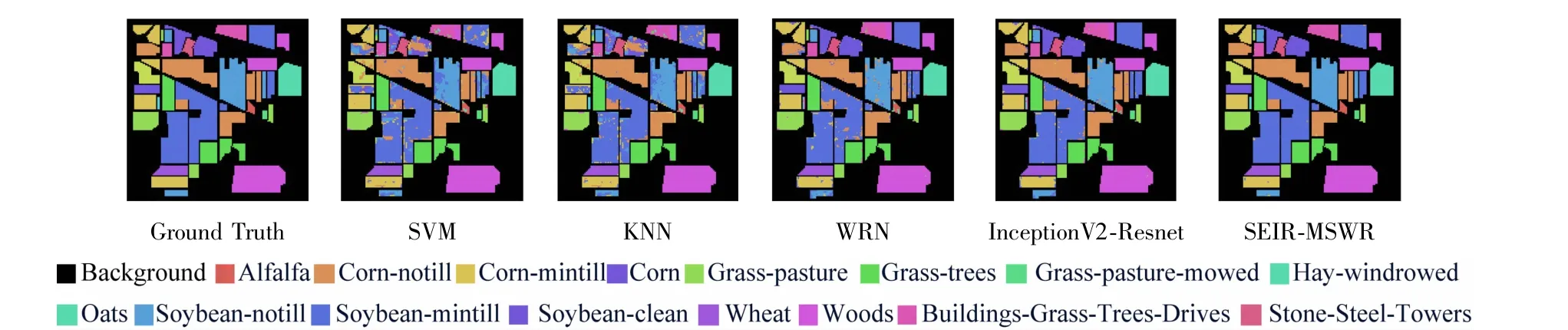
图10 Indian Pines高光谱图像分类结果
表3给出了Indian Pines高光谱图像数据集对应的分类结果,针对OA、AA和Kappa系数,WRN、InceptionV2-Resnet以及SEIR-MSWR较SVM和KNN有较为明显的提升。此外,SEIR-MSWR的OA相比于RBF-SVM、KNN、WRN 和InceptionV2-Resnet分别提高了20.86%、20.09%、5.48%、3.39%,AA 分别提高了17.98%、16.31%、6.03%、3.73%,Kappa 分别提高了0.18、0.17、0.06、0.04。

表3 Indian Pines数据集上各种分类算法的正确率统计%
(2)Pavia University数据集。图11给出了训练过程中损失函数的变化情况。从中可以看出,随着迭代次数的增加,损失函数呈下降趋势。当迭代次数增加到一定范围时,损失函数的下降趋于平缓。同时,WRN损失函数的波动明显高于InceptionV2-Resnet和SEIR-MSWR。
图12给出了3种深度学习网络结构在训练过程中总体分类精度的变化情况,从中可以看出,随着迭代次数的增加,总体分类精度呈上升趋势。当迭代次数增加到一定范围时,分类精度的增长趋于平缓。同时,WRN总体分类精度的波动明显高于InceptionV2-Resnet和SEIR-MSWR。
图13给出了Pavia University数据集上不同算法的分类图,SEIR-MSWR分类噪声相比于其他方法更少,获得了更好的分类效果。但是对于数据集中易于区分的地物类别,SEIR-MSWR分类效果于其他方法相当,如Meadows、Trees。对于特征相近的地物类别,SEIR-MSWR能很明显地提高分类精度,从而改善总体的分类效果。
表4给出了Pavia University高光谱图像数据集对应的分类结果,针对OA、AA和Kappa系数,WRN、InceptionV2-Resnet以及SEIR-MSWR较SVM和KNN有较为明显的提升。此外,SEIR-MSWR的OA相比于RBF-SVM、KNN、WRN 和InceptionV2-Resnet分别提高了23.1%、16.89%、6.66%、2.58%,AA 分别提高了23.1%、19.13%、7.42%、3.35%,Kappa 分别提高了0.22、0.17、0.07、0.03。
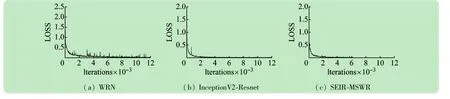
图11 Pavia University高光谱图像损失函数的变化情况
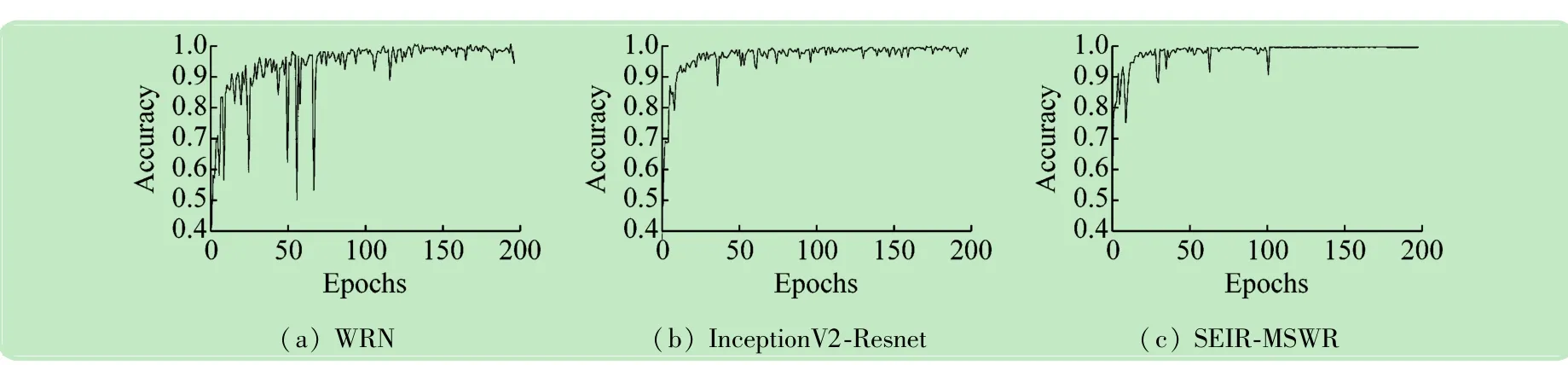
图12 Pavia University在训练过程中损失函数的变化情况

图13 Pavia University高光谱图像分类结果
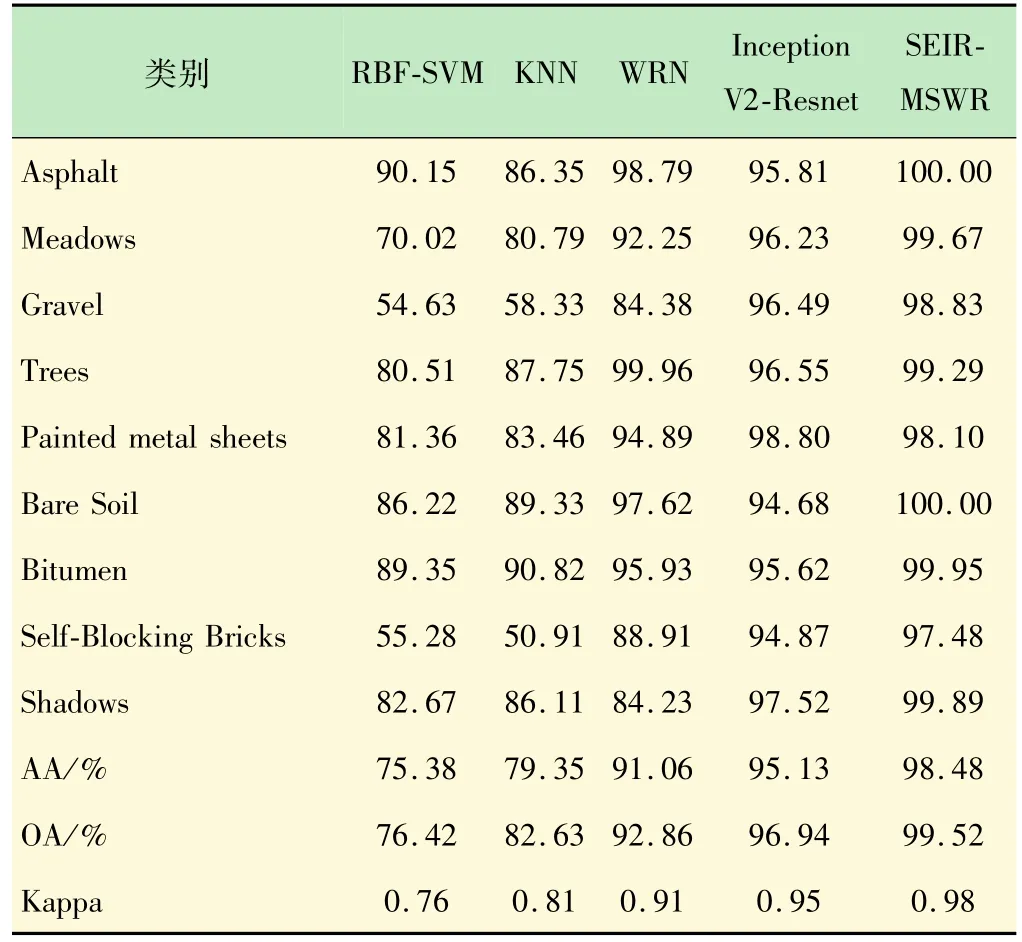
表4 Pavia University数据集上各种分类算法正确率统计%
3 结 语
本文针对高光谱图像特征提取和分类的问题,提出了将SE-Inception-Resnet和MSWideResnet模型融合实现对高光谱图像分类的方法。首先,由于高光谱图像中存在冗余信息,利用PCA算法对原有的高光谱图像进行降维处理得到三维的高光谱图像。其次,将提出的两种深度学习网络结构应用于对高光谱图像的分类,第1种网络结构是将Senet模块分别嵌入到Inception-Resnet-A、 Inception-Resnet-B、 Inception-Resnet-C中,并将网络的多层特征进行融合得到SEInception-Resnet网络结构,第2种网络结构是通过增加宽残差网络中并行的卷积层得到MSWideResnet网络结构。最后,利用结果加权平均模型融合的方式获得高光谱图像的类别。实验结果表明,通过对Indian Pines和Pavia University两个真实高光谱图像数据进行实验,验证了本文方法比传统方法对高光谱图像特征提取和分类有更好的效果。
融合多层特征SENet和多尺度宽残差的高光谱图像地物分类方法更好地提取了高光谱图像的本质特征,提高了高光谱图像的分类精度,但是该方法存在耗时较长的问题,如何提高高光谱图像分类的速度还有待进一步研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
网络安全与数据管理(2022年3期)2022-05-23
空间科学学报(2021年1期)2021-05-22
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
军事运筹与系统工程(2016年4期)2016-07-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
智能系统学报(2015年4期)2015-12-27
中国惯性技术学报(2015年1期)2015-12-19
中国光学(2015年5期)2015-12-09
