
基于注意力机制的DenseNet 模型的树种识别应用
2020-09-14 08:29宋宇鹏边继龙张锡英
实验室研究与探索 2020年7期
宋宇鹏, 边继龙, 安 翔, 张锡英
(东北林业大学信息与计算机工程学院,哈尔滨150040)
0 引 言
图像识别分类是计算机视觉领域内的一项关键技术。近几年硬件设备和理论水平不断发展,图像识别分类技术被人们广泛地应用在医疗疾病检测、工程灾害预警和林业监测评估等各个领域[1-6]。图像识别分类技术能够有效地提取图像中的特征,并根据所提取的特征判断图像所属类别。随着图像识别分类数据规模和特征维度的增加,传统机器学习方法已经不能完全满足需要,因此以神经网络为主流的深度学习方法成为发展的方向。自2012年Hinton团队提出AlexNet[7]模型后,使用深度卷积神经网络进行图像识别分类成为热点,不同的网络模型陆续被提出,如VGG[8]、NIN[9]、Inception[10]、ResNet[11]、DenseNet[12]和NASNet[13]等,在各个网络模型识别分类精度不断提高的同时,模型训练的各个阶段也进行相应地改进,其中包括数据预处理、损失函数设计、网络结构调整和模型优化等方面。网络模型深度的增加使网络参数量变大,更容易导致网络模型出现“网络退化”,难以训练。
由于不同领域背景的数据集各有差异,某些特定领域的分类任务中,例如,林业工程中复杂树种分类问题。仅使用上述的神经网络并不能很好地完成识别分类任务,而简单地增加网络的层数会导致网络参数冗余,甚至出现网络退化现象。
就此,提出在神经网络模型DenseNet中引入注意力机制,更有效地提高网络的整体性能。通过注意力机制去更好地获取数据特征,同时模型不会因为过深而出现网络退化的问题。提出的模型既解决了特定领域内复杂数据集识别分类效果不理想的问题,还提高了网络训练效率。针对林业工程中多类别复杂树种分类任务,以此背景开展实验,使用基于注意力机制的DenseNet模型,取得了较好的结果。为证明模型的通用能力,使用公共数据集SVHN验证模型的鲁棒性。
1 相关知识
1.1 注意力机制
注意力机制同神经网络一样都是受到仿生学启发。人类在进化发展过程中逐渐形成的视觉注意力机制能够快速扫描图像,判断出感兴趣区域并投入更多的注意,能够较好地获取感兴趣区域的详细信息,对于非感兴趣区域则较少关注,从而更准确地帮助人们捕捉信息,提高自身事务处理能力。注意力机制在深度学习中的应用同人类注意力机制相似,其目的是通过使用注意力机制更快速、准确地获取重要信息,忽略无关信息,以提高工作效率。注意力机制最早由计算机图像领域中提出,经发展现已被应用在许多计算机领域的研究方向,如:机器翻译,文本分类,图像分割和图像分类等[14-17]。
注意力机制训练过程将注意力机制分为硬性注意力(Hard Attention)机制和柔性注意力(Soft Attention)机制。硬性注意力是一种非确定性的随机动态过程,在训练过程中不可微分,大多通过增强学习完成。柔性注意力是一种确定性的注意力机制,其最大的特点在于该注意力机制在训练过程中是可微分的,能够通过网络梯度及反馈,实现端到端的自动训练。由于柔性注意力能够实现自动训练,现阶段图像分类任务中较多使用柔性注意力机制。根据注意力域的不同,将柔性注意力机制分为空间域(Spatial Domain)、通道域(Channel Domain)和混合域(Mixed Domain)。基于空间域注意力机制的典型网络就是空间映射网络(Spatial Transform Network,STN),该网络模型2015年由Jaderberg等[18]提出,通过注意力机制提取重要的原始图像空间信息,并将其保存在新的空间信息中。基于通道域注意力机制的典型网络,即2017年提出的SENet[19],该网络通过得到每个通道与重要信息之间的关联度,产生基于通道域的注意力机制。混合域注意力机制的典型网络—残差注意力网络(Residual Attention Network,RAN)[20],该网络模型通过使用“残差方式”去学习其内部每一个特征元素的权重,并形成基于空间和通道双向的注意力机制,能够较好地获取原始图像信息,在一定程度上降低了网络参数冗余度。
1.2 Densenet神经网络
密集神经网络(DenseNet)是2017年由康奈尔大学、清华大学、Facebook FAIR实验室联合提出的一种深层卷积神经网络。DenseNet受到ResNet模型结构中“跳跃连接”的特征传递方式所启发,提出了一种“前层传递”的方式,即网络模块中每层的输入都来自于模块中该层前面所有层的传递。DenseNet神经网络的“前层传递”方式能够有效地将原始特征传递给后续网络,同时还能避免因为网络过深导致的“梯度弥散”问题。
ResNet神经网络通过恒等映射的方式进行特征传递,防止梯度弥散。ResNet特征传递方式:
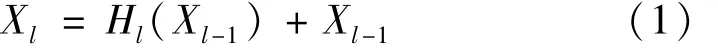
DenseNet的特征则是使用前层之间的传递方式,DenseNet特征传递方式:
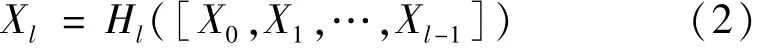
式中:Xl为第l层的输出;Hl(·)为每层的非线性函数;[·]为各层的密集连接。相比于ResNet恒等映射后相加的特征传递方式,DenseNet的网络参数量较少,且更有利于网络中信息的传递,使得DenseNet网络有更好的鲁棒性。

图1 DenseNet模型结构
DenseNet网络主要通过内部密集模块(Dense Block)实现神经网络的密集连接,如图1所示。其中每个Dense Block内部都包含一定数量的神经元,神经元个数根据网络任务不同而有所区别。其中每个神经元主要由批归一化(Batch Normalization,BN)、激活函数(RectifiedLinearUnits,ReLU) 和卷积层(Convolution,Conv)组成,每个神经元都与其之前的神经元连接,对于含有L个神经元的Dense Block,则有L×(L+1)/2个连接。其中Dense Block的增长率表示每层输出的特征图个数。为了实现更好的效果,提高网络计算效率,每个神经元中都会添加一个卷积层作为Dense Block的瓶颈层(Bottleneck Layer)减少特征图数量,形成最终的神经元BN+Relu+Conv(1×1)+ BN +Relu+Conv(3×3)。DenseNet模型在相邻的Dense Block之间添加Translation Layer降低网络整体参数量,Translation Layer由一层卷积层和一层池化层(Pooling Layer)构成。经过实验验证表明,DenseNet不仅能够提升目标分类准确率,还能有效防止梯度弥散。
2 基于注意力机制的DenseNet模型
2.1 基于注意力机制的DenseNet模型
注意力机制能提高网络模型对图像特征的提取能力,帮助网络获取兴趣区域,减少对非重要信息的关注度,提高网络的分类识别效率。与此同时,DenseNet是经典的图像分类模型,其“前层传递”的特征传递方式能将原始特征传递给后层网络,有效减缓“梯度弥散”现象,能较好地完成大多数图像分类识别任务。受到两者特性所启发,提出了基于注意力机制的DenseNet模型,该模型将注意力机制引入DenseNet结构中,将原有的DenseNet进行改进,形成最终的新型网络结构,如图2所示。
基于注意力机制的DenseNet模型(见图2)的核心是提出了模型内部的注意力密集模块(Attention-Dense Block,ADB)。具有ADB的网络有更强的特征提取能力,同时保留了DenseNet对原始特征的“不破坏性”传递的特点,在特定领域背景分类任务的数据集中表现出色。
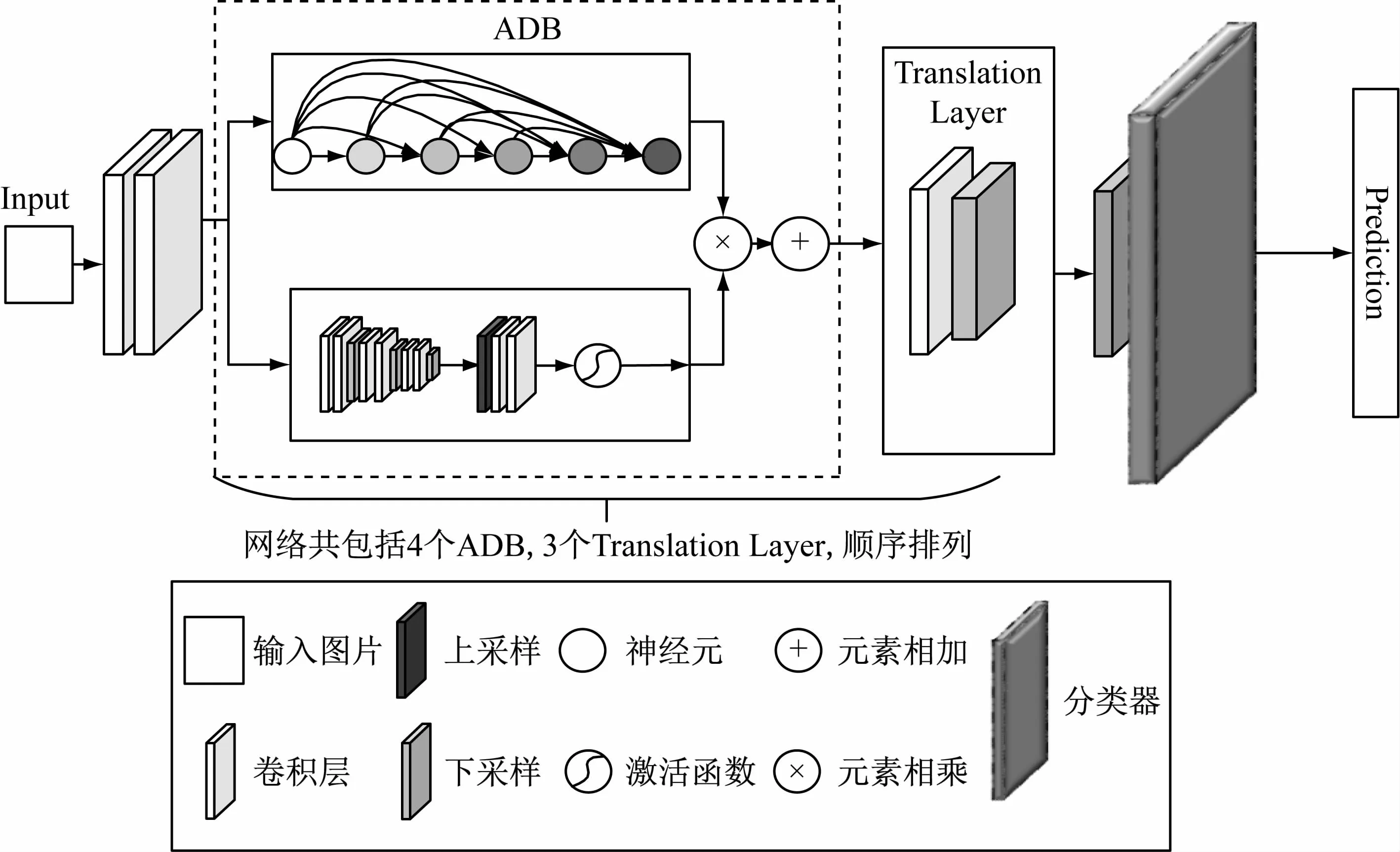
图2 基于注意力机制的DenseNet模型结构图
ADB分为主干分支和标记分支。主干分支以Dense Block为基础进行设计,采用DenseNet神经元前层传递的方式进行特征传递,尽可能地保证了网络有较好的特征信息处理能力。其中每个主干分支设计包含6个神经元,每个神经元都添加了Bottleneck Layer,最终形成单个神经元结构为BN+Relu+Conv(1×1)+BN+Relu+ Conv(3×3)。这种结构使得偏后的网络层也能获得较多的特征信息,能够避免梯度弥散的发生,具有较好的分类性能。同时ADB还设计了标记分支部分。该部分受到残差注意力网络所启发[20]。基于混合域的残差注意力机制,采用空间域和通道域两个方向同时学习,通过输出与主干分支数量一致的标记分支特征图,最后同网络中主干分支相结合,实现网络的注意力机制。ADB中的每一个标记分支不仅仅在前向传播时作为特征选择器对图像特征进行筛选,在网络训练反向传播阶段时,该部分还可以作为梯度更新的过滤器。标记分支通过下采样(down sample)和上采样(up sample)运算实现,ADB的标记分支部分通过3组Conv(3×3)和Max Pooling(3×3)完成标记分支部分下采样运算。其中下采样运算能够帮助网络快速搜索全局特征,获取兴趣区域信息。上采样使用双线性插值完成,该运算能获取特征图中的兴趣区域信息同原始信息相结合,并使用两个连续的Conv(1×1)运算使得标记分支部分的特征图尺寸和主干分支特征图尺寸相同,其后通过激活函数将特征图数据进行归一化,以点乘的方式与主干分支的特征信息相结合,实现了端到端的联合训练。
根据林业工程的复杂树种分类任务,经实验对比最终确定整体网络包含4个ADB、3个Translation Layer和1个Classification Layer。其中每个Translation Layer由Conv(3×3)和Pooling(2×2)组成。ClassificationLayer包括全局平均池化(Global Average Pooling)和全连接层(Fully Connected Layer)。整个网络使用Softmax作为输出层激活函数,将得到的分类结果归一化,并对结果进行概率判定,最终得到类别判断结果。
2.2 注意力机制的残差学习方式
面对背景杂乱、场景复杂、外观变化较大的分类任务时,仅使用一个ADB难以获取图像中的重要信息,且只能对图像重点信息关注一次,标记分支部分一旦出现错误信息,难以修正。基于注意力机制的DenseNet模型使用了多个ADB。简单地添加多个ADB作为网络标记分支的方式并不能起到有效的注意力机制,反而会导致网络模型的性能下降,其主要原因是ADB中经过下采样、上采样和卷积等一系列运算后会通过激活函数进行归一化处理,标记分支部分的特征数据都将变为[0,1]范围之间的数值,之后标记分支的特征数据同主干分支中的特征数据进行点乘运算,在这一过程中会逐渐降低主干分支部分特征数据值,特征数据在传递过程中逐渐衰减,造成训练困难。与此同时,标记分支判断图像原始特征的全局信息获取兴趣区域时,经过归一化后非重要区域数据得到较低的权重,与主干分支数据结合传递时造成对原始特征数据的破坏。针对以上问题,在ADB中使用残差学习方式去降低其对数据的干扰。
注意力机制的残差学习方式是受到ResNet中恒等映射的思想所启发,如图3所示。大多数注意力机制学习得到权重后直接作用在原始图像中,以此提高网络对于重点信息的关注:

式中:Hi,c(x)为第i层c通道经过注意力机制后的输出;x为主干分支和标记分支的输入;T(x)为主干分支的输出;M(x)为标记分支输出。这样的学习方式会逐渐导致特征图信息越来越小,使得网络模型的性能下降。

图3 残差学习方式图
注意力机制的残差学习方式提出使用类似于ResNet恒等映射的方法进行改进:

将标记分支的输出构造为相同的映射,能够有效的防止网络模型在训练过程中出现退化现象。即使标记分支输出M(x)为0时,该部分并不影响主干分支的特征数据,对于标记分支判定为重要信息的特征,经过注意力机制后重要特征会变得更加显著。注意力机制的残差学习方式保证了网络整体性能,还解决了注意力机制对于数据的干扰问题。
3 实验
3.1 实验数据集
本次实验以林业工程复杂树种识别分类为背景,使用Leafsnap网站所提供的树木叶片数据集进行实验。该数据集共包含7 719张通过移动设备所拍摄的户外环境中的树木叶片图像,其中共有184种类别的树木叶片图像,图像的原始尺寸为800×600(像素)。为了提高网络模型的泛化能力,使用更多的数据训练网络,对该数据集进行数据增强操作。数据增强方式主要通过:伽马变换、空间几何变换、低通滤波图像平滑和噪声扰动。经过数据增强操作,共计获得27 863张224×224(像素)的实验数据集,其中26 253张做训练集,1 610张做测试集。经过数据增强后的数据集,在原始数据集基础上经过缩放、旋转、裁剪、平移、加噪和调整亮度等操作,尽可能符合真实环境,提高实验数据的可靠性和真实性。
3.2 实验对比及分析
实验环境为Linux系统,使用Keras框架设计实现。硬件配置如下:内存256 GB,CPU:Intel(R)Xeon(R)CPU E5-2630 V 4。GPU:Tesla V100 (16 GB)×4。实验以林业工程复杂树种识别分类任务为研究背景,对27 863张实验图片,184个类别的树木叶片进行分类识别。使用基于注意力机制的DenseNet模型进行实验,实验过程设置100个迭代周期,模型增长率设置为12,初始学习率设置为0.001,采用阶梯式衰减,当迭代周期达到50和75时,当前学习率分别降低到目前的1/10。为加快模型收敛,反向传递阶段采用批次随机梯度下降法,其中动量参数为0.9,批量大小(batch size)设置为64。实验首先对ADB中标记分支不同的采样方式和采样次数进行实验对比。针对不同的注意力域进行分析对比,得到最优的ADB结构,确定基于注意力机制的DenseNet模型的具体结构。使用基于注意力机制的DenseNet模型同其他网络模型做比较,并根据实验结果进行分析。同时使用公共数据集SVHN对网络模型进行分析验证。
(1)采样方式和采样次数实验对比分析。标记分支部分主要包括下采样和上采样运算,下采样方式和下采样次数都会影响ADB的性能,实验以双线性插值为上采样方式,比较不同下采样次数和不同下采样方式下网络的分类性能,选取最优下采样方式和下采样次数。
由表1可知,实验选取最大池化(Max pooling)、平均池化(Average pooling)和重叠池化(Overlapping pooling)3种池化方式,分别下采样1、2和3次实验对比,发现在标记分支中使用Max pooling池化3次时网络模型性能最优,确定网络ADB的标记分支部分使用3组Max Pooling。

表1 不同采样方式和采样次数模型分类错误率 %
(2)不同注意力域的实验对比分析。标记分支随着主干分支的不同而有所差别。标记分支中的注意力机制能够根据主干分支而进行自适应改变。标记分支的输出依靠其激活函数将数据进行归一化,不同注意力域的注意力机制在网络中表现也有所不同。设计实验对比不同注意力域激活函数的网络模型性能,选择最优注意力域的注意力机制。基于通道域和空间域的Sigmoid的混合域函数为
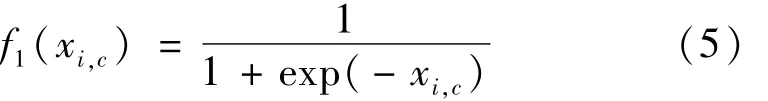
基于通道域的L2归一化去限制空间信息激活的通道域函数为

f3对特征信息做标准化处理,只保留关于空间信息的空间域函数为

式中:i为在空间位置上的取值;c为在通道位置的取值meanc;stdc为第c通道的特征图所对应的特征值和方差。经过实验比较混合域、通道域和空间域的Top-1错误率见表2,分别为8.75%、9.67%和9.25%。基于混合域的激活函数网络模型性能最优。

表2 不同注意力域模型分类错误率
(3)同其他网络模型对比分析。经过实验(1)和实验(2)确定基于注意力机制的DenseNet神经网络模型的具体结构。为了验证模型的性能,使用卷积神经网络ResNet26[5]和DenseNet-40[12]网络进行对比实验,分析3种网络使用相同的数据集在相同迭代次数下模型的精确率(Precision)、召回率(Recall)和综合评价指标F1(F-Measure)。判定网络模型的性能,各模型测试集精确率如图4所示。
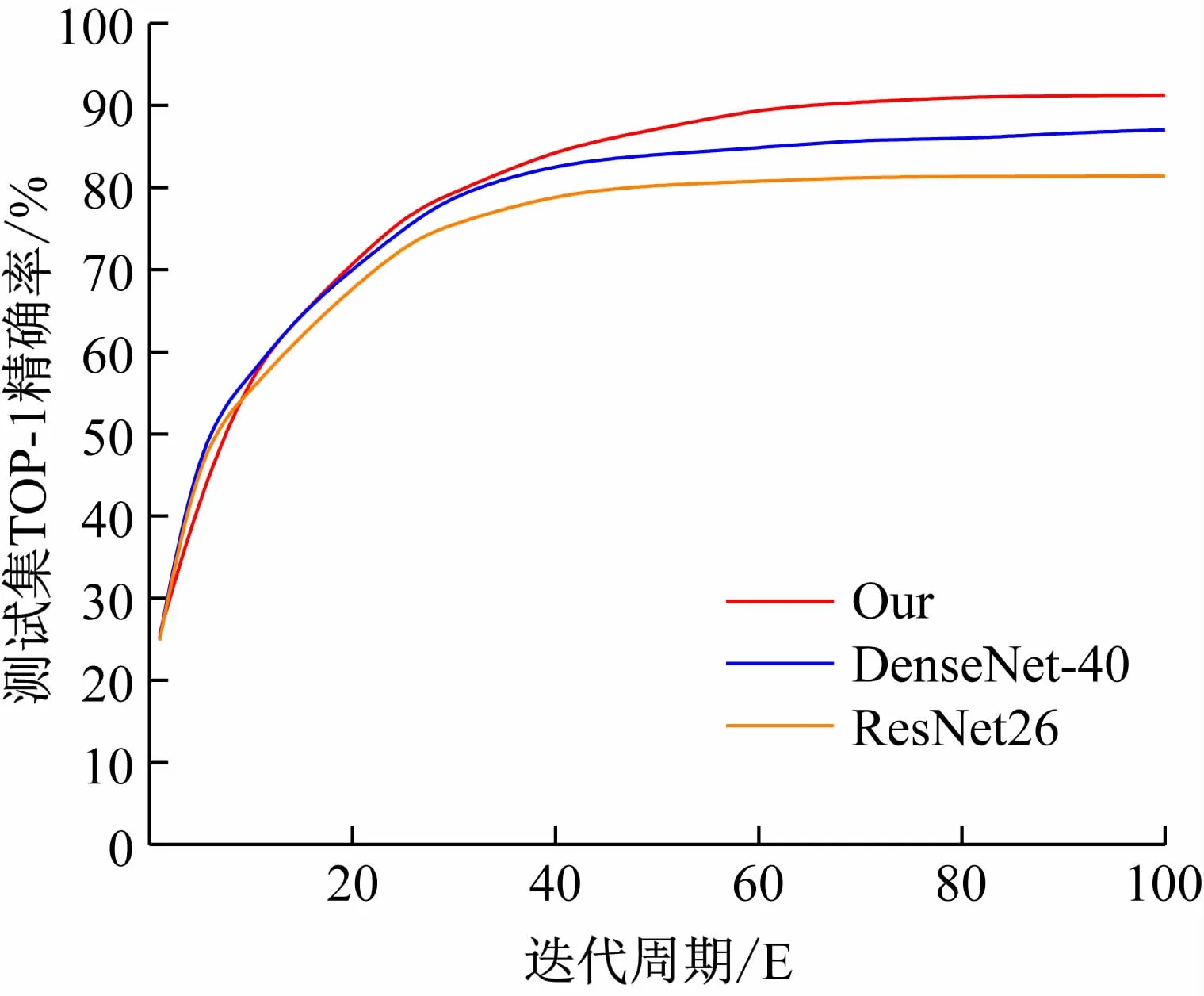
图4 各模型Top-1测试集精确率图
如表3所示,经过实验对比发现,ResNet26、DenseNet-40和基于注意力机制的DenseNet 3种不同的神经网络模型,在相同数据集相同迭代次数下基于注意力机制的DenseNet模型测试集的模型综合评价最优。

表3 各网络模型的测试集结果 %
3.3 网络模型验证
为证明基于注意力机制的DenseNet模型的可行性,设计实验在公共数据集SVHN上验证网络模型。SVHN数据集是一个类似于MNIST的数字识别数据集,包括训练集图片73 257张,测试集图片26 032张,此外还有531 131张图片用于额外训练。SVHN数据集共包括10个类别,其中每个样本对应该类别所属类别标签。SVHN数据集是从Google街景图像中得到的自然场景下门牌号码图像,图像中具有简单的自然场景和数字,与此次实验研究任务相近,因而选择SVHN数据集做模型验证数据集。由于SVHN数据集中图片尺寸都为32×32(像素)大小,根据数据集情况,模型使用3组ADB进行实验分析。实验基于注意力机制的DenseNet模型,使用文章3.2中相同的实验设备和实验参数,迭代100个周期,得到该模型在SVHN数据集上的不同迭代周期的测试集精确度,如图5所示。基于注意力机制的DenseNet模型在SVHN数据集测试集中精确度为98.27%,证明该网络的可行性。
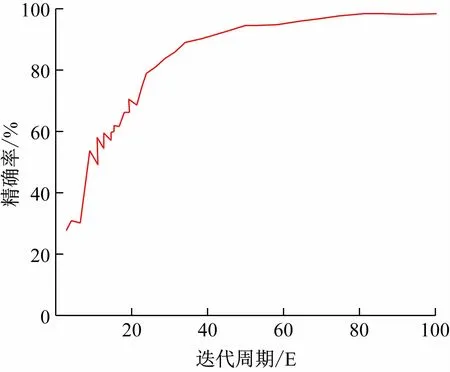
图5 SVHN测试集精确率图
经过实验分析发现,基于注意力机制的DenseNet模型中ADB标记分支部分采用3组Max Pooling时,基于混合注意力域时网络模型性能最优。通过在相同实验环境下对比ResNet26[5]、DenseNet-40[12]和本文的基于注意力机制的DenseNet模型,发现基于注意力机制的DenseNet模型识别分类精确率最高。与此同时,为了验证所提出的神经网络模型,使用SVHN数据集进行测试,证明了基于注意力机制的DenseNet模型的可行性。基于注意力机制的DenseNet模型能够较好地解决网络模型过于复杂造成的参数冗余、训练困难和网络退化问题。在林业工程领域复杂树种识别分类任务上取得了较好的分类效果。
4 结 语
受到注意力机制和DenseNet卷积神经网络的启发,提出了基于注意力机制的DenseNet模型,解决了模型因数据特殊而出现识别效果不佳的问题。实验以林业工程领域复杂树种识别分类为研究背景。基于注意力机制的DenseNet模型结合注意力机制和DenseNet的良好特性,使得网络有较强的特征提取能力,对184种树木叶片分类过程中取得了较好的实验效果,证明了基于注意力机制的DenseNet模型的可行性。与此同时,实验在GPU设备上训练,训练时间较长,今后还需对网络模型及训练方法进行调整,提高网络模型的训练效率。形成实体产品应用在林区工作和林业院校教学中,提高林业工程效率。
·名人名言·
科学的未来只能属于勤奋而谦虚的年轻一代。
——巴甫洛夫
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
黑龙江大学自然科学学报(2022年1期)2022-03-29
数学物理学报(2021年4期)2021-08-30
数学小灵通(1-2年级)(2021年4期)2021-06-09
学生天地(2019年28期)2019-08-25
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
