
多特征非接触式测谎技术
2020-09-11 23:19:42魏江平林家骏
华东理工大学学报(自然科学版) 2020年4期
魏江平, 林家骏, 陈 宁
(华东理工大学信息科学与工程学院,上海 200237)
说谎是人类通过虚假陈述、扭曲事实和遗漏等形式误导别人的一种特殊行为。自动检测说谎是计算机语言学、心理学、军事、情报机构等各学科研究的重要领域。由于人类检测说谎的能力几乎为随机猜测,因此需要科学、可靠的自动化方法检测说谎。自动检测说谎技术通过自动分析人们的行为、语言、以及各种生理指标对人们是否说谎作出判断,其在刑事案件处理、医疗以及司法等职业中起着至关重要的作用,具有广阔的应用场景。
目前的说谎检测方法大致分为两大类:一是基于言语线索的检测方法;二是基于非言语线索的检测方法。基于言语线索的检测方法主要是通过分析语法以及词性等特征来检测真话和假话[1]。文献[2]提出了基于语言探究和字数统计词典的心理语言学特征用于测谎。Newman 等[3]发现说谎者使用更多的负面情绪词。还有人提出不同的语言特征(字数、词性和句子统计特征)[4-5]以及文本句法复杂性等都与说谎存在联系[6]。Pérez-Rosas 等[7]基于语词计量文本分析工具LIWC(Linguistic Word Count)发现说谎者在讲述过程中比讲真话者更加自信。
基于非言语线索的检测方法虽没有基于言语线索检测方法多,但在检测说谎方面也取得了很大成功,主要分为3 类:基于生理、视觉和声音线索。基于生理的检测方法包括使用测谎仪[8]、热成像方法测量面部血流量和面部皮肤温度[9-11]以及使用脑功能磁共振成像 (Functional Magnetic Resonance Imaging,FMRI)测量脑血流量等[12]。这些方法都需要测试者配合且设备昂贵,另外操作人员需具备专业知识。基于声音的检测方法包括利用声压分析器(Voice Stress Analysis,VSA)和分层声音分析技术两种商业产品对人体声带进行操作来测谎[1]。有相关研究表明,音高、持续时间、能量以及说话过程中的停顿[13-16]可表明说谎信息。基于视频的检测方法近年来也越来越受到关注。Depaulo 等[17]发现瞳孔扩张是一种表明说谎的行为。面部微表情如嘴唇突出翘起以及一些标志性手势也被认为是说谎的一类标志[7,18-21]。
多模态测谎也不断受到关注。Pérez-Rosas 等[7]引入了一个新的说谎数据库,包含法庭审判的真实审判场景视频,并且通过提取文本、手势和面部动作等特征,评估了不同模态特征对测谎的重要性。文献[19, 22-24]结合声学、视觉、文本模态提出了不同的多模态模型来检测说谎,其中文献[19]除通过Glove 对文本进行词编码来获取文本的词向量表示以及提取了音频MFCC 等基本特征外,还主要关注了可表明说谎信息的动态运动特征等;文献[23]除提取了音频、视频、文本模态的基本特征外,还采用了人工标注的微表情特征。文献[24]采用CNN 和LSTM 深度学习模型来提取音频和视频特征。这些模型结构相对比较复杂,且在实际场景中不可能采用由人工标注的微表情特征,模型的分类准确率并不理想。文献[25-27]提出心率变化与说谎有关,可较好地反映说话者内心情绪的变化,但心率等生理特征通常都是通过电子仪器设备这种接触式的方法来获得。实际的应用场合往往不允许接触式测谎,因此开发一种易于部署的非接触式测谎系统成为必然。
本文提出了一种基于视频、心率、文本三模态融合的非接触式测谎模型,采用线性支持向量机(Linear Support Vector Machines,L-SVM)作为分类器。该多模态模型未使用人工标注特征,且引入了心率进行非接触式说谎检测,在降低模型复杂度的同时提高测谎的准确率,实验结果表明本文模型相较于其他模型有效地提高了测谎准确率。
1 基本理论
1.1 光电体积描记(PPG)技术
早期的研究工作中,将心率用于测谎时都是通过生理传感器来测量心率,这种接触式方法会让测试者存在防备心理。本文采用非接触式PPG 技术从视频图像的局部区域中提取心率值,其中正常环境光作为光源[25]。其原理是血液比周围组织吸收更多的光,血液体积的变化影响着入射光和反射光。面部血管扩张,入射光路径长度增加,反射光强度也随着变化,即血容量的变化通过反射光亮度值的变化体现出来,反射光强度的变化反映在图像像素值的变化上。
1.2 3D 卷积神经网络(3D-CNN)
与2D-CNN 相比,3D-CNN 更容易检测出视频图像中的微妙表情或者肢体动作。2D-CNN 一般是通过分析视频的每一帧信号进行识别,没有考虑时间维度上的帧间动作信息。而3D-CNN 通过3D 卷积操作,可同时获取空间和时间维度上的特征,捕获

1.3 Word2Vec
由Google 公司提出的Word2Vec 模型在获取词向量工作方面取得了很大的成功,它的主要优势是可使语义相接近的词语或短语之间的距离更小,可较好地度量词与词之间的相似度。Word2Vec 主要包含Skip-Gram 与CBOW 两种模型。Skip-Gram 模型的输入是一个句子中的某个词语,然后预测该词语的上下文。CBOW 模型则相反,输入的是句子中某个词语的上下文,然后根据上下文来预测出目标单词。本文采用基于CBOW 的Word2Vec 模型进行词向量映射。Word2Vec 模型是在Google News 数据集上预训练好的,该数据集包含一百多万个英文的短语和词语。利用Word2Vec 模型的训练结果可得到每个词语的词向量,将文本中每个词语映射到维度一定的向量空间中,保存样本单词之间的语义信息。
2 特征提取
2.1 基于局部面部的心率特征提取
2.1.1 心率提取 心率反映了测谎者内心情绪的变化,对于测谎有很大的帮助。非接触式PPG 技术首先通过读取AVI 格式的视频信号,使用面部自动跟踪器检测视频帧内的人脸并定位到感兴趣的测量区域 (Regions of Interest,ROI)。借助图像处理工具包Opencv 库和具有类似Haar 数字图像特征的级联增强分类器来获取ROI 的坐标以及高度、宽度。对ROI 区域中R、G、B 3 个通道的像素值分别进行空间平均[26]以提高信噪比。计算ROI 区域中R、G、B 3 个通道的像素均值,将每个图像帧的画面信息转变成点信息,得到3 个通道的脉动信号。假设在时刻t,脉动信号中R、G、B 3 个通道的信号幅度分别为s1(t)、s2(t)、s3(t)(感兴趣测量区域像素值的平均值),则脉动信号如式(2)所示。

其中:aj代表每个通道的权重。G 通道具有最强的体积描记信号[26],则G 通道权重值最大。本文仅对G 通道信号取灰度均值,然后进行快速傅里叶变换以获得脉动信号的功率谱密度。功率谱中最高功率对应的频率则代表了脉冲频率,即可得到每一帧视频信号对应的心率值。假设得到的频率值为f,则根据式(3)可得到每一帧视频信号的心率值(频率表示的是1 s 内完成周期性变化的次数,心率是指每分钟心跳的次数)。

文献[27]证明了在整个面部、前额、眼角周围这3 个区域中,前额区域提供了更为丰富的信息,所以本文选择前额区域为ROI。在检测到人脸后定位额头,借助非接触式PPG 技术得到每一帧视频信号的心率值,将每一帧信号的心率值拼接组合成一维向量,此一维向量包含了一个视频样本所有帧的心率值。为防止人脸检测错误影响算法性能,若当前帧没有检测到人脸额头,则将前一帧的额头坐标返回。若检测到多个面部和额头,则选择最接近前一帧的额头坐标返回,且为了能更准确地获取心率值,只有当视频帧长大于10 帧时才开始获取心率值。
2.1.2 心率特征提取 通过PPG 技术获得了每个样本的心率值向量后,为获得心率变化特征,采用全连接网络来获取反映心率变化情况的心率特征。全连接网络包括1 个输入层,4 个隐藏层以及1 个输出层。将获取的心率值向量作为输入,然后经过隐藏层。4 个隐藏层分别具有1 024、1 024、512、300 个神经元,都采用ReLU 作为激活函数,且每一层都采取Dropout 为0.5 的措施以防止过拟合。采用随机梯度下降优化算法训练模型,训练损失函数为最小交叉熵。将训练好的模型的最后一个隐藏层的输出作为心率特征,最终得到的心率特征是长度为300 的一维特征向量。
2.2 基于整个面部的视频特征提取
3D-CNN 模型的输入由一系列图像帧组成,在输入图像帧之间生成多个通道信息,最终的视频特征由所有通道信息组合得到。3D-CNN 网络结构如图1所示。首先,以原始视频图像作为输入,输入的视频维度为(C,N,H,W),其中C表示信道数,实验中输入的是彩色图像帧,有R,G,B 3 个通道,C=3;N表示一次输入的图像帧数,取值30;H和W分别表示输入的每一帧图像的高度和宽度,取值均为96。输入的图像帧首先通过一个硬连线层得到5 种不同的特征,分别是灰度、X方向的光流、Y方向的光流、X方向的梯度、Y方向的梯度,即形成5 个不同的通道。硬连线层使用一个固定Hardwired 核对输入帧进行处理,获得多个通道信息。光流和梯度分别表明物体运动趋势和图像边沿分布,3D-CNN 模型正是通过获取光流和梯度这两种信息来识别视频行为。硬连线层的输出经过一个卷积层对5 个通道的特征分别进行卷积操作,卷积核的大小为(M,C,L,Fh,Fw),产生一个维度为(M,C,N-L+1,H-Fh+1,W-Fw+1)的输出。其中M表示特征映射的数量,L表示执行一次3D 卷积操作的图像帧数,Fh,Fw分别表示卷积核的高度和宽度,实验中采用的卷积核大小为(32,3,5,5,5)。卷积层的输出经过一个窗口大小为3×3×3 的最大池化层,然后经过一个具有300 个神经元且激活函数为Softmax 的全连接层,全连接层的输出即为提取出的视频特征。最终得到的视频特征是长度为300 的一维向量。

图1 3D-CNN 网络结构Fig.1 Network structure of 3D-CNN
2.3 文本语义特征提取
早期的研究工作已经证明了文本含有丰富的语义信息,对于测谎很有帮助,因此可以用来测谎[2-5]。受到文献[23]启发,本文采用图2 所示的模型对文本进行分析,提取其语义特征。首先以文本作为输入,通过Word2Vec 模型对原始文本进行词向量映射,得到文本中每个单词的词向量;然后将这些词向量进行拼接得到每个样本的词向量矩阵;最后使用CNN 模型进一步提取词向量矩阵上下文的语义相关性信息。假设一个样本包含了N个单词,经过Word2Vec模型进行词向量表示后得到词向量矩阵M∈RN×L,L表示词嵌入维度,取值300。mj∈M为文本中第j个单词的向量表示,即矩阵M的第j行。由于CNN 模型的输入要求是固定大小的矩阵,所以实验中以具有最多单词数的样本为基准,单词数不足的样本采取补零措施,使得每个样本得到的词向量矩阵M大小相同。将矩阵M作为CNN 模型的输入,通过卷积层、最大池化层以及全连接层获取语义特征向量。其中卷积层使用了3 种不同尺寸大小的卷积核,分别为3×3、5×5、8×8,卷积核个数都为20。将卷积层的输出经过窗口大小为2×2 的最大池化层;然后通过Flatten 将池化层的输出融合成一维向量。将3 种卷积池化层的输出直接拼接成一维长向量,该向量经过具有300 个神经元且激活函数为ReLU 的全连接网络层。将全连接网络层的输出表示为文本语义特征,即得到的文本语义特征是长度为300 的一维向量。
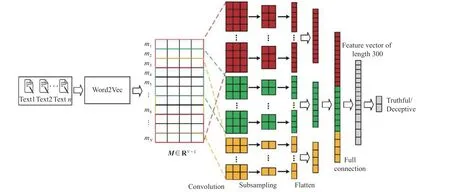
图2 Word2Vec+CNN 网络结构Fig.2 Network structure of Word2Vec+CNN
2.4 模型描述与特征融合
本文采取两种不同的融合方法将各个模态的特征进行融合,得到特征融合向量FC或FH+C,不同模态之间通过信息互补能更好地检测说谎。
心率、视频、文本3 个模态中每一个样本的特征向量都是长度为300 的一维向量,分别表示为Fh、Fv、Ft。受到文献[23]启发,实验采用了两种传统的特征融合方式:一种是直接拼接,通过直接拼接得到的特征向量是长度为900 的一维向量,可表示为Fc=[Fh,Fv,Ft],采用这种融合方式的模型称为LSVMC;另一种融合方式是哈达玛积,该方法可降低特征长度,融合得到的特征向量FH+C如式(4)所示。

通过哈达玛积融合方法最终得到的特征向量是长度为300 的一维向量,采用这种融合方式的模型称为L-SVMH+C。
CNN 作为分类器一般需要较多的训练样本,其优势在于多分类问题。本文采用CNN 模型和L-SVM模型对三模态融合向量FH+C进行实验比较。从表1的实验结果中可以看出,采用L-SVM 可达到更高的精确度。图3 示出了本文提出的多模态模型框架图。

表1 不同分类模型对测试集的客观评价指标对比Table 1 Comparison of objective evaluation indicators of different classification models on test sets
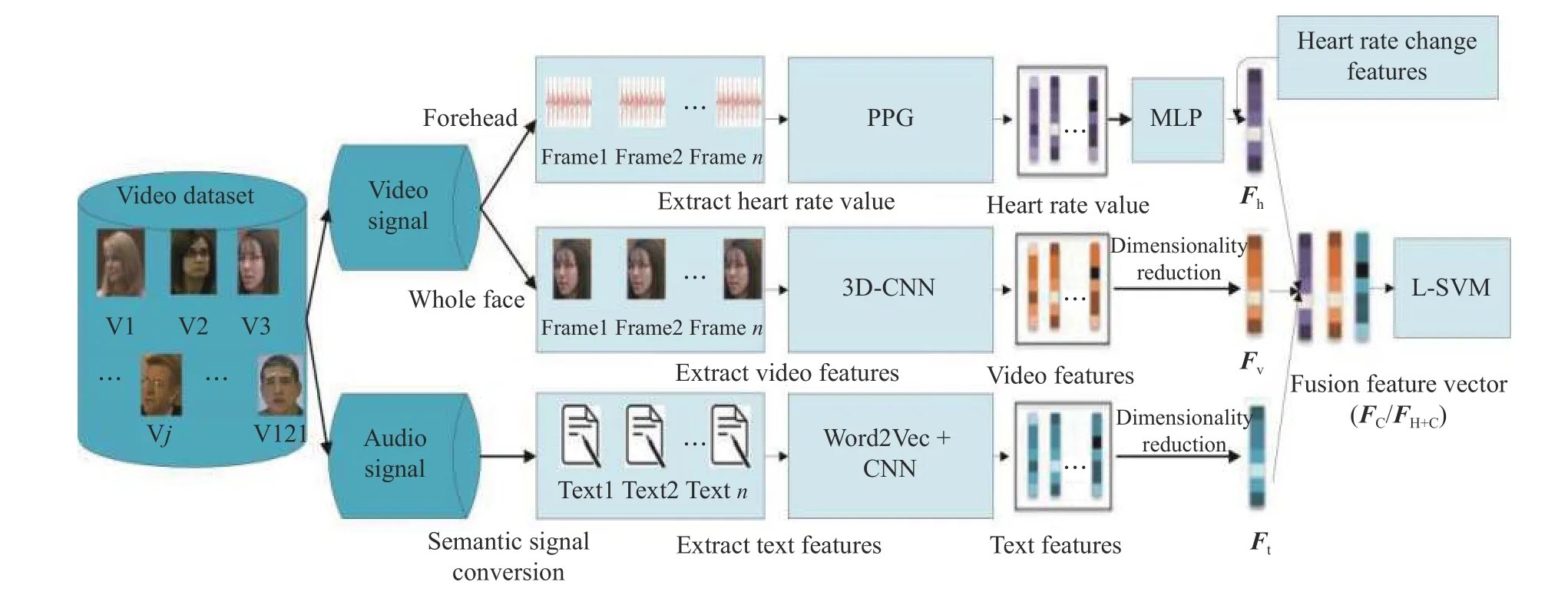
图3 多模态模型框架图Fig.3 Framework of multi-modal model
3 实验结果与分析
3.1 数据集与评价标准
实验采用文献[7]中由真实法庭审判视频组成的Real-life Trial 数据集,该数据集由121 个法庭审判视频剪辑组成,其中包含61 个说谎视频、60 个说真话视频。数据集中视频的平均长度为28.0 s,说谎话和说真话的视频平均长度分别为27.7 s 和28.3 s。将mp4 格式的视频数据转换成WAV 格式的音频数据,即得到音频数据集;文本数据集由音频信号的手工转录得到。实验中对数据集的划分采用以下3 种方式:
(1)留一法交叉验证[7]。假设共有D个样本,每次取出一个样本作为测试集,剩余样本作为训练集,直到每个样本都作过测试集,总共计算D次,然后将D次测试结果求平均值作为最终实验结果。留一法虽然计算复杂,但其不受随机样本划分的影响,样本利用率较高,适合小样本的分类问题。
(2)随机抽取10 个样本作为测试集,剩余样本作为训练集,进行10 次划分,然后取10 次实验结果的平均值作为最终实验结果[24]。
(3)该数据集由不同的测试者组成,为防止同一个测试者对应的样本同时被分到训练集和测试集中,实验中划分训练集和测试集时,采用了对测试者进行10 折交叉验证而不是对样本进行交叉验证,每次将9/10 测试者对应的样本作为训练集,1/10 测试者对应的样本作为测试集,进行10 次实验,然后取10 次实验结果的平均值作为最终实验结果。
采用测试分类准确度以及AUC 值作为客观评价指标。
3.2 实验结果分析
为评估不同模态的特征组合对测谎模型性能的改善,使用各个模态的特征组合进行实验,并将其与其他多模态模型[7,19,23-24]进行比较。文献[7]、文献[19, 23]、文献[24]分别采用3.1 节中的3 种数据集划分方式。表2、表3、表4 给出了3 种数据集划分方式的实验结果对比。表中L-SVMC表示采用直接拼接特征融合方法的模型,L-SVMH+C表示采用哈达玛积特征融合方法的模型。针对第3 种数据集划分方式,本文给出了不同模态特征组合矩阵相乘后的ROC(Receiver Operating Characteristic)图,如图4 所示。相比之下,本文提出的多模态测谎模型的测试准确率与AUC 值相对较高。

表2 留一法的客观评价指标对比Table 2 Comparison of objective evaluation indicators of leaveone-out cross-validation
实验结果表明,在L-SVMH+C模型基础上,本文三模态模型相较于双模态以及文献[7, 19, 23-24]模型的预测精度明显提升,具有更高的测试精确度以及AUC 值。其中文本与心率模态组合的测试精确度为96.89%~97.70%,比文献[23]的静态模型以及文献[7, 19, 24]的模型高6%~22%,同时AUC 值达到了0.968 3;在第3 种数据集划分方式的基础上,文本、视频、心率模态的组合取得了98.88%的测试精确度及0.988 3 的AUC 值。实验结果表明,三模态模型都表现出了更好的性能,比文献[23]的动态模型以及文献[7, 19, 24]模态的测试精度高出了3%~23.3%。从ROC 曲线图中也可以看出,3 个模态的特征组合明显改善了模型性能,心率、文本、视频特征组合ROC 曲线同时包含了心率和文本的特征组合ROC 曲线以及心率和视频特征组合ROC 曲线。实验结果表明本文提出的多模态模型可有效提高测试准确率,可更好地检测说谎。

表3 随机抽取方式的客观评价指标对比Table 3 Comparison of objective evaluation indicators of random extraction method
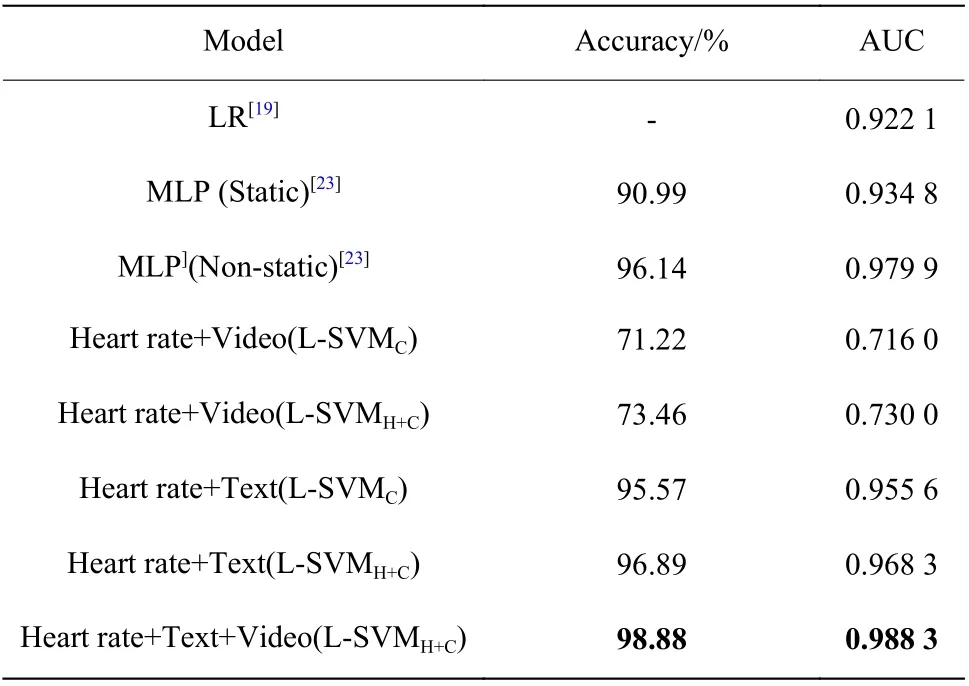
表4 10 折交叉验证方式的客观评价指标对比Table 4 Comparison of objective evaluation indicators of ten-fold cross-validation method

图4 不同模态特征组合的ROC 图Fig.4 ROC diagram of combination of different modal features
4 结束语
本文提出了一种新的多模态非接触式测谎模型,通过整合心率、视频和文本特征来检测说谎。实验结果表明从中提取的心率特征和文本特征可能是检测说谎的显著指标。此外,整合不同的特征来检测说谎可以显著提高检测性能,特别是心率和文本特征的组合取得了很高的精确度。与其他对数据敏感的检测模型一样,该模型也存在局限性。使用更有效的检测特征,收集更大规模的说谎人场景数据库以进一步提高模型的检测精度与泛化能力是未来的研究方向。
猜你喜欢
保健医苑(2022年4期)2022-05-05 06:11:10
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
求学·理科版(2020年4期)2020-05-13 14:03:12
新世纪智能(数学备考)(2020年12期)2020-03-29 02:15:42
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
广东教育·高中(2017年11期)2017-12-04 17:09:16
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
计算物理(2014年2期)2014-03-11 17:01:39
