
适用于一票制公交大数据的系统化处理方法及应用
——以银川市为例
2020-09-07 09:54:58赵海宾吴洪洋刘海旭王子甲
交通运输研究 2020年4期
赵海宾,郭 忠,吴洪洋,刘海旭,王子甲
(1.交通运输部科学研究院城市交通与轨道交通研究中心,北京 100029;2.北京城建设计发展集团股份有限公司交通研究中心,北京 100032;3.北京交通大学土木建筑工程学院道路与铁道工程系,北京 100044)
0 引言
公交乘客出行特征分析不仅是评价公交运行现状的内容之一,也是公交线网优化的前提和基础。通过传统的公交调查方式获取公交乘客出行特征需要耗费大量人力物力。随着公交智能化系统的不断完善,公交大数据的应用为分析乘客出行特征提供了新的思路。
相比于传统的公交调查方式,公交大数据获取成本更低,包含的信息也更为丰富[1-2]。近年来,基于公交大数据分析乘客出行特征的研究越来越多,如陈绍辉等[3]利用禁忌搜索算法及数据匹配模型将公交IC 卡数据与GPS 数据等相匹配,发现该方法可以较高的准确率得到交易记录和上车站点ID 之间的关系;陈君等[4]利用公交数据和数据仓库技术建立了智能公交数据分析平台,将智能调度与公交IC卡系统进行关联,结果表明该方法在判断公交乘客上车站点的准确率方面表现突出。
上述研究主要针对乘客上车站点的推断。由于常规公交一般采用一票制,从而缺乏可用的下车位置信息,所以相比于乘客上车站点推断,识别乘客下车站点更具挑战性[5]。目前主要存在两种估算乘客下车站点的方法:集计法和非集计法。集计法一般假设乘客根据出行距离和车站吸引力的特定概率分布下车[6],如徐文远等[7]利用公交IC 卡数据和GPS 信息,结合站点吸引权概念进行了居民出行上下车站点推断,但是在推断下车站点时精度较差。为了获得更可靠的推断结果,大量研究采用基于乘客出行链的估算方法[8-10],如Wang 等[9]基于出行链,从伦敦的智能卡交易数据中获取了OD 信息,并用实际出行调查数据验证了方法的有效性,但缺陷在于部分公交线路的调研率较低;Barry[10]根据纽约自动售检票系统采集的数据推断下车站点,且基于以下假设来定义个人出行链:(1)很大一部分乘客从前一次出行的下车站开始下一次出行;(2)乘客将在其结束前一天出行的车站开始其当天第一次出行。
以上研究都为基于一票制公交大数据分析公交乘客出行特征奠定了基础,但少有研究提出从公交数据采集与处理到站点推断算法构建、再到最终数据分析全流程的系统方法。本文则在总结前人工作的基础上,提出适用于一票制公交大数据的系统化处理方法,以期为基于公交大数据的公交乘客出行特征分析提供新的思路。
1 公交数据采集与处理
本文所用大数据包括公交IC 卡数据、公交GPS 数据、车载机数据及单程站点信息表4 类。不同类型数据的采集与处理方法不同。
1.1 公交IC卡数据采集与处理
公交刷卡收费系统主要包括车载收费终端和后台管理系统两部分,当乘客在车载收费终端刷卡上车时,数据会传回后台管理系统,完成对公交IC卡数据的记录。
公交IC 卡数据处理主要是删除逻辑上明显不合理的记录,处理过程如下:
(1)由于刷卡记录中包含众多字段信息,其中大量字段信息对本研究而言为无效字段。本研究主要提取与乘客出行时空信息相关的字段,包括交易卡编号、交易时间、线路编号和车牌号等4种,因此删除其他多余字段。
(2)由于公交刷卡收费系统故障等原因,通过步骤(1)提取的字段尚有一定数量的错误数据或某些字段内容为空,这些数据在后续研究中属无效数据,予以删除。
经过上述处理,公交IC 卡数据的有效字段及其说明如表1所示。

表1 公交IC卡数据有效字段及其说明
1.2 公交GPS数据采集与处理
公交GPS 数据主要包括两种类型的位置数据。第一种是公交车进出公交站点时,GPS 系统记录的公交车进出站状态及相应坐标,一般会在站点前后5m 内分别产生到站和离站数据。另一种是固定时间间隔(通常为1min左右)的车辆位置上传,这一类数据用以计算公交车的行驶速度等。
以银川市为例,公交GPS 数据处理过程如下:
(1)银川公交GPS数据共有59个字段,但部分字段目前尚未启用。提取对本研究有效的字段,包括车载机编号、到离站信息、定位时间、定位经度、定位纬度、线路编号、子线编号、站点顺序号等,删除无效字段。
(2)由于公交GPS 系统故障等原因,GPS 数据存在部分定位在银川市范围外的错误数据,本文基于ArcGIS将其删除。
(3)通过步骤(1)和(2)提取到的数据尚存在一定数量其他类型的错误数据,主要表现为字段信息不全,即只有到站或离站数据,对这一类数据也予以删除。
经过上述处理,银川公交GPS 数据的有效字段及其说明如表2所示。
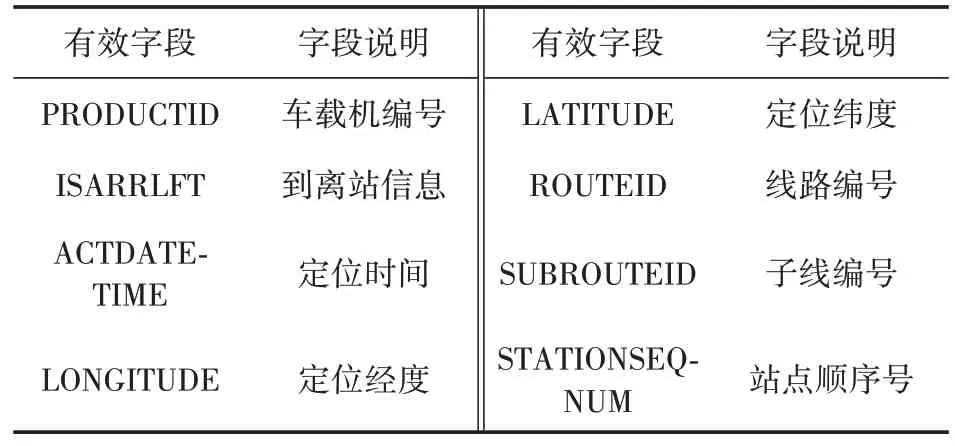
表2 公交GPS数据有效字段及其说明
1.3 车载机数据信息采集
车载机数据信息可从公交企业的车辆数据库中获取,为车载机编号与公交车车牌号及线路编号之间的对应关系,用于匹配GPS 数据对应的车牌号以及GPS 数据和IC 卡数据的关联融合,其数据样本如表3所示。

表3 车载机数据信息表
1.4 单程站点关系表采集
单程站点关系表可从公交企业的线路数据库中获取,为线路编号和子线编号对应的站点顺序号、站点名称及站点类型编号。鉴于GPS 数据只有站点顺序号,并没有定位站点名称,所以使用单程站点关系表将站点名称匹配到GPS 数据中,其数据样本如表4 所示。通过筛选线路编号和子线编号,站点顺序号和站点名称为一一对应关系。
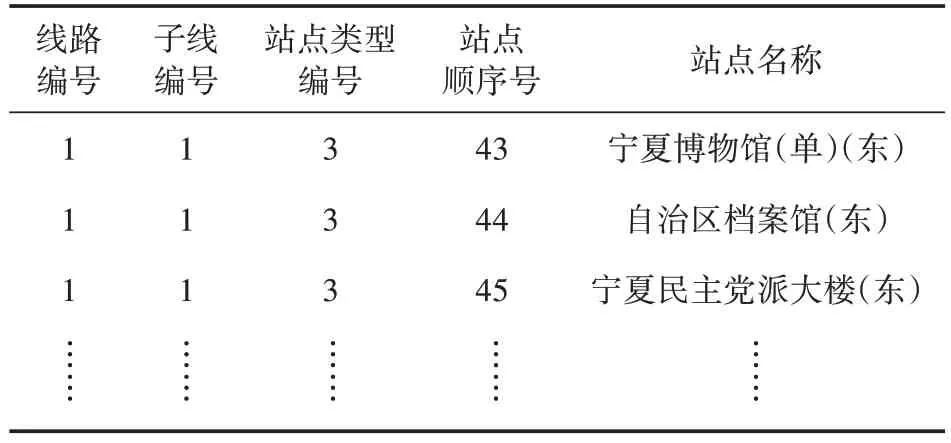
表4 单程站点关系表
单程站点关系表中,许多站点分东西南北4个方向,同一个站点在GIS 地图中往往存在多个相邻的经纬度。为方便后续研究,结合GIS 数据中的站点信息,将同一个站点、不同方向、不同线路的经纬度取平均值进行融合,获得站点的唯一经纬度,如图1所示。
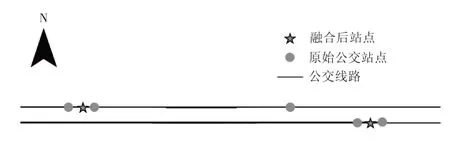
图1 公交站点经纬度融合前后示意图
将公交GPS 数据、车载机数据信息、融合后的单程站点关系表进行关联融合,获取包含站点名称、站点经纬度等的到离站GPS 数据,其数据样本如表5所示。

表5 匹配经纬度后的单程站点关系表
2 站点推断算法构建
一票制公交刷卡数据中缺少乘客的上下车站点及换乘站点信息,为了将这些信息补全,本文基于既有文献,分别构建乘客上车站点推断算法、乘客下车站点推断算法、乘客换乘站点识别算法,共同组成系统化处理方法的关键环节。
2.1 乘客上车站点推断算法
将公交GPS 数据与公交IC 卡数据进行关联融合,通过比对站点GPS 数据更新时间和乘客刷卡时间,以确定乘客的上车站点[11-12],其推断算法伪代码如下。

其中,Selectdata(data,condition)函数表示从data中提取满足condition条件的数据;ComputeIn⁃terval(A,B)函数表示计算时间点A和时间点B之间的时间间隔。
由于GPS 定位时间和刷卡时间的误差,算法中将GPS 定位时间和刷卡时间差大于180s 的数据剔除,以保证匹配结果的准确性。
2.2 乘客下车站点推断算法
不同乘客1d内乘坐公交出行的次数不同,部分乘客会在1d 内公交出行多次,而大量乘客1d只进行1 次公交出行。针对这两种不同的情况,本文结合既有文献,利用下述两种方法完成乘客下车站点的推断。
2.2.1 基于出行链的乘客下车站点推断算法
针对1d内公交出行多次的乘客,其全天数据中包括多条刷卡记录,能形成闭合公交出行链或非闭合公交出行链。本文利用乘客出行链推断乘客下车站点[13-14],过程如下:
(1)提取乘客刷卡记录中卡号相同的1d内的全部刷卡记录,并按刷卡时间排序;
(2)针对1 名乘客1d 内的全部刷卡记录,首先根据其第1 条刷卡记录的上车站点,获取该名乘客本次上车线路的所有站点;
(3)根据该名乘客下1 条刷卡记录的上车站点,搜索计算与上1 次乘坐线路所有站点空间距离最近的站点,则该站点为乘客上1 次乘车时的下车站点;
(4)当刷卡信息为该名乘客的最后1 条刷卡记录时,则利用该名乘客第1 条刷卡记录作为推断计算时的下1 条刷卡记录,从而推断其最后1次乘车时的下车站点,至此该乘客的下车站点推断结束;
(5)针对所有乘客的刷卡记录,重复运行步骤(1)~步骤(4),直到完成所有乘客下车站点推断。
2.2.2 基于概率的乘客下车站点推断算法
针对1d中无连续公交出行的乘客,本文利用基于站点下车概率的乘客下车站点估计模型来推断乘客下车站点。既有研究表明,公交站点吸引强度与发生强度基本平衡,因此可用公交站点的发生强度等价替换其吸引强度[15]。根据乘客上车站点推断结果,可统计得到任一条线路各个站点的上车人数,并由此计算公交站点的吸引强度为:
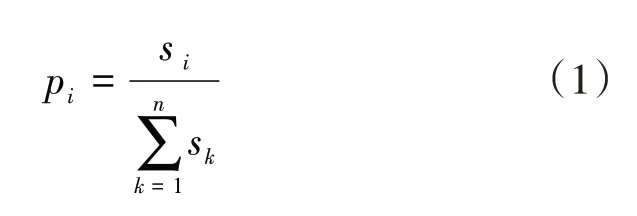
式(1)中:pi为第i站的吸引强度;s i为第i站的上车人数;为一条线路所有站点的上车人数之和,其中sk为第k站的上车人数;n为单线公交站点总数。
乘客在第i站上车第j站下车的概率pij与公交出行的平均乘站数λ、站点i的吸引强度pi有关。而居民公交出行的乘站数主要集中在一定的范围内,在固定的行驶方向上,居民公交出行的乘站数近似符合泊松分布:

式(2)中:Zij为乘客第i站上车第j站下车的概率;λ为公交出行的平均乘站数。当i站以后的站点数目小于λ时,λ=n-λ。
由此可以构造出乘客从站点i上车到站点j下车的概率为:
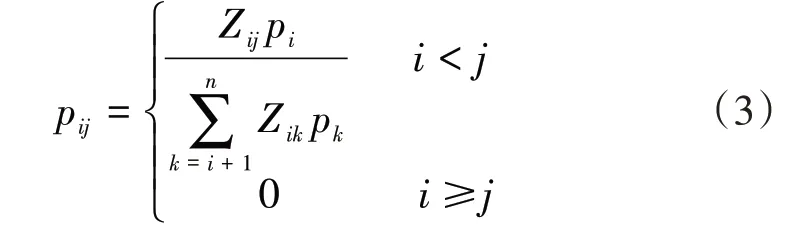
式(3)中:pij为乘客第i站上车第j站下车的概率;Zik为乘客第i站上车第k站下车的概率;pk为第k站的吸引强度。
至此,可得任意i站上车j站下车的乘客总数为:

式(4)中:Mij为第i站上车第j站下车的乘客总数;pij为乘客第i站上车第j站下车的概率。
2.3 乘客换乘站点识别算法
乘客换乘站点识别可从时间与空间角度进行考虑[16]。如图2 所示,公交乘客在P1站点t1时刻刷卡上车,公交车经过T1时间至t2时刻到达P2站点,步行距离L,耗时T2到达换乘站点P3,等待T3时间至t3时刻刷卡上车,乘坐换乘的线路,运行时间T4至t4时刻到达终点站P4,完成本次出行,则换乘过程时耗可用Ts表示为:

式(5)中:Ts为乘客换乘过程的时耗(min);Twalk为乘客从前一次下车站点至换乘站点的步行时间(min);Twait为乘客在换乘站点的等待时间(min);Tv为乘客前一次的在车时间。
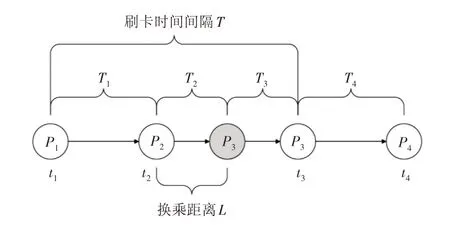
图2 乘客异站换乘过程示意图
分析换乘步行时间Twalk、换乘站点等待时间Twait、前一次在车时间Tv的最大值,便可得到换乘最大时间间隔。本文结合既有文献和交通调查,取最大可能换乘时间的阈值Tmax为60min。
于是,换乘识别过程如下:
(1)提取一条公交IC 卡刷卡记录,记录刷卡时刻为t1,获取其相邻的后一次刷卡记录,记录刷卡时刻为t2;
(2)计算刷卡时间间隔Ti=t2-t1,若Ti≤Tmax且换乘站点之间距离L<500m,则认为乘客后一次出行是换乘行为,否则认为是一次出行;
(3)对同一卡号的所有刷卡记录进行判断,并记录识别的结果;
(4)重复步骤(1)~步骤(3),直到完成所有乘客的换乘行为识别。
3 案例应用
根据上述系统化处理方法,本文利用银川市工作日1d 公交IC 卡数据和GPS 数据等分析了银川公交的运行状况,主要分为3 部分:(1)基于乘客上车站点推断算法和乘客下车站点推断算法,分析所有乘客上车站点和下车站点,得到公交站点上下客流量分布情况;(2)将所有乘客出行起讫点依次“叠加”在公交线路上,得到公交线路客流量分布情况;(3)基于乘客换乘站点识别算法分析所有乘客换乘行为,得到公交站点的换乘客流量分布情况。
3.1 站点客流量分布
图3为公交站点的全天上下客流量分布情况,图例中括号内给出了相应全天上下客流量级别的站点数量。从空间分布来看,全天上下客流量较大的站点均集中于城市东部,而分别有超过1/3的站点上客量或下客量不足300 人次。这反映出站点客流量分布并不均衡,公交引导城市发展的能力还需进一步提高。图4 给出了全天上下客流量排名前15位的公交站点,这些站点是重要的客流集散地,在制定公交线网布设方案时应重点考虑。

图3 公交站点全天客流量分布图

图4 全天上下客流量排名前15位的公交站点
3.2 线路客流量分布
图5所示为公交线路的全天客流量分布情况。从空间分布来看,客流量较集中的公交线路主要用于整个城市的横向联系和东部地区的竖向联系,并且集中在某几条公交线路的某些路段上。图6 给出了全天客流量超过1 万人次的公交线路,共有15条。在公交规划中,需考虑在这些路段设置公交专用车道来提升服务能力,并适当优化其他线路来缓解客流量较集中线路的压力。
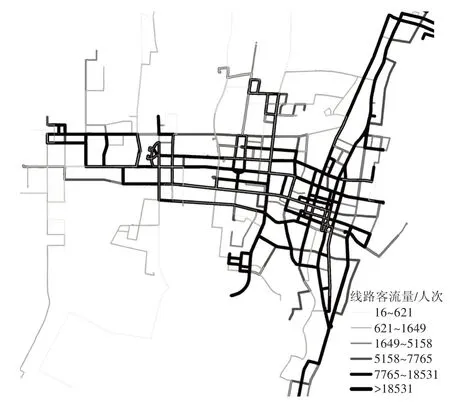
图5 公交线路全天客流量分布图
3.3 站点换乘客流量分布
图7为公交站点的全天换乘客流量分布情况,图例中括号内给出了相应全天换乘客流量级别的站点数量。从空间分布来看,全天换乘客流量较大的站点集中分布于城市的东部核心区。图8 给出了全天换乘客流量排名前15位的公交站点。在公交规划中,一方面需重点考虑这些站点的换乘设施布置,另一方面需进一步优化途经线路走向,以减少换乘、提升直达性。

图6 全天客流量超过1万人次的公交线路
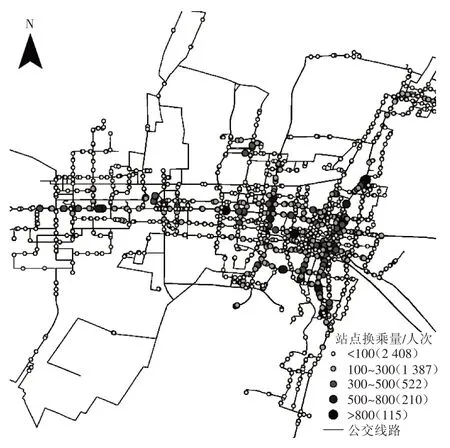
图7 公交站点全天换乘客流量分布图
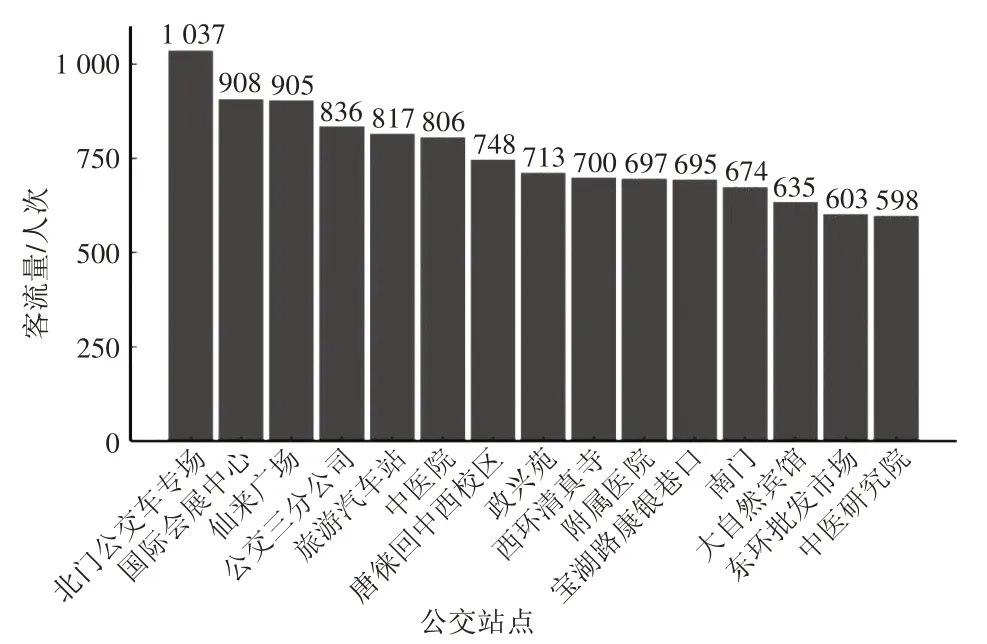
图8 全天换乘客流量排名前15位的公交站点
4 结语
随着交通大数据技术的不断发展,利用交通大数据挖掘结果指导运营及规划是未来交通管理的重要方向之一。本文在参考既有文献的基础上,提出了适用于一票制公交大数据的从处理到挖掘的全流程算法,并将其应用到银川市公交大数据分析中,探析了工作日1d 的公交运行状况,包括站点客流量分布情况、线路客流量分布情况和站点换乘客流量分布情况等,可为后续线网和站点优化提供理论支撑。
该方法尚存如下改进空间:(1)公交IC 卡数据和公交GPS 数据在实际运营中存在明显误差,导致数据处理过程中损失了大量数据;要解决这一问题,一方面需提升相关设备的精度及可靠性,另一方面可集中对错误数据进行分析,以探寻原始数据校正算法;(2)针对单次出行乘客,仅利用站点上客量计算站点下客概率的依据略显不足,今后可考虑结合站点周边建成环境信息,如土地使用情况、周边职住分布情况等,优化站点吸引度算法,提升下车站点的推算精度。
猜你喜欢
世界家苑(2020年5期)2020-06-15 11:13:34
哈尔滨师范大学自然科学学报(2020年6期)2020-05-13 07:59:08
精密制造与自动化(2018年1期)2018-04-12 07:42:49
小学生·新读写(2016年5期)2016-05-14 13:48:40
中国铁道科学(2015年1期)2015-06-26 08:33:56
作文大王·笑话大王(2015年7期)2015-05-30 10:48:04
黄冈职业技术学院学报(2015年5期)2015-03-27 21:34:14
奥秘(2014年8期)2014-08-30 06:32:04
交通运输研究(2014年24期)2014-04-16 01:38:45
城市道桥与防洪(2014年6期)2014-02-27 07:26:48
