
PSP:一种高效的偏序域上skyline 查询处理方法
2020-09-06 13:34白梅王京徽王习特朱斌李冠宇
湖南大学学报(自然科学版) 2020年8期
白梅,王京徽,王习特,朱斌,李冠宇
(大连海事大学信息科学技术学院,辽宁大连 116000)
近年来,随着互联网技术的发展以及信息获取设备的进步,数据库收集处理的数据量增多,进一步,数据库中存储的数据量也急剧增加.但是,人们却很难从这些海量、庞杂的信息中挖掘出自己最想要的有价值的信息.因此,如何快速高效地从海量数据中返回给用户最为关心的数据,成为学术界的研究热点.
skyline 查询根据用户在各个维度的偏好,利用“支配”的概念,将数值间的大小比例作为“好坏”的评价标准,直观而准确地返回给用户最为关心的结果集.具体地,给定两个点p1和p2,p1支配p2指的是在所有维度上p1都不比p2差,并且至少在一个维度上p1要严格好于p2.如图1 所示,共有20 条图书信息记录{p1,p2,…,p20},每一条图书信息包括了两个维度信息:图书价格和评分,评分维度利用倒数映射到[0,1]区间内,使两个维度均以小值为“优”.例如图1中p8在每一维都比p15小,说明p8价格和评分都比p15要好,即p8支配p15.经过skyline 查询后,图中最终skyline 集合为{p8,p12,p16,p17},其他图书记录都可以被这个集合中的点支配.
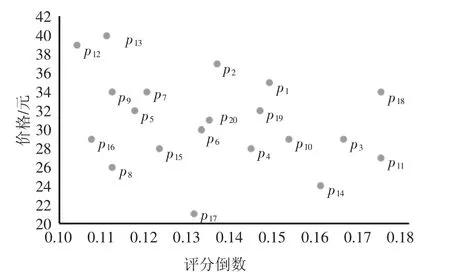
图1 skyline 集合举例Fig.1 The example of skyline
偏序域上的skyline 第一次被考虑到是在2005年,Chan 等[1]讨论了具有偏序域属性的数据集上的skyline 查询,他们将一个偏序域映射到两个全序域上,来适应自己提出的skyline 算法,并针对这种映射提出了SDC+和BBS+算法.但这种方法映射时成本太高,且不具有可扩展性.Sacharidis 等[2]在2009年提出了一种基于拓扑排序的skyline 查询方法可以用来处理动态skyline 查询.Liu 等[3]提出了ZINC(Z-order Indexing with Nested Codes)算法,通过降维等方法来处理偏序维度,但当偏好关系复杂时,偏序维度降维成本将会很高.文献[4] 提出了一种PSLP(Parallel Skylines with Logical Partitioning)框架,通过过滤不含skyline 点的逻辑分区提高计算效率,但分区成本较高且过滤效率提高效果不明显.
综上所述,为了避免查询成本过高,本文将在映射的基础上引入倒排索引,提前对数据集进行过滤剪枝,通过减少对整个数据集的扫描来达到提高计算效率的目的.
偏序域上的skyline 查询处理,在现实生活中是一个非常有意义的议题.例如,在为用户进行图书推荐时,用户往往希望得到评分高且价格低的图书推荐,并且不同用户对不同种类图书的偏好不同,如图2 所示,需要将全序域与偏序域结合起来进行skyline 查询,高效地针对不同用户进行个性化推荐.因此,在偏序域上进行高效skyline 查询具有极大的实际应用价值.
为了更有效地减少开销,提高轮廓查询效率,本文将倒排索引应用到查询中,首先提出了一种高效的偏序域上skyline 查询处理方法(Basic Partiallyordered Skyline Processing based on inverted index,PSP_B).之后,在此算法的基础上,通过提前对数据点进行分组,提出了改进的优化算法(Improved Partially-ordered Skyline Processing based on inverted index,PSP_I),利用优化算法在极大程度上对冗余点进行过滤.实验证明,该算法能更高效地处理偏序域上的轮廓查询.

图2 偏序域上的skyline 查询举例Fig.2 The example of skyline for partially ordered domains
总的来说,本文的主要贡献如下:
1)提出将倒排索引引入skyline 查询领域,倒排索引将每个偏好维度上的属性按从优至劣进行排序,减少大量的冗余计算,从而提高计算效率.
2)提出了PSP_B 算法,解决了传统算法中每次计算都对整个数据集进行扫描的问题.算法对数据集在每个维度上建立倒排索引,通过循环扫描策略快速找到扫描结束点来结束算法,达到了对数据集过滤剪枝的目的,提高了计算效率.
3)在PSP_B 算法的基础上,提出了PSP_I 算法,在将偏序域映射到全序域之后,建立倒排索引之前,对整个数据集按文中提出的分组策略进行分组,在组内建立倒排索引.并提出整组过滤策略,对不含skyline 结果点的分组进行整组过滤,在基础算法的基础上进一步提高了剪枝效率.
4)设计了详细的性能比较实验,通过实验证明了本文提出的PSP_B 和PSP_I 算法可以有效地处理偏序域上的skyline 查询问题,并且PSP_I 算法在查询效率上要更优于PSP_B 算法.
1 相关工作
1.1 传统skyline 查询
早期,人们主要关注于全序域上的skyline 查询.Borzsonyi 等[5]第一次将skyline 查询的概念引入数据库领域,并提出了BNL(Block Nested Loops)和D&C(Divide and Conquer)算法,BNL 算法对待测元组建立临时表,通过将每个待测元组与表内元组比较来进行轮廓查询,因此BNL 算法性能受主内存大小的限制;D&C 算法是将数据集划分为多个分区,在每个分区内进行查询,计算出局部的skyline 点,再将得到的结果进行合并,然后对合并的结果再进行查询来得到最终结果.这两种算法都会产生多次迭代,查询效率较低.
之后,Chomicki 等[6]提出了SFS 算法,该算法是在BNL 的基础上对数据按单调函数进行预排序,然后再进行skyline 查询,减少了开销.Tan 等[7]提出的Bitmap 算法先将每个元组映射成一个m 位矢量,然后通过矢量间的计算得到最后的skyline 集合.之后,NN(Neural Network)算法[8]利用R 树索引数据集,并利用K 近邻算法来进行skyline 查询,通过不断循环删除skyline 点支配的区域来找到结果,因此在对高维数据进行查询时会有大量的重复查询,导致效率低.
2005 年Chan 等提出BBS 算法[1],基于最近邻搜索策略,用R-Tree 对待测数据集建立索引,将所有待测元组划在一个个最小边界矩形上.通过对最小边界矩形左下角元组的比较来过滤冗余元组,又进一步节省了开销.
此外,还有许多针对特定数据环境下的skyline查询算法,如P2P 网络[9]、分布式环境[10]和不确定数据环境[11]等.
1.2 偏序域上的skyline 查询
在实际应用中,有许多维度是无法直接通过数值间的大小比例来判断好坏的,因此,偏序域上的skyline 查询在现实生活中是一个非常有意义的议题.Chan 等在2005 年第一次讨论了具有偏序域属性的数据集上的轮廓查询[1],由于引入偏序域后,传统的轮廓查询算法将不能再有效地修剪空间,因此,他们提出将每个偏序域映射到两个全序域上来解决这一问题,并且提出了BBS+、SDC 和SDC+三种算法.BBS+是进行投影空间转换后直接适应BBS;SDC 和SDC+都利用支配关系将数据进行分层,虽然减少了不必要的比较,但分层时的开销却很大.
2009 年,Sacharidis 等[2]提出了一种基于拓扑排序的skyline 查询方法TSS(Topologically Sorted Skylines for Partially Ordered Domains),利用拓扑排序将偏序域映射成全序域上的间隔,并且,TSS 算法可以用来处理动态skyline 查询.2010 年,Liu 等[3]提出了ZINC 算法,通过降维来简化用户偏好情况,并使用嵌套码将其转化为部分阶映射到总阶数.最后用ZB树来索引编码值,然而,当用户偏好复杂时,偏序降维成本将会很高.
Hsueh等在2017年提出e-DFS(extended Depth-First Search)算法[12],通过缓存之前的查询结果,将这些结果作为索引,对相似查询直接在缓存区中进行查询,该算法在相似性比较上开销大,且针对性不强,在缓存区没有相似查询时仍要访问整个数据集.
综上所述,虽然在全序域上的skyline 查询已经取得了丰硕的成果,但在处理偏序域上的数据时仍缺少一种有效率的方法.因此,本文将针对偏序域上的数据集,将偏序与全序结合起来,引入倒排索引的概念,在进行skyline 计算之前对数据集进行过滤剪枝,将明显提高计算效率,有较高的实用价值.
2 问题描述
本文关注的是偏序域上的skyline 查询问题,以小值为优举例,遇到大值为优的维度需要经过预处理变成倒数后再进行计算.为了描述方便,表1 给出了本文的符号定义.
传统的支配关系和skyline 的相关概念分别如定义1 和定义2 所示.
定义1 (支配[5])给定d 维数据集P,其中两个元组p1和p2,p1支配p2(记作p1<p2)满足下列条件:(i,j 指不同的属性维度)
1)∀i∈{1,2,…,d},p1[i]<p2[i];
2)∃j∈{1,2,…,d},p1[j]<p2[j].
定义2 (skyline[5])给定数据集P,其skyline 是所有不被其他点支配的点的集合,即SKY(P)={pj|
偏序域由多个二元关系组成,表明对于集合中的某些元素对,其中一个元素要优于另一个元素.偏序一词用于表示不是每对元素都需要具有可比性.引入偏序域后,原有的支配定义将不再适应现有的数据集,因此给出新的支配关系.

表1 符号定义Tab.1 List of symbols
定义3 (偏序-支配[1])给定d 维数据集P,对两个元组p1和p2,p1支配p2(记作p1<p2)满足下列条件:(其中i∈TO,j∈PO,m∈d)
1)∀i∈TO,p1[i]不差于p1[i];
2)∀j∈PO,p1[j]不差于p2[j];
3)∃m∈{TO∪PO},p1[m]优于p2[m].
利用图2(a)的数据集举例说明,图1 是对该数据集仅考虑价格和评分两个全序域,直接在全序域上求skyline 的结果,最终计算得到的skyline 集合为{p8,p12,p16,p17},但在图2(b)中,加入了偏序域上不同用户对不同种类图书的偏好,对3 个不同用户分别求得的skyline 集合分别为{p4,p6,p8,p9,p11,p12,p14,p15,p16,p17}、{p5,p8,p9,p11,p12,p16,p17}、{p8,p12,p16,p17}.
3 基于倒排索引的高效处理方法
本章首先介绍了文中的数据索引(倒排索引);然后,介绍了利用倒排索引的过滤方法;最后,介绍了基于倒排索引的基础算法PSP_B.算法利用倒排索引对数据提前进行处理,对数据集进行过滤剪枝,使得进行skyline 查询时不必扫描整个数据集.
3.1 倒排索引
对于具有偏序域的数据集,在建立倒排索引前,为了方便计算,需要将偏序维度映射到全序维度.
映射规则[2]:算法采用将偏序域属性映射到两个全序域的方式来处理偏序域属性.如图3 所示,对于偏好哈斯图[13]进行深度优先遍历,并用间隔[po-to1,po-to2]进行标记,其中po-to1表示节点在深度优先遍历时第一次被扫描到的时刻,po-to2表示节点结束扫描的时刻,即该点的子节点全部遍历结束.偏序域上的偏好关系就可以用间隔间的覆盖来表示.

图3 映射规则举例Fig.3 Examples of the mapping function
如用户u2所示的偏好图,在进行映射前事先为偏好图加一个虚节点,方便对偏好属性进行映射;并且对于映射出不止一个间隔的情况,按所有间隔的并集处理,如用户u3所示,由于属性D 优于属性A,因此将属性A 映射出的间隔并到属性D的间隔中.假设属性M、N 的间隔分别为[po1-to1,po1-to2],[po2-to1,po2-to2],若属性M 的间隔[po1-to1,po1-to2],被包含在另一个属性N 的间隔[po2-to1,po2-to2]内,即po2-to1<po1-to1并且po2-to2>po1-to2那么就说明在该偏序维度上属性M 优于属性N.若两个区间互不包含,则相应属性的好坏无法比较.例如图3 中,对于用户u1来说,属性C 映射到全序域的间隔为[2,5],属性B 映射到全序域的间隔为[3,3],属性C 的间隔可以覆盖属性B 的间隔,即对于用户u1来说,属性C 要优于属性B.
扫描结束点:为方便描述,本文引入扫描结束点的概念,我们称第一次扫描到满足结束条件1 的元组就是扫描结束点(参考结束条件1),扫描到扫描结束点时可以结束查询,将结果集返回给用户.
为了减少计算数据点的数量,本文采用了倒排索引结构来对数据进行管理.倒排索引可以加快元组间支配关系的判定,快速找到扫描结束点,从而减少计算数据量.具体地,对于所有的偏序维度按映射规则映射到全序域上,然后,针对每一维的数据,都按照从优到劣的顺序(本文例子中除PO-TO2维度以大值为优外,其他维度均以小值为优)建立倒排索引如图4 所示.

图4 倒排索引应用举例(用户u3)Fig.4 The example of the inverted index application
基础循环扫描策略:由于全序域和偏序域上数据属性值的数量差距较大,导致建立的倒排表不同维度分布不同,属性值个数有差距,如图4 所示,因此对倒排索引上每个维度i 维护一个timesi变量,用来记录该维度上扫描过的点的个数,每次扫描均选择timesi值最小的维度,并在该维度上选择索引位置最靠前的元组进行计算,当timesi最小值对应多个维度时可以对这些维度按顺序依次扫描.
图4 中,以第一次循环扫描顺序为评分、价格,PO-TO1、PO-TO2为例,结束第一轮扫描后,4 个维度的timesi值分别为1、1、3、3,进行第二轮扫描时,根据基础循环扫描策略,应从timesi值最小的维度价格和评分维度按序依次扫描,即选择价格维度,那么结束这次扫描后4 个维度的timesi值变为2、1、3、3,此时应选取评分维度进行扫描.这样一直循环扫描下去,直到算法结束(参见结束条件1).
在skyline 查询时,基础循环扫描策略对倒排索引进行扫描,并对扫描过的点进行扫描次数标记.对每一个元组仅在第一次扫描到的时候进行skyline计算,之后扫描到时仅增加该元组的扫描次数.
3.2 冗余点过滤
在本小节中主要描述了算法过滤冗余点的过程,为描述方便首先给出结束条件1 的内容,用来描述算法的结束条件,之后再通过引理1 证明其正确性.
结束条件1:当扫描到一个元组pi在所有维度上都被扫描过一次时,若pi在偏序维度POm对应多个间隔,判断pi在POm上扫描到的值是否来自同一间隔,若是,则pi可以作为扫描结束点,此时可以结束算法,将结果集返回给用户;否则pi不能作为扫描结束点,继续循环扫描.
引理1[1]:若出现一个元组pi至少在每一个维度上都被扫描过一次,即pi.count>=|Dtotal|,根据基础循环扫描策略,此时在任一维度上都没有被扫描过的元组pj(pj.count=0)一定不会是skyline 点.
证明:根据引理1,当有元组在每一个维度都扫描到一次时可以结束算法,但由于POm-TO1、POm-TO2是由同一个偏序维度m 映射出的且存在一个元组对应多个间隔的情况,必须是同一个间隔扫描结束才能保证是该偏序维度扫描过一次.
证毕
图4 中,第一次count 值达到4 的元组为p8,此时判断,p8在PO-TO1、PO-TO2上扫描到的值分别为7、3,由于p8偏序域映射出的间隔为[3,3],[5,7],3 和7 并不来自同一间隔,因此不停止算法,继续进行循环扫描.直到扫描到元组p17.count 值为4 时,且在PO-TO1、PO-TO2上扫描到的值分别为1、8,来自同一间隔,根据引理1 和结束条件1,此时可以结束算法(如图4 中阴影所示),阴影下方还没有被扫描过的点至少都可以被p17支配,一定不能成为skyline点,可以直接过滤.
为描述方便,定义Ri为暂时结果集,用来存放di维度上已扫描过的skyline 点.
定理1:对维度Di建立对应的结果集Ri,那么对于扫描到在维度Di上的元组pi,若pi不被Ri中的元组支配,那么pi一定是skyline 点.
证明:根据支配定义,一个元组若可以支配元组pi,则在所有维度都不能比pi差,因此,元组pi当前所在维度Dm表现不如元组pi的都不可能支配pi,因此仅考虑Dm对应的结果集Rm中的元组即可.
证毕
在图4 中,当扫描到价格维度上的第二个元组p14时,只需要与R1中的p17进行支配关系比较即可,如图5 所示,不需要与p12,p7比较,节省了比较成本.
由引理1 和定理1 可以过滤掉大量的冗余点,只针对最必要的元组进行skyline 查询,极大地提高了查询效率.

图5 维度Ri 上的结果集举例(用户u3)Fig.5 The example of result set on domain Ri


算法1 第2~6 行根据基础循环扫描策略将偏序域映射到全序域,并建立倒排索引来维护数据.第8~22 行是算法主体,根据维护的count 值来进行skyline 计算.其中,元组仅在第一次被扫描到的时候(即count=0 时)进行skyline 计算(如算法2 所示),当count>0 时,只记录扫描次数,不再进行skyline 计算;当count 值与|Dtotal|相等时,根据引理1 与定理1判断扫描到的偏序属性是否来自同一间隔,若是,则跳出循环,执行第23 行,返回结果集,结束算法,否则继续循环扫描,直到算法结束.

如图4 所示,以第一轮维度扫描顺序为价格、评分PO-TO1、PO-TO2为例,结束一轮扫描后,4 个维度的timesi值分别为1、1、3、3,且其中扫描过的元组{p17,p12,p2,p7}的count 值为{3,1,2,2},本轮中进行了skyline 计算的元组为{p17,p12,p2,p7},计入结果集的元组为{p17,p12,p2,p7}.然后根据基础循环扫描策略继续进行扫描,处理价格、评分维度,扫描元组{p14,p16},根据结束条件1,p14与R1中的p7、p17进行skyline 计算,p16与相R2中的p12进行skyline 计算.依次循环计算,当扫描到元组p8的count 值等于4 时(即与|Dto-tal|相等),根据定理1 判断扫描到PO-TO1、PO-TO2维度上的值不是来自同一个间隔,因此继续循环扫描,直到扫描到元组p17的count 值为4,与|Dtotal|相等,此时算法结束,最终得到结果集{p7,p8,p12,p16,p17}.
4 优化算法
在将倒排索引引入算法的基础上,本文又采用提前分组的方式对算法进行了进一步优化.
4.1 分组倒排
分组策略:给定d 维空间上的数据集P,根据数据集P 的偏序维度(若有多个偏序维度则选择属性值最少的一个偏序维度)进行分组,将在该维度上拥有相同属性值的元组分到一组,例如选取图书种类作为分组维度,将具有相同种类的图书分到一组,如图6 所示.

图6 分组倒排举例Fig.6 The example of grouping inversion
对数据集P 按选定偏序维度进行分组,并将除该维度外的其他偏序维度按映射规则映射到全序维度,在组内建立倒排索引.之后根据除分组维度外的所有维度分别建立临时表Ti,用于存放每个分组中取值最小的一个或多个元组(本文以小值为优).
临时表的更新:进行计算时,在每个维度i 上从对应的临时表Ti中取出最优值,与所在维度结果集Ri中的元组进行比较,若不被结果集中的点支配则加入结果集,将其从Ti中删除,从对应维度i 的分组中再选择最优元组加入Ti.同时与基础算法一样,将记录该数据点的扫描次数值加1.当元组的count 值与|Dtotal|-1(除分组维度外所有维度总数)相等时,根据结束条件1,判定该组计算是否结束.
优化循环扫描策略:1)临时表选择:同基础循环扫描策略类似,对每个临时表i 维护一个变量timesi′,用来记录在临时表Ti中扫描过的元组的个数,每次扫描时选择timesi′值最小的临时表进行扫描.2)元组选择:每次扫描选定临时表后,选择该表内具有最优值的元组pi进行计算,并根据临时表的更新策略更新临时表.
如图6 所示,初始化时分别从每一个分组中,根据每一个维度的倒排索引取出第一个元组加入到对应维度的临时表中(图7).此时T1,T2的times′均为0,因此按顺序选取T1,那么第一次计算的就是T1中值最优的元组p17,计算完成后,此时T1的times′为1,T2的times′为0,因此第二次对T2进行扫描,选取T2中值最优的元组p12进行计算.这样依次按优化循环扫描策略计算,直到算法结束(参见结束条件2).

图7 临时表举例Fig.7 The example of temporary tables
4.2 整组过滤
定理2(整组过滤方法):若扫描到的元组pi在除分组维度外其他维度上均满足结束条件1,那么可以结束元组pi所在分组的计算,并且可以根据用户偏好,将在分组维度上表现比元组pi差的所有分组的计算结束.
证明:当扫描到元组pi在除分组维度外其他维度上均满足结束条件1 时,根据引理1 此时没有扫描过的元组在除分组维度外所有维度上都不会优于pi,根据支配的定义,同一分组内的元组和分组维度上表现比pi属性差的分组内的元组,在分组维度表现也比pi差,因此不存在skyline 元组,可以直接过滤,结束整个分组的计算.
证毕
例如在本文中,当p8被扫描到两次时,通过图2可知,对应的分组维度图书分类上属性值为B,对于用户u3的偏好来说,根据整组过滤方法,E、D、A、C分组都可以整组过滤,因此算法此时可以结束,没有扫描过的元组一定不会是skyline 点.
结束条件2:所有分组的计算都结束时算法结束.
当所有分组的计算都结束时,算法结束,此时所有维度上结果集Ri的并集就是最终所求的结果.由于实际情况中偏序属性远远少于全序属性,在删除整个偏序分组时将直接过滤掉大量数据点,极大加快了计算速度.并且在与结果集中的skyline 点进行比较时,由于是按每个维度从最优开始的顺序,可以只与来自相同的维度的结果集中的点进行比较.

5 实验分析
本节展示了所提算法的高效性.实验环境配置为Inter Core i5 7300HQ 2.50 GHz CPU,8 GB 内存,1 T 硬盘,Windows 10 操作系统的PC.算法用C++语言编写.为了评估本文所提算法性能,以ZINC 算法[3]和PSLP 算法[4]为对比实验进行.
本文分别用真实数据和合成数据验证算法性能.真实数据采用的是股票数据集(共包含2×106条股票记录,每条股票记录包含4 个属性:交易量、股票价格涨幅、股票类别和上市板块,其中股票类别和上市板块为偏序属性维度).真实数据集计算结果如表2 所示.
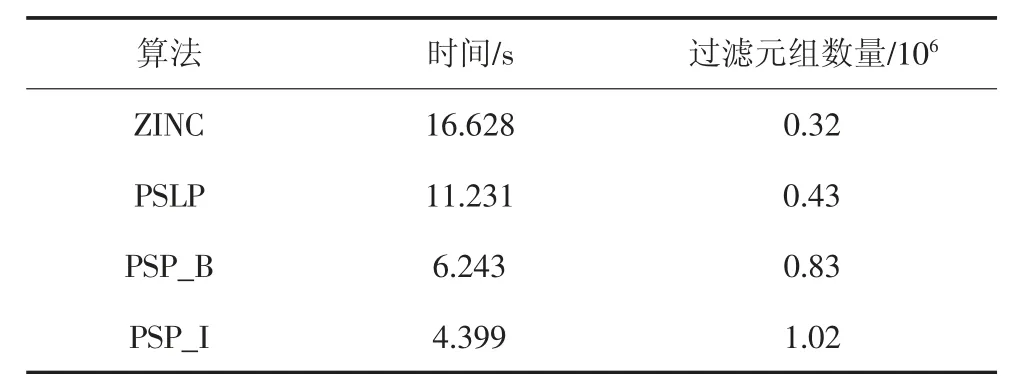
表2 真实数据集实验结果Tab.2 Result of real data set
通过表2 可以看出本文提出的PSP 算法在真实数据集上的表现,在进行skyline 计算的速度上较之前的算法有明显提高,并且由于高效地剪枝过滤,需要计算的数据量也明显少于ZINC 算法和PSLP算法.
合成数据由文献[14]给出的数据生成器生成,包括独立分布数据集和反相关分布数据集.默认数据集包括5 个偏好维度,3 个全序和2 个偏序;默认数据量规模为106;默认用户偏好DAG 的宽度为4,深度为8,密度为0.6.整体上数据服从随机分布,本章实验主要通过维度、数据集规模、哈斯图宽度和深度以及哈斯图密度的变化对实验结果的影响来验证算法的优越性,衡量实验的主要标准为skyline 的计算时间,实验中合成数据的主要参数及其变化范围如表3 所示.
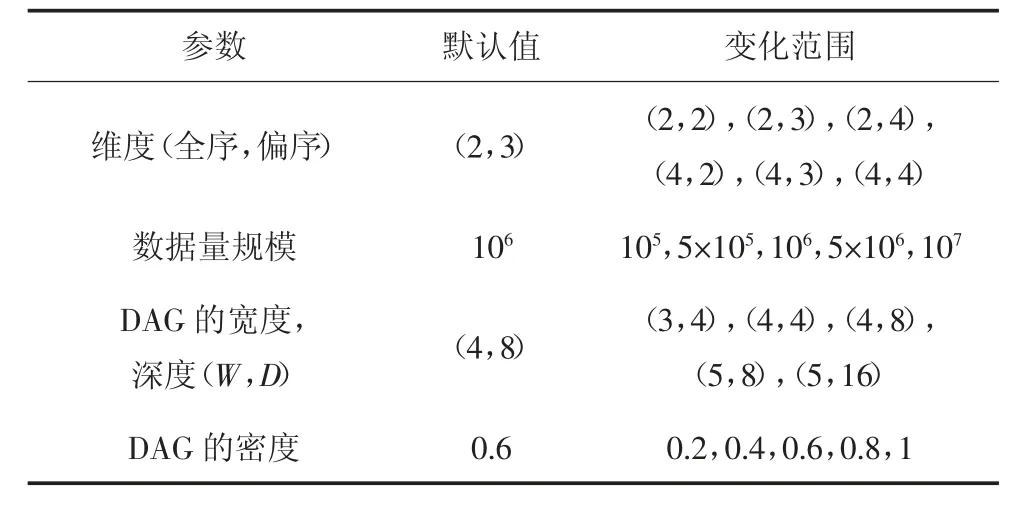
表3 实验参数Tab.3 Experimental parameters
5.1 维度变化对算法性能的影响
为了分析数据集维度对实验的影响,在固定全序维度个数的情况下模拟了偏序维度个数变化的情况,组合(t,p)表示全序维度和偏序维度个数,其中t表示全序维度个数,p 表示偏序维度个数.为了更加稳定地测出算法性能,对于每种取值组合都利用数据生成器随机生成了100 次数据集,进行100 次实验,然后取这100 次实验的平均值进行记录.图8记录了在不同维度个数下进行skyline 计算所消耗的时间,图9 记录了在不同维度下计算过的元组的数量.
图8 和图9 表明了当偏序域维度个数增多时,4种算法的计算时间和计算元组数量的变化.从图中可以看出当|TO|相等,|PO|增多时4 种算法所需时间均呈现指数上升趋势,计算过的元组数量也呈现上升趋势.可以看出,4 种算法中PSP_B 和PSP_I 算法要明显优于另两种算法,这是因为当偏序域增多时,用户偏好复杂,降维成本会很高,PSP_B 算法在映射后采用倒排索引进行轮巡扫描,可以过滤掉大量冗余点,节省了计算时间与计算成本,PSP_I 算法在PSP_B 算法的基础上对数据集进行分组,通过过滤方法对整组数据进行过滤,进一步提高了过滤效率.
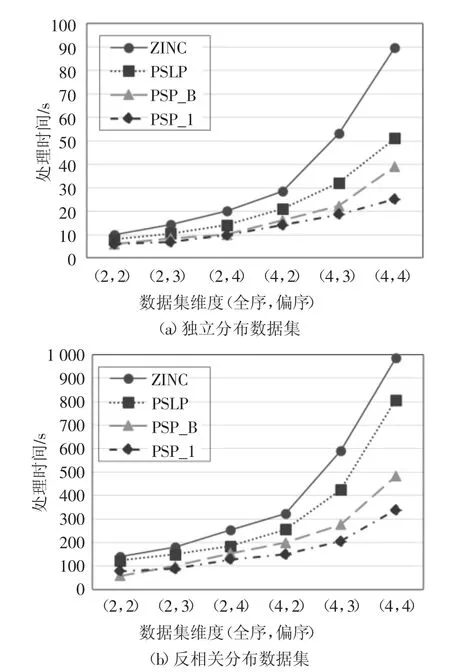
图8 数据集维度对计算时间的影响Fig.8 The effect of dataset dimensions on calculation time
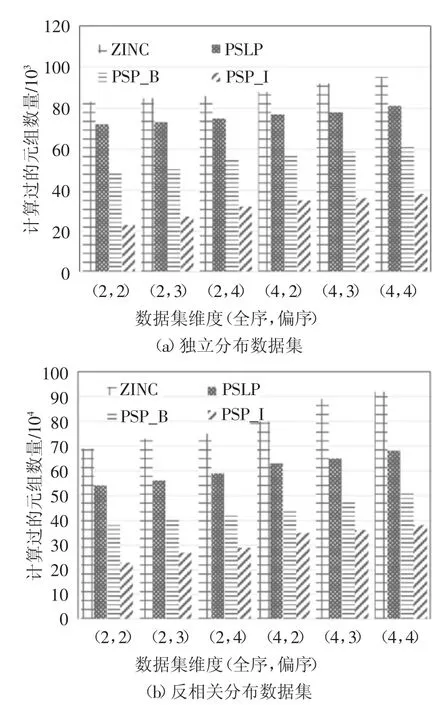
图9 数据集维度对计算过元组数量的影响Fig.9 Effect of dimensions on the number of calculated tuples
5.2 数据集规模对算法性能的影响

图10 数据集规模对计算时间的影响Fig.10 The effect of cardinality on calculation time
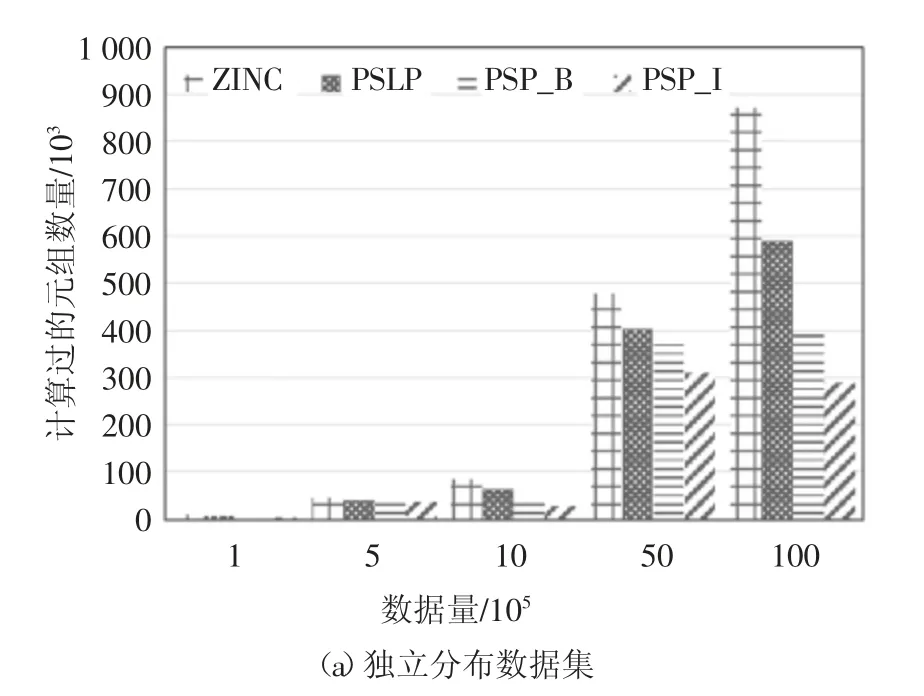

图11 数据集规模对计算过元组数量的影响Fig.11 The effect of cardinality on the number of calculated tuples
图10 和图11 描述了当数据集规模不同时,4 种算法进行skyline 查询所需要的处理时间和所要计算的元组数量.从图中可以看出,随着数据规模增大,计算所需的时间也明显增加,特别是ZINC 算法和PSLP 算法,在数据量增大时显出明显的劣势;在数据量增大时,PSP_B 算法通过倒排索引可以对数据集进行提前过滤,避免了大量不必要的冗余点的计算,明显加快了计算速度;PSP_I 算法在此基础上通过分组倒排可以一次性过滤掉整个分组,提高了过滤效率,进一步减少了计算时间.实验表明PSP_I算法有明显的过滤剪枝效果,并且当数据量增大时对计算效率的提升效果更明显.
5.3 哈斯图宽度和深度对算法性能的影响
比较了当用户偏好哈斯图不同时4 种算法的表现情况,实验除哈斯图形状外其他参数均采用实验默认值,并采用多次实验求平均值的方式进行实验记录.图12 和图13 分别记录了在哈斯图宽度和深度不同情况下的实验结果.

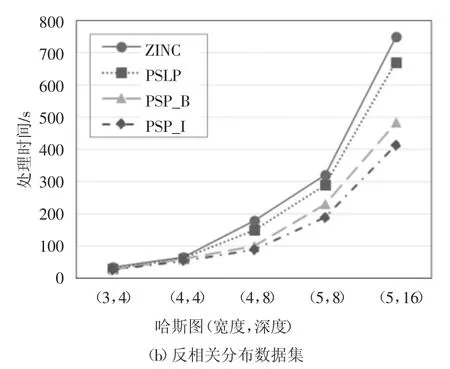
图12 哈斯图宽度和深度对计算时间的影响Fig.12 The effect of the depth and width of the hasse on running time
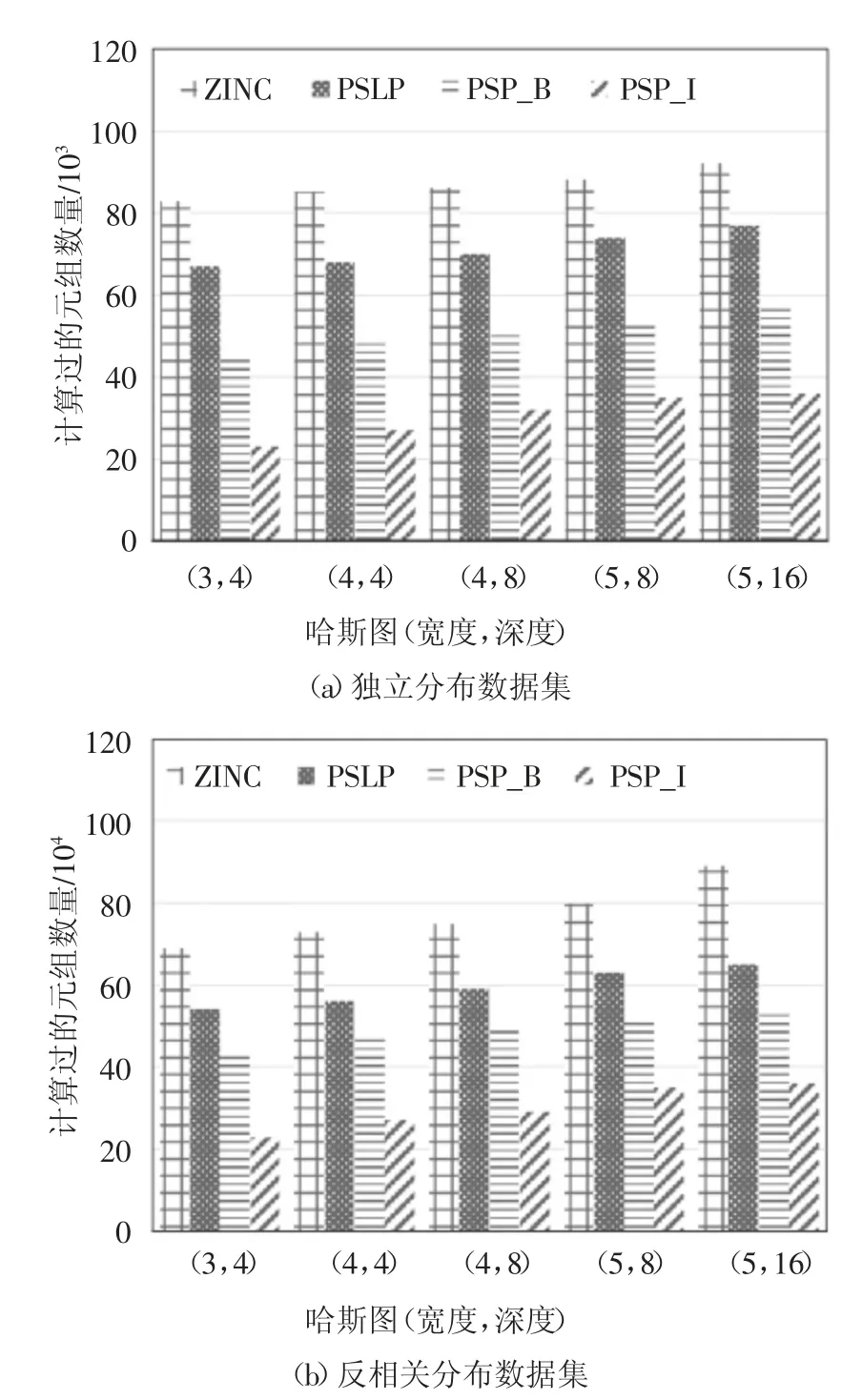
图13 哈斯图宽度和深度对计算过元组数量的影响Fig.13 The effect of the depth and width of the hasse on the number of calculated tuples
从图12 中可以看出在哈斯图宽度和深度不同的情况下,PSP_B 算法和PSP_I 算法计算时间均少于ZINC 和PSLP 算法,且随着宽度和深度的增加差距逐渐明显.图13 则说明了PSP_I 算法剪枝效果的优越性,该算法大量地减少了需要计算的元组数量.通过独立分布数据集和反相关数据集的对比实验表明在不同的数据分布情况下本文提出的算法对skyline 计算效率有明显提高,通过对数据剪枝过滤减少了计算时间.
5.4 哈斯图密度对算法性能的影响
本小节的实验比较了在其他属性均取默认值的情况下,不同的哈斯图密度对实验结果的影响.图11 记录了哈斯图密度分别取0.2、0.4、0.6、0.8 和1.0 时,4 种算法的计算时间.同之前的实验相同,采用多次实验求平均值的方法进行实验记录,结果如图14、图15 所示.
图14 表明4 种算法在哈斯图密度不同的情况下进行skyline 计算所需要的时间.从图中可以看出,在哈斯图密度不同的情况下本文提出的PSP_B算法和PSP_I 算法所需的计算时间均少于之前的算法.图15 表明本文提出的算法有明显的过滤效果,大量减少了元组的计算数量,证明了本文提出的算法可以有效地提高skyline 查询的计算效率.
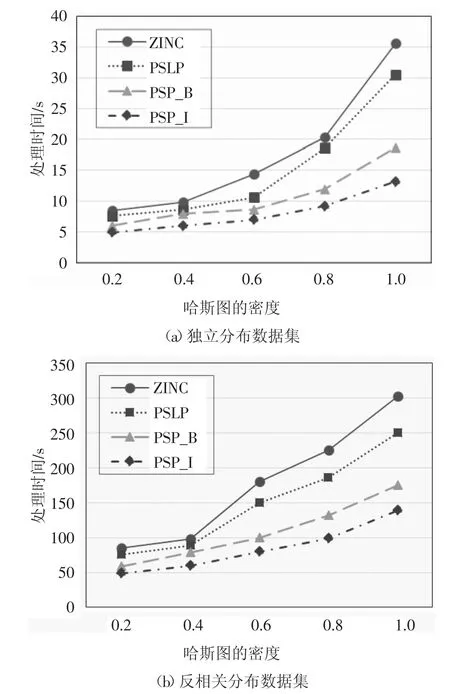
图14 哈斯图密度对计算时间的影响Fig.14 The effect of the density of the hasse on running time
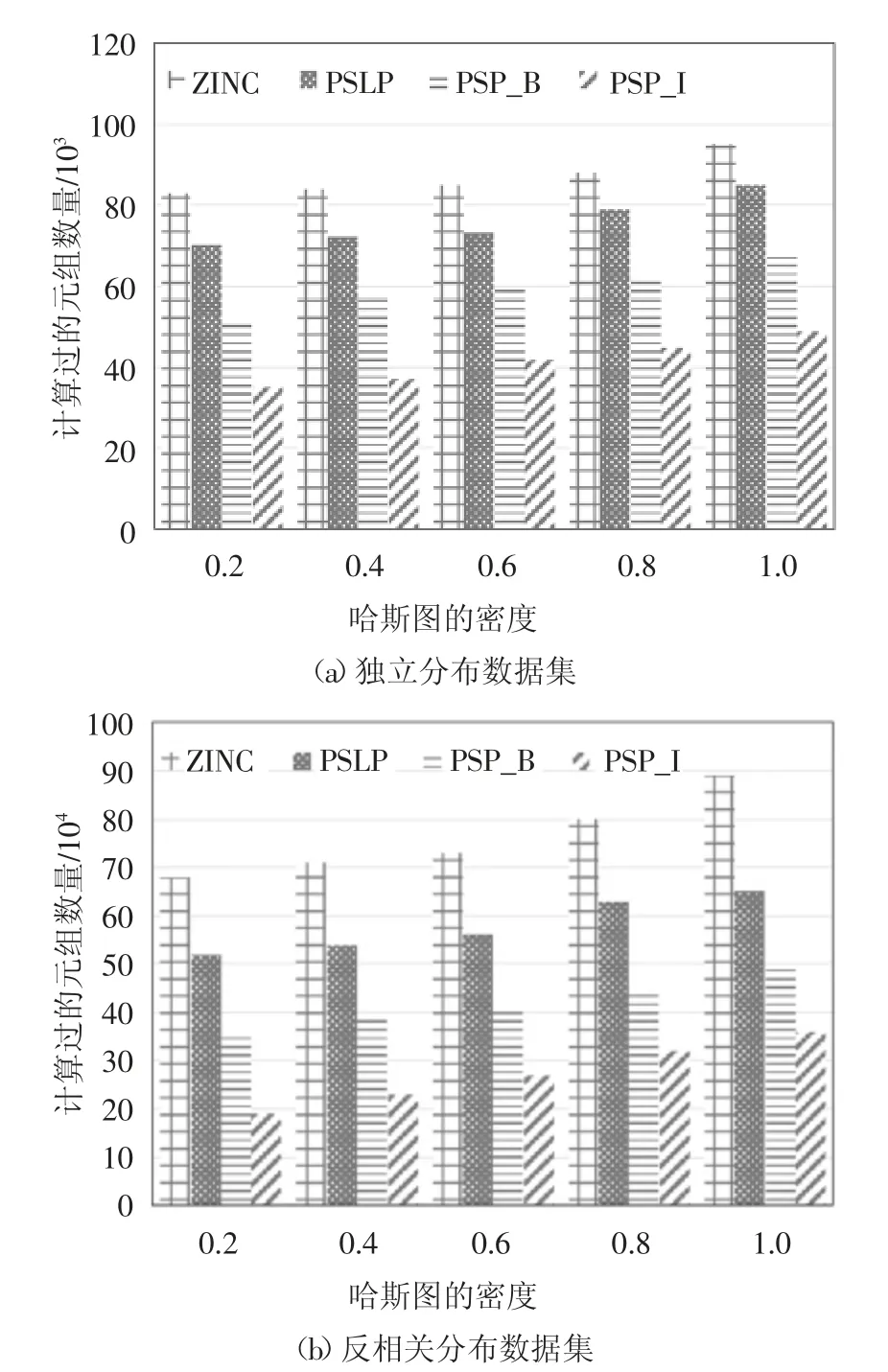
图15 哈斯图密度对计算过元组数量的影响Fig.15 The effect of the density of the hasse on the number of calculated tuples
6 结论
本文对偏序域上的skyline 查询技术进行了深入研究.首先提出将倒排索引引入skyline 查询领域,利用倒排索引来管理数据,在查询前进行大量的剪枝过滤,并通过实验证明其可以有效地提高查询效率;在此基础上提出了一种优化算法,在建立倒排索引前通过分组的方式对数据进行预处理,在进行计算时将一定不会成为结果的分组整组过滤,从而进一步加快了过滤效率,提高计算速度.实验结果表明,本文提出的新算法在计算速度和过滤效果上优于之前的算法,具有合理性.
猜你喜欢
模具制造(2021年6期)2021-08-06
电脑报(2021年14期)2021-06-28
模具制造(2021年4期)2021-06-07
小哥白尼(野生动物)(2020年5期)2020-09-24
计算机与生活(2020年8期)2020-08-12
软件学报(2019年11期)2019-12-11
计算机与生活(2019年5期)2019-07-18
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
