
高光谱成像的图谱特征与卷积神经网络的名优大米无损鉴别
2020-09-05 03:45翁士状唐佩佩张雪艳黄林生赵晋陵
光谱学与光谱分析 2020年9期
翁士状, 唐佩佩, 张雪艳, 徐 超, 郑 玲, 黄林生, 赵晋陵
安徽大学, 国家农业生态大数据分析与应用工程研究中心, 安徽 合肥 230601
引 言
中国是世界上最大的大米生产国, 年产量连续多年名列前茅[1]。 2018到2019年度, 中国大米产量预计占全球产量的28.90%。 中国地大物博, 土壤气候差异较大, 孕育出多种优质大米。 不同品种的大米所含水分, 蛋白质, 脂肪等成分不尽相同, 优质大米中所含的营养成分较多[2]。 一些商家为赚取更多利益, 开始在优质大米中掺劣质大米, 甚至以次充好。 为保护消费者的消费权益, 生产者的积极性, 实现对大米的品种鉴定是非常必要的。
大米的外观微小且相近, 很难通过人为观察去准确的辨认出种类, 需结合图像、 光谱等方法实现大米的准确鉴别。 机器视觉和红外光谱已被广泛应用在食品检测中。 机器视觉可获得形态、 纹理、 颜色等图像信息而被广泛应用于损伤检测、 实时分级以及质量评估[3]等。 但机器视觉的方法只能获取大米的外观信息, 缺少对食品内在成分的分析。 近红外光谱可获取物质的内部成分的光谱信息, 利用物质的内在成分实现无损检测、 掺杂分析和食品分类[4]等。 但近红外光谱缺少可见光波段光谱信息且无法提供样本的外在特征。
高光谱成像则整合了机器视觉和红外光谱可同时获取样本的光谱和空间图像信息[5], 具有快速、 高效、 准确和无损的特点, 广泛应用于农药残留检测、 食品内在成分含量分析和食品种类的鉴别等。 杨小玲等采用400~1 000 nm波段范围的高光谱成像技术研究成熟和未成熟玉米种子, 选用主成分分析法提取特征波长, 采用偏最小二乘法和波段比运算结合KW检验分析平均光谱[6]。 吴静珠等通过偏最小二乘算法选取特征变量建立多个籽粒的小麦粗蛋白平均模型, 再提取其高光谱图像应用于平均模型预测单个籽粒小麦每个像素点的粗蛋白, 取其平均值作为小麦的最终粗蛋白含量[7]。 王璐等通过高光谱图像获取大米的光谱和图像信息, 图像信息选取了垩白度和形状特征(“长轴长”、 “短轴长”“长宽比”、 “周长”和“偏心度”), 数据融合结合BPNN模型实现对大米的品种和品质的鉴别[8]。 在前人的研究基础上, 本研究探究一种融合图像和光谱特征的名优大米无损鉴别方法, 大米的图像信息不仅选取多种形态特征, 还尝试了大米的其他图像信息的融合, 实现对多种名优大米的精准鉴别。
近年来, 深度学习网络如卷积神经网络(convolutional neural network, CNN)、 循环神经网络(recurrent neural network)和深度置信网络(deep belief networks)在语音识别、 图像识别和信息检索等方面的表现优越[9]。 最近, 深度学习开始应用在高光谱对物质的分析。 谢忠红等利用菠菜的高光谱图像建立光谱和图像的样本库, 再基于CNN建立识别模型, 发现基于图像识别的效果最佳, 对菠菜新鲜度的识别正确率达到了80.99%[10]。 桂江生等提出了一种基于卷积神经网络模型的大豆花叶病害的诊断识别方法, 最终模型训练集识别率达到94.79%, 预测集识别率达到92.08%[11]。 在深度学习网络中, CNN是具有多层感知机的分类模型, 以局部链接方式, 实现权值共享, 减少权值数量, 提高数据处理速度, 而且可以减小模型的过拟合问题。 与传统的方法相比, CNN的容错性更高, 提取数据特征信息更准确, 从而极大地提升了模型性能。 因此, 本研究选用CNN融合图谱特征对大米进行分类。
选用七种名优大米为对象, 利用高光谱成像和CNN结合图谱特征实现大米种类的鉴别。 首先, 测量了七种名优大米的400~1 000 nm高光谱图像, 并从图像中提取了每种大米的光谱、 纹理与形态特征。 同时, 使用连续投影算法(successive projections algorithm, SPA)、 竞争自适应重加权算法(competitive adaptive reweighting algorithm, CARS)以及两者级联方法(CARS-SPA)选取多元散射校正(multiplicative scatter correction, MSC)处理后光谱特征的重要波长。 SPA用于确定形状与纹理特征中的重要变量。 最后, CNN融合不同特征构建分类模型对大米种类进行识别。 此外, K-近邻(K nearest neighbor, KNN)和随机森林(random forest, RF)被用来进行对比分析。
1 实验部分
1.1 样本
选择来自全国各地的七种名优大米作为研究对象, 包括: 京和桥米(湖北京山)、 梅河大米(吉林梅河口)、 宁夏珍珠米(宁夏青铜峡)、 盘锦大米(辽宁盘锦)、 上林大米(广西上林)、 丝苗米(广东增城)、 五常大米(黑龙江五常)。 不同种类大米均从其生产地购买, 为保证样本的普遍性, 每种大米购买三批, 每批采集96粒大米。 七种大米共2016个样本被采集。
1.2 高光谱图像采集与标定
大米样本的高光谱图像使用可见-近红外反射高光谱成像系统采集。 该高光谱成像系统(图1)由实验暗箱、 成像光谱仪以及数据收集处理单元组成。 实验暗箱包含可放置样本的移动升降台和两个150瓦的卤素灯; 高光谱成像仪为(SOC710VP, USA); 数据收集处理单元包括: 带有光谱数据采集软件的计算机(用于设置曝光时间, 修改图像分辨率以及对样本光谱的分析)。
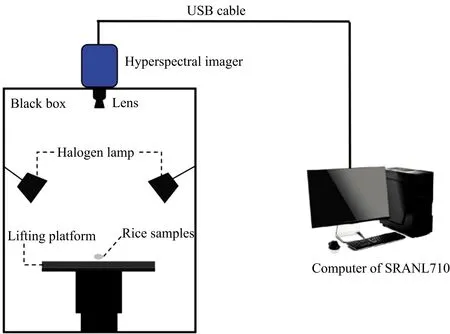
图1 高光谱成像系统装置原理图
测量之前, 打开仪器30 min使光照稳定。 在黑板上每次放置48粒大米, 将大米按照6行8列排列放置在置物台上。 调节样本与镜头距离为35 cm并使镜头焦距对焦, 保证高光谱图像中只有大米矩阵, 以便更好采集大米的实际形态。 本实验设置的图像分辨率相对较高为1 392×1 392, 曝光时间设置也相对增加为200 ms。 使用线性扫描的方式获取大米的三维(x,y,λ,x和y为空间维度,λ为光谱维度)高光谱图像。 每种大米的每个批次采集两张高光谱图像, 7种大米共采集42张高光谱图像。
为减少CCD相机长期使用而产生的暗电流, 噪声以及光照不稳定等因素影响, 需要对高光谱图像进行黑白板校正。 如式(1)所示
(1)
式(1)中,I为校正后大米图像;I0为原始图像;B为黑板图像;W为白板图像。
1.3 图谱特征的获取
1.3.1 光谱特征
光谱特征是对高光谱图像中的每粒大米进行感兴趣区域的提取与计算所得。 感兴趣区域提取与计算的流程为: 对高光谱图像去除噪声和背景, 再进行阈值化分割转变为二值图像, 对大米矩阵中的每粒大米提取感兴趣区域, 再计算每粒大米像素的平均反射率, 以此作为光谱特征。 为提高大米种类鉴别的准确性, 使用了MSC对光谱进行预处理。 MSC是常用于修正光谱间的相对基线平移和偏移校正的一种数据处理方法, 经过散射校正后的光谱可以有效的地消除散射影响, 增强有用的光谱吸收信息。
1.3.2 图像特征
针对大米的特点, 图像特征选用纹理和形态两种特征。 使用灰度梯度共生矩阵(GLGCM)来提取大米的纹理特征。 GLGCM是综合了灰度和梯度信息来提取纹理特征。 在灰度共生矩阵中加入图像的梯度信息, 使共生矩阵更能包含图像的纹理基元和排列信息。 主要有15个特征值: 小梯度优势(2), 大梯度优势(3), 灰度分布的不均匀性(4), 梯度分布的不均匀性(5), 能量(6), 灰度平均(7), 梯度平均(8), 灰度均方差(9), 梯度均方差(10), 相关性(11), 灰度熵(12), 梯度熵(13), 混合熵(14), 惯性(15), 逆差矩(16)。
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)
(14)
(15)
(16)
对只有大米区域的二值图像使用轮廓追踪方法获取每粒大米的外边界, 再进行8联通处理后标注, 最后提取大米的形态特征。 基于前人的研究选取了以下11种大米的形态参数: 长度(大米最小外接矩形的长); 宽度(大米最小外接矩形的宽); 周长(大米边缘上所有像素数之和); 面积(大米区域内所有像素和); 长轴长(与大米区域具有相同标准二阶中心矩的椭圆的长轴长度(像素意义下)); 短轴长(与大米区域具有相同标准二阶中心矩的椭圆的短轴长度(像素意义下)); 离心率(与区域具有相同标准二阶中心矩的椭圆的离心率); 紧密度(大米面积与大米最小外接矩形面积的比值); 长短轴比(大米长轴长与短轴长的比值); 外观比(大米最小外接矩形的长宽比值); 最小外接矩形面积(大米最小外接矩形的面积=长度×宽度)。 由于纹理和形态的特征参数的数值差异性较大, 采用归一化处理将所有图像特征的数值换算到同一个量级内, 从而达到消除各特征值之间的差异。
1.4 特征变量选择方法
选用SPA和CARS以及CARS-SPA三种高效的变量选择方法选取大米的重要波长。 同时, 选择了最简便的SPA选取纹理和形态特征的重要变量。 SPA是一种前向变量选择算法, 可使矢量空间共线性最小化, 对于光谱特征可提取最优的特征波长, 对于图像特征可挑选出重要的特征参数, 消除原始特征矩阵中冗余的信息, 被广泛用于特征的筛选。 CARS是建立在模仿达尔文进化理论中“适者生存”的原则基础上提出的变量选择方法, 该算法在消除无信息变量的同时可以对共线性信息进行去除。 还使用了CARS和SPA的级联方法, 先利用CARS筛出部分无信息和冗余特征, 再用SPA对特征变量进行选择。
1.5 分类建模方法与评估
CNN, KNN和RF被用于构建分类模型, 实现对大米种类的鉴别。 CNN是一种常用的神经网络模型, 它的神经元间的连接是非全连接的, 并且同一层中某些神经元之间的连接的权重是共享的(即相同的)。
CNN的结构包括卷积层、 池化层、 规范层(batch normalization, BN)以及全连接层。 卷积层主要是用来提取输入的不同特征, BN层的作用是防止过拟合。 池化层将卷积层得到的高维度特征切分成几个区域, 取其最大值或平均值, 得到新的并且维度较小的特征。 全连接层则是将所有局部特征结合变成全局特征, 用来计算最后每一类的得分。 本工作所用的CNN算法结构为: 三层卷积层, 两层规范层, 两层池化层以及两层全连接层, 两层的规范层与前两层卷积层融合(图2)。 同时在全连接层添加了起加速运算和防止过拟合作用的Dropout(Dropout是指神经网络训练过程中将神经网络单元按照一定的概率从网络中暂时丢弃)。 其中, CNN的输入是将一维特征数据转化为3x1的二维向量。 CNN的参数包括learning_rate, batch_size, n_epochs, nkerns和poolsize。
KNN是一种简单的分类算法, 核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别, 则该样本也属于这个类别, 并具有这个类别上样本的特性。 这种方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 其模型参数包括: n_neighbors(KNN中的K值)、 weights(确定每个样本的最近邻样本的权重, 默认为“uniform”即所有最近邻样本有相同的权值)。
RF是一种基于Bagging算法的重要的集成学习方法, 可以用来做分类、 回归等问题。 随机森林算法具有很多优点: 能够处理很高维度的数据, 不需要做特征选择, 对数据集的适应能力强: 能处理多种类型的数据, 数据集无需规范化; 训练速度快, 可以得到变量重要性排序; 不容易陷入过拟合。 其模型参数包括: n_estimators(随机森林中决策树的数目)、 max_features(随机森林分区的最大特征数)、 max_depth(决策树的最大深度)。

图2 卷积神经网络的结构示意图
每类大米数据按照3∶2被划分成训练集与预测集。 每种大米288个样本, 173个样本数据被选为训练集, 115个样本数据作为预测集, 七种大米共2 016个样本。 分类模型的优劣是基于分类准确度(accuracy, ACC)进行评估[12]。 ACCT和ACCP分别表征训练集和预测集的分类准确度。 图谱特征的提取, 光谱的预处理以及特征的变量选择均是基于MATLAB(R2017b)实现。 三种分类算法则是基于Python语言的Scikit-learn框架实现。
2 结果与讨论
2.1 大米反射率光谱特性
为提高大米种类鉴别的准确度, 选用MSC对400~1 000 nm范围内的大米光谱进行预处理。 图3(a)和(b)可明显看出预处理后的一种大米的光谱相较于原始光谱更加集中, 消除了光谱的散射, 增大七种大米光谱反射率的区别。 因为MSC是用于修正光谱间的相对基线平移和偏移校正的一种数据处理方法, 经过散射校正后的光谱可以有效的地消除散射影响, 增强有用的光谱吸收信息。 图3(c)可见七种大米的光谱曲线整体趋势相同, 在可见光波段(400~680 nm)大米的反射率较低, 曲线平滑。 随后光谱曲线突增, 在近红外波段(720~1 000 nm)大米的反射率维持在0.35~0.5之间, 在883, 889和896 nm有三个窄带吸收峰, 其出现的原因是大米中与水分有关的O—H官能团的第三次泛音拉伸[13]。 大米的光谱提供了大米主要成分的化学信息, 如蛋白质、 淀粉和水分, 这些成分与C—H (910 nm), O—H (750~900 nm)和N—H (962~1 000 nm)泛音的拉伸有关[14]。 同时, 在近红外波段可明显观察到七种大米具有不同的反射率曲线, 光谱特征大体可实现大米种类的区分, 但有些大米曲线相近, 可能无法准确鉴别, 如五常大米和丝苗米, 上林大米和盘锦大米, 需补充大米其他特征信息来提升大米的鉴别度。
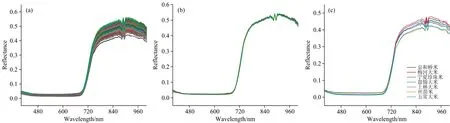
图3 一种大米的原始反射率光谱(a)、 MSC预处理光谱(b)以及七种大米的平均反射率光谱(c)
2.2 光谱特征的重要波长选择
利用SPA, CARS以及CARS-SPA对大米的光谱特征进行重要波长的选择, 减少光谱特征的冗余信息, 为后期数据分析提高计算速率。 SPA通过设置最小波长点个数来确定特征波长数, 最终获取15个光谱重要波长。 CARS是通过自适应重加权采样技术选择出模型中回归系数绝对值大的波长点, 去掉权重小的波长点, 再利用交互验证选出RMSECV值最低的子集, 可有效的找到最优波长组合。 经过多次试验得出均方根误差RMSECV的最小值为1.69, 从而得到12个光谱重要波长。 对于CARS-SPA级联方法, 先使用CARS对大米光谱特征进行降维后再使用SPA选取最终特征, 经过多次尝试挑选出14个光谱重要波长(表1)。 SPA和CARS-SPA选取的波长大多数在近红外端, 而CARS选取的波长在可见端和近红外端分布均匀。
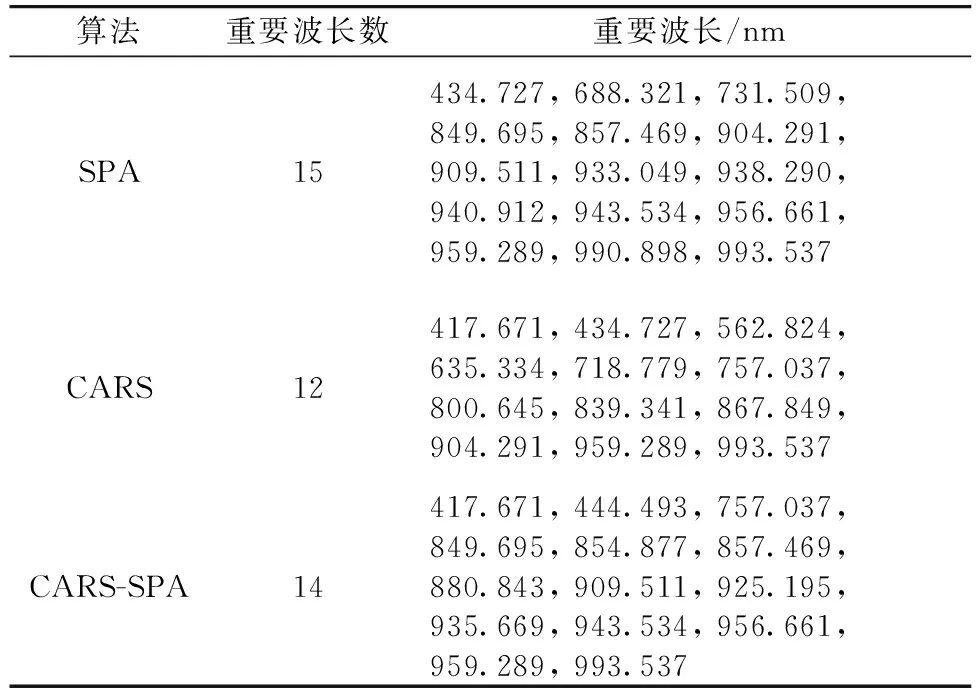
表1 不同特征选择算法选取的光谱重要波长
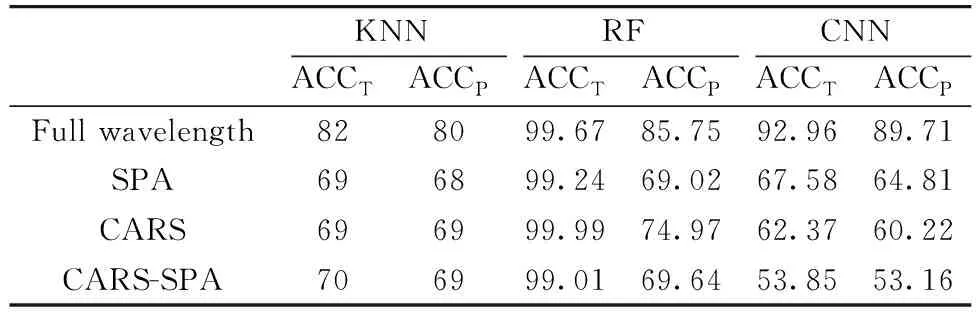
表2 使用光谱特征的大米种类鉴别结果(%)
2.3 基于光谱特征的大米种类识别
对260维的全光谱特征和光谱重要波长使用KNN, RF和CNN构建模型, 结果在表2中显示。 对于全光谱特征, KNN建模效果最差, RF的效果较好, CNN网络的模型性能最优, ACCT和ACCP分别为92.96%和89.71%。 对SPA和CARS-SPA选择的重要波长构建分类模型, RF模型的效果较好, KNN次之, CNN模型则相差较多, 对大米种类鉴别准确度都低于70%。 对CARS方法选择的重要波长建模分析, CNN网络较差ACCT为62.37%, ACCP为60.22%; KNN模型的预测集准确度为69%; RF分类结果最佳, ACCT和ACCP分别为99.99%和74.97%。 优于其他两种变量选择方法。 但光谱的重要波长相较于全光谱特征的分类准确度相差较多, 原因可能是光谱整体差异不大, 选择出来的光谱变量不能表达出全光谱信息。 此外, 为了更准确区分多种大米的种类, 全光谱的分类准确度有待提高, 需要融入更多信息。
2.4 大米纹理与形态特征分析
为了融入更多大米的特征信息, 取了大米的纹理和形态特征。 选用GLGCM方法选取了15个纹理特征, 形态特征则选取了11个常用的大米形态特征。 为减少纹理和形态特征的信息冗余, 挑选出与大米种类相关性较高的重要变量。 考虑到简便、 快速等特点, SPA被用于对形态、 纹理特征的筛选。 对纹理特征选取了8个纹理特征变量, 分别为小梯度优势、 能量、 梯度平均、 灰度均方差、 相关性、 灰度熵、 梯度熵和惯性。 对形态特征选取面积, 长轴长, 长短轴比三个特征变量。 为了更直观地了解选择后的纹理、 形态特征重要变量的整体情况, 我们计算它们的均值和标准差(表3、 图4)。
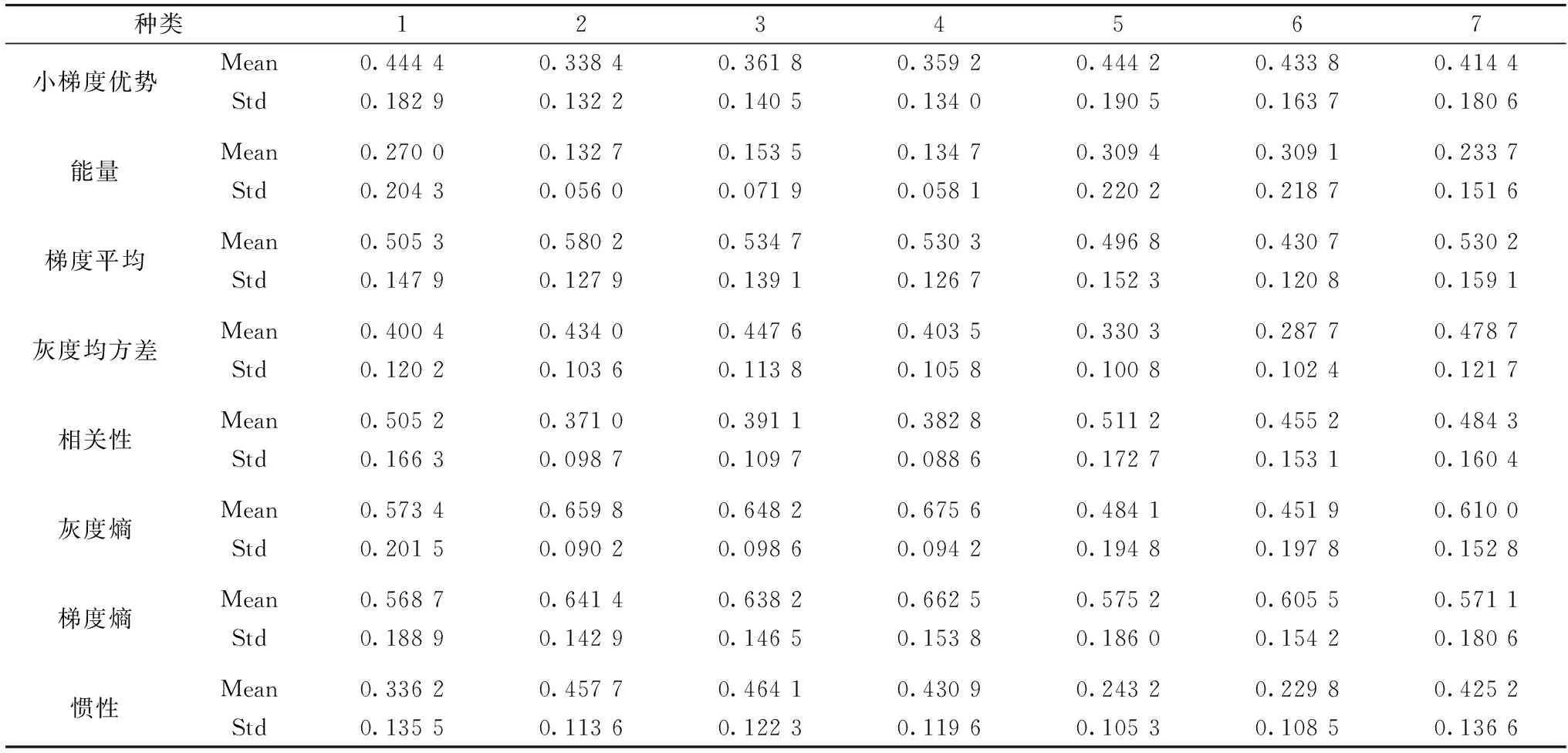
表3 经过SPA挑选的八个纹理特征的均值与标准差(Mean为参数的均值, Std为参数的标准差)(像素)
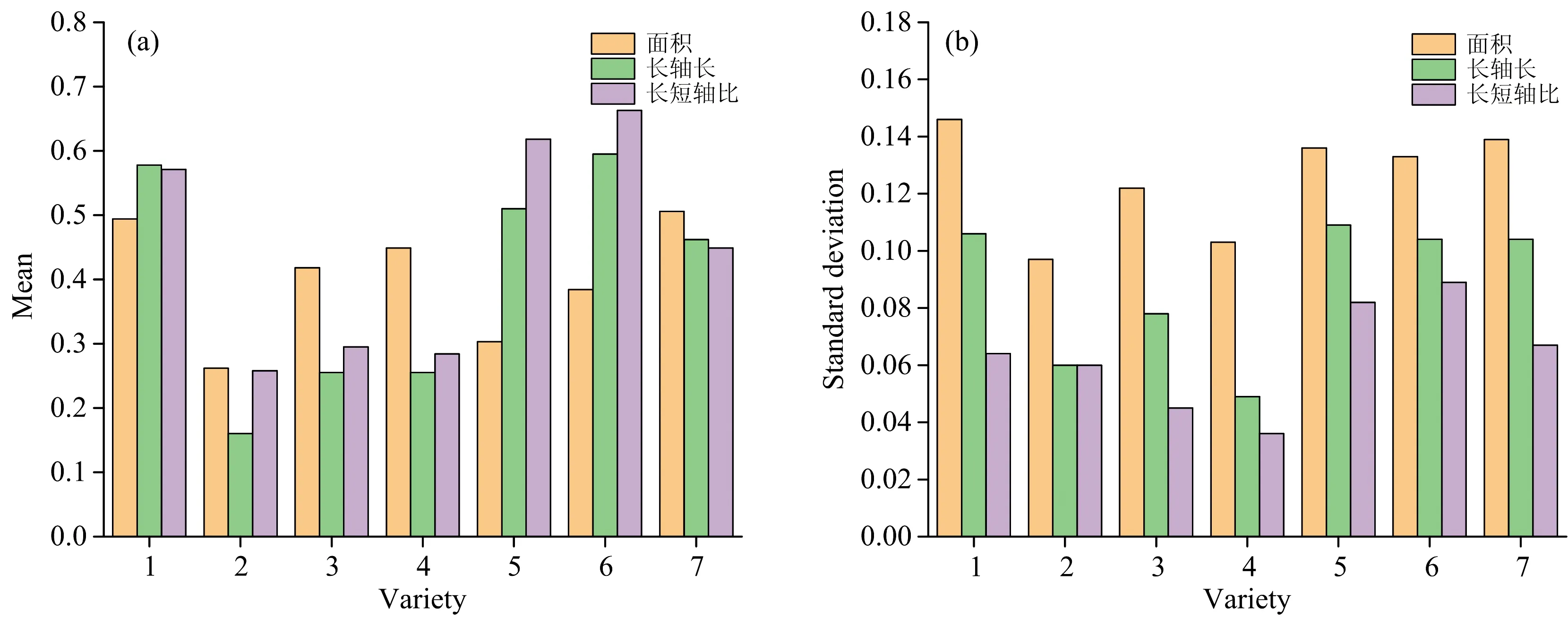
图4 经过SPA挑选的三个形态特征(面积, 长轴长, 长短轴比)的均值(a)和标准差(b)
表3可以看出七种大米的纹理特征参数的均值都有所不同, 但均值差异较小且各个纹理变量的标准差大都相近, 可用于大米种类区分但分类效果有待继续探究。 图4中不同种类大米的形态特征重要变量的均值和标准差的数值相差不同, 有些差异较大, 有些则相近。 同时, 相较于所选的纹理参数, 形态参数的差异较大, 对大米鉴别的贡献能力可能更大。 综上, 不同种类大米的纹理、 形态特征存在一定的区别, 可作为大米种类鉴别的辅助信息。
2.5 谱图特征融合的大米种类鉴别
为准确识别七种名优大米, 对光谱与纹理、 形态融合特征构建模型(表4)。 KNN模型的分类精度非常差, 光谱与纹理融合的预测集精度只有45%左右, 光谱与形态结合的预测集准确度67%左右。 说明KNN模型不适用于多元信息结合的数据。 RF模型的ACCP都在80%以上, 光谱与纹理融合的准确度在81%左右, 而光谱与形态融合的准确度在89%左右。 最优结果来自光谱与形态特征重要变量的融合, ACCT和ACCP为 99.98%和89.10%。 RF分类准确度较高的原因是RF里的每一个决策树都需要预测出一个结果, 然后综合考虑所有结果给出最终的预测, 对于数据集表现良好, 因此精确度比较高。
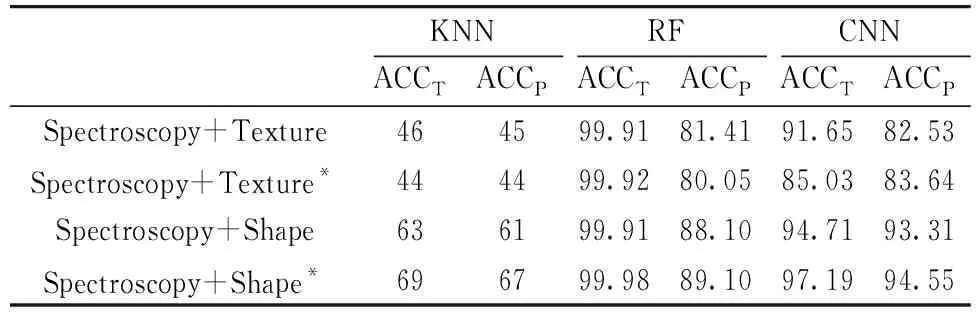
表4 融合光谱、 纹理与形态的大米种类鉴别结果(%)
对于CNN模型, 光谱与纹理结合的ACCP为82%以上, 而光谱与形态结合的ACCP达到93%以上, 优于RF模型。 光谱与形态特征重要变量融合的分类效果最佳(ACCT=97.19%, ACCP=94.55%), 具体分类结果显示在图5, 可直观的看出每类样本的具体错分情况。 其中, 第一类错分成第七类的样本较多, 第五类错分成第一类和第七类的样本较多, 第七类错分成第一类的较多。 说明第一类(京和桥米)、 第五类(上林大米)和第七类大米(五常大米)的相似度较高, 是影响大米种类鉴别准确度的主要因素。
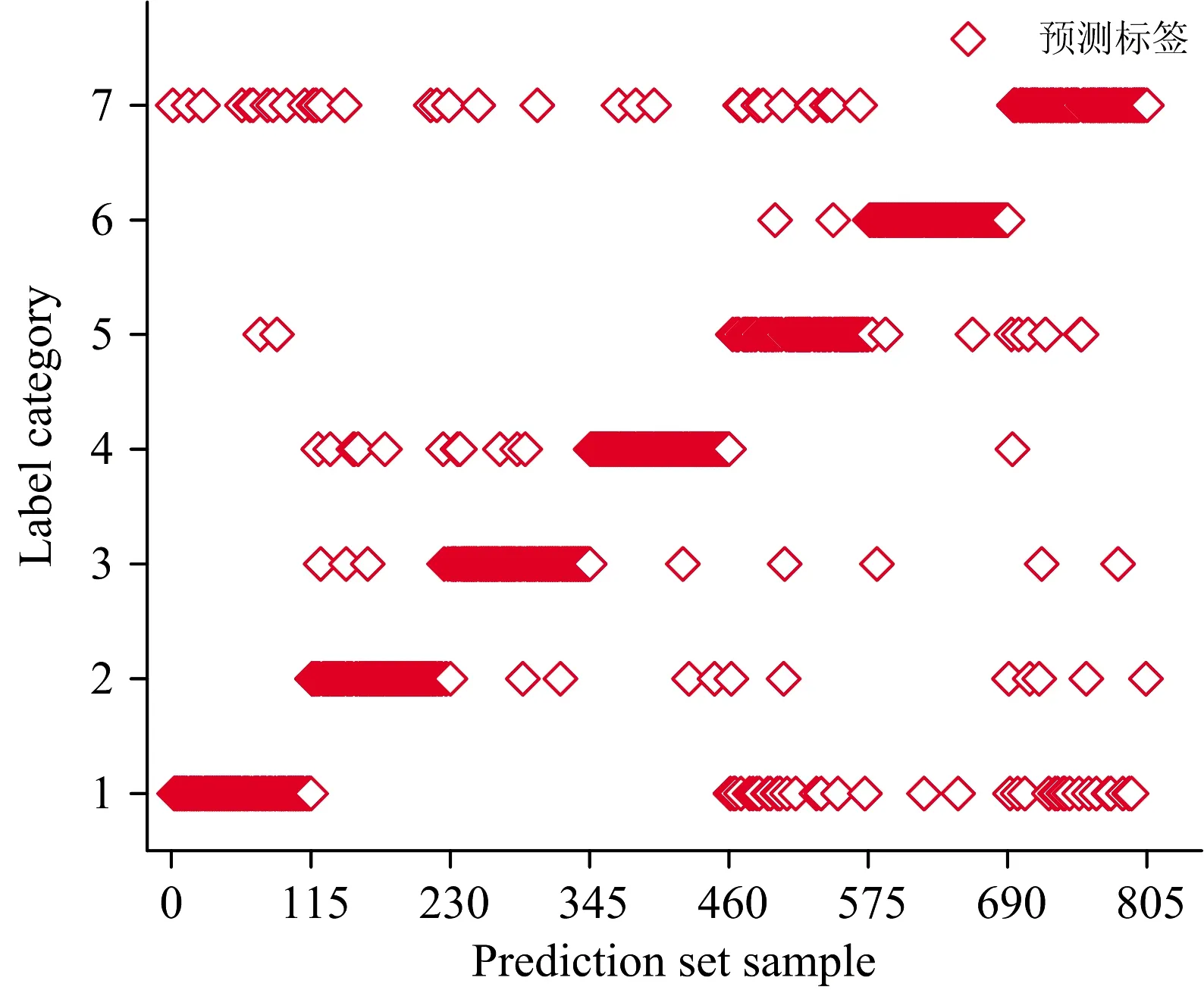
图5 光谱与形态重要变量融合的分类散点图
综上所述, 对于图谱特征的融合, 光谱与形态特征重要变量融合的特征最优。 光谱与纹理融合的建模差于仅用光谱建模, 说明纹理特征弱化了分类结果, 因为不同种类大米的差异较小, 纹理信息作用不明显, 因此建模效果差。 对于模型性能来说, CNN模型的性能明显优于其他两种机器学习方法, 可以提供更好的分类效果。
3 结 论
发展一种高光谱成像的图谱特征与深度学习网络结合的名优大米无损鉴别方法。 对高光谱图像提取每种大米的光谱、 纹理与形态特征, 并选取各类特征中的重要变量。 紧接着, KNN, RF和CNN融合上述特征构建大米种类识别模型。 结果表明, 使用CNN模型对全光谱特征建模分析, 其ACCT和ACCP分别为92.96%和89.71%。 光谱特征重要波长的最优结果ACCP仅为74.97%, 明显差于使用全光谱的分类准确度。 对于图谱特征的融合, 纹理特征的融入弱化了分类性能, 而光谱与形态特征的融合则提升了分类准确度。 其中, 光谱与形态特征变量的融合的效果较好, 且CNN对大米识别的准确度最高, ACCT和ACCP分别为97.19%和94.55%。 综上, 基于CNN融合光谱、 形态特征重要变量可实现对大米种类的准确鉴别, 当然也可应用于其他农产品的鉴别和品质分析。 然而, 成像光谱仪时间与经济成本较高, 构建简易、 低成本的大米种类分析将具有更高的应用价值。 本研究结果还为基于非成像光谱仪、 数字图像设备搭建大米种类鉴别的便携式装置积累相关经验, 为大米种类的在线分析提供了技术参考。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
空间科学学报(2021年1期)2021-05-22
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
Coco薇(2017年8期)2017-08-03
中南大学学报(自然科学版)(2016年2期)2017-01-19
中国照明(2016年4期)2016-05-17
Coco薇(2015年5期)2016-03-29
中国光学(2015年5期)2015-12-09
中国当代医药(2015年26期)2015-03-01
