
基于关键姿势的双人交互行为识别
2020-09-04 10:00杨文璐于孟孟
计算机应用 2020年8期
杨文璐,于孟孟,谢 宏
(上海海事大学信息工程学院,上海201306)
0 引言
近年来,高新技术产业的快速发展和市场对智能设备需求的逐步扩大,极大地促进了计算机视觉的广泛应用和发展。人类行为识别的研究成果被广泛应用于智能监控、智能家居、视频检索定位、运动属性分析等日常生活领域[1]。
目前针对人类行为的分析多集中在单人或人与物的分析,对双人或者多人交互行为分析的研究还比较少[2]。与单人动作相比,双人交互行为在日常生活中更常见。同时,目前一些特定场合的智能监控系统对于双人交互行为识别的需求更为迫切,如从敏感的监控场景(机场、火车站等)大量的视频中检测出推搡、踢打等具有潜在危害性的行为,可以及时地反馈到相关部门,从而提高安保效率,大大提高智能视频监控系统的智能化水平。因此,双人交互动作的识别应用领域更广。
根据原始数据的不同,对于双人交互行为识别的分析方法可以分为基于RGB 视频和基于关节点数据两类[3]。基于RGB 视频的研究开始得比较早,到目前为止的研究成果也非常丰富[4-6],但是由于其缺乏维度信息,导致交互行为识别的效果不是很好。
随着时代的进步与科技的发展,以Kinect 为代表的深度摄像机开始出现。Kinect 可以通过简单的采集方式获取高精度的数据,提供的三维关节点信息可用于人体行为识别研究,也可以解决利用传统图像或视频时难以分割人体的困难[7]。Kinect 开启了利用三维关节点信息进行行为识别的新篇章。文献[8]中将Kinect 捕获的三维关节点数据转换成关节角度特征,并使用支持向量机(Support Vector Machine,SVM)对人体姿态进行检测;文献[9]中为了降低识别过程的计算复杂度,提出了一种基于人体关节结构相似度的行为关键帧提取方法;文献[10]中提出了一种基于空间关系和身体部位之间语义运动趋势相似性的新特征描述符用于双人交互识别;在文献[11]中,交互式身体对之间的关系和运动信息被用作独特的特征。
在双人或多人交互行为的研究中,关键姿势的提取是关键问题之一。文献[12]中通过测量四肢之间的距离粗略地确定交互对,收集交互姿势,然后进行对比挖掘提取典型的交互姿势以进行交互识别;文献[13]中通过连续两帧之间的深度变化计算出某一帧姿势对应的运动能量,定义一段时间内运动能量最大的部分是运动部分,即关键姿势。
本文拟结合骨骼点角度变化的方差和骨骼点间的空间关系来提取关键姿势;然后用关节距离、角度和关节运动等特征表示关键姿势,每一个动作表示为一个特征矩阵;最后,利用不同的降维和分类算法组合进行实验,选取识别率最高的算法组合。实验结果表明本文提出的方法对复杂的交互行为具有较强的鲁棒性和较好的识别率。
1 本文方法
本文通过Kinect 获取人体的骨骼数据,对双人交互进行识别,具体步骤包括获取数据、提取关键帧、提取特征值、降维和分类等,如图1所示。

图1 双人交互行为识别过程Fig.1 Recognition process of two-person interaction behavior
1.1 获取数据
在获取数据阶段,本文采用经典数据集和自建数据集结合的方式。
经典数据集采用SBU 数据集[14]。该数据集采用Microsoft Kinect 传感器获取并提取骨骼数据。该数据集中包含8 种类型的双人互动,即靠近、远离、推人、踢人、拳打、递书、拥抱和握手。所有数据均记录在相同的实验室环境中,7 名参与者组成21 对进行交互,每个动作类别每一对做一次或两次。整个数据集大约有300 个交互,除了包含640 × 480 像素的彩色图像和深度图之外,该数据集还包含每帧每个人15 个关节的三维坐标。由于骨骼的快速移动和关节点之间的遮挡、重叠,导致采取的某些数据不稳定甚至不正确。
自建数据集则使用Kinect 2.0 获取了7 种交互动作的彩色视频、深度图像和骨骼数据。数据集包含的交互动作类型为靠近、远离、推人、踢人、拳打、递书和握手,是由5个人组成10对,每种动作每对做10~15次组成。此外,该数据集是在背景杂乱的室内环境中捕获的,彩色视频和深度图均具有640 ×480 像素的分辨率。利用Kinect 2.0 的骨骼跟踪技术可以捕获人体25个关节点的三维位置信息,如图2所示。
1.2 提取关键帧
关键姿势是表示该帧及其邻帧中人体状态的姿态,由关键姿态表示的状态对于解释人的行为最有意义[15]。为了防止交互行为识别中关键信息的丢失,减少数据的冗余,本文提取关键帧中的人体姿态信息作为关键姿态。
帧间差异比较是一种常用的提取关键帧的技术,通过比较相邻帧图像之间的颜色直方图或者人体关节位移等信息,将帧间差异小于特定阈值的帧图像过滤掉,剩余的帧图像被确定为关键帧[16]。本文就采用帧间差异比较,利用式(1)计算连续两帧之间骨骼坐标的移动距离,设定一个阈值,筛选出大于阈值的帧组成关键帧,然后再进行特征提取。
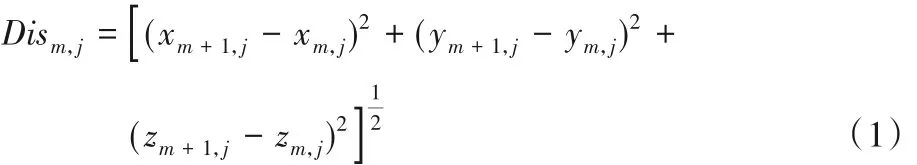
其中:m代表帧数;j代表是骨骼点。
1.3 提取特征值
目前国内外提出的动作识别算法中有三种表示骨骼特征的方法:第一种是空间描述,通过计算一定时间内人体骨骼所有关节或部分关键关节的两两距离,用协方差矩阵表示识别动作的特征;第二种是几何描述,利用运动骨架变换序列对骨架关节的子集或相对几何特征进行描述;第三种是基于关键姿势的描述,使用算法选择一组表示每个动作的关键姿势,每个骨架序列使用最接近的关键姿势来表示[17]。
使用骨架关节作为特征的最大挑战之一是语义上相似的运动不一定在数值上相似[18]。但对于同一类动作总会有相同的关键姿势,即每一个交互动作都有自己独有的一个或多个区别于其他动作的特征,除了这些主要的特征之外大都是一些多余动作,如握手,只需判断双方的右手或者左手是否握在一起,至于双方的其他动作都是干扰动作。所以本文提出了一种新的基于关键姿势的描述对双人交互的动作进行识别。
1.3.1 提取关键骨骼点
提取关键姿势首先要找到关键姿势中的骨骼点,关键骨骼点是完成一个动作最主要的部位,而其他的多余行为则不是我们研究的重点。在概率论和统计学中,随机变量的方差描述了它的离散度,即变量与期望值的距离。本文利用连续帧之间关节点角度变化的方差来说明骨骼点运动的幅度大小,从而找到运动的主要部位。
交互双方各自建立一个以臀部为中心的直角坐标系,坐标系的方向和Kinect 自身的坐标系一样,如图3 所示。本文以Y轴正方向(0,1,0)为标准向量,计算骨骼点与中心形成的方向向量与标准向量之间的角度,计算公式为:
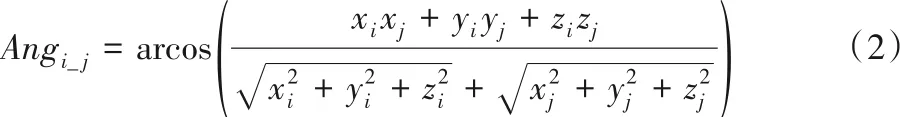
其中:i、j是交互中肢体的任一关节,关节可以来自一个人也可以是不同的人。
获得交互双方所有骨骼点的角度后用方差来说明角度变化的程度,以此找到动作中最活跃的部位。方差表示为:

其中:i代表任何一个骨骼点;m代表关键帧的帧数;Angin为连续两帧之间骨骼点i角度的变化是骨骼点i连续两帧之间角度变化的平均值。
根据方差的大小,获取方差最大的两个骨骼点作为关键骨骼点。
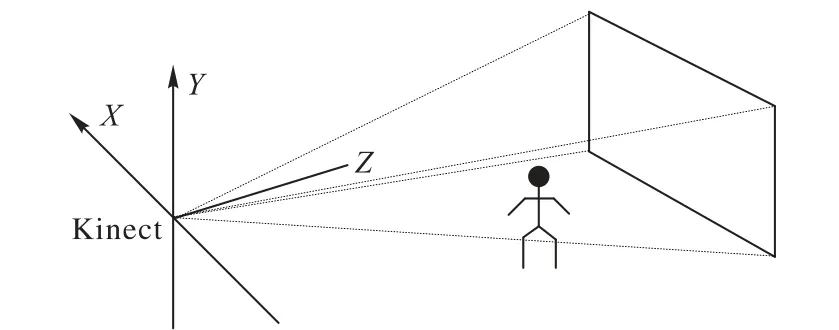
图3 Kinect2.0坐标系图Fig.3 Kinect2.0 coordinate system diagram
1.3.2 提取关键姿势
提取关键骨骼点之后更重要的是确定关键姿势,即确定互动肢体对。每个交互动作都有其必不可少的互动肢体对,由于交互双方的身体部位总是按照交互顺序彼此接近甚至接触,因此本文通过测量关键骨骼点之间的距离确定交互对。关节距离最常用的是欧氏距离,Disi_j定义为:
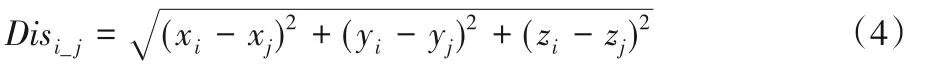
其中:i、j 是交互中肢体的关键关节,关节可以来自一个人也可以是不同的人。
利用欧氏距离获取关键骨骼点与交互方所有骨骼点的距离,根据距离大小确定交互对。
1.3.3 计算特征向量
实验中Kinect 采集的骨骼数据为一组时间序列数据,原始数据包括人体15 或25 个关节点的三维坐标。然后转化为每帧的多个特征维度,一个交互行为中的若干帧特征构成一个交互动作的样本。根据1.3 节提取出的关键交互对,针对每个交互动作利用一个或两个特征值来表示出关键关节的姿势状态,具体表示如下所述(以1.1 节图2 的25 个关节为例,用0~24 表示交互的第一个人的关节,25~49 表示交互的第二个人的关节):
1)利用1.3.2 节中的式(4)计算关节1(SpineMid)和关节26(SpineMid)间的距离Dis1_26来表示交互双方身体间的距离,若此距离小于某个阈值则输出1,否则输出0。
2)计算关节3(Head)和关节28(Head)在X 轴方向上的距离,记为DisX3_28,然后计算关节3和关节11(HandRight)、关节7(HandLeft)在 X 轴 上 的 距 离 以 及 关 节 28 和 关 节 36(HandRight)、关节32(HandLeft)在X 轴上的距离,分别记为:DisX3_11、DisX3_7、DisX28_36和 DisX28_32;若 DisX3_28大于后四个距离中的任意一个则输出1,否则输出0。
3)计算关节 15(FootLeft)和关节 19(FootRight)、关节 40(FootLeft)和关节 44(FootRight)在 Y 轴上的距离,分别记为:DisY15_19和DisY40_44,若任一距离大于某个阈值则输出1,否则输出0。
4)由步骤1)得到每帧交互双方间的距离Dis1_26,接着计算前后两帧间交互双方距离的差值,若差值大于0 则为1,否则输出0。
5)利用1.3.1节中的式(2)计算关节4(ShoulderLeft)和关节 7(HandLeft)、关 节 8(ShoulderRight)和 关 节 11(HandRight)、关节 29(ShoulderLeft)和关节 32(HandLeft)、关节33(ShoulderRight)和关节 36(HandRight)分别形成的向量与 Y 轴正方向形成的夹角 Ang8_11、Ang29_32、Ang33_36,来说明胳膊抬起的大致位置,判断任一角度是否大于某个阈值,若成立输出1,否则输出0。
6)利用1.3.2 节中的式(4)计算关节7(HandLeft)和关节29(ShoulderLeft) 、关 节 11(HandRight) 和 关 节 33(ShoulderRight)、关节 32(HandLeft)和关节 4(ShoulderLeft)、关节36(HandRight)和关节8(ShoulderRight)间的距离,分别记为:Dis7_29、Dis11_33、Dis32_4、Dis36_8,若任一距离小于某个阈值,则输出1,否则输出0。
7)计算关节 1(SpineMid)和关节26(SpineMid)在 X 轴上的 距 离 DisX1_26,再 计 算 关 节 11(HandRight)、关 节 36(HandRight)在 X 轴方向上和 DisX1_262 的距离差,若差值小于某个阈值则说明右手位于交互双方之间,输出1,否则输出0。
8)利用1.3.2 节中的式(4)计算关节11(HandRight)和关节36(HandRight)间的距离Dis11_36来表示交互双方右手之间的距离,若此距离小于某个阈值则输出1,否则输出0;然后在Dis11_36小于前者阈值的情况下,再次判断是否小于更小的某个阈值,若成立输出1,否则输出0。
综上所述,每帧提取的特征包含9 个特征,判断每一帧的上述特征条件是否成立,如果成立则为1,否则为0,这样就形成一个二值矩阵作为特征矩阵。
1.4 降维和分类
SBU 数据集的样本数量在平常的研究中属于小样本的数据。为了使实验结果更有说服力,本文采用“leave-one-out”方法来进行实验。“leave-one-out”方法也可叫“留一法”,该方法中使用的训练集比初始数据集少一个样本,这使得在leaveone-out方法中实际评估的模型与在大多数情况下预期要评估的数据集上训练出的模型非常相似。因此,留一法的评估结果往往被认为比较准确。
目前已存在多种应用广泛的降维算法和分类器模型,本文选取了几种常用、较流行的降维算法和分类器模型进行组合,并在SBU 数据集以及本文自建的数据集上进行实验。其中降维算法有:主成分分析(Principal Component Analysis,PCA)、奇异值分解(Singular Value Decomposition,SVD);分类算法有随机森林(Random Forest,RF)、SVM、长短期记忆(Long Short-Term Memory,LSTM)网络。
PCA 算法是一种线性降维方法,它的主要思想是将L 维度中的特征映射到k(k <L)维度。这k 维是一个新的正交特征,也称为主成分,是基于尺寸特征重建的k 维特征,即找到数据中最重要的方面,并用数据中最重要的方面替换原始数据。
SVD可以很容易地获得任何矩阵的满秩分解并使用满秩分解达到对数据进行降维压缩的目的[19]。降维处理的重要性取决于SVD 中奇异值的重要性,它是丢弃不重要特征向量的过程,而由剩余特征向量组成降维后的空间。
Bagging 算法是Bootstrap aggregating,其思想就是从总体样本当中随机取一部分样本进行训练,通过多次这样的操作,进行投票获取平均值作为结果输出,这就极大可能地避免了不好的样本数据,从而提高准确度[20]。而RF是基于树模型的Bagging 的优化版本。通过从原始训练样本集中随机选择w个样本,生成一个新的训练样本集,并根据自助样本集生成一个w 分类树,形成一个RF。新数据的分类结果取决于分类树形成的分数数量。
SVM 是线性分类器,其主要目的是在足够的空间中找到一个超平面以划分所有数据样本,并最大限度地减少数据集中所有数据与该超平面之间的距离。SVM最重要的方面是核函数的选取和参数的选择,这些可以通过实验识别率来选择。
LSTM 方法是在循环神经网络(Recurrent Neural Network,RNN)方法的基础上改进而来,引入一个新的状态单元Cell作为计算核心,解决了循环神经网络的梯度消失和梯度爆炸问题[21]。LSTM 的核心是门控制机制,包括输入门、输出门和遗忘门,这使LSTM 可以选择记住、忘记或更新历史信息,并且LSTM可以解决丢失RNN梯度的问题。
本文主要是使用Matlab 2016b 中的工具箱对数据进行降维和分类,故只简要介绍一下上文所提到算法的实现原理。为了减少录制数据时无法避免的骨骼遮挡和数据不稳定的影响,本文在降维和分类之前加入一个判断条件:如果二值矩阵的某个特征有间断的一个1或两个1存在,则把1置为0。
2 实验与结果分析
实验环境为 Inter Core i3-3217U,CPU@1.8 GHz,4 GB 内存,Windows 8 操作系统,Visual Studio 2015 和 Matlab 2016b。使用Kinect 采集并获取实验数据集,在获取人体骨骼的三维坐标后在Visual Studio 上编写程序对原始数据进行关键帧和特征的提取等处理,得到特征矩阵后把特征矩阵在Matlab 中利用降维和分类工具箱进行处理并得到识别结果。
降维算法和分类器模型的不同组合在SBU数据集以及本文自建的数据集上的实验结果对比如表1所示。
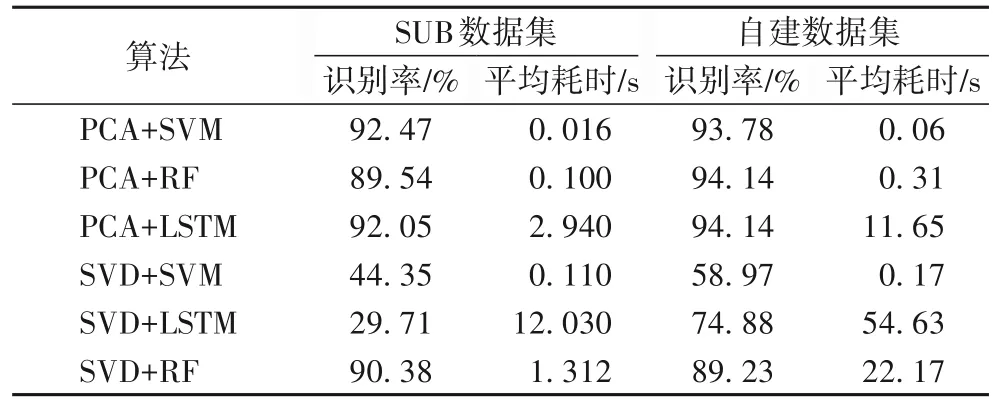
表1 不同算法组合在两个数据集上的实验结果对比Tab. 1 Experimental results comparison of various algorithm combinations on SBU dataset and self-built dataset
由表1 可知:PCA+SVM 的组合在SBU 数据集上识别率最高并且平均耗时最少,由此可知PCA+SVM 相比其他组合更适合于SBU 数据集;PCA+RF、PCA+LSTM 两个组合在本文自建数据集上识别率最高,但PCA+RF 平均耗时相对更少,在优先考虑识别率的情况下PCA+RF 更适合于自建的数据集。综述所述:对于上述两个数据集来说,降维算法PCA 比SVD 效果更好;对于降维算法,由于SVD 的维数多于PCA,所以SVD平均耗时更多;而对于不同的分类器模型,SVM平均耗时少于RF,RF 耗时少于LSTM,所以在各种算法组合中PCA+SVM 平均耗时是最少的。
2.1 SBU交互数据集实验
PCA+SVM 组合在SBU 数据集上的识别率结果如表2 所示。由表2 可以看出,由于交互动作的明显特征,踢人和拥抱以100%的正确率被识别出来,而靠近和远离动作受拥抱和递书前期的靠近动作以及完成后的分离动作的影响,使得部分动作的识别出现错误;而对于拳击和推人、握手和递书相似性很大,识别也有些困难。
将本文方法的识别率与现有算法的结果进行比较,具体如表3 所示。本文方法的识别率达到92.47%,其识别率分别比文献[14]、文献[19]、文献[12]和文献[10]中的方法提高了12.17、3.07、5.57 和1.35 个百分点。图4 给出了文献[14]、文献[19]、文献[10]中的方法和本文方法中每个动作类别详细的识别精度比较。与文献[10]中的方法相比,本文方法中拥抱、推人和拳击动作的识别率略高。相较于文献[19]中的方法,本文方法的最大优势在于拳打动作的识别。此外,除了远离和递书动作,其他动作识别的准确度均高于文献[14]中的方法。
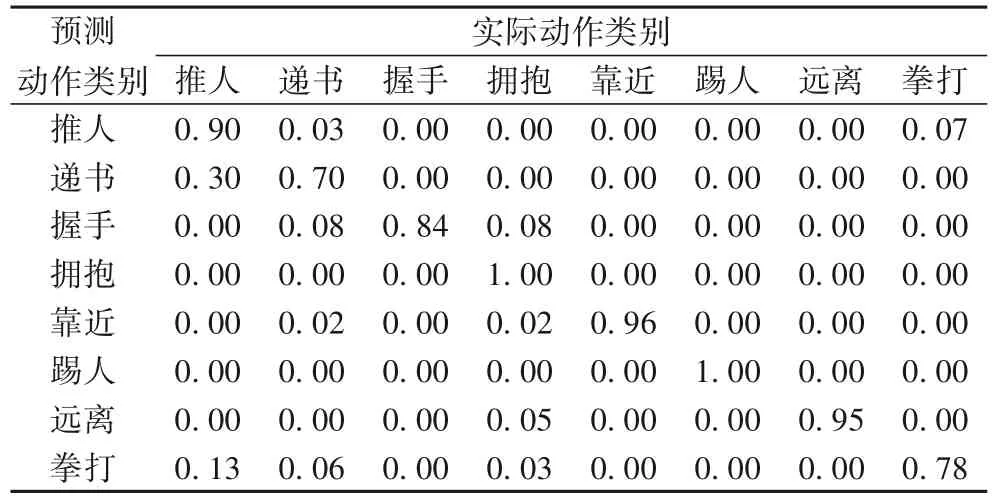
表2 PCA+SVM在SBU数据集上的识别率结果Tab. 2 Recognition rates of PCA+SVM on SBU dataset
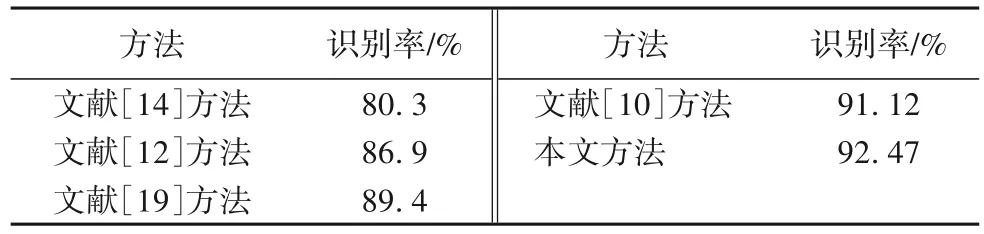
表3 SBU数据集上各方法的识别率对比Tab. 3 Recognition rates comparison of vairous algorithms on SBU dataset
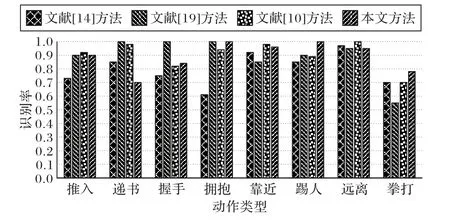
图4 SBU数据集上各个动作的识别率对比Fig. 4 Recognition rates comparison of different actions on SBU dataset
2.2 自建的数据集实验
利用PCA+SVM 组合对自建的数据集进行动作识别,识别结果如表4 所示。可以看出,交互类别中的识别率都超过了90%,并且有的达到了100%。其中拳打和推人动作相似性极高,难以区分使得二者的识别率最低,且错误中的绝大多数被识别为对方;而靠近和远离易受到其他动作的影响使得识别率难以达到100%。
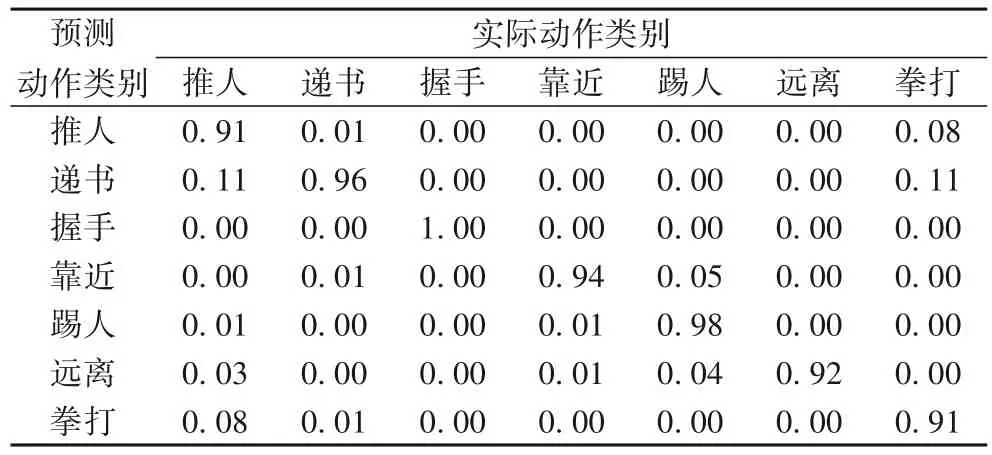
表4 PCA+SVM在自建数据集上的识别率结果Tab. 4 Recognition rates of PCA+SVM on self-built dataset
3 结语
针对双人交互行为识别应用领域广但效率低的问题,本文提出了一种基于关键姿势的双人交互行为识别方法。以往的研究多采用直方图来表示每一帧的姿势信息,导致空间信息的丢失;有些研究保留了姿势中的空间信息,但忽略时间信息[4]。而本文提取每个交互动作的关键姿势组合成特征矩阵,既保留了在空间尺度上的信息,同时也把时间尺度的信息包含在内。在SBU交互数据集和自建的交互数据集上评估本文的识别方法,识别率分别达到92.47%和94.14%。
本文自建了一个包含更多样本的新的双人交互数据集,数据集包含RGB 图像、深度图像和骨架关节。本文提出的基于关键姿势的识别算法得到的特征矩阵能够有效地表示不同的交互类别。SBU 交互数据集和本文收集的数据集的实验结果表明本文方法明显优于大多数文献中所提出的方法。
然而,双人交互行为识别时,骨架关节的遮挡问题一直存在,因此下一步工作主要集中在通过结合深度图像的信息来提取更有效的特征,以实现更多交互动作类别更准确的识别。
猜你喜欢
中老年保健(2021年5期)2021-12-02
中老年保健(2021年5期)2021-08-24
文苑(2020年5期)2020-06-16
小学生学习指导(低年级)(2020年3期)2020-06-02
学校教育研究(2017年30期)2017-08-13
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
少年科学(2009年12期)2009-07-07
