
面向煤矿的实体识别与关系抽取模型
2020-09-04 10:00张心怡冯仕民丁恩杰
计算机应用 2020年8期
张心怡 ,冯仕民 *,丁恩杰
(1. 矿山互联网应用技术国家地方联合工程实验室(中国矿业大学),江苏徐州221008;2. 中国矿业大学信息与控制工程学院,江苏徐州221008; 3. 中国矿业大学物联网(感知矿山)研究中心,江苏徐州221008)
0 引言
随着“互联网+”与“大数据”的发展,煤矿科学数据总量日趋庞大,煤矿安全的相关信息也爆炸式增多,这些离散存储的资料中包含着不安全事故发生原因、影响因素、响应措施、预防办法等重要信息。有效整合利用、充分挖掘这些具有专业性的资料与文献,可有效监督、把控、预防不安全事件的发生,在煤矿安全领域是十分迫切的安全需求。而传统仅靠人力手动提取、整合、管理信息已经远远无法满足目前信息抽取的需求。因此,设计模型自动抽取信息已成为目前煤炭行业的热点问题。其中,命名实体识别作为信息自动抽取任务的重要一环,对知识图谱的构建、本体的自动构建等下游任务有着重要意义。
目前,对命名实体识别的研究已有很多,但与通用领域相比,煤矿安全领域的资料由于包含煤矿地理信息以及大量专有名词,其信息抽取任务难点在于命名实体具有一词多义或多次同义的现象,并且不同的命名实体间存在一定语义关系,这些语义关系对实体识别有很大影响,应被充分利用。由此,煤矿安全领域的命名实体识别任务依然有很大改进空间。
本文主要针对命名实体的语义多样性、结构嵌套、长度较长的问题来设计模型,另外,为充分利用实体间关系对实体识别的影响信息,提出同时进行命名实体识别与关系抽取的联合学习模型。本文主要工作如下:
1)提出了一种新的词嵌入方法。使用多种向量模型对输入进行映射,以解决一词多义问题并提升低频词表示的准确性。
2)提出了一种端到端的联合学习模型。该模型将命名实体识别与关系抽取以统一标注的方式视为一个统一的任务,使用本文提出的深层注意力网络同时完成,从而关注到实体间关系对实体识别的影响信息。
3)提出了两种模型的加强方案:一种方案是在注意力机制中嵌套双向长短期记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)模型,以牺牲时间来提升精度;另一种方案是将卷积网络与注意力机制相结合,从而在保证学习速度的前提下同时关注整体特征与局部特征。
4)提出了在序列标注任务中省略解码结构。通过对比实验得出深层网络足以学习时序特征,无需对标签解码也可得到准确率较高的标注结果,解码结构的省略减少了模型的训练时间,提高了对未标注词、低频词的识别准确率。
实验结果表明,本文模型不仅对煤矿安全领域的命名实体识别有较好的识别效果,对关系抽取的效果也有了提升。同时,并行化与编码层的省略,提高了模型的训练速度。
1 相关工作
传统的命名实体识别方法主要是基于规则的方法与基于机器学习的方法。其中基于规则的方法对专家及规则库的要求严格,难以迁移,因此,基于机器学习的方法逐渐流行。张海楠等[1]提出将命名实体识别的任务看作是序列标注任务,从而根据标签确定实体的边界与类型。Bikel等[2]提出隐马尔可夫模型,张玥杰等[3]、Artalejo 等[4]将最大熵引入马尔可夫模型,Song 等[5]提出条件随机场(Conditional Random Field,CRF)模型等,以上方法全都旨在使用状态转移矩阵来表示标签与文本的依赖关系,从而更为科学与灵活地识别出实体的边界与类别,但需研究者手动提取文本特征并设定特征模板,模型的泛化性较差。同时,针对中文语料,以上方法不可避免地需要基于分词技术的结果来完成实体的识别,而矿山领域知识体系复杂,现有的分词算法对该特定领域的语料分词效果较差。
为避免手工构建并选择特征的繁琐以及分词对实体识别任务的影响,基于字的深度学习方法逐渐成为命名实体识别领域关注的热点。Lu等[6]将文本表示成字符级的分布式形式送入深度学习模型进行实体识别;Dong 等[7]使用字级别的网络结构对实体进行识别;王博冉等[8]将字级模型与词表匹配信息相结合,提出了Lattice LSTM 模型,取得了很好的效果。然而煤矿领域的专业术语存在嵌套情况,长度较长,仅通过字符级的单一网络忽略了词语级的语义信息,且难以学习语句间的依赖关系。不少学者针对这一问题提出了编码-解码系列模型,加入标签间的依赖特征以提高识别性能。如柏兵等[9]提出结合Bi-LSTM 与CRF 的识别方法,在人民日报1998 年语料上取得了很好的效果;李明扬等[10]在 Bi-LSTM 与 CRF 模型的基础上引入自注意力机制,丰富了文本特征,在命名实体识别微博语料库中达到了58.76%的成绩;谷歌团队[11]提出使用单纯的注意力机制网络完成实体识别等任务。以上方法在一定程度上提高了实体识别的准确率,但解码结构的引入带来了时间上的耗费,同时也增强了模型对标签的依赖,而矿山领域知识语义多样,使用该结构的实体识别模型会导致对低频词、未标注词的识别效果不明显等问题,也忽略了实体间关系对实体识别的影响作用。综上所述,针对矿山领域术语的识别,一方面需要充分提取文本信息,减少模型对标签的依赖,避免嵌套术语、未标注术语等无法识别的问题;另一方面可通过弥补实体间关系对实体识别的影响,来提升实体识别效果。
对此,本文提出了联合学习实体及实体间关系的深度注意力模型,旨在重点关注文本信息,同时探究解码结构对时序标注效果的影响,并对二者间的相关性信息进行关注以提升煤矿领域术语的识别效果。
2 实体识别与关系抽取模型
2.1 数据标注策略
本文将联合学习任务看作序列化标注任务进行端到端的直接抽取,即给定一个句子,联合学习的目标是识别句子中的所有实体及关系,并对其进行语义分类。本文采用与文献[12]中相同的标注策略。例如,对句子:“河北海岷工矿集团有限公司坐落于全国标准件集散地河北-邯郸。”,产生如图1所示标注。其中,“河北海岷工矿集团有限公司”与“河北-邯郸”为相同的关系类“属于(SY)”,且标签为“1”代表关系中的主语,标签为“2”代表关系中的宾语。由此可使用关系将两个实体进行连接,从而得到最终的三元组结果。
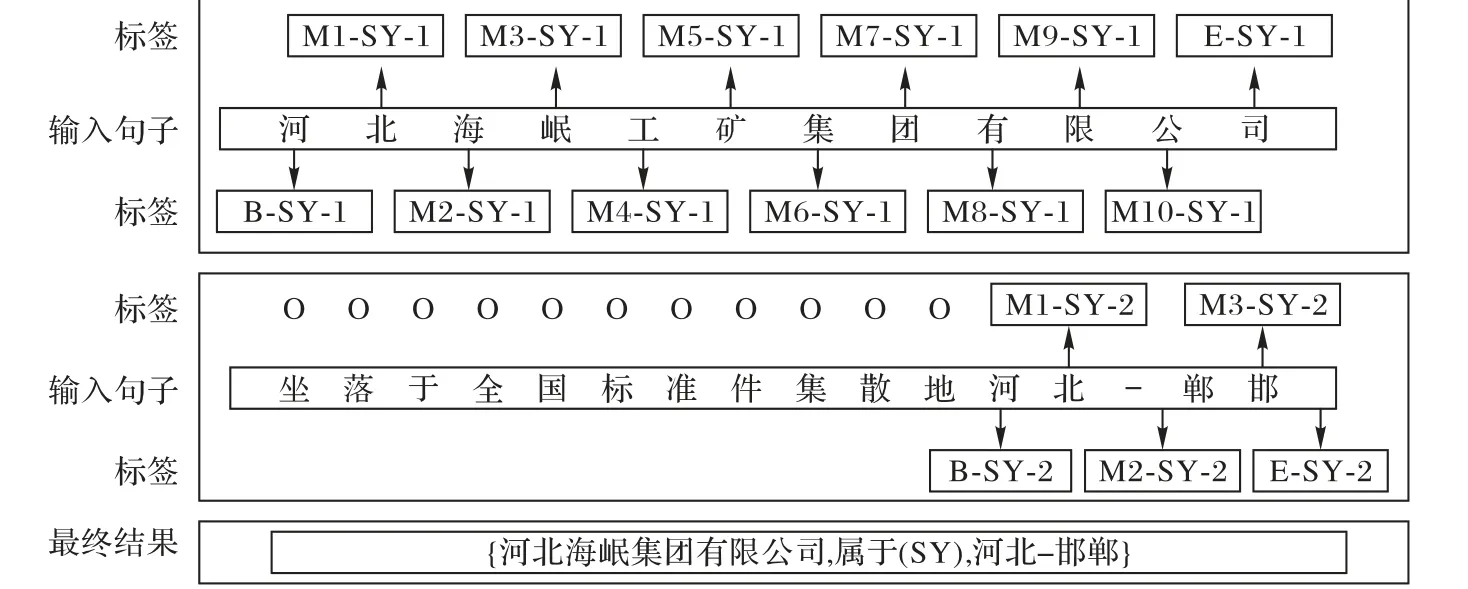
图1 标注策略Fig. 1 Annotation strategy
2.2 模型框架
本文的联合学习模型框架主要分为三个模块,模型整体框架如图2 所示。训练过程分别由文本数据预处理模块、投影模块、特征提取模块以及分类模块构成。
首先,将原始话语投影到实值向量中,再将其输送至下一层;然后,设计了一个深层的多头自注意力神经网络,该神经网络将嵌入矩阵作为输入,以捕获句子的嵌套结构以及标签之间的依存关系;最后,使用分类层对实体及其关系进行分类。
模型的推理方法为端到端的直接推理,即仅将句子经过预处理送入模型后便可得到实体及其关系的序列标注。
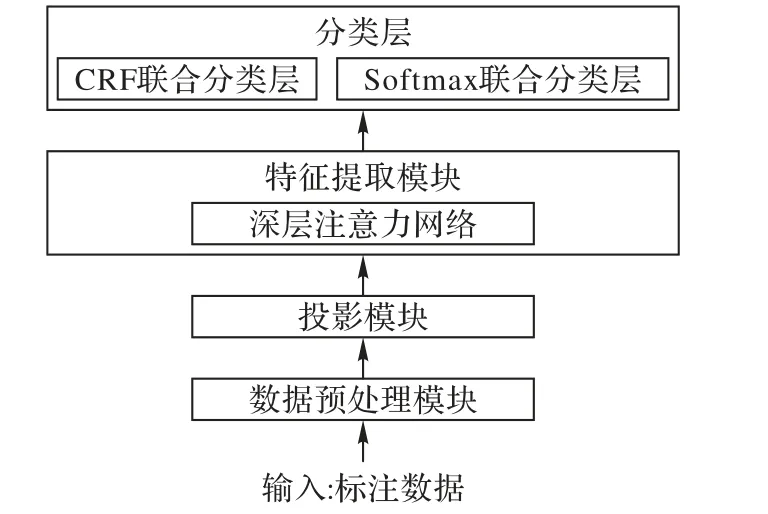
图2 基于深度注意力的联合学习模型框架Fig. 2 Framework of joint learning model based on deep attention
2.3 模型组件
2.3.1 数据预处理模块
由于本文模型为实体及其关系的联合抽取模型,需对句子中的实体及其关系进行同时关注,为避免句子中实体过多对模型带来的干扰,本文在模型训练前对语料进行以下处理:
1)对于以顿号连接的相似实体,生成随机数x,仅保留第x个实体,从而减少句子冗余性。
2)分词:采用jieba分词软件对文本进行分词处理。
2.3.2 投影模块
投影模块的整体框架如图3所示。
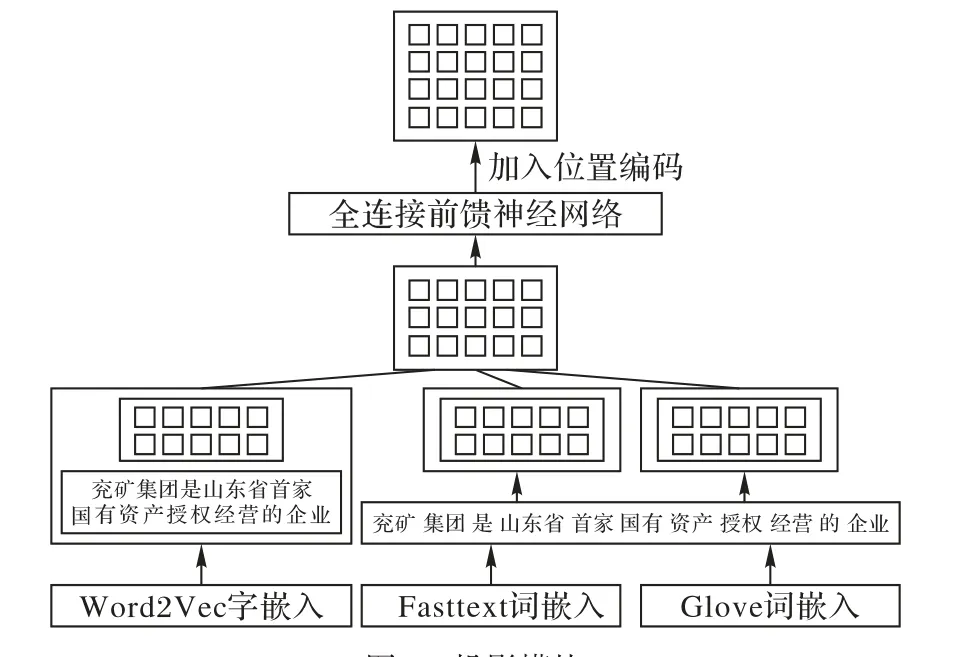
图3 投影模块Fig. 3 projection module
为丰富句子的语义信息,本文使用三种分布式模型为输入语句进行编码,具体如下:
1)使用词向量(Word to Vector,Word2Vec)[13]对字向量与词向量进行联合训练。为提升低频词表示的准确率,将更细粒度的字向量引入词表示中,与词向量一同使用连续词袋(Continuous Bag-Of-Words,CBOW)模型联合训练出新的词表示模型。词向量与字向量的组合方式如图4所示。
CBOW的改进公式如下:

其中:N为文本中的中文数量;cjk为字编码;系数保证了字向量与词向量计算词语距离的一致性。并且,为了简化模型,仅对上下文部分引入字向量信息,即最终的target信息是由字向量与词向量的组合信息预测得到。

图4 基于CBOW的字词嵌入模型Fig. 4 Word embedding model based on CBOW
2)使用Fasttext[14]训练词向量。为学习词级的上下文信息及句子结构信息,使用Fasttext训练词向量。
3)使 用 全 局 词 向 量(Global vectors for word representation,Glove)[15]训练词。为学习词间共现信息,使用Glove对词进行分布式学习。
4)提取相对位置信息。本文使用注意力机制对特征进行提取,而注意力机制本身无法区分不同的位置特征,因此本文加入每一个字的位置编码信息。
将前三部分向量进行串联,生成新的投影向量作为下一模块的输入。为避免由于信息重复抽取导致的数据偏移,进行以下操作:
1)在拼接好的向量后加入全连接层。主要思想是引入一个权重矩阵,对输入进行降维。
2)在全连接层后加入Dropout 层。Dropout 层类似于Bagging 的轻量级版,主要思想是以一定概率临时扔掉一些神经元节点,从而使得每次都在训练不同结构的网络。
2.3.3 特征提取模块
特征提取模块旨在设计网络模型,学习输入语料的嵌套结构及与标签间的潜在依存关系,模型结构如图5所示。
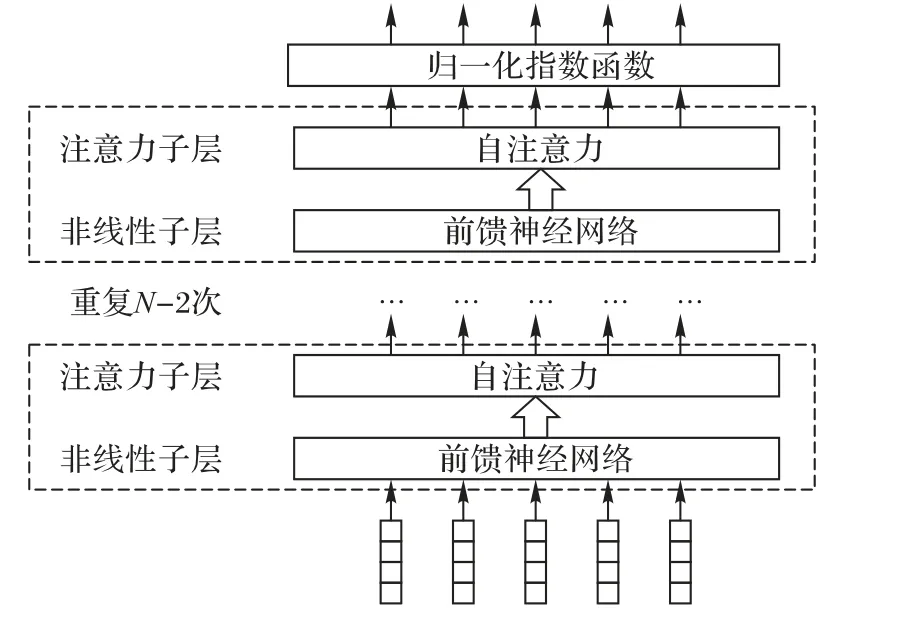
图5 基于深度注意力的特征提取模块Fig. 5 Feature extraction module based on deep attention
原始模型使用深度注意力机制对实体与实体间关系进行联合学习。相较于传统联合学习方案,本文方案无需对样本与标签特征进行编码与解码的单独学习,而是使用深层网络学习文本特征,使用最大似然得到序列的标签。该模型具体细节如下:
1)自注意力机制。自注意力是注意力机制的一种特殊情况,其输入为一个单独的分布式序列,即在没有任何额外信息的情况下,仍可从句子中获取需要关注的信息。自注意力机制已经在机器翻译、文本表示等自然语言处理任务中被成功使用。其计算公式如下:

首先计算当前隐态与之前隐态的匹配度得分,作为当前隐藏单元的注意力得分;其次将得分通过归一化映射转换成概率值;最后对当前状态以前的所有隐藏状态加权求和。
2)多头注意力机制。若只计算一个注意力得分,则难以捕捉到输入句子中所有空间的信息,因此,Vaswani 等[11]提出多头注意力机制。多头注意力机制是点乘注意力的堆叠版,其基本思想是将输入线性投影到不同空间h 次,每一次分别做点乘注意力计算。本文使用的多头注意力机制基于自注意力机制之上,详细过程如图6 所示:首先将输入矩阵X 映射为K、Q、V 三个矩阵,再分别对K、Q、V 三个矩阵做h 个不同的线性变化;然后将线性变化后的结果输入至自注意力机制,并行产生h 个不同的注意力得分;最后将h 个得分进行拼接,并使用线性映射融合三个矩阵通道,得到输出矩阵Y。
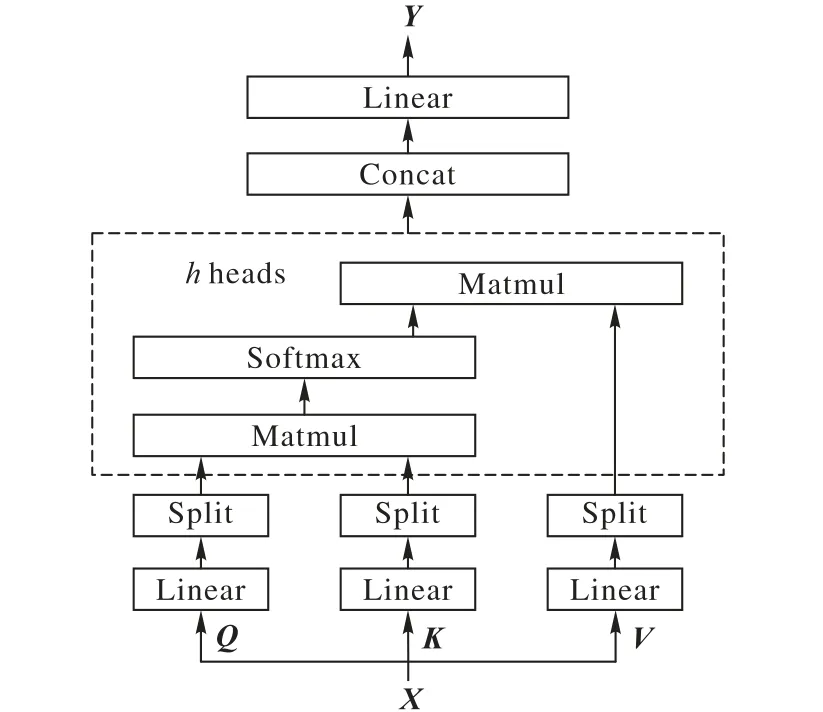
图6 多头注意力模型Fig. 6 Multi-head attention model
3)非线性映射层。非线性映射层是避免多层网络等同于单层线性网络的重要步骤。由于注意力机制使用加权和来生成输出向量,其表示能力受到了一定限制。对此,需要采用非线性子层对底层输入进行非线性映射。在原始模型中,使用类似于多层感知机的全连接层作为非线性映射层。
4)残差机制。在误差反向传播时,由第L 层传播至输入的第一层的过程中,会有很多参数与导数的连乘计算,从而会导致梯度的消失或者膨胀。对此,He等[16]借鉴了高速公路网络跨层连接的思想,将原本带权重的残差项改为恒等映射,即将某一层的输出直接短接到两层之后,而跳过的两层只需拟合上层输出和目标之间的残差即可。计算式如下:

若本层网络学习到的预测值和观测值之间的差距较小(或下层误变大时),则下个学习目标是恒等映射的学习,即使输入X近似于H(X),从而保持模型精度不会下降。
本文的改进模型1 是在原始模型的基础上将双向长短时记忆网络嵌入于自注意力机制中,以更好地提取文本与标签的时序特征。改进的具体细节如下:
1)基于双向 LSTM 的注意力层。Jozifowicz 等[17]提出双向LSTM,是前向LSTM 与反向LSTM 结果的拼接,可有效利用文本序列的上下文信息。将注意力机制与双向LSTM 进行结合,可有效克服注意力机制在时序特征提取方面的不足。基于LSTM的注意力层的相关计算公式如下:
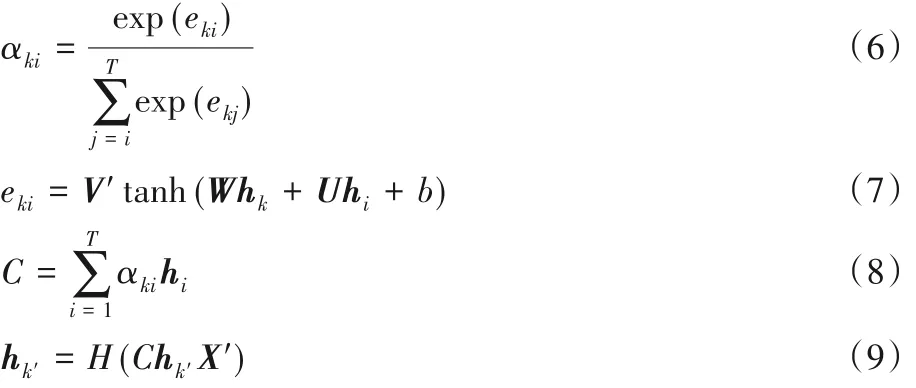
其中:T为输入序列的长度;eki为第i个节点对第k个节点的注意力得分;αki即为第i 个节点对第k 个节点的注意力权重;hi为前向隐层序列的第i个向量;hk为反向隐层序列的第k 个向量;C 为语义编码;hk′则为最终的特征向量,最终提取的特征向量对关键词分配了较多注意力,特征提取有效突出了关键词的作用。
2)非线性映射层。该部分的前馈子层由线性整流函数(Rectified Linear Unit,ReLU)连接的两个线性层组成,计算公式如下:

其中,W1∈Rd*hf与W2∈Rhf*d是可训练的权重矩阵。使用残差机制对LSTM 的改进如下:在双向LSTM 中使用残差机制,有选择地对隐层进行更新,从而提高训练速度。
本文的改进模型2 则在原始模型的基础上将注意力机制引入卷积模型中,从而在提取更多信息的基础上,更好地加速模型训练。具体细节如下:
1)加入CNN 的注意力层。对于卷积层,本文使用门控线性单元(Gated Linear Unit,GLU)。与标准卷积神经网络相比,GLU更易于学习,并且在语言建模和及其翻译的任务上取得了较好的效果。GLU的输出激活计算如下:

并且分别在卷积网络之前的输入层和池化层使用注意力机制,使整个网络不仅能关注整体信息还能关注到局部信息。
2)非线性映射层。该部分的前馈子层仍由ReLU 连接的两个线性层组成。
2.3.4 分类模块
由于语义标签之间存在依赖性,传统的大多数网络使用解码层学习标签间的顺序关系。本文所设计的网络结构将文本与标签一同作为网络输入进行特征提取,为探究深度模型对依赖特征学习的性能,在分类模块中分别使用CRF 层与Softmax层对实体进行分类,具体算法如下。
1)使用CRF 作为分类层。CRF 层以路径为单位,考虑路径概率,其原始目标函数如下:

为简化该目标函数做了两个假设:首先假设该条件概率为指数分布;其次,假设输出间的关联仅发生在相邻两个位置上。最终,其目标函数如下:
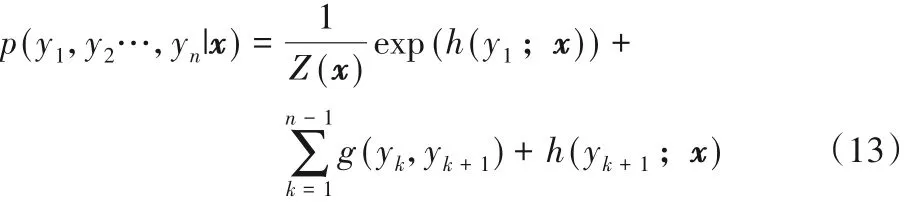
对 于 输 入 序 列 为x=(x1,x2,…,xn),标 签 序 列 为y={y1,y2,…,yn}的训练集,使用最大似然法对目标函数求解参数值。预测阶段,CRF 模型根据深度注意力网络的最后一层产生的隐藏状态预测相应的标签。
2)使用Softmax 作为分类层。模型训练阶段,对于给定的输入x=(x1,x2,…,xn),相应的标签序列y={y1,y2,…,yn}的似然函数为:
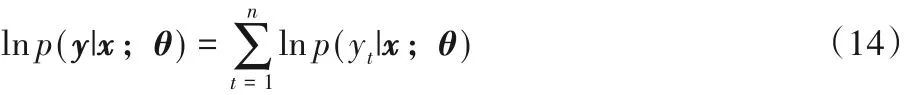
预测阶段,Softmax 模型根据深度注意力网络的最高关注子层产生的隐层表示预测相应的标签,计算式如下:
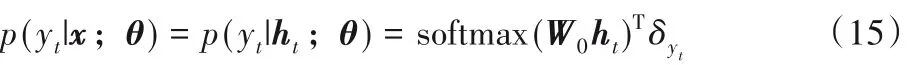
3 实验与结果分析
本文的语料库以众源数据库(OpenStreetMap,OSM)和中国矿业大学测绘学院收集的地理实体作为基础地名,通过爬取百度百科、维基百科及各种煤矿安全相关文献的正文及简介,清洗并标定了实体及关系的数据集合。训练集包含8 233 425 个句子,其中包含23 个可能的关系及1 个不相关负例,实体对921 876 个,关系事实425 871 个;测试集包含2 254 162个句子,其中实体对116 781个,关系事实34 565个。
3.1 模型设置及评价标准
3.1.1 模型初始化
针对原始模型,设置模型所有子层的初始权重为一个随机的正交矩阵。设置其他参数的初始值为基于(0,1d)高斯分布的随机采样,其中d为隐层单元数。嵌入层的初始权重设置为预训练模型的权重。设置所有Dropout 层参数为0.8,即以0.8 的概率对神经元进行保留。设置隐层个数为15,隐层单元数为200。设置多头自注意力机制的head 数为8,使用人工手动调参。
3.1.2 学习参数设置
使 用 Adam(ε= 106,ρ= 0.95)作 为 随 机 梯 度 下 降(Stochastic Gradient Descent ,SGD)的优化算法,即设置初始学习率为1.0,使用梯度的一阶矩和二阶矩动态调整学习率,从而使梯度的下降较为平稳。同时为避免梯度爆炸,将梯度范数剪裁为1.0。
3.1.3 评估标准
本文使用F1-score(F1)作为评价指标对命名实体识别与实体关系抽取的效果进行评估。F1的计算公式如下:


其中:P表示精确度;R表示召回率;TP表示测试集中的正例被正确预测为正例的个数;FP表示测试集中的正例被误分类为负例的个数;FN表示测试集中的负例被误分类为正例的个数。
3.2 结果分析
3.2.1 模型深度对结果的影响分析
如表1 所示,本文研究了模型深度对序列标注效果的影响。可以看到,在层数为4,词嵌入模型为Glove 时,F1 仅为73.2%。因此本文对网络层数进行不断叠加,经实验可得,10层的网络表现接近最佳,并且在12 层可以看到F1 的提升不再明显,因此网络深度最佳值为10。
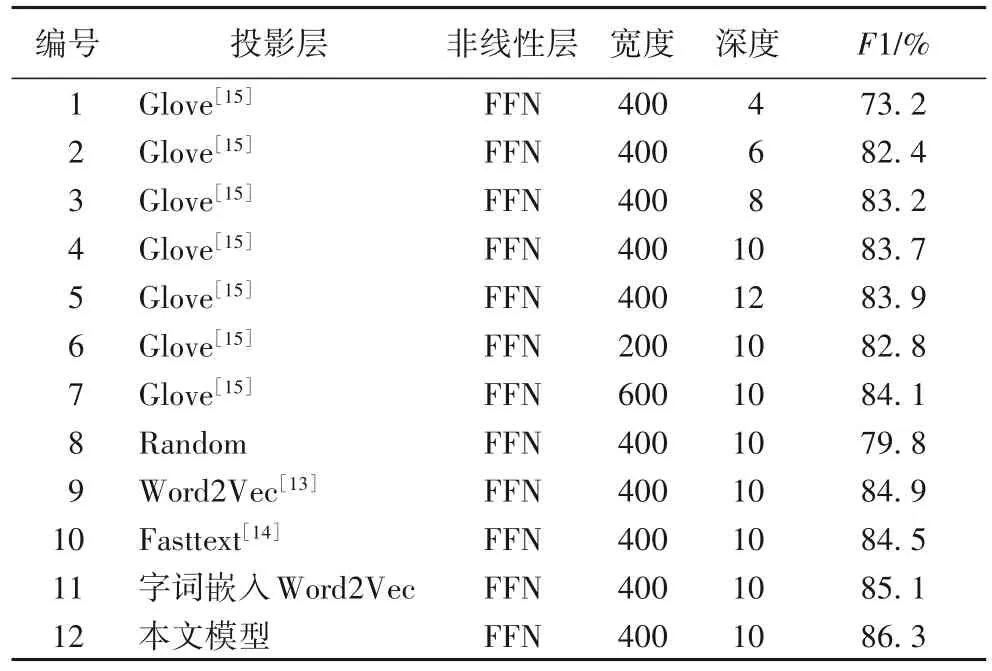
表1 模型参数实验对比结果Tab. 1 Experimental comparison results of model parameters
3.2.2 模型宽度对结果的影响分析
同样,针对网络隐藏单元的个数对标注效果的影响,本文也设计了探究实验,实验结果见表1。可以看到,在隐藏单元数为400时F1达到了83.7%,本文模型表现接近最好,再继续加宽网络,模型的提升并不明显,反而还增加了需要承担的训练时间成本,因此网络宽度最佳值为400。
3.2.3 投影层对结果的影响分析
Gormley等[18]研究表明,可以通过对未标记的词嵌入进行预训练来提高下游任务的性能。本文使用多种词嵌入对网络进行初始化,其中:Glove 为利用了全局信息的词嵌入模型;Word2Vec 为浅层的词嵌入模型;Fasttext 在Word2Vec 基础上增加了多元语法等信息;Random 为随机初始化的词分布式表示。将以上词嵌入方法与本文提出的词嵌入方法进行对比,实验结果见表1。可以看到,使用一种预训练词嵌入模型的最佳效果比不使用词嵌入模型的F1 最高增加了5.3 个百分点,而使用本文嵌入方法相较最好的单一词嵌入方法的F1又增加了1.2个百分点。
3.2.4 分类层对结果的影响分析
为提取标签之间的依赖关系,传统模型普遍采取解码层提取标签间的依存关系,但解码层会大大降低模型的学习速度,因此,本文对深度网络中的解码层设计实验进行探究,结果如表2 所示。可以看到,与Softmax 使用最大似然原理的分类层相比,在深度网络中使用解码层的模型性能反而下降。由此说明,深度网络对特征的学习能力已经足够强大,无需特定的解码层就可捕获标签间的依赖关系。

表2 分类层对模型的影响Tab. 2 Influence of classification layer on model
3.2.5 与其他模型的对比分析
将本文模型与经典的实体识别与关系抽取模型在本文数据集上进行了如表3 所示的对比实验。其中多特征组合嵌入模型(Feature-Rich Compositional Embedding Models,FCM)[18]与 LINE(Large-scale Information Network Embedding)[19]为基于串行结构的实体识别与关系抽取模型:FCM 将文本表示与词向量表示进行融合,然后分步进行实体识别与关系抽取;LINE 则是基于网络的嵌套方法分步抽取实体及实体间关系。由实验结果可以看到,联合学习两项任务相较于串行学习效果更好。多实例联合抽取(Multi-instance Relation extraction,MultiR)模型[20]与增量集束搜索算法和结构化感知器的联合抽取算法 DS-Joint[21]为联合学习模型,其中:MultiR 针对远程监督的噪声问题提出了多实例的联合学习方法;DS-Joint则在标注数据集中使用结构感知器对实体与实体关系进行联合抽取。可以看出,与经典浅层联合模型相比,本文模型的F1 有了近 5 个百分点的提升。LSTM-CRF[12]与 LSTM-LSTM[12]是序列标注任务中的经典模型;LSTM-SA-LSTM-Bias[12]则将注意力机制引入LSTM-LSTM,在准确率上达到了更好的效果。与序列标注领域常用的经典编码解码模型相比,本文方案也有了一定提升;而相较于编码-解码结构的前沿模型Transformer[11],本文提出的联合深度注意力网络Joint-DeepAttention 的F1高出了1.5个百分点。上述实验结果验证了本文模型的有效性。
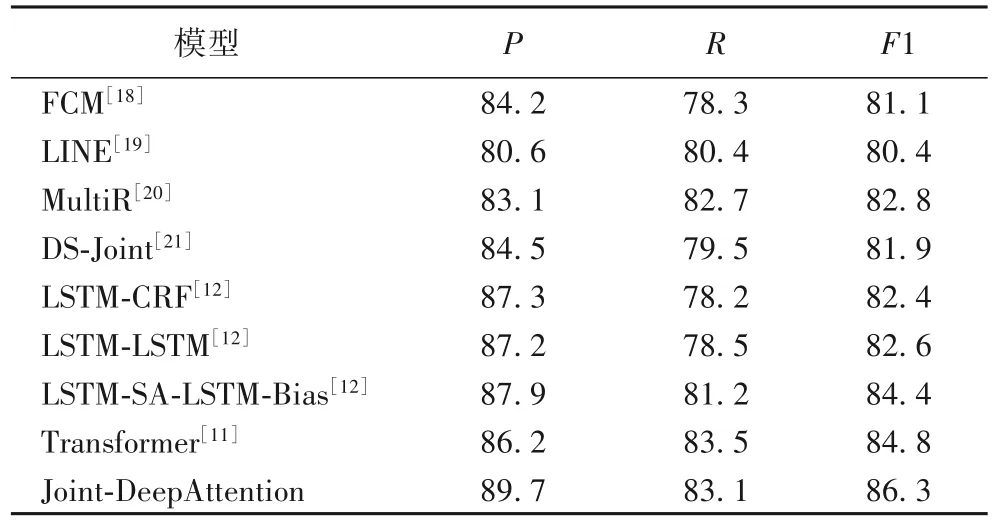
表3 本文模型与传统抽取方法的实验结果对比 单位:%Tab. 3 Comparison of experimental results between the proposed model and traditional extraction methods unit:%
3.2.6 探究模型有效性
在煤矿安全领域数据集上抽取四种主要的实体类型进行模型性能的测试,实验结果如表4所示。表4中:PER为人名,ORG 为组织结构名,LOC 为区域名,EQU 为煤矿设备名。可以看到,识别效果较好的实体类型为人名,区域名、组织机构名与设备名由于类型多变、语义丰富,F1得分相对较低,但相较于人名长度短、位置单一的识别优势,其识别效果的差距可以接受。
同样对四种关系类型进行抽取,完成模型性能的测试,实验结果如表5所示。表5中:SY 为地理从属关系;JZ为人与机构间的从属关系;SS 为实施者与被实施者的关系,如“运输工超速驾驶机车”中运输工与机车间的关系;ZW为职务关系,为机构内部人与人的关系。可以看出,由于在煤矿安全领域语料加入地理语料,施事关系与地理从属关系频繁出现,且由于实体特征较明显,识别效果较好。
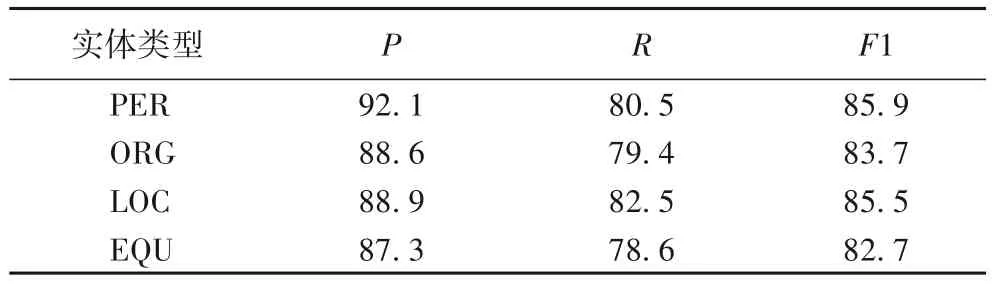
表4 实体识别结果 单位:%Tab. 4 Entity recognition results unit:%
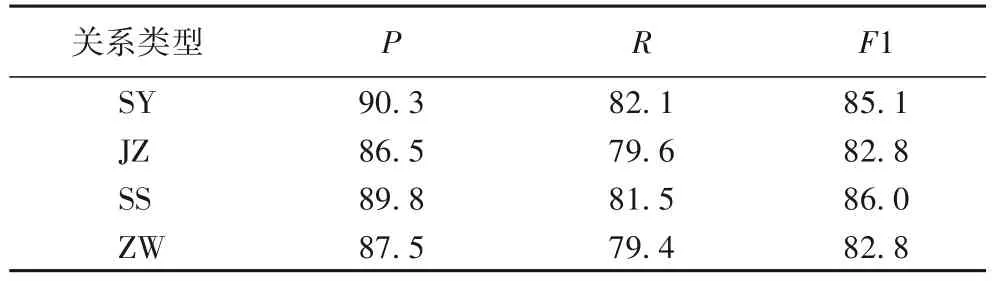
表5 关系抽取结果 单位:%Tab. 5 Relation extraction results unit:%
4 结语
本文针对矿山领域知识具有的语义丰富等特点,提出了一种端到端的联合学习实体及其关系的深度注意力模型,该模型与词向量融合模型进行结合,并通过实验验证了结合不同词向量的联合学习模型可丰富词的表达、增加任务间的交互特征,同时可提高实体抽取和实体关系抽取两个任务的准确率。另一方面,探寻了解码模块在深度网络中的作用,证明了解码模块在基于深度网络的序列标注任务中可被省略从而提升模型训练速度。最后,本文提出了两种模型增强方法,用户可根据对模型的精度与速度的平衡进行模型增强方向的选择。
下一步工作将在已提取的实体及实体间关系的三元组基础上,形成本体化的知识表达,同时结合知识融合与知识加工技术,形成面向矿井安全领域的结构化语义知识库,从而通过聚合大量知识的方式实现矿井安全领域知识的快速响应与推理。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
南方周末(2019-12-19)2019-12-19
中国外汇(2019年19期)2019-11-26
南方周末(2019-07-18)2019-07-18
南方周末(2019-05-09)2019-05-09
海峡姐妹(2018年3期)2018-05-09
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
Coco薇(2015年11期)2015-11-09
