
卷积神经网络的优化在车牌号识别上的运用
2020-09-03 00:57:44刘永雪李海明
上海电力大学学报 2020年4期
刘永雪, 李海明
(上海电力大学 计算机科学与技术学院, 上海 200090)
在车牌号识别模型中,传统的神经网络模型输入层的每一个神经元代表一个车牌号图片中提取出的像素值。但这种模型用于车牌号识别存在若干问题,一是每相邻两层的神经元都是全相连,产生大量参数,使模型训练时间受到限制;二是堆叠更多的层次导致训练时间指数倍增长,训练效果受到限制。尤其是汽车车牌号的位置受外界环境因素影响较大,因此传统的神经网络已不能有效解决以上这些问题。这就需要运用卷积神经网络(Convolutional Neural Network,CNN)来操作。CNN使用了共享卷积核,可以毫无压力地处理高维数据,快速训练,使得采用多层神经网络变得容易,从而提高识别准确率。
在图像识别领域的每一个重大突破无一不是用到了CNN。CNN可以直接将图像数据作为输入,不仅无需人工对图像进行预处理和额外的特征提取等复杂操作,而且以其特有的端到端的特征提取方式,避免了图像变形产生的特征提取不够精确等问题[1]。
但是CNN也存在一些缺点,比如训练时间长或者模型准确率不够高的问题,采用梯度下降算法很容易使训练结果收敛于局部最小值而非全局最小值,池化层可能丢失大量有价值的信息,从而忽略局部与整体之间的关联性。为了使CNN更适用于实际应用,使用分层生成模型来处理高维图像以达到较高的准确率[2]。卷积是神经网络的核心计算之一,其计算复杂,模型运行大部分时间都耗费在卷积过程中,因此优化卷积计算来改进模型具有可行性。
本文通过改进的CNN搭建框架,利用采集的有效数据集经过充分的训练得出高效的识别模型,并经过测试识别给出的车牌号图片。
1 车牌号识别CNN模型
1.1 模型结构
与传统神经网络相比,CNN除了输入层和输出层,其隐层中又包含多个卷积层和子采样层。CNN模型结构如图1所示。
图1中CNN的输入层是原始输入图像,在车牌号识别模型中即车牌号图像,CNN能够自动处理并提取图像特征,完全不需要手动输入车牌号图像的提取特征。其卷积层C1中包含若干卷积核分别对输入车牌号图像进行处理,生成对应的卷积特征图,之后进行综合操作,得到全部的特征。采样层S2对卷积层C1 中的卷积特征图进行局部特征提取,生成相应的子采样特征图。卷积层C3 和 采样层S4 重复 C1 和 S2 的动作。CNN模型的隐层一直重复这样的结构,使用“卷积 + 采样” 的结构进行特征提取,压缩数据和参数的数量,增加生成特征图的数量,更高层次对局部进行操作,得到全局的特征信息。最后得到的特征图片全部展开构成全连接层,全连接层与输出层(即分类器)采用全连接的方式得到最后的识别到的车辆信息。
本文采用的实验方法是把车牌号的图片经过图像定位分割处理,分为相关省份简称、城市代码和编号3部分,并分别建立模型进行训练,最后测试该模型的识别准确率。
1.2 卷积层
人脑识别图片的过程,并不是一步将整张图片同时识别,而是对图片中的每一个特征进行局部感知。CNN模型与人脑识别图片类似,每个卷积核对应一个感受野,每个神经元只感受局部的图像区域。即输入项的局部子矩阵与局部过滤器做运算,输出结果为卷积输出矩阵的对应维数。在CNN结构中,不仅卷积核个数对识别精度有影响,卷积核大小的设置也很关键,而激活函数的选取更是决定了算法的时间效率[3]。为了得到更好的数据表现形式,卷积层往往有多个局部过滤器来形成多个输出矩阵,运算过程如下
(1)
式中:l——建立模型的层数;
f——选取的激活函数;
Mk——l-1层的第k个特征图;
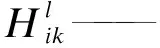

理论上,卷积核越小,提取得到的特征越精细。但是,卷积核太小也是不好的,只有使用很多卷积核的模型性能才会得到提升。另外,由于实际采集到的车牌号图像会因为腐蚀或者生锈产生噪声污染,如果卷积核的设置过小,很容易提取到一些无用有干扰的特征信息[4]。
1.3 池化层
CNN模型的池化层也称下采样层,是进一步缩小特征维数,同时减小过拟合和提高容错性的过程。池化层可以通过最大池化或者平均池化的方法来构造。上层卷积层的信息作为池化层的输入信息,池化后的输出结果又成为输入信息传给下一层卷积层[5]。
假设输入的车牌号特征图为矩阵F,池化层采样的池化域为c×c的矩阵P,偏置为b2,得到的子采样特征图为S,池化过程中的移动步长为c。平均池化方法采用局部求均值的方法进行降维,运算过程如下
(2)
最大池化法的运算过程如下
(3)

2 CNN在车牌号图像特征提取中的优化
2.1 网络结构扩展
传统卷积神经网络是直接将灰度图像作为原始数据输入,只需要单通道便可在网络中进行训练和识别。HE S F等人[6]提出一种针对彩色图像的3通道输入的方案,即先对输入图像进行多尺度超像素分割,得到3个通道的输入序列,每个通道参数可以不同,然后将 3个通道的信息输入CNN进行训练,原始图片与卷积核中通道个数相等,最后输出图像的信道数取决于卷积核的个数。
2.2 卷积核选取
传统神经网络没有明确限制卷积核的大小和数量,而是采用迭代算法训练整个模型,随机设定初值,计算当前的输出,采用随机梯度下降法去改变前面各层的参数,直到网络收敛。BP算法作为传统多层神经网络的典型算法,容易造成模型收敛到局部最优值而非全局最优。有研究者在通过CNN进行图像识别时,提出将卷积核改进到加权 PCA 矩阵的形式,采用双层卷积网络结构,即先对图像分块,之后将每小块进行映射,映射结果都进行码本聚合,产生最终特征向量[7]。汽车在经过长时间的使用后,车牌号所在的钢板会受到不同程度的损害,车辆识别码也会有不同程度的腐蚀,图片质量受到影响,所以这种方法同样也可以应用到车牌号的识别中,阴天晴天、室内室外同样可以取得良好的特征提取。
2.3 激活函数改进
CNN的关键部分之一是激活函数的选取。激活函数是在神经元上运行的非线性函数,将输入映射到输出端,使神经网络可以任意逼近非线性函数,从而应用到众多的非线性模型中[8]。常见的激活函数有 sigmoid 函数和tanh函数。sigmoid 函数在梯度反向传导时发生梯度消失的概率比较大,tanh函数解决了sigmoid 函数不是零输出问题,但是梯度消失和幂运算的问题仍然存在。稀疏性越大,提取出来的特征就越具有代表性。纠正线性单元(Rectified Linear Units,ReLU)函数增大了网络的稀疏性,具体运算方式如下
h(i)=max(w(i)Tx,0)=
(4)
其原理是当卷积计算的值小于零时,输出函数值等于零;否则输出值保持原来的值不变。ReLU函数是一种直接强制某些数据为零的方法,输出为零时,训练完成后为零的神经元越多,稀疏越大,泛化能力越强,无梯度耗散问题,收敛速度较快,但同时也可能造成很多无用的神经元[8]。
2.4 池化模型的改进
池化层最常见的两种方法是平均池化法和最大池化法。这两种方法都不能很好地提取池化域的特征。为了改进池化模型的算法,文献[9]提出了一种基于最大池化算法的动态自适应池化算法,针对不同的特征图像,可以动态调整池化的过程,然后根据不同池化域的内容,自适应地调整池化权值。假如池化域中仅有唯一值,该值就是最大值,即特征表示。本文在最大池化算法的基础上,利用插值原理,构建模型进行函数模拟。假设μ表示池化因子,则基于最大池化算法的动态自适应算法表达式如下
(5)
动态自适应算法的原理是通过池化因子μ对最大池化算法进行优化,改进后的方法能更准确地提取特征。其余参数设置与最大池化模型一致。
池化因子μ的计算方法如下
(6)
式中:a——池化域中除最大值外所有值的平均值;
vmax——池化域中的最大数值;
θ——校正误差项;
ρ——特征系数。
特征系数ρ的计算方法如下
(7)
式中:c——池化域的边长;
nepo——迭代次数。
池化因子μ的取值受到特征系数ρ与池化域中各数值的影响。因此,当池化域大小确定,迭代周期不变时,池化因子就能根据池化域的不同而变化;当在同一池化域时,池化因子则会因为迭代次数的不同,自动调整到最优值。池化因子μ∈(0,1),这样在处理最大值明显的池化域时也不会丢失太多精度,在处理其他池化域时弱化最大池化的影响,从而使模型在不同的迭代次数下处理不同的池化域时都可以提取到更为精确的特征。
3 实验分析
3.1 数据集
本文搜集经过图像定位分割处理后的车牌号,共3部分,分别为相关省份简称(如粤、苏、沪、浙、闽、京等)37个、城市代码(大写英文字母26个)、编号(数字0~9和24个大写英文字母的组合),共约1万张图片作为训练集和测试集。每个图片都是二值化后的灰度图。样例如图3所示。

图2 分割后的车牌号字符数据集样例
3.2 CNN训练模型
根据车牌的省份简称、城市代码、编号3个部分的数据集,分别建立CNN模型。首先,进行图片处理,用PIL库把数据集中的灰度图转换成需要的数据形式,之后用Python+TensorFlow深度学习框架搭建3个CNN模型并训练分类器,用测试集测试训练出来的分类器。3个部分采用同一个CNN结构,但是每个网络结构里面的具体参数是各自独立的。
输入层大小为20×20,第一层卷积C1的卷积核大小为8×8,卷积核个数为16,Stride 步长为1,Same 卷积。第二层卷积C2的卷积核大小为5×5,卷积核个数为32,Stride 步长为1,Same卷积。最后一层为分类层,神经元个数表示类别个数。省份简称模型只有6类有效;所属城市区域模型有26类有效;编号模型有34个神经元有效。
初始化用saver函数,激活函数为relu,设置每次训练的输入个数和迭代次数,为了支持任意图片总数,定义了一个余数remainder。譬如,如果每次训练的输入个数为60,图片总数为150张,则前面两次各输入60张,最后一次输入30张(余数为30)。每完成5次迭代,判断准确度是否已达到100%,达到则退出迭代循环。建立两层卷积神经网络模型进行信息提取测试验证,输出识别出来的3部分字符。
首先,选取1 254张省份简称图片进行训练,耗时相对较短,经过100多次的迭代之后准确率达到100%,训练完成,效果如图3所示。由图3中的实验数据可以分析出,迭代次数与准确率之间的关系如图4所示。由图4可知,随着迭代次数的增加,在经过20次的迭代后,准确率趋于100%并维持稳定。

图3 省份简称训练结果
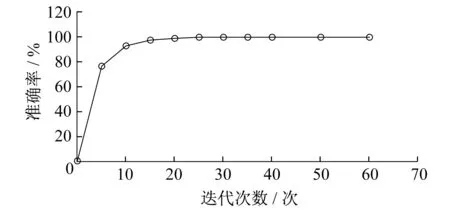
图4 省份简称训练准确率与迭代次数的关系
其次,选取3 467张城市代码图片进行训练。省份简称耗时较长,经过将近500次迭代之后准确率达到100%,效果如图5所示。由图5中的实验数据可以分析出,迭代次数与准确率之间的关系如图6所示。由图6可知,随着迭代次数的增加,在经过50次的迭代后,准确率趋于100%并基本维持稳定。
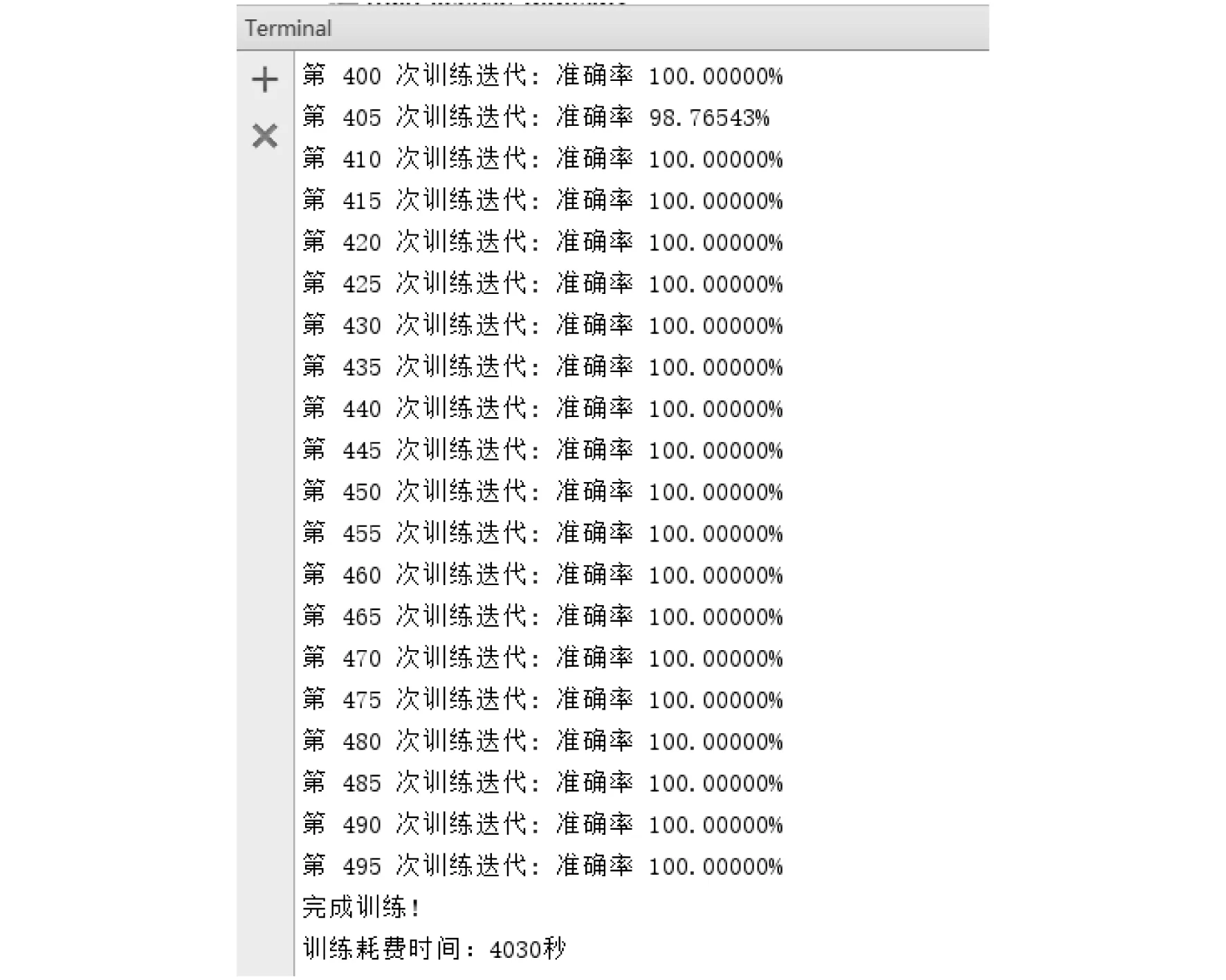
图5 城市代码训练结果
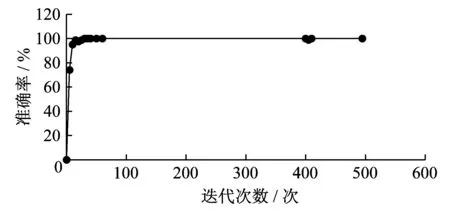
图6 城市代码训练准确率与迭代次数的关系
最后,选取4 285张编号图片进行训练,由于包含大写英文字母和数字,迭代次数较多,耗时很长,但准确率达到99%,效果如图7所示。由图7中的实验数据可以分析出,迭代次数与准确率之间的关系如图8所示。由图8可知,随着迭代次数的增加,在经过约100次的迭代后,准确率趋于99%并基本维持稳定。

图7 编号训练结果
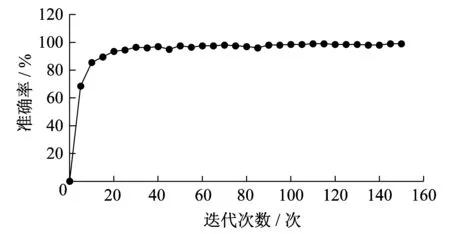
图8 编号训练准确率与迭代次数的关系
3.3 实验验证与对比
通过训练完成的模型来进行测试。本实验选用车牌号为“闽O 1672Q”的图片来验证该CNN训练模型的准确率。车牌号原图如图9所示。

图9 车牌号原图
经过几秒钟的时间,分别得出了车牌省份简称、城市代码、编号的识别结果,最终得出与原图一致的实验结果,“闽O 1672Q”。识别结果如图10所示。

图10 识别结果
利用采集的数据集,分别用BP神经网络、传统LeNet-5 CNN和改进后的CNN 3种方法对相同的字符集进行对比分析实验,实验结果如图11所示。
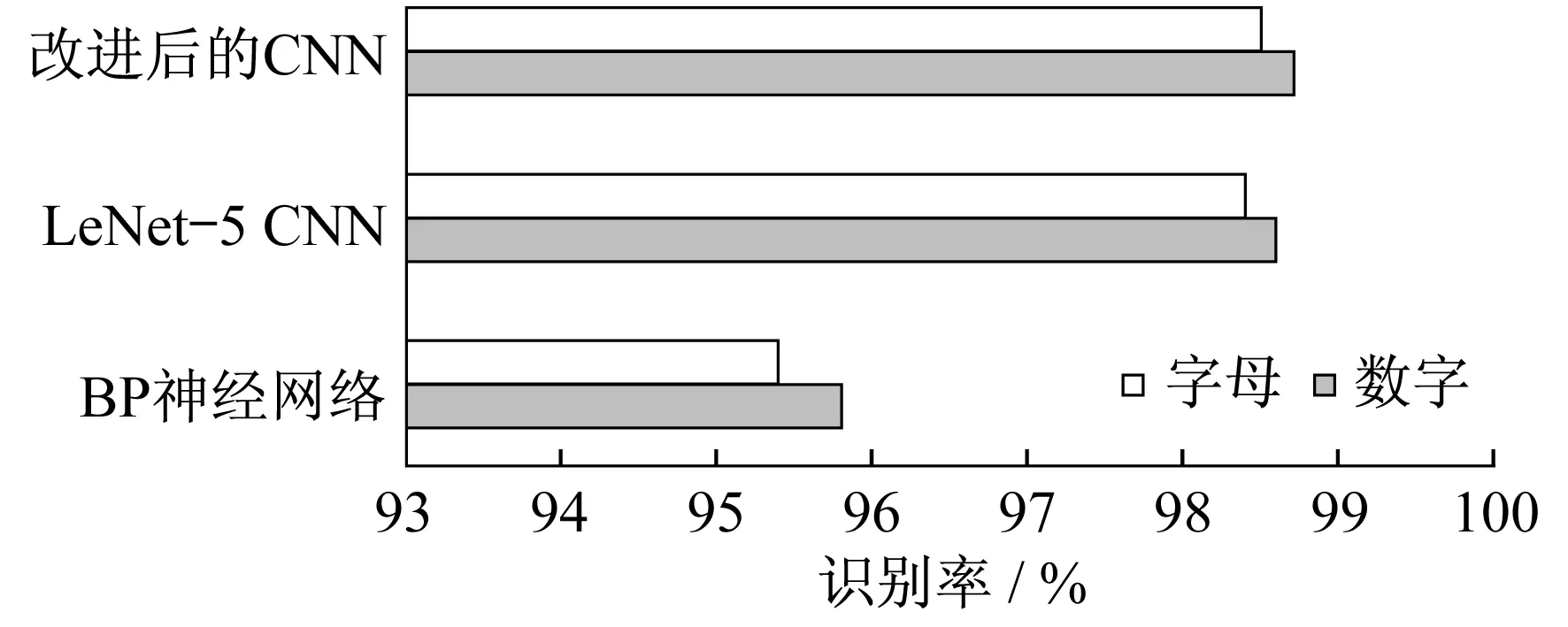
图11 3种方法实验结果对比
相较于传统的BP神经网络,LeNet-5 CNN在识别率上有着明显的优势,而改进后的CNN算法与LeNet-5 CNN虽然相近,但前者还是提高了识别率。
4 结 语
本文通过对比传统的多层神经网络分析CNN在车牌号图像识别中的应用和改进,并建立了车牌识别的训练模型,快速准确识别出测试车牌号。本文采取的CNN模型不需要进行复杂的调参,降低了模型的复杂性,避免特征提取和分类过程中数据重建的复杂度。随着电动汽车的普及,人工智能的发展,高速有效的图像特征提取越来越重要。CNN经过不断改进和优化,逐渐克服其数据集要求高、平移不变性等传统缺陷,并且随着硬件平台的不断发展,其训练时间不断缩短,效率不断提高,使其在车牌号图像特征提取中的应用更加成熟稳定。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
计算机技术与发展(2019年1期)2019-01-21 00:56:38
莫愁(2018年6期)2018-11-14 14:06:12
高中生·天天向上(2018年9期)2018-11-06 07:39:34
中国交通信息化(2018年5期)2018-08-21 03:37:40
