
基于信息熵的异常检测算法
2020-09-03 00:58:00张安勤
上海电力大学学报 2020年4期
张安勤, 吴 蕊, 张 挺
(上海电力大学 计算机科学与技术学院, 上海 200090)
随着电力系统的信息化程度不断提高,电网的数据规模飞速增长[1]。如何对海量的电网数据进行高效分析,快速准确地检测出异常的电力数据,是电网安全有效运行的重要保证。
异常检测可以发现数据集中与一般数据有差异的数据对象,即一些与众不同的数据[2]。在电力领域中,异常检测可以作为数据研究的基础,如检测出异常的电力负荷数据能有效提高负荷数据的质量,对后续进行负荷预测及合理规划电网有着重要的作用[3-4]。异常检测也可以直接用于数据分析,如异常用电检测和设备故障检测等。
异常检测技术主要可以分为基于监督、半监督和无监督3种类型。基于监督的异常检测方法的训练集由带标签的正常和异常数据构成,主要有概率统计方法[5]、神经网络方法[6]等;基于半监督的异常检测方法[7]能够从大量无标签的数据及部分有标签的数据中挖掘出异常数据的信息;基于无监督的异常检测方法可以直接从无标签的数据集中检测出异常数据,主要有基于K-means算法的异常检测[8]、基于AP聚类的异常检测[9]和基于局部离群因子的异常检测[10]等。基于监督的异常检测方法需要提前得到训练样本的标签信息,一般可通过人工标记来获得足够的训练样本,成本及代价较高;而电力负荷数据集中大多数为无标签的数据,采用无监督的异常检测方法具有代价小、简单、高效等优点。
近年来,研究者们提出了很多针对异常检测的相关方法。文献[11]通过划定时间窗口来提取相关特征,并运用核密度估计算法建模,实现了在无标签的海量数据中识别异常数据。文献[12]基于最小生成树提出了一种新的距离度量方法,能够比欧氏距离更好地进行样本间相似性度量,并通过捕获数据点或簇之间的相对连通性来进行异常数据的检测。文献[13]提出了一种异常检测模型,包含了特征提取、主成分分析、网格处理、局部离群因子计算等方法,可用于检测电力用户异常的用电模式。
K-means算法作为一种无监督聚类算法,方法简单且易于实现,可以广泛应用于异常检测且检测效果良好[14]。但是存在以下两个问题:一是算法随机选择初始中心,易使结果陷入局部最优且初始中心可能包含异常数据点,导致聚类效果差且影响最终的异常检测率;二是在计算样本间的相似性时采用各属性无差别的欧氏距离来进行度量,没有考虑数据的属性权重,使得计算的样本间相似性不准确[15]。
针对上述问题,本文结合信息熵与改进的K-means算法,提出了一种用于电力负荷数据的异常检测算法。首先,通过信息熵确定属性权重,在计算欧氏距离时引入属性权重来度量样本间的相似性;其次,计算每个样本的密度及数据集的平均密度,在样本密度大于平均密度的数据对象中根据密度及距离依次选出K个初始中心;最后,在K-means算法的迭代过程中,对比簇中数据对象到簇中心的加权欧氏距离与该簇平均加权欧氏距离,以检测数据是否异常。实验表明,改进的异常检测算法在检测率和误检率方面结果更优。对电力负荷数据进行异常检测时,相较于对比算法,改进算法的检测率提高了10.3%,误检率降低了1.7%,适合应用于电力领域。
1 Kmeans算法及属性权重的计算
1.1 Kmeans算法
K-means算法的主要思想是基于欧氏距离来计算样本间相似性,并根据样本间的相似程度将其划入所属的簇。传统K-means算法流程如下。
输入:样本集X={x1,x2,x3,…,xn},聚类中心数K。
输出:簇P={P1,P2,P3,…,PK}。
步骤1 从X中随机选择K个样本作为初始中心{c1,c2,c3,…,cK}。
步骤2 计算X中的样本与各簇中心ci(1≤i≤K)的距离,并将样本划入与其最近的聚类中心所属的簇。
步骤3 根据簇中包含的样本,重新形成每个簇的中心点。
步骤4 重复步骤2和步骤3直到聚类中心不变,算法结束。
1.2 属性权重的计算
K-means算法在计算时并未考虑数据的属性权重对聚类的影响,将会导致算法的聚类结果不准确。信息熵是一种计算属性权重的经典算法,可以用来计算属性的离散程度。对于某项指标,其熵值越小,则该指标的离散程度越大且具有更大的信息量。因此,对属性而言,熵值越小时该属性对聚类的影响越大。将信息熵应用于K-means算法时,可根据各属性的离散程度计算其权重,并通过计算加权欧氏距离来提高聚类效果和异常检测率。
信息熵计算属性权重的算法流程如下。
步骤1 假设数据集X由n个m维样本构成,则X可以表示为一个n×m的矩阵,即
步骤2 为了消除量纲对聚类结果的影响,对数据进行归一化处理,公式为
(1)
式中:xij——第i个样本的第j列属性值;
max(xj),min(xj)——数据集中第j列属性的最大值和最小值。
步骤3 计算第i个样本的第j列属性所占的比重,公式为
(2)
步骤4 计算第j列属性的信息熵,公式为
(3)
步骤5 计算第j列属性的差异系数,公式为
qj=1-Ej
(4)
步骤6 计算第j列属性的权重,公式为
(5)
其中,0≤wj≤1。
计算得到各属性的权重后,给出数据对象a和b的加权欧氏距离[16],公式为
(6)
式中:xaj,xbj——数据对象a和b的第j列属性取值。
2 异常检测算法
2.1 Kmeans算法初始中心的选择
需要进行异常检测的数据集一般包含正常和异常两种数据。由于传统K-means算法的初始聚类中心是随机选出的,算法有可能将异常点选作初始中心,从而影响聚类结果。异常数据一般具有以下特征:与正常数据相比,异常数据所占比例较小,数据集中的大多数数据都为正常数据;异常数据的密度较小,分布在稀疏的区域,比如在进行异常用电检测或计算机监控时,数据集中的大多数数据为正常数据,而异常数据大多处于正常数据所聚集的簇的边缘或者簇与簇之间的区域。根据异常数据的特点,可以选择密度大于数据集平均密度的数据点作为初始中心,使得初始中心不含异常点。
K-means算法的聚类结果和聚类效率与初始中心有直接的关联。算法的初始中心越接近实际簇中心则聚类效率越高,而随机的选择初始中心则导致了聚类结果不够可靠。
初始聚类中心的选择算法如下。
输入:样本集X={x1,x2,x3,…,xn},最近邻数据点个数t,聚类中心数K。
输出:初始中心C={c1,c2,c3,…,cK}。
步骤1 计算X中数据点xj(1≤j≤n)的密度为
(7)
式中:Gt(xj)——xj的t个最近邻数据点集合。
步骤2 计算所有数据对象的平均密度D,由D(xj)>D的数据点形成新的数据集X′。其平均密度的公式为
(8)
步骤3 在X′中,取D(xj)最大的数据点作为第1个初始中心c1,取距离c1最远的数据点作为第2个初始中心c2。对于X′中的样本xj(j=1,2,3,…,n),计算其与前i-1(3≤i≤K)个初始中心的加权欧氏距离dist(xj,c1),dist(xj,c2),…,dist(xj,ci-1),选出其中的最小值min(dist(xj,c1),dist(xj,c2),…,dist(xj,ci-1))。按照上述方式依次计算X′中的每个样本与前i-1个初始中心加权欧氏距离的最小值,并放入集合中,集合中最大值对应的数据对象为第i个初始中心ci,直到选出K个初始中心,算法结束。即满足
max{min(dist(xj,c1),dist(xj,c2),…,
dist(xj,ci-1))}
(9)
由上述算法过程可知,实际的簇中心一般处于密度较大的区域且相互间具有一定的距离,改进算法在密度大于平均密度的数据点中均匀地选择初始聚类中心,满足了密度较大和保持距离的要求。另外,改进算法有效避免了将异常点作为初始中心的情况,使算法不会从开始就陷入误差,提高了聚类效率。
2.2 基于信息熵与改进Kmeans算法的异常检测算法
本文根据异常数据的特征和分布模式提出了一种异常检测算法。该算法在聚类迭代时通过对比数据点到所属簇中心的加权欧氏距离与该簇中所有数据点到簇中心的平均加权欧氏距离来检测异常。在异常检测过程中采用加权欧氏距离,考虑了属性权重对异常检测计算的影响,使异常检测结果更加准确。
基于信息熵与改进K-means算法的异常检测算法如下。
输入:样本集X={x1,x2,x3,…,xn},最近邻数据点个数t,聚类中心数K,异常度阈值η(X不同时,η的取值也不相同)。
输出:簇P={P1,P2,P3,…,PK},异常点集合U。
步骤1 设数据集中每个数据对象的初始异常度为Fj=0(j=1,2,3,…,n),并根据信息熵计算属性权重的算法来计算数据集X中各属性权重。
步骤2 根据初始聚类中心的选择算法选择K个初始中心{c1,c2,c3,…,cK}。
步骤3 计算数据对象xj与各簇中心ci(i=1,2,3,…,K)的加权欧氏距离,并将xj划入距其最近的聚类中心所在的簇。
步骤4 在K个簇中,若xj(j=1,2,3,…,n)与所属簇中心的加权欧氏距离大于该簇中所有数据对象到簇中心的平均加权欧氏距离,则Fj++。上述判断公式为
(10)
式中:|Pi|——簇Pi中的数据对象个数。
步骤5 重新生成每个簇的中心点
(11)
步骤6 若c′i≠ci,则将ci更新为c′i,并返回执行步骤3。
步骤7 若数据对象xj的异常度Fj≥η,则判断xj为异常点,将xj并入U中。
步骤8 聚类算法结束,输出P和U。
由于数据对象的异常度是通过计算每次迭代时该数据对象与所属簇中心的加权欧氏距离来确定的,因此算法选择的初始中心越接近实际的簇类中心,异常检测的性能越好。当初始中心含异常点时会严重影响异常检测的准确率,而改进算法选择的初始中心不含异常点,有效避免了上述问题。最后,在异常计算中引入属性权重,考虑了各个属性对异常检测的作用。
3 实验分析
实验数据采用UCI机器学习数据库的Parkinson Disease Spiral Drawings Using Digitized Graphics Tablet数据集[17-18](以下简称为“帕金森数据集”),以及某电厂一个月的电力负荷数据。将检测率和误检率作为异常检测性能的评价指标。
检测率(Detection Rate,DR)和误检率(False Alarm,FA)的定义如下[19]
(12)
(13)
其中:TP——被正确检测为异常的异常样本数;
FN——被错误检测为正常的异常样本数;
TN——被正确检测为正常的正常样本数;
FP——被错误检测为异常的正常样本数。
帕金森数据集包含静态螺旋、动态螺旋和定点稳定性3种测试。算法在每种测试中随机选择1 000条健康样本与100条患者样本作为数据集,分别对3种测试类型进行计算,并将患者样本当做异常数据来验证异常检测的效果。实验对比了改进算法与传统K-means算法、MinMax K-means算法的异常检测性能[20-21],结果如表1所示。其中,对比算法的数据结果为两种算法分别计算100次后的平均值[22]。
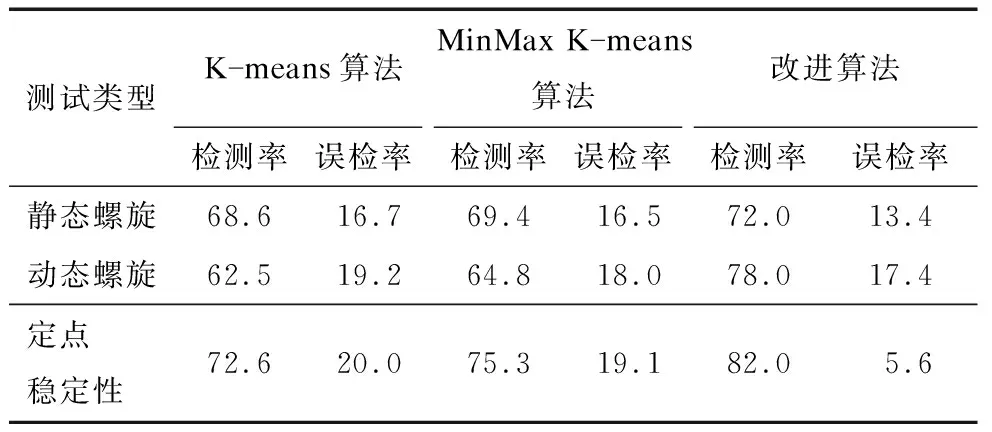
表1 3种算法在帕金森数据集中的实验结果对比 单位:%
对于电力负荷数据集,通过在其中随机添加一定比例的异常数据来对比3种算法的异常检测性能,结果如表2所示。

表2 3种算法在电力负荷数据集中的实验结果对比 单位:%
实验结果表明,与K-means算法和MinMax K-means算法相比,改进算法的检测率更高且误检率更低。究其原因如下:首先,改进算法选择了更优的初始中心,不同的初始中心会导致在每次迭代时生成不同的簇类中心,而在迭代过程中数据对象的异常度计算与其所属的簇中心相关;其次,初始中心含有异常点,会使算法从一开始就陷入偏差,影响数据对象异常度的计算,进而影响最终的检测率和误检率,而改进算法有效避免了这种情况;最后,改进算法引入了属性权重的概念,根据各属性影响程度的不同,其在计算时的占比也不同,使得异常计算的结果更加准确,从而提高了异常检测的性能。
4 结 语
本文根据异常数据的特征和分布情况,结合信息熵与改进的K-means算法,提出了一种适用于电力负荷数据的异常检测算法。算法在选择初始聚类中心时有效避免了异常点并使得初始聚类中心均匀分布,聚类的效果更优。在此基础上,算法引入了属性权重和加权欧氏距离来计算数据点的异常度。实验证明,相较于其他对比算法,本文提出的改进算法有着更优的异常检测性能,能够有效检测出异常的电力负荷数据,为实现高精度的负荷预测提供了重要保障。
猜你喜欢
小学生导刊(2018年34期)2018-12-18 01:53:14
电子测试(2017年15期)2017-12-18 07:19:27
山东青年(2016年3期)2016-02-28 14:25:55
智能系统学报(2015年4期)2015-12-27 09:38:39
母子健康(2015年1期)2015-02-28 11:21:33
电子设计工程(2015年6期)2015-02-27 12:04:53
延河(下半月)(2014年3期)2014-02-28 21:06:45
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
自然资源遥感(2014年3期)2014-02-27 11:56:33
探索地理(2013年5期)2014-01-09 06:40:44
