
迁移学习与GAN结合的医学图像融合模型
2020-09-02 06:52肖儿良简献忠
小型微型计算机系统 2020年9期
肖儿良,周 莹,简献忠
(上海理工大学 光电信息与计算机工程学院,上海 200093)(上海市现代光学系统重点实验室,上海 200093)
E-mail:tracer96@sina.com
1 引 言
医学影像在临床诊断和治疗中发挥着重要的作用.由于不同的成像模式侧重于不同类别的器官、组织信息,各自有其自身的优势和局限性,因此仅由一种图像通常不能为整个医学诊断提供完整的信息.例如,计算机断层扫描(CT)图像显示骨骼和种植体等致密结构的信息,而磁共振(MR)图像显示软组织等高分辨率的解剖信息[1].我们可以通过把多种模态的医学图像进行融合,以集成来自不同模态的图像的互补信息,从而利用融合图像中获得的附加信息进行更快速、精确的异常定位,来提高医学诊断的鲁棒性.
目前常用的图像融合技术可以分为两大类,基于传统方法[2-5]以及基于深度学习方法[6-10].传统图像融合方法大都涉及图像变换、活动水平测量和融合规则设计三个关键部分,这些都需要人为的设计与选择,依赖于丰富的先验知识.并且为了得到效果突出的融合图像,人为设计的模型越来越复杂,需要选择的参数越来越多,存在融合效果不稳定、运行速率低的问题.而深度学习可以自动化地提取图像中更具表现力的特征,因此,近年来深度学习被应用于图像融合中[6],可以解决传统方法中由于人为因素影响融合效果不稳定的问题.
现有的基于深度学习的图像融合技术多依赖于卷积神经网络(Convolutional Neural Network,CNN)模型,文献[7]提出了一种有效的三层CNN结构来解决泛锐化问题,通过添加几个非线性辐射测量指数的映射来增强融合性能,实现了遥感图像的融合.文献[8]用一个CNN模型实现源图像和焦点图之间的直接映射,通过CNN联合了活动水平测量和权重分配两部分,从而对多聚焦图像进行融合,并且在文献[9]中将该模型成功用于多模态的医学图像融合.但这样的模型仍然需要设计一种基于局部相似度的融合策略,以自适应地调整融合系数,才能得到效果良好的融合图像.由于利用CNN实现图像融合任务还存在需要人为设计融合规则的不足,文献[10]提出一种利用生成对抗网络的网络模型,不需人为设计融合规则或选择参数,只需给定标签图像即可以做到自适应地生成红外与可见光图像的融合图像,实现了端到端的多模态图像融合.但该模型对数据依赖性强,数据量的不足会影响深度学习网络的性能.
2 相关工作
在医学领域,由于医学图像具有隐私性和特殊性,数据采集和标注成本也比较高,所以构建大规模的、高质量的注释良好的数据集非常困难.目前已有数据增强(Data Augmentation)的方法[11],可以通过对现有数据集进行微小改动,例如旋转、缩放或翻转,从而利用已有数据创造出更多相关数据,来使得神经网络具有更好的泛化效果.然而对于医疗影像这一小样本领域,有效的数据增强技术相对较少、且不成熟,目前还没有成熟的可以有效获取足够丰富且高质量的医学影像数据的数据增强方法[12].随着迁移学习的发展,可极大缓解深度学习中数据不足引起的问题.这激发了我们使用迁移学习来解决在利用深度学习网络完成医学图像融合任务中训练数据不足的问题.
在机器学习领域中,迁移学习研究如何将已有模型应用到新的不同的、但是有一定关联的领域中.迁移学习主要有四种实现方法:样本迁移、特征迁移、参数/模型迁移以及关系迁移.深度学习中应用的迁移学习属于参数迁移,它具有非常强的数据拟合能力,能学习到与领域无关的,即泛化能力更强的特征表达[13].文献[14]提出通过融合不同深度卷积神经网络(DCNN)架构中提取的多种迁移学习特征,可以提高图像分类的精度.文献[15]提出一种迁移深度特征融合的学习框架,它可以有效地整合各个模块的优势,在人脸识别任务上表现出显著的优越性.文献[16]研究了域自适应在生成对抗网络图像生成中的应用,发现利用预先训练的网络可以有效地加速学习过程,并在目标数据有限的情况下,利用先验知识可以缩短网络收敛时间,显著提高图像质量.文献[17]提出了一种基于对抗学习的非监督域适应模型,该模型增加了一个特征共享转换网络,直接将源域的特征映射到目标特征空间,在情绪分析、数字分类、自然图像分类等任务上均表现良好.但国内外对迁移学习在医学图像融合中的研究还没有引起足够的重视.
基于以上对深度迁移学习应用的研究,本文首次提出利用迁移学习来提高用于多模态医学图像融合的Transfer-WGAN-GP模型的性能,从而自适应地生成高质量的CT与MR-T2的融合图像.首先利用源域中大量的红外与可见光数据预训练网络,提取在图像融合过程中具有代表性的语义信息,学习融合图像与源图像之间的特征映射,并转化为网络中的参数,以得到一个基本网络,然后利用目标域中少量的CT与MR-T2数据对模型进行微调,由此完成了将参数从源域迁移到目标域的特征空间中.最后,只需对训练完成的生成器输入待融合的CT与MR-T2的源图像,即可快速得到充分保留源图像信息的高质量融合图像.
3 Transfer-WGAN-GP模型
3.1 网络结构设计
本文提出的Transfer-WGAN-GP模型中包含两个在GAN的基础上进行改进的网络,两个网络之间通过迁移学习实现参数共享,每个网络中都包括生成器G与鉴别器D两个部分,如图1所示.
网络的训练过程如图1(a)所示,首先将待融合的两幅多模态图像以一幅图像多通道形式输入G,然后将通过G生成的融合图像和标签图像分别输入D,G与D根据改进的WGAN-GP损失函数相互博弈竞争,从而不断优化网络,最终使D完成区分真实的标签图像与G生成的假图像的分类任务.预训练中得到的生成器Gp与主训练中得到的生成器Gm相当于两个参数共享的特征提取器,预训练中得到的鉴别器Dp与主训练中得到的鉴别器Dm相当于两个参数共享的分类器.
网络的测试过程如图1(b)所示,对于训练好的Transfer-WGAN-GP,只需要将待融合的两张图像以一幅图像多通道形式输入到训练好的生成器中,生成器就可以自动生成理想的高质量的融合图像.
3.1.1 生成器的网络结构
本文的生成器网络结构是基于全卷积网络进行设计的,如图2所示.生成器的输入是经过连接操作的红外与可见光图像或经过连接操作的CT与MR-T2图像,不需要提取出图像的特征图来作为网络输入.网络主要由五层卷积神经网络构成,前四层中采用3×3的滤波器,最后一层采用1×1滤波器.为保持图像大小不变,减少源图像信息的丢失,每一层的步长均设置为1.此外,为了防止噪声的引入,没有设置填充操作.为避免医学图像在下采样中丢失部分语义信息,整个生成器网络中只引入了卷积层,没有引入下采样操作,这样做还可以保证输入图像和输出图像大小相同.最后,对于激活函数的选择,由于使用ReLU需要小心平衡学习率,效果可能不佳,因此本文在前四层选择使用Leaky ReLU激活函数,来提高网络的非线性程度,最后一层中采用tanh激活函数.
3.1.2 判别器的网络结构
GAN中的鉴别器与生成器不同,其根本目的在于分类.它通过从输入的图像中提取特征,然后根据特征进行分类,判断输入图像为真实的标签图像还是假的由生成器生成的图像[18].本文的鉴别器网络主要由四层卷积神经网络构成,如图3所示.四层中均采用3×3的滤波器,每一层的步长设置为2,最后一层linear层主要用于分类.值得注意的是,由于传统的GAN存在的一些缺陷,本文采用改进的WGAN-GP网络[19],由于该模型是对每个样本独立地施加梯度惩罚,为防止引起同一个批次中不同样本的相互依赖关系,所以鉴别器网络结构中去掉了批归一化(Batch Normalization,BN)层.

图3 鉴别器的网络结构Fig.3 Network architecture of discriminator
3.2 损失函数设计
损失函数是用于衡量网络生成的数据与输入的标签数据之间的差距,网络训练的目的旨在使损失函数最小化.本文提出的Transfer-WGAN-GP网络的损失函数主要包含两部分,即生成器G的损失函数和鉴别器D的损失函数.
首先是G的损失函数,G的损失函数如式(1)所示,主要由两部分组成:
LG=LGAN+ζLcontent
(1)
其中,LG表示总的损失函数,LGAN表示生成器G与鉴别器D之间的对抗损失,Lcontent表示内容损失.ζ用于在对抗损失和内容损失之间取得平衡,本文所做实验中ζ取10.对抗损失具体定义如式(2)所示:
(2)
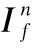
由于医学图像的信息由图像中像素点强度和梯度信息表示,CT图像中更多表现在边缘的明暗信息,而MR-T2包含更多由梯度表达的纹理细节信息.为更好地学习到两种图像中包含的信息,我们需要使融合图像更多的从标签图像中同时学习强度信息与梯度信息,所以内容损失函数Lcontent定义如式(3):

(3)
其中,If表示由G生成的融合图像,IL表示输入的标签图像.H和W分别表示输入图像的高和宽,‖·‖F表示矩阵的F范数,表示求梯度的函数.ξ是用于平衡两部分的正则参数,本文中取值为8.
其次是D的损失函数,如式(4)所示.为使网络训练过程更稳定,防止产生模式崩溃等问题,在损失函数中仿照WGAN-GP加入了梯度惩罚项,重点在生成样本集中区域、真实样本集中区域以及夹在它们中间的区域上施加Lipschitz限制.这样做还可以显著提高训练速度,加快网络收敛.本文中λ取10,η为从[0,1]的正态分布中选取的随机数.
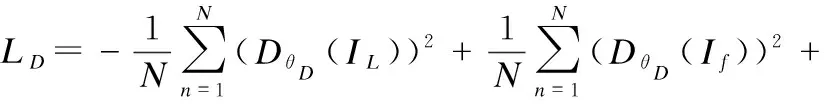
(4)
3.3 算法伪代码
Transfer-WGAN-GP模型的核心算法包括预训练、参数迁移和主训练三个部分,为了更好地理解网络的工作原理,总结网络训练过程的伪代码如算法1所示.
在预训练过程中,网络中G与D学习红外与可见光图像以及相应的融合图像之间的特征映射,在迭代过程中相互对抗以优化损失函数中的参数,不断缩小生成图像与标签图像之间的差距;保存训练好的G与D中的参数,选择适当的微调方式,即开放或冻结部分卷积层的参数,再迁移到CT与MR-T2图像以及相应的融合图像的数据集中;在有基础参数的网络上继续训练,使G与D的损失函数中的参数继续优化,直到最大迭代次数;最后对训练好的G进行测试,即可得到CT与MR-T2的融合图像.
Algorithm 1.Transfer-WGAN-GP医学图像融合算法
Parameter:α=0.0001,β1=0.5,β2=0.9
Require:训练迭代次数t,批次数量m,G中的初始参数θ0,D中的初始参数ω0.
Part 1.预训练
Input 1.经连接操作的红外与可见光图像PIR-VI(S)
Input 2.标准融合图像PIV(X)
1.whileθ1没有收敛 do
2. fori=1,…,t do
3. forj=1,…,m do
4. 采样s1~PIR-VI(S)
5. 采样x1~PIV(X)
6. 取一随机数∈1~U[0,1]
10. end for
12. end for
14.end while
Part 2.参数迁移
15.存储训练好的G与D中的参数
16.选择适当的微调方式对网络中部分卷积层参数进行冻结
Part 3.主训练
Input 3.经连接操作的CT与MR-T2图像PCT-MR(S)
Input 4.标准融合图像PCM(X)
17.whileθ2没有收敛 do
18. fori=1,…,t do
19. forj=1,…,m do
20. 采样s2~PCT-MR(S)
21. 采样x2~PCM(X)
26. end for
28. end for
30.end while
31.对训练好的G进行测试
Output:CT与MR-T2的融合图像
4 实验分析与讨论
本实验的硬件平台:CPU为IntelCorei7-8700,主频3.20GHz;内存16G;GPU为NVIDIA 1080Ti 12GB.软件平台:操作系统为Windows10 64位;MATLAB版本为2017b;训练环境为Tensorflow-gpu 1.8.0;Python版本为3.5.0.
4.1 数据集设计
4.1.1 标签图像数据集
本文所使用的红外与可见光图像来自于公开的TNO红外与可见光图像融合数据集[20],采用的医学图像来自Havard Medical School的The whole brain atlas(1)http://www.med.harvard.edu/aanlib/home.html.
为解决网络训练中缺少作为标签的标准融合图像的问题,具体的标签图像制作过程如下:从TNO数据集中选取45对来自不同场景的经过配准的红外与可见光图像,通过基于现有的性能优良的CSMCA[2]、GFF[3]、NSST[4]、NSCT[5]四种传统方法分别得到融合图像,然后使用以下6种多模态图像融合任务中常用的图像质量评价指标对得到的融合图像进行分析,最后选取综合评价指标更优的方法来产生标签图像.
我们选取的指标主要有3个无参考图像的评价指标和3个有参考图像的评价指标.无参考图像的评价指标有:熵(Entropy,EN)、标准差(Standard Deviation,SD)和平均梯度(Average Gradient,AG).图像的熵反映图像包含信息量的多少;标准差反映图像像素值与均值的离散程度;平均梯度反映图像对微小细节反差的表达的能力.有参考图像的评价指标有:基于熵的互信息指标(Mutual Information,MI),用于衡量融合后的图像从源图像中保留了多少信息;基于梯度的评价指标QAB/F,衡量融合图像中对源图像边缘信息的保存程度;多层级结构相似性(Multi-Scale Structural Similarity,MS-SSIM)从亮度、对比度和结构三个方面衡量融合图像与源图像的相似程度,其值在[0,1]之间.需要指出的是,上述6个指标都是值越大表示图像质量越好.
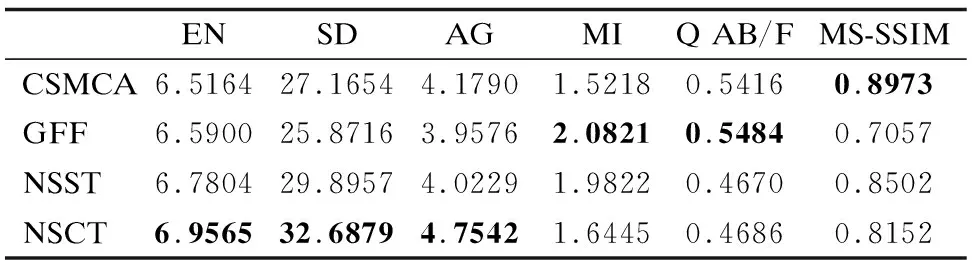
表1 源域中标签图像选取依据表Table 1 Selection of label image of source domain
从45组图像中抽取一组评价指标数据作为展示,如表1所示,加粗的数值表示四组方法中的最佳得分,由于NSCT方法在6个指标中有3个指标为最优,并且其余3个指标与其他方法相差不大,因此选取NSCT方法产生的融合图像作为在源域中预训练使用的标签图像.为扩充源域中数据集的样本数量、充分利用源域中的特征,要对红外图像、可见光图像和标签图像数据集,以240×240大小的窗口进行滑动裁剪得到大量的图像子块,为保持与目标域所用的CT与MR-T2图像大小一致,还需要将这些图像进行标准化到256×256大小.这样就得到了在红外与可见光图像上预训练中使用的,包含红外图像、可见光图像、以及相应的标签图像的数据集.
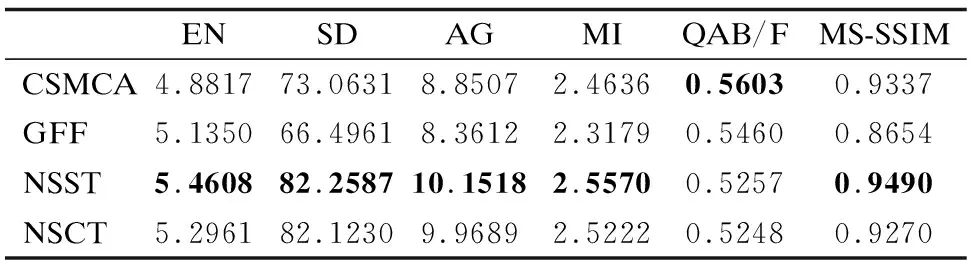
表2 目标域中标签图像选取依据表Table 2 Selection of label image of target domain
主训练中采用的数据集从Havard Medical School的全脑图谱数据集获取.从10种不同病症的脑部图像中各选取15组切片,得到共150组CT与MR-T2图像.与红外与可见光图像的数据集制作步骤相同,通过如表2所示指标对比,由于NSST方法得到的融合图像有5个指标优于其它三种方法,QAB/F指标中的得分与其他三种方法也相差不大,所以选取NSST方法产生的融合图像,作为在目标域中主训练使用的标签图像.这样就得到以CT、MR-T2、以及相应的标签图像构成的训练集,作为主训练中生成器的输入.
4.1.2 数据增强数据集
为证明迁移学习相对于数据增强方法在深度学习网络训练中的优势,首先要通过数据增强的方法,对原始数据集中样本数量进行扩充,以满足改进的WGAN-GP网络的训练.数据增强方法可以分为两类,一类是离线增强,适用于较小的数据集;一类是在线增强,适用于较大的数据集.由于本文中使用的CT与MR-T2数据集只有150组,因此采用离线增强的方法.本文通过MATLAB对每一张原图像进行翻转、不同角度的旋转,以及图像亮度、对比度的调节等方法,把每一张图片扩充出30张图片,以达到数据量扩大的目的.
然而数据增强的方法虽然能有效解决样本数量问题,但在解决样本多样性方面,所取得的效果并不是很理想.因为经过数据增强处理得到的数据集中的医学图像不够多元化,类似场景的数据样本过多,利用这些样本网络可能会只学习到一个场景,容易导致网络的过拟合.因此通过数据增强的方法得到的数据集样本数量不宜过多,通过实验选择,最终本文在基于数据增强的网络训练中用的数据集中CT与MR-T2的样本数量为4650组.
4.2 源域中最佳样本数选择
本文提出的方法主要分为在源域的预训练过程和在目标域的主训练两部分.源域中训练集包含红外图像、可见光图像以及对应的标签图像,目标域中训练集包含CT图像、MR-T2图像以及对应的标签图像.为探究源域中样本数量对于网络性能的影响,将源域中样本数量分别设置为4443组、6665组以及8450组,目标域中样本数量固定为150组.构建相同的网络,设置相同训练次数,最后通过测试训练好的网络,以得到的融合图像进行客观评价指标的分析,结果如表3所示,加粗的数值表示三组实验中的最佳得分.

表3 源域样本数对网络性能的影响Table 3 Influence of source domain sample size on network performance
从表中数据可以看到,源域中样本数由4443组增加到6665组时,各项指标数据对比均有提升,即生成图像质量更好,意味着网络性能得到提高.但当源域中样本数继续增加到8450组时,各项指标对比均有下降,即生成图像质量更差,意味着网络性能变差.由此可见,源域中样本的数量对网络性能有所影响,并且不是一定样本数量越多得到的网络越好,而是需要在一定的范围内合理选取源域中的样本数量.由于三组实验中,第二组实验训练得到的网络生成的图像质量最高,因此本文后续实验中源域中的训练集采用的样本数设置为6665组.
4.3 迁移网络的微调
在迁移学习中,为选择性地利用一些在源域中学习到的特征,可以通过微调(finetune)网络以提高网络性能,加快网络收敛速度[21].本文采用的微调的步骤如下:
1)在源域的红外与可见光数据集的融合任务上训练一个基本网络;
2)将基本网络中生成器GS的前p层复制到目标网络生成器GT的前p层,基本网络中鉴别器DS的前q层复制到目标网络鉴别器DT的前q层,这样可以将网络学习到的源图像与对应融合图像之间的特征映射转移到目标域的网络上;
3)随机初始化目标网络的其余层,并在CT与MR-T2的数据集上进行图像融合训练.由于源域中的任务与目标域中的任务均为图像融合,因此转移的特征映射是通用的,同时适用于基本任务和目标任务,而不是特定于基本任务.
基于以上步骤,对如何微调网络在CT与MR-T2的图像融合任务中的影响进行了实验.在源域与目标域中,我们采用相同结构的网络,对如3.1.1和3.1.2中所示的生成器中的4个卷积层与鉴别器中的5个卷积层进行不同位置的冻结与微调,通过对最终得到的融合图像质量的客观指标评价分析来判断如何微调能得到性能更好的网络.四组实验的评价指标如表4所示.加粗的数值表示四组微调方法中的最佳得分.
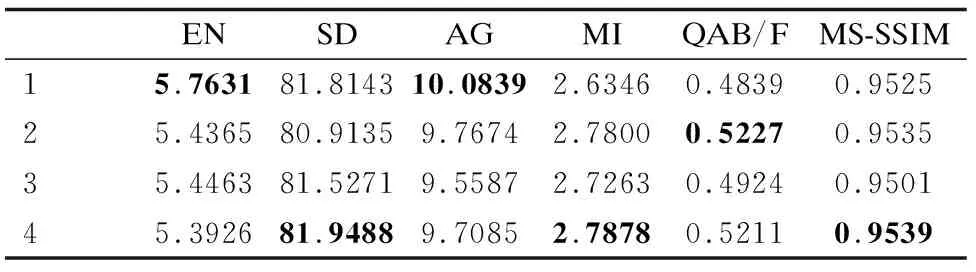
表4 微调对迁移学习效果的影响Table 4 Influence of fine tune on transfer learning effect
第1组实验是把源域中训练得到的WGAN-GP网络不经任何微调直接用于目标域的数据集上,通过表4中数据可以看到,基于源图像的评价指标都很差,说明融合图像与源图像的相似度非常低,保留的源图像的信息量很少.这是因为只在源域中训练过的网络虽然可以根据输入的源图像生成融合图像,但由于网络中高层的卷积层学习到的特征具有特异性,只适用于红外与可见光图像的融合,而在CT与MR-T2图像的融合中表现较差.
第2组实验是把源域中训练好的GS全部复制到GT,DS的前4层复制到DT,仅重新训练DT中主要用于分类的最后一层.从表4中数据可以看到相对于第1组实验,三个基于源图像的评价指标MI、QAB/F、MS_SSIM指标均有提升,说明经过在CT与MR-T2数据集上的训练,对基本网络进行微调,使之学习到更多具有特异性的特征,从而使融合图像包含更多源图像的信息,与源图像更为相似.
第3组实验是把源域中训练好的GS的后3层复制到GT,DS的前3层复制到DT,然后重新训练GT中的第一层和DT中的最后一层.由于GAN中的生成器相当于一个特征提取器,网络中的第一层学习到的是更特异于源域的特征,为提高特征提取器在目标域中的性能,选择对GT的第一层微调.而鉴别器中最后一层相当于分类器,为了使其更适应与目标域中的特征,提高在目标域中的分类性能,要对DT的最后一层进行微调.从表4中数据可以看到,这种微调方法相对于其他三种方法得到的融合图像质量较差,说明这样的微调方法不适合于本文提出的网络结构.
第4组实验是把源域中训练好的GS与DS的所有卷积层全部复制到GT和DT中,在经过初始化的网络基础上,利用网络中保留的参数,开放所有层在目标域的数据集中继续训练.这样做是因为源域与目标域中需要完成的任务是一致的,因此在源域和目标域中需要网络学习的特征映射类似,可以使用预训练的网络当做特征提取器,用提取的特征映射训练DT中的线性分类器,以提升整个网络的性能,得到更高质量的融合图像.由表4中最后一行数据可以看到这种微调方法得到的融合图像质量相对较高.
综合四组实验结果可以发现,在网络由源域迁移到目标域的过程中,从目标域中学习到的基础特征的迁移效果受微调方法的影响.几种微调方法中,第4组方法得到的融合图像效果最好.这是因为目标域中的数据集样本数很少,并且和源域中数据集样本相似度较高,而且源域中与目标域中要完成的任务是相同的,所以在目标域中的任务上可以利用大部分从源域中学习到的特征,在此基础上继续学习,可以提高网络性能,有利于得到更高质量的融合图.
4.4 迁移学习有效性实验
实验中一方面采取上文4.3中选取出的最优的微调方法,在目标域中150组CT与MR-T2以及标准融合图像的数据集中继续训练,得到一个基于迁移学习方法的网络NT;另一方面构造与NT结构相同的网络,在经过数据增强的4650组CT与MR-T2图像以及标准融合图像的数据集中训练,得到一个基于数据增强方法的网络ND;然后对网络NT和ND分别进行训练2000次、4000次、6000次的三组实验;最后对训练完成的网络测试,以得到CT与MR-T2的融合图像.
首先通过人眼观察,对融合图像效果进行主观上的比较.

图4 融合效果对比图Fig.4 Contrast diagram of fusion effect
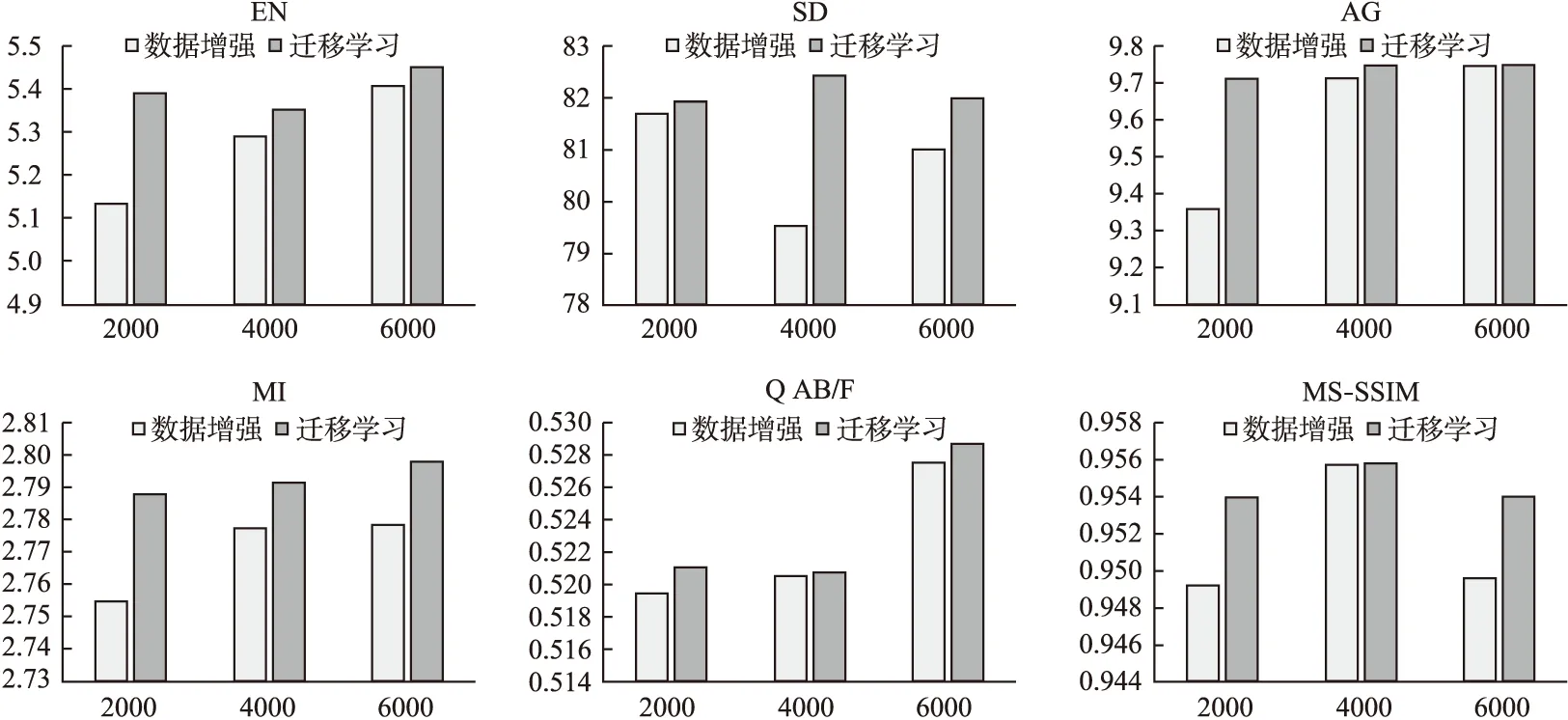
图5 迁移学习有效性实验的评价指标对比Fig.5 Comparison of evaluation indexes of transfer learning effectiveness experiment
除了对整幅图像的全局观察外,把每幅图像中代表性区域放大,以便更好地进行比较.如图4所示,为多发性栓塞性梗塞病症的脑CT与MR-T2图像融合结果.图4(a)、(b)分别为CT与MR-T2的原图像以及图中方框所圈出的局部放大得到的细节图;图4(c)、(d)、(e)分别为通过数据增强训练的网络在训练2000、4000、6000次时得到的结果,以及图中方框圈出的局部细节放大图;图4(f)、(g)、(h)分别为本文提出的Transfer-WGAN-GP的网络模型在训练2000、4000、6000次时得到的结果,以及图中方框圈出的局部细节放大图.由医学影像学可以知道,CT图中亮度表示组织密度,MR-T2中的亮度表示组织的流动性和磁性.从图4(a)中可以看到CT图中呈现高亮度的为高密度低流量的颅骨,而相对灰暗的为充以低密度高流量的脑脊液的脑室.由于二者有明显的亮度差异,融合图中应保留这样的语义信息.首先从6张融合图像中可以看到两种方法均较完整的保留了两种源图像中的语义信息,并且边缘纹理都比较丰富;通过6张局部放大的细节图可以看到,本文提出的Transfer-WGAN-GP网络模型得到的融合图像相比于数据增强的方法得到的融合图像对比度稍高,图像相对更清晰.
由于主观评价虽然可以对融合图像的视觉效果直接作出判断,但是人为评价可能受很多主观因素影响评价结果,并且如图4所示,两种方法得到的融合图像视觉上差别不大,无法判断哪种方法更优.所以需要通过前文提到的6种评价指标对融合图像进行客观的分析.为更加直观的看出两个网络在6种客观评价指标上的对比,对实验得到的数据进行可视化得到如图5所示.
从图5中每个评价指标中的三组实验的数据可以看到,随着训练次数的增加,各指标数值均有一定的提升,说明两个网络的性能随着训练次数增加有一定的提升.此外,在训练次数相同的情况下,由本文提出的Transfer-WGAN-GP模型生成的融合图像,相较于基于数据增强得到的网络生成的融合图像,在六个指标上均具有明显优势,说明本文提出的网络模型性能更优.这是由于经过数据增强处理得到的数据集中的医学图像不够多元化,类似场景的数据样本过多,利用这些样本网络可能会只学习到一个场景,容易导致网络的过拟合.而本文提出的方法是在经过初始化的网络上继续训练,利用网络在源域中学习到的基本的特征映射,可以提升网络在目标域中的训练效果,从而在小样本的数据集上训练也不会产生过拟合的现象,最终得到质量较高的融合图像.
由此可以证明在生成对抗网络中使用迁移学习在小数据集的训练上有一定的优越性,有效抑制了网络的过拟合,使得模型的泛化能力更好.
5 结 论
本文首次提出了一种Transfer-WGAN-GP网络模型,利用从红外与可见光图像的融合数据中学习特征映射来提高网络性能,从而在CT与MR-T2图像的融合中得到高质量的融合图像.利用Havard Medical School的全脑图谱中的CT与MR-T2图像进行融合,通过对比实验可以看到,在数据集有限的情况下,相对于数据增强的方法,基于迁移学习的网络可以得到更高质量的融合图像,模型更具有优势.验证了提出的Transfer-WGAN-GP模型用于CT与MR-T2图像融合的有效性,为深度学习方法用于小数据集的医学图像融合提供了一种新思路.由于本文中仅对医学图像中的CT与MR-T2图像进行融合实验,课题组下一步工作考虑通过修改现有模型,用于其他小数据集的多模态医学图像融合.
猜你喜欢
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
计算机技术与发展(2020年11期)2020-12-04
领导决策信息(2018年16期)2018-09-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
数学学习与研究(2017年3期)2017-03-09
青年文学家(2015年29期)2016-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
西南学林(2011年0期)2011-11-12
