
基于子网络级联式混合信息流的显著性检测
2020-08-27 14:35:06王永雄高远之於嘉敏张梦颖
光电工程 2020年7期
董 波,王永雄,周 燕,刘 涵,高远之,於嘉敏,张梦颖
基于子网络级联式混合信息流的显著性检测
董 波,王永雄*,周 燕,刘 涵,高远之,於嘉敏,张梦颖
上海理工大学光电信息与计算机工程学院,上海 200093
针对现有显著性检测算法在复杂场景下细节特征丢失的问题,本文提出了一种多层子网络级联式混合信息流的融合方法。首先使用FCNs骨干网络学习多尺度特征。然后通过多层子网络分层挖掘构建级联式网络框架,充分利用各层次特征的上下文信息,将检测与分割任务联合处理,采用混合信息流方式集成多尺度特性,逐步学习更具有辨别能力的特征信息。最后,嵌入注意力机制将显著性特征作为掩码有效地补偿深层语义信息,进一步区分前景和杂乱的背景。在6个公开数据集上与现有的9种算法进行对比分析,经实验验证,本文算法运行速度可达20.76 帧/秒,并且实验结果在5个评价指标上普遍达到最优,即使对于挑战性很强的全新数据集SOC。本文方法明显优于经典的算法,其测试结果F-measure提升了1.96%,加权F-measure提升了3.53%,S-measure提升了0.94%,E-measure提升了0.26%。实验结果表明,提出的模型有效提高了显著性检测的正确率,能够适用于各种复杂的环境。
显著性检测;级联式;混合信息流;注意力机制

1 引 言
显著性检测是对人类视觉注意力机制进行建模,准确定位图像中最重要的前景信息。作为计算机视觉任务的预处理过程,其类型众多,在静态图像中有RGB图像显著性检测[1],光场显著性检测[2],融合深度信息的显著性检测[3]以及高分辨率的显著性检测[4]。在视频场景中有目标显著性检测[5]和注视点显著性检测[6]。
本文研究聚焦于对象级的显著性检测,其实现方法很多,可以归纳为两类:早期的计算方法和基于深度学习的方法。早期的方法主要基于各种手工特征设计显著性检测模型,由于人眼对视觉中心和周围的敏感性[7]具有一定的差异,对比度[8]成为一种广泛的研究特性,其他手工特征还包括中心先验[9]、背景先验[10]等。近年来,基于深度学习的显著性检测方法已经显示出令人印象深刻的结果。整合卷积神经网络的层次特征来实现多尺度特征融合的方法是当前的趋势。
近几年,许多研究者通过集成层次化的卷积特性,实现细粒度的显著性检测。这是因为更深层次的卷积特征倾向于对高层次知识进行编码,能够更好地定位突出的目标,而较低层次的卷积特征更有可能捕获丰富的空间信息。Liu等人[11]将提取的多层特征输入多个子网络,预测最高分辨率的显著图,并直接融合,取得了较好的效果。但是多个子网络的方式可能会导致不同尺度的特征信息混淆,难以准确获得复杂区域边界。因此,Liu等人[12]采用了由粗到细的特征提取方法,通过引入递归聚合方法,将各级初始特征融合在一起,逐级生成高分辨率的语义特征,并结合全局和局部的注意力机制,较好地解决了这一问题。尽管这类方法取得了良好的性能,但该方法中高层的语义信息逐层传输到浅层,所捕获的深层位置信息逐渐稀释或缺失。并且该方法中堆积大量的注意力模块,导致前景和背景区分不明显的部分的边缘模糊,某些层次的不准确信息还会导致错误检测。采用逐层融合的方式,解决了显著性目标稀释的问题。然而,由于逐级生成,随着网络深入,其特征逐渐由低级特征向高级特征发生转变,过多的低层次特征带来更多的空间细节,但这将导致高层特征无法获取准确的显著性目标,使得模型在复杂情况下可能失效。
为了有效整合多层的特征,本文借鉴多分类器级联在目标检测任务[13]上的良好性能,构建了一种用于显著性检测的多层子网络级联式全卷积神经网络框架。和逐级融合的方式不同,该模型抛弃了大量冗杂的低层特征,仅利用较高层的特征进行处理,有效避免了引入过多的低层信息,导致模型误判。为了使得子网络生成尽可能精确的显著图,引入混合信息流机制,捕捉更加有效的上下文信息,以确保子网络得到的显著图不会出现漂移。同时,利用中间层生成的显著性映射嵌入注意力机制来细化高阶特征,滤除噪声的同时改善信息流的传递方式,增强了多尺度显著性特征的有效性。与现有的显著性检测方法相比,该方法通过级联式多级细化,从而获得多层次的表征信息;利用通道组合的方式融合多分支信息流,从而获得更为有效的上下文信息,并结合注意力机制增强了显著性特征信息,从而提高了显著性检测的性能。
2 算法理论推导
在显著性检测中,信息的提取和流动方式决定了最终特征融合的效果。本文提出的多层子网络级联式混合信息流框架如图1所示。输入的图像经骨干网络处理后,获取的多层次特征分别进入不同的子网络,每一个子网络由混合信息流模块获取显著性特征信息,并将获得的三个尺度的特征经通道融合的方式整合。由于直接利用各阶段深层次的卷积特征提取显著性对象仍然存在一定的不足,因此本文使用注意力机制,将该层次的信息过滤后流入更深的层次中,从而辅助深层提取显著性信息。最后经非线性加权融合后即可获得准确的显著图。
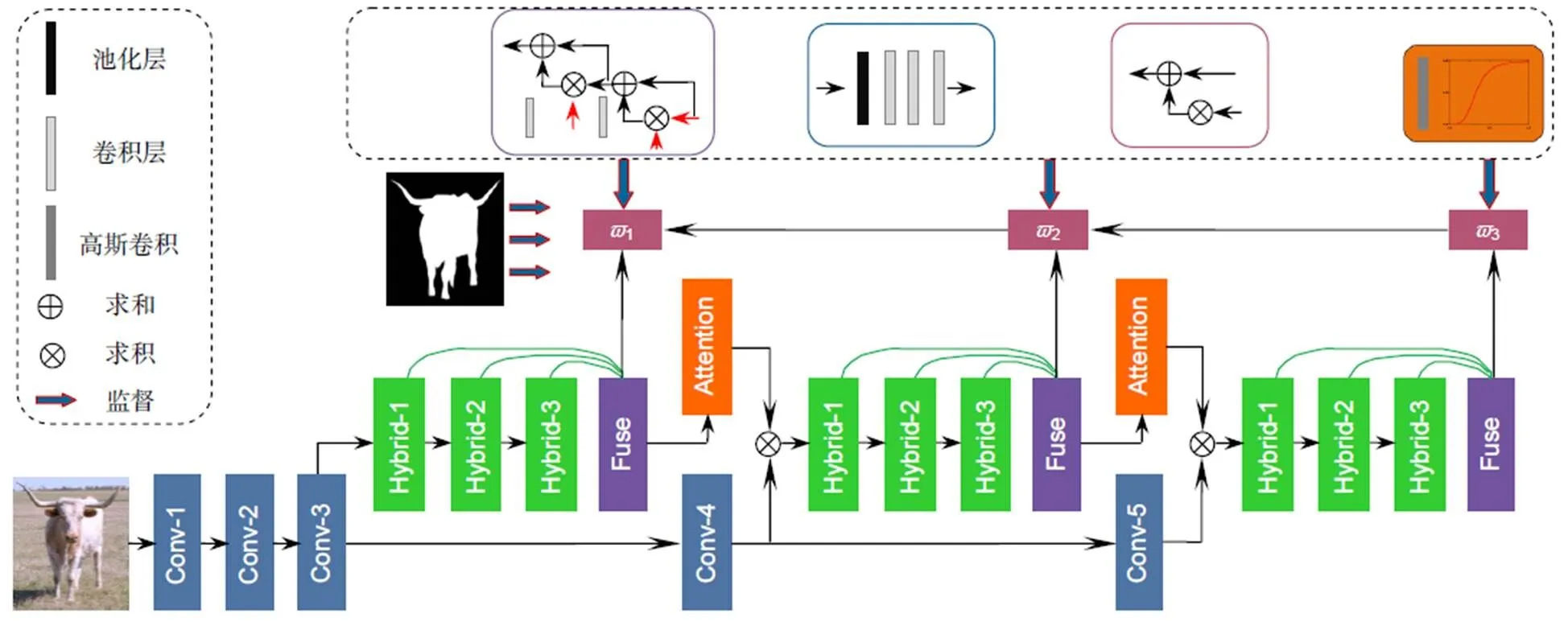
图1 基于多层子网络级联式混合信息流的显著性检测模型
2.1 级联式主框架
全卷积神经网络[14](FCNs)是显著性检测模型中应用最为广泛的网络,该网络模型的较浅层能提取到低层次特征,较深层能提取到更有效的高层次特征。本文将FCNs[14]作为骨干网络获得多层次特征,并采用级联式混合信息流方式进行多尺度特征融合,有效避免了FCNs[14]对应点聚合的弊端,形成更加丰富的特征信息。
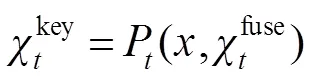

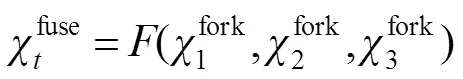
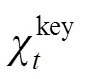
2.2 混合信息流
当显著性目标结构复杂时,单个层次的特征往往无法提供足够的细节辨别能力,为了区分前景和复杂的背景信息,需要准确获取空间上下文信息。本文增加了一组混合任务分支,用于建立整个图像像素的上下文语义关联信息。具体是将前一分支的掩码特征反馈到当前掩码特征,采用直连方式加强掩码分支之间的信息流,利用分层式结构和新增的特征融合层实现多尺度最优融合。上下文信息是对多尺度特征的有效补充,因此组合他们可以获得更好的预测结果。
该模块首先通过1´1的卷积层将特征投影到一个不同的特征空间,接着,为了充分构建多个层次之间的上下文信息,利用´1和1´对流层来处理这些特征,并将结果反馈到每一个分支进行处理,其中=(3, 3, 5, 7),以得到多个层次的特性并弥补不同特征在空间语义上的不足,如图2所示。此外,为了扩大各分支的感知区域,采用相对应大小的扩张卷积进行上采样解码。最后将转换后的不同层次特征图通过连接进行融合,使得模型捕获到任意空间位置在不同尺度下的上下文语义信息。结合本地特征对融合后的特征图进行补充,利用ReLU消除冗杂信息,从而建立显著性对象区域的上下文信息。
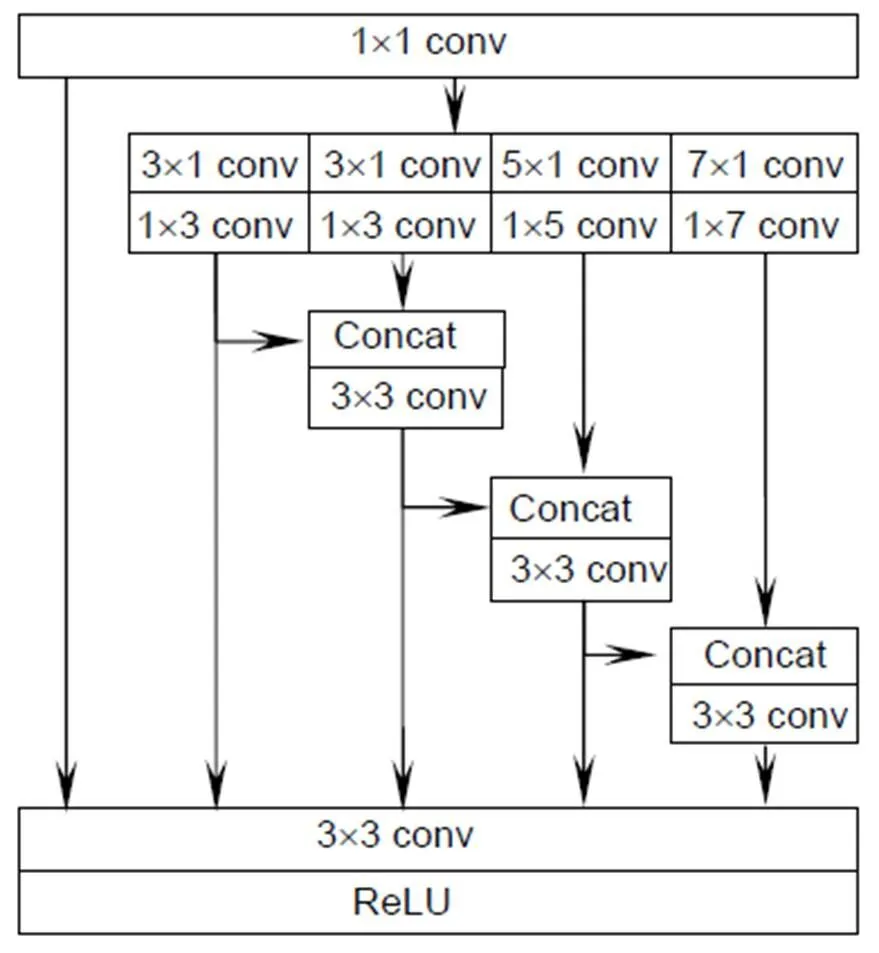
图2 混合信息流
密集连接有利于改善特征的表示方式,提升显著性检测性能。本文将深层次的语义特征与各层次的上下文信息结合,从而建立不同层之间的连接关系,实现多分支之间的语义信息交互。为了解决语义信息的融合问题,采用通道组合的方式,逐步融合高层的语义信息以获取更有效的上下文信息,并将上采样处理后采用卷积层对融合后的特征图进行平滑处理,使得下一步融合更加有效。该机制如下所示:
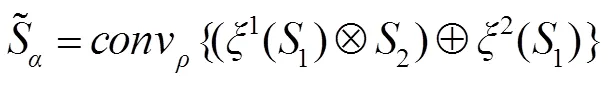
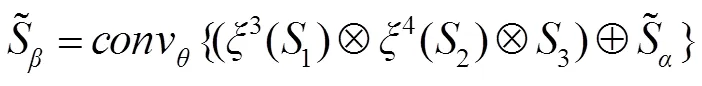
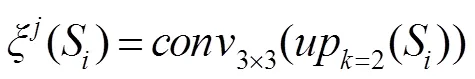
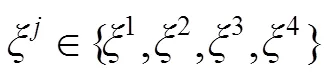
为了验证该机制的有效性,本文对其附近的特征图进行了可视化处理。如图3所示,其中图3(a)、3(b)列表示较浅层的特征信息,能够凸出显著性目标的空间细节信息,图3(c)、3(d)列表示深层次的特征映射,能够很好地定位显著性目标。经混合信息流机制处理后特征图3(a)、3(c)相对于未处理的特征图3(b)、3(d),能够更好地捕获显著性目标的空间细节以及定位信息,有助于模型持续关注图像中的显著性对象。
2.3 注意力机制
混合信息流机制能够获得不同层次特征之间的上下文语义信息,但是不同层次的语义信息比较独立,难以在全局范围内构建信息网络流。本文提出了一种注意力机制,弥补了混合信息流机制的不足,实现了不同层次特征的语义信息传递方式。该机制引入高斯滤波方式,降低噪声特征,提高模型对边界区域的感知性能。再将特征图映射到[0,1],利用(×)函数的分类机制,提高深层次中显著性目标区域的权值,并且减小了非显著性区域的权值,从而增强了全局注意力图。最后将空间注意力图作为权重与骨干特征的各个通道相乘,得到带有空间注意力的特征¢。计算方式:
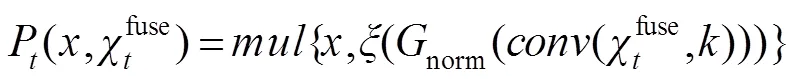
, (8)
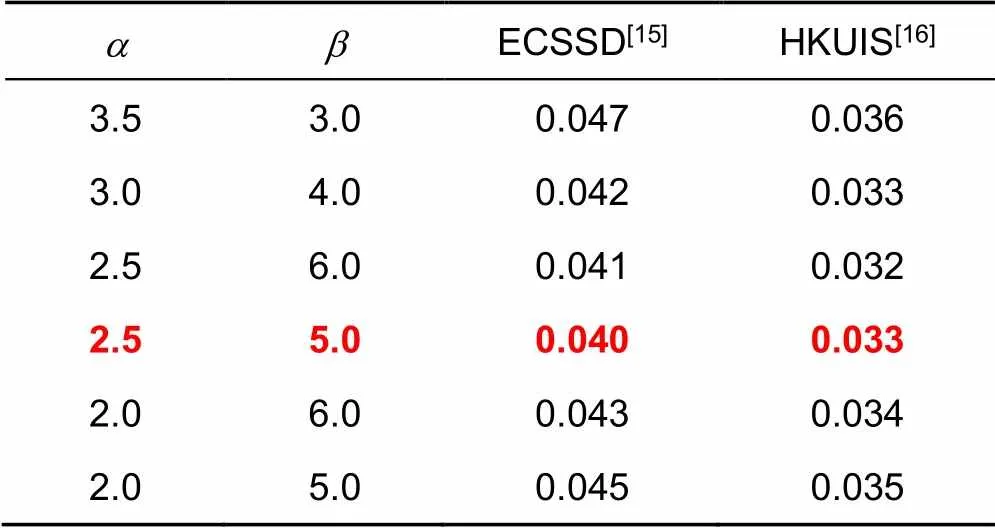
表1 x(×)函数参数选择
3 实验步骤
3.1 实验细节
本文实验基于PYTORCH框架实现,使用NVIDIA GeForce GTX 1080Ti GPU进行加速训练。训练阶段采用VGG-16预训练模型初始化骨干网络参数。利用数据集作为训练集,包含10553幅图像,将输入图像大小调整为350´350,仅使用简单的随机水平翻转来增强数据集。模型采用Adam优化器,初始化学习率为5e-5,衰减权值为5e-4,共进行25个epoch。采用的目标函数[17]为
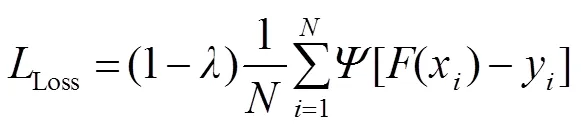
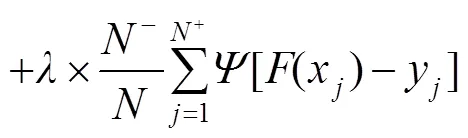
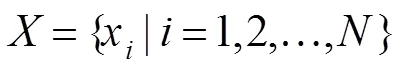
3.2 数据集
本文使用5个显著性基准数据集评估本文的模型,分别为ECSSD[15]、PASCAL[18]、DUT-OMRON[19]、HKUIS[15]和DUTS[20],其中ECSSD[15]有1000个语义上有意义且复杂的图像,包含各种复杂的场景。PASCAL[18]数据集由850幅图像组成,均是带有像素级注释的自然图像。DUT-OMRON[19]包括5168张具有挑战性的图片,每张图片通常都有复杂的背景。HKUIS[15]包含4447张低对比度的图片,每张图片中都有多个前景对象。DUTS[19]数据集是目前数量最多的显著性检测基准数据集,包含了用于训练的10553张图像(DUTS-TR)和测试评估的5019张图像(DUTS-TE)。该数据集大多数显著性目标位置和规模不同,并具有复杂的背景。除此之外,本文对一个全新的数据集SOC[21]进行了探索研究,它包含日常物体类别中显著和非显著物体的图像,并且显著图像含有单个或多个显著性目标。除了对象类别注释之外,每个显著的图像都伴有反映现实场景中常见挑战的属性,极具挑战性。
3.3 评估指标
本文使用2个常用指标(F-measure[22],平均绝对误差(MAE)[23])以及最近提出的3个新的指标(加权F-measure[24],S-measure[25],E-measure[26])进行评估。
1) F-measure[22]():将预测的显著图与其对应的真值图进行对比,通常使用一个阈值来将一个显著性映射二值化成一个前景掩码映射,计算出平均准确率(Precision,用P表示)和召回率(Recall,用R表示):
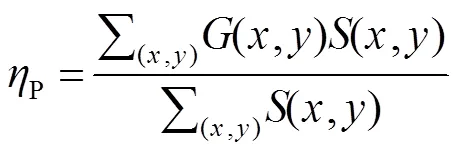
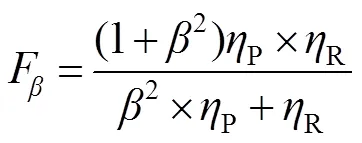
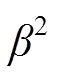
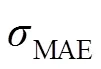
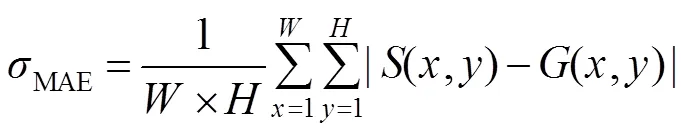
其中:和表示显著图的宽度和高度,(,)和(,)表示像素(,)处的显著性值和二元真值。MAE分数越小,显著图与真值图之间相似程度高。
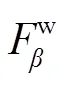
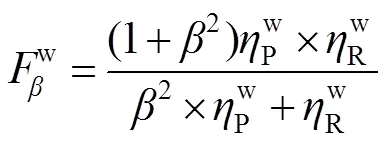
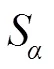
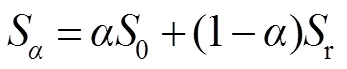
5) E-measure[26](m):最近Fan等人提出了一种增强定位度量的方法,该指标能够主动适应度量整体与局部的显著性差异。为了比较非二值显著性映射和二值映射,我们采用了一种类似于上述最大F-measure的方法,首先通过运行所有可能的阈值将显著性映射二值化,再将两个二进制映射的全局平均值对其进行对齐,然后计算局部像素相关性,最后得出最大m,如下所示:
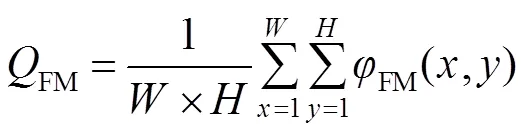
4 实验结果与分析
4.1 定量分析
对现有的8个模型进行了比较,其中包括7个基于深度学习的模型与1个传统的显著性模型,基于深度学习的模型包括:DCL[27](深度对比学习),DSS[28](具有短连接的深度监督模型),DHS[29](深度分层学习),Amulet[30](聚合多层次特征模型),DLS[31](深层次聚合),NLDF[32](非线性深度连接),SRM[33](逐步修正模型),同时本文对比了一种传统方法:DRFI[34](区域特征融合)。DCL[27],DSS[28],DHS[29],Amulet[30],DLS[31],NLDF[32]利用VGG-16作为骨干网络,而SRM[33]是在ResNet-50上实践。实验结果如表2~5所示,其中,-TR-表示该数据集作为该方法的训练集,红色表示方法的最优结果,蓝色表示方法的次优结果。
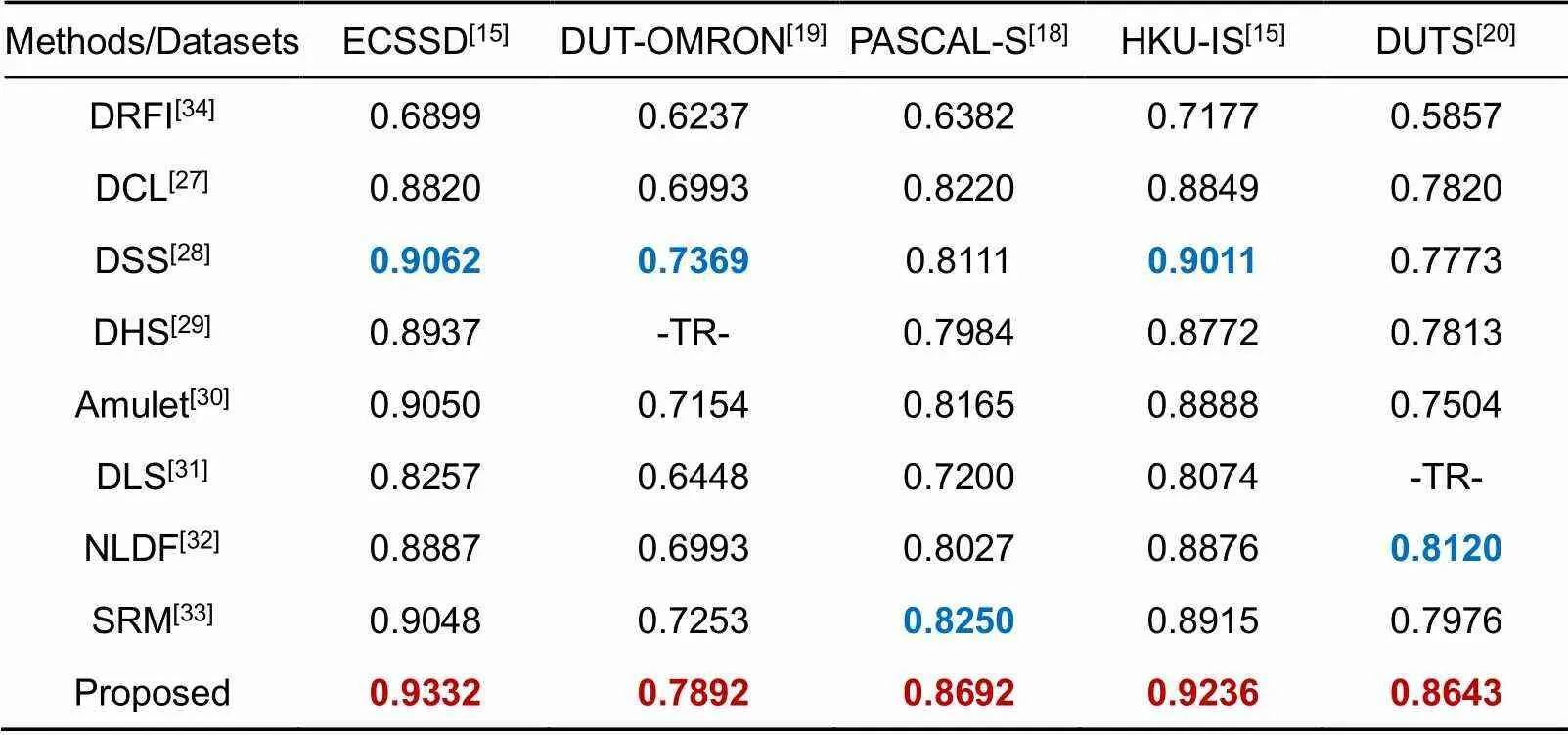
表2 在5个基准数据集的Fb评分结果(越高越好)
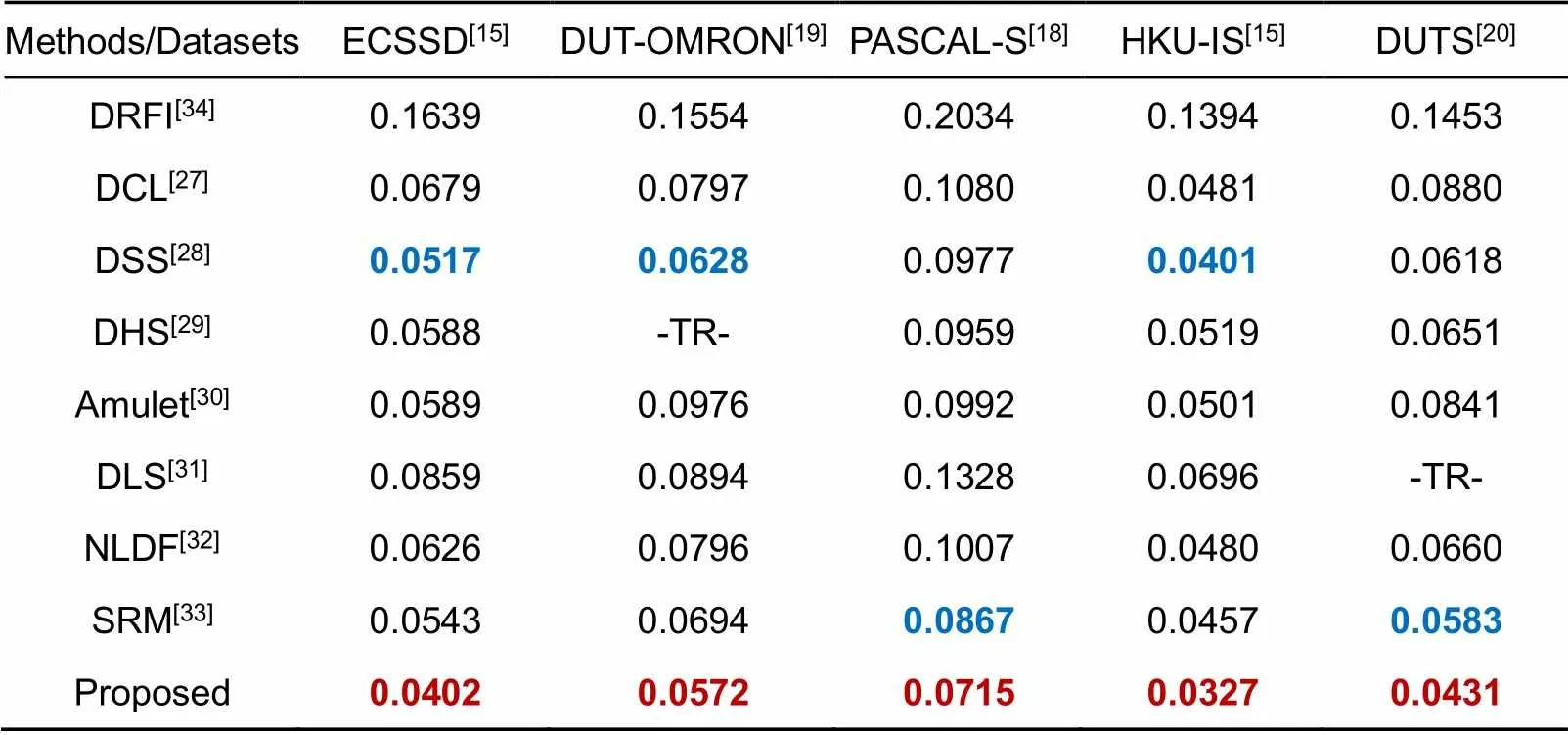
表3 在5个基准数据集的MAE评分结果(越低越好)
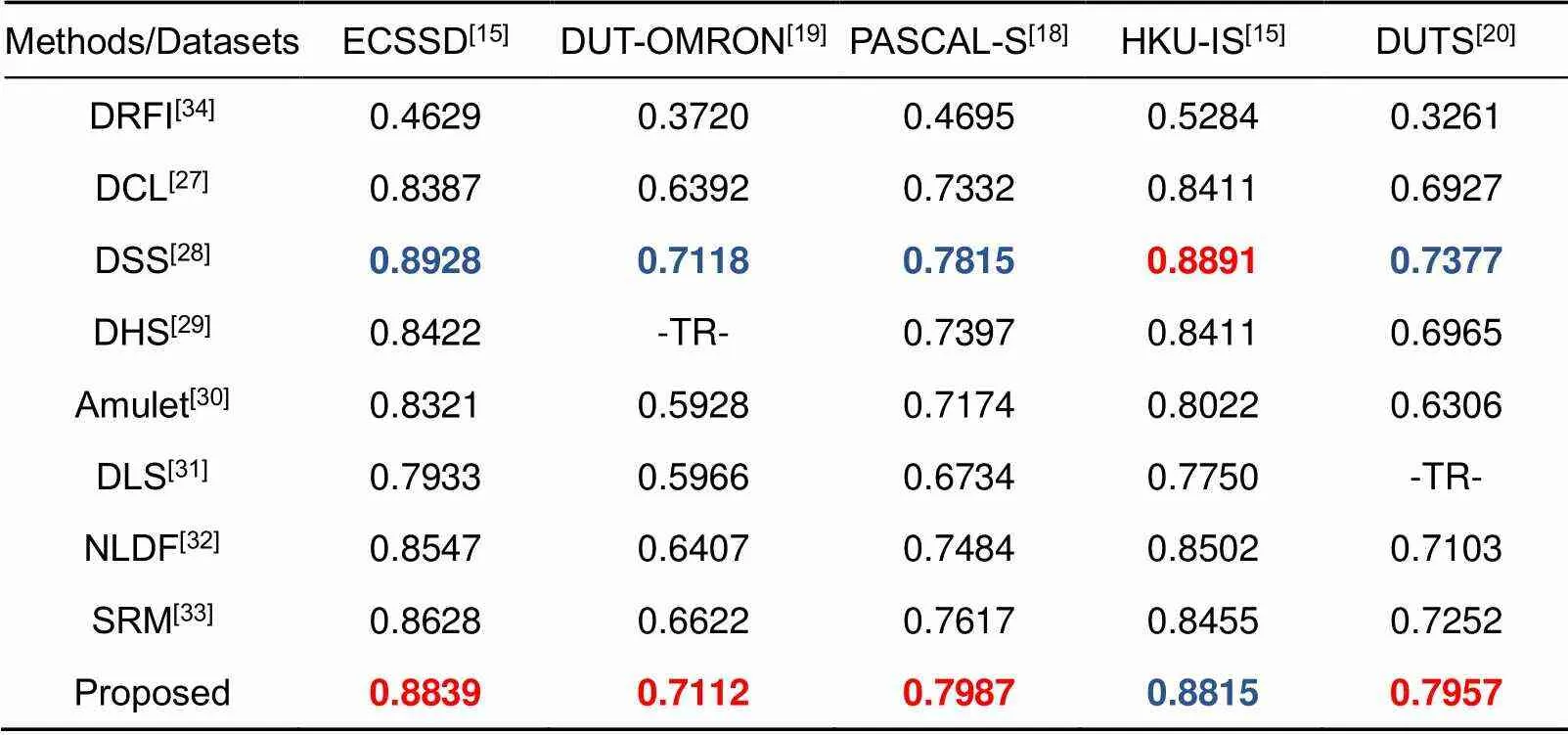
表4 在5个基准数据集的Fwb评分结果(越高越好)
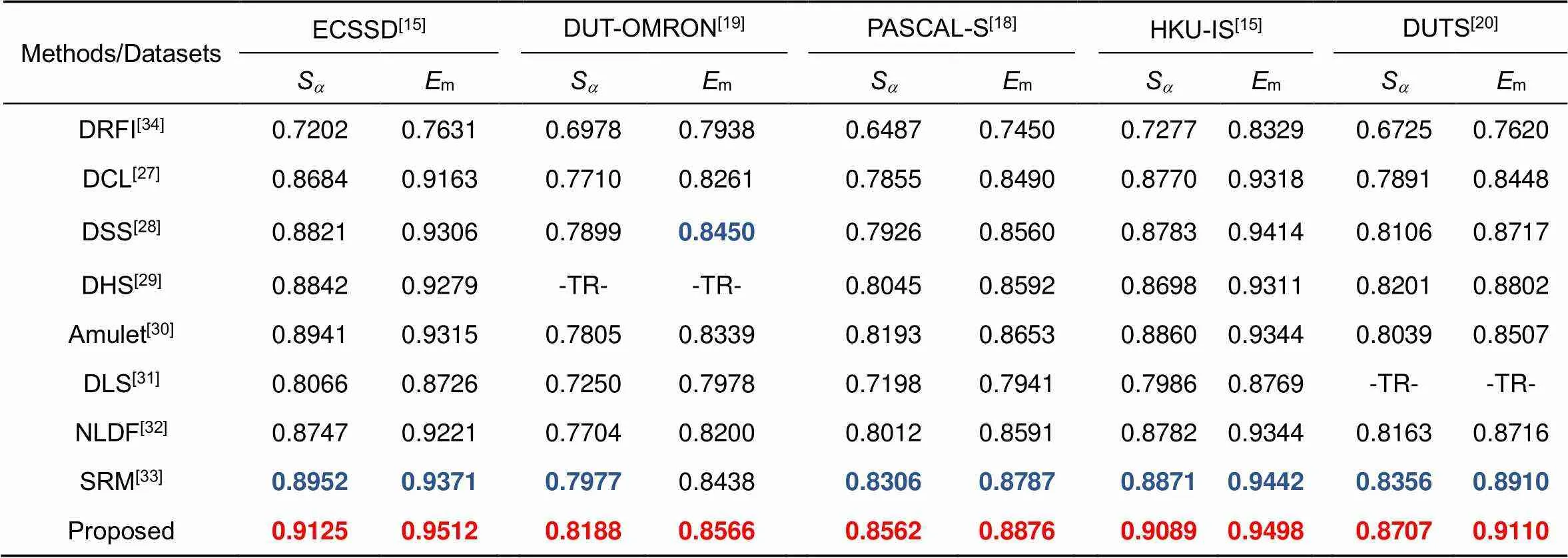
表5 在5个基准数据集的Sa和Em评分结果(越高越好)
此外,本文对SOC数据集进行了评估,这是最近提出用于显著性检测的一个全新数据集,具有很强的挑战性。与DCL[27]、DSS[28]、DHS[29]、RFCN[35]、NLDF[32]、SRM[33]这6种先进的算法进行比较,如表6所示(最优结果红色标记)。所提方法能够很好地适应这样一个新的数据集,在各个指标下均达到最优结果,进一步说明本文模型的准确性与鲁棒性。
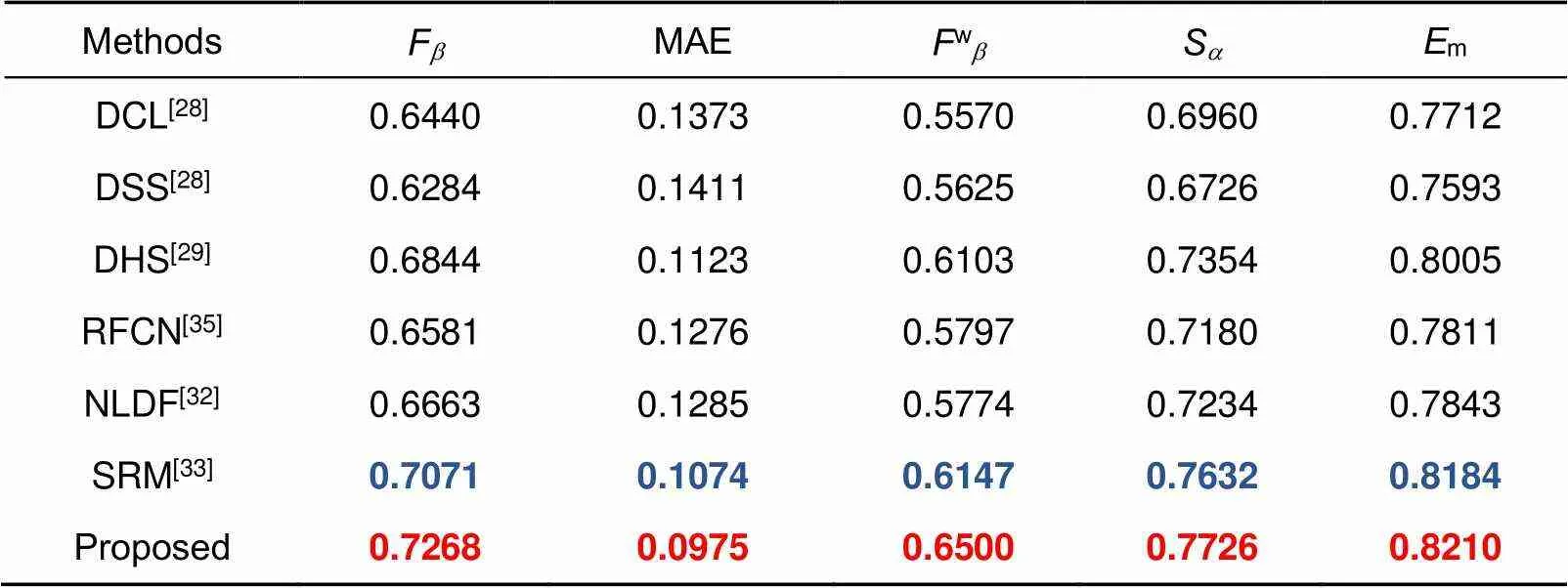
表6 在SOC基准数据集的测试结果
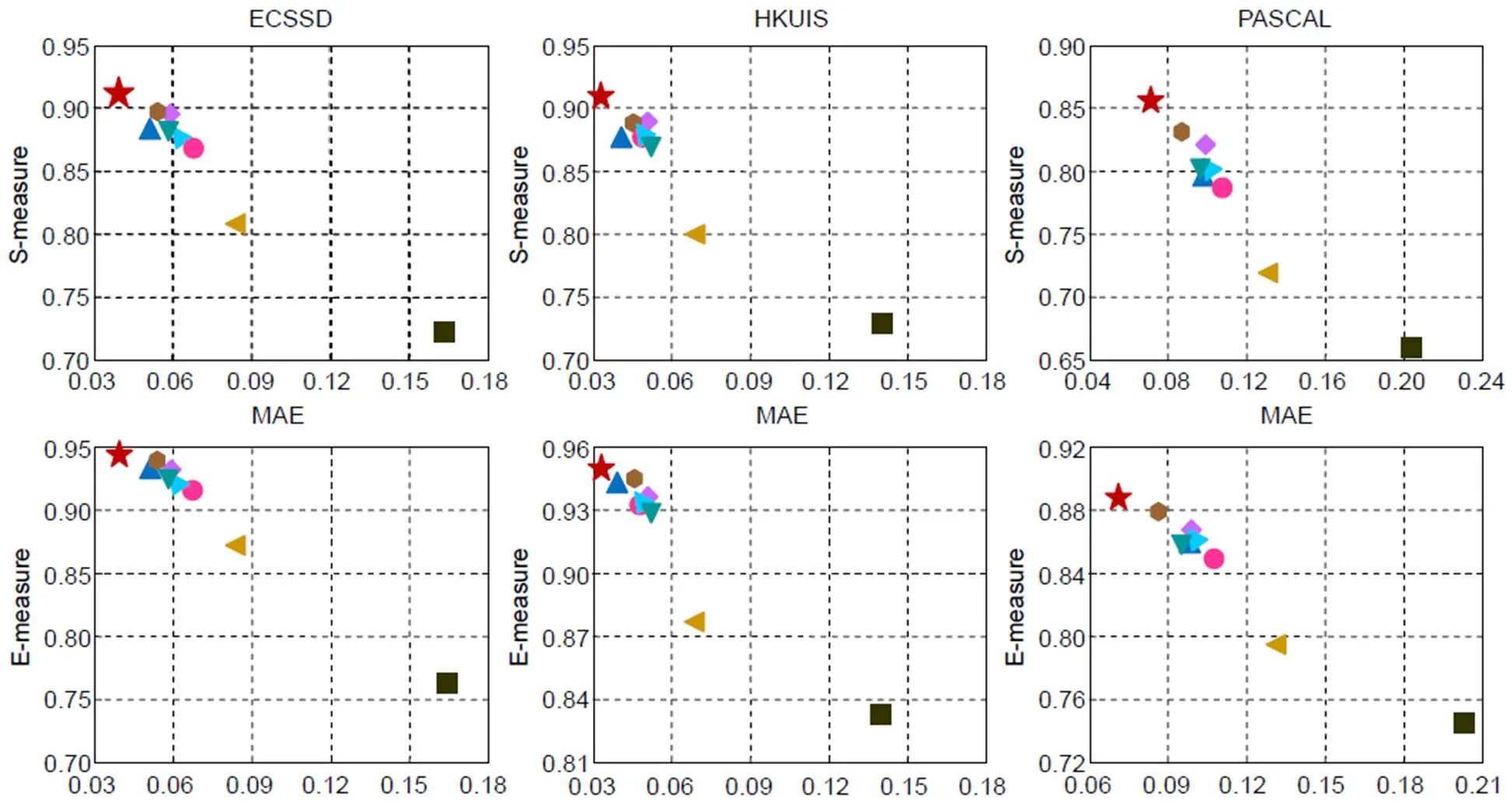
为了更加直观地表明评价之间的关系,本文对MAE与,m的分布趋势进行关联分析,如图4所示。本文的方法基本位于最左上角,在平均绝对误差MAE减小的前提下,和m均有提升,表明所提方法能够更加突出前景区域和结构。这主要得益于混合信息流方式集成各个阶段互补特性,逐步学习更多具有辨别的特征信息,同时结合注意力机制使得信息之间可以实现非线性流动,从而使得最终的显著性映射集成了更多有效的多尺度的上下文信息。
4.2 定性对比分析
为了进一步说明本文方法的优点,在图5中给出了部分数据的可视化结果。红色方框内是本文结果与真值图,可以得出该方法能够准确地识别图像中最显著的目标对象,并且几乎在所有情况下都能保持其尖锐的边界分割,目标区域高亮均匀,在特征融合以及抗噪性能方面达到了最优效果。
4.3 时间复杂度分析
本文利用ECSSD[15]数据集作为测试,比较不同算法的运行时间与精度如表7。从表7可以看出,与DHS[29]、DSS[28]、NLDF[32]、Amulet[30]、SRM[33]算法相比,所提算法在保证处理效率的同时,精度大有提高,体现了本文算法的高效性。
4.4 有效性验证
为了验证本文提出的混合信息流、注意力机制以及非线性加权融合方式的有效性,在本文提出的级联框架上对各模块进行实验分析。分别用两层卷积替换对比,采用DUTS-TR[19]数据集作为训练集,DUTS-TE[19]数据集作为测试集,结果如表8所示,最佳结果用红色突出显示。实验结果说明,各个模块对模型精度都有一定的提升,缺失任何模块都会对模型精度造成影响。

图5 本文算法与其他模型定性比较结果

表7 时间复杂度对比(ECSSD[15]-MAE)

表8 基于DUTS-TE[19]数据集的有效性分析

图6 (a) 原图;(b) FCNs网络;(c) FCNs+级联方式;(d) 加入混合信息流机制后的效果;(e) 引入注意力机制的效果;(f) 非线性融合
由图6中的显著性映射可以看出,在一些复杂的场景中,仅使用骨干网络很难定位出显著的目标,结果较为模糊。引入级联式框架后,得到的显著图的质量有较大的改善。结合混合信息流以及注意力机制,显著的区域可以被精确地分割,从而说明了本文模型的有效性。
5 结 论
本文提出的子网络级联式混合信息流框架,有效解决了复杂场景下的显著性检测方法存在多尺度融合问题。该方法结合了级联式的优势,提出的混合信息流机制可充分提取各层次特征,并利用注意力机制增强特征提取。最后通过非线性方式融合不同尺度的特征信息,取得了很好的效果。在5个广泛使用的基准数据集上进行定量分析,5个评估指标均达到最优,同时在一个全新的SOC数据集上测试结果达到最佳,有效地验证了本文模型的准确性与鲁棒性。通过可视化定性分析,同时对不同指标结果进行关联分析和运行速度分析,验证了所提模型的性能都有较大提升。本文还对级联式框架、混合信息流机制、注意力机制进行了有效性验证,进一步说明了所提方法的良好效果。
[1] Zhang X D, Wang H, Jiang M S,. Applications of saliency analysis in focus image fusion[J]., 2017, 44(4): 435–441.
张学典, 汪泓, 江旻珊, 等. 显著性分析在对焦图像融合方面的应用[J]. 光电工程, 2017, 44(4): 435–441.
[2] Piao Y R, Rong Z K, Zhang M,. Deep light-field-driven saliency detection from a single view[C]//, 2019: 904–911.
[3] Zhao J X, Cao Y, Fan D P,. Contrast prior and fluid pyramid integration for RGBD salient object detection[C]//, 2019: 3927–3936.
[4] Zeng Y, Zhang P P, Lin Z,. Towards high-resolution salient object detection[C]//, 2019: 7233–7242.
[5] Fan D P, Wang W G, Cheng M M,. Shifting more attention to video salient object detection[C]//, 2019: 8554–8564.
[6] Shen C, Huang X, Zhao Q. Predicting eye fixations on webpage with an ensemble of early features and high-level representations from deep network[J]., 2015, 17(11): 2084–2093.
[7] Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis[J]., 1998, 20(11): 1254–1259.
[8] Perazzi F, Krähenbühl P, Pritch Y,. Saliency filters: Contrast based filtering for salient region detection[C]//, 2012: 733–740.
[9] Zhao H W, He J S. Saliency detection method fused depth information based on Bayesian framework[J]., 2018, 45(2): 170341.
赵宏伟, 何劲松. 基于贝叶斯框架融合深度信息的显著性检测[J]. 光电工程, 2018, 45(2): 170341.
[10] Wei Y C, Wen F, Zhu W J,. Geodesic saliency using background priors[C]//, 2012: 29–42.
[11] Liu J J, Hou Q, Cheng M M,. A Simple Pooling-Based Design for Real-Time Salient Object Detection[C]//, 2019: 3917–3926.
[12] Liu N, Han J W, Yang M H. PiCANet: Learning pixel-wise contextual attention for saliency detection[C]//, 2018: 3089–3098.
[13] Chen K, Pang J M, Wang J Q,. Hybrid task cascade for instance segmentation[C]//, 2019: 4974–4983.
[14] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//, 2015: 3431–3440.
[15] Yan Q, Xu L, Shi J P,. Hierarchical saliency detection[C]//, 2013: 1155–1162.
[16] Li G B, Yu Y Z. Visual saliency based on multiscale deep features[C]//, 2015: 5455–5463.
[17] Xi X Y, Luo Y K, Wang P,. Salient object detection based on an efficient end-to-end saliency regression network[J]., 2019, 323: 265–276.
[18] Li Y, Hou X D, Koch C,. The secrets of salient object segmentation[C]//, 2014: 280–287.
[19] He X M, Zemel R S, Carreira-Perpinan M A. Multiscale conditional random fields for image labeling[C]//, 2004: II.
[20] Wang L J, Lu H C, Wang Y F,. Learning to detect salient objects with image-level supervision[C]//, 2017: 136–145.
[21] Fan D P, Cheng M M, Liu J J,. Salient objects in clutter: bringing salient object detection to the foreground[C]//, 2018: 186–202.
[22] Cheng M M, Mitra N J, Huang X L,. Global contrast based salient region detection[J]., 2015, 37(3): 569–582.
[23] Cheng M M, Warrell J, Lin W Y,. Efficient salient region detection with soft image abstraction[C]//, 2013: 1529–1536.
[24] Margolin R, Zelnik-Manor L, Tal A. How to evaluate foreground maps[C]//, 2014: 248–255.
[25] Fan D P, Cheng M M, Liu Y,. Structure-measure: a new way to evaluate foreground maps[C]//, 2017: 4548–4557.
[26] Fan D P, Gong C, Cao Y,. Enhanced-alignment measure for binary foreground map evaluation[C]//, 2018: 698–704.
[27] Li G B, Yu Y Z. Deep contrast learning for salient object detection[C]//, 2016: 478–487.
[28] Hou Q B, Cheng M M, Hu X W,. Deeply supervised salient object detection with short connections[C]//, 2017: 3203–3212.
[29] Liu N, Han J W. DHSNet: deep hierarchical saliency network for salient object detection[C]//, 2016: 678–686.
[30] Zhang P P, Wang D, Lu H C,. Amulet: aggregating multi-level convolutional features for salient object detection[C]//, 2017: 202–211.
[31] Hu P, Shuai B, Liu J,. Deep level sets for salient object detection[C]//, 2016: 2300–2309.
[32] Luo Z M, Mishra A, Achkar A,. Non-local deep features for salient object detection[C]//, 2017: 6609–6617.
[33] Wang T T, Borji A, Zhang L H,. A stagewise refinement model for detecting salient objects in images[C]//, 2017: 4039–4048.
[34] Jiang H D, Wang J D, Yuan Z J,. Salient object detection: a discriminative regional feature integration approach[C]//, 2013: 2083–2090.
[35] Wang L Z, Wang L J, Lu H C,. Saliency detection with recurrent fully convolutional networks[C]//, 2016: 825–841.
Saliency detection hybrid information flows based on sub-network cascading
Dong Bo, Wang Yongxiong*, Zhou Yan, Liu Han, Gao Yuanzhi, Yu Jiamin, Zhang Mengyin
Institute of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China
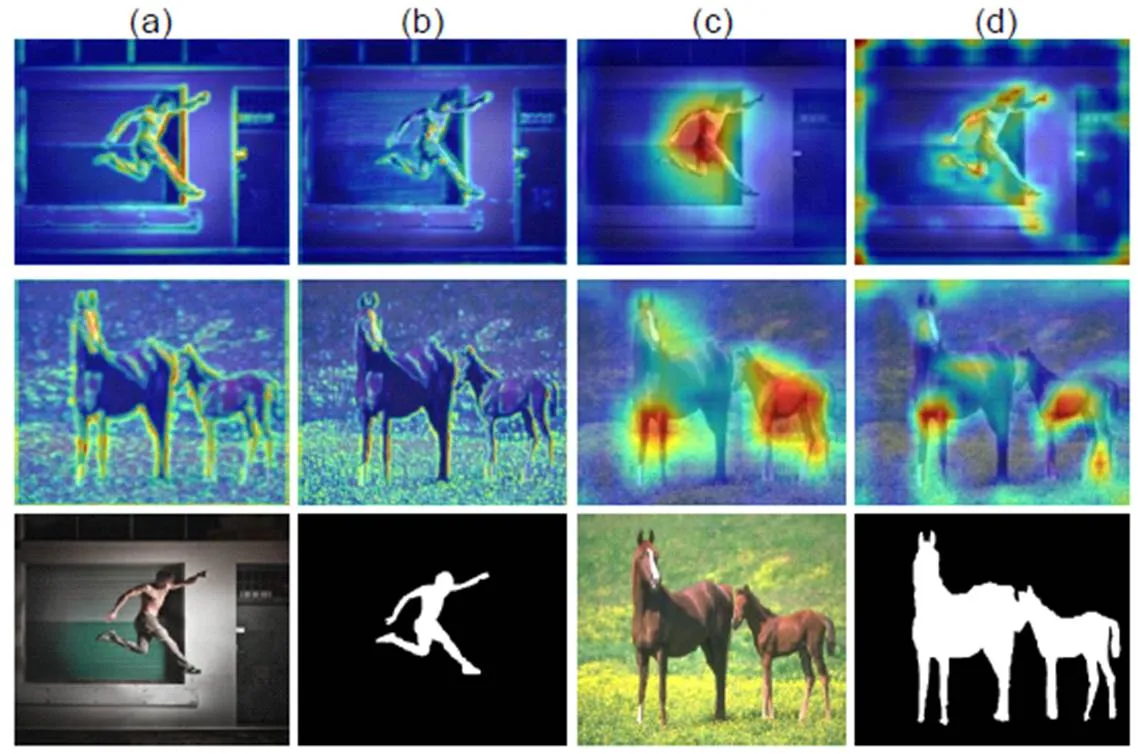
Visual comparison before and after hybrid information flows
Overview:Saliency detection (SOD) is to detect and segment most important foreground objects that are modeled to accurately locate the mechanism of human visual attention. It has many types, including RGB SOD, light field SOD, RGB-D SOD, and high-resolution SOD. In the video scene, there are object SOD and fixation SOD, while the specific task is broken down into object-level saliency detection and instance-level significance detection. In view of the multi-scale feature fusion problem existing in the complex scenario of the existing saliency object detection algorithms, a fusion method of multi-layer sub-network cascade hybrid information flows is proposed in this paper. First of all, the FCNs backbone network and feature pyramid structure are used to learn multi-scale features. Then, through the multi-layer sub-network layering mining to build a cascading network framework, the context information of the characteristic of each level is fully used. The method of information extraction and flows determines the effect of final feature fusion, so we use the hybrid information flows to integrate multi-scale characteristics and learn more characteristic information with discernment. In order to solve the problem of semantic information fusion, high-level semantic information is used to guide the bottom layer, obtaining more effective context information. In this paper, we adopt the way of channel combination fusion, and the sampling processing is accompanied by the convolution layer smoothing the fusion feature map, making the next fusion more effective. Finally, the effective saliency feature is transmitted as mask information, which realizes the efficient transmission of information flows and further distinguishes the foreground and messy background. Finally, the multi-stage saliency mapping nonlinear weighted fusion is combined to complement the redundant features. Compared with the existing 9 algorithms on the basis of the 6 public datasets, the run speed of the proposed algorithm can reach 20.76 frames and the experimental results are generally optimal on 5 evaluation indicators, even for the challenging new dataset SOC. The proposed method is obviously better than the classic algorithm. Experimental results were improved by 1.96%, 3.53%, 0.94%, and 0.26% for F-measure, weighted F-measure, S-measure, and E-measure, respectively, effectively demonstrating the accuracy and robustness of the proposed model. Through the visual qualitative analysis verification, the correlation analysis and running speed analysis of different indicators are carried out, which further highlights the superior performance of the proposed model. In addition, this paper verifies the effectiveness of each module, which further explains the efficiency of the proposed cascading framework that mixes information flow and attention mechanisms. This model may provide a new way for multi-scale integration, which is conducive to further study.
Citation: Dong B, Wang Y X, Zhou Y,Saliency detection hybrid information flows based on sub-network cascading[J]., 2020, 47(7): 190627
Saliency detection hybrid information flows based on sub-network cascading
Dong Bo, Wang Yongxiong*, Zhou Yan, Liu Han, Gao Yuanzhi, Yu Jiamin, Zhang Mengyin
Institute of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China
In view of the detail feature loss issue existing in the complex scenario of existing saliency detection algorithms, a fusion method of multi-layer sub-network cascade hybrid information flows is proposed in this paper. We first use the FCNs backbone network to obtain multi-scale features. Through the multi-layer sub-network layering mining to build a cascading network framework, the context information of the characteristic of each level is fully used. The detection and segmentation tasks are processed jointly. Multi-scale features are integrated by hybrid information flows, and more characteristic information with discernment is learned step by step. Finally, the embedded attention mechanism effectively compensates the deep semantic information as a mask, and further distinguishes the foreground and the messy background. Compared with the existing 9 algorithms on the basis of the 6 public datasets, the running speed of the proposed algorithm can reach 20.76 frames and the experimental results are generally optimal on 5 evaluation indicators, even for the challenging new dataset SOC. The proposed method is obviously better than the classic algorithm. Experimental results were improved by 1.96%, 3.53%, 0.94%, and 0.26% for F-measure, weighted F-measure, S-measure, and E-measure, respectively. These experimental results show that the demonstrating the proposed model has higher accuracy and robustness and can be suitable for more complex environments, the proposed framework improves the performance significantly for state-of-the-art models on a series of datasets.
saliency detection; cascade; hybrid information flows; attention mechanism
TP391
A
10.12086/oee.2020.190627
: Dong B, Wang Y X, Zhou Y,. Saliency detection hybrid information flows based on sub-network cascading[J]., 2020,47(7): 190627
董波,王永雄,周燕,等. 基于子网络级联式混合信息流的显著性检测[J]. 光电工程,2020,47(7): 190627
Supported by National Natural Science Foundation of China (61673276)
* E-mail: wyxiong@usst.edu.cn
2019-10-17;
2019-12-11
国家自然科学基金资助项目(61673276)
董波(1998-),男,主要从事机器视觉的研究。E-mail:535806671@qq.com
王永雄(1970-),男,博士,教授,主要从事智能机器人与机器视觉的研究。E-mail:wyxiong@usst.edu.cn
猜你喜欢
军事运筹与系统工程(2020年1期)2020-09-11 06:41:08
电子制作(2019年24期)2019-02-23 13:22:26
铁道通信信号(2018年12期)2019-01-31 05:36:40
军事运筹与系统工程(2018年1期)2018-11-10 05:33:12
西南交通大学学报(2018年5期)2018-11-08 10:58:04
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20 15:25:20
电子制作(2016年15期)2017-01-15 13:39:09
知识产权(2016年8期)2016-12-01 07:01:32
系统工程与电子技术(2016年2期)2016-04-16 05:16:51
军事运筹与系统工程(2015年3期)2015-09-08 13:12:35
