
基于SIFT-SVM的发动机主轴承盖识别与分类
2020-08-27 06:19石志良张鹏飞李晓垚
图学学报 2020年3期
石志良,张鹏飞,李晓垚
基于SIFT-SVM的发动机主轴承盖识别与分类
石志良,张鹏飞,李晓垚
(武汉理工大学机电工程学院,湖北 武汉 430070)
机械零部件的识别与分类任务是制造业自动化生产线的关键环节。针对发动机主轴承盖混合清洗后的分类,通过分析发动机主轴承盖零件的实际特征,提出基于SIFT-SVM的主轴承盖分类识别方法。该方法首先提取训练数据集图像的所有尺度不变(SIFT)特征向量,采用K-means聚类方法,将所有的特征向量聚类成K个分类,并将其代入词袋模型(BoW)中,使用K个“词汇”来描述每一张训练图像,从而得到图像的BoW描述。且以每张图像的BoW描述作为训练输入,使用支持向量机(SVM)训练主轴承盖的分类模型。实验结果表明:在标定的照明条件下,主轴承盖零件的识别率可达100%,单个零件识别时间为0.6 s,验证了该算法的有效性和高效性。
零件识别与分类;机器视觉;SIFT;词袋模型;支持向量机分类器
汽车发动机主轴承盖用于发动机曲轴定位,是汽车发动机的重要零部件之一。由于发动机的尺寸、造型及动力性能存在多样化,导致发动机主轴承盖的形状及尺寸有所不同。企业在实际生产过程中,通常是一条生产线同时生产几种类型的主轴承盖,经过混合清洗工序后,需要将不同种类的主轴承盖零件进行分类包装。目前通常是人工目视分类,工人需要长时间在生产一线工作,工作环境差、强度高、易疲劳甚至个人情绪都会降低分类的可靠性。通过引入机器视觉方法进行主轴承盖自动分类,有助于减轻一线工人繁重的体力劳动,同时提高零件分类的效率及可靠性。
随着图像识别算法的不断更新与优化,基于机器视觉的识别与分类系统受到越来越多国内外专家学者的关注。BHAT等[1]提出一种基于机器学习的机械加工车刀状态识别方法,该方法通过灰度共生矩阵提取加工表面的纹理特征,利用支持向量机(support vector machine,SVM)识别加工表面的质量,最终由加工表面质量与车刀状态的关系,完成车刀3种锐利状态的识别;OLGUN等[2]将基于SIFT-SVM的机器视觉系统应用于小麦的自动识别中,通过提取图像中小麦的尺度不变特征(scale- invariant feature transform,SIFT),然后在词袋模型(bag of word model,BoW)中得到小麦图像的词袋描述,最后使用SVM分类器得到了有效的分类结果,类似的方法还被应用于蜡染图像识别[3]、车辆识别[4]、手语图像识别[5]、三维人脸面部表情识别[6]等领域;KRÜGER等[7]利用涡轮机零部件自身的形状特征,通过构建带残差块的卷积神经网络ResNet-152进行识别训练,实验结果表明:对于50种形状差异明显的涡轮机零部件,其识别正确率可达96%,基于深度神经网络的方法还被应用于电子板缺陷图像分类[8]、水果和花卉图像分类[9]等领域。在结合图像分类方法及应用的基础上,本文提出一种基于机器视觉的机械零部件识别方法,用于发动机主轴承盖零件的识别与分类,实验结果证明了该方法的实用性和有效性。
1 基于SIFT-SVM的主轴承盖识别
在实际生产中,同一时段生产的多种主轴承盖零件,在不同的铸造生产线加工完成后,会合并到同一条生产线统一进行清洗、除锈,接着进入识别分类工序。对于不同种类主轴承盖零件,其外观尺寸差异小,底部半圆孔尺寸完全相同,因此选取零件的顶部侧边支撑面作为分类识别的目标区域,如图1所示。
发动机主轴承盖识别分类方法的具体流程如图2所示。在模型训练过程中,训练数据集全体主轴承盖图像的SIFT特征向量组合成特征矩阵,通过无监督聚类方法形成BoW模型的词汇集并保存,最终,以每张图像的词袋描述作为输入数据,由SVM分类器得到主轴承盖识别分类模型。

图1 5种发动机主轴承盖零件分类所依据的形状特征
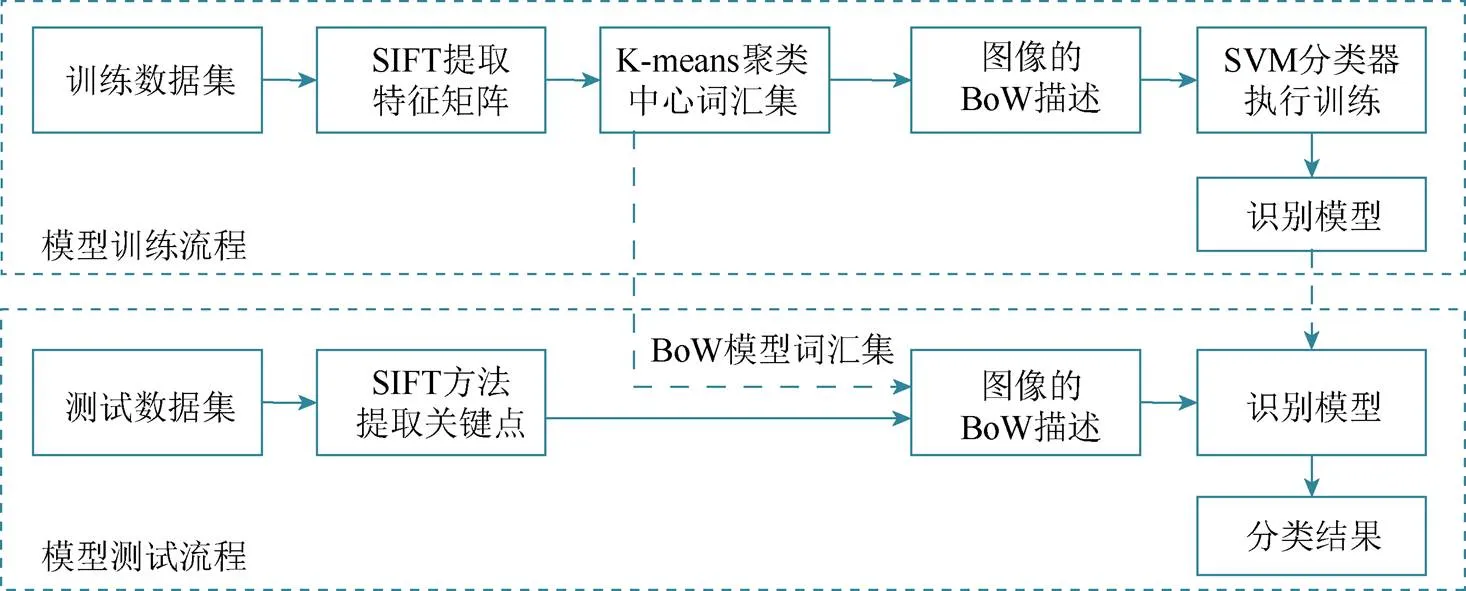
图2 发动机主轴承盖零件识别方法流程图
在进行实际分类识别时,将实时拍摄的主轴承盖图像,直接输入到识别系统中,通过SIFT方法提取图像的关键点,并结合训练时已保存的BoW模型词汇集,得到该主轴承盖图像的BoW描述,由此利用已经训练完成的识别模型,即可完成对当前主轴承盖的识别与分类。
2 发动机主轴承盖的具体识别过程
2.1 发动机主轴承盖识别系统的硬件组成
发动机主轴承盖识别系统的硬件部分,主要由物料传送、图像采集、辅助光源和识别处理4个模块组成。其简化模型如图3所示。

图3 主轴承盖识别系统的硬件组成
物料传送模块由驱动电机、差速器和传送带组成,差速器用于调整传送带的传输速度,控制生产节拍,并验证该节拍下的识别系统准确率。图像采集模块由单通道工业CCD相机、漫反射光电触发器组成,经过标定后的光电触发器,会在主轴承盖零件传送至靠近触发器的固定位置处,触发CCD相机进行图像捕捉,从而获得质量良好的主轴承盖零件图像。辅助光源模块由环形LED光源、电源和辅助遮光罩组成,采用的环形多角度照明方式,照射面积大、光照均匀、可展现各种类主轴承盖零件的差异性细节。另外,辅助遮光罩的设置,有效抑制了外界环境光照的影响,提升了采集图像的品质,提高了系统识别的准确率。识别处理模块主要由工业计算机组成,通过构建基于Visual Studio平台和OpenCV计算机视觉库的零件识别系统,在计算机上执行具体的识别与分类程序,实现识别模型的训练和应用。
2.2 主轴承盖图像关键点的提取
从主轴承盖图像中提取目标区域的有效关键点是完成其识别分类的根本依据,使用目标区域关键点信息来描述不同种类主轴承盖之间的差异,并将该描述作为分类输入是发动机主轴承盖识别方法的主要思路。理想的关键点应该集中于主轴承盖侧边支撑面形状的边缘或是几何中心等位置,以便突出不同种类主轴承盖侧边形状上的差异。
提取主轴承盖目标区域形状差异的关键点采用SIFT算法。SIFT是由LOWE[10]提出的一种局部特征描述子,其基于图像多尺度金字塔,综合考虑了各像素点处梯度的大小和方向,使得SIFT特征在旋转、尺度缩放、光照明暗变化等方面保持良好的不变性,并将检测多尺度空间下的局部极值点作为潜在关键点。首先将图像逐步下采样构成图像金字塔,其次,对每层图像,通过计算得到多张不同尺度的图像,形成尺度金字塔。SIFT方法通过二维高斯函数(,,),将图像的尺度空间(,,)定义为原图像(,)与高斯函数(,,)的卷积,即

式中,*表示图像卷积运算,高斯函数(,,)为
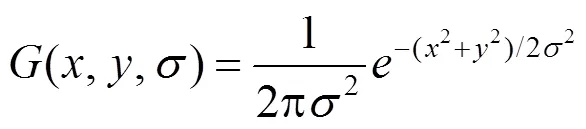
为提高局部极值点检测的效率与稳定性,SIFT使用高斯差分函数(difference of Gaussian,DoG)代替高斯-拉普拉斯算子(Laplacian of Gaussian,LoG),并由此计算出用于局部极值点求解的高斯差分图像(,,),即
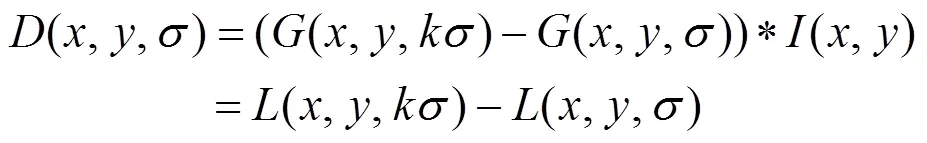
其中,为2个相邻尺度图像的分离系数。
尺度空间下的极值点,最终是由该样本点与当前图像相邻的8个像素点,以及上下两层尺度图像的各9个像素点,共26个最邻近像素点相比较得到的(图4)。
但是,由上述方法从离散尺度空间得到的极值点并不都是稳定的关键点,因为某些极值点可能存在于对比度较低区域,而且DoG算子具有较强的边缘突出效应,易受图像噪声影响。因此,需要对极值点进行进一步的插值和2筛选。
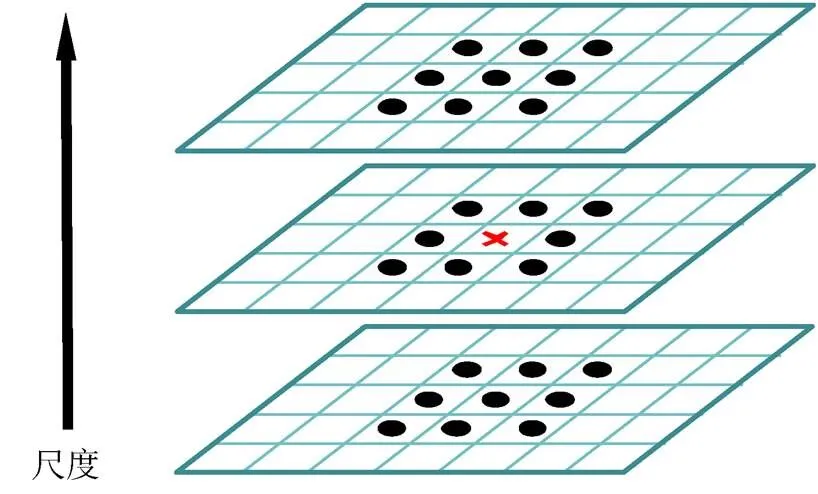
图4 高斯差分图像局部极值检测示意图


SIFT特征利用极值点的Hessian矩阵计算主曲率,筛选出处于不稳定边缘处或噪声处的极值点
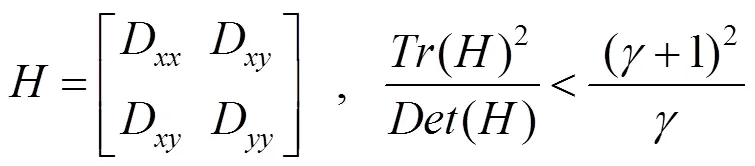
实验表明:取=10时,且仅保留满足上式的极值点,可以有效增强极值点的稳定性[10]。
经过筛选后的极值点,即确定为主轴承盖目标区域的稳定关键点。不同种类主轴承盖零件图像在侧边支撑面区域所提取的关键点如图5所示。
由图5可知,实际提取的关键点大部分稳定地集中于顶部侧边支撑面的边缘位置,同时对于中间圆形螺栓孔的定位非常精准。这些关键点可以很好地描述不同种类主轴承盖零件间的形状差异,为组建BoW模型提供了稳定的“词汇”信息。
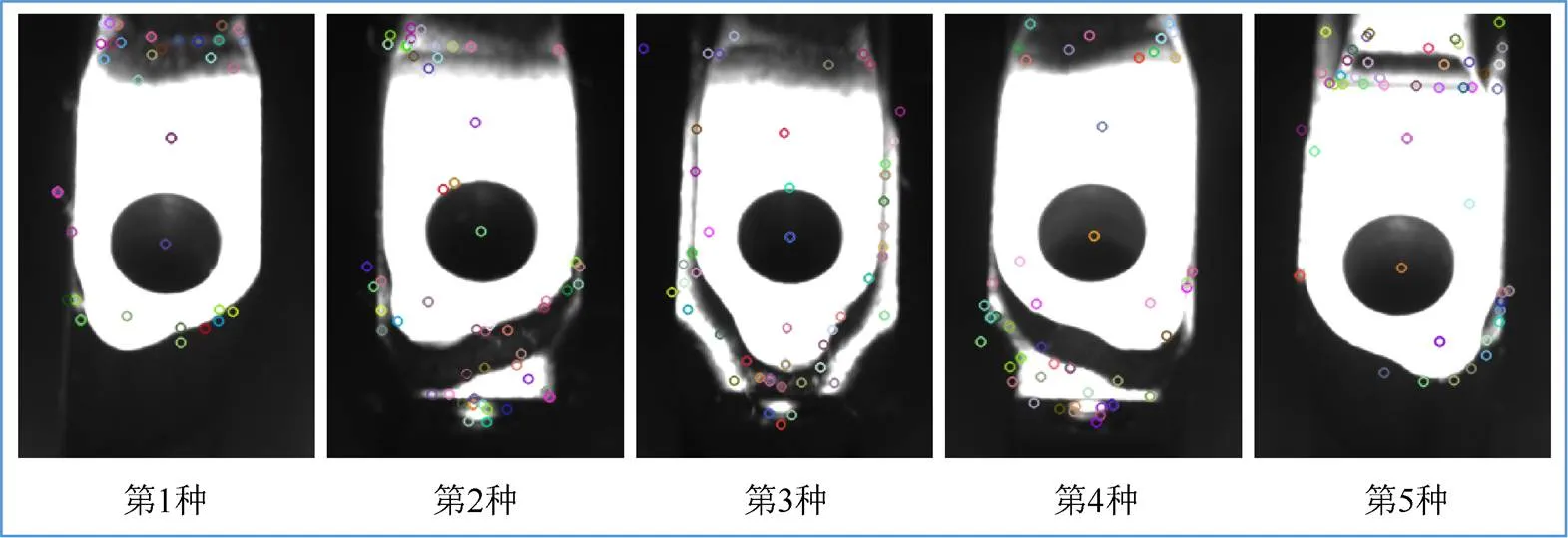
图5 提取主轴承盖顶部侧边支撑面区域的关键点
2.3 主轴承盖图像关键点的描述
从发动机主轴承盖图像中提取的关键点是实际的像素点,仅包含单张图像的具体空间位置信息,因此需要进一步将关键点转化为特征向量,以此作为关键点的数学表达,才能充分反映任意一张主轴承盖图像在该点处的像素梯度及方向信息。
通过图像的梯度信息,为每一个关键点确定一个方向,并且在后续的关键点描述中包含这些方向信息,使得SIFT特征获得有效的旋转不变性。对于任一个关键点(,),其梯度大小(,)和方向(,)可表示为
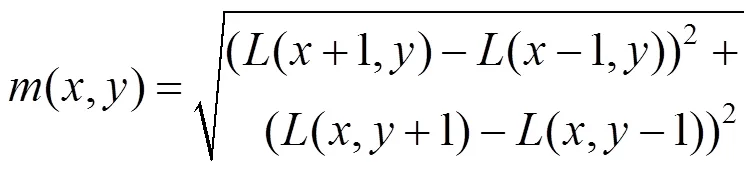
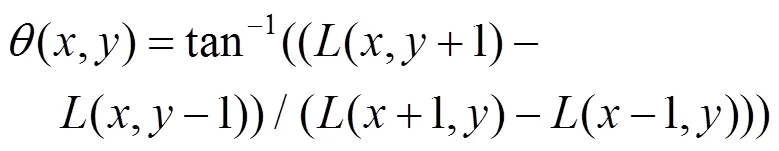
描述主轴承盖图像关键点的具体方法如图6所示。在实际拍摄的图像中取与关键点相邻的8×8像素块,计算每个像素点的梯度大小及方向。再将该像素块分成16个2×2的子像素块,对每个2×2子块中的4个像素点的梯度做高斯加权,并投影至8个方向,即,每个2×2子块描述成一个1×8维的向量(共16个子块)。由此,一个关键点最终由一个1×128维的特征向量描述。
2.4 构建主轴承盖零件的BoW模型
由主轴承盖图像得到的SIFT特征向量是针对每一个具体关键点的描述,是该关键点周围局部特征的体现。将这些关键点使用K-means聚类算法分成个分类,并以这些分类组成的词汇模型来描述主轴承盖图像,可以突出不同种类主轴承盖之间所包含的关键点的差异,同时也降低了图像特征向量的维度。
K-means算法[11]是一种基于样本间相似性度量的无监督分类方法。此方法首先将所有样本数据随机分类成个簇,然后执行迭代:将簇中全体样本的位置均值设定为簇的中心,重新将样本划分为距离最近的簇中,完成一次迭代计算。通过重复的迭代完成样本的聚类。在汽车发动机主轴承盖分类识别方法中,所有主轴承盖训练图像中提取的SIFT特征,聚类成个分类,作为BoW模型的输入。
BoW模型最初应用于自然语言处理和信息检索中,将文本看作是无序单词的组合,建立词汇表,统计每个文本中的词汇信息实现文本的分类与检索。随着新的更稳定的图像特征提取算法的提出,BoW模型方法开始被引入机器视觉的任务中[12],例如卫星图像分类[13]等。
本文将K-means聚类方法得到的个分类,抽象为BoW词汇表中的个词汇,每一个训练数据集图像均可由这个词汇表述,形成的描述向量经过L2归一化,得到图像最终的BoW描述。通过构建BoW模型,将图像的描述向量维度降低为[1×],提高了识别系统的运行效率。同时,基于关键点词汇表的图像描述,可以突出不同种类零件关键点的差异,有利于提高系统的识别效率。
将所有训练数据集合的关键点特征向量进行无监督聚类,使得具有相似描述的关键点,成为一类相似特征的组合。其中,描述关键点的特征向量,是由主轴承盖图像在该关键点的邻域内的像素点所决定的。因此,某一类关键点的组合,可以直观的理解为主轴承盖图像的某个具体形状特征,如图7所示。
由图7可知,每一张主轴承盖图像均可由聚类形成的中心词汇集表示,这种图像的表达形式称为图像的BoW模型描述。假设通过K-means聚类方法得到个词汇,则对于任意一张主轴承盖图像,均可由一个[1×]的词袋描述向量来表示,该向量内的每一个元素表示:描述指定图像时,对应“词汇”出现的次数。图像的BoW描述作为SVM分类器训练时的输入信息。
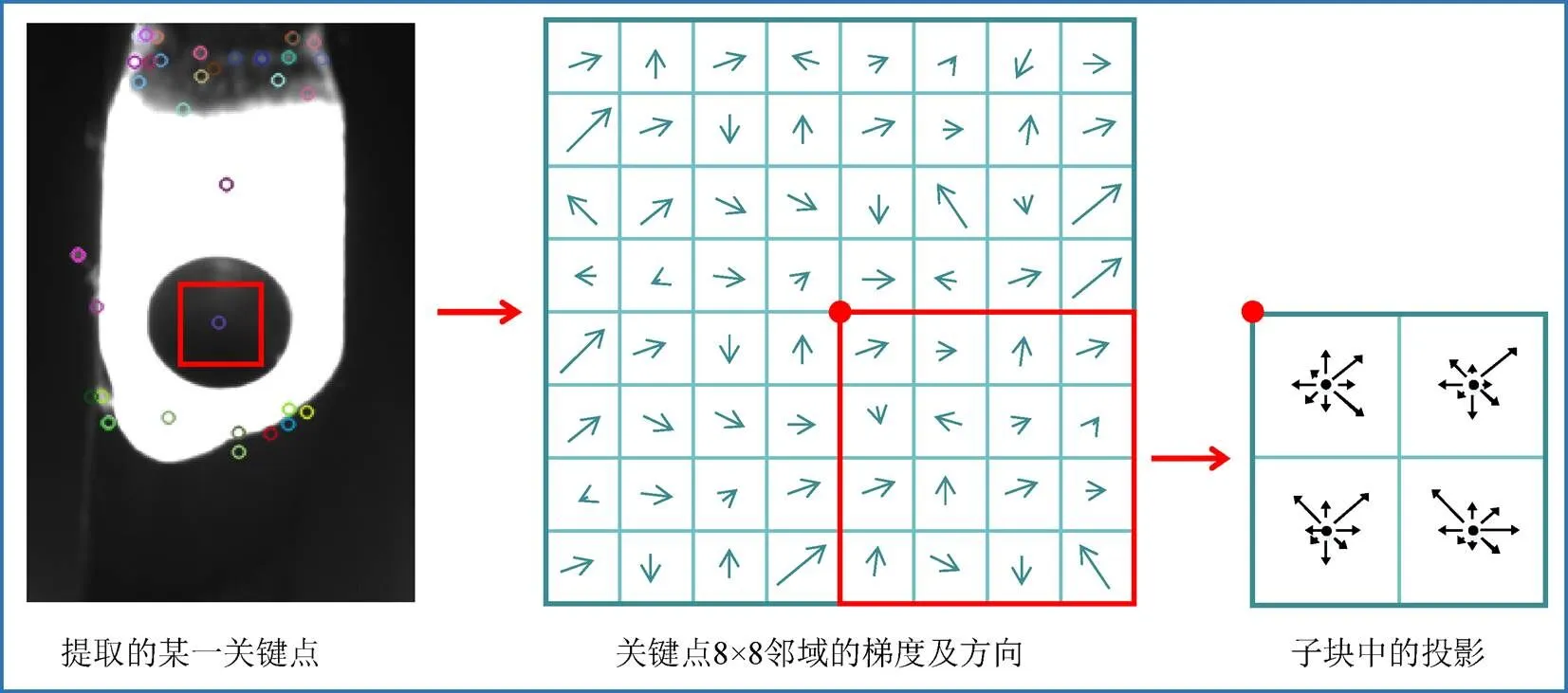
图6 利用邻域的像素梯度和方向来描述主轴承盖的关键点

图7 由主轴承盖图像关键点特征向量聚类形成的BoW模型“词汇”
2.5 构建SVM分类器
SVM[14]是一种基于统计学习理论的机器学习算法,根据有限的样本信息,综合考量模型的复杂性和学习能力,针对小样本、非线性分类以及高维模式问题具有突出优势。SVM将图像分类问题简化为一个二分类模型,其核心思想是寻找一个使得最小分类间隔最大化的分类超平面。
对于已知的样本空间(x,y),=1,2,···,,ÎR,Î{±1},其超平面为wx+=0,如果该样本空间线性可分,并且考虑添加合页损失函数以考虑少数柔性不可分样本,则SVM二分类问题的数学模型可表示为如下所示的凸二次规划问题,即

对于实际应用中更普遍存在的线性不可分样本空间,SVM运用核函数将低维样本空间映射到高维特征空间,并在高维空间中构建超平面以完成分类。核函数是SVM的重要手段,可避免直接求解非线性映射函数的具体形式,有效解决高维空间计算带来的“维数灾难”问题,可极大扩展SVM的实际应用场景。常用的核函数有
线性核函数:(,x)=·x
多项式核函数:(,x)=[(·x)+1]
Sigmoid核函数:(,x)=tanh((·x)+)
3 识别方法验证及分析
3.1 验证实验的基础环境及数据集
基于SIFT-SVM的发动机主轴承盖识别分类方法中,识别准确率的影响参数包括:①SVM分类器的核函数;②K-means聚类算法的类别数。在该方法的验证中,本文进一步探究了上述参数在实际识别过程中的具体影响。实验的评价指标为:分类模型对于同一测试集数据的识别准确率以及单张图像的识别时间。验证实验的数据集图像来源于实际拍摄的主轴承盖图像,主轴承盖零件共有5个种类,训练集共采集500张图像,每小类100张;测试集共采集200张图像,每小类40张;图像尺寸大小为2048×2048。
3.2 SVM分类器不同核函数的影响
分别构建4种常用核函数下的SVM分类器,进行模型训练。同时,为了突出不同核函数对识别结果的影响,将聚类类别数取较小值=50,以使识别准确率处于较低水平,各核函数下的整体识别结果见表1,其中,依次列举线性核函数以及RBF核函数分类器所对应的识别结果混淆矩阵,见表2和表3。

表1 采用不同核函数的SVM分类器识别结果

表2 K=50与线性核函数组合下的识别结果混淆矩阵
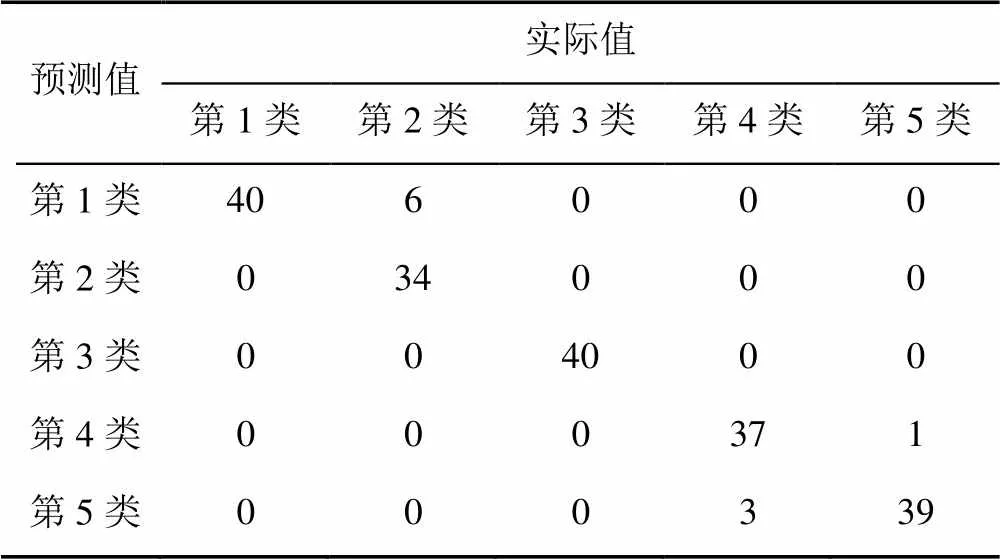
表3 K=50与RBF核函数组合下的识别结果混淆矩阵
由表1结果可知,基于RBF核函数的SVM分类器识别准确率最高,且单张图像识别时间满足在线识别要求。综合比较表2和表3的结果,采用线性核函数的SVM分类器,主要在第1类和第2类、第3类和第4类零件的识别上存在错误,而采用RBF核函数可以有效改善识别准确率。是因为线性核函数对原样本空间仅进行线性映射,对于线性不可分的数据模型存在较大误差,上述4类主轴承盖的特征区域图像,两两之间较为相似,关键点分布趋近,使得SVM分类器难以通过简单的线性分割平面进行分类,而RBF核函数则可以将主轴承盖零件的原始特征映射至多维空间,使得原本分布趋同的特征描述在高维空间中分离,求解出更准确的分割超平面,有效提升了主轴承盖零件的识别准确率。
同时,RBF核函数也含有2个主要参数:高斯参数和惩罚系数。高斯参数与样本分类的精细程度有关,的值越小,分类越精确,即分类器力求将每个样本都分类,因此存在过拟合的风险;的值越大,则分类越粗糙,可能导致分类模型欠拟合。惩罚系数的直观理解是允许SVM模型错分样本的程度,直接影响到分类模型的适应性。的值越大,表示模型对错分样本的关注度越高,允许的错分样本越少,而要求每个样本都被准确分类会存在过拟合的风险,模型的适应性也随之越低;相反,的值越小,表示模型允许的错分样本多,同时,追求最大的分类间隔会导致欠拟合,优化算法难以收敛。针对上述2个参数,验证实验采用网格搜索法[15]探究不同参数组合的实际影响,同样取聚类类别数=50。实验结果以“识别准确率-单张图像识别时间”格式记录于表4。

表4 不同高斯参数和惩罚系数的识别结果(识别准确率-单张图像识别时间(s) )
由表4可知,高斯参数和惩罚系数对主轴承盖零件识别结果影响差异较小,其原因是本文方法提取的目标区域关键点稳定、有效,且存在明显的分类差异,使得分类结果趋于稳定。结合上述实验验证,最终选取高斯参数=1,惩罚系数=1,此时分类模型识别率最高,且识别时间损耗较小。
3.3 聚类类别数K的影响
根据实际经验,聚类的类别数越大,则词汇模型中用于描述图像的“基本词汇”越充足,描述越详细,因此通常会取得更好的识别效果。但由于主轴承盖图像目标区域有效的关键点数目有限,因此,当超过一定值时,识别系统的效果将不再变化,甚至因为冗余描述导致分类错误。因此,进行对照组实验,见表5。
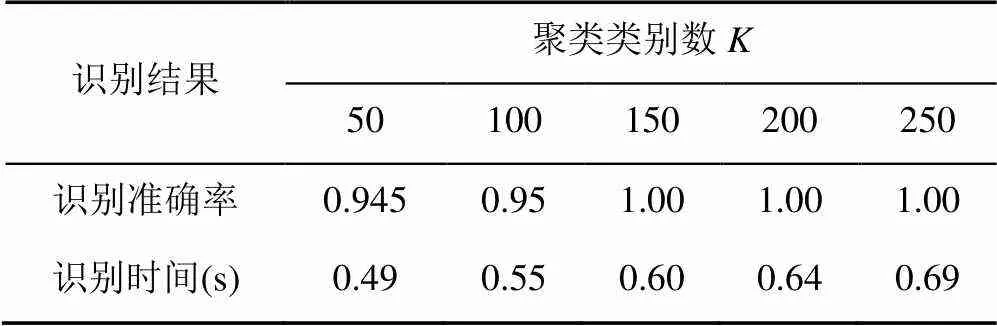
表5 不同聚类类别数的识别结果
由表5结果可知,对于主轴承盖零件的分类,聚类类别数的最优选择是=150,此时零件识别的准确率达到100%,且单张图像的识别时间为0.60 s。综合比较表3和表6,通过增大聚类类别数,可以将各种类主轴承盖零件间的差异性关键点,划分为不同的基础特征,避免了相似分布的关键点仅被简单聚集成一个特征,因此,扩展了SVM分类器的识别依据,从而有效提升识别准确率。
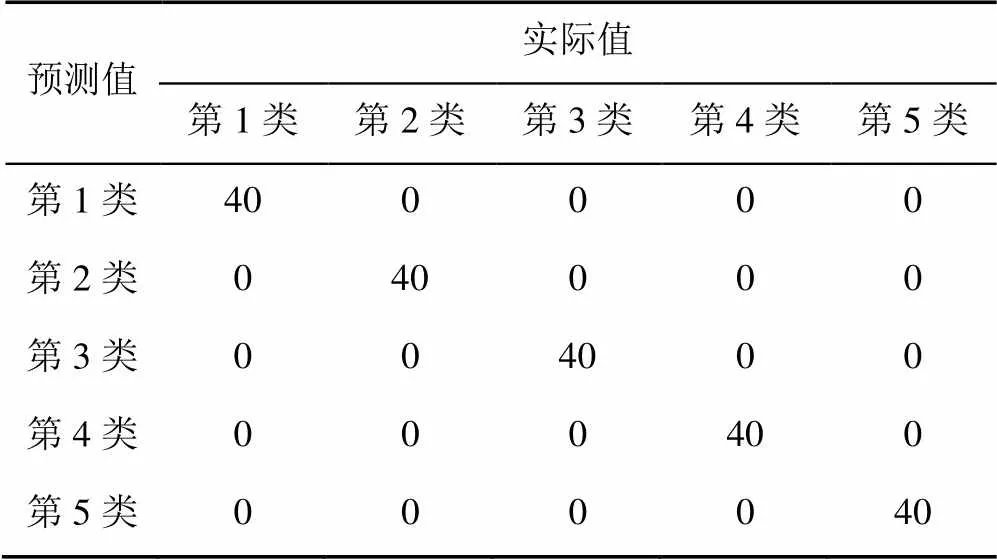
表6 K=150与RBF核函数组合下的识别结果混淆矩阵
综合相关参数对识别结果影响的验证实验,可以得到发动机主轴承盖识别方法的最优参数为:SVM分类器的核函数确定为RBF核函数,其高斯系数=1,惩罚系数=1,聚类类别数150。经实际数据测试,基于SIFT-SVM的发动机主轴承盖识别分类方法的识别准确率为100%,单张识别时间为0.60 s。
4 结束语
本文提出的基于SIFT-SVM的发动机主轴承盖识别方法,结合了各种类零件之间的形状差异,有效的实现了识别与分类。该方法将机器视觉相关理论应用到工业生产,其基本组件包括工业相机、环形LED光源、光电传感器、电源和计算机,硬件组成简单易实现,成本低廉。通过实验进一步验证了该方法的有效性,在参数组合为:SVM分类器采用RBF核函数,其高斯参数=1,惩罚系数=1,聚类类别数=150的情况下,该方法的识别正确率可以达到100%,单个零件的识别时间为0.60 s。
在实际应用中,该方法对获取图像时的拍摄环境有一定的要求,需要额外设置光线遮挡装置,以保证工作光源可以正常有效地照亮主轴承盖零件上特定的目标区域。当外部干扰光线将零件分类特征区域以外的部分打亮时,会对识别系统产生严重干扰,导致图像有效的SIFT关键点发生改变,由此造成识别错误。因此,识别系统的下一步改进方向应当考虑采用更稳健的关键点提取方案,以提高识别系统的灵敏性。
[1] BHAT NAGARAJ N, DUTTA S, VASHISTH T, et al. Tool condition monitoring by SVM classification of machined surface images in turning[J]. The International Journal of Advanced Manufacturing Technology, 2016, 83(9-12): 1487-1502.
[2] OLGUN M, ONARCAN AHMET O, ÖZKAN K, et al. Wheat grain classification by using dense SIFT features with SVM classifier[J]. Computers and Electronics in Agriculture, 2016, 122: 185-190.
[3] AZHAR R, TUWOHINGIDE D, KAMUDI D, et al. Batik image classification using SIFT feature extraction, bag of features and support vector machine[J]. Procedia Computer Science, 2015, 72: 24-30.
[4] MANZOOR MUHAMMAD A, MORGAN Y. Vehicle Make and Model classification system using bag of SIFT features[C]//2017 IEEE 7th Annual Computing and Communication Workshop and Conference (CCWC). New York: IEEE Press, 2017: 1-5.
[5] 杨全, 彭进业. 采用SIFT-BoW和深度图像信息的中国手语识别研究[J]. 计算机科学, 2014, 41(2): 302-307. YANG Q, PENG J Y. Chinese sign language recognition research using SIFT-BoW and depth image information[J]. Computer Science, 2014, 41(2): 302-307 (in Chinese).
[6] BERRETTI S, BEN AMOR B, DAOUDI M, et al. 3D facial expression recognition using SIFT descriptors of automatically detected keypoints[J]. The Visual Computer, 2011, 27(11): 1021-1036.
[7] KRÜGER J, LEHR J, SCHLÜTER M, et al. Deep learning for part identification based on inherent features[J]. CIRP Annals, 2019, 68(1): 9-12.
[8] IWAHORI Y, TAKADA Y, SHIINA T, et al. Defect classification of electronic board using dense SIFT and CNN[J]. Procedia Computer Science, 2018, 126: 1673-1682.
[9] NAJVA N, EDET BIJOY K. SIFT and tensor based object classification in images using Deep Neural Networks[C]//2016 International Conference on Information Science (ICIS). New York: IEEE Press, 2016: 32-37.
[10] LOWE DAVID G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110.
[11] JAIN ANIL K. Data clustering: 50 years beyond K-means[J]. Pattern Recognition Letters, 2010, 31(8): 651-666.
[12] SILVA FERNAND B, WERNECK RAFAEL DE O, et al. Graph-based bag-of-words for classification[J]. Pattern Recognition, 2018, 74: 266-285.
[13] YUAN Y, HU X Y. Bag-of-words and object-based classification for cloud extraction from satellite imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2015, 8(8): 4197-4205.
[14] CORTES C, VAPNIK V. Support-vector networks[J]. Machine learning, 1995, 20(3): 273-297.
[15] 奉国和. SVM分类核函数及参数选择比较[J]. 计算机工程与应用, 2011, 47(3): 123-124. FENG G H. Parameter optimizing for support vector machines classification[J]. Computer Engineering and Applications, 2011, 47(3): 123-124 (in Chinese).
Classification of engine main bearing cap parts using SIFT-SVM method
SHI Zhi-liang, ZHANG Peng-fei, LI Xiao-yao
(Mechanical and Electrical Engineering, Wuhan University of Technology, Wuhan Hubei 430070, China)
The recognition and classification of mechanical components is a key process on the manufacturing automation line. In terms of the classification of the mixed and cleaned engine main bearing cap, through the analysis of the actual characteristics of the main bearing cap parts, the classification and recognition method for the main bearing cap based on SIFT-SVM was proposed. The method first extracted all scale-invariant feature transform (SIFT) feature vectors of the training dataset image, then employed the K-means clustering method to cluster all feature vectors into K classifications, and substituted the obtained K clustering results into the bag of word model (BoW). “Vocabulary” was utilized to describe each training image, thereby obtaining a BoW description of the image. The BoW description of each image served as a training input, and the classification model for the main bearing cap was trained using a support vector machine (SVM). The experimental results show that under the calibrated lighting conditions, the recognition rate of the main bearing cap parts can reach 100%, and the recognition time for a single part was 0.6 seconds, which verified the effectiveness and efficiency of the algorithm.
parts recognition and classification; machine vision; scale-invariant feature transform; word bag model; support vector machine classifier
TP 391.4
10.11996/JG.j.2095-302X.2020030382
A
2095-302X(2020)03-0382-08
2019-11-07;
2020-02-25
石志良(1974-),男,湖北武汉人,副教授,博士,硕士生导师。主要研究方向为3D打印、计算机视觉等。E-mail:shizhiL998@163.com
猜你喜欢
电子产品世界(2022年4期)2022-04-21
建材发展导向(2022年3期)2022-04-19
今日农业(2021年8期)2021-11-28
建材发展导向(2021年11期)2021-07-28
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
电子技术与软件工程(2017年14期)2017-09-08
新高考·高一物理(2015年5期)2015-08-18
