
联合增强局部最大发生特征和k-KISSME度量学习的行人再识别
2020-08-27 06:24夏苗苗陆伟明张旭东
图学学报 2020年3期
孙 锐,夏苗苗,陆伟明,张旭东
联合增强局部最大发生特征和k-KISSME度量学习的行人再识别
孙 锐1,2,夏苗苗1,2,陆伟明1,2,张旭东1,2
(1. 合肥工业大学计算机与信息学院,安徽 合肥 230009;2. 工业安全与应急技术安徽省重点实验室,安徽 合肥 230009)
行人再识别是一种在监控视频中自动搜索行人的重要技术,该技术包含特征表示和度量学习2部分。有效的特征表示应对光线和视角变化具有鲁棒性,具有判别性的度量学习能够提高行人图像的匹配精度。但是,现有的特征大多都是基于局部特征表示或者全局特征表示,没有很好的集成行人外观的精细细节和整体外观信息且度量学习通常是在线性特征空间进行,不能高效地利用特征空间中的非线性结构。针对该问题,设计了一种增强局部最大发生的有效特征表示(eLOMO)方法,可以实现行人图像精细细节和整体外观信息的融合,满足人类视觉识别机制;并提出一种被核化的KISSME度量学习(k-KISSME)方法,其计算简单、高效,只需要对2个逆协方差矩阵进行估计。此外,为了处理光线和视角变化,应用了Retinex变换和尺度不变纹理描述符。实验表明该方法具有丰富和完整的行人特征表示能力,与现有主流方法相比提高了行人再识别的识别率。
行人再识别;增强的局部最大发生特征;核学习;特征表示;度量学习
行人再识别是对不同时间出现在非重叠的多摄像机下的行人进行匹配,即检索在一个摄像机中出现的行人是否在另外的时间出现在其他摄像机中。近些年,行人再识别技术在视频监控领域和公共安全领域中具有重要和潜在的应用价值[1]。但是由于多个摄像机之间差异和外部环境的复杂性,行人再识别的难点主要体现在:①不同行人从一个摄像机消失后出现在另一个摄像机的时间不固定,使得时间约束和空间约束的设置不可行。②真实场景摄像机拍摄的行人图像可能具有低分辨率的特点,使得获得的行人生物特征不可靠。③跨摄像机下的行人存在光线、视角变换、遮挡、相似外观等问题。图1为分别来自2个摄像机拍摄的行人图像。

图1 行人再识别面临的挑战(从左到右)依次是:视角、光线、姿势、部分遮挡、分辨率、相似外观和不同的背景
为了应对上述挑战,目前行人再识别的研究领域主要集中在特征表示和度量学习2个方向。特征表示的目的是提取具有鲁棒性的行人特征,以便更好地进行图像的区分;度量学习的目的是通过学习一个具有强判别力的距离度量函数,对提取到的行人图像特征进行分类。
特征表示方法用于描述不同环境中的行人外观。为了实现对不同变化的区分和鲁棒性,这些特征通常从水平条纹或密集块中提取。例如,从6个非重叠水平条纹中提取显著颜色名称(salient color names,SCN)[2]和局部特征集合(ensemble of local features,ELF)[3]。另外作为ELF的延伸,ELF18[4]是从18个非重叠条纹中提取的特征计算得到。通常,这些基于条带的描述符适用于解决交叉视图主体未对准问题并且可以很好地捕获整体外观信息。与基于条带的描述符相比,从密集块提取的特征可以很好地捕获相对较小块中的精细细节。局部最大发生(local maximal occurrence,LOMO)[5]描述符是在密集块中提取的,其在解决视角变化问题中表现出很强的鲁棒性。文献[6]试图从密集补丁集群中学习中级过滤器。文献[7]设计了高斯-高斯描述符(Gaussian of Gaussian,GOG),通过将每个行人图像描述为由均值和协方差表示的一组分层高斯分布。然而,这些基于密集块的描述符存在不善于描述图像的整体外观的缺点。
近年来,提出了很多基于度量学习的行人再识别方面的方法。保持简单高效的度量学习(keep it simple and straightforward metric learning,KISSME)[5]方法导出了具有高效度量的封闭形式解。为了在高维设置中执行KISSME,文献[8]设计了交叉视图二次判别分析(cross-view quadratic discriminant analysis,XQDA)作为KISSME的扩展,其采用广义Rayleigh商来找到一个判别的低维子空间用于更有效地度量。文献[9]提出了成对约束分量分析(pairwise constrained component analysis,PCCA)以从稀疏成对约束中学习投影矩阵。边缘最近邻方法(large margin nearest neighbor,LMNN)[10]旨对于K最近邻(k-Nearest Neighbor,k-NN)分类性能表现良好。文献[11]提出使用三元组约束策略从相对距离比较中学习度量。文献[12]对多种度量学习进行组合,解决特征融合造成的维数灾难问题。文献[13]考虑利用QR分解将数据映射到低维空间,然后执行KISSME在投影空间中学习稳健的Mahalanobis矩阵。文献[14]考虑到红外-可见光行人图像跨模态识别问题,提出了多模态度量学习算法。文献[15]提出一种自适应深度度量学习解决行人再识别问题。然而,这些工作都是在线性特征空间中进行的,而忽略了非线性特性。
随着深度学习的兴起,出现了一些通过强大的深层模型来学习特征的方法。如文献[16]指出,当将深度学习与手工制作的特征结合使用时,可以进一步提高后者的性能;文献[17]设计了一个能够同时提取连续图像帧中全局与局部特征的时间残差学习模块,从而提高视频行人再识别的识别率;文献[18]提出一种联合特征映射矩阵和异构字典对学习的算法优化基于图像与视频的行人再识别的结果。但是,深度学习的缺点是需要大量的训练数据,容易遭受过度拟合的风险。所以训练样本的数量较小时,度量学习方法的高效性要强于深度学习。
本文设计了增强局部最大发生(enhanced LOMO,eLOMO)的有效特征表示,并提出一种被核化的KISSME度量学习即(k-KISSME)方法用于行人再识别。为了结合基于条带和密度块特征提取的优点,可将来自条纹区域的整体外观信息和来自密集块的精细细节整合以增强特征的辨别力。为了学习高效稳健的度量函数,还提出将KISSME方法与核函数相结合的k-KISSME方法,允许使用非线性映射捕获数据集中的非线性空间结构。行人再识别方法的流程图如图2所示。
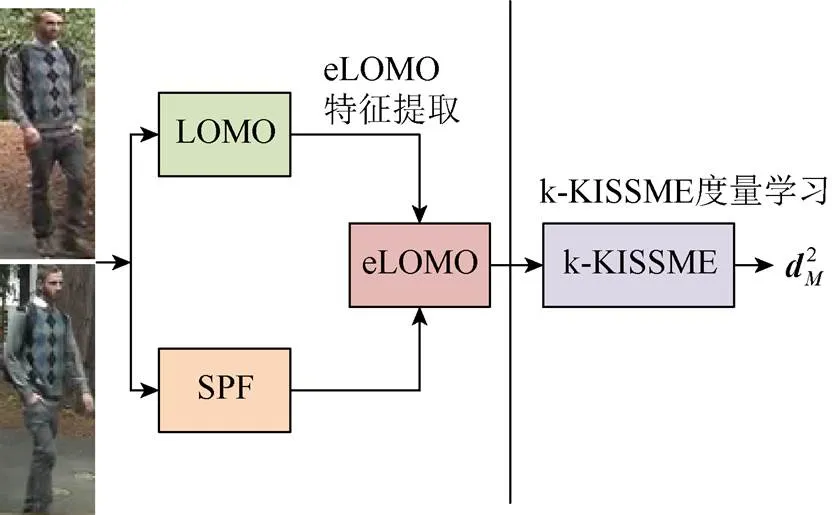
图2 行人再识别方法流程图d2 M
本文工作的重点如下:
(1) 设计了一种称为eLOMO特征的行人特征表示方法,该特征是在LOMO特征的基础上进行的特征增强,有效地提升了行人图像的特征表示能力。
(2) 提出了一种称为k-KISSME的度量学习方法,将KISSME度量学习映射到内核空间,允许捕获数据集中的非线性结构,有效地提升了度量学习的灵活性。
(3) 将k-KISSME与其他度量学习方法在3个具有挑战性的数据集上进行比较。实验结果表明,本文方法的有效性体现在能够在大多数实验中获得了更好的Rank-1匹配率。
1 LOMO特征表示和KISSME度量学习原理
1.1 局部最大发生(LOMO)特征表示
(1) 解决光照变化的问题。颜色是描述行人图像的重要特征。但是,由于摄像机设置和光照条件的不同,可能导致同一个人的感知颜色因不同的摄像机视角而发生变化。本文应用Retinex方法[19]来预处理行人图像,解决因相机视角导致的颜色感知问题。Retinex方法旨在表达与人类观察场景相一致的彩色图像,使其包含鲜艳的颜色信息,尤其在阴影区域中能够增强细节信息。
除了颜色描述符,还应用尺度不变局部三元模式(scale invariant local ternary pattern,SILTP)[20]描述符解决光照不变的纹理描述。SILTP是已知局部二元模式(local binary pattern,LBP)的改进算子。其优点是引入了尺度不变的局部比较容差,克服了LBP对图像噪声不稳健的缺点,实现了应对光照变化的不变性。
(2) 解决视角变换的问题。行人图像在不同的相机下具有不同的视图。如,在一个相机下具有正面视图的人可能出现在另一个相机下的后视图中。因此,在不同视角下对行人进行匹配也是一项挑战。为了解决该问题,文献[21-22]提出将行人图像等分为6个水平条纹,并在每个条纹中计算单个直方图特征,其能够解决视角变化的行人表示。但缺点是可能丢失条纹中的空间细节,从而影响辨别力。
本文采用滑动窗口来描述人物图像的局部细节。具体使用大小为10×10的子窗口,其重叠步长为5个像素,来定位128×48图像中的局部补丁。在每个子窗口中,提取2个SILTP直方图(SILTP0.3 4,3和SILTP0.3 4,5)和一个8×8×8-bin联合HSV直方图。每个直方图表示子窗口中对应模式的发生概率。为了解决视角变化的问题,需检查相同水平位置的所有子窗口,并最大化这些子窗口中每个模式(即相同的直方图块)的局部出现,进而使得到的直方图具有应对视角变化的不变性,并可捕获行人的局部区域特征。图3显示了LOMO特征提取的过程。为了进一步考虑多尺度信息,构建了一种三尺度金字塔的表示,其通过2个2×2局部平均合并操作对原始128×48图像进行下采样,并重复上述特征提取过程。通过连接所有计算的局部最大出现次数,最终描述符具有(8×8×8个颜色块+34×2个SILTP块)×(24+11+5个水平组)=26 960个维度。最后,可应用对数转换来抑制大的块值,并将HSV和SILTP特征规范化为单位长度。
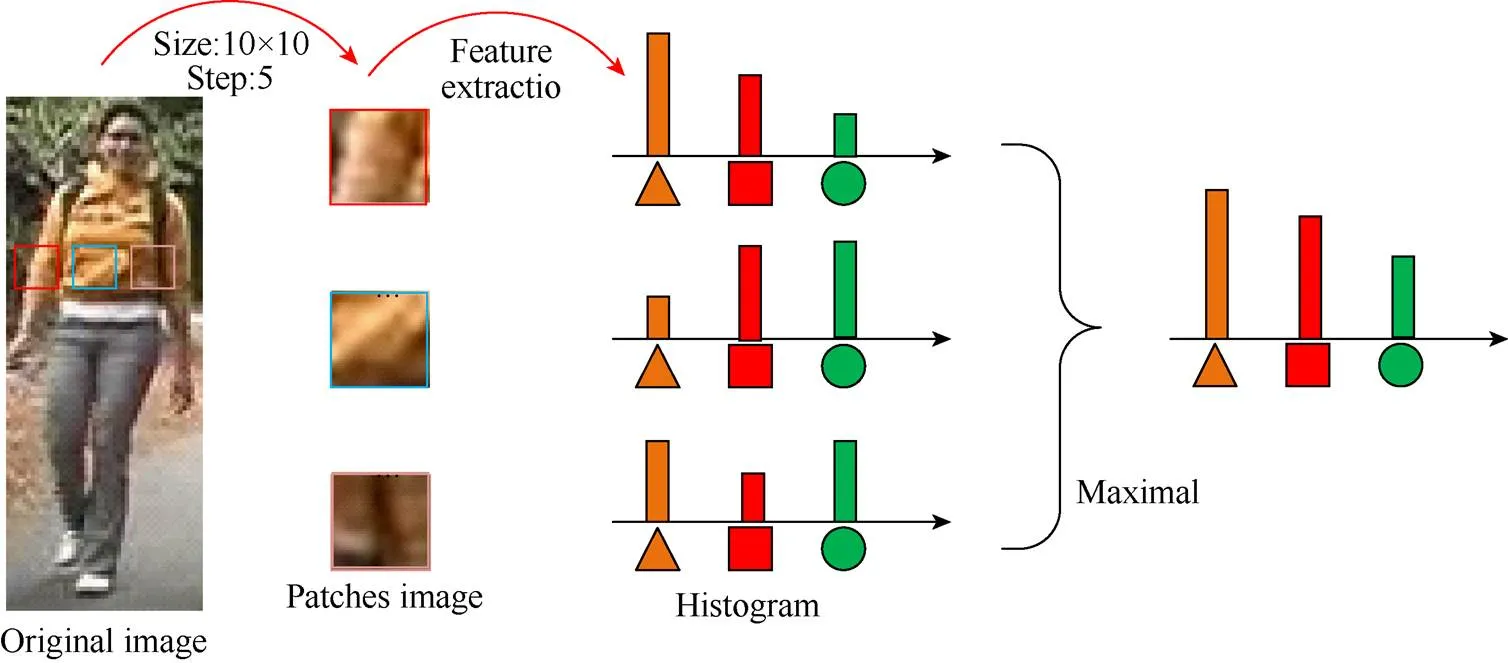
图3 LOMO特征提取过程
1.2 KISSME度量学习方法
文献[23]中提出了一种基于等价约束的度量学习方法,其利用2个小尺寸的协方差矩阵进行基于Mahalanobis距离函数的度量学习,第一次提出了KISSME度量学习方法,并将该方法扩展到大规模数据集上。
给定一对特征向量(,),其中和表示行人图像对(,)的特征向量。令0表示2个样本相似的先验知识,即(,)来自相同行人,1表示2个样本不相似的先验知识,即(,)分别来自2个不同的行人。一对行人图像的相似度函数为

其中,(0|(,))为和来自相同行人的概率密度函数;(1|(,))为和来自不同行人的概率密度函数。(,)的值越大,则表示行人对(,)属于相关行人对的概率越大,反之,则表示属于不相关行人对的概率越大。
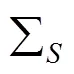
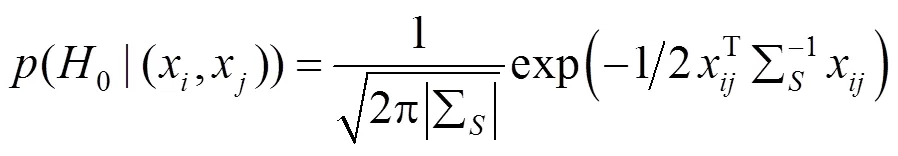
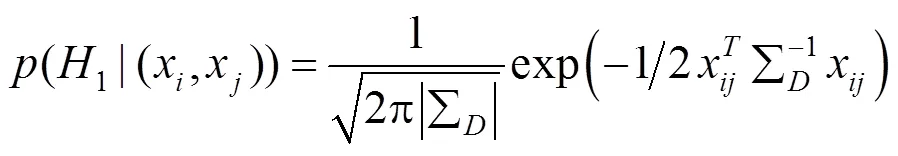
其中,

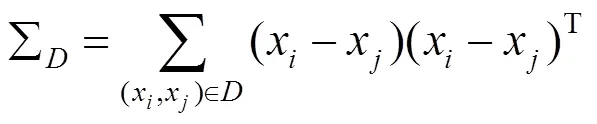
将式(2)和(3)代入式(1)得到
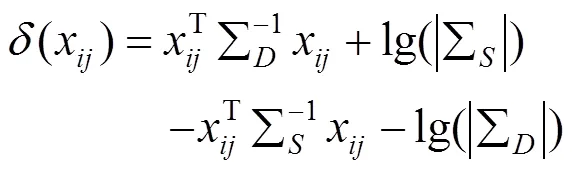
由于()函数中的常数项不影响相似度的测量,可以将常数项省略则式(6)简化得到式(7)
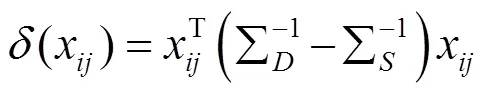
可以看出式(7)在形式上与Mahalanobis距离函数很相似,因此可以将2个样本之间的距离定义为
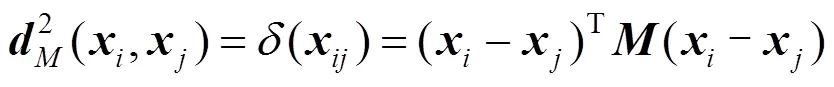
2 所提出的行人再识别方法
2.1 增强的局部最大发生(eLOMO)特征表示
类似于人类视觉系统由粗到细的识别机制,视觉学习的判别特征表示应考虑图像之间的精细细节和整体外观信息。其优点体现在可以捕获不同摄像机下的行人外观的不变性,帮助确定感兴趣的目标。在本文中,将提取到的LOMO特征表示与一个基于条带的特征描述符融合在一起,得到一个新的行人再识别特征描述符——增强局部最大发生(eLOMO)特征表示。LOMO特征擅长捕获密集块的精细细节,而基于条带的描述符可以更好地利用来自较大区域的整体外观信息。因此,它们的融合可以导致粗略到精细的表示,符合人类识别机制。
本文利用从类似文献[23]获得的重叠条纹的两级金字塔空间中提取基于条带的特征。为了降低背景杂乱的干扰,首先对图像进行预处理。然后,将预处理后的图像等分为8个水平条纹。为了减少无用信息的提取,提高特征的准确性,可从图像的顶部和底部分别放弃1/2条纹,将得到的图像再次重新划分为7个条纹,因此,总共有15条尺寸相同的水平条纹。可从每个条纹中提取4个基本特征:HSV和RGB的8×8×8大小的联合直方图特征,SCN特征以及2个尺度分别为SILTP0.3 4,3和SILTP0.3 4,5的直方图特征。使用LOMO特征中的相同设置提取联合HSV和SILTP直方图,并且以与HSV直方图相同的方式计算联合RGB直方图,这2个直方图特征仅具有颜色空间的差异。使用与文献[2]中相同的16种标准颜色计算SCN特征。与LOMO特征提取不同的是,此时每个条带是作为整体计算的,在计算局部特征之后没有最大化局部发生模式的操作。最后,连接从所有条纹获得的4个基本特征,并获得总尺寸为(83+83+34×16×2)×15=18810的描述符。为了获得对噪声的鲁棒性,需将除了已经被标准化的SCN特征之外的其余特征都进行标准化。由于特征是从基于条带的金字塔空间中提取的,所以可将所获得的描述符称为基于条带的金字塔特征(stripe-based pyramid features,SPF)。
表1显示了LOMO和SPF描述符的比较,从中可以发现两者的相似在于:均应用了Retinex方法进行预处理,并且都采用颜色直方图和SILTP纹理描述符来捕捉行人外观信息。因此,可以将SPF描述符视为基于条带的LOMO描述符的变体。其主要区别在于提取方式的不同:LOMO是根据不同比例空间上的密集块计算的,而SPF是从两级重叠条纹中提取的。此外,SPF中的附加RGB直方图和SCN可以提供比LOMO中唯一的HSV直方图更丰富的颜色信息。构建SPF描述符的目的是捕获较大区域的整体外观信息,使其与LOMO特征的融合可以捕获行人外观的整体和细节信息。图4给出了通过LOMO和SPF提取器从一个行人图像条带计算的联合HSV直方图的示例。可以表明LOMO提取器可以捕获比SPF更多的细节,而后者则擅长描述整体外观。这是因为在裁剪的前景条纹中通常存在大约4种颜色图案,且对应于SPF直方图中的4个区域簇。受人类视觉系统特征的启发,应相信SPF和LOMO特征的融合可以提供描述符来执行粗到细的识别。因此,融合描述符被认为比单独使用其更具辨别力。由于SPF可以被视为LOMO的基于条带的变体,因此将融合描述符称为eLOMO。

表1 LOMO特征和SPF特征的比较
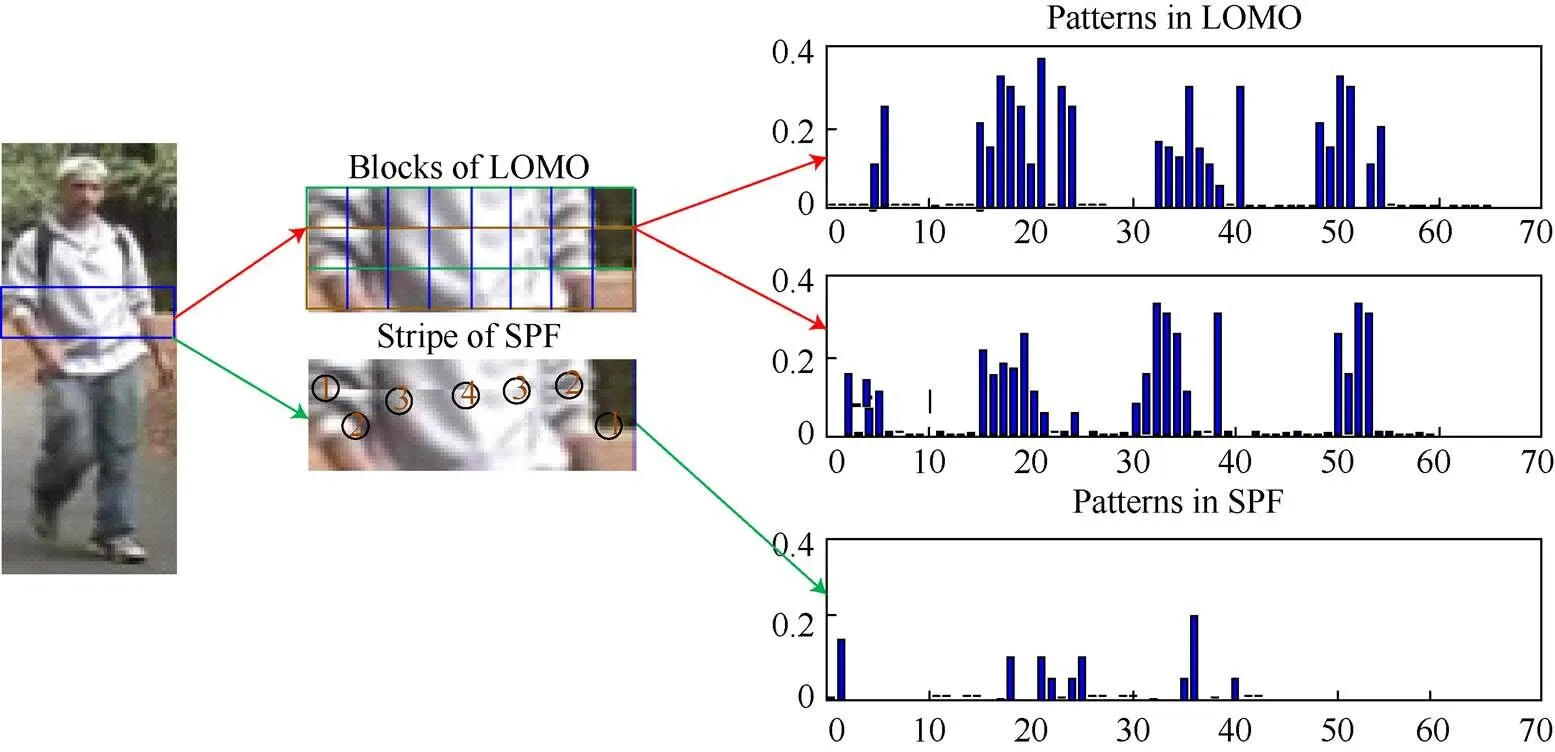
图4 LOMO特征与SPF特征表示示例(圆圈中的数字表示不同的颜色模式)
2.2 k-KISSME度量学习方法
本文提出了基于核学习的KISSME非线性度量方法。通过在协方差矩阵中引入正则参数,使得k-KISSME方法具有更好的稳健性和泛化性。

假设给出了和中的成对约束,所以需介绍一些符号。令为列向量,其在第个条目处的值为1,并且在其他条目处的值为0。令0(相应的1)是×对角矩阵,其对角矢量在第个条目处包含(对应于)中约束的数量,其中第一个元素是,即
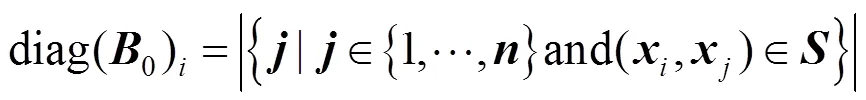
令0(相应的1)为×对角矩阵,其对角矢量在第个条目处包含(别为)中约束的数量,其中第二元素是,即
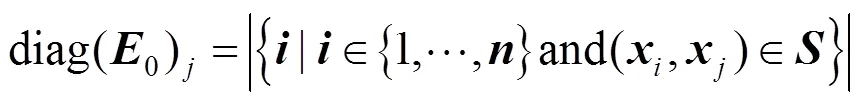


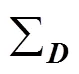

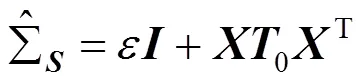
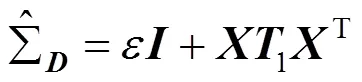
通过该方法可以获得比使用最大似然估计更稳健和稳定的估计。为了评估这些矩阵的逆,可根据文献[28]给出下式
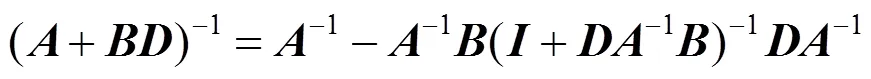
将式(11)和(12)代入到式(13)中得到
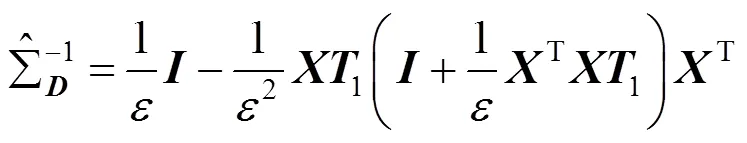
最后,这2个逆协方差矩阵之间的差为
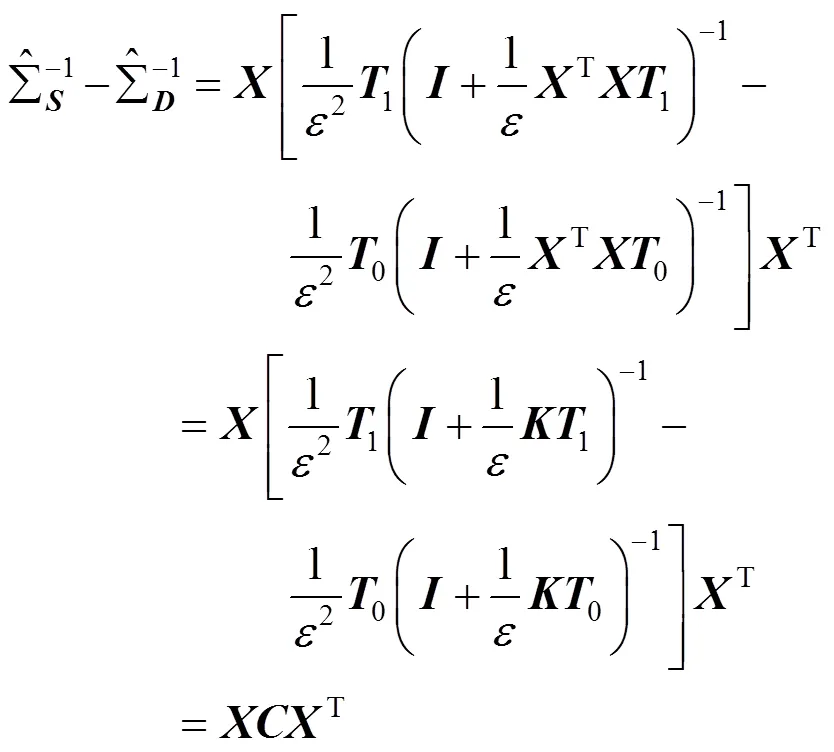
其中,=T为×的矩阵。并且得到下式
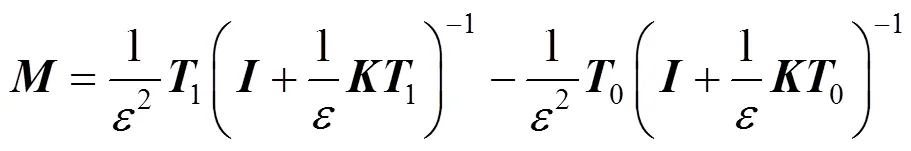
其中,=T。通过核函数替换内积,以在特征空间中执行度量学习。
k-KISSME的算法如下:
Algorithm 1 k-KISSME
Input: A pairwise training data (x,x), the kernel function K
Output: The distance2betweenxandx
Step 3: Calculate the distance2according to the Eq. (8) and (14)
该方法的最大的优点是:①线性KISSME方法通过使用内核技巧以直接的方式扩展到非线性场景;②允许在包含定义了内核函数的结构化对象的数据集上应用KISSME。由于仅需要核函数,所以可以在基于内核的框架内有效地处理许多未显示矢量表示的真实数据。k-KISSME的总体计算复杂度主要取决于矩阵的计算。值得指出的是,本文算法中的k-KISSME算法是结合eLOMO特征提出的,其对处理特征数量明显大于实例数量的问题具有优势。
3 实验结果与讨论
3.1 实验参数设置
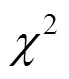
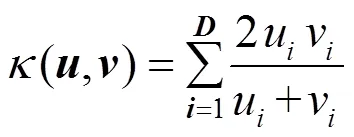
为了防止数据过拟合,需对参数进行正则化设置,正则化参数=0.001。实验中的其他参数在前文中已经给出。
实验配置内存为16 G的Intel(R) Core(TM) i7-8700 CPU,NVIDIA GeForce GTX 1070Ti GPU,Matlab2015b软件。
3.2 行人再识别基准数据集的实验结果
在3个广泛使用的行人再识别数据集上评估了所提出的方法,包括PRID450S[29],iLIDS[30]和CUHK01[31],以验证所提出的k-KISSME方法的有效性。图5为3个数据集中一些行人图像示例。
为了进行比较,重复进行了10次随机实验,以取得具有稳健性的实验结果。并对实验结果的方差进行计算,得到的方差值均小于0.04,再一次证明了实验的稳定性。在表2中的描述中,为训练集中的行人数量。将实验分为2组进行:①利用PCA降维技术使用低维特征的k-KISSME和其他度量学习方法之间的性能比较;②k-KISSME与目前先进的度量学习方法性能比较。在第1组,使用PCA基于相同的100维特征表示的度量学习方法,在第2组,使用原始特征进行k-KISSME方法与其他度量学习方法的性能比较。

图5 行人再识别数据集示意图

表2 实验数据集的简要介绍
3.2.1 PRID450S行人数据集实验结果
PRID450S数据集包含450个行人图像对的900张图像,且由2个不同的监控摄像头拍摄。由于不同的视点变化、背景干扰和部分遮挡,使得PRID450S数据集成为具有挑战性的行人再识别数据集之一。在实验中,为了减少计算时间,所有图像标准化为128×48的像素相同尺寸。试验随机选择225人的图像用于训练,其余用于测试。将k-KISSME与一些最先进的如SCNCD,QRKISS和XQDA等方法在基于LOMO特征的基础上进行比较。除此之外,还提出了基于eLOMO特征的k-KISSME方法与一些先进方法进行比较。表3的结果显示,k-KISSME在大多数报告的排名中获得了最佳或次佳的表现,其中基于eLOMO特征的k-KISSME方法在这些方法中获得了最高匹配率,尤其是在不使用PCA降维技术时的Rank-1匹配率达到了55.6%。本文方法具有比LOMO特征更加丰富、完整的表示,并且充分利用了核特征空间中的非线性特性。
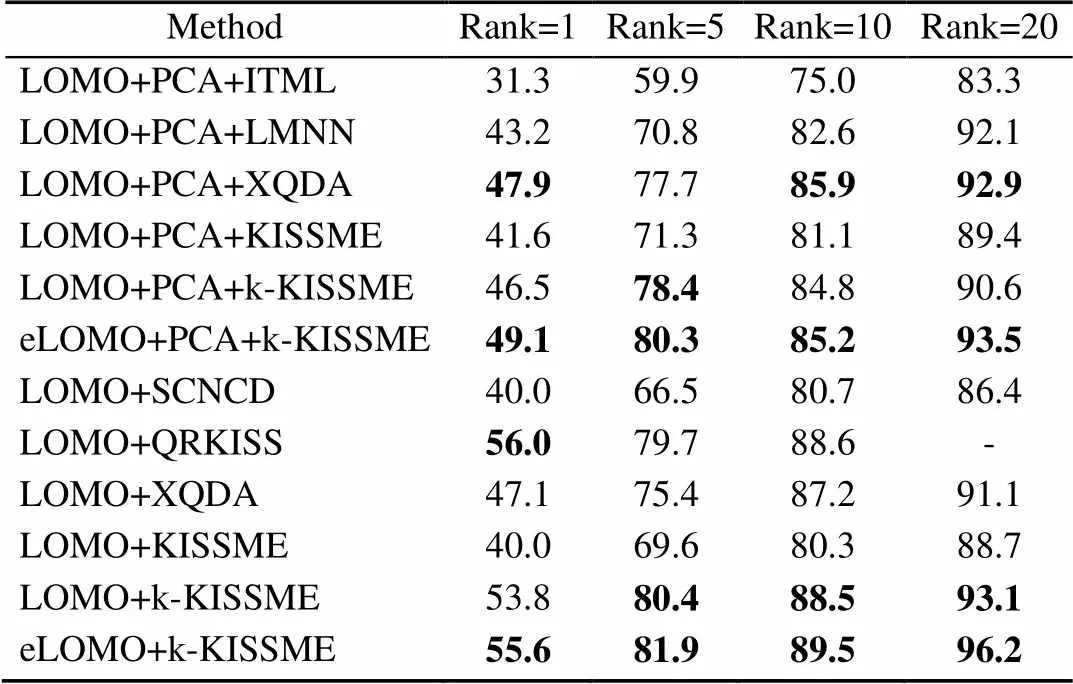
表3 PRID450S数据集中的最高匹配率
3.2.2 iLIDS数据集上的实验结果
iLIDS数据集包含从机场的2个非重叠摄像机拍摄的119个行人的476张图像。数据集中每个人的图像数量在2~8之间,所有图像被标准化为128×48像素的相同尺寸。由于该数据集是由机场相机捕获,所以其中大多数行人具有由行李或其他行人走动引起的遮挡问题。本文遵循广泛采用的试验方案,随机选择60人的图像用于训练,其余行人图像用于测试。使用基于原始的LOMO特征的方法进行比较,包括本文提出的k-KISSME度量学习和几种最先进的方法KISSME,XQDA,PCCA,LATENT-re-id[32],rPCCA,kLFDA,LFDA[33],MFA[34]和DCNN[35],本文将基于eLOMO特征的k-KISSME方法与一些先进方法进行比较。从表4中可以看出,k-KISSME始终优于XQDA和其他先进的方法,其中本文基于eLOMO特征的k-KISSME方法的性能表现最佳。与文献[35]中提出的深度网络相比,k-KISSME也能获得更高的等级匹配率。这是因为深度网络需要大量的实验数据,而iLIDS数据集只有少数行人的几百张图像,难以发挥深度网络训练大数据集的优势,但是本文方法却适用于小型数据集。
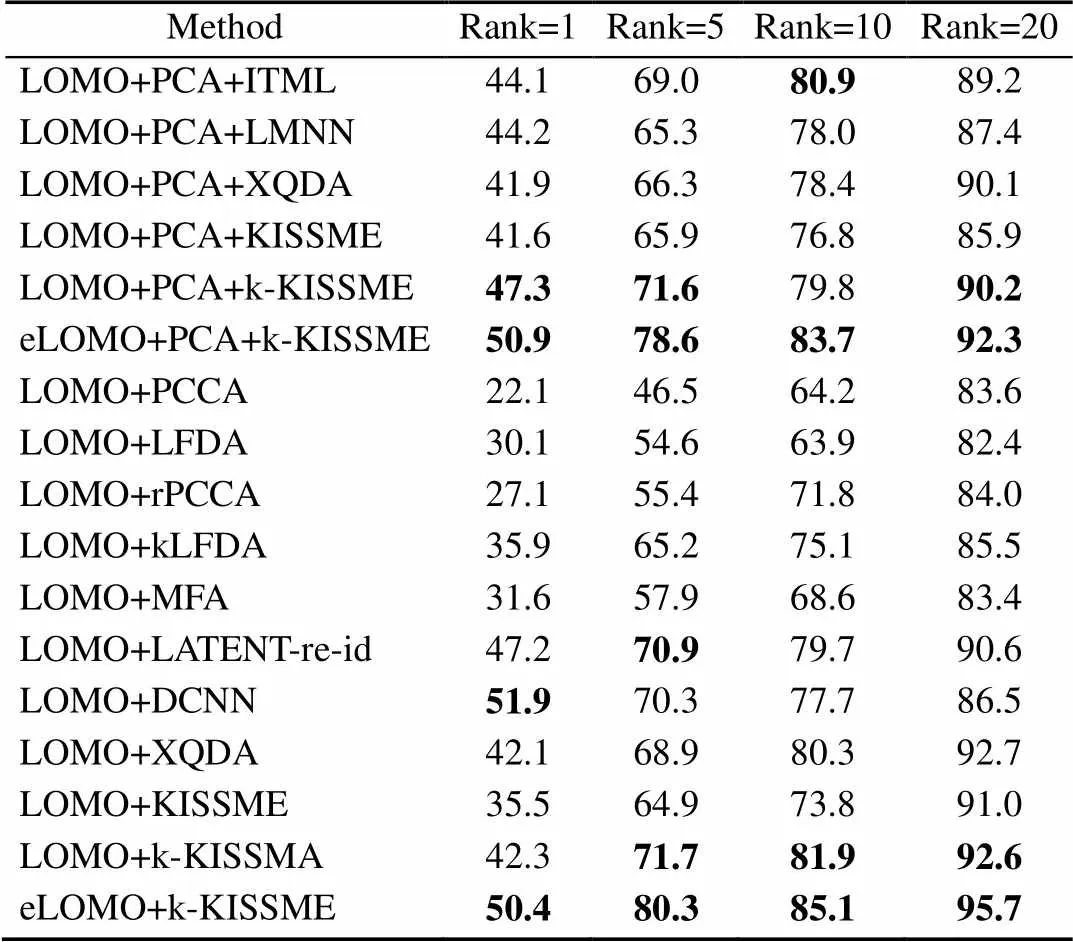
表4 iLIDS数据集中的最高匹配率
3.2.3 CUHK01数据集上的实验结果
CUHK01数据集包含从大学校园的2个不相交的摄像机拍摄的971个行人的3 884张图像,每个相机拍摄一个行人的4张图像,所有图像被标准化为128×48尺寸的像素分辨率。随机选取486人的图像进行训练,其余图像用于测试以便与其他方法进行比较。表5显示了基于原始LOMO特征的k-KISSME方法与一些最先进方法比较的结果,包括kLFDA,Ensembles[36],IDLA[37],ImpTrpLoss[38]和DeepRanking[39]。根据实验结果可以看出,本文提出的k-KISSME方法性能优异,其中基于eLOMO特征的k-KISSME方法的性能表现最佳或次佳。即使是与深度学习相比,其也能在Rank-1获得了比深度学习方法更好的性能,但是在Rank-5,10,20却没有深度学习性能高。这是因为深度学习方法使用数据增强等高级技术以提高匹配率,并能避免过度拟合。
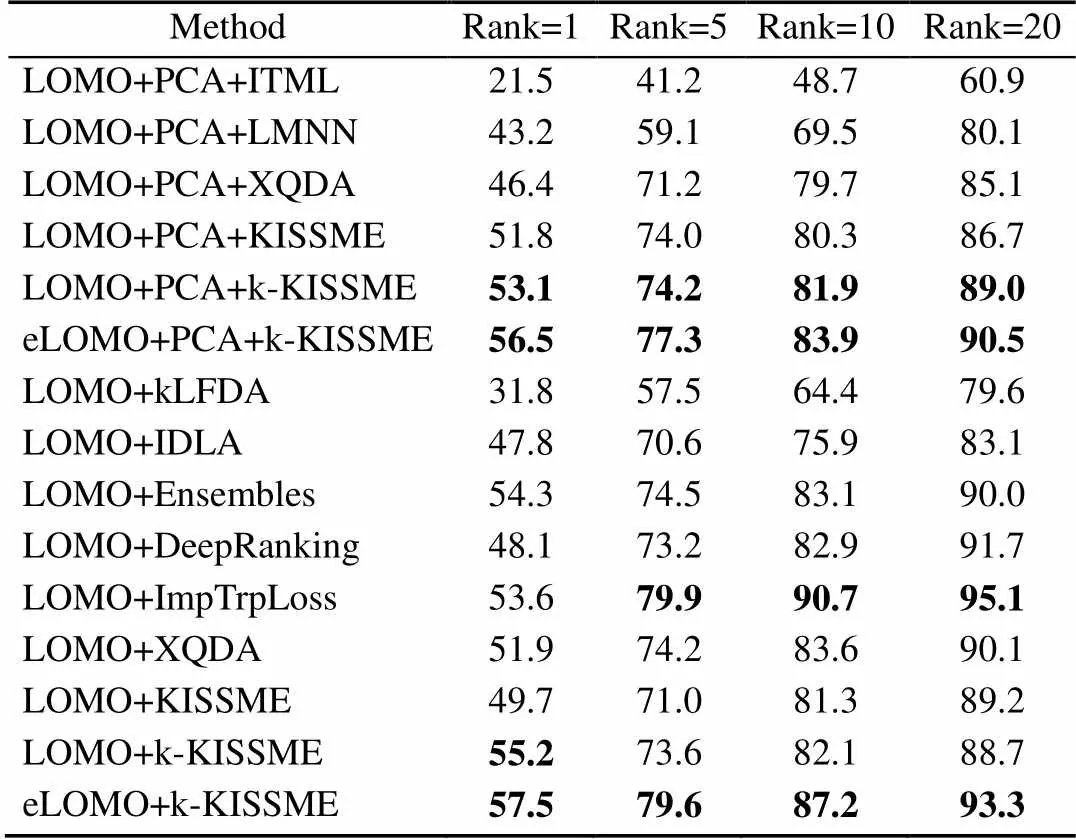
表5 CUHK01数据集中的最高匹配率
根据实验结果可以看到,当特征和维度相同时,在大多数数据集上k-KISSME方法在与传统的行人再识别度量学习方法相比,如ITML、LMNN、XDQDA、KISSME等,能够取得最佳的性能。并且与深度度量学习方法,如DCNN、SCNCD等相比,本文提出的k-KISSME方法的识别率也毫不逊色。值得注意的是,k-KISSME始终获得具有较小Rank值的高匹配率。由于最匹配的行人图像需要由操作员进行验证,进而低秩高匹配率的特性为行人再识别系统提供了重要信息。与其他特征相比较,K-KISSME在eLOMO特征上的高性能匹配率体现了其在应对特征数量明显大于实例数量的问题具有很大的优势。本文还注意到k-KISSME在应用PCA降维时的性能优于大多数线性方法,且k-KISSME使用核学习技巧在非线性特征空间中对复杂任务具有很好的鲁棒性。
3.3 运行时间
表6中显示了当前几种先进的度量学习方法在不同数据集上的平均训练时间。值得注意的是,该数据包含了计算eLOMO特征描述符和核矩阵的时间。从表中可以看出,XQDA在所有数据集上耗时最少,其次是KISSME。应该注意的是,k-KISSME比其他迭代方法(如ITML和LMNN)在小型数据集上要快得多。通过使用先进技术来加速核矩阵的计算,可以进一步改进运行时间。此外,k-KISSME实现起来非常简单,计算效率高,是本文的主要目标。

表6 几种度量学习方法的平均训练时间(s)
4 结 论
本文提出了联合增强局部最大发生特征和k-KISSME度量学习的行人再识别方法。其中,增强局部最大发生特征融合了行人图像的精细细节和整体外观信息,能有效解决由光线和视角变化等导致的行人外观不匹配的问题;k-KISSME的度量学习结合了核学习的非线性特性和KISSME方法的计算高效性,允许在由核函数引起的非线性特征空间中进行操作。实验结果表明,本文方法在3个行人再识别数据集上与其他先进的行人再识别方法相比提高了识别率。在将来的工作中,可以通过空间约束扩展本文方法,并将其应用到其他视觉学习任务。
[1] 李幼蛟, 卓力, 张菁, 等. 行人再识别技术综述[J]. 自动化学报, 2018, 44(9): 1554-1568. LI Y J, ZHUO L, ZHANG J, et al. A survey of person re-identification[J]. Acta Automatica Sinica, 2018, 44(9): 1554-1568 (in Chinese).
[2] YANG, YANG J M, YAN J J, et al. Salient color names for person Re-identification[M]. Computer Vision – ECCV 2014. Cham: Springer International Publishing, 2014: 536-551.
[3] GRAY D, TAO H. Viewpoint invariant pedestrian recognition with an ensemble of localized features[C]// Lecture Notes in Computer Science. Heidelberg: Springer, 2008: 262-275.
[4] CHEN Y C, ZHENG W S, LAI J. Mirror representation for modeling view-specific transform in person re-identification[C]//Proceedings of the International Conference on Artificial Intelligence. Buenos Aires: Argentina, 2015: 3402-3408.
[5] LIAO S C, HU Y, ZHU X Y, et al. Person re-identification by local maximal occurrence representation and metric learning[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 2197-2206.
[6] ZHAO R, OUYANG W L, WANG X G. Learning mid-level filters for person Re-identification[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 144-151.
[7] MATSUKAWA T, OKABE T, SUZUKI E, et al. Hierarchical Gaussian descriptor for person re-identification[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 1363-1372.
[8] LI Z, CHANG S Y, LIANG F, et al. Learning locally-adaptive decision functions for person verification[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2013: 3610-3617.
[9] MIGNON A, JURIE F. PCCA: a new approach for distance learning from sparse pairwise constraints[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2012: 2666-2672.
[10] WEINBERGER K Q, SAUL L K. Distance metric learning for large margin nearest neighbor classification[J]. Journal of Machine Learning Research, 2009, 10(2): 207-244.
[11] ZHENG W S, GONG S, XIANG T. Re-identification by relative distance comparison[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35 (3): 653-668.
[12] LISANTI G, KARAMAN S, MASI I. Multichannel- kernel canonical correlation analysis for cross-view person reidentification[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2017, 13(2): 1-19.
[13] ZHAO C R, CHEN Y P, WEI Z H, et al. QRKISS: a two-stage metric learning via QR-decomposition and KISS for person Re-identification[J]. Neural Processing Letters, 2019, 49(3): 899-922.
[14] WANG Z X, WANG Z, ZHENG Y Q, et al. Learning to reduce dual-level discrepancy for infrared-visible person Re-identification[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 618-626.
[15] YANG W X, YAN, CHEN S. Adaptive deep metric embeddings for person re-identification under occlusions[J]. Neurocomputing, 2019, 340: 125-132.
[16] TAO D, GUO Y, YU B J, et al. Deep multi-view feature learning for person re-identification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 28(10): 2657-2666.
[17] DAI J, ZHANG P P, LU H C, et al. Video person re-identification by temporal residual learning[J]. IEEE Transactions on Image Processing, 2019, 28(3): 1366-1377.
[18] ZHU X K, JING X Y, YOU X G, et al. Image to video person re-identification by learning heterogeneous dictionary pair with feature projection matrix[J]. IEEE Transactions on Information Forensics and Security, 2017, (99): 1.
[19] LUO P, WANG X G, TANG X O. Pedestrian parsing via deep decompositional network[C]//2013 IEEE International Conference on Computer Vision. New York: IEEE Press, 2013: 2648-2655.
[20] LIAO S C, ZHAO G Y, KELLOKUMPU V, et al. Modeling pixel process with scale invariant local patterns for background subtraction in complex scenes[C]//2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2010: 1301-1306.
[21] PROSSER B, ZHENG W S, GONG S G, et al. Person re-identification by support vector ranking[C]// Procedings of the British Machine Vision Conference 2010. UK: Aberystwyth, 2010: 1-11.
[22] ZHENG W S, GONG S G, XIANG T. Person re-identification by probabilistic relative distance comparison[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2011. New York: IEEE Press, 2011: 649-656.
[23] KÖSTINGER M, HIRZER M, WOHLHART P, et al. Large scale metric learning from equivalence constraints[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2012: 2288-2295.
[24] 齐美彬, 檀胜顺, 王运侠, 等. 基于多特征子空间与核学习的行人再识别[J]. 自动化学报, 2016, 42(2): 299-308. QI M B, TAN S S, WANG Y X, et al. Multi-feature subspace and kernel learning for person re-identification[J]. Acta Automatica Sinica, 2016, 42(2): 299-308 (in Chinese).
[25] XIONG F, GOU M G, CAMPS O, et al. Person re-identification using kernel-based metric learning methods[C]//European Conference on Computer Vision (ECCV). Heidelberg: Springer, 2014: 1-16.
[26] NGUYEN B, MORELL C, DE BAETS B. Supervised distance metric learning through maximization of the Jeffrey divergence[J]. Pattern Recognition, 2017, 64: 215-225.
[27] DAVIS J V, KULIS B, JAIN P, et al. Information- theoretic metric learning[C]//Proceedings of the 24th International Conference on Machine Learning-ICML ’07. New York: ACM Press, 2007: 209-216.
[28] PETERSEN K B, PEDERSEN M S. The matrix cookbook [EB/OL]. [2019-12-06]http://www2.imm.dtu. dk/pubdb/views/edoc_download.php/3274/pdf/imm3274.pdf.
[29] ROTH P M, HIRZER M, KÖSTINGER M, et al. Mahalanobis distance learning for person Re-identification[C]//Person Re-Identification. London: Springer London, 2014: 247-267.
[30] ZHENG W S, GONG S G, XIANG T. Associating groups of people[C]//Procedings of the British Machine Vision Conference 2009. UK: London, 2009: 7-10.
[31] LI W, ZHAO R, WANG X G. Human reidentification with transferred metric learning[C]//Computer Vision–ACCV 2012. Heidelberg: Springer, 2013: 31-44.
[32] SUN C, WANG D, LU H C. Person re-identification via distance metric learning with latent variables[J]. IEEE Transactions on Image Processing, 2017, 26(1): 23-34.
[33] PEDAGADI S, ORWELL J, VELASTIN S, et al. Local fisher discriminant analysis for pedestrian Re-identification[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2013: 3318-3325.
[34] YAN S C, XU D, ZHANG B, et al. Graph embedding and extensions: a general framework for dimensionality reduction[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(1): 40-51.
[35] DING S Y, LIN L, WANG G R, et al. Deep feature learning with relative distance comparison for person re-identification[J]. Pattern Recognition, 2015, 48(10): 2993-3003.
[36] PAISITKRIANGKRAI S, SHEN C H, VAN DEN HENGEL A. Learning to rank in person re-identification with metric ensembles[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 1846-1855.
[37] AHMED E, JONES M, MARKS T K. An improved deep learning architecture for person re-identification[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 3908-3916.
[38] CHENG D, GONG Y H, ZHOU S P, et al. Person re-identification by multi-channel parts-based CNN with improved triplet loss function[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 1335-1344.
[39] CHEN S Z, GUO C C, LAI J H. Deep ranking for person re-identification via joint representation learning[J]. IEEE Transactions on Image Processing, 2016, 25(5): 2353-2367.
Joint enhanced local maximal occurrence representation and k-KISSME metric learning for person re-identification
SUN Rui1,2, XIA Miao-miao1,2, LU Wei-ming1,2, ZHANG Xu-dong1,2
(1. School of Computer and Information, Hefei University of Technology, Hefei Anhui 230009, China; 2. Anhui Province Key Laboratory of Industry Safety and Emergency Technology, Hefei Anhui 230009, China)
Person re-identification is an important technique for automatically searching for pedestrians in surveillance videos. This technology consists of two key parts, feature representation and metric learning. Effective feature representations should be robust to changes in illumination and viewpoint, and the discriminative metric learning can improve the matching accuracy of person images. However, most of the existing features were based on local or global feature representation and failed to efficiently use the fine details and profile information of the appearance of pedestrians. More importantly, metric learning was usually conducted in a linear feature space, and nonlinear structures in the feature space couldn’t be efficiently utilized. To solve these problems, we first designed an effective feature representation called enhanced local maximal occurrence representation (eLOMO), which could realize the fusion of fine details and profile information of the appearance of the person image and satisfy the human visual recognition mechanism. Furthermore, we proposed a kernelized KISSME metric learning (k-KISSME) method, simple and efficient, only requiring two inverse covariance matrices to be estimated. In addition, to handle changes in light and viewing angle, we applied Retinex transforms and scale-invariant texture descriptors. Experiments show that the proposed method possesses the ability regarding abundant and integral person feature representation and improves the recognition rate of person re-identification in comparison with the existing mainstream methods.
person re-identification; enhanced local maximal occurrence feature; kernel-based learning; feature representation; metric learning
TP 391
10.11996/JG.j.2095-302X.2020030362
A
2095-302X(2020)03-0362-10
2019-12-09;
2020-03-10
国家自然科学基金面上项目(61471154);安徽省科技攻关强警项目(1704d0802181);中央高校基本科研业务费专项资金资助项目(JZ2018 YYPY0287)
孙 锐(1976-),男,安徽蚌埠人,教授,博士,硕士生导师。主要研究方向为机器学习、计算机视觉等。E-mail:sunrui@hfut.edu.cn
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
安徽电子信息职业技术学院学报(2020年5期)2020-11-13
计算机应用与软件(2020年6期)2020-06-16
速读·下旬(2019年11期)2019-09-10
小福尔摩斯(2019年2期)2019-09-10
电子制作(2019年2期)2019-02-14
摄影之友(影像视觉)(2018年12期)2019-01-28
雷达科学与技术(2017年5期)2018-01-15
都市丽人(2017年4期)2017-04-12
初中生世界·八年级(2017年3期)2017-03-24
