
基于语义分割的食品标签文本检测
2020-08-26 07:44王子亚王建新
农业机械学报 2020年8期
田 萱 王子亚 王建新
(1.北京林业大学信息学院, 北京 100083; 2.国家林业草原林业智能信息处理工程技术研究中心, 北京 100083)
0 引言
食品标签是印刷于食品封装容器上的文字,主要包括产品名称、配料、生产商、产地和营养成分等用于描述该食品相关信息的内容。消费者根据该信息查询并判断该食品是否符合自身需求,食品监督抽检机构根据该信息进行食品安全相关的数据挖掘和分析[1-2]。作为食品标签识别的必要步骤,食品标签的文本检测(即定位其边界)对于食品安全监督和保障非常重要。
文本检测是图像信息分析和提取过程中的重要技术,其关键在于如何区分和定位复杂的文本区域和背景区域。传统的图像文本检测主要利用人工设计特征检测图像中的文本,主要包括基于连通域分析和基于滑动窗口两类检测方法。其中,笔画宽度变换(Stroke width transformation,SWT)[3]和最大稳定极值区域(Maximally stable extremal regions,MSER)[4]是经典的基于连通域分析的方法,分别利用图像中文本的笔画宽度和像素特征获取文本区域。基于滑动检测窗的方法采用了自顶向下策略检测文本,该类方法[5-6]采用不同尺寸窗口对整幅自然场景图像进行扫描,然后提取窗口区域的人工设计特征[7-8],结合已训练的分类器判断图像中窗口位置是否为文本。
食品标签检测属于复杂场景下的文本检测[9],不同的食品包装包含不同尺寸、颜色、形状、对比度的标签文本,并且食品标签的背景相较于印刷文档更加复杂,传统的文本检测方法[10-13]受到人工设计特征的局限性,难以满足复杂的食品标签文本检测需求。目前,深度学习技术已经广泛应用于目标检测领域[14],并且对文本检测技术的创新具有重要的推动作用,能够有效避免人工设计特征存在的局限性。其中,基于区域建议的方法[15-16]由于需要预设固定形状的候选框,使其对不规则文本的检测受到限制。语义分割技术[17]能够从图像中分割任意形状目标区域,经典的语义分割算法包括FCN[18]、SegNet[19]、DeepLab[20]和PSPNet[21]等,目前已经出现众多基于语义分割的自然场景文本检测算法[22-25],但这些方法检测食品标签的准确率有待提升。本文借鉴经典语义分割算法的思路,提出基于语义分割的距离场模型,以检测食品标签文本,使计算机能够有效分割图像中的文本,实现食品包装上文本内容的自动定位。
1 数据集构建
鉴于目前没有公开可用的食品包装图像数据集,本文通过自采数据集形式进行模型训练和实验评估。通过手机拍摄,从不同颜色以及透明的袋、盒、瓶和罐状包装表面采集得到食品包装图像共计509幅,这些图像涵盖了茶叶类、肉制品、奶制品、调味品、食用油、干果类和酒类等主要食品类型。图像中包含不同的食品标签文本,文本框共计13 205个,其中矩形文本框11 880个,弯曲不规则文本框1 325个。但本文在研究过程中利用由若干个坐标点顺时针连接构成的多边形表示文本区域,因此并不对规则矩形和弯曲标签文本进行特别区分。
1.1 数据集划分
采用自助采样方法划分训练集和测试集,即假设初始数据集Q包含M个样本,每次使用有放回采样方式从数据集Q中随机选取一个样本,将其复制放入新数据集Q′中,每个样本每次未被采样到的概率为1-1/M,重复上述随机采样过程M次,得到一个新的数据集Q′。显然,数据集Q中存在一直未被采样到的样本,本文将这些样本作为测试集,其他样本作为训练集。通过这种采样方法使得从数据集Q中划分的测试集约占数据集总数的1/e,即
(1)
通过上述方法本文将食品包装图像划分为训练集和测试集,如表1所示,其中训练集图像为327幅且包含8 453个文本框,测试集图像为181幅且包含4 752个文本框。

表1 数据集数量Tab.1 Number of datasets
1.2 数据集标注
为了有效表示食品包装图像中标签文本区域,本文将属于同一标签内容的空间区域视为一个单独的文本区域。鉴于食品包装可能存在褶皱和弯曲的现象,采用由若干个坐标点顺时针连接构成的多边形表示文本区域,这样可以满足任意形状的标签区域标识需要,因此未区分规则矩形和弯曲标签文本。原始图像和人工标注如图1所示。

图1 原始图像和标注图像示例Fig.1 Examples of original images and annotated images
2 基于语义分割的距离场模型
针对食品包装图像中的标签文本检测,提出一种基于语义分割的距离场模型(Semantic segmentation based distance field model,DFM),该模型包含像素分类任务和距离场回归任务。DFM能够根据神经网络模型预测图像中文本区域内像素点至其边界的归一化距离以及文本与背景分割图。为了有效利用像素分类任务与距离场回归任务之间存在的联系以提升模型的检测效果,在回归预测模块中增加了注意力模块,并且针对距离场回归任务损失值过小导致模型训练优化不佳的问题,对其损失函数提出改进,以提高模型的预测准确率。最后根据DFM两类任务的预测结果利用扩展分组算法获得食品包装的标签文本区域。
2.1 模型框架
DFM包含两部分:多尺度特征提取模块和回归预测模块,多尺度特征提取模块利用基础网络提取并融合不同维度的图像特征,再将融合特征输入到回归预测模块。回归预测模块包含像素分类和距离场回归任务,分别预测食品包装图像中的文本分割图以及文本区域内像素到最近边界的归一化距离(简称距离场),模型检测流程如图2所示。
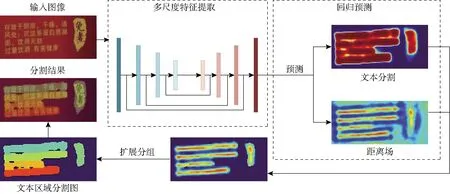
图2 基于语义分割的距离场模型检测流程Fig.2 Detection process of distance field model based on semantic segmentation
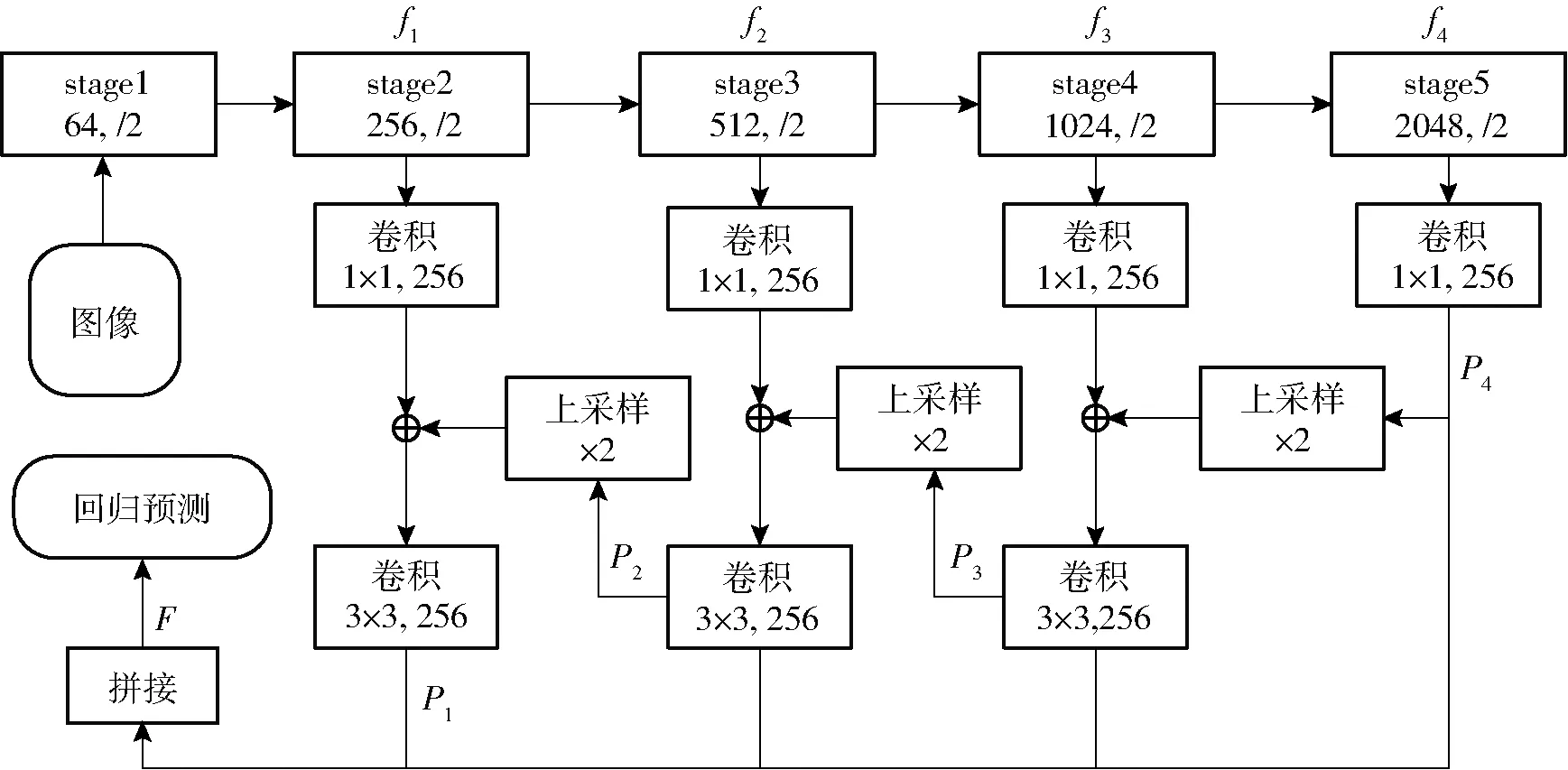
图3 基于语义分割的距离场模型结构Fig.3 Structure diagram of distance field model based on semantic segmentation
2.1.1多尺度特征提取模块
DFM使用ResNet[26]网络作为基础特征提取网络,该网络是当前应用最广泛的深度卷积特征提取网络之一。ResNet[26]主要由stage1~stage5共5个网络模块组成,多尺度特征提取模块采用基于FPN[27](特征金字塔网络)的方式,对ResNet[25]提取的特征进行融合作为后续回归预测模块的输入,即融合低维图像精细特征和高维图像粗略特征。
如图3所示,将ResNet-50网络中不同阶段得到语义特征f1、f2、f3和f4通过卷积和上采样运算得到不同维度融合特征P1、P2、P3和P4,其计算方式为
P4=Conv1×1(f4)
(2)
Pi=Conv3×3(Conv1×1(fi)+Up×2(Pi+1))
(i=1,2,3)
(3)
式中 Up×s——s倍上采样函数
Convk×k——核尺寸k×k的卷积函数
最后通过上采样运算和拼接操作将P1、P2、P3和P4合并得到多尺度融合特征图F,其计算方式为
F=[P1;Up×2[P2;Up×2[P3;Up×2(P4)]]]
(4)
式中 [X1;X2]——X1与X2拼接
2.1.2回归预测模块及其改进
回归预测模块对特征F进行卷积运算并上采样至原图像大小,得到预测图P∈RH×W×3,其中RH×W×2用于食品包装图像的像素分类预测任务,RH×W×1用于距离场回归任务,H和W分别表示输入图像的高度和宽度。
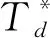
(5)
(6)
Pd=Pc
(7)
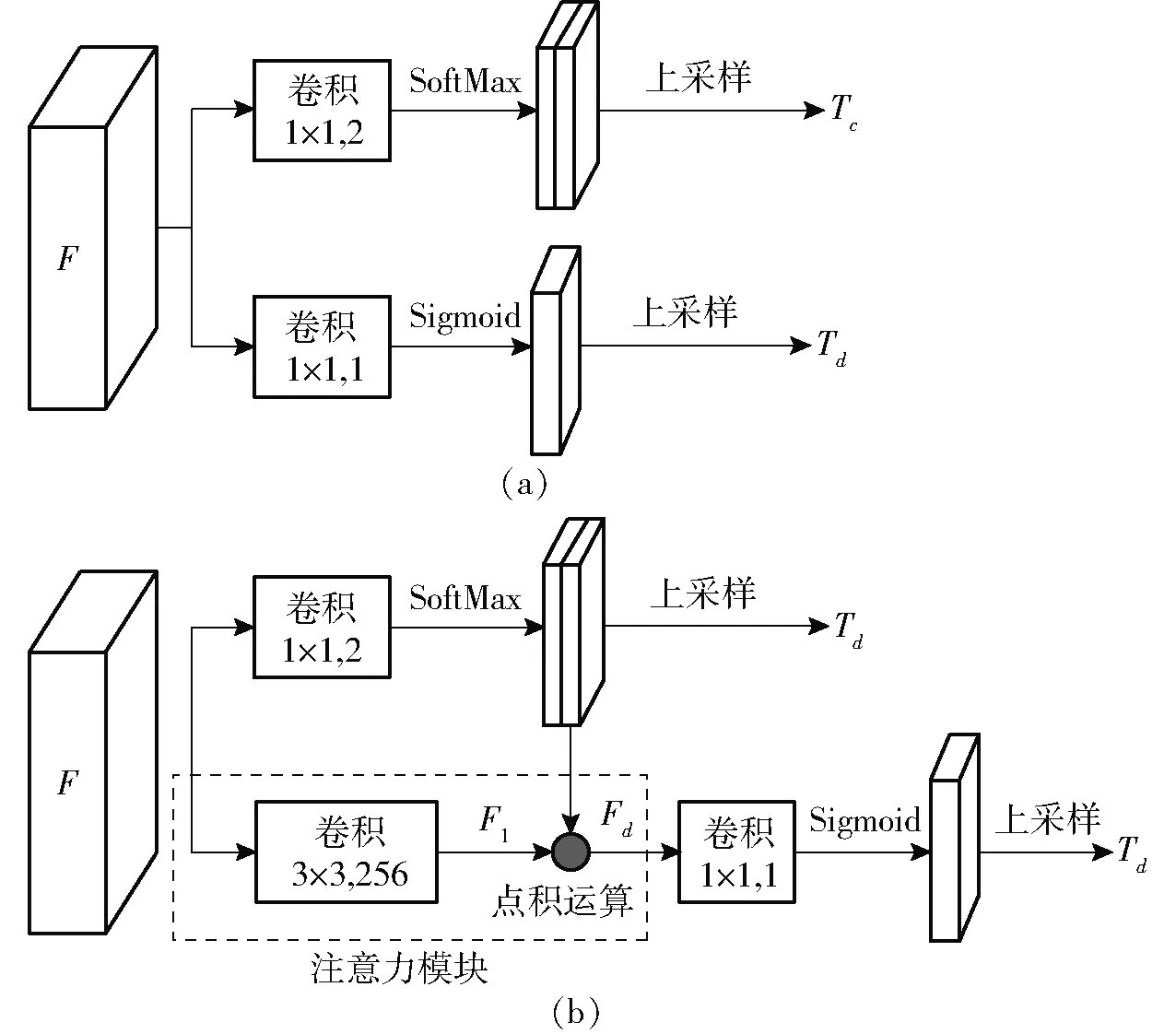
图4 回归预测模块结构Fig.4 Structure diagram of regression prediction module
在计算距离场损失值时,本文仅考虑图像文本区域中像素点距离预测值与真值的差距。因此,距离场的预测结果仅关注食品图像中像素分类结果为文本区域的特征,鉴于DFM两类预测任务之间存在这样的关联性,本文在回归预测模块增加注意力模块(Attention module,AM)以进一步强化任务之间的关系,并利用这种关系提高模型的预测准确率。如图4b所示,考虑到距离场的预测任务要比像素分类任务更加困难,本文在多尺度融合特征F的基础上利用宽高均为3的卷积核提取图像复杂特征F1,提高距离场预测结果准确性。然后将像素分类任务文本区域预测图与特征F1按元素相乘得到特征Fd,最后再对特征Fd进行卷积运算并通过Sigmoid激活函数得到距离场的预测结果Td。
2.1.3模型损失函数及其改进
DFM模型的损失函数L为
L=Lt+λLd
(8)
式中Lt——像素分类任务的损失函数
Ld——距离场回归任务的损失函数
λ——两类任务损失的平衡系数
(1)像素分类任务的损失函数
像素分类任务预测食品包装图像中标签文本区域,本文将文本区域内的像素点标记为正样本,背景区域的像素点标记为负样本,通常食品包装图像中背景区域占比较大,这种类别不平衡使得网络偏向学习背景特征从而影响食品标签的检测。当前有不同的解决方法处理该问题,例如困难负样本挖掘(Hard example mining,HEM)[28]、焦点损失函数(Focal loss)[29]和平衡交叉熵等,本文采用HEM策略筛选预测错误的负样本,使正负样本的比例为1∶3。并使用平衡交叉熵作为像素分类的损失函数,公式为
(9)
式中Ω——经过困难负样本挖掘获得的所有正负样本的集合
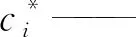
ci——预测置信度
(2)距离场回归任务的损失函数
仅依赖文本与背景的像素分类任务很难区分排列紧凑的文本行或者单词,本文提出距离场回归任务,即预测图像中属于文本区域内的第i个像素点与该文本区域边界的归一化距离di(图5a),将di大于阈值的部分视为文本中心区域,再向边缘区域按di递减扩展像素点,直至di不再递增。di的计算方式为
(10)
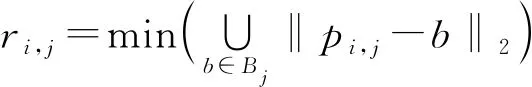
(11)
式中pi,j——属于文本区域j的第i个像素点的坐标
Bj——文本区域j的边界像素点坐标集合
ri,j——属于文本区域j的第i个像素点到其边界Bj的欧氏距离
rj——属于文本区域j的所有像素点至边界Bj欧氏距离的集合
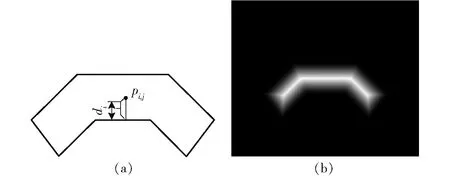
图5 距离场标签生成Fig.5 Label generation of distance field
为了消除距离对文本区域和图像尺寸的敏感性,本文将欧氏距离变换至范围为[0,1]的归一化距离di,将文本区域内像素点到边界的欧氏距离ri,j除以rj的最大值得到归一化距离di。对于背景区域的像素点,本文将其距离场的标签值设为零,最后生成的距离场标签如图5b所示。显然文本中心到边界区域的di逐渐减小,且相邻的不同文本区域边界区域的di呈现先递减再递增的变化趋势,这种特征有助于区分相邻的文本。最后基于分类预测和距离场回归结果使用后处理的距离场分组算法得到食品标签文本并分离相邻的文本,DFM的初始距离场损失定义为
(12)

在距离场真值标注中,由于越靠近边界区域的归一化距离值越接近于零,这种不一致性导致边界区域的距离场预测结果损失通常偏小,因而不能保证预测结果的准确性,这种损失值与期望准确率的不匹配性会影响距离场回归预测结果,进而影响后处理分组算法获取食品标签文本。
本文使用两个不同的方案解决该问题,从细节考虑,由于距离场损失和预测准确率的不匹配性源于误差参考尺度的不一致性,使用相对误差替换每个像素位置距离回归预测的绝对误差,即增加权重的方式,其计算方式为
(13)
从整体考虑,回归任务比分类任务有更高的预测精度要求,然而为了消除食品标签文本大小对距离的影响,本文使用归一化距离作为预测目标,这导致食品标签文本检测的距离场损失值很小,因此,在损失函数基础上增加开方运算自适应放大损失值,即增加开方的方式,而不仅依赖于固定的距离场损失系数,其计算方式为
(14)
为了对比验证不同函数对于模型训练优化的作用,本文将在距离场回归任务中分别采用损失函数Ld、Ld_w、Ld_s以及Ld_ws进行实验。Ld_ws为增加权重与开方的组合方式,其计算方式为
(15)
2.2 扩展分组算法
为了区分彼此靠近的食品标签文本,本文根据距离场任务的预测结果利用扩展分组算法来解决这个问题,其中心思想是源于广度优先搜索算法。模型预测结果中包含图像像素分类Tc和距离场Td,通过设置阈值α和β,将Tc>α且Td>β的区域通过连通域计算得到食品标签文本的中心区域Tk,如算法1第3~11行所示,其中α取值为0.9,β取值为0.5。
算法1 扩展分组算法
输入:像素分类预测Tc和距离场预测Td,文本区域分割阈值α,中心区域分割阈值β,边界阈值γ
输出:文本区域分割图Ts
1Tk←Tc>αandTd>β
2visited←∅,queue←∅,Ts←∅,N←0
3 forpi∈Tkdo
4 ifpi∉visitedthen
5queue.put(pi);visited←visited∪pi;N←N+1;K←∅
6 whilequeue≠∅ do
7pi←queue.pop();K←K∪(pi,N)
8 if ∃h∈neibor(pi) andh∉visitedandh∈Tkthen
9queue.put(h);visited←visited∪h
10 end if
11 end while
12queue.put(boundary(K))
13 whilequeue≠∅ do
14pi←queue.pop()
15 if ∃h∈neibor(pi) andh∉visitedandTd(pi)≥Td(h)≥γthen
16queue.put(h);K←K∪(h,N);visited←visited∪h
17 end if
18 end while
19Ts←Ts∪K
20 end if
21 end for
22 returnTs
然后将Tc>α的非中心区域像素点进行分组将其划分入不同的标签文本,如算法1第12~17行所示。该分组过程为:将Tk的边缘像素点作为初始点,选择每个像素点的相邻且未分组的点作为候选扩展点,根据标签文本区域距离场从内向外的递减特征,若候选像素点位置的距离场预测值不大于当前点,将其作为扩展像素点划分入Tk中,循环上述步骤寻找新增点的候选扩展点并判断是否符合分组条件,直至扩展到边界时停止。由于Sigmoid激活函数预测值大于零,算法实现中将距离场边界的阈值γ设置为很小的值(本文中γ取值为0.001)而不是零。
3 实验与结果对比分析
3.1 模型训练与评估
3.1.1训练细节及参数
由于本文数据集偏小,故采用以下数据增广策略提高模型训练效果:将图像随机垂直翻转或旋转大小在(-10°,10°)区间内的角度;将图像按照比例{0.5,1.0,2.0}随机缩放;从图像中随机裁剪尺寸为512像素×512像素子区域作为训练样本。此外,还将图像按通道内的均值和标准差进行归一化以统一训练数据的分布,增加模型的训练速度。训练阶段使用权重(decay)为0.001、动量为0.9的随机梯度下降算法作为优化器,损失函数平衡系数λ取值为5,每次训练图像数量为8,数据集训练轮次(epoch)为600,初始学习率为10-3,且每150轮次缩小90%。
3.1.2评估方法
目前文本检测包含3个评价指标:召回率Rrecall、准确率Pprecision和调和平均值Fmeasure,调和平均值的计算方法为
(16)
真值框与检测框的交并比Ii,j的计算方法为
(17)
式中 intersection(·)——交集函数
union(·)——并集函数
area(·)——面积函数
Gi——真值框Dj——检测框
3.2 实验结果对比
为了验证注意力模块对模型的影响以及不同损失函数的预测效果,通过消融实验对比改进前后的模型检测性能。并且为了证明模型检测食品标签文本的准确性,将DFM与其他文本检测模型进行实验对比,并介绍分析实验结果。
3.2.1不同回归预测模块的对比
首先分别对改进前的预测结构(图4a)以及改进后包含注意力模块的预测结构(图4b)进行训练,以此验证注意力模块对于模型性能的提升。为了消除损失函数优化对于实验结果的影响,本实验的损失函数采用均方差损失函数Ld,其具体计算方法如式(12)所示。实验结果如表2所示,增加空间注意力模块使得模型在准确率以及调和平均均有所提升,分别提高了4.39、2.23个百分点。相较于改进前直接预测像素分类结果和距离场回归结果的方式,通过增加注意力模块使得距离场的回归预测与像素分类结果存在关联关系,即利用像素分类任务的预测结果弱化模型提取的图像背景区域特征,使得距离场回归任务减少对于非文本区域的错误预测,而当距离场回归任务出现假文本区域的距离场预测结果时,表明模型的像素分类任务存在错误的背景与文本预测结果,通过间接反馈使得模型在训练的过程中进一步优化像素分类任务。其意义在于使得模型的像素分类任务更加关注图像的背景与文本的二分类预测,降低模型对于食品图像中背景区域的错误预测,从而增加模型整体的预测准确率。

表2 是否包含注意力模块的模型对比Tab.2 Model comparison of whether or not attention modulewas included %
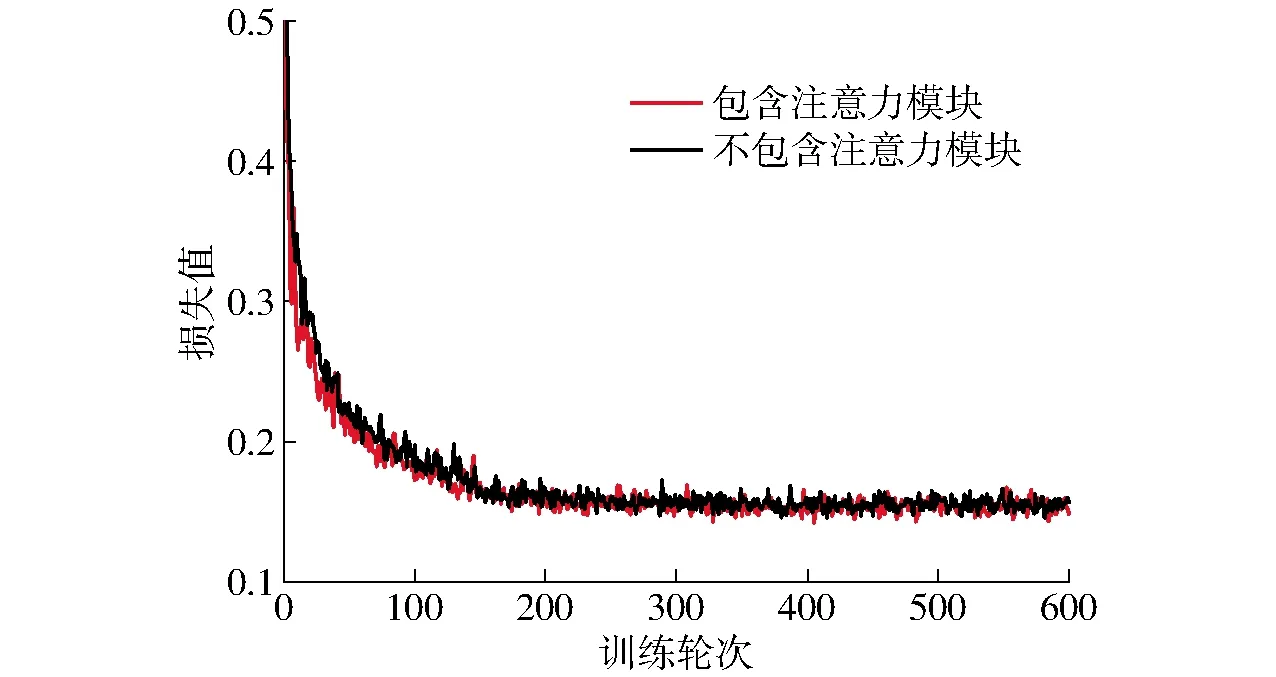
图6 模型训练过程的损失值对比Fig.6 Comparison of loss value during process of model training
如图6所示,注意力模块使得模型在训练过程中收敛更快,并且模型预测任务的损失值略小于未包含注意力模块的模型。这说明增加注意力模块有效减少了像素分类任务以及距离场任务对于图像中非文本区域的错误预测结果。鉴于注意力模块对模型预测准确率的有效提升,回归预测模块采用包含注意力模块的架构设计。
3.2.2不同损失函数的对比
在增加注意力模块的基础上,为了验证距离场回归任务中损失函数修改的有效性,对4种距离场损失函数分别进行了实验,实验结果如表3所示。其中利用开方自适应增加损失值的方式将准确率提升了3.80个百分点。增加权重的方法使得模型在检测性能上没有明显的提升,由于增加权重的方法中权重值大于等于1,因此一定程度上等效于增加了损失值,但增加边缘区域的损失权重意味着中心区域的损失权重相对降低,进而影响距离场中心区域距离值的预测准确性,弱化了模型预测准确率的提升效果。这也使得同时使用两种方法相较于仅使用开方自适应增加损失值的方式准确率减低了1.85个百分点。因此本文最终采用Ld_s作为模型的距离场回归任务损失函数,易于模型的训练优化,提高模型的预测准确率。
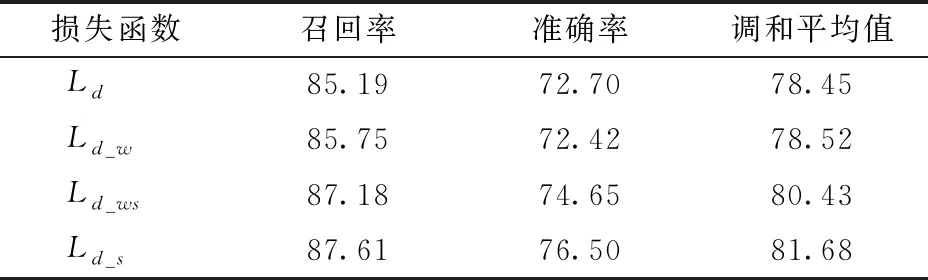
表3 不同距离场损失函数训练的模型对比Tab.3 Comparison of model trained with different distance field loss functions %
3.2.3不同模型方法的对比
为了验证DFM对食品标签文本检测的性能,最后将DFM与基于语义分割的自然场景文本检测方法TextSnake[22]、TextField[25]和PSENet[23]作对比如
表4所示,实验结果表明DFM对食品标签文本检测具有更高的性能,改进前的初始模型准确率较其他模型提升约2个百分点,增加注意力模块以及损失损失函数的改进使得DFM的召回率、准确率和调和平均值分别为87.61%、76.50%和81.68%,比其他模型的召回率提升超过2个百分点,调和平均值的提升超过7个百分点。相较于改进前,改进后的DFM预测结果比其他模型更加准确。
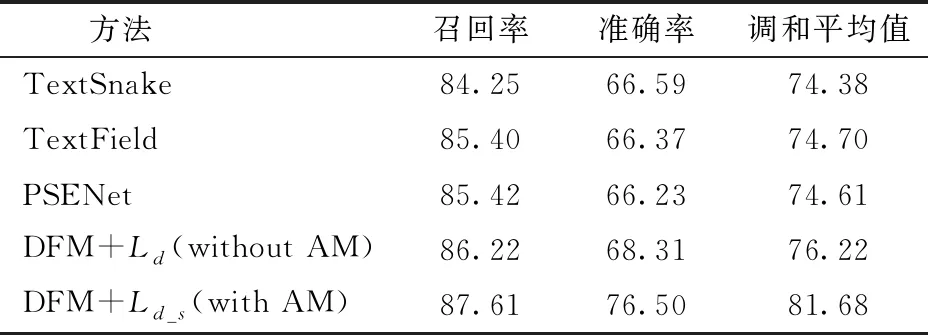
表4 不同模型方法的对比Tab.4 Comparison of different models %
对食品标签文本检测效果的影响主要在于标签文本检测不准确或者丢失。如图7所示,TextSnake[22]模型中利用圆盘参数表征文本区域,其圆盘连接不稳定,极大影响了检测效果。TextField[25]模型根据预测结果生成的文本区域代表像素存在丢失的情况,导致检测文本失败。PSENet[23]模型检测营养成分等较小的文本存在丢失,该方法依赖于标签中心区域的文本和背景二分类预测,对于很小的文本其中心区域极小,很容易被忽略。DFM对标签文本的检测比其他方法更加准确,PSENet[23]检测到图像中的文本,但并没有将属于同一标签的内容定位为整体,并且丢失了强光照附近的标签内容。

图7 不同模型的检测效果对比Fig.7 Comparison of detection result of different models
4 结束语
针对食品包装上的食品标签检测提出一种基于语义分割的距离场模型,对模型回归预测模块结构和距离场回归任务损失函数的改进使得模型的预测准确率分别提升了4.39、3.80个百分点。改进后的DFM模型在食品包装图像数据集上的调和平均值达到81.68%,优于近两年流行的其他自然场景文本检测模型。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
科学导报(2022年19期)2022-04-02
食品安全导刊·中旬刊(2019年4期)2019-09-10
红领巾·萌芽(2019年8期)2019-08-27
小学生导刊(2018年34期)2018-12-18
食品安全导刊(2017年9期)2017-09-13
CHIP新电脑(2016年3期)2016-03-10
山东青年(2016年3期)2016-02-28
母子健康(2015年1期)2015-02-28
延河(下半月)(2014年3期)2014-02-28
