
不可忽略的无回答机制下的校准研究
2020-08-24 05:42金勇进刘晓宇
统计与信息论坛 2020年8期
金勇进,刘晓宇
(中国人民大学 a.应用统计科学研究中心;b.统计学院;c.调查技术研究所,北京 100872)
一、引言
在抽样调查中,出于现实条件的限制,难免会产生一定数量的无回答。调查中的无回答是指由于种种原因没有能够对被抽出的样本单元进行计量,从而没有获得有关这些单元的数据。无回答是造成缺失数据的基本原因,它不仅使有效样本量减少、样本信息难以真实反映总体情况,还导致估计量有偏且方差增大,从而影响了统计数据质量。
在不同的缺失数据机制下,回答单元与无回答单元之间的相似程度和相互关系不同,需根据不同情况选择相应的处理方法。Rubin将缺失数据机制分为完全随机缺失、随机缺失和非随机缺失,可忽略的无回答机制对应的缺失数据机制为完全随机缺失和随机缺失,目标变量y是否作答与缺失的y值无关;不可忽略的无回答机制对应的缺失数据机制为非随机缺失,目标变量y是否作答与y值有关,无论其是否被观测到[1]。当缺失数据是完全随机缺失时,可直接利用观测数据进行推断,文中不予讨论,后文提及的可忽略缺失数据机制仅指随机缺失。
已有研究多在可忽略的缺失数据机制假定下讨论,通常以插补法和加权法为基础[2]。插补法根据观测数据构造预测分布,再根据插补值对完整数据集进行分析,其效果取决于预测分布的拟合情况。加权法通过增大回答样本的权数以代表无回答样本,其效果取决于对回答概率的估计优劣。对可忽略的缺失数据机制的讨论很有必要,但不够完整,忽略了现实中更一般的“不可忽略的无回答”,此时基于随机缺失假定的处理方法不再适用。对于不可忽略的无回答机制,现有研究较少,主要基于模型进行,将缺失数据的条件分布转化为完整数据和响应模型的乘积[3],此类方法的缺陷主要表现在以下两方面,一是该方法属于参数方法,模型假设较强、对模型的错误识别非常敏感;二是由于数据缺失,无法评估模型的好坏、验证模型是否适用。
随着抽样调查的发展,辅助信息起着愈发重要的作用[4]。校准法就是一种系统利用辅助信息进行权数调整的方法,最早由Deville和Särndal提出,校准估计量具有渐进无偏性和设计一致性[5-6]。Lundström和Särndal首先将校准法用于无回答问题[7]。金勇进等人对项目无回答问题中的校准估计进行了研究。已有研究表明,校准法不仅可以减小估计标准误,还可以校正由样本无回答、抽样框覆盖不全或重复而导致的误差[8]。Oh和Scheuren提出的准随机化方法,将样本是否回答看作概率抽样的一个阶段,并假定回答概率服从某一响应模型,在此基础上,有学者将不同形式的响应模型用于校准估计,以降低对模型识别的敏感度[9]。然而,现有研究并未区分缺失数据机制,缺少不可忽略的无回答机制下的针对性研究。
本文聚焦不可忽略机制下的无回答,基本思路是将校准法和响应模型结合,在保持校准估计量优良性质的基础上,解决前文提出的现有无回答处理方法所存在的问题,该方法称为RGRG法。本文的创新之处在于统一理论和应用,理论方面:从模型形式上直观体现无回答机制的不可忽略性;应用方面:在实证分析中直接利用目标变量进行响应模型的建模。研究表明,RGRG法规避了已有方法的不足,解决了不可忽略的无回答机制下的权数调整和估计问题,同时放松了对模型识别和模型假设的要求。
二、模型校准法与准随机化的响应模型
模型校准法利用超总体模型刻画总体分布,根据辅助信息调整权数。准随机化方法的响应模型是根据对单元回答概率的估计调整权数。二者均可用于权数的调整,将其结合,响应模型可以体现缺失数据机制,校准法作为估计途径,可以保证估计量的优良性质。
(一)基于模型的校准法
假设已知样本单元p维辅助变量xk(k∈S)和p维工具向量zk(k∈S)、已知辅助变量xk的总体总值Tx。根据变量x建立校准方程为:
线性超总体模型由式(1)、(2)、(3)组成:
(1)
E{εk|(xj,zj;j∈U}=0
(2)
f(yk|[xj,zj,Ij;j∈U])
=f(yk|[xj,zj;j∈U])(k∈U)
(3)

(二)准随机化方法下的响应模型
准随机化方法最早由Oh和Scheuren提出,它在抽样设计原有随机性基础上,将样本单元是否作答看作概率抽样的一个阶段,增加了一层随机性[9]。用示性变量体现这两部分随机性,令Ij=IjsIjr,若单元j在原始样本中,则Ijs=1,否则为0;若单元j作答,则Ijr=1,否则为0。单元的入样情况和回答情况相独立,即Ijs和Ijr关于j独立。准随机化的方法下的响应模型为:
pk=Pr(Ikr=1|[xj,zj,Ijs;j∈U],
(4)
其中γ是未知参数,h(η)是一个单调、二阶可微函数。响应模型刻画了第k个单元回答的概率,其中函数h(η)可采取不同形式,如h(η)=1+η、h(η)=1+exp(-η)、h(η)=exp(η)等。Folsom和Singh对不同函数h(η)进行了总结[13]。
(三)模型校准法与准随机化响应模型的结合
通过校准法可实现对响应模型的参数估计,校准方程对参数g加以限制,通过超总体模型寻得最优参数,最后根据响应模型调整权数。
在超总体模型(1)、(2)、(3)基础上,结合响应模型(4)进行校准,校准方程为:
(5)
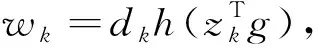
超总体模型下可得到目标变量总值Ty的无偏估计,响应模型下的校准估计是Ty的一致估计。两个模型只要有一个成立即可得到Ty的良好估计,这就是校准估计对无回答的双重保护机制。
三、RGRG法:不可忽略的无回答机制下的处理方法
前文将模型校准法与准随机化的响应模型相结合,用于无回答情况下的权数调整和参数估计,但并未区分无回答机制。现在对前述模型进行适当修改,以区分不同类型的缺失数据机制,由此得到RGRG法。此部分主要对RGRG法的模型假设、模型形式和估计量性质进行分析。
为区分不同协变量的用途,我们称用于响应模型建模的协变量为模型变量,用于构建校准方程的变量为背景变量。校准法要求已知样本单元的背景变量和背景变量的总体总值,响应模型要求已知回答者的模型变量。在进行不可忽略无回答机制下的权数校准时,根据不同变量的用途可知,目标变量本身也可以作为模型变量,即变量y可以作为变量z的一部分,因为它对于回答者而言是已知的。
(一)模型推导
回顾线性超总体模型(1)、(2)、(3),为便于分析再次列出:
(6)
E{εk|(xj,zj;j∈U}=0
(7)
f(yk|[xj,zj,Ij;j∈U])
=f(yk|[xj,zj;j∈U])(k∈U)
(8)
模型在给定变量x、z的情况下,样本选择机制和回答机制可忽略,只有控制了变量x、z才能利用超总体模型进行分析。现有模型无法体现非随机的数据缺失机制:在公式(8)的作用下,对于单元k∈S和k∉S均有公式(6)、(7)成立,回答样本和无回答样本的目标变量y分布相同。对于不可忽略机制下的无回答,回答机制与目标变量y有关,选择机制却没有这样的相关关系。因此,需对式(7)、式(8)进行修改。
首先将式(7)简化为E{εk|(xj;j∈U)}=0,再将式(8)变为f(yk|[zj,Ij;j∈U])=f(yk|[zj;j∈U])。修改后的模型假定回答机制关于变量z可忽略,对于误差项而言,有E{εk|(xj;j∈U)}=0成立,此时E{εk|(xj,Ij;j∈U)}=0不一定成立,也就是说,样本中回答者与无回答者的目标变量分布不一定相同,无回答机制可以是不可忽略的。至此,经过对式(7)、(8)的修改,为不可忽略的无回答机制下的分析提供了可能。由此得到的RGRG法,完整模型由式(9)、(10)、(11)组成:
假定目标变量y与协变量x的关系为:

(9)
E{εk|(xj;j∈U)}=0
(10)
f(yk|[zj,Ij;j∈U])=f(yk|[zj;j∈U])
(11)
假定单元k的回答概率为如下响应模型:
pk=Pr(Ikr=1|[xj,zj,Ijs;j∈U],
校准方程为:
(13)
其中示性变量Ij=IjsIjr,Ijs表示单元j的入样情况,Ijr表示单元j是否作答;γ是未知参数,估计值为g;h(η)是一个单调、二阶可微函数。

根据Kott的研究,估计量方差的渐进无偏估计为[6]:
(14)
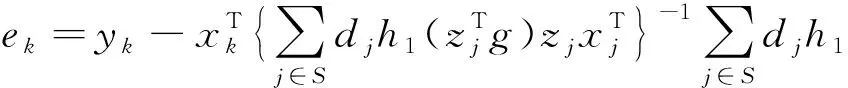
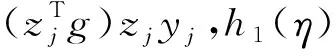
(二)模型扩展
考虑模型(9)、(10)、(11)的另一种表达形式,将其转化为式(15)、(16)构成的模型。假设目标变量y与模型变量z具有线性关系,背景变量x可以通过多元测量误差模型拟合:

(15)

(16)
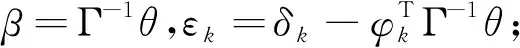
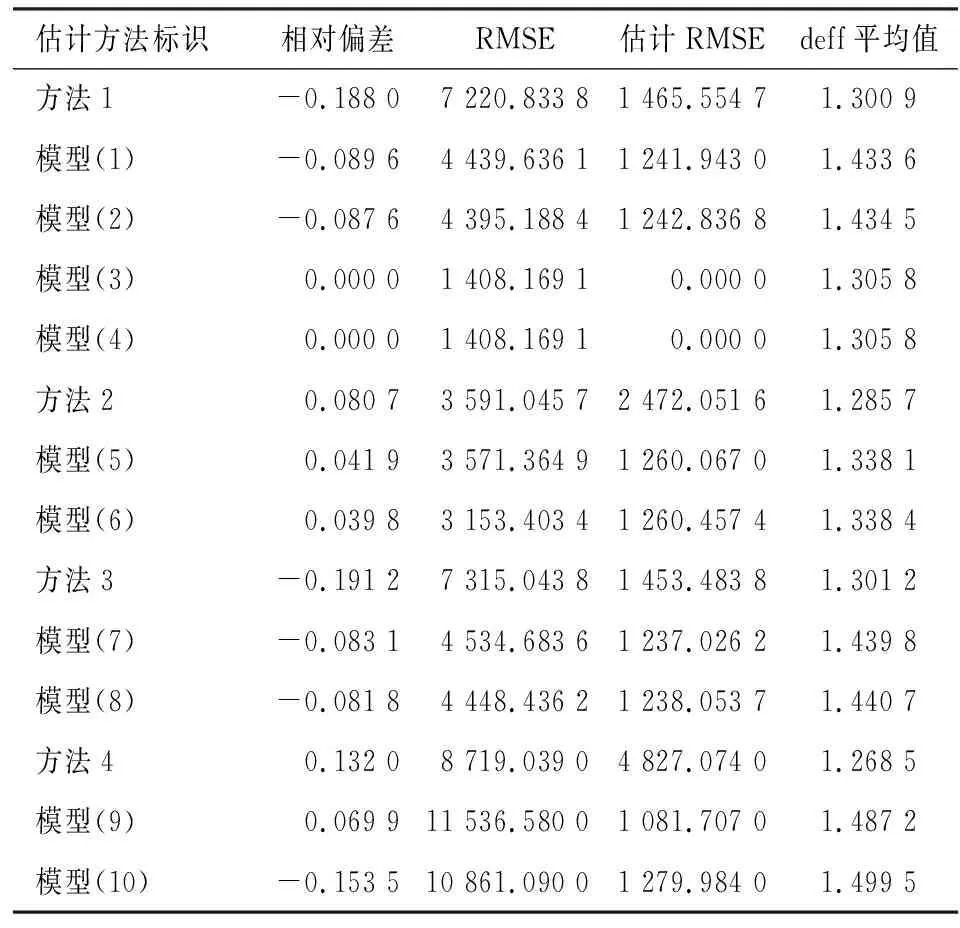
前述分析均假定背景变量x的维数p和模型变量z的维数q相同,而二者的功能不同,如何取消维数限制仍缺乏研究[15]。Chang和Kott对q RGRG法在非随机缺失机制下,将校准法与响应模型相结合,校准法在超总体模型的假定下进行,旨在估计响应模型的参数。响应模型在准随机化方法下进行,用于设计权数的调整。校准法可以根据辅助变量调整权数,为每个设计权数生成一个调整因子,当调查中出现的无回答不可忽略时,权数调整因子可以隐式估计在假定的响应模型下每个单元回答概率的倒数。因此,校准加权可以消除或大大减少无回答偏差。假定目标变量与校准变量具有线性关系,并且不受样本选择机制和回答机制的影响,那么无论响应模型是否成立,目标变量的校准估计都是总体参数的优良估计。 RGRG法为不可忽略无回答机制下的权数调整与总体估计提供了有效途径,估计量具有良好的统计性质,是渐进无偏和渐近一致的。同时,RGRG法对无回答具有双重保护作用,模型假设较简单,并降低了对模型识别的敏感度。 本文采用2015年CGSS(China General Social Survey)调查数据,进行不可忽略的无回答机制下的校准研究。CGSS调查始于2003年,是中国最早的全国性、综合性、连续性学术调查项目,全面收集了社会、社区、家庭、个人多个层次的数据,由中国人民大学调查与数据中心组织实施。调查的目标总体范围涵盖了全国31个省份(不含港澳台)的所有城市、农村家庭户,并通过分层三阶段抽样的方式获取了全国层面的代表性样本。 由于收入属于个人隐私问题,在面访调查中,受访者可能由于自身收入水平导致无回答情况的产生,故个人年收入符合不可忽略机制的条件。经济学中的人力资本理论将劳动者收入差异主要归结为劳动者人力资本的不同,教育水平和性别是影响人力资本的重要因素。其中,教育可以提高人的知识和技能,进而提高生产能力,增加个人收入,并进一步使个人工资和薪金结构发生变化;在人力资本视角下,女性劳动者和雇主的双向理性选择,导致了劳动力市场普遍存在着性别收入不平等现象。因此,本文选取个人年收入作为目标变量进行均值估计,将个人年收入的均值简称为人均年收入,选取教育水平和性别作为辅助信息,模型构建详见下文。 表1 样本构成(n=8 675) 根据受教育程度和性别进行交叉分类,样本分布如表2。 表2 交叉分布:受教育程度×性别(n=8 675) 事后分层法是校准法的特殊情况,进行校准的辅助变量为事后层的总体规模,是处理无回答问题的常用方法之一。为说明RGRG法在不可忽略的无回答机制下的估计优势,分别使用事后分层法和RGRG法进行校准估计。现从以下三方面对实证过程进行说明:无回答样本的构造、辅助信息的选择和响应模型的拟合函数选择。 个人年收入为目标变量,其回答情况与收入本身密切相关。假定收入越高回答率越低,无回答单元的生成方法如下:以个人年收入的上、下五分位数为截点,将样本分为低收入、中等收入和高收入人群,设定这三类人群的无回答率为p=(0.2,0.3,0.6),计算可知总体无回答率为0.2×0.2+0.6×0.3+0.2×0.6=0.34。为研究样本量对RGRG法的影响,分别从原样本(样本量为n=8 675)中随机抽取样本量为0.8n、0.5n和0.3n的样本进行估计。 事后分层的辅助变量采用受教育程度和性别,具体信息见表2。RGRG法的背景变量采用受教育程度和性别,为说明RGRG法在模型变量选取上的优势,分别采用受教育程度和个人年收入、受教育程度和性别两种组合;受教育程度分为五类、性别分为两类、个人年收入根据人均年收入划分为两类。据此得到10维背景变量和10维模型变量。 不同估计方法的标识及模型设置详见表3。 表3 模型设置 本文共进行500次重复试验,按照上文所述的构造方式随机生成无回答单元,在n、0.8n、0.5n和0.3n的样本量下,分别采用事后分层法、RGRG法进行估计。估计方法的评价准则采用相对偏差、均方误差根(RMSE)、估计均方误差根(估计RMSE)和权效应(deff)的平均值①,结果见表4。 表4 不同模型的估计结果 1.RGRG法与事后分层法的对比 根据表4,对比方法1和模型(1)~(4)、方法2和模型(5)~(6)、方法3和模型(7)~(8)、方法4和模型(9)~(10),可得到事后分层法和RGRG法的相对优劣。 以方法1和模型(1)~(4)的估计效果为例,可以看到,模型(1)~(4)的相对偏差、均方误差根和估计均方误差根显著小于方法1的相对偏差、均方误差根和估计均方误差根,RGRG法的估计效果优于事后分层法。其中,方法1与模型(3)~(4)的比较结论与Kott的研究结果相同,其估计效果良好,但由于其响应模型没有体现无回答机制的不可忽略性,此处仅作为历史研究的验证,不作详细讨论[14]。对比方法2和模型(5)~(6)、方法3与模型(7)~(8),与方法1和模型(1)~(4)的相对优劣相同,RGRG法的效果均明显优于事后分层法。对比方法4和模型(9)~(10),当样本量较小时,RGRG法的偏差和估计RMSE小于方法4,但RMSE较大,RGRG法的估计优势并不明显。 权效应(deff)可以反映相同抽样方法下权数对估计量方差的影响。根据表4可知,虽然RGRG法的权效应与事后分层法相比较大,但均在1.5以下,从权效应的角度考虑,根据RGRG法对设计权数进行调整,有效控制了调整后权数的波动性、估计效果良好。 总体而言,无论模型变量如何选择、响应模型如何构造,与传统基于设计的事后分层法相比,RGRG法具有明显优势,估计效果更优、估计结果更精确。 2.样本量、响应模型对RGRG法的影响 对比模型(1)~(2)、模型(5)~(6)、模型(7)~(8)和模型(9)~(10),可得到样本量对RGRG法估计效果的影响。对比模型(1)与(2)、模型(3)与(4)、模型(5)与(6)、模型(7)与(8)以及模型(9)与(10)可得到不同响应模型对RGRG法估计效果的影响。 对比模型(1)~(2)、模型(5)~(6)、模型(7)~(8)和模型(9)~(10),当样本量由n(模型(1)~(2))减小到0.8n(模型((5)~(6))、再减小到0.5n时(模型(7)~(8)),RGRG法估计的相对偏差、均方误差根、估计均方误差根和权效应没有明显变化,估计效果相当;当样本量减小到0.3n时,相对偏差变化不大,但均方误差根显著增加,这是由于进行模型拟合的样本量相应减少,从而造成了模型拟合的效果降低。综上所述,随着样本量的减少,RGRG法的估计效果略微有所下降,但总体而言,无论样本量大小如何变化,RGRG法与事后分层法相比均具有明显优势。 分别将函数h1(η)下的模型(1)、(3)、(5)、(7)和模型(9),与函数h2(η)下的模型(2)、(4)、(6)、(8)和模型(10)进行比较,相对优劣没有统一结论,即无论响应模型的形式如何,均能得到目标变量的优良估计,不同响应模型对RGRG法估计效果的影响可以忽略。 3.结论 在不可忽略的无回答机制下,与传统事后分层法相比,RGRG法具有更小的偏差、标准误和均方误差根,估计效果更好。RGRG法允许选择目标变量作为模型变量,可以更好地体现无回答机制的不可忽略性。该方法在不同响应模型下的估计效果稳定,与传统方法相比仍具有明显优势。样本中无回答单元数量对RGRG法的效果有轻微影响,无回答单元数量越多,进行模型拟合的样本量越少,估计效果有所下降。 实证中采用的超总体模型并未很好拟合总体,一方面未考虑个人年收入的其他影响因素,另一方面可能存在其他的函数形式优于线性模型。即便没有采用最优超总体模型,RGRG法仍能得到人均年收入的优良估计。 通过RGRG法进行总体均值估计,估计量具有渐进无偏性和渐近一致性。该方法对不可忽略机制下的无回答情况实现了双重保护,且允许超总体模型和响应模型仅在一定程度上反映总体情况。 当样本存在无回答时,直接利用回答样本进行推断势必是有偏且效率低的,尤其在遇到非随机缺失情况时,样本是否作答与目标变量有关,潜在的无回答偏差不容忽视。目前常用方法大多基于随机缺失的假设,不适用于不可忽略机制下的无回答。少数非随机缺失下的方法对模型假设和模型识别具有较强的要求,造成其在实际应用时的效果并不理想。 本文采用2015年CGSS调查数据进行了实证研究。结果表明,在不可忽略的无回答机制下,与传统事后分层校准法相比,使用RGRG法可以得到变异性更小的最终权数,有效降低了估计偏差和均方误差根,得到的加权估计量是渐进无偏和渐近一致的。即使响应模型和超总体模型都没有很好拟合总体的真实情况,RGRG法得到的估计量仍具有优越性。 本文通过RGRG法有效解决了不可忽略无回答机制下的权数调整和目标变量的估计问题。进一步研究考虑在通过回答样本推断总体时,先将回答样本还原到样本全体、再还原到总体,两种还原方法的实际效果如何需专门讨论。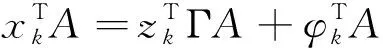
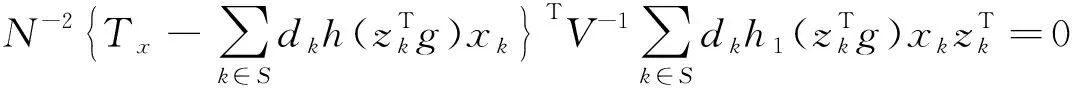


(三)方法评价
四、实证研究
(一)数据来源与整理


(二)无回答的构造与模型设定


(三)结果与分析

五、总结与讨论

猜你喜欢
心理学报(2022年10期)2022-10-12
福建农林大学学报(自然科学版)(2022年5期)2022-10-08
中国循证心血管医学杂志(2022年1期)2022-03-15
内蒙古统计(2021年4期)2021-12-06
中学生数理化·中考版(2021年8期)2021-07-31
小学生学习指导(高年级)(2021年4期)2021-04-29
中学生数理化·高一版(2021年2期)2021-03-19
今日农业(2020年23期)2020-12-15
中国外汇(2019年6期)2019-07-13
中学生数理化·高一版(2017年2期)2017-04-25
