
移动边缘计算环境下面向安全和能耗感知的服务工作流调度方法
2020-08-21 01:09李万清李忠金袁友伟
计算机集成制造系统 2020年7期
李万清,刘 辉,李忠金,袁友伟
(杭州电子科技大学 计算机学院,浙江 杭州 310018)
0 引言
随着通信、网络和智能产品的发展,移动便携式的用户设备(User Equipment,UE)越来越受欢迎。新型移动应用如人脸识别、自然语言处理、增强现实等不断涌出,引起了人们的广泛关注。这些移动应用的执行需要较高的计算资源,并消耗较大的电力能源。然而,移动设备由于物理尺寸的限制,通常只具有有限的计算能力和电量。因此,如何在资源受限的移动设备上高效地运行新型移动应用是当前移动网络环境下的一个挑战[1]。
移动边缘计算(Mobile Edge Computing, MEC)的出现为该问题的解决提供了新的平台和机遇。移动边缘计算通过与内容提供商和应用开发商深度合作,在靠近移动用户侧就近提供内容存储计算及分发服务,使应用、服务和内容部署在高度分布的环境中,以更好地满足低延时的需要[2-4]。因此,在MEC环境中,执行计算和存储的服务器均部署在网络边缘,UE可以通过将移动应用的一部分任务卸载到边缘服务器上执行的方式,来提高移动应用的服务质量并减少UE的能源消耗。然而,不是任何一个任务卸载方案都会提高服务质量,不合理的任务卸载会造成大量的数据传输和更长的任务执行时间,这不仅导致应用的执行延时,还会增加更多的电池消耗[5-6]。
一个移动应用一般包括多个任务,任务之间存在先序关系和数据依赖关系。与并行任务相比,MEC环境下的工作流应用调度问题更具有复杂性和挑战性,如任务的执行顺序以及执行位置都会对移动应用的完成时间和能耗产生影响。因此,如何将移动工作流应用中的多个任务合理地分配到移动设备和边缘服务器上执行,在满足工作流应用的约束条件限制下减少移动设备的能耗是移动边缘计算环境下的一个重要研究问题[7-8]。
MEC能够有效减少UE的能耗和应用的延时,数据安全性也是其重点关注的问题之一。在MEC环境中,移动应用的数据往往携带隐私信息,由于用户设备和边缘服务器频繁进行数据交互,一些数据在交互过程中有可能丢失或者被恶意篡改,会给用户造成重大的损失。因此,在MEC环境中运行移动应用时,需要部署一系列的安全服务以保证数据的安全性[9]。
基于以上分析,本文主要研究移动边缘环境下的工作流调度问题,提出了面向安全和能耗感知(Security and Energy Aware, SEA)的调度算法,该算法能够实现在满足工作流截止时间和风险率约束的条件下UE能耗最小化。SEA算法在粒子群优化(Particle Swarm Optimization, PSO)的基础上融合了工作流调度问题,在编码过程中考虑了任务的调度位置、机密性服务和完整性服务。针对异构服务器对安全服务计算时间影响,构建了新的安全开销模型,包括数据量与安全开销的关系、多核CPU与安全开销的关系和计算频率与安全开销的关系,使得该模型可以根据MEC的参数,对任务的安全开销进行定量描述。
本文的主要贡献如下:①从移动用户的安全性出发,提出一种面向安全和能耗感知的工作流调度方法;②对数据量、CPU核数和计算频率与机密性服务和完整性服务之间的关系进行建模,提出了安全开销的定量描述方法;③提出一种基于PSO的工作流调度编码策略,解决了多维多约束优化问题。
1 相关工作
近年来,移动网络及应用得到了飞速发展,许多学者对应用的任务调度进行了大量研究。Zhu等[10]在遗传算法的基础上提出了多目标优化(Evolutionary Multi-objective Optimization,EMO)算法,对工作流的执行时间和成本进行优化,解决了基础架构即服务(Infrastructure as a Service,IaaS)平台上的工作流调度问题;Jia等[11]研究了移动边缘计算环境中多用户通信和计算资源分配问题,提出3种不同的卸载策略,即局部压缩卸载、移动云压缩卸载和部分压缩卸载,显著减少了应用的延迟;曹斌等[12]提出基于粒子群算法的最优化调度搜索方法,利用关键路径进行粒子初始化和搜索阶段的筛选处理,解决了在时间约束下最小化费用问题;周业茂等[13]考虑了用户的不断移动,提出了基于延时传输机制的多目标工作流调度算法,解决了网络变化情况下工作流调度问题。
Xie等[14]提出针对具有期限和安全约束的并行应用程序的任务分配算法,以及针对并行任务的安全感知和异构感知资源分配的算法,解决了集群中具有安全性约束的实时并行作业资源分配问题;Zeng等[15]指出云环境的工作流调度策略不仅要考虑CPU执行时间,还需考虑内存、存储容量等其他资源,提出一种安全和费用感知工作流调度策略(Security-Aware and Budget-Aware,SABA),该策略在市场可用的云服务提供商之间选择经济任务分配方案,为客户提供更短的完工时间以及安全服务;Li等[16]考虑到在科学工作流中任务通常是异构的,提出一种安全和成本感知调度(Security and Cost Aware Scheduling,SCAS)算法,使任务在执行过程中,在满足截止时间和风险约束的同时,最小化工作流执行成本;Chen等[8]提出工作流调度策略不仅需要满足中间数据的安全性需求,还要考虑加密中间数据对后续工作流任务开始的性能影响,提出一种具有选择性任务重复调度算法,有选择地重复执行前驱任务,有效地利用任务松弛时间优化执行时间、货币成本和资源效率。
Liu等[17]通过研究移动边缘环境下如何最小化执行延迟,提出了基于马尔可夫的一维搜索算法,该算法根据应用程序缓冲区排队状态、UE和MEC服务器上可用的计算资源以及UE和MEC服务器之前网络特性,找出最优的卸载决策策略;Mao等[18]通过研究带有能源收集装置的绿色MEC系统,提出了基于Lyapunov的动态计算卸载算法,该算法决定了卸载决策、移动设备执行的CPU周期频率和计算卸载的传输功率,达到执行成本(执行时延和任务失败)最优。
当前在移动边缘环境下进行工作流安全调度的研究很少,本文在上述研究的基础上提出的SEA算法,实现了在满足安全需求和工作流的截止时间的情况下,最小化移动设备的能耗。
2 模型及问题描述
下面介绍MEC环境下任务调度框架、服务工作流模型、安全服务模型、任务执行分析和工作流风险分析,提出具有安全需求的工作流调度问题。
2.1 任务调度框架
如图1所示,MEC系统由用户设备、无线网络和若干个部署了边缘服务器的基站组成[19]。假设一个用户设备执行某个应用,该应用被建模成一个一般工作流。工作流中的任务有可能被卸载到演进型基站(evolved Node B,eNB)上或在UE上执行。通常eNB管理着不同类型的服务器,每台服务器拥有不同的计算资源,如CPU内核数量、CPU频率大小和内存大小,因此每台服务器拥有不同的计算能力。S={s0,s1,s2,…,sm}表示服务器的集合,其中s0为移动设备本身,m表示边缘服务器的总数。此外,假设不同eNB信号不能相互干扰,eNB之间拥有相同的通信带宽。

2.2 服务工作流模型
本文在经典的有向无环图(Directed Acyclic Graph, DAG)基础上进行扩展,重新定义了具有安全性的工作流W={T,E,θ,Td},如图1所示。其中:T={t1,t2,…,tn}表示n个任务的集合,E为任务之间的有向弧或边的集合,表示任务之间的依赖关系,例如边e(i,j)表示任务ti必须在任务tj开始前完成执行的约束。这种情况下,任务ti被认为是任务tj的前驱任务,任务tj被认为是任务ti的后继任务,式(1)表示任务ti的所有前驱任务:
pred(ti)={tj|(tj,ti)∈D}。
(1)
在工作流中,一个任务通常可以有一个或者多个输入,一旦输入完成,将触发任务执行。任务ti的输入总量为Ii,Ii等于任务ti的前驱任务传输给任务ti数据总量。假设任务的输出已知,当任务ti完成时,输出Oi。在工作流中没有前驱任务节点的任务称为tentry,表示工作流的开始任务。此外,没有后继任务节点的任务称为texit,表示工作流的结束任务。通常一个工作流有且仅有一个tentry和texit。如图1所示,工作流中t1和t8分别表示工作流的tentry和texit。工作流中θ表示安全约束,它的值是由用户根据数据的敏感程度指定的,0≤θ≤1.0,安全约束最低为0,最高为1.0。此外,每个工作流都有一个截止时间Td,它被定义为工作流执行的时间约束。
2.3 安全服务模型
根据任务调度模型考虑单个UE将任务卸载到多个eNB的情况。这些eNB通常是异构的,它们支持不同的覆盖范围,具备不同的计算能力。一般而言,eNB中的服务器也是异构,即每个服务器拥有不同的CPU、计算性能和存储资源。
目前,在移动边缘计算环境下用户隐私数据面临安全威胁[20],但是许多现有移动边缘计算环境并没有采用任何安全机制来对付安全威胁,因此有必要部署安全服务来保护用户的数据安全[21]。欺骗和篡改是移动边缘环境中两种常见的攻击,如恶意用户利用非法程序获得MEC服务器部分控制权并篡改用户的数据[22]。因此,考虑实现两种安全服务(机密性服务和完整性服务)[23]来综合保障数据的安全性。通过对应用程序(可执行文件)和数据进行加密来支持机密性,从而使信息和资源无法提供或者泄露给未经授权的人员或者应用;数据的完整性服务确保数据不被授权篡改或在篡改后能够被迅速发现。使用安全服务保护用户隐私数据是以性能为代价的,即安全服务会带来一定的时间开销,不同的安全服务算法(方法)会产生不同的时间开销[14,23]。
文献[9,14,23]都构建了安全开销模型,可以合理度量安全服务引起的安全开销,但是这些文献只考虑在固定的处理器、固定计算频率下数据量和安全服务之间的关系。在异构MEC环境下,eNB是异构的,它们的服务器也是异构的,这些服务器的处理器拥有不同的CPU核数和不同计算频率。为了精准衡量安全服务的时间开销,还需要研究多核CPU、不同计算频率与安全开销的关系。例如Barnes等[24]考虑CPU多核体系研究了加密算法安全开销,证明多核吞吐量远远大于单核串行执行。机密性服务的算法通常包括IDEA(international data encryption algorithm)、DES(data encryption standard)、AES(advanced encryption standard)、Blowfish和RC4(rivest cipher 4),如表1所示;完整性服务的算法包括TIGER、RipeMD160(integrity primitives evaluation message digest 160)、SHA-1(secure hash algorithm 1)、RipeMD128(integrity primitives evaluation message digest 128)和MD5(message digest 5),如表2所示。数据机密性和完整性算法分别记为CS={cs(1,c,f),cs(2,c,f),…,cs(N(CS),c,f)},IS={is(1,c,f),is(2,c,f),…,ci(N(IS),c,f)},N(j),j∈{CI,IS}表示第j个安全服务可选算法数量。其中:N(CS)表示机密性加密算法总数,c表示运行安全服务使用的CPU核数,f表示CPU频率(单位:GHz)。例如,ci(1,4,2.2)表示在4核、频率为2.2 GHz的MEC服务器运行机密性服务第1个算法。运行算法的服务器为戴尔R530 2.2 GHz,CPU核数为8核。下面分别研究数据量、多核CPU、不同计算频率和安全开销之间的关系,建立相应的数学模型。

表1 单核机密性服务加密算法

表2 单核完整性服务哈希算法
2.3.1 安全等级建模
在对算法的安全等级建模时,采用单核对固定大小数据运行安全服务算法,其中服务器的计算频率为2.2 GHz,加密数据的大小为100 MB。根据加密算法的执行速度(如表1中执行速度)为每个算法分配一个安全等级,安全等级范围为0.32~1.0。例如,将1.0分配给最强但计算速度最慢的加密算法IDEA(如表1),其余加密算法的安全等级的计算方式同文献[14,23],具体表示为:
(2)

同理,根据哈希算法的执行速度(如表2中执行速度),为每个算法分配安全等级,安全等级范围为0.44~1.0。将1.0分配给最强但是执行速度最慢的哈希算法TIGER(如表2),其余哈希算法的安全等级可以由式(3)计算得到:
(3)
2.3.2 数据量与安全开销的关系
在考虑数据量与安全开销的关系时,采用单核、固定频率对不同大小的数据运行安全服务算法,其中服务器的频率为2.2 GHz,实验效果如图2所示。在对不同大小的数据运行加密算法时,其安全开销和数据量成正比,具体关系如式(4)所示:
(4)
式中d为需要执行加密数据大小,当d=100时,co(cs(i,c,f),100)表示对100 MB数据执行加密的安全开销。如图2a所示为对不同大小数据执行机密性服务,数据量和安全开销的关系。
同理,在对不同大小的数据运行哈希算法时,运行哈希算法的安全开销和数据量成正比,具体关系如式(5)所示:
(5)
当d=100时,co(is(i,c,f),100)表示对100 MB数据执行完整性服务的安全开销。如图2b所示为对不同大小数据执行完整性服务时,数据量和安全开销的关系。

2.3.3 多核CPU与安全开销的关系
考虑到CPU的核数与安全开销的关系,本文对固定大小安全数据实现安全服务,在固定计算频率,利用不同核数运行安全服务,得到不同核数的安全开销。选择100 MB数据作为实验数据,在计算频率为2.2 GHz的服务器上运行安全服务算法。首先,将原始数据D切分成N份数据集,其中N对应算法使用的核数;然后利用多进程对N份数据集实现安全服务,实验效果如图3所示,随着CPU核数的增加,安全开销呈下降趋势。这是由于待加密数据被分成了若干份,实际上每个核只对每个小块数据进行加密。
在保护相同大小数据时,多核实现机密性服务的安全开销和核数成反比,具体关系如式(6)所示:
(6)
式中co(is(i,1,f))表示单核运行加密算法的安全开销。如图3a所示为对d=100 MB数据实现机密性服务时,多核服务器运行加密算法的安全开销和采用的核数关系。
同理,可以得出多核实现完整性服务的安全开销和核数成反比,如式(7)所示:
(7)
如图3b所示为对100 MB数据实现完整性服务时,多核服务器运行哈希算法的安全开销和核数关系。

2.3.4 计算频率与安全开销的关系
考虑到CPU的计算频率与安全开销的关系,采用具有不同计算频率单核对固定大小安全数据实现安全服务。实验效果如图4所示,随着计算频率升高,算法的安全开销呈下降趋势。在保护相同大小数据时,服务器实现机密性服务的安全开销和计算频率成反比,具体关系如式(8)所示:
(8)
式中F为CPU的最大计算频率。图4a所示为在对100 MB数据实现机密性服务时,服务器运行加密算法的安全开销和计算频率关系。同理,得出了完整性服务的安全开销和计算频率关系,如式(9)所示:
(9)
如图4b所示为对100 MB数据实现完整性服务时,服务器运行完整性的开销和安全数据的大小关系。

基于以上分析,可以得到实现安全服务的安全开销和数据大小、CPU核数、计算频率的关系。由于算法的安全等级是算法的固有属性,跟CPU的核数和计算频率无关,本文在单核上以最大频率运行算法的执行速度作为衡量算法的安全等级。对于给定一个服务器,已知它的CPU核数和计算频率,通过式(10)和式(11)分别计算出机密性服务和完整性服务的开销:
(10)
(11)
其中:D为需要保护的数据量;cs(1,1,2.2)表示单核以2.2 GHz运行第i个加密算法的安全开销;is(1,1,2.2)表示单核以2.2 GHz运行第i个哈希算法的安全开销。
2.4 任务执行分析
假设执行任务ti的服务器记为s(ti),则任务t1分配给服务器s1执行,记为s(t1)=s1。图1中工作流的部分任务执行过程如图5所示,任务t1在UE上执行,t1执行完成后对输出数据实现机密性服务(图5中E)和完整性服务(图5中H)。任务t1将输出数据传输给任务t2,任务t2接收数据后,对数据进行完整性验证(图5中IV)和解密(图5中DE)。由于任务t2和任务t5在同一个服务器执行,它们之间不需要执行安全服务,即任务t5可直接使用任务t2的输出数据。任务接收输入数据的时间可以表示为
(12)
式中B为服务器之间的一个带宽。如果两个任务在同一个服务器上执行,它们的传输时间为0,因此图5中t2和t5的传输时间为0。

当任务接收到输入数据,首先需要对数据进行完整性验证,时间记为IV(ti),然后通过解密算法对数据解密,解密时间记为DE(ti)。当输入完成后,任务ti开始在服务器s(ti)上执行,任务执行时间
(13)
式中:w(ti)为任务ti工作量;ps(ti)为服务器s(ti)计算能力。此外,由于完整性服务可以确保无人修改或者篡改数据未被发现,因此在执行任务时被用于处理数据更改的威胁。最后,为了避免对任务ti的输出数据进行非法授权的拦截,对输出数据进行加密以应对窥探攻击,确保未经授权的人员无法获取数据。因此,任务ti在s(ti)处理时间
PT(ti,s(ti))=TT(ti)+IV(ti)+DE(ti)+
ET(ti,s(ti))+H(ti)+E(ti)。
(14)
2.5 工作流风险分析
在MEC环境中,工作流应用程序执行过程并非无风险,需要对安全服务进行定量评测得出整个工作流的风险率。在该风险分析模型中,假设风险概率是安全等级的函数,任何固定时间间隔的风险率分布满足Poisson概率分布。因此,任意第k个安全服务的风险概率可以用指数分布表示[25-26]为:
(15)

(16)
(17)
2.6 问题描述
本文主要在移动边缘环境下实现一种调度算法,该算法在用户设备能耗最小的同时满足工作流截止期限和风险概率约束。根据资源集合、所有任务的安全级别、任务资源映射、用户设备的能耗、总执行时间、工作流风险和卸载决策定义调度算法为schedule=(M,SL,E,TET,P(T),x)。其中:M表示一个映射,由m(ti,s(ti))=(ti,s(ti),ST(ti),FT(ti))组成,映射元组的解释如下:任务ti在s(ti)上执行,在ST(ti)时刻开始执行,并在FT(ti)时刻完成;SL={sli|i=0,1,…,n-1}表示每个任务的安全等级;工作流的风险率P(T)通过式(17)计算得到;x={x0,x1,…,xn}是整个工作流的卸载决策集合,xi=1表示任务ti在用户设备上执行,xi=0表示任务ti不在用户设备上执行。移动设备的能耗和工作流的总执行时间计算如下:
(18)
TET=max(ET(ti)|ti∈T)。
(19)
此外,(FT(ti)-ST(ti))×E0是任务ti在移动设备执行的能耗,E0为移动设备单位时间的能耗。根据之前的定义,问题可描述为:找出一个调度算法使得E最小,并且TET不超过截止期限,P(W)满足工作流的风险率约束,具体如下:
minE;
(20)
s.t.
TET≤Td,
(21)
P(W)≤θ。
(22)
3 算法实现
工作流调度问题是一个NP难问题,因此本文提出一种基于PSO能耗和SEA算法得到问题的最优解解集。在粒子群算法中,许多粒子被放置在某个问题的搜索空间中,以一定速度在搜索空间探索[27]。每个粒子由3个D维矢量组成,这3个矢量分别为当前位置xi、历史最佳位置pi和速度vi。当前位置xi表示优化问题的候选解,如果当前位置好于历史最佳位置,将现有位置保存在pi向量中。在群体中所有粒子经历过的最好位置的索引号用向量pg表示,它的适应度记为gbest。此外,个体目前最佳适应度的值保存到参数pbesti中。在粒子群优化过程中,算法将继续迭代,直到满足停止条件:通常是达到最大迭代次数或者一个预定义的适应度值。在每次迭代中,粒子的速度和位置基于式(23)和式(24)更新:
vi←w×vi+φ1×rand1(pi-xi)+
φ2×rand2(pg-xi),
(23)
xi←xi+vi。
(24)
其中:加速常数φ1和φ2表示每个粒子推向pi和pg位置的统计加速项的权重大小,这两个加速度常数被认为是一个单一的加速度常数φ=φ1+φ2>4,一般情况下φ1和φ2不一定非要相等[28]。rand1和rand2是在[0,1]范围内均匀分布的随机数。惯性权重w使粒子保持运动的惯性,使其有扩展搜索空间的趋势,有能力探索新的区域。此外种群的大小通常在20~50之间,粒子的维度和它们允许移动的范围,这些值完全取决于问题的性质以及它如何模拟以适应PSO,粒子的维度和范围将在3.1节中描述。SEA算法的伪代码如算法1所示,下面将详细介绍它们的相关实现。
算法1基于PSO的SEA算法。
BEGIN
01.N←粒子的大小,D←粒子的维度;
02.gbest←0,pg←0;
03.for i= 0 to N//遍历所有的粒子
04.初始化xi和vi;
05. Letpi=xi,pbesti=fitness(xi)
06.end for
07.while iterate//最大的迭代次数
08. for i=1 to N
09.根据工作流的调度算法和条件限制计算每个粒子的适应度;
10.更新pbesti,pi;
11.end for
12.选择到目前为止所有粒子的最佳适应度值的粒子,将其索引赋给变量g;
13. for i=1 to N
14.根据式(23)式(24)更新vi,xi;
15.保持粒子在搜索空间内,以防它超出其边界
16.end for
17.Iterate++//迭代次数加1
18.end while
END
3.1 编码
要定义问题的编码,需要了解粒子的表示方式和维度。SEA算法的目标是在满足期限和风险率约束的同时最小化移动设备的能耗,为每个任务选择适当的服务器和安全等级。为了求解式(20),设计了以下编码策略:
(25)
s.t.
s(ti)∈S,i=0,1,…,m-1;
(26)
(27)
其中Γ(·)的能耗函数与执行任务的服务器、任务安全等级有关。此外,SLl,l∈{is,cs}是一组安全服务的等级,其中包括0,如机密性服务包括6个等级(如表1),SLl={1.0,0.85,0.53,0.56,0.32,0}。
粒子的个数等于函数Γ(·)中的参数数量,即D=3×n。如图1所示,工作流有8个任务,每3个粒子属于一个任务,因此粒子个数是24。粒子的值可以在相应的搜索空间中变化,每个任务的第一个粒子的值表示该任务运行的服务器;第二个粒子的值是任务的机密性的安全等级;第三个粒子的值是任务的完整性的安全等级,如任务t1编码为(0,0.36,0.3),表示任务t1在服务器s0上执行,任务的机密性和完整性的安全等级分别为0.36和0.3。
3.2 工作流调度
工作流调度的伪代码如算法2所示。初始化服务器S、安全等级SL和映射M为空,能耗E、执行时间TET和风险率P(T)为0,然后根据粒子的位置构建调度。至此,开始遍历位置中每个坐标并更新S,SL和M,首先确定任务、服务器和安全等级对应的粒子位置和对应值,这是通过使用前面描述的编码策略得到的,即粒子的索引3i,3i+1,3i+2对应任务ti,它们的值pos[3i],pos[3i+1],pos[3i+2]分别对应执行任务的服务器、机密性安全等级和完整性安全等级;然后计算任务的开始时间ST(ti)的值。任务开始时间ST(ti)主要有两种场景:①任务没有前驱任务节点,则立即执行;②任务有一个或者多个前驱任务节点,等待所有前驱任务节点完成才开始执行。
如果服务器被使用,则FT(ti)的值根据任务开始时间和整个任务处理时间得出。任务的处理时间PT(ti,s(ti))由数据接收时间、输入数据解密时间、执行时间和安全开销组成。FT(ti)是ST(ti)和PT(ti)总和。
算法2工作流调度算法。
Begin
01.R=M=SL=∅,E=TET=P(W)=0;
02.if T≠∅
03.for ti∈T do
04.if pred(ti)=∅ then
05.ST((ti)=0;
06.else
07.ST(ti)=max{FT((tj)|(tj∈pred((ti)}
08.end if
09.if s(ti)=s(ti-1)// 任务ti和任务ti-1在同一台服务器上执行
10.Ii-1,i=0// 任务ti-1传输到任务ti-1数据量为0
11.根据式(14)计算执行时间PT(ti,s(ti))
12.FT(ti)=ST(ti)+PT(ti,s(ti))
13.if s(ti)=s0
14.xi=1
15.end if
16.根据式(14)计算执行时间PT(ti,s(ti))
17.FT(ti)=ST(ti)+PT(ti,s(ti))
18.end if
19.集合M添加m(ti,s(ti),ST(ti),FT(ti)),SL添加sli
20.end for
21.根据式(17)计算P(W)
22.根据式(18)计算E
23.根据式(19)计算TET
24.记录schedule=(M,SL,E,TET,P(W),x)
END
3.3 约束处理
针对约束条件,采用文献[29]中的3种可行解方法优先性准则:①根据适应度函数,在两个可行解之间寻找最优解;②可行解比不可行解更好;③在两个不可行解之间,优先考虑违约之和较小的解。本文将约束条件式(21)和(22)转化为约束数的总和,具体计算如下:
f(xi)=max(0,TET-TD)+
max(0,P(T)-θ)。
(28)
3.4 粒子越界和算法复杂度分析
速度和位置可能导致粒子超出可行区域的边界,因此必须修改PSO算法以使粒子在约束内搜索最优解。这样做的方式可能会对算法的性能产生很大的影响,因为它会影响粒子在搜索空间中移动的方式,当最优决策变量值位于或接近边界时,这一点尤为重要。因此,当一个决策变量超出其边界时需要做两件事:①取其相应边界的值(要么是下边界,要么是上边界);②其速度乘以-1,以便在相反的方向上搜索[30]。
SEA算法在每次PSO迭代中通过更新粒子的位置和速度获得新的适应度。种群的数量N和粒子的大小D决定了更新粒子位置和速度所需的计算次数,根据粒子定义可知粒子的大小D=3×n。粒子通过遍历所有的任务计算适应度,则适应度函数的时间复杂度为Ο(n)。基于以上分析,SEA的每次迭代的总体复杂度为Ο(3·n2·N)。
4 实验
首先通过仿真实验对SEA算法的性能进行评估,主要从能耗、安全服务和任务数量3个方面考虑。在仿真实验中,采用随机生成的方式产生工作流,其中任务的工作量大小在[1,10]随机产生;每个任务的输出数据大小服从[1,10]均匀分布(单位:MB);随机选择3个服务器。用户设备的计算能力、计算功率、数据的发送功率、数据的接收功率和带宽以及MEC服务器配置如表3所示。利用面部表情识别流程作为实例验证了算法的可用性,实验使用的移动设备为荣耀8(4核2.3 GHz),服务器选择三台联想服务器RD450(8核2.1 GHz)。

表3 用户设备和MEC服务器性能参数
4.1 能耗对比
在本节中仿真下面的算法:
(1)LOCAL:该算法中工作流中任务都在用户设备执行。
(2)Max_Level:该算法将每个任务的所有安全等级设置为1.0,因此工作流的风险率始终为0。
(3)Min_Level:该算法中所有任务都不实现安全服务,即工作流的风险率始终为1.0。
(4)SEA:本文所提算法是在满足截止时间和风险概率约束的情况下最小化移动设备的能耗。
在这组实验中,通过改变风险率大小,研究风险系数对4种算法性能的影响。风险率从0.1变化到1.0,步长为0.1。任务数量分别取10、50和100;种群数量和迭代次数取值50和1 000。4种算法的能耗的仿真结果如图6所示。总的来说,LOCAL算法的能耗最高,Min_Level算法的性能最好,SEA算法和Max_Level算法能耗适中,前者优于后者。Max_Level和Min_Level算法的曲线表明能耗与风险率无关,因为两种算法都使用了固定的安全服务。对于SEA和LOCAL算法来说,开始时能耗下降很快,当风险率等于或大于0.5时,能耗下降缓慢。这是因为风险概率函数是指数函数,当工作流的风险率较低时,每个任务都要求较低的风险率,这就需要较高的安全服务,从而导致能耗较高。由于LOCAL算法在用户设备执行,能耗比其他算法要高,SEA算法的能耗在Max_Level算法和Min_Level算法之间变化。因此,用户可以实现工作流执行的能耗安全权衡,以保证工作流的执行,保护自己的隐私。
4.2 安全服务对比
本节考虑SEA算法的两个安全服务对安全工作流的性能影响。缩写integ_only和confi_only分别表示完整性服务和机密性服务,integ_only表示应用只实现了任务的完整性服务;confi_only表示应用只实现了任务的安全性服务。如图7所示为风险率对这两种安全服务的能耗影响。对于完整性服务和机密性服务,它们的安全开销取决于要保护的数据的大小,因此其能耗随着风险率的升高而降低。此外,由于机密性服务比完整性服务执行慢,在相同的风险率下,confi_only的能耗高于integ_only。

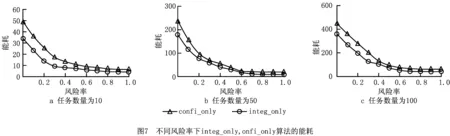
4.3 安全系数影响
如2.5节所述,风险率与风险系数高度相关。例如,如果第l个安全6服务的风险系数λl=0,则其风险概率为0,因为它不会遭受相应的攻击,所以任务不需要实现第l个安全服务。本节将重点讨论SEA算法的风险系数的性能影响,实验结果如图8所示,工作流的风险系数从0.3~3.0。从图8可以看出,integ_only较优于confi_only,原因已经在4.2节中解释了,这里不再赘述;从图8中还可以看出,当风险系数高于2.0时,两种算法的能耗曲线变得平缓,这是因为风险数据在式(15)小范围内变化时,风险率会发生显著变化,能耗亦会以相同的速度变化。总之,不同的风险系数对能耗产生不同的影响。

4.4 服务器数量的影响
本节考虑MEC服务器数量变化对SEA算法的影响,工作流的数量分别取10、50和100,3个工作流记为SEA_10、SEA_50和SEA_100,风险率和风险系数分别为0.3和1.5,其中MEC服务器的数量变化范围为[0,9]。实验结果如图9所示,服务器数量越多,移动设备的能耗越低,当服务器的数量达到5时,能耗曲线变得平缓,这是因为服务器受工作流的结构限制,当服务器的数量大于工作流的并发量时导致部分服务器空闲。因此在进行调度算法时,需要选择适量的服务器。
4.5 实例验证
本节采用面部表情识别流程作为实例验证所提算法的可用性。算法的能耗是指手机运行面部表情识别流程消耗的电量,单位:mAh。面部表情服务流程由8个任务组成:输入视频、人脸检测、脸部特征检测、脸部标记、脸部特征提取、面部动作单元识别、表情识别、输出类别[31]。这8个任务可以组织成一个带有数据依赖的工作流,工作流中每个任务可以在本地执行或者卸载到服务器上执行。其中任务1和任务8分别是工作流开始任务和结束任务,这两个任务必须在本地执行。实现了4.1节的能耗对比、4.2节的安全服务对比和4.3节的风险系数的实验,实验结果证明了SEA算法的可用性,实验效果如图10所示。


5 结束语
本文提出一种在MEC环境中面向安全和能耗感知的工作流调度算法。该算法在PSO算法的基础上融合了工作调度问题,目标是在满足工作流的截止时间和风险率两个约束条件下,最小化移动设备的能耗。此外,还提出一种新的工作流编码策略,解决了多维约束优化问题。通过仿真实验和实例对算法进行评估,验证了算法的有效性和实用性。
本文还有需要改进的地方,如在调度过程中均假设任务的执行都是成功情况,没有考虑任务失败的情况。因此,调度过程中的任务容错问题将是未来的研究工作之一。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
昆明医科大学学报(2022年1期)2022-02-28
当代水产(2021年10期)2022-01-12
建材发展导向(2021年23期)2021-03-08
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
铁道通信信号(2019年9期)2019-11-25
网络安全和信息化(2019年8期)2019-08-28
华人时刊(2018年15期)2018-11-10
浙江工业大学学报(2017年5期)2018-01-22
