
改进卷积神经网络的手写试卷分数识别方法
2020-08-20 04:04仝梦园金守峰尹加杰
西安工程大学学报 2020年4期
仝梦园,金守峰,陈 阳,李 毅,尹加杰
(西安工程大学 机电工程学院/西安市现代智能纺织装备重点实验室,陕西 西安 710048)
0 引 言
试卷作为评价学生学习效果的主要形式,评阅过程主要以人工进行阅卷及分数统计,但人工阅卷及分数统计过程中存在劳动强度大、人为主观统计误差等问题。机器评阅作为辅助手段,主要在客观题中大量使用,但是设备价格贵,需要特定的答题卡。随着深度学习在人工智能技术的快速发展,在语音、手写数字识别等领域受到广泛关注[1-2]。
近年来,手写字符识别已应用于快递表单[3]、条码识别[4]、数字表盘抄表[5]、档案信息[6]等各方面,应用深度学习技术的手写字符识别可分为传统模型、模型改进与新模型。在传统模型阶段,陈龙等分别通过对各传统模型进行手写体数字识别,验证了BP神经网络效果较好[7]。在模型改进阶段,通过对卷积神经网络[8]、VGG-16网络改进[9]与LeNet-DL网络[10]等的改进使手写字符识别得到更好地识别。为了进一步提高识别的准确率与效率,魏明俊等提出了一种带PCA卷积的稀疏表示分类算法,解决卷积核训练困难的问题[11];杨怡等提出了一种结合评判函数Silhouette改进的AP聚类算法,实现手写字符的识别[12];Kang等提出在不需要任何预处理任务,通过编码器、CNN和双向GRU的手写体识别模型,能够逐字符拼写相应的单词,但是出现大写字母时,识别过程会出错[13];Wang等提出了一种新的具有密集连接结构的自由基分析网络(DenseRAN),使DenseRAN具有识别未见汉字类的能力,但是识别的种类有限[14];刘庆等基于稀疏自编码器和卷积神经网络,提出新的CNN模型,克服了带标签训练数据样本不足的问题,还可以提取有效特征以加速网络收敛[15];任晓奎等提出了一种多分类器下无分割手写数字字符串识别算法,使用动态选择策略,以避免长度分类器误分类对识别结果的影响[16];Mohamad等提出了一种基于HSA的元启发式方法,采用Freeman链码作为数据表示,求解HCR最短路径长度和最短的计算时间[17];Roy等提出了一种基于深度架构的串联方法,用于无限制的手写笔迹识别,充分利用隐藏在文档图像中的监督信息,并解决识别任务[18];杨钟亮等提出了一种基于sEMG的KF-LSTM模型,实现由sEMG信号预测并重建手写数字的轨迹,但是需要按住按钮来完成数字图像的绘制,与平时书写习惯不完全匹配,会造成人手疲劳[19]。
针对人工评阅强度大、效率低等问题,文中采用图像分割来简化手写分数识别的类别,通过构建卷积神经网络提取特征,PCA进行降维,应用贝叶斯分类器实现数字分类,提高分数识别的准确性与效率。
1 分数提取
1.1 试卷图像校正
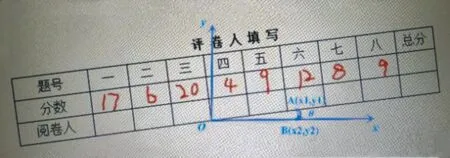
由于图像存在噪声、光照等干扰,本文采用直方图增强、中值滤波及同态滤波等预处理算法对图像进行处理,以提高图像质量。由于试卷成像过程中的随机放置会导致图片发生倾斜,对手写数字的提取造成影响,本文对预处理后的图像建立旋转模型,计算分数栏与水平方向的夹角来进行旋转校正。对原图进行最大类间方差法的图像分割获得标题栏区域后,应用Canny算子提取边缘特征建立如图1(a)所示的计算模型,点A(x1,y1)为标题栏上边缘除原点外任意一点,点B(x2,y2)为x轴上的任意一点,分别与原点构成向量OA和向量OB,根据向量数量积运算原理来计算它们之间的夹角,表达式为
(1)
式中:θ为图像旋转角。根据计算的旋转角,进行旋转校正补偿,并二值化后的图像如图1(b)所示。
(a) 原图
1.2 分数区域分割
在试卷图像采集视场高度一定的前提下,成像大小是一致的,每个图像中分数栏线框的大小都是一致的,通过计算每个分数栏区域内的像素来判别是否存在手写数值,对分隔栏进行一次分割如图2(a)所示。对于单个手写数字0~9之间的像素范围为36~65,2个手写数字的像素数范围将大于71,超过单个最大像素数的图像则判定为存在左端数字部分。根据区域分割法,将每个分数栏中的分数进行一次分割,对于分数栏中超过单个最大像素的图像进行二次分割,分割后的图像如图2(b)所示。对分割后的图像进行图像透视变换,转换为28×28的子图,作为神经网络训练的样本。

(a) 一次分割
2 分数求和理论模型
2.1 卷积神经网络框架
为提高手写试卷分数的精度,本文构建如图3所示的卷积神经网络模型,由输入层、第1卷积层(用C1表示)、第1池化层(用S1表示)、第2卷积层(用C2表示)、第2池化层(用S2表示)、输出层组成。输入层为分割后的28×28的手写分数图像;C1层由8个5×5的滤波器对输入图像进行卷积;C2由18个5×5的滤波器对S1的输出图像进行卷积;S1与S2层用2×2的窗口,以步长为2进行最大池化采样;输出层为手写分数图像的特征。卷积过程中ReLU函数作为激活函数,学习率为2.4。

图 3 CNN网络结构的设计
2.2 基于PCA的数据降维
通过卷积神经网络提取单幅图像的特征为288维,由于构建卷积神经网络导致特征维数较多,影响识别效率,因此本文采用PCA方法对数据进行降维,将卷积神经网络提取的18层4×4的特征组成18条16维的数据,将数据排成16行18列的矩阵Am×n,先对Am×n进行零均值化表达式为
(2)

之后,对协方差矩阵C进行求取,表达式为
(3)
式中:m表示样本个数。同时求出协方差矩阵的特征值λ1,λ2,…,λk。
最后,对特征向量按照对应特征值λ大小从上到下按行排列成矩阵B,Y=BA即为降维后的k维矩阵。特征贡献率的表达式为
(4)
通过分析不同特征累计贡献率下数字的识别效果,在Mnist数据库中验证最优的特征识别率,得出特征累计贡献率与识别率的关系如图4所示。

图 4 特征累计贡献率与识别率的关系
如图4所示,特征累计贡献率为95%时,由于剔除了特征中冗余信息,因此识别准确率最高。将特征提取后的原始数据与降维后数据进行对比,得到对全部训练集的训练次数与时间和识别准确率之间的关系如表1所示。
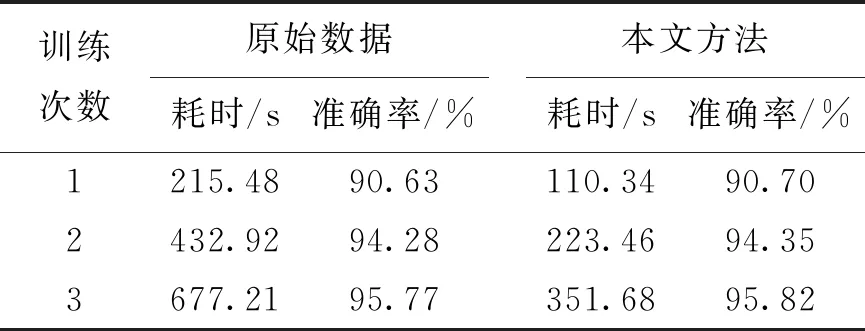
表 1 原始数据与PCA降维的对比
如表1所示,将特征从288维降到144维后,依然保持着较高的准确率,但是算法消耗的时间节省约51%。
2.3 融合贝叶斯分类器的识别分类
通过降维后需要实现手写数字的识别分类,由于特征降维后的特征数量减少,且数字识别分类为多分类问题,本文通过融合贝叶斯分类器对手写数字进行分类。
贝叶斯分类器是对训练数据集中图像的特征进行独立性假设,对输入的特征利用贝叶斯公式求出后验概率的最大输出,进而实现数字的分类。假设一个待分类样本H(h1,h2,…,hm),类别集合表示为Ω(ω1,ω2,…,ωn),对样本H判别分类,就是求取后验概率的最大值。先计算先验概率,其表达式为
(5)
式中:Ni为数字i的样本数;N为样本总数;P(ωi)为类别数字i的先验概率。
之后,计算每个类别的条件概率,其表达式为
P=(H|ωi)=P(h1,h2,…,hm|ωi)
(6)
式中:P(H|ωi)训练集中每个类别的条件概率。
最后,求取后验概率,其表达式为
P(ωi|H)=P(ωi)P(H|ωi)/P(ω0)P(H|ω0)+
P(ω1)P(H|ω1)+…+P(ωn)P(H|ωn)
(7)
式中:P(ωi|H)为后验概率。
由于本文实现的是手写数字多分类问题,为体现预测结果和实际结果的差别,选择对数损失函数,其表达式为
L(Ω,P(Ω|H))=-lgP(Ω|H)
(8)
对手写试卷分数栏进行预处理后,通过输入卷积神经网络提取特征,经过PCA降维,融合贝叶斯分类器进行分类识别,直接输出图像的类别。实现端到端的学习方法,不用对各部分问题进行方法的选择与分析。
2.4 分数求和模型
在识别出手写数字后,需要将识别结果与分数栏区域相匹配进行分数的求和,由于单个分数栏中的分数不能出现3位数的成绩,只存在单个数字和2位数字,因此在二次分割的分数栏区域进行标记的基础上,建立分数求和模型为
(9)
式中:zi为统计的分数;i为分隔栏数量;f为二次分割中十位左边的分数;g表示为进行二次分割中右边的分数。
3 实验分析
3.1 算法对比
为了验证本文算法的效率,采用Mnist数据库分别与文献[20]和文献[21]的算法进行对比分析,实验结果如表2所示。

表 2 实验对比结果
由表2可知,本文算法的识别率较高,算法耗时短,具有较好的效率。
3.2 分数识别与求和
本文以液压传动及控制技术、互换性与测量技术与机械设计基础这3门专业核心课程的试卷来验证本文算法的可行性。每门课程的开课班级为12个班共计396份试卷,3门课共计1 188份试卷。
对3门课程各396份试卷分数,通过预处理将每组手写分数栏整理成28×28的图片作为样本输入,将本文算法与文献[20]、文献[21]算法对手写试卷分数进行识别,实验统计数据如表3所示。

表 3 分数识别数据
如表3所示,本文算法对3门课程共计1 188份试卷识别的平均准确率为98.23%,平均每份试卷识别时间为7.5 s,与文献[20]、文献[21]进行对比,准确率高,耗时短。本文算法的识别平均准确率为98.23%,其1.77%的错误率主要来源于,在试卷分数栏图像采集过程中会出现手写数字不规范、数字与分数栏有交叉等情况。
4 结 论
1) 本文通过对手写试卷图像的采集、对分数栏的提取以及分割处理等将手写分数简化为单个数字识别的问题。
2) 本文算法通过卷积神经网络提取图像的特征,为实现效率采用PCA进行特征降维,融合贝叶斯分类器实现数字的分类,在Mnist数据库中实现较高的识别率。
3) 将本文算法对手写试卷各栏分数进行识别,通过各栏分数的统计,得到3门课程共计1 188份试卷识别的平均准确率为98.23%,平均每份试卷识别时间为7.5 s,证明了算法的实用性。
4) 解决人工评阅试卷耗时长的问题,为提高手写试卷的识别质量以及统计准确率,后面需要进一步提高图像采集质量与优化算法。
猜你喜欢
车主之友(2022年4期)2022-08-27
汽车实用技术(2022年4期)2022-03-07
故事作文·低年级(2021年12期)2021-12-21
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
装备环境工程(2020年3期)2020-04-03
海峡姐妹(2019年12期)2020-01-14
文苑·经典美文(2019年8期)2019-08-06
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
