
基于BERT 和双通道注意力的文本情感分类模型
2020-08-11 06:52谢润忠
数据采集与处理 2020年4期
谢润忠,李 烨
(上海理工大学光电信息与计算机工程学院,上海,200093)
引 言
句子级别的文本情感分析,即针对语句的情感倾向性分析,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。随着论坛、博客和推特等社交媒体的发展,我们拥有了海量的情绪化数据,情感分析技术扮演着越来越重要的角色。
现有的情感分析技术有基于情感词典的方法、基于机器学习的方法、基于深度学习的方法。基于情感词典的方法通过对文本进行词语和句法分析,并计算情感值作为判断文本情感倾向的依据。该方法根据情感词典可以很好地锁定文本情感信息,且实现较为简单。个体在进行语言表达时,会增添必要的情感词汇,情感褒贬词、程度副词、否定词等对情感语义增强或减弱有着重要的促进作用[1]。赵妍妍等[2]通过构建否定词、副词、情感表情等相关词典来扩充情感词典,大大增强了文本情感极性的判断能力。Keshavarz 等[3]将语料库与词典相结合,构建自适应情感词典,以改善微博中情感的极性分类。蒋翠清等[4]利用初始情感种子词构建了一个面向中文社交媒体文本的领域情感词典,有效地改进了句子级文本的情感分类效果。
基于机器学习的方法主要是将文本的情感倾向分析转换为一个分类问题,然后利用经典的支持向量机、朴素贝叶斯等机器学习算法[5],通过有监督的训练得到一个模型,进而根据该模型进行文本情感倾向分析。然而由于传统的机器学习算法多采用词袋模型来表示文本,其面临数据特征稀疏,且不能很好地抽取文本中蕴涵的情感信息等问题。
近年来兴起的深度学习方法能够较好地弥补传统机器学习方法的缺陷,由卷积神经网络和循环神经网络(Recurrent neural network,RNN)为代表的深度学习模型被广泛地应用于文本情感分析领域。王煜涵等[6]采用CNN 模型学习文本中的深层语义信息,挖掘Twitter 文本的情感倾向,比传统机器学习方法取得了显著提高。Zhu 等[7]提出了一种统一的CNN-RNN 模型,用于视觉情感识别。该体系结构利用CNN 的多个层次,在多任务学习框架内提取不同层次的特征,并提出了一种双向RNN 来集成CNN模型中不同层次的学习特征,极大地提高了情感分类性能。Zhang 等[8]提出了一种基于BiGRU 的分层多输入输出模型,该模型同时考虑了情感表达的语义信息和词汇信息,实现了对客户评论情感分类的突破性改进。Peng 等[9]将BiGRU 与注意力机制融合应用于细粒度文本情感分析,在不同的数据集上都取得了良好的性能。此后,基于CNN、BiGRU、注意力机制等的混合神经网络模型在文本情感分析任务中得到了广泛应用。
Word2vec[10]是目前NLP 领域中最常用的词向量工具。Glove 模型于2014 年由Pennington 等[11]提出,因其提高了词向量在大语料上的训练速度且稳定性高,在最近几年得以流行。预训练模型(Pretrained model)是一种基于大型基准数据集训练得到的深度学习架构,在此基础上可以进行后续任务。预训练模型对改进许多NLP 任务都有非常大的帮助[12]。随着预训练模型研究的深入,ELMo[13]、ULMFiT[14]、基于变换器的双向编码器表征技术(Bidirectional encoder representations from transformers,BERT)15]等众多NLP 预训练模型相继被提出,通过将大型文本语料库作为语言模型进行预训练,为给定句子中的每个单词创建上下文关联的嵌入(Embedding),这些嵌入将被输入到后续任务中。选择高效的词向量表示工具对深度学习的应用研究有着极其重要的影响。
对比传统情感分类方法,情感词、否定词、强度词等情感信息词起着至关重要的作用[16]。尽管情感语言词很有用,但在近几年的卷积神经网络(Convolutional neural network,CNN)和长短时记忆网络(Long short-term memory,LSTM)等深度神经网络模型中,情感语言知识的应用还很有限。受文献[15,17]启发,结合深度学习和情感词典方法的优点,本文提出一种基于BERT 和双通道注意力(Dualchannel attention,DCA)的新模型(BERT-DCA)应用于句子级文本情感分析。
1 相关技术与BERT-DCA 模型
1.1 情感信息集合的提取
修饰词词典一般包括否定词、程度副词、连词等部分。当情感词被这些修饰词围绕时,有很大概率伴随着整句的情感极性变化,如极性反转、加强或减弱等。因此,综合考虑情感词和修饰词对判断文本情感极性至关重要。参考Lei 等[18]构造情感语言库的方法,本文构建的情感语言库主要考虑情感词、否定词和程度副词。通过构建的情感语言库,提取文本句子中包含的情感信息,从而得到每一条文本句子所对应的情感信息集合。设定策略方案如下:
策略1:若当前词语为情感词,直接将当前词语加入到情感信息集合中。
策略2:若当前词语为程度副词,且下一个词语为情感词,则将二者作为一个整体加入到情感信息集合中;若该情感词已存在于情感信息集合中,则将其删除。
策略3:若当前词语为否定词,且下一个词语为情感词,则将二者作为一个整体加入到情感信息集合中;若该情感词已存在于情感信息集合中,则将其删除。或者若否定词依次紧跟副词和情感词,则将三者作为一个整体加入到情感信息集合中;类似的,若副词与情感词的整体存在于情感信息集合中,则将其删除。
1.2 BERT 预训练模型
Word2vec 等传统词向量工具只是简单地提供词嵌入作为特性,相比之下,BERT 还可以集成到下游任务中,并作为特定于任务的体系结构进行动态调整。与ELMo 使用独立训练的从左到右和从右到左LSTM 的级联来生成下游任务的特征不同,BERT 使用的是更为强大的双向 Transformer 编码器[19],如图 1 所示,并以遮蔽语言建模(Masked language model,MLM)和下一句话预测(Next sentence prediction,NSP)为无监督目标,使模型输出的每个字与词的向量表示都能尽可能全面、准确地刻画输入文本的整体信息,为后续的微调任务提供更好的模型参数初始值;且其输入表征(Input embedding)是通过对相应词的词块嵌入(Token embedding)、段嵌入(Segment embedding)和位置嵌入(Position embedding)求和来构造的,包含了更多的参数,因此具有更强的词向量表示能力。
BERT 在大量句子级和Token 级任务上获得了最佳性能,优于许多具有任务特定体系结构的系统,包括情感分析领域中的任务[20]。
1.3 双向GRU 神经网络
门控循环单元(Gated recurrent unit,GRU)由Cho 等[21]提出,是一种对LSTM 改进的深度网络模型,其模型结构如图2 所示。GRU 最大的优点在于很好地解决了循环神经网络中的长期依赖问题,且被认为更易于计算和实施。它保留了LSTM 对解决梯度消失问题的优点,但内部结构更简单,只有2 个控制门:更新门和重置门。GRU 神经网络的参数比LSTM 减少了1/3,不易产生过拟合,同时由于采取对Cell 融合和其他一些改进,在收敛时间和需要的迭代次数上更胜一筹。

图1 BERT 模型结构图Fig.1 BERT model structure
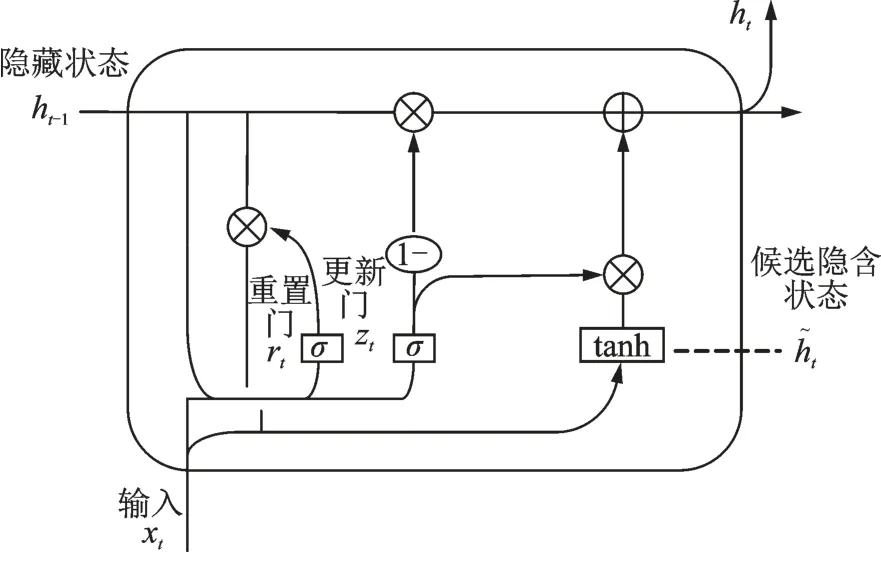
图2 GRU 神经元结构图Fig.2 Structure of a GRU neuron
GRU 神经网络的更新方式如下

式中:rt为t时刻的重置门,zt为t时刻的更新门,ht为t时刻的候选激活状态,ht为t时刻的激活状态,ht-1为t-1 时刻的隐层状态,wr、wz、w为相应的权重矩阵,σ为sigmoid 激活函数,tanh 为双曲正切激活函数。更新门由当前状态需要被遗忘的历史信息和接受的新信息决定;重置门由候选状态从历史信息中得到的信息决定。
单向GRU 在使用时是从上文向下文推进的,容易导致后面的词比前面的词更重要,而双向GRU(BiGRU)通过增加从后往前传递信息的隐藏层,能更充分利用上下文信息,克服了这一缺陷。BiGRU 的模型结构如图3所示。
1.4 注意力机制
2014 年,Mnih 等[22]在图像分类任务中首次提出注意力机制,使得结合注意力机制的神经网络成为研究的热点。Bahdanau 等[23]将注意力机制和RNN 结合以解决机器翻译任务,将注意力机制引入到自然语言处理领域。
通过计算概率分布,选择出对当前任务目标更关键的信息,可对深度学习模型起到优化作用,注意力机制在文本情感分析领域中已经得到广泛应用。
1.5 BERT-DCA 模型
如图4 所示,BERT-DCA 模型结构包含输入层、信息提取层、特征融合层和输出层4 个信息处理层次,在结构上则采用了2 个信息处理通道:左侧为语义信息注意力通道(Semantic information attention channel,SAC),右侧为情感信息注意力通道(Emotional information attention channel,EAC)。
1.5.1 输入层
对于一条文本句子序列,经分词后的词语序列{W1,W2,⋅⋅⋅,Wn}作为SAC 的输入,通过情感信息集合的提取策略,进而得到由该文本句子提取的情感信息词集合{E1,E2,⋅⋅⋅,Em}作为EAC 的输入;然后利用预训练模型BERT 为整个模型提供词向量,能配合上下文语境实现词向量的动态调整,更好地将真实情感语义嵌入模型训练,从而得到语义信息词向量矩阵Rx和情感信息词向量矩阵Re

式中:⊕为行向量连接运算符,Rx和Re的维数即为评论文本中词语的数目和情感信息词的数目。

图3 BiGRU 结构图Fig.3 Structure of BiGRU
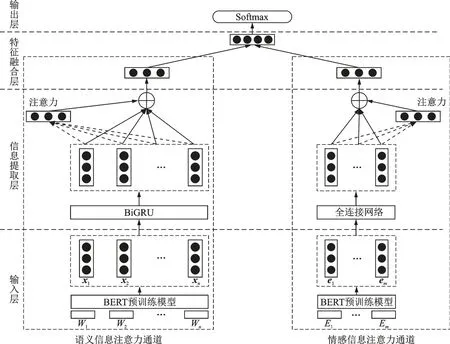
图4 BERT-DCA 模型结构示意图Fig.4 Structure of BERT-DCA model
1.5.2 信息提取层
对于语义信息文本,首先利用BiGRU 神经网络同时处理正向和反向文本序列,对文本深层次的信息进行特征提取,然后利用注意力机制对提取的特征信息分配相应的权重。对于情感信息集合,采用全连接网络与注意力机制相结合的方式对情感信息词进行编码,以获取最重要的情感信号。
某一时刻t的BiGRU 信息提取模块输出状态由正向GRU 和反向GRU 的输出相连接组成,其计算方法为

为了捕获更直接的语义依赖关系(使模型在训练时聚焦到数据中的重要信息),将评论文本BiGRU 模型的输出和情感信息集合全连接网络的输出分别输入到注意力机制中,采用双通道注意力分别对评论文本句子和情感信息进行编码。注意力计算方法如下


式中:ww与bw为注意力机制的可调节权重和偏置项,ht为BiGRU 或全连接网络的输出;ut为ht的隐含状态,uw为Softmax 分类器的权重参数,αt表示句子中每个词的重要度信息;V即为经过注意力模型计算后的特征向量。
1.5.3 特征融合层
特征融合层的主要任务是将SAC 中生成的特征向量Vs和EAC 中生成的特征向量Ve进行合并,从而构建文本整体的情感特征向量。为了简化模型的计算量,采用行连接的方式进行特征融合,构建一个 (rs+re)×c的 矩 阵V*,生 成 最 终 情 感 特 征 向 量 ,其 中rs和re分 别 为Vs和Ve的 行 数 ,c为Vs和Ve的列数。
1.5.4 输出层
将特征融合层生成的情感特征向量V*输入Softmax 分类器,从而得到模型最终预测的情感分类结果

式中:wo为权重系数矩阵,bo为偏置矩阵,p为输出的预测情感标签。
1.5.5 模型训练
情感分析模型的训练采用端到端的反向传播方式,最小化所有文本中已知情感类别和预测情感类别的交叉熵。

式中:D为训练数据集,C为情感标签的类别数,y为实际情感类别,为预测情感类别,λ为L2正则化,θ为设置的参数。
2 实验与分析
2.1 实验设置
选取2 个语料库进行实验:
实验数据1采用流行的中文情感挖掘酒店评论语料ChnSentiCorp,该语料规模为10 000 篇。为了方便起见,将语料整理为4 个子集。选择ChnSentiCorp-Htl-ba-6000 的数据进行实验,该语料为平衡语料,包含正负类各3 000 篇。
实验数据2利用爬虫工具Pyspider 在豆瓣电影平台上抓取了近30 部热播电影用户评论及评分,并进行了去短文本(少于30 个字符)处理操作,再以影评的评分作为判定依据,2 星及以下判定为情感消极的评论,反之4 星及以上判定为情感积极的评论,分别获取消极情感评论文本10 000 条,积极情感评论文本20 000 条。
情感词词典来自大连理工大学的情感词本体数据库,程度副词和否定词来自于知网中文词库HowNet。为了构建语义信息和情感信息的词向量,采用结巴分词系统对酒店评论语料文本句子进行分词,在分词过程中,将构建的情感语言库作为自定义分词词典,如表1,使其在分词后作为一个基本的语言单元存在。此外,还进行了去重、过滤、去停用词等文本预处理。
实验设置的超参数如表2 所示。

表1 情感语言库Table 1 Emotional language library

表2 模型参数设置Table 2 Model parameter setting
2.2 实验评测指标
采用文本情感分析中常用的准确率P(Precision)、召回率R(Recall)、F1测度(F1measure)和损失率L(Loss rate)作为实验数据的评测指标。

式中,对于某一类别,nTP表示正确判断属于该类别的数量,nFP表示误判为该类别的数量,nFN指误判为错误类别的数量,G为测试数据集。
2.3 对比实验
进行3 组对比实验,所有实验均基于情感二分类(积极和消极)的任务进行十折交叉验证。第1 组比较词向量工具对模型的影响,只采用SAC 通道;第2 组实验对比SAC 和EAC 对模型分类性能的影响;第3 组实验探究模型情感分类迭代过程中准确率和损失率的变化情况。
2.3.1 词向量工具对比实验
基于SAC 通道信息提取层中的BiGRU-Attention 神经网络模型对比不同词向量工具的性能。
优质的内容是线上竞争的核心竞争力,年轻人乐于分享、热衷模仿,选取极具特色景点,多元融合创造趣味性,移动互联网时代的短视频肯定不同于以往的电视广告,短视频创造了新的平等对话语境,一定要有原创性,使用平台内容的调性。如西瓜视频具有精致化、精品化的特征,而抖音则带有节奏的嘻哈快感,迎合年轻人的口味。原创内容即是用户心理的表现,也是用户内心情感的宣泄,同时还能表达用户的生活态度,所以容易产生共鸣,创造出魔性内容,更具传播性。
Word2vec-SAC:采用Word2ec 作为词向量工具,然后通过BiGRU-Attention 神经网络进行训练。
Glove-SAC:将词通过Glove 模型转换为词向量以后,利用BiGRU-Attention 神经网络进行训练。
ELMo-SAC:将词通过ELMo 模型转换为词向量以后,利用BiGRU-Attention 神经网络进行训练。
BERT-SAC:采用Google 预训练好的中文模型BERT-Base-Chinese 训练数据文本转换为词向量以后,利用BiGRU-Attention 神经网络进行训练。
对表3 中的实验结果进行分析:
(1)由于Glove 模型是在统计词向量模型和预测词向量模型基础上,通过矩阵分解的方法利用词共现信息,不仅关注Word2vec 窗口(Context)大小的上下文,而且用到了全局信息,能较好地提高语义表征能力。因此,Glove-SAC 的模型评价结果略优于Word2vec-SAC。

表3 基于不同词向量模型的对比结果Table 3 Comparison results based on different word vector models
(3)相比ELMo 采用LSTM 进行提取词向量特征,BERT 采用更为强大的Transformer 编码器,进一步提高了特征提取的能力,有效增强了情感表征,在2 组数据中BERT-SAC 均获得了最优结果。
2.3.2 分类模型对比实验
本组实验参照文献[24]选择了现阶段句子级情感分析领域中较为常用的几种分类模型进行对比研究,其中5 种模型均采用BERT 作为词向量工具。实验结果如表4。
对表4 中的实验结果进行分析:
(1)相比于CNN,BiLSTM 更擅长时序特征的捕获,因此BERT-CNN 实验效果稍逊于BERT-BiLSTM;而BERT-BiGRU 的表现性能更优,这与Xu 等[25]针对CNN 与BiLSTM 的评论文本情感分析实验的结论一致。
(2)相比 BERT-BiGRU 模型,BERT-SAC 模型在BiGRU 神经网络基础上增加了注意力机制,有助于提取文本重点信息,因而性能取得了明显的提升。
(3)相比于 BERT-SAC 模型,BERT-DCA 模型的性能有进一步提升,这是由于BERT-DCA 构建了SAC和EAC 双通道,其中EAC 中采用由全连接网络和注意力机制相结合的深度网络模型,针对文本中包含否定词、程度副词、情感词等具情感色彩的词进行提取,结构化的情感语言词及全局上下文都得到了充分考虑,有助于捕捉文本潜在的语义特征,更好地挖掘出文本深层情感信息。
(4)相对于数据 1 的实验结果,数据 2 中 BERT-DCA 比 BERT-SAC 在准确率、召回率、F1测度上分别提升了2.94%,3.31%,3.09%,且5 个综合模型的分类效果均优于数据1,这是因为本组实验选取了大于等于30 个字符的长文本实验数据,其情感信息词词频更高,文本数据中所含的情感信息更丰富,有利于情感信息注意力通道中注意力机制发挥更好的效果,准确捕捉文本情感极性。
2.3.3 迭代过程性能对比实验
为进一步说明BERT-DCA 模型的有效性,且更直观地体现注意力机制和语义信息与情感信息的双通道构造对模型的性能提升效果,本组实验选择均包含了双向GRU 神经网络架构、较为相近的3 种模型BERT-BiGRU、BERT-SAC、BERT-DCA,对比分析其分别在2 个数据集实验中10 次迭代的准确率和损失率变化,实验结果如图5,6 所示。
可以观察到,在2 个数据集上BERT-DCA 的准确率始终高于其他2 种模型,而损失率则始终更低。而且,虽然随着迭代的进行,3 个模型均出现了不同程度的性能退化,但相对而言BERT-DCA 的性能要稳定得多,准确度下降和损失率上升的幅度小,显然这得益于双通道的构建。在收敛速度上,BERT-DCA 和BERT-SAC 模型在2 个数据集上均优于BERT-BiGRU 模型,这归功于注意力机制带来的优化效果。在数据2 上3 个模型的收敛速度均比在数据1 上更快些,这是由于数据2 选择的文本序列长度较为统一,情感信息更为丰富,为模型准确快速识别评论文本情感极性提供了良好条件。

表4 分类模型实验的对比结果Table 4 Comparison results of classification model experiments

图5 3 种模型准确率变化曲线Fig.5 Accuracy curves of the three models

图6 3 种模型损失率变化曲线Fig.6 Loss rate curves of the three models
表5 给出了部分评论文本示例在BERT-DCA 模型训练后的情感分类效果。

表5 实例展示Table 5 Case demonstration
3 结束语
针对句子级文本情感分析任务,提出了一种基于BERT 和双通道注意力的新模型。采用BERT 作为词向量工具,一方面,由BiGRU-Attention 神经网络作为语义信息注意力通道,另一方面,通过自定义的情感信息集合提取策略和引入注意力机制,构建并行的情感信息注意力通道;最后进行双通道特征融合,利用Softmax 分类器实现情感分类。实验结果表明,相比其他词向量工具,BERT 的特征提取能力更为优异,而情感信息通道和注意力机制增强了模型捕捉情感语义的能力,明显提升了情感分类性能,且在收敛速度和稳定性上表现更优。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
传媒评论(2017年3期)2017-06-13
中国修辞(2017年0期)2017-01-31
第二课堂(课外活动版)(2016年2期)2016-10-21
中国社会历史评论(2016年2期)2016-06-27
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
