
实时流计算在保险决策系统中的应用*
2020-08-11 00:46陆智卿赵文洋
计算机与数字工程 2020年6期
吴 锋 陆智卿 赵文洋
(中国石油大学(华东)计算机与通信工程学院 青岛 266580)
1 引言
实时和流计算是近期非常热门的关键词,随着Spark等专为大数据[1]设计的开源引擎的出现和完善,实时流[2]计算在国内外知名企业中的应用呈现井喷爆发之态势。实时流计算技术更是为金融保险行业商业智能领域带来新的契机,采用实时流计算技术能够解决决策系统信息滞后的痛点,极大提高经营决策效率和准确度[3]。
2 研究现状
实时流计算已在金融保险行业广泛应用和实施,成为促进企业经营快速发展的必备技术[4]。而此技术对于数据加工环节的及时性,一般可以分为批处理模式和流式大数据模式,流式大数据模式也会被称为大数据实时计算,技术体系方面主要还是以Hadoop作为主要生态系统,技术推动涌现出storm、spark等应用于流计算的框架工具,其中以Spark作为主要的流计算处理框架,在世界范围内应用最为广泛[5~7]。
在金融保险行业、电商、物流等多个行业中,为了提升对用户的满意度、以及公司经营发展的需要,催生出的智能决策分析、决策管理驾驶仓等,都需要在数据加工环节有了不一样的需求。为了实现业务目标,数据加工必须快速返回数据结果,而传统的决策加工技术一般都是批作业方式实施,数据要先经过多个环节处理加工、存储并返回结果,往往都有相当的滞后性,通常都是N+1天,特别是一旦业务数据量急剧膨胀时,传统的决策加工技术更是无法支撑其更高的业务目标要求。
随着保险公司业务不断的扩大发展,其业务数据越来越庞大,而过去所使用的传统决策系统已无法支撑其更高的要求,为此本文提出开展实时流式处理的技术在决策分析中的应用研究,子课题便是在个险作战地图的报表分析实现“个险首年期交保费”的实时流计算应用,用大数据技术实现对该指标数据的实时追踪。
3 实时计算原理
3.1 决策分析
决策分析[8]通常包括数据收集、数据存储、数据计算[9~10]和数据分析[11~12]等多个方面,以数据为基础,借助利用先进的存储、计算以及可视化等技术,让更多的数据用于业务经营和管理决策。其具体内容如图1所示。
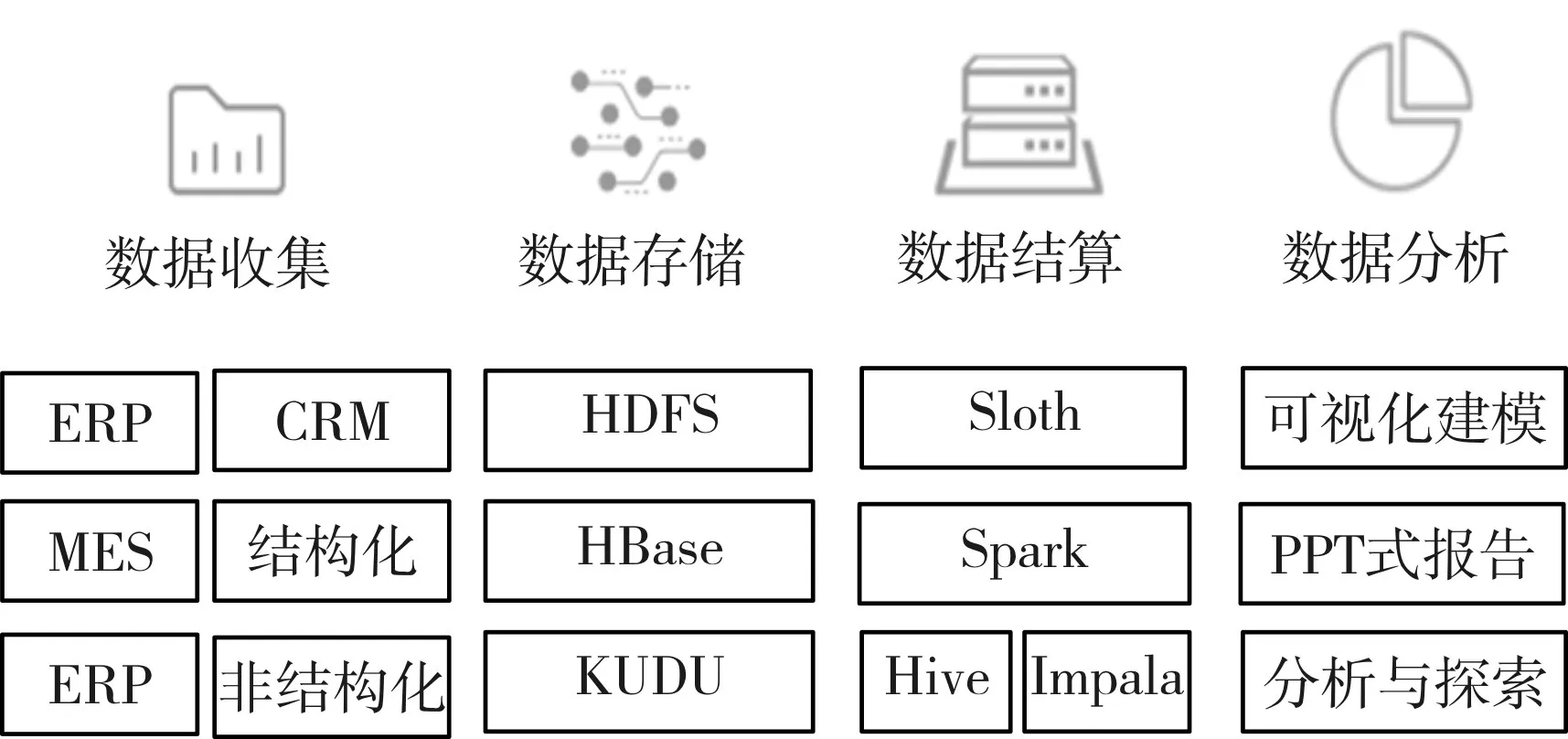
图1 决策分析内容详解图
3.2 实时流式计算
流计算[13]的应用场景主要还是面向巨量数据时,能够秒级返回处理结果。流计算技术就是面向这一应用场景的,能够实时处理计算并且实时落地数据库[14~15]。而 Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,实时流式计算可以实现数据高速流转[16]。
4 系统设计与实现
4.1 需求特征
具体的业务场景,是要实现一套挂图作战实时指标等实时数据追踪系统,通过对其业务场景进行需求分析,其需要实现实时的指标加工计算和呈现,而在指标技工过程中,需要对大批量的历史数据进行一次性加工计算,以及实时能够加工新的增量数据,同时向地图应用能够实时呈现最终结果。实时增量数据主要源于核心业务处理系统,客户实时购买的业务保单,这部分实时进单保费,具有数据量大,数据价值随时间流逝而降低的特性,且数据价值密度低,很少需要精细查询。历史全量数据则为数据字典等,例如组织架构代码等,具有数据量小,修改不多的特征;统计结果数据为上述数据的复杂计算结果,例如挂图作战中的个险首年期交保费,该指标加工复杂,需配合实时进单保费、历史存量数据并进行复杂的多列聚合计算而成,而因为增量的进单保费一般数据相对较小,在应用场景中需要实时的进行呈现,因此需要对其进行快速且并发进行加工计算。
4.2 实时决策分析中的指标计算
实时流应用在决策报表中,指标加工计算是其重要的一环。而其加工指标一般要求能够在秒级能够完成数据加工,对于大多实时流计算指标而言,其最主要的加工口径为

WE等于数据加工完毕时间-数据生成时间。
WX等于决策分析指标可延迟的时间。
指标数据加工需要在业务要求范围内实施,根据公式只有E远远高于1,其实时指标加工计算的能力才能够符合系统的要求。反之,如果无法实现实时加工计算,那么公式中的E将低于1。如果再加工的过程中,计算延迟严重,那么WE便会快速放大,最终整个业务场景实时流计算加工指标将无法达成目标。对于保险行业的决策分析应用,目前要求其WX为5min,且未来将逐步减少到1min。
4.3 设计原则
结合保险公司的建立实时挂图作战决策系统的应用场景,同时基于其系统中所要求实现的实时追踪指标的加工方式,将提出需要在设计过程中重点实现4条设计原则。
1)存量数据加工。一次性初始化实现,存量数据加工因为变化小,数据量大,为了保证加工计算的时效性,这部分数据加工处理场景将不会用流计算的模式,将会采用一次性初始化加工抽取完成。考虑到后续内存数据库技术的逐步完善,未来把会将这部分数据放在内存中进行计算,同样可以大幅提升其加工效率,同时采用内存和存储的互相切换,能够更加理想的提供计算查询服务。
2)小数据量的增量流式计算服务能力。这部分需要要求实时性高,同时数据量较小,多为业务增量实时产生,对于这部分加工设计,将会根据业务上的需要,在内存中实时加工计算,不落地存储的方式。
3)混合计算模式。由于实时挂图作战决策报表系统需要实时呈现指标的动态变化周期以及体现高速增长时效性,将对其指标采取预先计算处理方式,在存量加工指标的基础上,实时叠加增量的部分,将结果预先计算好,根据决策系统的查询报表条件存储在Hadoop存储中,这样也能够提供高并发查询的指标级服务,最终体现实时监控的周期性、时效性等特征,动态变化。
4)预计算模式取代实时计算模式。由于实时监控数据具有强烈的周期性特征及时效性特征,故将要计算的指标均采用预先处理的模式,先计算好结果,存入到KV存储引擎中,将用户的查询转换为按照条件组成Rowkey的KV查询模式,从而实现快速的高并发查询Redis服务。考虑到高速并发以及容灾措施,将结果集指标定期存储在redis服务中,一旦出现加工不及时或者数据库错误时,能够实时切换至redis查询服务中,给用户带来系统更加稳定的感受。
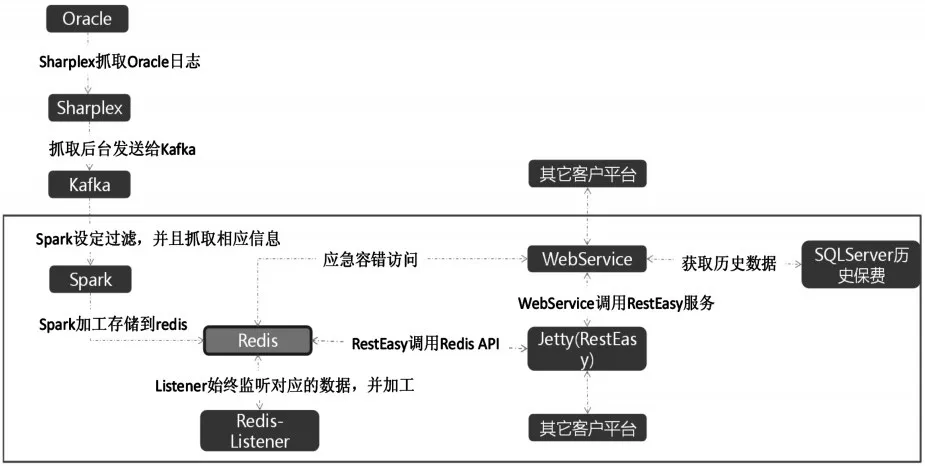
图2 基于流处理的数据流程图
因此,基于流处理的数据流程如图2所示,通过该流程设计,将计算与数据存储分离,解决传统架构中计算与存储混合对系统处理效率的影响。因此,一方面能够解决传统决策系统计算存在的问题,也能够将计算和存储进行分离、且混合处理。
4.4 技术架构
为了支撑指标的实时追踪,在技术架构上,将采用“职责分段”的思路,进行了如下几项设计:
1)使用SharePlex监控Oracel日志文件,捕获数据库操作消息,从而获取业务系统数据库的增、删、改的增量数据。
2)使用Kafka记录SharePlex的数据消息,负责消息队列分发。将增量数据转成消息往下游推送和处理加工。
3)使用Spark Streaming对数据进行抽取、过滤。根据指标的业务口径,将消息增量数据加工成决策系统中的指标数据。
4)使用Redis负责存储、加工消息数据。将处理后指标数据暂存在Redis内存数据库中。
5)封装WebService服务,对外提供数据查询。封装后的接口服务,可以提供给任意决策分析应用进行调用,保证数据对外输出的一致性。
通过以上技术架构的设计,具体的系统架构图如图3所示,能够提供可靠、准确、稳定、实时的保费指标,这些设计使得决策分析系统的价值体现迈向了一个新的台阶。
5 结语
本文从保险行业的特点以及其决策系统的时效性要求出发,提出要建立一种新的流式计算基于混合计算、分离存储过程的模式,极大地提升了报表的数据及时性,基本满足更多业务追踪上的应用场景。技术框架上,采用的是Spark和kafka等开源软件作为技术核心,具备一定的可扩展性和先进性,同时为了让该技术方案具备一定的推广性,提出了基于实时计算平台的公共JAR包以及简易SQL的模板支持,可以将该方案快速复制,具有开发周期短、可复用性高等特点。
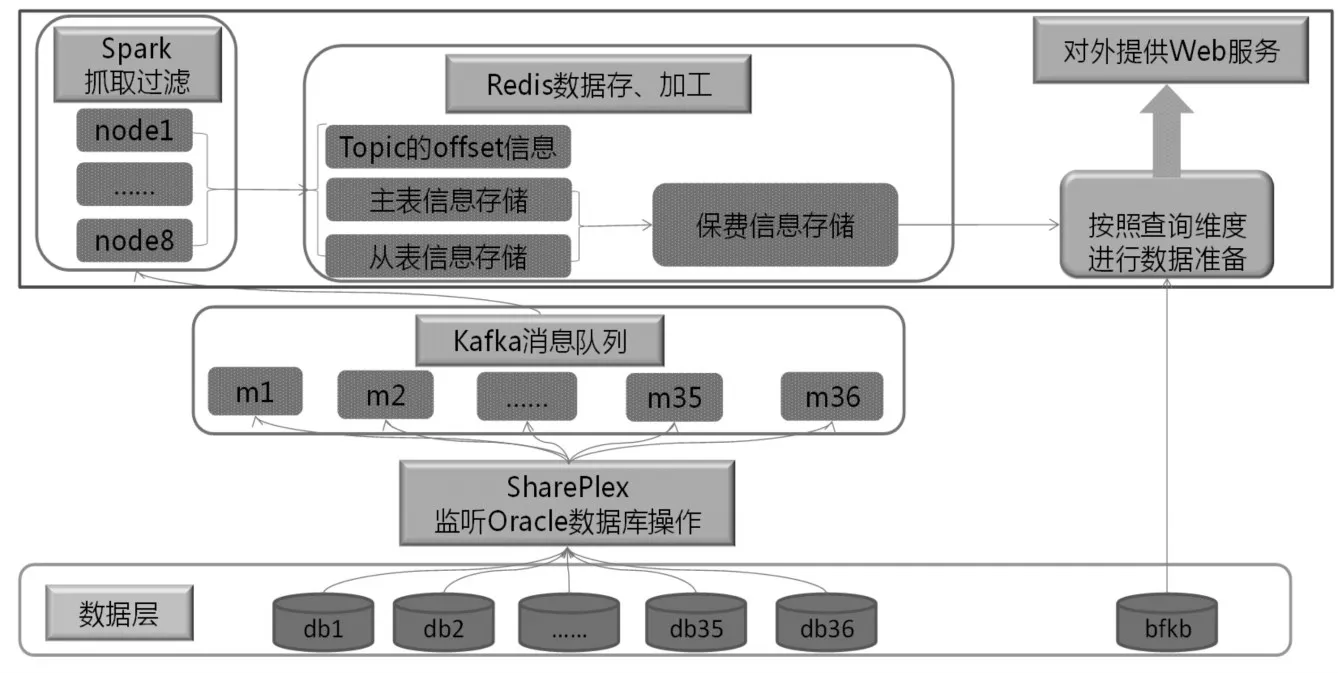
图3 系统架构图
在未来,将会进一步对该技术架构迭代改进,并针对保险行业对于数据质量要求高、重稳定等特点进行针对性优化,使之能够在更多的数据分析场景中快速推广,能够为公司数据存储、计算、分析的全价值链提供数据可视化平台,迎接更多的大数据挑战。
猜你喜欢
煤炭加工与综合利用(2022年7期)2022-08-29
中老年保健(2022年5期)2022-08-24
内燃机与配件(2022年2期)2022-01-17
债券(2021年1期)2021-02-04
债券(2020年4期)2020-08-04
决策(2018年8期)2018-12-10
决策(2018年11期)2018-11-28
决策(2018年10期)2018-11-07
小天使·四年级语数英综合(2018年1期)2018-07-04
债券(2018年11期)2018-02-21
