
增量自适应学习算法 ①
2020-08-10 09:47:14孙明轩徐晨晨邹胜祥
高技术通讯 2020年7期
孙明轩 徐晨晨 邹胜祥
(浙江工业大学信息工程学院 杭州 310023)
0 引 言
积分自适应方法适用于连续时间参数系统,它提供的自适应机制在线调整控制器参数,以实现期望的控制性能。这种自适应方法的典型特征在于其积分自适应参数估计算法,可利用 Lyapunov综合方法推导这种自适应律,并建立闭环系统稳定性与收敛性。积分自适应算法在相关文献中较为常见,关于它的详细理论(包括算法推导、算法性质)可参见文献[1,2]。由已发表文献可以看出,积分自适应方法在处理参数不确定性方面是十分有效的,通过算法形式的设置能够直接导致性能分析的完成。由于自适应算法的积分形式,实现时需要求解用于估值计算的积分方程,即需要进行离散近似。离散近似后的参数估值与积分自适应律所得结果是存在偏差的。已发表文献中提出了多种鲁棒自适应策略,可以使得积分自适应律在离散实现时仍能够保证闭环系统的控制性能[2]。通过采取界已知的不确定性鲁棒处理手段,文献[3]提出的自适应鲁棒控制方法能够预先规定系统性能,从而有效改进了闭环系统的瞬态性能。
迭代学习方法借鉴人们处理重复行为的做法,经由逐步学习过程不断改善、提高性能,如运动员的训练过程。迭代学习控制技术适于有限区间上重复运行的受控对象,通过学习可实现完全跟踪任务。值得借鉴之处在于学习算法的构造形式,它能够提供关于时变参数的估计,但每次作业完成后要求初始定位。重复控制是与迭代学习控制并行发展的领域,重复控制适于周期参考信号控制任务,可实现周期参考信号的渐近跟踪及周期干扰的抑制[3-8]。自适应方法已被用于处理存在未知周期时变参数的情形,形成了自适应学习控制,其中的周期性自适应机制用于估计周期性时变参数。它适用于处理周期性干扰信号,因为这种干扰可以被认为是受控系统动态特性中的周期时变参数[7-9]。学习控制器设计时的一个重要问题是估值限幅,通过限幅措施可以确保有界估计[10-13]。这种控制技术在电机控制等工业场合已有应用报道[14-17]。
借鉴上述学习控制方法,本文提出增量自适应学习策略,以推广学习控制的适用范围。具体地,增量自适应学习方法可应用于连续运行受控对象,其参考信号不要求为周期的。针对连续时间自适应系统,文中应用增量自适应学习策略,避免使用积分自适应律,从而规避了在实现积分自适应律时进行离散化带来的近似问题。文中提出具有未知常参数不确定系统的自适应学习控制算法,与通常自适应控制类似,适合于任何参考输入信号跟踪(除光滑性要求外),并未有周期性或重复性要求。本文详细分析了非限幅和限幅自适应学习机制,给出了数值仿真结果,并将其应用于实际运动控制装置。
1 问题的提出
考虑下述参数不确定动态系统:
(1)
其中,x和u分别是标量状态和控制输入,θ是nθ维未知参数向量,φ(·)是连续非线性函数向量。θ在式(1)的右端呈线性形式,这表明与传统自适应系统类似,本文也注重处理线性参数不确定性。本文的控制目标是,对于系统式(1),设计自适应控制器,使得系统状态收敛于0,即当t→∞时,x(t)→0;同时,闭环系统中所有信号都是有界的。为了实现这一控制目标,本文提出设计控制器的增量自适应方法,而不是采用通常的积分自适应方法。
常规积分自适应控制器具有如下形式:
(2)
并采用下述自适应律:
(3)
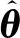
(4)
(5)
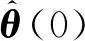

式(3)被称为积分自适应律,这是因为它可写为
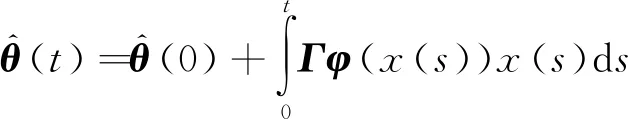
对于t>T,

将上述两式相减,可得式(3)的增量形式为

(6)
利用积分中值定理:
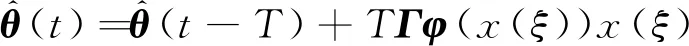
(7)
其中,ξ位于t-T和t之间的某个时刻。式(7)右边的第2项,其取值取决于ξ;由于ξ的不确定性,在不同时刻这一项的取值也无法确定。由于实际控制系统中采用计算机技术,该积分自适应律在应用时只能近似实现,即x(ξ)以x(t)替代,也可以x(t-T)替代。通常,闭环性能分析是针对式(3)进行的,或者是针对式(6)进行的,而不是针对替代后的闭环系统。因此,替代后的闭环系统性能尚无理论保证。本文拟探讨无需采用积分近似的自适应方法,以便规避实现积分自适应算法时遇到的问题,并分析其闭环系统控制性能。
2 增量自适应学习算法及其收敛性
本节给出的自适应系统设计采用了增量自适应方法,它不同于使用积分自适应算法的传统设计。本文将分别讨论未限幅和限幅自适应机制。
首先,考虑下述自适应律:
(8)

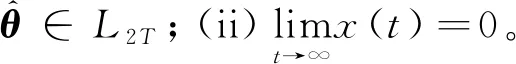
证明选择下述Lyapunov-Krasovski泛函:
(9)
它关于时间的导数为


利用下述等式:
可将V的导数表达为

(10)
利用自适应律式(8),可将式(10)写为

(11)

可以得出,x∈L2T。进一步地,对于t∈[iT, (i+1)T],t0=t-iT∈[0,T)。
因而,
由级数收敛的必要性条件可知:
利用不等式(a-b)2≤2a2+2b2,由式(4)得:
由于x的有界性和φ(x)的连续性,存在常数c1和c2使得:

式(8)给出了一种增量形式的自适应律,它在应用中可以直接实现,无近似计算。不像式(6)那样含有积分运算,实现时需近似计算积分。

通过在式(8)所示自适应律中引入饱和函数,本文提出如下形式学习律:
(12)
(13)

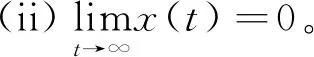
证明利用式(4),V的时间导数可表达为
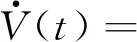

依据文献[11]中引理1(取q1=1,q2=0),
因此,

利用式(12)和式(13),得到:
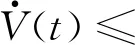
-βx2(t)≤-βx2(t)
至此,容易推出该自适应学习系统的稳定性和收敛性结果。

仿真结果如图1~图3所示。从图1可以看出,系统状态在所提出的控制器作用下收敛;图2为控制输入信号;由增量自适应学习律给出的参数估值收敛性能如图3所示。
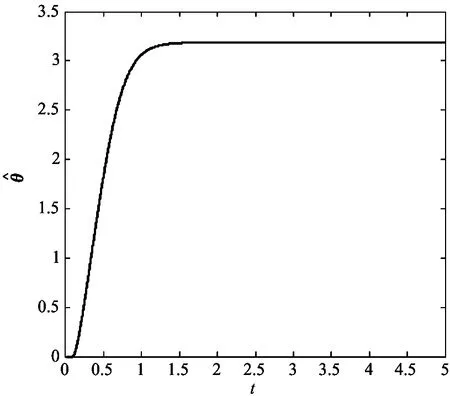
图3 参数θ的估计(其真值为3)

图2 控制输入u
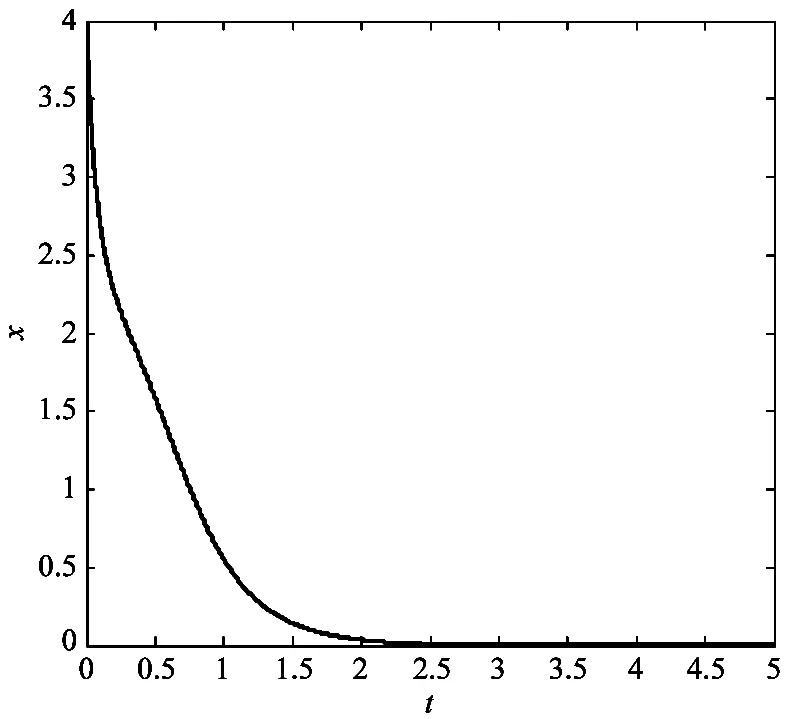
图1 系统状态x
3 增量自适应鲁棒控制
这一节,本文将增量自适应方法应用于实际中常见的运动控制系统。对于这类系统,自适应鲁棒控制是一种有效控制方法。
考虑下述不确定运动控制系统:
(14)
其中,x1和x2分别为系统位置与速度变量,u是控制输入,M为惯性负载的转动惯量,B为粘滞摩擦系数,Δ表示扰动、建模误差等集总不确定性。
为了表达简便,定义参数θ1=M,θ2=B,可将式(14)写为
(15)
对于未知参数及外部干扰,假设其变化范围有界,且界已知。
假设1在式(15)中:
θ∈Ωθ={θ: 0<θmin<θ<θmax}
(16)
(17)

给定位置参考轨迹xd,本文的控制目标是设计控制输入u,使得系统实际位置尽可能跟踪上该参考轨迹。为了达到此控制目标,本文采用增量自适应学习算法估计未知参数,同时以鲁棒手段处理外部扰动,设计增量自适应鲁棒控制器。
为此,定义如下滤波误差函数:
(18)

对式(18)求导,并代入式(15)可得:
(19)
考虑误差动态方程式(19),本文设计如下自适应学习控制器:
u=ua+ur
(20)
(21)
ur=us1+us2
(22)

(23)
(24)
(25)
(26)
这里,γ1、γ2>0为增益系数,sat(·)为饱和函数。ur为由2项组成的控制项,比例反馈控制项us1=-ksef,ks>0,us2为鲁棒控制项,用于处理不确定性影响,本文假定us2有界(在状态有界情形下)。与文献[3]中相似,此项需满足以下条件:
(27)
P2:efus2≤0
(28)
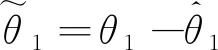
本文首先仅考虑存在参数不确定性的闭环系统收敛性能,即考虑Δ=0的情形。
定理3系统式(15)在控制律式(20)作用下,当Δ=0时,闭环系统所有变量有界,且跟踪误差渐近收敛于0。
证明选取如下Lyapunov泛函:
(29)
为了分析收敛性能,本文考查该泛函在整个周期上的差,即ΔL(t)=L(t)-L(t-T),
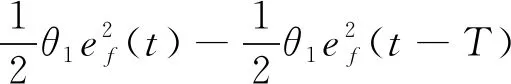
(30)
当Δ=0时,对于上式右端的前2项,依据条件式(28)可得:
(31)
进一步地,有下述关系式:
(32)
以及
(33)
将式(31)~(33)代入式(30),可得:
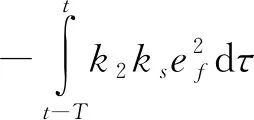
(34)
依据文献[11]中引理1(取q1=1,q2=0)可知:
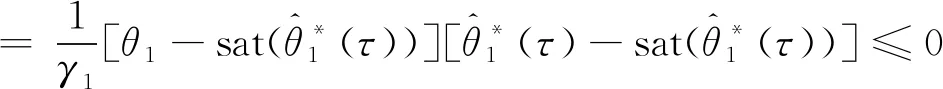
这样,式(34)可写为
(35)
对于t∈[iT,(i+1)T],记t0=t-iT∈[0,T),可将L(t)写为
由式(35)可知:
(36)
为了得到L(t)的有界性,需先证得L(t0)是有界的,即,对于t∈[0,T),L(t)有界。由L(t)的定义可知:

对上式关于时间求导:
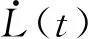
为了方便实现,本文需设计具体的鲁棒控制项us2。该项需满足条件P1和P2,本文设计us2为如下形式:
(37)
式中,取h满足:

(38)
这里,各界值定义见假设1。
定理4系统式(15)在控制律式(20)作用下(采用式(37)给出的us2),当Δ≠0时,系统响应满足下述微分不等式:
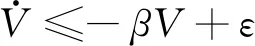
(39)

证明根据式(20),对V求导可得:

可得:
定理得证。
由定理4可以看出,在控制器式(20)中采用鲁棒控制项式(37)规定了闭环系统响应的瞬态过程,瞬态及稳态性能可以预先设定。这与常规自适应鲁棒控制方法是相同的。对于增量自适应学习算法(不同于积分自适应算法),本文证明了这种控制性能能够预先设定的特点。本文提出的控制方案并未要求参考轨迹是周期信号,这不同于重复控制方法。
4 算法实现
在电机实验装置上,实现本文提出的增量自适应学习控制方案,以便验证其控制效果。该实验装置如图4所示,它以TMS320F2812控制器、ELMO HAR-5/60驱动器、APM-SB01AGN交流伺服电机构成闭环控制系统,完成位置跟踪控制过程,上位机作为运行监控设备。

图4 电机实验装置
实验中采用了2组期望轨迹,以便检验正弦信号跟踪与点到点控制效果。
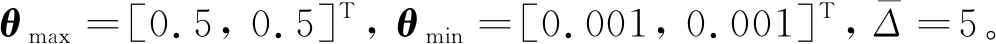
4.1 正弦信号跟踪
取正弦参考信号xd(t)=90sin(πt)。图5~图7为采用增量自适应学习算法的跟踪控制结果。其中,图5(a)分别给出实际输出信号与参考信号;图5(b)为跟踪误差。由图中可以看出,它最终收敛于-0.3520~0.3020 deg;图6为控制输入;图7为参数θ1和θ2的估计,如图中所示,参数估值会逐渐趋于常值(或是在某邻域内波动),但无法确认参数估值是否收敛于真值,因为本文在保证稳定性与控制精度下,仅证明参数估值有界。
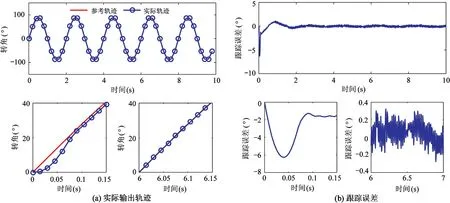
图5 增量自适应学习控制下的实际输出轨迹与跟踪误差

图6 控制输入

图7 参数θ1和θ2的估值
4.2 点到点控制
为了检验由式(23)~(26)所表示的增量自适应学习算法性能,在测试点到点控制性能时考虑以下3种学习周期:T=Ts=0.005 s;T=5Ts=0.025 s;T=10Ts=0.05 s。
点到点参考信号如图8所示;图9分别给出3种学习周期下的跟踪误差,对于不同的学习周期,误差最大峰值分别为-1.8238 deg、-1.7990 deg、-1.8296 deg,且跟踪误差分别收敛至[-0.3495,0.3660] deg、[-0.3540,0.3697] deg、[-0.3793,0.3540] deg;图10为3种学习周期下的控制输入;图11和图12给出了不同学习周期下的参数θ1和θ2的估计。
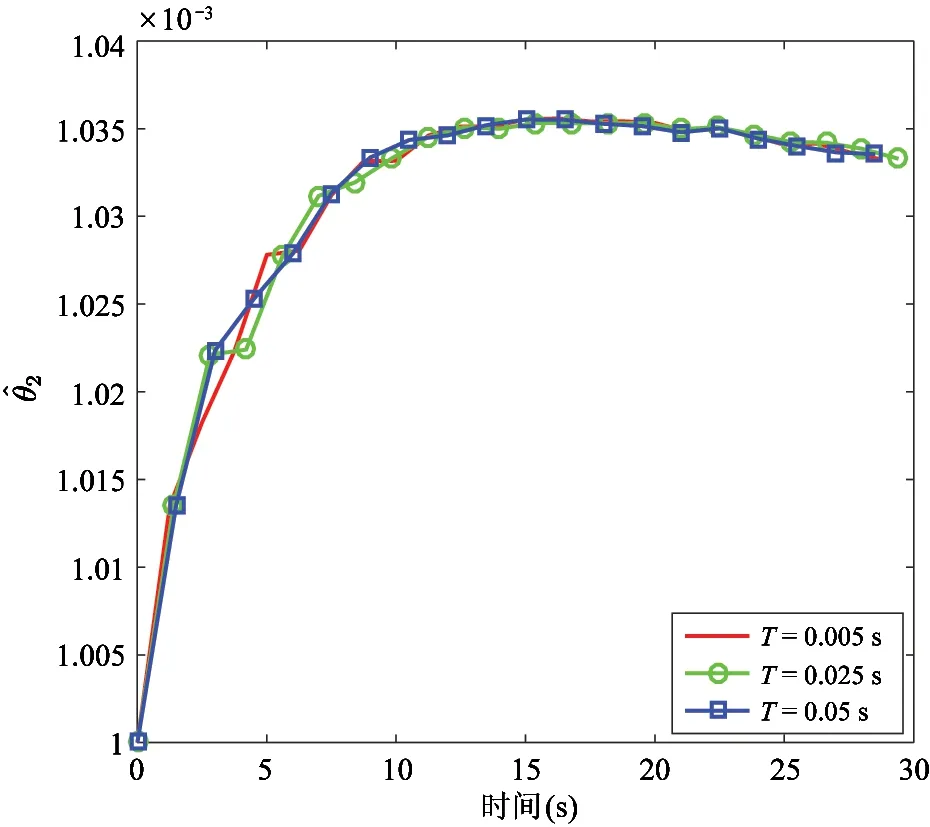
图12 系统参数θ2的估值

图11 系统参数θ1的估值

图8 点到点运动参考信号
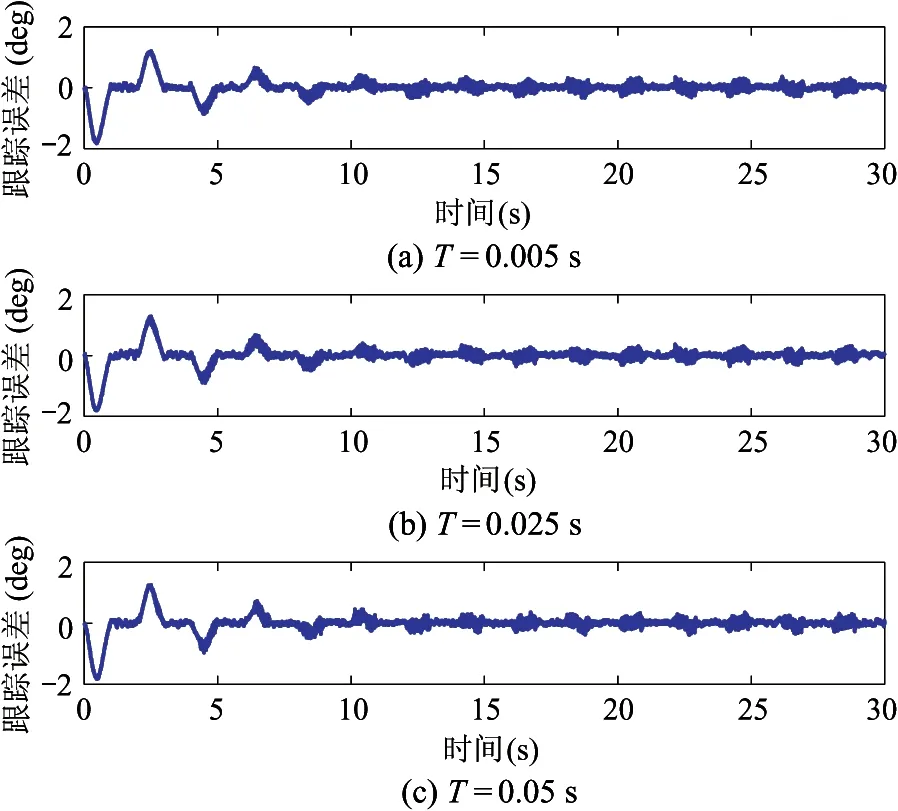
图9 跟踪误差
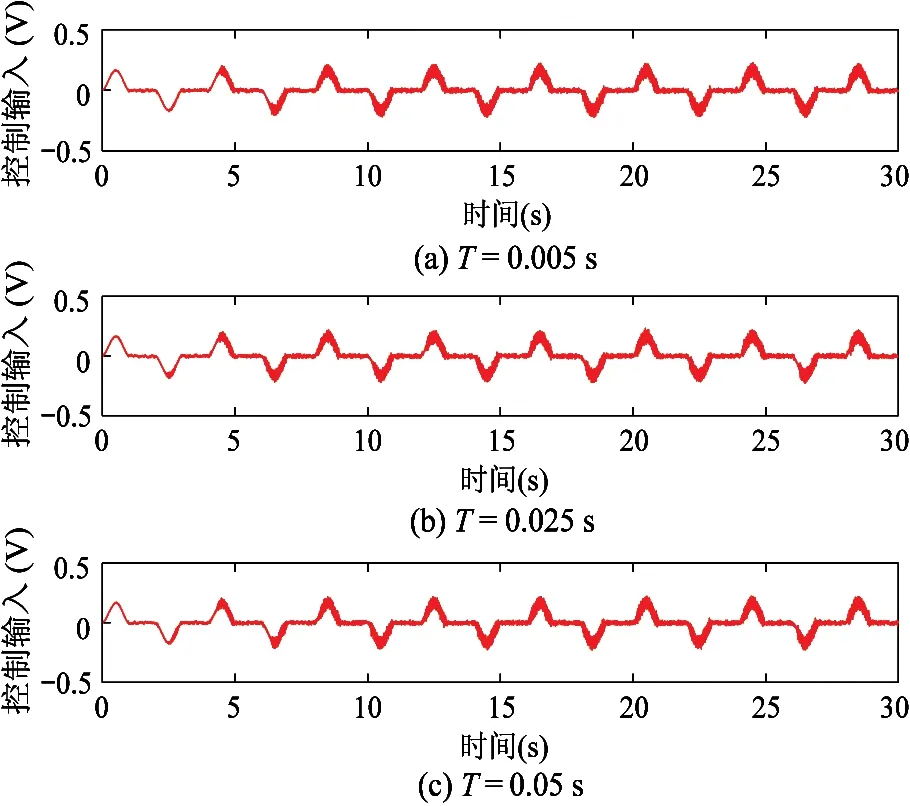
图10 控制输入
5 结 论
本文提出了一种增量自适应学习策略,适用于连续时间自适应控制系统,它不同于传统自适应系统中采用的积分自适应算法,在实现时规避了像积分自适应算法那样的离散化处理。为此,本文分析了积分自适应算法在应用时的近似实现方式。提出的增量自适应学习策略具有未限幅与限幅2种形式。本文证明了非限幅增量自适应系统的渐近收敛性,且估值在L2T意义下有界。提出的限幅增量自适应学习算法,能够保证参数估值本身有界,并借助类Barbalat引理,证明了闭环系统收敛性。理论分析与实验结果表明,提出的增量自适应学习算法能够有效处理受控系统中的参数不确定性,也证明了引入限幅是获得有界估计的有效方法;更为重要的是,它规避了积分自适应算法的离散化实现方式。
猜你喜欢
当代陕西(2022年6期)2022-04-19 12:12:22
系统工程与电子技术(2021年8期)2021-07-27 08:39:18
中学生数理化·中考版(2019年9期)2019-11-25 09:39:44
自动化学报(2019年6期)2019-07-23 01:18:22
厦门理工学院学报(2016年1期)2016-12-01 04:50:41
北京航空航天大学学报(2016年7期)2016-11-16 01:51:01
系统工程与电子技术(2016年4期)2016-08-24 07:46:18
电信科学(2016年9期)2016-06-15 20:27:25
物理化学学报(2015年7期)2015-12-30 12:13:18
电子设计工程(2015年16期)2015-02-27 12:07:58
