
基于多参数融合优化的隐马尔科夫模型的设计
2020-08-07 14:40:54蒋正锋黄勇萍
现代计算机 2020年18期
蒋正锋,黄勇萍
(广西民族师范学院数学与计算机科学学院,崇左532200)
0 引言
语音交互技术随着计算机科学与信息等学科的发展逐步成为人机交互的手段,其中语音识别在现阶段还是研究的一个热点。语音识别技术的研究工作起始于二十世纪五十年代,主要是对语音识别技术的初步研究,集中在元音、辅音、音节的识别。到了二十世纪六十年代,线性预测和动态规划技术的出现,解决了语音识别中语音信号特征提取、模型的产生及语音信号不等长等问题取得了实际性的进展。二十世纪七十年代,在语音识别的研究中,提出了动态时间规整(Dynamic Time Warping,DTW)、矢量量化(Vector Quantization,VQ)和隐马尔可夫模型。二十世纪八十年代,从基于标准模板匹配的语音识别算法转到基于统计模型的方法,识别任务的重点是大词汇量、非特定人和连续语音。因为语音的时变性和平稳性能被HMM 很好的描述出来,在大词汇量连续语音识别(Large Vocabulary Continuous Speech Recognition,LVCSR)中HMM 被广泛用于声学建模[1-2],统计语言模型开始应用于语音识别系统[3]中。这一时期,由于HMM/VQ、HMM/高斯混合模型、HMM/人工神经网络的语音建模在LVCSR 系统中被提出,语音识别的技术取得突破性的新进展。二十世纪九十年代,语音识别从实验走向实用,语音识别技术深入和细化方面取得了较大的进展[3]。二十一世纪初,HMM 和前馈神经网络[4-5]等为代表的传统语音识别方法占主导地位。就整个语音识别技术发展历史来看,探索浅层表现和深层的人工神经网络持续了多年,由于2006 年,深度学习理论[6-7]在机器学习中初步的应用成功引起了极大的关注,直到2009 年开启了深度学习的研究序幕,语音识别与深度学习技术相结合[8-9],逐渐掀起基于深度学习的语音识别研究热潮。
在理解语音识别原理的基础上,使用HTK(Hidden Markov Model Toolkit)工具箱,搭建一个汉语离散数字语音识别系统,探索不同参数融合的隐马尔科夫模型对语音识别率的影响,设计多参数融合优化的且有较高识别率的隐马尔科夫模型。
1 HTK简介
二十世纪七十年代,语音识别领域引入了隐马尔可夫模型,它使得自然语音识别系统取得了突破性进展,成为传统语音识别的主流技术。目前大部分的语音识别系统还是基于HMM 的,虽然深度学习技术已引入到语音识别领域中。HTK 是由剑桥大学基于C 语言开发,专门用于创建和处理HMM 的工具,广泛应用在语音识别、语音合成、字符识别和DNA 排序等多个领域。经过剑桥大学、Entropic 公司及Microsoft 公司对HTK 的不断改进,使HTK 在传统语音识别领域处于世界领先水平[10-11]。
另外,HTK 的源代码是对外公开的,可以把源代码中基于ANSI C 的模块嵌入到用户系统中,方便用户的开发。
1.1 HTK语音识别系统的体系结构
构建基于HTK 语音识别系统[11-13],具有如图1 所示的体系结构,主要由三部分构成,分别为特征提取、声学模型训练和语音识别。
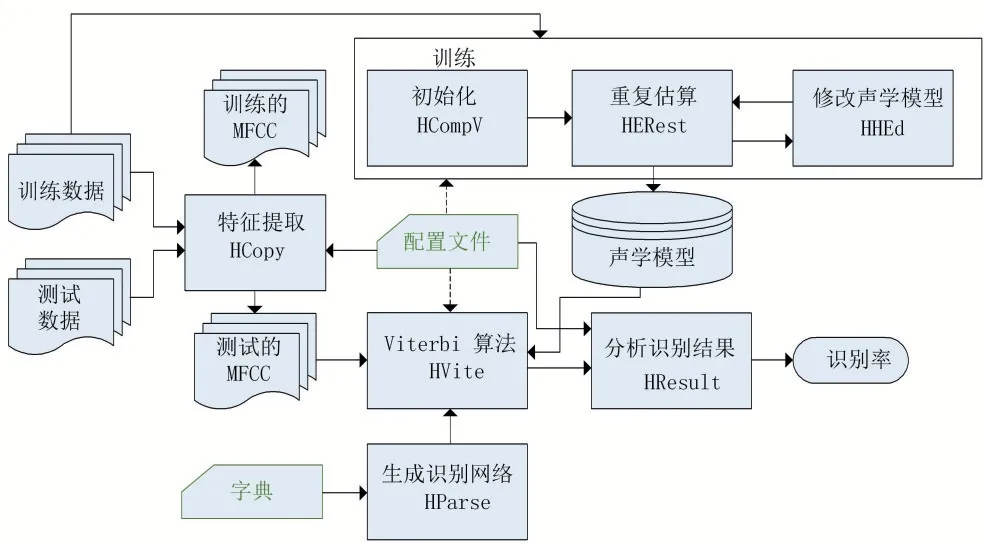
图1 基于HTK语音识别系统的结构
1.2 HTK语音识别工具
基于HTK 语音识别系统由语音数据准备、HMM模型的训练、语音的识别以及结果数据分析等组成。
(1)语音数据准备:语料库的创建用CoolEdit 等录音软件进行采集语音[6-7],手工或自动标注好语料库中的语料,语音特征的提取用HCopy 工具。
(2)HMM 模型的训练:创建好原始的HMM 模型,基于EM 重估算法,使用HCompv 和HInit 工具初始HMM 模型参数,然后对HMM 模型的参数用HRset 和HERest 重新估计,应用上下文无关的建模方法,用HERest 对HMM 模型进行嵌入式训练,模型中的参数不断被调整,参数性能不断向最佳状态逼近。
(3)识别:基于Viterbi 算法的HVite 命令用来识别未知的要测试的语音。
(4)识别结果分析:HResults 是训练好的HMM 模型的性能分析工具,用于分析未知语音的识别率。
2 实验准备
2.1 实验环境
设计的汉语离散数字语音识别系统,是在基于隐马尔可夫模型的HTK3.4 上搭建的,运行在PC Windows 10 平 台 上,CPU 为Intel Core i7- 6700HQ @2.6GHz,内存为8GB。
2.2 语料库的创建及模型状态个数
离散数字语音识别系统是在语音库基础上搭建的,所以先要准备好语料库中用于训练和测试的语音样本,语料库的详细情况如表1 所示。离散数字语音录制是在实验室环境下,采样率设置为16000Hz,量化精度为16bits。

表1 语料库样本详情
在实验中提取的语音特征参数是梅尔倒频谱,分别提取了13、26、39 维的MFCC(Mel Frequency Cepstral Coefficients)特征。语音的识别单元分音节和声韵母两种,其中声学模型状态的个数如表2 所示,每个状态的高斯分量从1 逐个增加到7 进行实验。HMM 模型是采用存在跳变的Left-to-Right 的类型。
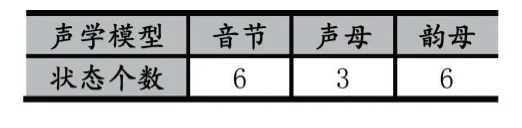
表2 声学模型状态个数
3 实验与结果分析
实验中提取了三种不同维度的MFCC 特征,分别为13 维、26 维和39 维,不同维度的MFCC 特征分别训练不同的HMM 模型,因此分三个大的实验。每个大的实验中语音识别单元采用了音节和声韵母两种,就语音识别单元不同的高斯分量对训练集和测试集中的离散数字进行了识别。
3.1 13维的MFCC特征参数训练模型
提取的特征参数MFCC 为13 维,声学模型分别为音节、声韵母,按表1 所示音节的状态个数设定为6,声母的状态个数设定为3,韵母的状态个数设定为6,不同高斯分量个数训练好的的HMM 对语料库中训练集和测试集分别进行了测试,识别结果如表3 和表4所示。
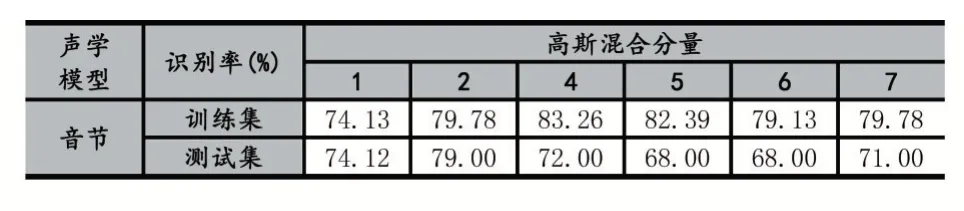
表3 声学模型为音节的13 维MFCC 特征训练模型的识别率

表4 声学模型为声韵母的13 维MFCC 特征训练模型的识别率
从表3 的识别结果可知:
(1)在高斯混合分量个数相同的情况下,训练集的识别率要高于测试集的识别率,因为用训练集来训练HMM 模型的,而测试集中的离散数字语音没有训练HMM 模型。
(2)不管是训练集还是测试集,识别率不是随高斯混合分量的增加而提高,对于训练集,高斯混合分量个数为4 时识别率最高,而测试集高斯混合分量个数为2识别率达到最高,再增加高斯混合分量,识别率反而降低。
从表4 的识别结果可知:
(1)在高斯混合分量个数为1 或2 时,测试集的识别率反而高于训练集,整体来看,训练集的识别率高于测试集。
(2)训练集识别率几乎是与高斯混合分量个数成正比,测试集的识别率随高斯分量个数增加而降低,在高斯分量个数为2 时,识别率达到最高。
由表3 和表4 识别结果得到:
(1)声学模型为声韵母时识别率不管是在训练集还是在测试集要高于识别单元是音节的HMM 模型。
(2)对于训练集来说,HMM 中高斯混合分量个数为4、5 和6 识别率比较高。而对于测试集,高斯混合分量个数为1 或2 时,识别率较高。
3.2 26维的MFCC特征参数训练模型
特征参数MFCC 为26 维,声学模型分别为音节和声韵母,按表1 所示设定音节、声母和韵母的状态个数分别为6、3 和6,不同高斯分量个数的情况下对语料库中训练集和测试集分别进行了识别,识别结果如表5所示。

表5 26 维MFCC 特征训练模型的识别率
从表5 的识别结果可知:
(1)声学模型为音节时,训练集的识别率在对应不同高斯分量个数上几乎是高于测试集,在高斯混合分量为7 时,测试集的识别率高于训练集。训练集在高斯混合分量个数为4、5 和6 时识别率较高,最高识别率为89.00%,而测试集在高斯混合分量个数也是4、5和6 时识别率较高,最高识别率为85.00%。
(2)声学模型为声韵母时,训练集的识别率在对应不同高斯分量个数上全高于测试集。训练集在高斯混合分量个数也是为4、5 和6 时识别率较高,最高识别率为92.39%,对应的高斯混合分量个数为5,而测试集在高斯混合分量个数为4、5 和7 时识别率较高,最高识别率达到85.22%,对应高斯混合分量个数为5。
(3)声韵母为识别单元时整体上比以音节为识别单元的识别率高。
3.3 39维的MFCC特征参数训练模型
与提取的13 和26 维的MFCC 特征参数类似,39维MFCC 语音特征参数训练的HMM,声学模型分别为音节和声韵母,按表1 所示设定音节、声母和韵母的状态个数分别为6、3 和6,不同高斯分量个数的情况下对语料库中训练集和测试集分别进行了识别,识别结果如表6 所示。
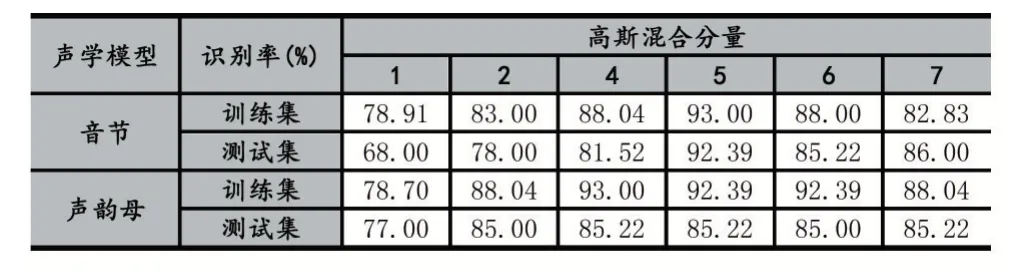
表6 39 维MFCC 特征训练模型的识别率
从表6 的识别结果可知:
(1)声学模型为音节时,训练集的识别率在对应不同高斯分量个数上几乎是高于测试集,只有高斯混合分量个数为7 时,测试集的识别率高于训练集。训练集在高斯混合分量个数为4、5 和6 时识别率较高,最高识别率达到93.00%,而测试集在高斯混合分量个数为5、6 和7 时识别率较高,最高识别率达到92.39%。
(2)声学模型为声韵母时,训练集的识别率在对应不同高斯分量个数上全高于测试集。训练集在高斯混合分量个数也是为4、5 和6 时识别率较高,最高识别率为93.00%,对应的高斯混合分量个数为4,而测试集在高斯混合分量个数为4、5 和7 时识别率较高,最高识别率达到85.22%,对应高斯混合分量个数为4、5或7。
(3)声学模型为声韵母的识别率在训练集或测试集上高于以音节为识别单元。
4 结语
本文结合隐马尔可夫模型原理,利用HTK 语音工具,搭建了汉语离散数字语音识别系统,探索多参数融合优化的HMM 模型。由实验结果得到的表3、表4、表5 和表6 的识别结果得到:
(1)声学模型的选择:声韵母作为识别单元比音节的识别效果要好。
(2)高斯混合分量个数:一般选择4 个或5 个或6个,个数过高或过低模型都不是最优的。
(3)MFCC 特征维度:39 维的MFCC 语音特征参数比13 维和26 维MFCC 特征参数识别率高。
(4)声学模型为声韵母时训练集和测试集识别率的差异大于声学模型为音节时训练集和测试集识别率的差异,避免过拟合。
由上述可以看出,以声韵母为基本语音识别单元,特征参数为39 维的MFCC,高斯混合分量为4 或5 或6 时,可以获得较高的识别率,对以后搭建基于HMM性能更优的离散或连续语音识别系统具有借鉴意义,也为研究基于深度学习的语音识别打下基础。
猜你喜欢
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52
今日农业(2022年16期)2022-11-09 23:18:44
计算机工程(2020年3期)2020-03-19 12:24:50
作文周刊·小学一年级版(2019年28期)2019-09-07 03:42:03
小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
中国交通信息化(2016年2期)2016-06-06 07:28:02
四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:36
当代修辞学(2011年4期)2011-01-23 06:41:00
