
基于注意力双向循环神经网络的业务流程剩余时间预测方法
2020-08-06 06:18倪维健孙宇健曾庆田
计算机集成制造系统 2020年6期
倪维健,孙宇健,刘 彤,曾庆田,刘 聪
(山东科技大学 计算机科学与工程学院,山东 青岛 266510)
0 引言
预测型流程监控[1](predictive process monitoring)是近年来业务流程管理领域中涌现出的一个新的热点研究话题,其目标是对正在执行中的业务流程实例进行预测型分析,预判当前实例未来可能的执行状态,比如下一个将要执行的活动、实例最终执行结果、实例剩余执行时间等。相比于传统的基于仪表盘和报表的传统流程监控方法,预测型流程监控不仅能够实时监测业务流程实例的执行状态,还能对其未来可能的执行结果进行智能预测,从而为必要的人工干预提供决策依据,有助于避免业务流程实例继续执行可能带来的诸如执行超时、资源冲突等不良后果。
业务流程剩余时间预测[1-2]是一类重要的预测型流程监控任务,其目标是预测正在执行的业务流程实例的剩余执行时间。剩余时间预测在业务系统性能优化等方面具有重要作用,以医院就诊流程为例,如果能够准确预测病人的就诊时间,则能够有效提升病人就诊体验,同时也可以为医院诊疗流程优化提供决策依据。传统的剩余时间预测研究主要通过从历史业务流程执行日志中挖掘变迁系统[1,3]、随机Petri网[4]、流程树[5]等形式化的流程模型,然后依据流程模型进行剩余时间预测。近年来,很多研究者将机器学习技术应用于剩余时间预测任务,并取得了不错的预测效果。Dumas等[6]提出了基于长短期记忆(Long-Short Term Memory, LSTM)循环神经网络的剩余时间预测方法,击败了已有的基于流程模型和机器学习的方法,取得了最优的预测效果[7],这一研究表明深度学习技术在剩余时间预测任务中具有广阔的应用前景。
然而,基于深度学习的剩余时间预测研究才刚刚起步,还有很多问题没有得到很好的解决,具体问题如下:
(1)现有研究主要集中于基于经典的LSTM网络构建剩余时间预测模型[7-8],而在自然语言处理等领域的研究表明LSTM网络对序列数据的建模能力有限,如何应用更先进的深度学习方法进一步提升剩余时间预测效果,是一项亟待研究的课题。
(2)现有研究在应用LSTM网络等深度学习方法时,仅将流程实例看作一种序列数据,在一定程度上忽略了剩余时间预测任务自身的特点。事实上,不同长度的流程实例之间具有很大差异[9],如对于一个刚开始执行不久的流程实例和一个即将执行结束的流程实例而言,预测剩余时间所考虑的因素应不同;此外,训练数据中不同长度的流程实例在数量上也有很大区别,通常短实例数量远多于长实例数量,简单地将所有流程实例混合在一起训练剩余时间预测模型容易被数量更多的短实例影响,进而降低预测效果。
针对上述问题,本文提出一种新的基于深度学习的剩余时间预测方法。该方法使用注意力双向循环神经网络,并分别尝试LSTM和门控循环单元(Gated Recurrent Unit, GRU)作为循环神经网络的神经元实现。相比于传统的LSTM网络,这种网络模型考虑了序列数据的双向信息,同时使用注意力机制自动学习流程实例中不同事件的权重,提升重要事件对预测结果的影响,并排除无关事件的干扰,从而可以更好地对流程实例进行建模。此外,本文采用迁移学习方式,为不同长度的流程实例分别构建剩余时间预测模型,以提高模型的针对性。为了克服不同长度的流程实例的数量差异,并有效利用不同长度实例前缀之间的相关性,首先在数量较多的短流程实例上训练模型,然后将短实例模型参数作为长实例模型的初始值,通过Fine-tuning的方式实现长实例模型的高效训练。最后,本文在5个公开事件日志数据集上开展了实验,实验结果表明本文方法显著优于传统的模型驱动和数据驱动方法。
1 相关工作
依据是否依赖于业务流程模型,剩余时间预测的相关研究可以在整体上分为模型驱动的方法、数据驱动的方法和模型与数据相结合的方法3类。
模型驱动的方法依赖于从日志中挖掘得到或从领域专家事先制定的业务流程模型中进行剩余时间预测,代表性的工作有:van der Aalst等[1]提出了基于变迁系统的剩余时间预测方法,该方法首先从事件日志中挖掘变迁系统模型,用以记录流程实例的所有可能状态,然后在变迁系统模型中的每个状态上标记时间信息,进而根据正在执行的流程实例的当前状态预测其可能的剩余执行时间;Rogge-Solti等[4]从事件日志中挖掘随机Petri网,在其上模拟正在执行的流程实例,根据模拟结果预测剩余执行时间;Jimenez-Ramirez等[10]利用声明式模型解决多实例、资源约束等复杂场景下的剩余时间预测问题;Senderovich等[11]利用队列模型解决多个服务流程处于排队状态时的剩余时间预测问题。
数据驱动的方法应用机器学习技术直接从历史事件日志中挖掘剩余时间预测模型。这类工作采用的基本方法是首先使用聚类技术对历史流程实例进行划分,每个划分代表流程的一类变种,然后应用回归技术在每个划分上构建剩余时间预测模型[6]。对于聚类、回归等机器学习方法而言,设计有效的实例特征是影响模型效果的重要因素,Folino等[12]针对剩余时间预测任务中的特征设计问题开展了研究。由于流程实例剩余时间相关的因素众多,且流程实例是一种序列数据,需要设计序列编码方案构建流程实例的特征向量[9],该过程通常需依赖专家经验人工实现。近年来,研究者应用LSTM网络构建剩余时间预测模型,在真实数据上取得了很好的预测效果[7-8]。基于深度学习的剩余时间预测方法的一个优势是能够自动学习流程实例的特征表示,避免了传统机器学习方法所需的特征工程带来的大量繁琐的任务量。
模型与数据相结合的方法,其主要思想是利用机器学习技术强化业务流程模型,提升时间预测的准确性。这类方法能够克服单纯依赖模型或数据的方法的一些不足,是近期剩余时间预测研究的一个热点。这类工作的代表有:Polato等[13]提出了数据感知的变迁系统,为每个状态构建朴素贝叶斯分类模型,并为每个变迁构造支持向量回归模型进行剩余时间预测;Verenich等[14]使用流程树作为对业务流程的抽象形式,在流程树的活动节点和网关节点上分别训练回归模型和分类模型用于剩余时间预测。
2 基本概念
下面给出剩余时间预测任务相关的基本概念,主要涉及到业务流程管理领域中的事件、轨迹、轨迹前缀、流程实例、事件日志,定义如下。
定义1事件。事件是业务系统中某个活动的一次执行实例,可以表示为元组e=(a,cid,start,end,p1,…,pm)。其中,a∈是该事件中执行的活动,cid∈+是该事件所属的流程实例ID,start∈+和end∈+分别是该事件执行的开始时间和结束时间(start 定义2轨迹。轨迹是事件的有限非空序列σ=e1,…,e|σ|,且对于∀1≤i 定义3轨迹前缀。轨迹前缀σ(k)是轨迹σ中的前k个事件,即σ(k)=e1,…,ek(1≤k≤|σ|)。对于轨迹前缀σ(k),轨迹σ的剩余时间为remain(σ,k)=e|σ|.end-ek.end。 定义4流程实例。流程实例是整个业务流程的一次完整执行,可以表示为元组c=(cid,σ,p1,…,pn)。其中:cid∈+是该流程实例的ID,σ∈E*是该流程实例内的轨迹,对于∀1≤i≤|σ|,σ(i).cid=cid,其中σ(i)表示轨迹σ中的第i个事件。通常,σ(1)为该流程实例的开始事件,σ(|σ|)为该流程实例的结束事件。p1∈1,…,pn∈n是该流程实例的属性,如流程实例的执行者、执行代价等。 本文仅依据流程实例的轨迹信息预测剩余时间,流程实例的属性信息将放在后续工作中进一步考虑,故在后文中无歧义的情况下使用轨迹σ指代其所属的流程实例c。 定义5事件日志。事件日志是流程实例的集合,记录了业务系统的历史执行情况,可以表示为L={σ1,…,σ|L|}。 基于前述基本概念和符号表示,本章给出业务流程剩余时间预测任务的描述。在机器学习框架下,业务剩余时间预测任务的目标是利用事件日志中记录的历史流程实例数据训练剩余时间预测模型f:ε*→+,其能够为正在执行的流程实例(即轨迹前缀)预测剩余执行时间。进一步地,剩余时间预测模型训练可以被分解为训练集生成和模型学习两个阶段。 训练集生成阶段的目标是将事件日志转换为机器学习算法可以使用的训练数据。本文采用基于轨迹前缀长度的方式构建训练集,具体步骤如算法1所示。该算法的基本思想是对于事件日志中每条历史轨迹σ(行3),在指定的长度范围[lmin,lmax]内对之进行截取,得到各种不同长度轨迹前缀σl以及其对应的剩余时间remain(σ,l),以之作为训练数据集Dl中的训练样本(行4~6),最后返回所有长度的训练数据集。 算法1TrainDataGenerating。 输入:事件日志L,最小前缀长度lmin,最大前缀长度lmax; 输出:训练数据集D={(x,y)}。 1: For(l=lmin;l≤lmax;l++) 2: Dl←∅ 3: Foreach(σ∈L) 4: For(l=lmin;l≤lmax;l++) 5: If(l<|σ|) 6: Dl←Dl∪{(σl,remain(σ,l))} 7: Return Dlmin∪…∪Dlmax 模型学习阶段的目标是基于生成的训练集学习剩余时间预测模型f。该阶段可以被抽象为一个回归预测问题,其数学形式为: 该优化问题中的第一项为训练集上的预测误差,使用均方误差计算;第二项为模型正则项,用以克服学习过程中的过拟合问题。 本章将详细介绍所提出的业务流程剩余时间预测方法,首先简要介绍传统的循环神经网络(Recurrent Neural Networks, RNN),然后给出本文使用的注意力双向循环神经网络模型,最后给出基于迁移学习的模型训练方法。 RNN是一类用于处理序列数据的深度神经网络模型,其基本特点是每个神经元在t时刻的输出会作为t+1时刻输入的一部分,可以实现对变长序列数据的建模,基本网络结构如图1所示。RNN神经元的基本功能是接收向量化表示的序列中当前时刻的信息xt∈d以及上一时刻的输出ht-1∈k作为输入,对其进行非线性变化后得到输出ht∈k。神经元的输出可以被认为是对当前时刻之前的子序列的编码。RNN神经元有多种具体实现方式,最具代表性的是LSTM和GRU[15],它们较为有效地解决了传统RNN所存在的梯度消失、短时记忆等问题。Chung等[16]在多个序列建模任务上对LSTM和GRU等循环神经网络进行了实验对比,结果表明GRU可以取得与LSTM相当或更好的效果,同时在训练时间上具有明显优势。 传统RNN是一种单向结构,即当前时刻的输出向量仅由当前时刻的输入和上一时刻的输出决定。此外,传统RNN采用相同的方式处理序列中的每个位置,没有对每个位置的重要程度进行区分。因此,传统RNN对序列数据的建模能力较为有限。为此,本文使用含有注意力机制的双向循环神经网络(Bi-directional Recurrent Neural Networks with Attention, Att-Bi-RNN)构建剩余时间预测模型。该模型在两个方面对传统RNN进行扩展:首先,采用双向结构对输入的轨迹前缀进行建模;其次,使用注意力机制自动学习轨迹前缀中每个事件的权重。 Att-Bi-RNN模型网络结构如图2所示,该模型主要包含如下关键模块: (1)事件表示 该模型以轨迹前缀σ(k)=e1,…,ek作为输入,将其中各个事件et(1≤t≤k)表示为事件向量xt。考虑到一个事件由活动、执行时间以及其他属性构成,对于活动等离散属性,本文采用独热编码的方式表示为0/1向量;对于时间等连续属性,首先进行离散化处理,然后采用与离散属性相同的方式进行编码表示。最后,事件向量由活动向量与执行时间向量拼接得到。在本文实验中,事件向量作为模型参数的一部分,在训练过程中进行自动更新。 (2)基于双向RNN的上下文编码 (3)基于注意力机制的轨迹编码 得到轨迹前缀每个时刻的上下文编码后,进一步计算整个轨迹的编码,具体计算方式如下: (1) 式中αt为第t时刻上下文编码的权重,在一定程度上反映了轨迹中第t个事件对剩余时间预测的重要程度。本文采用两层感知机网络(称为AttentionNet)计算上下文权重,即 (2) 其中Watt、batt、gatt是注意力机制的模型参数。 (4)剩余时间预测 根据轨迹编码,使用全连接网络构建剩余时间预测模型,具体计算方式为 remain_time(σ(k))=gT·ReLU(W·v+b)。 式中W、b、g是全连接网络的模型参数。本文使用线性整流函数(Rectified Linear Unit,ReLU)作为激活函数。 区别于训练一个统一的剩余时间预测模型,本文为不同长度的轨迹前缀分别训练剩余时间预测模型,以更好地处理轨迹前缀在长度上的差异性,提升模型的针对性。然而,为不同长度的轨迹前缀单独训练深度神经网络模型往往存在很多现实挑战。根据算法1所示的训练集生成方式,可以发现:首先,单一长度轨迹前缀训练集Dl的规模相对于整体训练集D的规模要小很多,这一现象在较长长度的轨迹前缀训练集上将更为明显,而训练深度神经网络模型通常需要较大规模的训练数据,单独训练模型将降低剩余时间预测模型的准确性;其次,不同长度轨迹前缀之间具有蕴含关系,即长前缀中包含了短前缀,这意味着不同长度的轨迹前缀模型之间具有内在关联,单独训练模型将无法有效利用轨迹前缀之间的关联关系。 针对上述问题,本文基于迁移学习的思想为不同长度的轨迹前缀训练剩余时间预测模型,模型训练方法如算法2所示。该算法的基本思想是首先从最短长度的轨迹前缀上训练Att-Bi-RNN模型(行1),然后对于每个前缀长度迭代训练Att-Bi-RNN模型(行3~5),其中在训练前缀长度为l的模型时,以前缀长度为l-1的模型的参数作为其模型初始值,通过Fine-tuning的方式利用对应训练数据集Dl进行模型训练(行4)。该过程重复进行直到收敛,收敛条件包括各个模型的预测效果达到稳定等。算法2中的RNNTraining表示在指定数据集(第一个参数)和模型参数初始值(第二个参数,∅表示随机初始化)条件下训练Att-Bi-RNN模型。 算法2ModelTraining。 输入:训练数据集D=Dlmin∪Dlmin+1∪…∪Dlmax; 输出:剩余时间预测模型{flmin,flmin+1,…,flmax}。 1: flmin←RNNTraining(Dlmin,∅) 2: While not converged 3: For(l=lmin+1;l≤lmax;l++) 4: fl←RNNTraining(Dl,fl-1) 5: flmin←RNNTraining(Dlmin,flmax) 6: Return{flmin,flmin+1,…,flmax} 算法2所示的基于迁移学习的模型训练方法的优势是在为特定长度轨迹前缀训练剩余时间预测模型时有效利用了其他长度的模型信息,因此能够克服特定长度轨迹前缀训练数据不足的问题,且通过合理初始化模型参数加快了深度神经网络模型的训练收敛速度。 本章将详细介绍针对业务流程剩余时间预测任务的实验研究,首先分别介绍本实验中使用的数据集和模型评价指标,然后将本文方法与传统方法进行对比,并对本文方法的各个模块的效果进行实验分析。 本实验使用5个公开事件日志数据集BPIC_2012_A、BPIC_2012_W、BPIC_2012_O、Helpdesk、Hospital_Billing,它们均可以在4TU Center for Research Data(https://data.4tu.nl/repository/collection:event_logs_real)下载。这5个数据集来自不同领域,BPIC_2012_A/W/O记录了某财政机构贷款申请审批日志,Helpdesk记录了某票务管理系统的后台日志,Hospital_Billing记录了某医院ERP系统中的出院结算流程日志,统计信息如表1所示。 表1 数据集基本统计信息 进一步,对这5个事件日志生成的训练集进行统计,如图3所示为原始事件日志与对应训练集中不同长度轨迹(前缀)的数量随长度的变化曲线,其中实线为原始事件日志统计曲线,虚线为生成的训练集的统计曲线。可以发现,各个事件日志中的轨迹数量随着长度基本呈下降趋势,特别是长度较长的轨迹数量非常稀少,从而生成的训练集中的轨迹前缀也随着长度的增加,数量呈急剧下降趋势。这些统计结果印证了特定长度特别是较长长度轨迹前缀数量的稀疏性,进而有必要采用迁移学习方式进行模型训练。 本实验使用平均绝对误差(Mean Absolute Error, MAE)作为剩余时间预测模型的评价指标,计算方式如下: 式中:D为测试数据集,f(σ(k))为对某长度为k的轨迹前缀剩余时间的预测值,remain(σ,k)为该轨迹前缀剩余时间的真实值。MAE值越低,则剩余时间预测的准确性越高。 本实验采用5折交叉验证的评估方式,即将数据集随机分成5等份,每次选择4份作为训练数据,1份作为测试数据,重复5次实验,各次实验MAE值的平均值作为最终评价结果。 本实验将本文方法与经典的基于流程模型的方法和基于深度学习的方法进行对比,所选择的基准方法具体如下: (1)van der Aalst等提出的基于变迁系统的方法[1],实验中分别使用集合、多重集和序列对变迁系统的状态进行抽象表示,简称为TS-set、TS-multiset和TS-sequece,该方法使用ProM 5.2实现。 (2)Rogge-Solti等提出的基于随机Petri网的方法[4],简称为SPN,该方法使用ProM 6.8实现。 (3)Tax等提出的基于LSTM深度神经网络的方法[7],简称为LSTM,该方法使用PyTorch 1.1实现。 笔者对LSTM和本文方法进行了基本调参,输入事件向量维度范围为{3,5,7,10},神经元隐向量维度范围为{3,5,7,10},学习率范围为{0.01,0.1},迭代轮数为150轮,优化算法为Adam。本文方法中使用GRU作为RNN的基本实现。 本文方法与基准方法在各个数据集上的MAE评测结果如表2所示。根据表2可以得到如下结论: 表2 基准方法效果对比 (1)基于深度学习的方法(LSTM和本文方法)在各个数据集上均优于传统的基于变迁系统和随机Petri网的方法,这说明深度学习方法在剩余时间预测任务中具有较大优势。其原因主要是真实事件日志往往具有海量、高噪音的特点,业务流程的实际运行往往并不符合预设的业务规范,从而使得变迁系统、Petri网等传统的形式化较强的业务流程模型难以有效建模整个事件日志,而循环神经网络使用隐向量记录业务流程实例的运行状态,具有更大的建模空间,辅以海量数据及高效的学习算法,往往能取得较好的预测效果。 (2)本文方法在各个数据集上均优于现有的深度学习方法LSTM,MAE值平均下降了约9%,从而验证了本文提出的Att-Bi-RNN模型和基于迁移学习的模型训练方法的优越性。另外,本文方法在Hospital_Billing数据集上取得了最大程度的提升(MAE值下降了约23%)。由表1可以发现,Hospital_Billing数据集在轨迹数量、事件数量、活动数量上均具有更大的规模,这说明本文方法在大规模事件日志上具有更强的适用性。 下面对本文方法中各个模块的具体效果进行分析。首先移除本文方法采用的迁移学习训练方法,使用传统方式为所有长度轨迹前缀训练一个统一模型。然后在训练过程中,分别移除Att-Bi-RNN模型中的双向模块和注意力模块,并分别尝试使用LSTM和GRU作为RNN的具体实现,由此设计了如表3所示的各种方法。 表3 模块效果分析对比方法 图4展示了以上方法在各个数据集上的MAE值。根据图4可以得到如下结论: 首先,引入双向模块后,Bi-LSTM相比于传统LSTM、Bi-GRU相比于传统GRU,分别在5个数据集中的3个和4个上取得了更低的MAE值;引入注意力模块后,Att-Bi-LSTM相比于Bi-LSTM在5个数据集上全部取得了更低的MAE值,Att-Bi-GRU相比于Bi-GRU在5个数据集中的4个上取得了更低的MAE值。因此,整体上而言,引入双向机制和注意力机制均可以提升RNN在剩余时间预测任务上的效果,特别是注意力机制对预测效果的提升具有更大的帮助。 其次,对比Trans-Att-Bi-LSTM与Att-Bi-LSTM、Trans-Att-Bi-GRU与Att-Bi-GRU,迁移学习模型训练方法在除Helpdesk外的数据集上均取得了比训练统一模型更低的MAE值,这说明使用迁移学习方法为不同长度轨迹前缀分别训练模型能够大大提升剩余时间预测的准确性。 再次,对比LSTM和GRU两个方法系列,GRU在5个数据集中的3个上取得了比LSTM更低的平均MAE值,这说明GRU在业务流程剩余时间预测任务上具有一定的优势,本文对GRU和LSTM两种RNN实现方法的尝试是有价值的。 本文基于深度学习技术开展业务流程实例剩余执行时间预测研究。相比于已有工作中使用传统LSTM网络训练单一剩余时间预测模型,本文使用更为先进的深度神经网络模型—注意力机制的双向循环神经网络对业务流程实例进行建模,此外使用迁移学习方法面向不同轨迹长度分别训练剩余时间预测模型,提升了剩余时间预测的针对性。最后,在5个真实事件日志数据上开展了实验研究,结果证明了本文方法能够显著降低剩余时间预测的MAE值。作为一种深度学习方法,本文方法虽然具有较高的预测准确率,但是可解释性较差,因此提升本文方法的可解释性是后续的一项重要研究工作。3 业务流程剩余时间预测任务描述
4 业务流程剩余时间预测方法
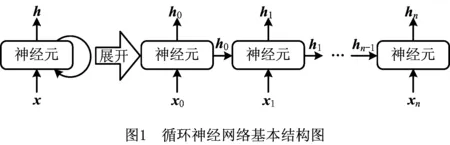
4.1 循环神经网络
4.2 注意力双向循环神经网络
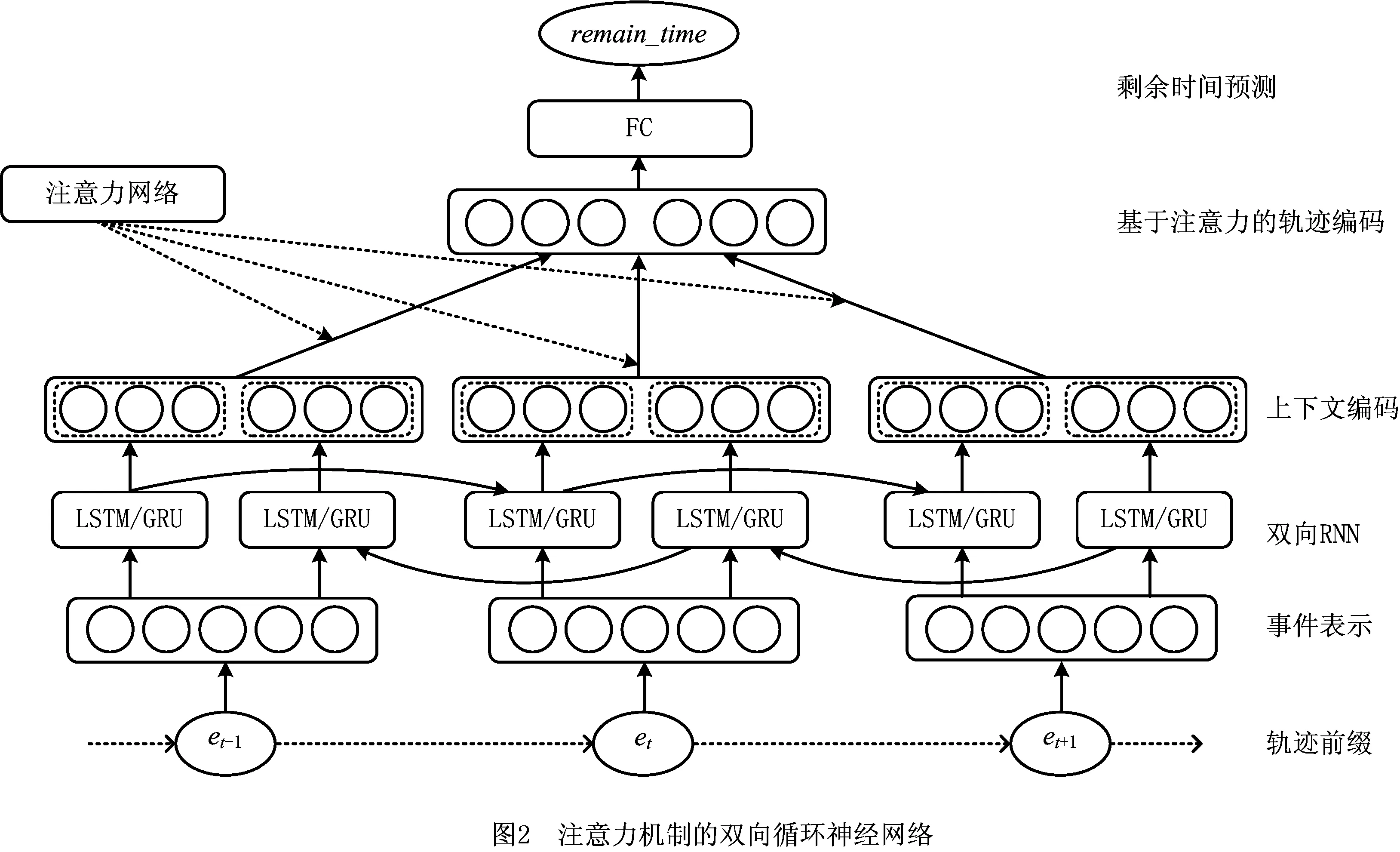
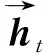
4.3 基于迁移学习的模型训练方法
5 实验研究
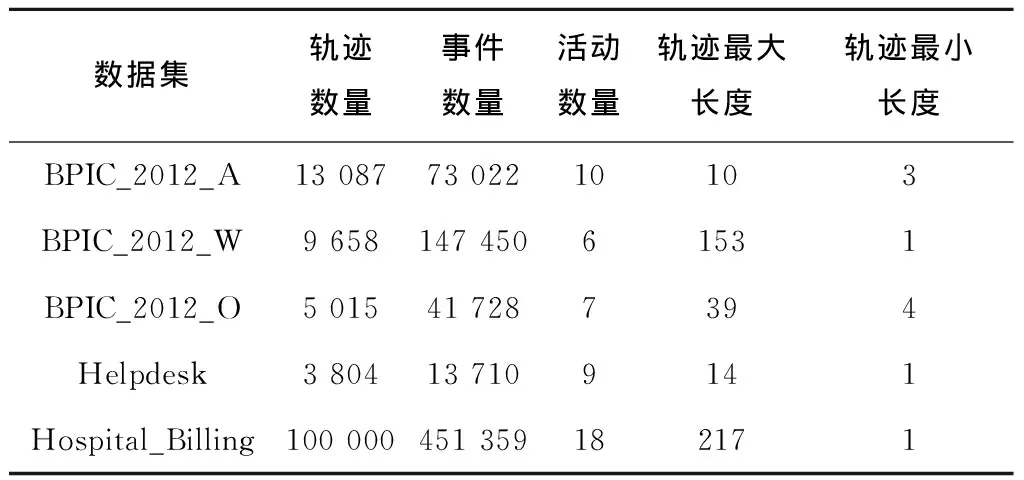
5.1 实验数据
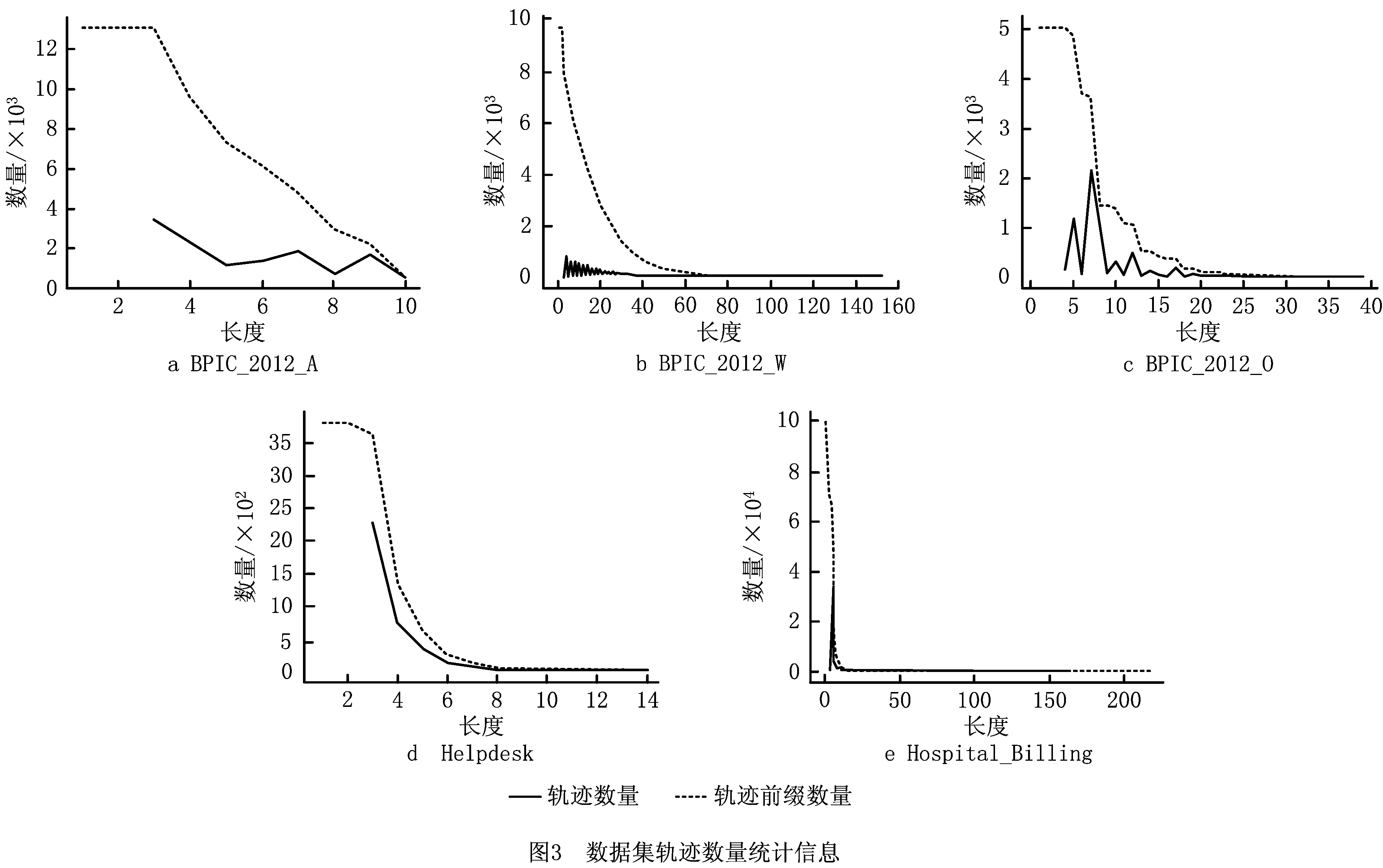
5.2 评价指标
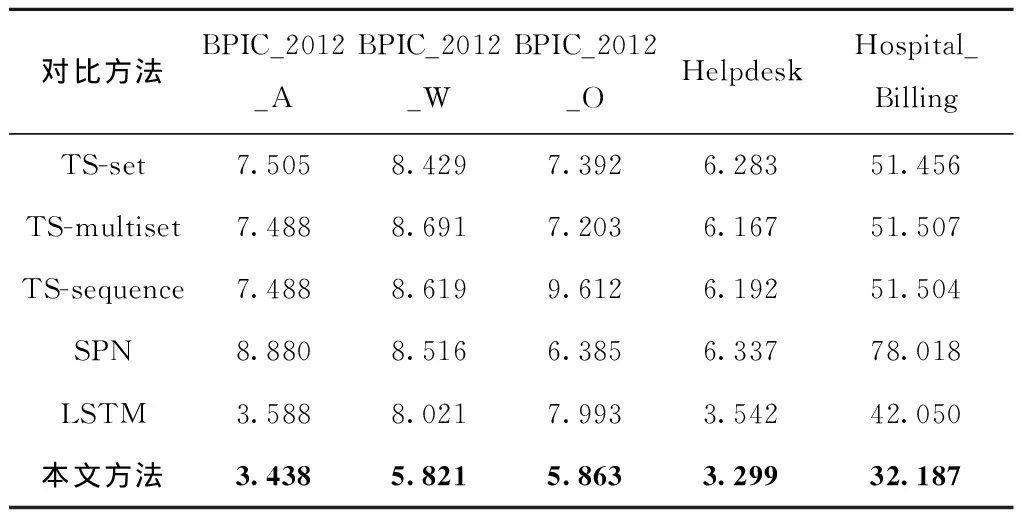
5.3 对比实验
5.4 各模块效果分析
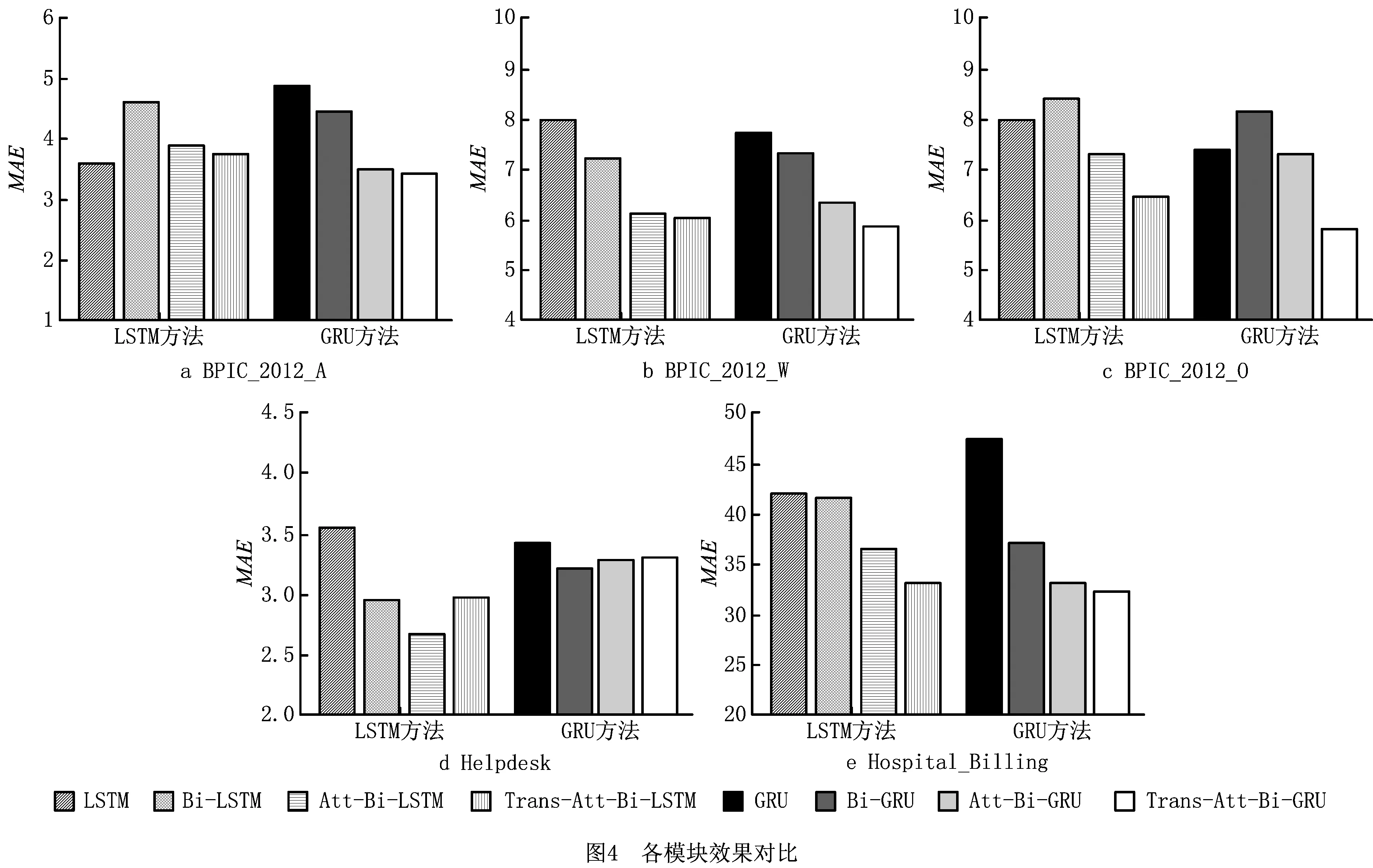
6 结束语
猜你喜欢
华人时刊(2021年13期)2021-11-27心声歌刊(2020年4期)2020-09-07读友·少年文学(清雅版)(2020年4期)2020-08-24读友·少年文学(清雅版)(2020年3期)2020-07-24思维与智慧·上半月(2018年9期)2018-09-22现代装饰(2018年5期)2018-05-26小学生(看图说画)(2017年6期)2017-11-06中国三峡(2017年2期)2017-06-09高中生学习·高三版(2014年3期)2014-04-29高中生学习·高三版(2014年3期)2014-04-29
