
基于二部网络表示学习的矩阵分解推荐算法
2020-08-06 06:18袁梦祥颜登程张以文
计算机集成制造系统 2020年6期
袁梦祥,颜登程,张以文,周 珊
(1.安徽大学 计算机科学与技术学院,安徽 合肥 230601;2.安徽大学 物质科学与信息技术研究院,安徽 合肥 230601;3.深圳易伙科技有限责任公司,广东 深圳 518000)
0 引言
随着互联网的不断发展,数据呈几何式增长,全球进入信息爆炸时代。如何帮助用户从海量信息中找到自己感兴趣的数据,满足人们的个性化需求,已成为学术界广泛关注的问题。推荐系统作为一种有效的信息过滤系统,是解决这一问题的重要工具[1]。通过对用户行为、项目属性和上下文等数据进行建模,推荐系统能够推断出用户的兴趣爱好,从而发掘用户的个性化需求,为企业带来可观的商业价值,近年来已在很多领域得到了应用[2-3]。
在个性化推荐领域,应用最为广泛的推荐算法是基于协同过滤[4-6]的推荐算法,通常划分为基于记忆(memory-based)的协同过滤方法和基于模型(model-based)的协同过滤方法两类。基于记忆的协同过滤直接使用整个已知的历史评分矩阵来预测用户对未知项目的评分,基于预测评分为用户进行推荐;基于模型的协同过滤使用机器学习的方法构建出用户与项目之间的关系模型,然后据此为用户生成合理的推荐。虽然现在很多工作都在研究基于协同过滤的推荐方法,但依然存在一些重要的问题,例如数据的稀疏性使得一些样本之间可能不存在同维度的数据,无法获取可度量的相似度,导致相似度计算不稳定。数据的高维度导致相似度计算复杂度高,容易受噪声数据影响。最近研究表明,相较于传统协同过滤算法中人工设计的相似度指标,使用网络表示学习的方法处理推荐系统中的相关信息,可以更有效地增强推荐系统的特征表示能力[7-8]。此外,推荐系统中天然存在着大量的网络结构,例如用户的评分信息、项目的标签信息都构成了二部网络。网络结构信息能为推荐算法提供丰富的输入,如何有效地利用网络结构数据是当前推荐系统研究的热点[9-10]。
在用户—项目二部网络中,虽然显式的连边关系只存在于不同类型的节点之间,但同一类型的节点之间存在隐式关系。例如,喜欢同一项目的两个用户之间就存在一种隐式的关系,这种关系表明用户之间存在相同的兴趣偏好。最近,文献[11]指出,对这种隐式关系进行建模可以提高推荐的性能。然而,现有大部分网络表示学习方法[12-14]仅对二部网络中节点的显式关系进行了建模,忽略了节点间潜在的隐式关系。为了能同时兼顾节点间的显式关系和隐式关系,笔者在学习节点表示时,同时对显式关系和隐式关系进行建模。此外,在考虑用户的历史行为信息的同时,引入外部标签信息以缓解冷启动问题[15]。本文综合考虑用户—项目二部网络中隐式关系和显式关系,并引入项目外部标签信息,主要贡献如下:
(1)针对用户—项目二部网络,使用二部网络表示学习的方法,学习用户的低维向量稠密表示,提高相似度计算结果的稳定性,降低相似度计算的复杂度。
(2)引入项目的标签信息构建项目—标签的二部网络,使用二部网络表示学习的方法,学习项目的低维向量稠密表示,从项目的内容角度来考虑项目之间的相似关系。
(3)将低维向量空间中用户与用户、项目与项目之间的相似关系融入传统矩阵分解算法,提出基于二部网络表示学习的矩阵分解推荐算法。
1 相关工作
1.1 矩阵分解模型
矩阵分解模型在NetflixPrize中大放异彩后,受到了学术界和工业界的广泛关注,催生出一系列基于矩阵分解的模型。传统的矩阵分解模型[16]基于用户的评分矩阵,将用户和项目都映射为一个低维隐式空间的向量,然后根据两者的点乘结果作为用户对项目的预测分数。Mnih[17]从概率论角度解释了传统矩阵分解模型的合理性,并提出概率矩阵分解模型。在Netflix竞赛期间,Koren等[18]将邻域信息集成到矩阵分解中,它假定用户对特定物品的评分不仅由用户和该物品的潜在特征决定,还由用户对其他相似物品的评价行为构成,即考虑物品之间的邻域信息。这种方法在许多领域的性能都优于传统的矩阵分解模型。Wu等[19]通过引入外部的标签信息获取用户和物品的相似性关系,将其融入概率矩阵分解模型中,提出基于近邻的概率矩阵分解模型。然而,现有的矩阵分解模型较少使用外部信息或者通过手工构造特征的方式使用外部信息,限制了外部信息的特征表达能力。
1.2 网络表示学习
近年来,网络表示学习逐渐成为机器学习中一个热门的研究方向。网络表示学习试图为网络中的每个节点学习到一个低维表示向量,并尽可能地保持其原有的结构信息[20]。DeepWalk[12]和Node2vec[13]算法使用随机游走方法将网络转换为节点序列的语料库,并基于Word2Vec[21]模型学习节点的低维向量表示。此外,一部分工作考虑网络的高阶结构特性,例如LINE[14]对节点中的一阶和二阶近邻关系进行建模。
但现有的网络表示学习方法主要针对同质网络[12-13],Gao等[20]指出这些方法应用于二部网络时忽略了二部网络的特殊性质,并提出二部网络表示学习算法(Bipartite Network Embedding, BiNE)[20]。BiNE同时考虑二部网络中不同类节点之间的显式关系和同类节点之间的隐式关系。通过联合优化这两个部分的目标函数来学习二部网络中节点的表示:
maximizeL=αlogO2+βlogO3-γO1。
(1)
式中:O1代表对二部网络中的显式关系进行建模的目标函数;O2和O3分别代表对二部网络中用户与用户之间、项目与项目之间隐式关系进行建模的目标函数;参数α,β,γ分别表示联合训练时各部分的比例。
最后,为了优化联合模型,使用随机梯度上升算法(Stochastic Gradient Ascent, SGA)对模型进行训练,获得网络中节点最终的低维向量表示。本文使用BiNE算法分别从用户—项目二部网络和项目—标签二部网络学习用户和项目的低维向量表示。
2 BiNRMF推荐算法
2.1 算法整体框架
本文结合二部网络表示学习算法和矩阵分解算法,利用两个异构信息源:项目的标签信息和用户的评分信息作为输入,通过训练模型预测用户对项目的评分。图1描述了算法的整体框架:首先,利用输入的信息分别构建用户行为和项目内容信息的二部网络。然后,使用二部网络表示学习的算法获得用户和项目的低维向量表示。最后,基于用户和项目的低维向量表示计算相似性,并融入矩阵分解模型,预测用户对项目的评分。
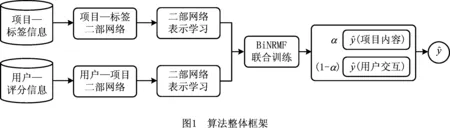
2.2 数据预处理
数据预处理的目的是从用户的评分行为和项目的内容信息中抽取用户—项目评分二部网络和项目—标签二部网络,并作为二部网络表示学习算法的输入。
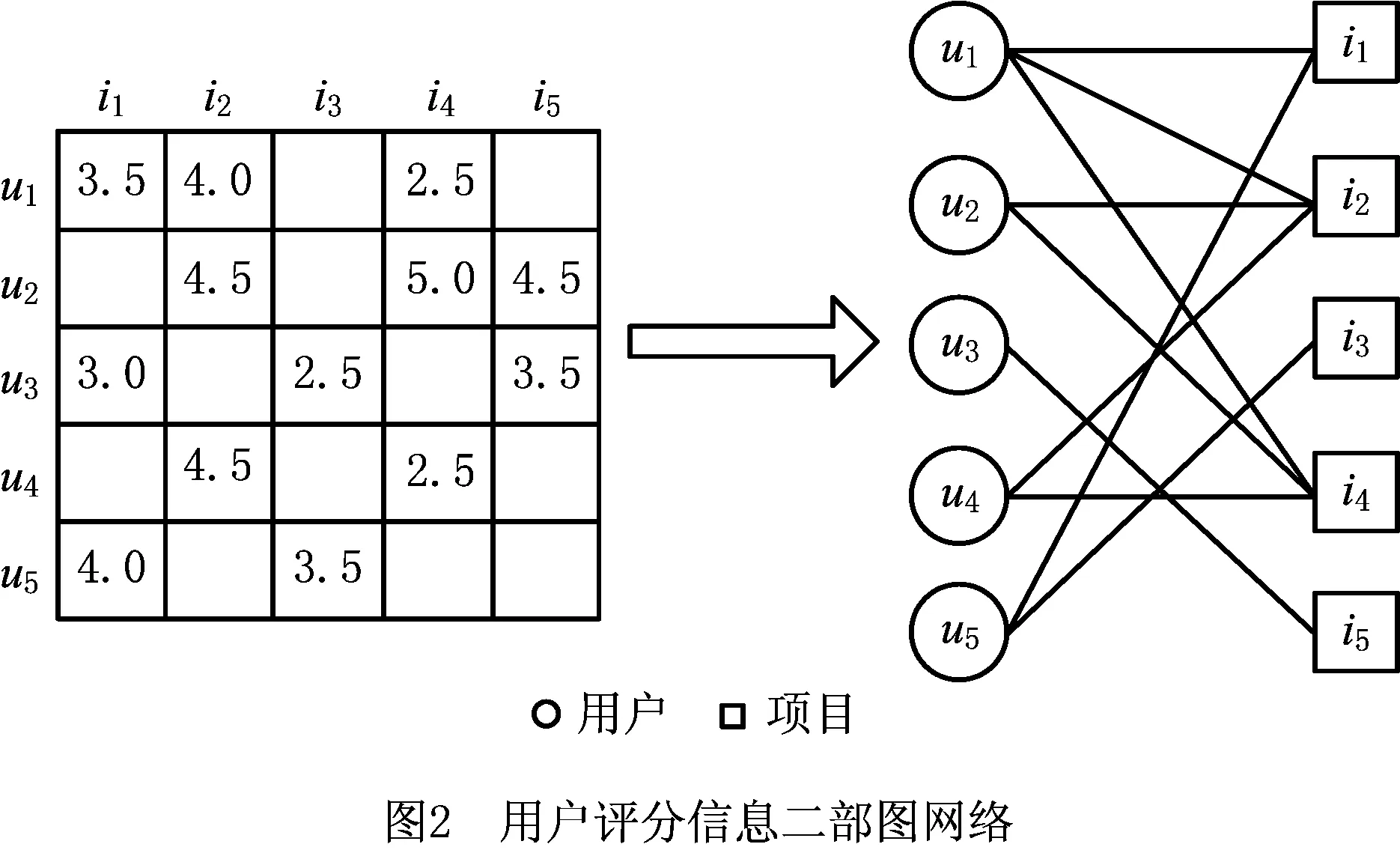
如图2所示,左图为用户的评分信息,转化为右图的用户—项目评分二部网络。节点之间的边代表用户对项目存在打分行为,边的权重代表对应的用户项目评分。
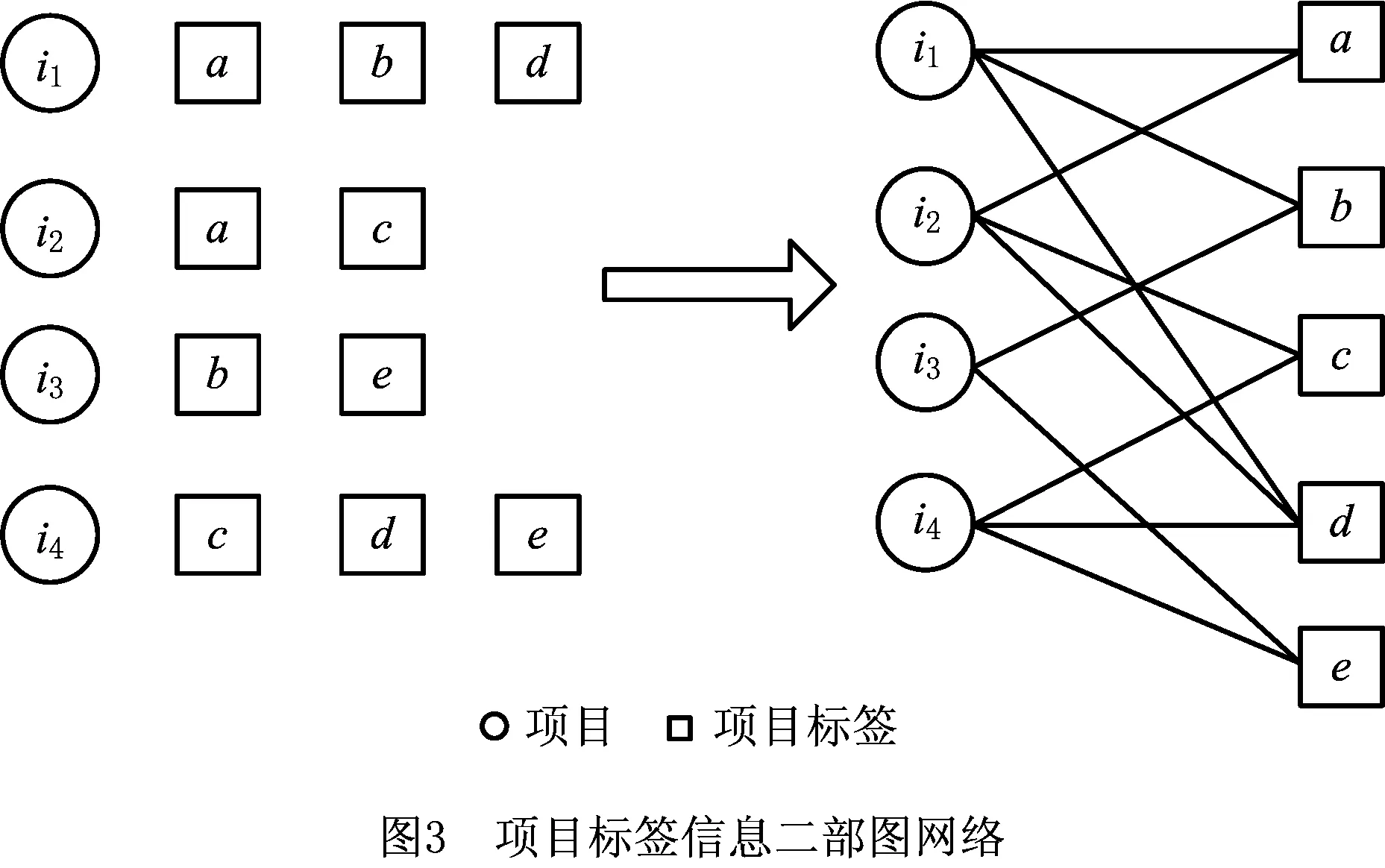
如图3所示,左图为项目的标签信息,节点之间的边代表对应项目被用户打上对应标签的次数。
最后,统一将二部网络的结构数据转化为二部网络表示学习算法所需要的格式,本文中数据的格式为:(节点A)(节点B)(边的权重)。
2.3 二部网络表示学习
获取到用户—项目二部网络和项目—标签二部网络的数据后,可将其应用到已有的二部网络表示学习算法。本文使用BiNE[20]算法分别对用户—项目二部网络和项目—标签二部网络进行表示学习,分别学习到用户和项目的低维向量表示。
本文使用的两个网络均为加权网络。具体来说,用户—项目评分二部网络反映了用户对项目的评分行为,其中连边的权重表示用户在对应项目上的评分;项目—标签二部网络反映了项目的内容信息,其中连边的权重表示标签在对应项目上被用户打上标记的次数。
2.4 获取节点的近邻集合
通过表示学习的算法获取到用户和项目的低维向量表示后,可以在对应的低维表示空间中考虑用户之间和项目之间的相似性。本文使用余弦相似度来度量低维空间中向量的相似度。在计算网络中各个节点之间的相似性后,根据相似度阈值θ定义与目标节点相似的近邻节点集合。例如,i用户的近邻节点集合定义为:
T(i)={k|cos(i,k)>θ,i≠k}。
(2)
节点之间的相似性信息将被用于正则化矩阵分解模型,而通过相似度阈值选取阈值范围内的近邻有助于减少相似度较低的节点对模型的干扰。
2.5 模型定义
矩阵分解是一种广泛采用的基于模型的协同过滤方法。传统的矩阵分解算法的目标函数如下:
(3)
该模型使用所有可以观测到的评分值来预测评分矩阵中的缺失值。然而,由于真实的评分矩阵非常稀疏,大多数情况下传统的矩阵分解不能生成最佳的预测值。因此,本文结合二部网络表示学习方法,提出了基于二部网络表示学习的矩阵分解推荐算法。建模用户之间的显式关系和隐式关系,并同时引入项目的外部内容信息,其目标函数定义为:
(4)
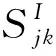
(5)
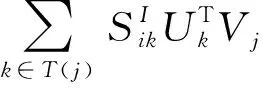
3 实验分析
3.1 实验设置
为了衡量本文提出的BiNRMF推荐算法的性能,本文使用MovieLens和GoodBooks两个数据集进行实验。MovieLens数据集被广泛用于电影推荐系统[22]。该数据集包含8万多条评分数,分别表示600多个用户对9 000多部电影的评分。类似地,GoodBooks数据集中包含书籍和评分的详细信息,该数据集包含5万多用户对1万本畅销书的12万多条评分数据。两个数据集中用户可以评5个不同等级(1~5分)。为了使数据集保持一致,使用与MovieLens数据集相同的方式过滤GoodBooks数据集,仅保留数据集中至少有过100次交互的用户。表1总结了实验数据集的统计信息。

表1 数据集的统计信息
3.2 评估指标
在实验中,选择每个用户评分数据的80%作为训练集,剩下的20%作为测试集,保证每个用户都拥有一定量的评分数据。本文选择绝对平均误差(MAE)和均方根误差(RMSE)两个指标衡量预测评分的准确性,分别定义如下:
(6)
(7)
3.3 性能评估
为评估所提出的BiNRMF方法的性能,选择以下经典推荐算法在MAE和RMSE两个指标上进行对比实验:
(1)User-CF:该方法是基于用户的协同过滤算法,基于相似用户的评分预测缺失值。
(2)Item-CF:该方法是基于项目的协同过滤算法,基于相似项目的评分预测缺失值。
(3)MF:该方法是传统的矩阵分解算法,使用训练数据训练模型,基于模型预测评分值。
(4)NIMF[23]:该方法是融合邻域信息的矩阵分解算法。
各个方法的参数设置如表2所示。

表2 算法重要参数
实验结果如表3所示。从表中可以看出,本文所提方法的MAE和RMSE明显小于其他方法。这表明通过使用二部图表示学习的方式,学到的用户和项目的低维向量表示可以有效提高矩阵分解模型的预测性能。
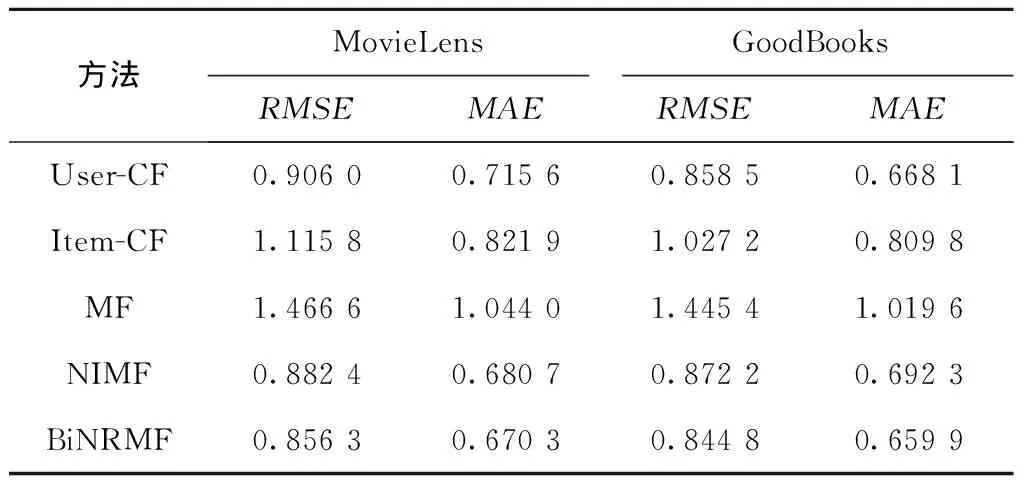
表3 性能对比
3.4 模型分析
(1)参数α对实验结果的影响
在本文的方法中,参数α表示基于相似项目和相似用户对预测评分进行修正的比例。为研究α对模型预测精度的影响,本文在MovieLens和GoodBooks数据集上,设置矩阵维度n=20,阈值θ=0,α的值从0.0~1.0以0.1的间隔递增,观察在两个数据集上MAE和RMSE的实验结果,如图4所示。
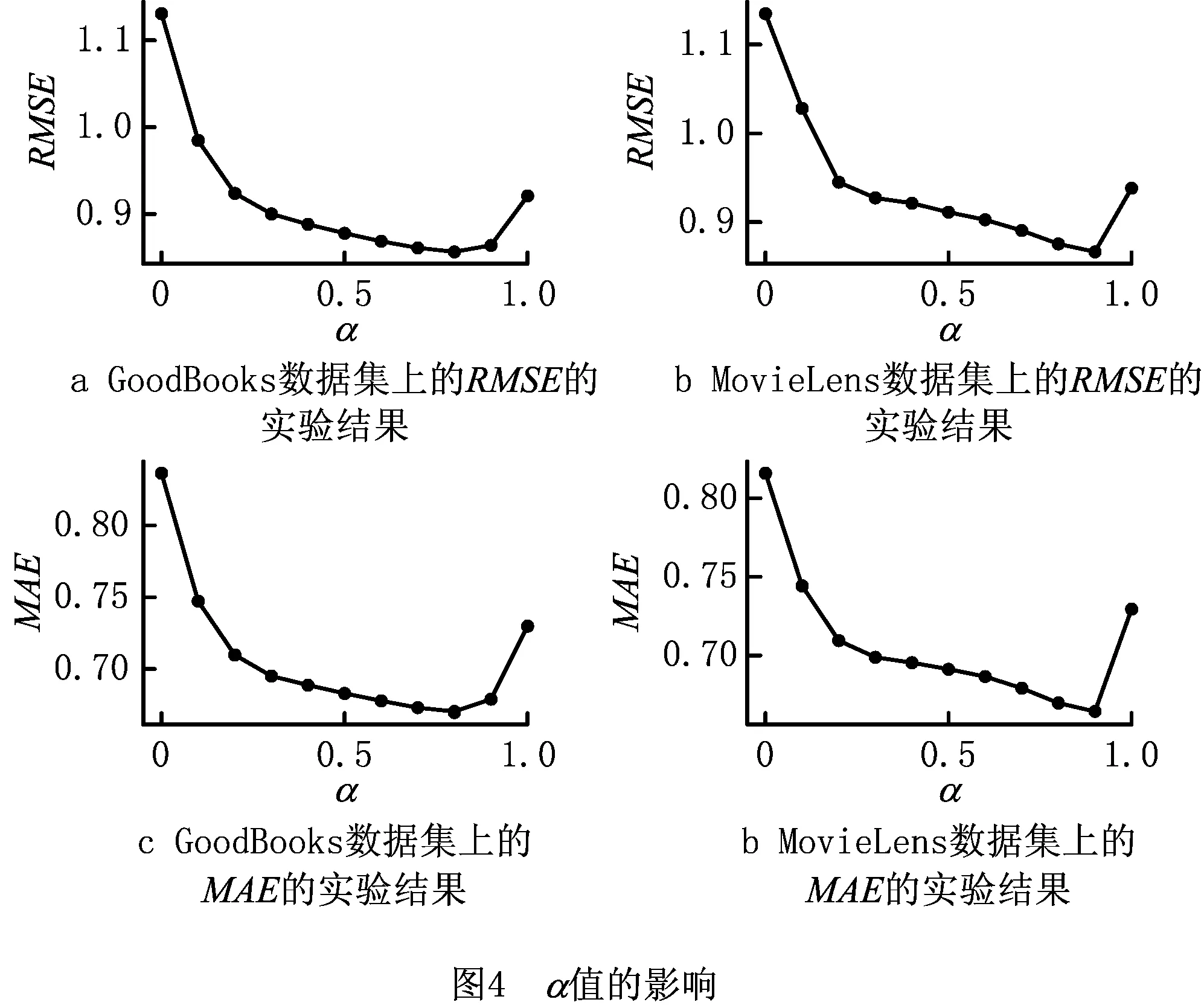
实验结果表明,选择一个合适的α值能够有效提高BiNRMF算法的预测精度。
图4a和图4c表明在GoodBooks数据集上α=0.8时模型的预测精度达到最优值;图4b和图4d表明在MovieLens数据集上α=0.9时模型的预测精度达到最优值。实验结果同时表明在不同的数据集上,达到最优预测精度时的α值是不一样的。从实验结果可以看出,对于GoodBooks数据集和MovieLens数据集,项目内容的相似关系比用户行为的相似关系对预测结果影响更大。
(2)阈值θ对实验结果的影响
参数θ决定节点近邻集合的大小、平衡噪声和有用信息的比例。为研究阈值对预测精度的影响,实验分别在GoodBooks和MovieLens两个数据集上进行。实验设置α在两个数据集上分别取0.2和0.9,矩阵维度n=20,设置θ值从0~0.9以0.1的间隔递增,分别观察用户和项目的阈值在两个数据集上MAE的实验结果,如图5所示。
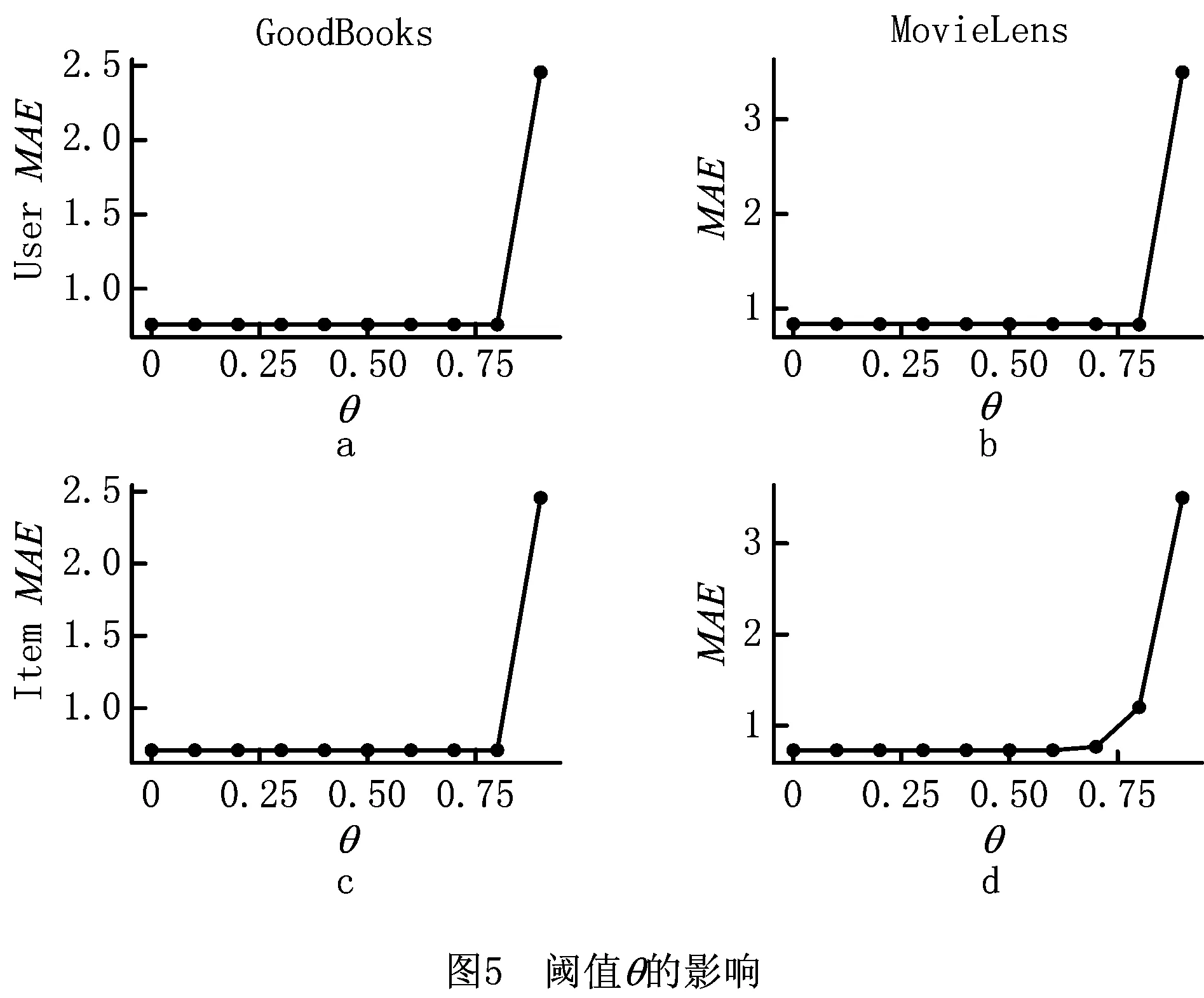
其中,图5a和图5b是α=0仅使用基于用户的方法进行预测时,用户的相似度阈值对MAE影响的实验结果。图5c和图5d是α=1仅使用基于项目的方法进行预测时,项目的相似度阈值对MAE影响的实验结果。从图5可以看出,本文模型对阈值的变化不敏感,模型具有很好的鲁棒性。
(3)矩阵维度n的影响
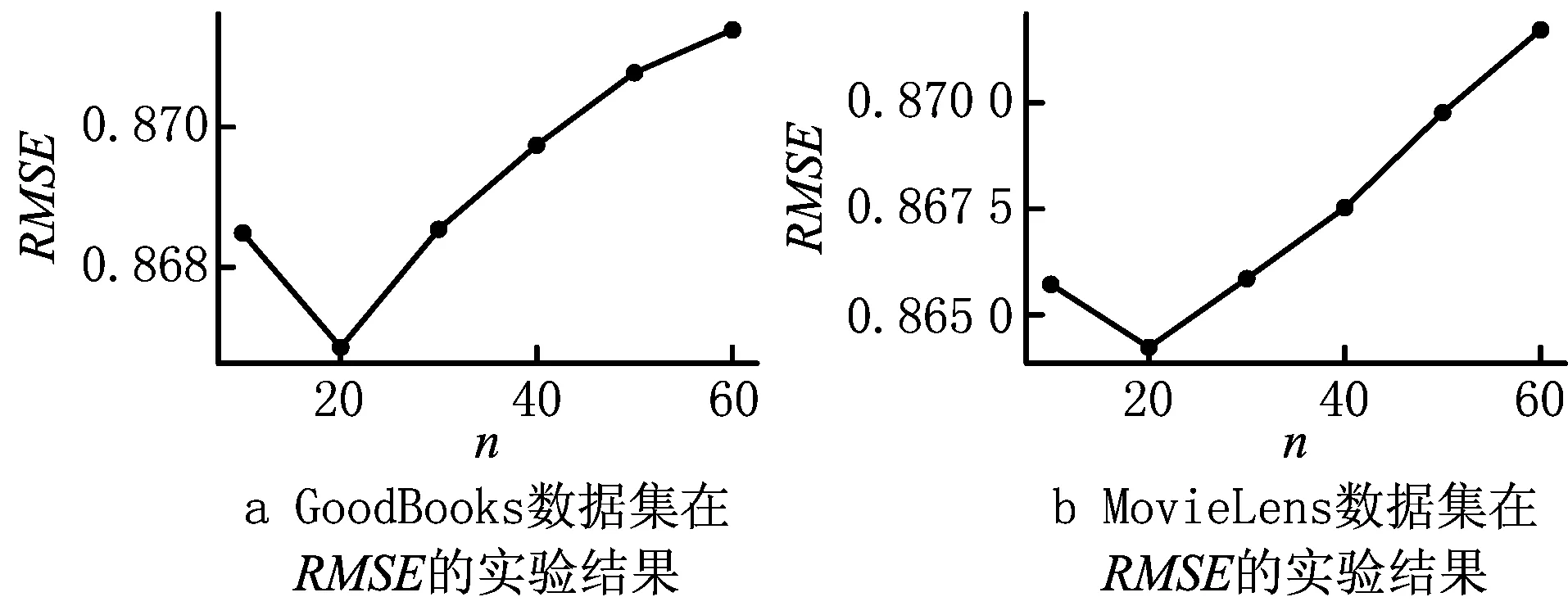
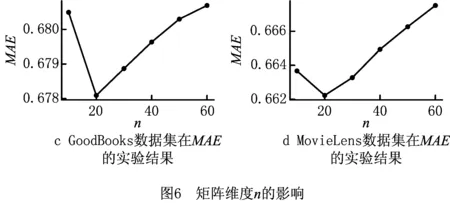
矩阵维度表示联合训练时矩阵的维度,影响最终的预测评分。为研究矩阵维度对预测精度的影响,实验分别在GoodBooks和MovieLens两个数据集上进行。实验设置α在两个数据集上分别取0.2和0.9,阈值θ=0,矩阵维度n的值从10~100,并以10的间隔递增,观察矩阵维度对算法预测精度的影响。实验结果如图6所示。
图6的实验结果表明,选择一个合适的矩阵维度可以有效提高BiNRMF方法的预测精度。由图6a和图6c可以看出,一开始,随着矩阵维度的增大,预测精度逐步提高,而当矩阵维度到达某个值后,随着矩阵维度的增大,预测精度开始降低;图6中的4个实验结果,都在矩阵维度n=20时,预测精度达到最优值。这表明矩阵维度过低时,隐藏向量空间对数据的刻画不够精细,导致预测精度下降,而维度过高时,可能会引入过多的噪声,同样会导致预测精度下降。因此,选择一个合适的矩阵维度n可以达到更好的预测精度。
4 结束语
本文提出一种基于二部网络表示学习的矩阵分解推荐算法BiNRMF。首先,根据用户评分历史信息和项目的标签信息,用二部网络表示算法BiNE分别对用户和项目进行表示;然后,在低维表示空间中获取用户和项目的近邻集合信息;最后,结合近邻集合信息和矩阵分解算法提出BiNRMF算法。在GoodBooks和MovieLens两个数据集的实验结果表明,与经典的协同过滤算法相比,该方法的预测精度明显提高。本文的工作假定融合协同过滤信息和项目内容信息所占的权重是固定的,但在实际场景下,针对不同的用户、不同的项目,本文模型应该学习到不同的权重。未来将考虑采用注意力机制,使用深度学习的方式,自适应地融合协同过滤信息和项目内容信息在模型中所占的权重。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
现代防御技术(2016年1期)2016-06-01
中国卫生(2015年12期)2015-11-10
南都周刊(2015年4期)2015-09-10
