
基于深度卷积网络的对讲机个体识别
2020-08-06 11:05茆旋宇官友廉陈永游祁友杰
航天电子对抗 2020年3期
茆旋宇,官友廉,陈永游,祁友杰,王 欢
(1.中国航天科工集团8511研究所,江苏南京210007;2.中国人民解放军75798部队,广东汕头515000)
0 引言
辐射源个体识别,也称特定辐射源识别(specific emitter identification),是通过辐射源信号之间的细微差异区分不同辐射源个体的技术,在军用和民用领域有着巨大的实用价值。传统方法主要通过构造并提取相关细微特征实现个体识别,比如文献[1]提取信号的模糊函数的零点切片作为辐射源个体特征,实验证明该特征具有较好的分类性能;文献[2]通过测量信号的瞬时频率对FSK调制信号进行个体识别;文献[3]使用希尔伯特黄变换对信号进行时频特征分析,完成信号个体的分类;文献[4-6]分别使用不同的方法获取双谱特征以表征信号的个体特征,得到了不错的识别结果;文献[7-8]对辐射源的发射机进行非线性建模,通过熵分析提取个体特征从而识别不同的辐射源个体,文献[9-10]分析了信号的暂态过程并使用分形维数表示个体特征,在高信噪比条件下取得了较好的识别效果。
上述方法虽然在一些特定场景下有不错的效果,然而都需要人为提取特征,这需要很强的先验知识,包括对辐射源类型、信号种类、调制方式、发射机设备的工作机理、信道环境等进行分析,这就导致提取特征的过程十分复杂且耗时。同时,提取何种特征、提取的特征是否有效往往没有严格的理论基础,一般是通过专业人员的经验确定,这就导致提取的特征可靠性存疑、特征很难适应不同类型的信号。随着信号处理技术的迅速发展,提取有效辐射源细微特征愈发困难,传统方法的识别效能愈发不足。
深度学习的概念最早由Hinton等于2006年提出,指基于样本数据通过一定的训练方法得到包含多个层级的深度网络结构的机器学习过程。深度学习之所以被称为“深度”,是相对支撑向量机、提升方法、最大熵方法等“浅层学习”方法而言的。深度学习所学得的模型中,非线性操作的层级数更多,浅层学习依靠人工经验抽取样本特征,网络模型学习后获得的是没有层次结构的单层特征;而深度学习通过对原始信号进行逐层特征变换,将样本在原空间的特征表示变换到新的特征空间,自动地学习得到层次化的特征表示,从而更有利于分类或特征的可视化。
深度学习由于具有强大的特征学习能力,逐渐成为各个领域的研究热点。深度学习方法通过卷积神经网络、受限玻尔兹曼机、自编码器及其变型等基础模块搭建深层神经网络,这类深层网络可以自动地学习得到层次化的特征表示,从而更有利于分类或特征的可视化,目前已经在语音识别、信息检索和计算机视觉等领域取得了突破性进展,也越来越多地被引入到个体识别领域。近年来,基于深度学习的辐射源个体识别技术也得到了研究人员的关注。
1 辐射源个体特征形成机理
一般认为,辐射源个体之间的差异是由于设备内部元器件生产制造时的细微容差,人为调试,工作环境如温度、湿度、气压的差异以及设备的老化等原因导致的。以典型的辐射源发射机为例,其简化框图如图1所示。基带信号经过数字信号处理与模数转换后进入模拟电路,信号通过滤波、调制、混频、功放、射频天线等辐射到空间中,这些设备内部的差异以及相互作用最终形成了辐射源的个体特征。
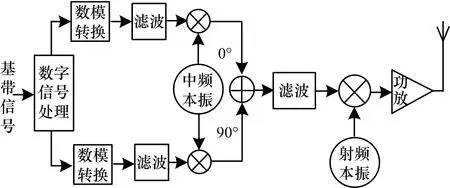
图1 典型辐射源发射机结构框图
1.1 振荡器不稳定影响
任何辐射源设备都需要振荡器获得稳定的频率源,对于常见的振荡器,其内部的半导体器件由于生产工艺的细微差异,其产生的载频不是恒定的,会存在一定偏差,甚至会出现频率的不稳定变化,这种影响可以用一个时变的相位噪声表示,其相应的信号表达式为:
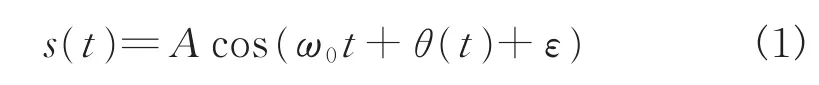
式中,ω0表示振荡器输出频率,ε为相对标准频率的偏移,而θ(t)为振荡器不稳定引起的相位噪声。
1.2 IQ调制器畸变
对于IQ正交调制,由于I路和Q路内部器件的微小差异,信号在正交调制时会出现IQ2路的增益不等、相位不是严格正交、延迟量有细微差异等问题,而这些非线性畸变会体现在信号的时域波形上,表现为调制参数的误差。假设基带的IQ2路数字编码序列为sI(n)与sQ(n),二者首先通过基带成型滤波器,假设滤波器为理想状态,则输出分别为:
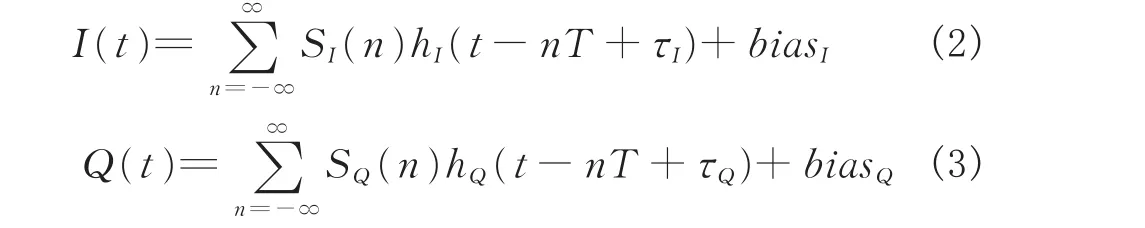
式中,h(t)表示基带成型滤波器,τI、τQ分别为这 2路的延迟误差,bias表示2路存在的偏置差异。两路信号经过正交调制后形成中频信号:式中ωc为信号中频,εI与εQ分别为2路的相位偏差,这种偏差会导致符号之间的干扰,星座图会发生形变。

1.3 内部器件的寄生调制
对于发射机内部诸如振荡器、混频器、功放等有源器件,在信号输入输出过程中由于器件的非线性影响,信号本身会产生寄生调制,一般是以寄生波叠加的形式出现在信号上,数学表达式为:

最终在信号主频带附近会出现寄生谐波,这种寄生谐波分量可以用于表示辐射源的个体特征。
以上部分对辐射源内部细微特征的产生原因与表现形式进行了分析,这些因素导致信号出现载频抖动、偏移、调制参数误差、谐波分量、杂散噪声等,而这些影响会在信号的时域波形以及频谱、功率谱等方面体现出来,因此通过对原始信号的相应处理,可将这些细微特征提取出来。
2 基于卷积网络的对讲机个体识别
卷积神经网络,即一种通过构建卷积层实现类似卷积运算操作的神经网络结构,已在数字图像处理、目标识别、自然语言处理领域取得了巨大成就,是当前最成功的深度学习模型结构,其主要由卷积层、池化层、全连接层等组成,基本结构如图2所示。鉴于其强大的实际性能与适用场景,本文将其用于对讲机个体识别领域。

图2 卷积神经网络基本结构
2.1 算法与实现架构
算法基本原理如图3所示,首先通过接收设备采集辐射源中频信号,接下来对中频数据进行预处理和个体类别标注形成训练数据集,然后构建卷积神经网络,使用训练数据集进行训练,得到训练好的模型。最后采集不同场景下的辐射源信号作为测试数据集,使用该模型进行推理识别,分析网络模型的识别性能。
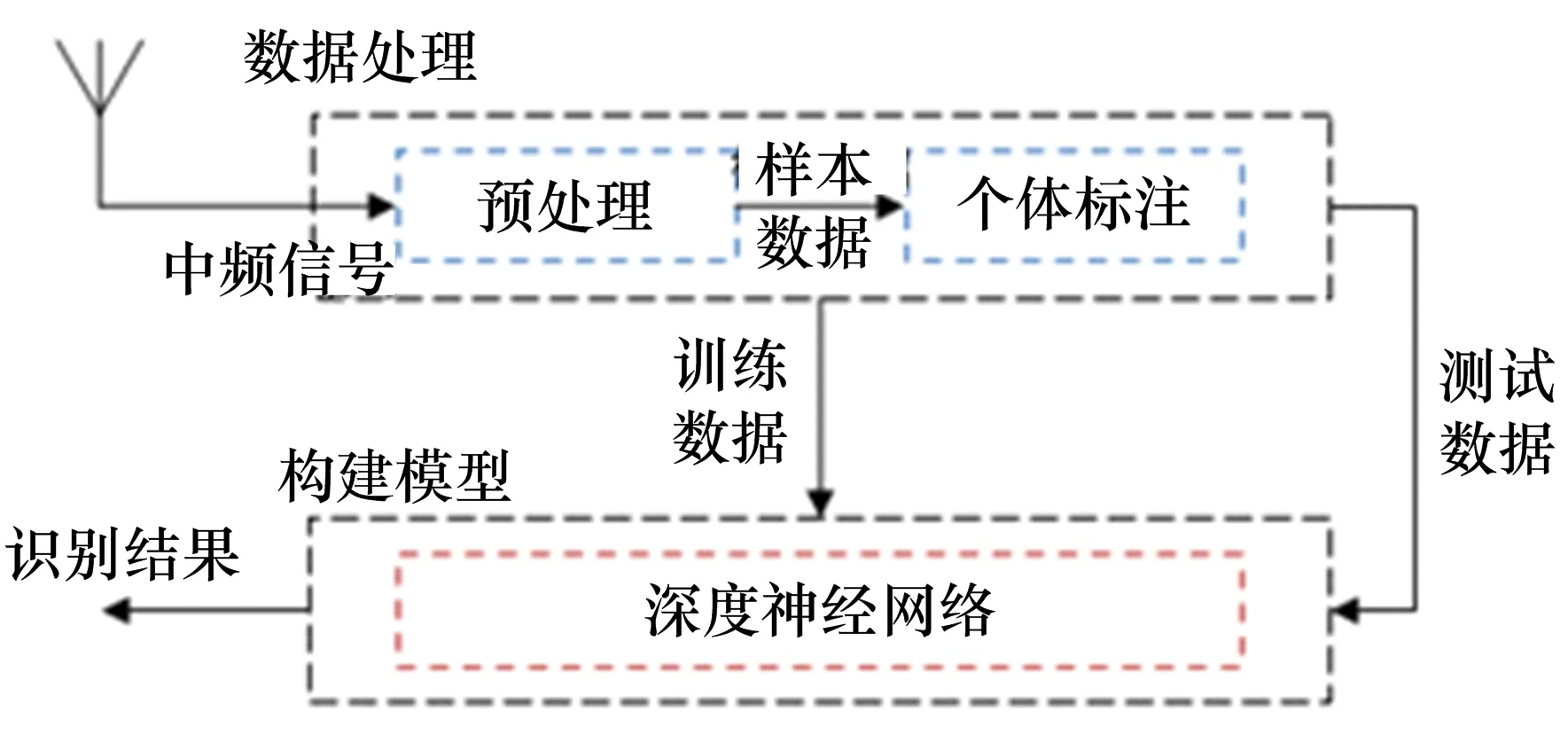
图3 个体识别结构框图
2.2 模型结构
本文构建了一种基于残差网络结构的深度卷积神经网络,由卷积层、池化层、BatchNormalization层、残差结构、全连接层等组成。
卷积层主要用于“空间滤波”,起到提取输入特征的作用。传统卷积神经网络一般用于图像视频等高维数据,而辐射源中频信号为一维时间序列,因此模型选用一维卷积核构建卷积层,考虑到辐射源信号的特点,使用了大尺度的一维卷积核以感知更大范围内的信号细微变化。
池化层用于对数据进行降维减小模型复杂度,同时可以扩大模型的感受野规模,提高模型的识别性能,该模型默认使用最大池化,而最后一层池化使用GlobalAveragePooling,通过对卷积层输出的每一个feature map进行全局平均,可以在大幅降低网络参数的同时保留空间信息[11]。
BatchNormalization层对输入数据的分布做归一化处理,使得输入分布更加均匀和固定[12],加速网络收敛。其数学表达式如下:
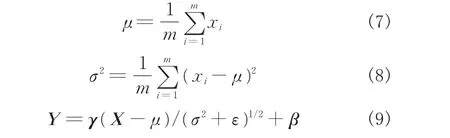
式中,X为上一层的输出结果,xi为其第i个节点的值,μ与σ2为其均值和方差,ε为一很小的正数以防σ2为零,Y为最终的输出结果,γ与β为线性运算的权重,可以通过训练得到。
引入残差技术在增加网络深度的同时减小模型的复杂度[13],进一步减小过拟合风险,提高网络性能。本文使用了bottleneck的残差结构,其基本形式如图4所示。相比传统残差结构,其首先对数据进行降维,寻找输入的低维表示,然后对数据进行升维,这样可以去除高频噪声,提高模型准确度。short cut将卷积前的输入连接到卷积后的输出上,可以在较深的网络结构中保证模型收敛。
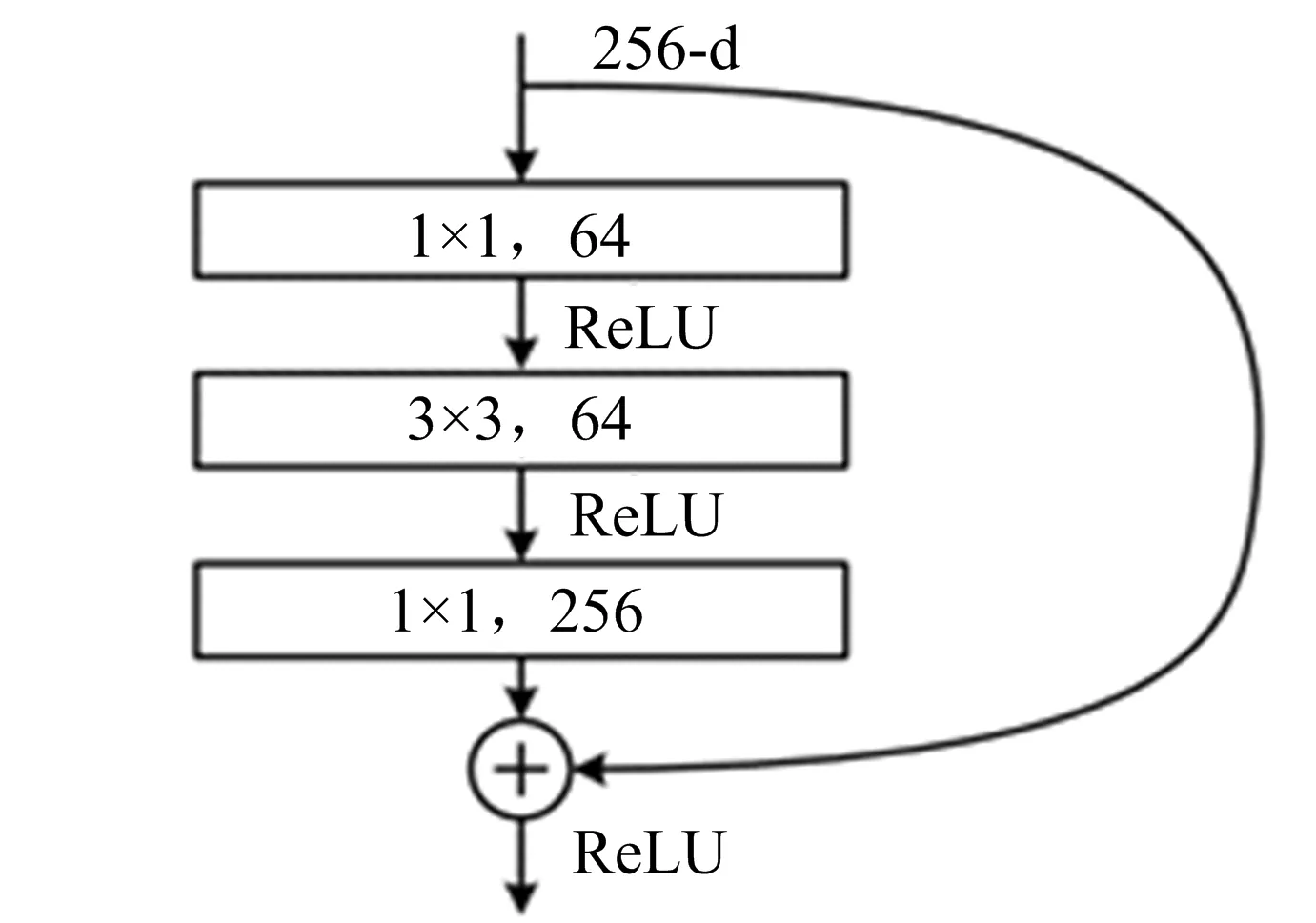
图4 bottleneck残差结构
2.3 网络训练
由于个体识别任务的特点,损失函数需要使得相同个体间特征差异小,不同个体之间特征差异大,常用的损失函数如交叉熵很难满足条件,因此本文使用AM-Softmax。对于传统的Softmax交叉熵损失函数,其数学表达式为:式中,Xi为最后一层的输入,属于yi类,Wj为最后一层第j个神经元的权重矩阵,cosθj代表Xi与Wj的角度余弦值。AM-Softmax通过L2归一化范数使得||Wj||为1,为一常数s,将最大的角度余弦值变为cosθj-m,式(10)变为:
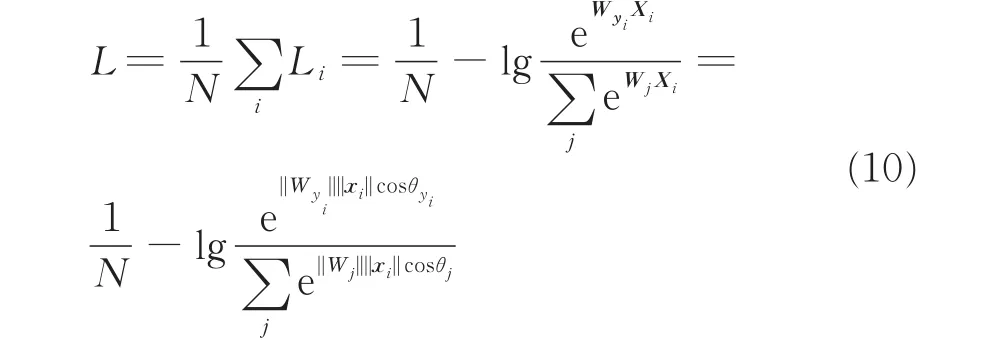
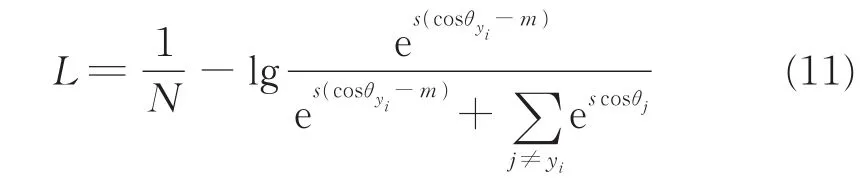
AM-Softmax通过对余弦距离添加约束,推动不同个体间的决策边界相距更远,从而提高了模型的识别能力。
优化器选择带动量的随机梯度下降(SGD)算法,使用变化学习率训练网络。
3 实验与分析
为了验证本文提出方法的有效性,使用对讲机作为测试用辐射源设备,通过采集对讲机中频信号训练神经网络,并另外采集一批数据用于识别验证。
3.1 数据概述及预处理
本文选用了4台摩托罗拉A 1D型号对讲机,这4台对讲机同型号同批次,因此理论上个体特征更为近似,更能有效验证模型的识别性能。该型对讲机采用调频工作方式,采集设备为IQ接收机,中心频率为414.5 MHz,采样率为976 k Hz。采集的中频信号波形如图5所示。
图5 对讲机信号波形
由于对讲机信号为调频连续波,整段信号波形基本没有变化,因此采用等长截取的方式,以1 024个采样点为周期,每一周期的信号作为一个样本。在室内采集一批无人讲话和有人讲话场景下的数据作为训练数据集,每个对讲机共采集2 000条样本。由于采集信号的幅度不等,将信号归一化到[-1,1]之间。使用这些数据训练深度卷积神经网络模型,batch size设为64,初始学习率设为0.025,训练周期数设为100。为了对比该方法与传统特征提取方法识别性能的差异,对该训练集进行特征提取,选用盒维数、包络前沿高阶矩、小波熵、方差维数、信息维数、灰度矩和小波能量比作为指纹特征,标准化处理后训练Adaboost得到识别模型。
3.2 实验结果
分别在室内无人声场景、室内有人声场景、户外多人嘈杂场景下采集数据对模型进行测试,得到识别结果如表1所示。
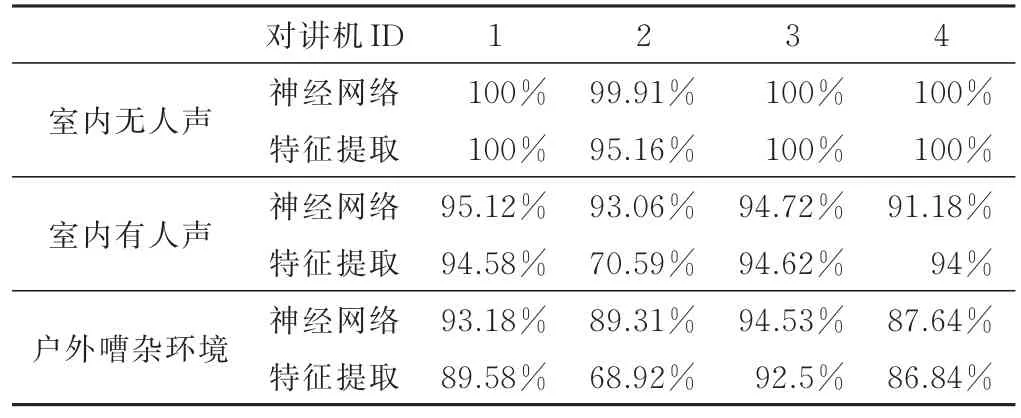
表1 识别结果
对于室内无人声场景下的测试数据,模型表现最好,识别率都在99%以上,而传统特征方法同样取得了优秀的识别结果,只有第2台对讲机识别率稍微低了一些,为95.16%。当识别室内有人声的信号时,模型的识别率明显下降,但也都在91%以上,而传统特征方法对第2台对讲机识别率偏低,只有70.59%。当测试户外嘈杂环境下的数据时,两种方法的识别率都变得更差,传统特征方法对第2台对讲机识别率已经不足70%,而卷积神经网络仍能保持在89.31%。
3.3 结果分析
由实验结果可知,本文使用的深度卷积神经网络在各个测试场景下的识别率都高于特征提取的方法,同时该模型对于户外场景有着更好的泛化能力。此外,2种方法在无人声场景下的识别准确率要远高于有人声场景,这是由于无人声时,对讲机信号为理想正弦波,没有语音信息的干扰,辐射源个体特征表现最明显。当有人声时,信号加入了语音信息,个体特征容易被语音信息掩盖,使得模型提取个体特征变得困难。而相比室内环境,室外接收的信号信噪比更低,受到干扰的影响也更大,同时嘈杂环境带来的语音信息更为复杂,这些都对模型产生了影响,从而使得识别率变差。
4 结束语
本文通过引入深度学习技术,构建深度卷积神经网络来解决对讲机个体识别问题,并通过采集对讲机中频信号验证该方法的实际性能,验证结果表明,该方法在多个场景下识别率都明显优于传统方法。然而,当信号携带大量与个体特征无关的信息时,该方法的识别性能明显受到影响,同时,当信号受到噪声和干扰的影响变大时,识别性能也明显下降,说明该方法针对这些情况还需继续优化,进一步提高系统的鲁棒性。■
猜你喜欢
舰船电子工程(2022年7期)2022-09-06
小天使·二年级语数英综合(2021年5期)2021-07-11
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
爆笑show(2015年11期)2015-12-17
现代电子技术(2015年15期)2015-08-14
青年时代(2009年1期)2009-09-24
成功营销(2004年6期)2004-01-01
