
一种优化聚类的协同过滤推荐算法
2020-08-03 10:05王永贵刘凯奇
计算机工程与应用 2020年15期
王永贵,刘凯奇
辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105
1 引言
随着大数据时代快速发展,互联网产生的海量信息与日俱增,网络覆盖率日益增高。信息检索已经不能满足用户日益增长获取个性化信息的需求,由此个性化推荐系统应运而生[1]。成功应用于电子商务、在线音乐、视频网站、购物商城、社交网络等各个领域。它已经逐步成为各种网络平台中必不可少的核心功能,力求为用户提供最优的决策支撑与信息服务。个性化推荐不需要用户提供明确的需求,而是根据用户的兴趣偏好和历史行为,向用户推荐感兴趣的信息和商品。
目前,个性化的推荐技术又分为基于内容的推荐[2]、协同过滤推荐[3]和混合推荐技术[4]。基于内容的推荐算法不需要依据用户对项目评分,而是通过抽取项目的属性进行特征学习,获得用户的兴趣资料。基于协同过滤推荐算法是根据与其兴趣相似,拥有共同经验之群体的喜好来推荐给目标用户感兴趣的信息。它不需要太多的特定领域知识,可通过基于统计的机器学习算法得到较好推荐效果。而混合推荐算法是将不同的推荐方法进行组合,综合利用基于内容推荐算法和基于协同过滤推荐算法的优点进行推荐。但往往会出现推荐时间增长、平衡不易实现、算法复杂度提高等问题。
协同过滤推荐算法是目前发展最成熟、应用最广泛的个性化推荐技术之一[5]。它最大的优点在于不需要提取内容的信息和项目的特征来构建用户兴趣偏好模型,因此适用于音乐、电影、图片等非文本结构项目。而且具有出色的健壮性和鲁棒性,在各大推荐系统中广泛应用。协同过滤推荐算法包括基于记忆的推荐算法、基于模型的推荐算法。基于记忆的协同过滤推荐算法可以分为基于用户[6]和基于物品[7]的协同过滤推荐算法。它依靠用户项目评分矩阵计算用户或项目之间的相似度进行推荐。但在现实应用中,伴随着用户和项目数量的大幅度增加,却只有一小部分用户对少部分项目评分或评论,因此协同过滤技术存在明显的数据稀疏性、冷启动[8]以及扩展性的问题[9]。基于上述问题,许多研究人员从不同方面将基于模型的算法引入到基于记忆的协同过滤算法中,例如聚类模型、贝叶斯分类模型[10]、隐语义模型[11]、图模型[12]、关联规则挖掘[13]等技术。基于模型的推荐算法利用历史行为数据训练得到模型,并利用该模型进行实时推荐。
其中Wu等人[14]证明基于聚类的协同过滤推荐算法在解决数据稀疏问题上推荐效果更好。骆孜等人[15]在原有非负矩阵分解的模型上,根据用户的评分数据对用户进行聚类,充分挖掘了用户之间的相关关系,有效缓解数据的稀疏性。龚敏等人[16]提出利用最小生成树K-means聚类算法对用户进行聚类,然后再利用Slope One算法填充原始评分矩阵,降低数据的稀疏性并提高算法的扩展性。杨兴雨等人[17]利用二分K均值聚类算法降低原始用户项目评分矩阵的维数,在线推荐时根据随机森林的模型规则进行评分预测,提高推荐的效率。吴月萍等人[18]在协同过滤推荐算法中运用群集智能算法,利用改进的人工鱼群算法实现用户聚类,为后来研究人员提供了新方向。Wang等人[19]提出PCA主成分分析和遗传优化K-means聚类混合推荐算法,提高推荐的准确性。郭磊等人[20]通过人工蜂群算法对项目聚类,大大缩小项目的空间,提高推荐的实时性。然而,以上使用的聚类算法都是硬聚类,将每个用户或项目划分到一个簇中,与实际情况不符。Verma等人[21]提出一种模糊C-means聚类和协同过滤推荐算法的混合推荐系统。FCM是一种软聚类算法,能根据隶属度的不同,将用户划分到多个簇中。李华等人[22]提出一种基于用户情景模糊聚类的协同过滤推荐算法,改善数据的稀疏性和实时性问题。林建辉等人[23]提出一种基于SVD与模糊聚类的协同过滤推荐算法,通过缩小搜索的邻居范围和改进Pearson相关系数来提高推荐质量。Birtolo等人[24]提出模糊C均值和信任感知的聚类协同过滤方法,提高推荐的质量和覆盖范围。Katarya等人[25]将基于粒子群优化的模糊C均值聚类算法应用于基于用户的协同过滤推荐算法中,粒子群优化算法提供最优初始聚类中心并优化模糊C均值聚类,提高推荐的准确率。
然而,上述大多数研究是根据用户对项目的评分进行聚类,没有考虑用户或项目之间的隐含信息,且用户或项目在聚类时容易导致目标数据陷入局部最优,造成最近邻选取不正确,降低推荐的准确性。因此,本文提出一种优化聚类的协同过滤推荐算法。首先预处理原始项目评分矩阵,同项目类型矩阵构造的用户类别偏好矩阵更好反映用户的兴趣偏好;然后在该矩阵上利用花朵授粉优化的模糊聚类算法对用户进行聚类;最后改进基于用户的相似度计算公式和评分预测公式,既融合项目属性隐含的信息,又考虑时间因素对用户兴趣变化的影响,提高推荐的准确性。
2 相关知识
2.1 基于用户的协同过滤推荐算法
在日常生活中,人们在购买商品或获取所需信息时,通常会借鉴与自己喜好相似或志趣相投的朋友所选择的商品或获取相关信息。基于用户的协同过滤推荐算法就是利用这种群体智慧,它的基本思想就是根据目标用户历史行为信息,挖掘与目标用户兴趣相似度高的近邻用户集合,然后根据邻居用户对此项目的评分来预测目标用户的相应评分,从这些预估评分中选择分数靠前的Top-N个推荐给目标用户。
假设用户A喜欢项目a、项目b和项目d,用户B喜欢项目c,用户C喜欢项目a和项目d,从这些用户历史偏好数据中,可以发现用户A和用户C都喜欢项目a和项目d,他们的偏好比较相似,因此也可以认为用户C也会喜欢项目b,所以将项目b推荐给用户C。图1表示此算法的原理。

图1 基于用户协同过滤推荐算法原理
基于用户的协同过滤推荐算法主要步骤:首先把用户评分数据转化成m行n列用户项目评分矩阵Rm,n,如表1所示;然后根据评分矩阵计算目标用户和其他用户之间的相似度,根据相似度的大小获得目标用户最近邻用户集合Nu;最后通过邻居用户对项目的评分预测目标用户的评分。
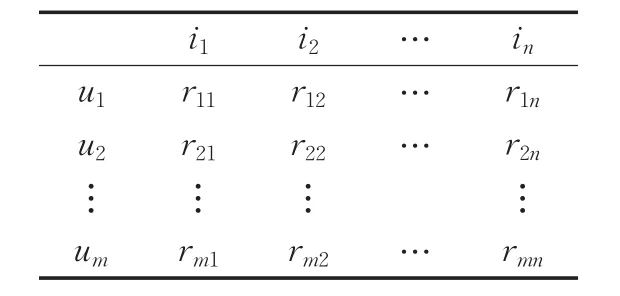
表1 用户项目评分矩阵Rm,n
为了基于用户项目评分矩阵计算出用户之间的相似性,相似度计算方法主要分为余弦相似度、改进的余弦相似度、皮尔逊相关系数等。皮尔逊相关系数用于度量两个变量之间的线性相关性,与改进的余弦相似度计算公式都是去中心化和进行归一化的结果,差别在于去中心化的不同。Herlocker等人[26]的实验表明,在基于用户的协同过滤推荐算法中,选择皮尔逊相似度最为适合,计算公式表示如下:
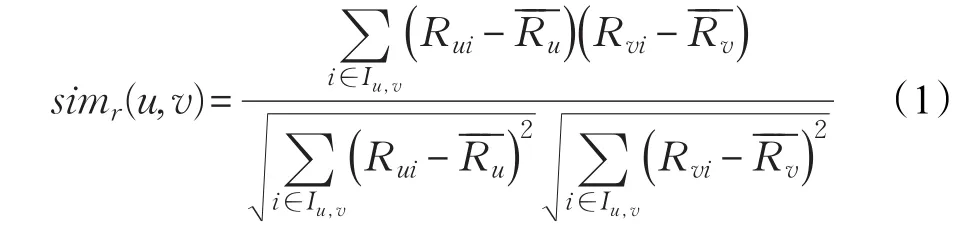
其中,Iu,v表示用户u与用户v共同评分项目构成的集合;Rui表示用户对项目i的评分;Rvi表示用户v对项目i的评分。 分别表示用户u和用户v对所有评分过的项目评分平均值。
2.2 模糊C均值聚类算法
设数据集x={x1,x2,…,xn}⊂Rn为一个有限数据集合,其中xi={xi1,xi2,…,xin},n为数据样本个数,c(2 ≤c≤n)是聚类数,聚类中心为C={c1,c2,…,cn} ,隶属度矩阵为U=(uij)c×n,uij∈[0,1] ,i=0,1,2,…,n;j=1,2,…,c。FCM算法采用误差平方和函数作为目标函数,定义式如公式(2)所示:

聚类是对数据处理的一种方式,它能够将无规则的数据根据相似度高低分成若干个数据组,同一组内的数据特征相似度最高。聚类技术分为硬聚类技术和软聚类技术。对于一个不能明确目标数据对象关系的数据集,使用硬聚类划分就不能符合实际问题的需求。模糊C均值聚类算法(Fuzzy C-means Clustering Algorithm)是在硬C均值聚类算法模型基础上进一步推理得到。硬聚类要求每个用户只能明确归属于一个聚类之中,而模糊聚类是一种软聚类,其中的模糊C均值聚类算法应用最广泛且较为成功。它可以将每一个目标数据对象以不同的隶属度聚到多个类中。FCM聚类算法在每次迭代时,会计算得到一个隶属度矩阵和一个聚类中心的集合。根据算出的隶属度矩阵和聚类中心集合求出目标函数的值。算法最终目的是尽可能找到较小的目标函数值。
其中,m是模糊聚类中的模糊指数,它的作用是平滑隶属函数、抑制噪音等。取值范围是[1.25,2.5]。使得公式(2)取得最优解过程是:首先计算各个用户和聚类中心之间的距离,然后生成用户对各个聚类中心的隶属度矩阵,比较用户在各个聚类中心隶属度的大小,将用户分配到隶属度最大的用户簇中,使得同一个用户簇中用户的相似度最高,减少不同用户簇中用户之间的相似度。将公式(2)求导,可以得到隶属度和聚类中心分别为:

FCM聚类算法基本步骤如下:
输入:数据集和聚类数目c。
输出:使得Jm(u,c)最小的聚类中心集合Cj。
过程:
步骤1确定目标簇的个数为c,模糊指数m。
步骤2随机生成初始聚类中心。
步骤3用公式(3)计算得出隶属度矩阵。
步骤4用公式(4)计算得出各类的聚类中心。
步骤5如果迭代时前后两次的目标函数值之差比最初设置的最小值小则终止迭代,否则返回步骤3。
步骤6输出结果。
2.3 花朵授粉算法
开花植物进化通过花粉传播来繁衍后代。授粉过程主要有生物和非生物两种形式。大部分植物是生物授粉,依靠动物来完成。也有少部分植物是非生物授粉,受到自然界的影响,如风和自然扩散等。花朵授粉算法(Flower Pollination Algorithm)就是模拟大自然中显花植物授粉的群智能优化算法。显花植物的授粉包括自花授粉和异花授粉两种。自花授粉也称为局部授粉,不需要授粉者,在同一种植物之间传播;异花授粉也称为全局授粉,主要是昆虫或鸟类携带花粉并通过莱维飞行进行传播。算法中的局部搜索过程和全局搜索过程由转换概率P决定。在现实中,每朵花可能产生数百万甚至是更多花粉,为了简化问题,花朵授粉算法假设每颗显花植物仅开一朵花,每朵花只产生一个花粉配子,就是说一朵花为求解优化问题的一个解。
FPA算法的主要思想:
(1)首先进行初始化种群。
(2)然后对种群个体进行适应值评价,找出适应值最优的个体作为当前全局的最优解。
(3)最后通过转换概率p∈[0,1],完成全局搜索与局部搜索之间的转换,不断地迭代直到满足收敛条件为止。
下面由数学公式描述花朵授粉的算法:
当p>rand时,算法执行全局授粉,公式如下所示:

其中,分别为花粉在第t+1次、第t次迭代的位置,g*为当前全局最优解,γ为控制移动步长的比例因子。L(λ)为对应花朵个体的莱维飞行步长矢量,当L>0时,其表达式如下:
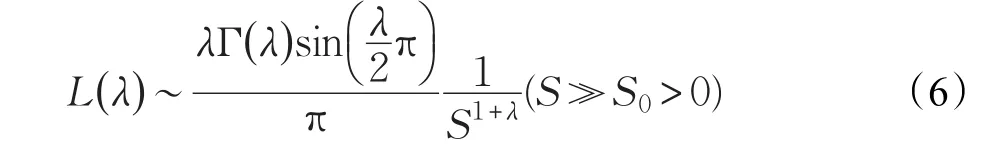
其中,,Γ(λ)为标准伽马函数,S为移动步长,采用曼特尼亚算法产生最有效的步长,公式如下所示:
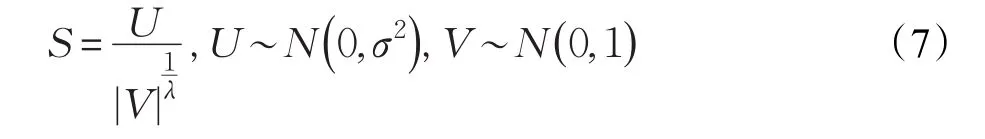
其中,U服从均值为零,标准差是σ2的高斯分布,V服从标准正态分布。σ2由以下公式得出:
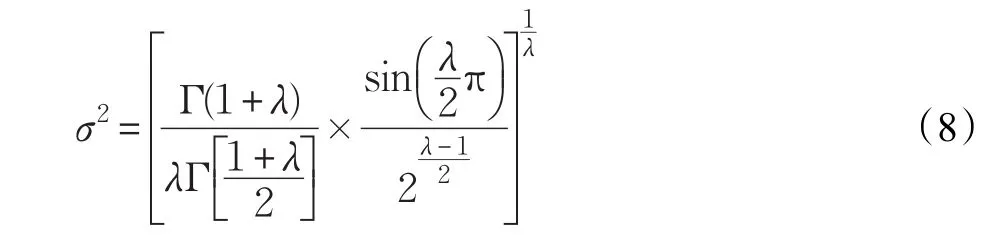
当p 其中,ε∈[0,1],是服从均匀分布的常数,是种群的两个随机解,代表同一品种植物不同花朵的花粉。 利用原始用户项目评分矩阵和项目类型矩阵构造用户类别偏好矩阵,其中考虑用户的评分差异,对用户项目评分矩阵进行预处理。在得到用户类别偏好矩阵基础上,通过FPAFCM算法对用户进行聚类,该算法是利用花朵授粉FPA算法去优化模糊聚类FCM算法。改进基于用户的相似度计算公式,将项目偏好隐性信息相似度加入到项目评分矩阵相似度计算公式中,得到K个最近邻居。评分预测时考虑时间因素对用户兴趣变化的影响,将预测评分值最高的N个项目推荐给目标用户。本文算法框图如图2所示。 图2 本文算法流程图 传统的协同过滤推荐算法依赖于用户项目评分矩阵,但是现实中用户评分项目很少,不同用户在同一项目上共同评分则更少。所以基于用户项目评分矩阵会受到数据稀疏性带来的严重影响。而且它通常只考虑到共同评分项目对相似性的影响,共同评分项目所占比例越高,与目标用户就会越相似。事实上,尽管用户评价的不是同一个项目,如果这些项目风格类型相似,同样可以说明用户之间有相似的兴趣爱好。比如用户u1喜欢观看电影“疾速备战”和“惊奇队长”,并给出了很高的评价,而用户u2喜欢观看“蜘蛛侠”和“巴尔干边界”,同样也给出了很高的评分。因为这四部电影属于动作片,可以认为用户u1和用户u2具有相似的兴趣偏好。然而传统的协同过滤推荐算法会因为他们没有共同评分而忽略它们之间的相似度,用户u1和用户u2就不能成为最近邻居。构建用户类别偏好矩阵对用户进行聚类,一是因为喜欢的类别相同也具有相似性,二是项目的类型数量远小于项目数量且比较稳定,构造出更加稠密的用户类别偏好矩阵达到降维效果,缓解数据的稀疏性。 用户类别偏好矩阵Pm,y可以通过原始用户项目矩阵Rm,n和项目类型矩阵Cn,y构造。设评分系统中项目的集合为I={i1,i2,…,in},项目类别集合为T={t1,t2,…,ty} 。项目与类别之间的关系用一个n×y的矩阵表示,这个矩阵称作项目类型矩阵Cn,y,如表2所示。矩阵中每个元素cit表示电影i是否属于类别t,可以表示为: 表2 项目类型矩阵Cn,y 用户与项目类别之间关系用m×y的矩阵表示,记作矩阵Pm,y,如表3所示。矩阵中元素put表示用户u对项目类别t的偏爱程度。 表3 用户类别偏好矩阵Pm,y 由于用户对项目的评分尺度没有明确标准,是由用户主观给出项目的评分,所以不同用户的评分尺度存在一定的差异,导致计算出的兴趣最相似近邻集合出现很大偏差。为了克服用户评分差异对推荐结果造成的影响,根据指定评分平均值对用户项目评分矩阵中的非零评分值进行预处理,得到用户项目评分矩阵R′m×n,用户评分处理后的公式如下所示: 其中,r′ui是预处理后的评分值,rui表示原始用户对项目i的评分值表示用户u的平均评分值。因为评分为5分制,所以rˉ定为3。 在得到的用户项目评分矩阵R′m×n上计算用户类别偏好矩阵元素的值。用户u所有评分项目集合用Iu表示,将预处理后评分值小于均值的项目过滤后,得到的项目集合表示为: 其中,cit=1表示项目属于类别t。 为了区分用户对项目类别的偏好程度,并且避免直接使用评分数据对计算造成偏差。将规范化后的评分划成不同区间,并设置相应的权值。α(r′ui) 计算公式为: 其中,|Lut|表示集合Lut中元素个数;对Put进行归一化处理,将分母乘以α(r′ui)的最大值作为归一化因子,取值为3。 FCM聚类算法在对给定的目标数据进行聚类时,初始化参数的选取会对最后聚类结果产生很大影响,且容易导致目标对象的数据陷入局部最优值。花朵授粉算法刚好能解决以上出现的问题,因此将两种算法融合到一起,对用户进行聚类。 FPAFCM算法思想:先利用花朵授粉算法找到最优的初始聚类中心,再通过最优的初始聚类中心对用户进行模糊C均值聚类。花朵授粉算法的每一朵花表示一个聚类中心矩阵C={c1,c2,…,cc},并且将适应度函数设置如下所示: FPAFCM算法基本步骤如下: 输入:用户类别偏好矩阵,花粉种群规模S,最终目标簇的个数c,隶属度矩阵指数m,最大迭代次数MCN。 输出:用户簇隶属度矩阵U。 步骤1随机产生初始花粉种群S。 步骤2根据隶属度矩阵的计算公式(3)得到一个当前循环的隶属度矩阵。 步骤3根据公式(2)对每个花粉的适应度值进行计算,找到最小的值及其对应的个体作为全局最优解。 步骤4当转换概率p>rand条件时,按照公式(5)~(8)进行全局授粉过程更新花粉位置,对解进行越界处理。 步骤5当转换概率p 步骤6根据步骤4或者步骤5得到更新之后的解,计算得到的相应隶属度矩阵,最后计算对应的目标函数值。当目标函数值小于历史目标函数值,用更新后的值代替个体当前最优值。如果不是,则保留当前结果。 步骤7将更新后的值和历史全局最优解进行比较,更新或保留历史全局最优解。 步骤8判断是否满足算法终止条件。如果不满足则转向步骤4继续迭代,满足则输出结果。 步骤9对步骤8输出的最优隶属度矩阵去模糊化处理,进而完成聚类。 根据用户聚类的结果,找出目标用户候选邻居簇,然后根据目标用户与簇中候选邻居之间的相似度计算,按照降序排列,将前K个作为目标用户的最近邻居。计算相似度时将用户对项目属性类型偏好信息反映的相似度同用户对项目评分反映的相似度进行加权求和。既包含原始用户项目评分矩阵的显性信息,又考虑到用户和项目类别之间的隐性信息,增加最近邻居搜索的准确度。改进后相似度计算公式如下所示: 其中,λ为比例因子,取值范围是[0,1],λ表示原始评分矩阵计算出的用户相似度在相似度公式中所占比例,(1-λ)表示用户类别偏好矩阵计算出的用户相似度在相似度公式中所占的比例。simr(u,v)是根据用户评分矩阵计算出的相似度,如公式(1)所示。simt(u,v)是根据用户类别偏好矩阵计算出的相似度,如下面公式(18)所示: 其中,Eu,v代表用户u和用户v共同评价过的项目类别集合,Put、Pvt分别表示用户u和以及用户v对类型为t的项目偏好值,分别代表用户u和用户v对评价过的项目类别偏好平均值。 传统的协同过滤推荐算法在预测评分时,不考虑评分时间,忽略用户兴趣变化对预测评分的影响,推荐的结果具有片面性。实际上,用户感兴趣的项目会随着时间而发生变化,过去感兴趣的项目现在不一定会感兴趣,所以在进行评分预测时要考虑到时间因素。根据人类记忆遗忘曲线提出的一种模拟人类兴趣变化的时间函数,将该函数融入到传统协同过滤推荐算法的评分预测。通过给予不同评分时间不同得分权重,来模拟用户的兴趣变化。模拟人类的兴趣变化函数公式如下所示: 其中,tui表示用户u对项目i的评分时间,tug表示用户u对项目最早评分时间,f(tui)表示预测评分中的时间权重因子。f(tui) 的取值范围是(0,1),随着tui的增大,权重因子f(tui)也在不断增大。将公式f(tui)引入到传统评分预测公式中,得到改进后评分预测公式(20)如下所示: 其中,Nu表示用户u的最近邻居集,sim(u,v)表示用户u和用户v之间相似度,rvi表示用户v对项目i评分,表示用户u平均评分值,表示用户v平均评分值。 从公式中可以看出,随着时间的推移,时间权重因子越小,预测的评分值越低。该公式符合用户的兴趣变化,更能准确预测用户对项目的评分。 MovieLens是一个基于评分的电影推荐系统,由美国明尼苏达州大学GroupLens研究小组创建,其中包括100 KB、1 MB、10 MB三个规模的数据集,专门用于研究推荐技术。本文使用的是MovieLens 100k数据集验证算法的性能,此数据集被公认是评估推荐算法的主要数据集。其中包括1 943名用户对1 682部电影的100 000个评分记录,且数据集的每个用户至少对20部电影进行评分,评分范围是1~5分,用户对某电影的评分值越高则说明用户越喜欢这部电影。本数据集构建的用户项目评分矩阵稀疏度为93.7%。在实验前把数据集按照9∶1的比例分割对数据进行交叉验证,即将90%的数据作为训练集,剩余的部分作为测试集。 (1)聚类效果评价指标 在实验中使用聚类的准确率来衡量聚类的效果。聚类准确率是指正确划分的样本个数占总体样本数的比例,公式如下: 其中,NUCF表示通过基于用户的协同过滤推荐算法得出的相似用户邻居集合;NFPAFCM表示本文算法得出的相似用户邻居集合。 (2)推荐质量评价指标 本文选择平均绝对误差MAE(Mean Absolute Error)作为评价推荐质量优劣的指标。通过计算训练集中预测评分和测试集中真实评分之间的平均绝对误差度量评分预测的准确性,预测评分与实际评分越接近,MAE值越小,推荐效果越好。假设用户U预测评分表为Pu={PU1,PU2,…,PUT},实际评分表为Qu={QU1,QU2,…,QUT},T为测试集的评分数量,平均绝对误差MAE的定义为: 在实验中,本文算法的参数设置m=2,S=20,MCN=500,p=0.8。 通过实验检验相似度计算公式中比例因子λ对推荐结果的影响,确定λ的最优值。实验中选取最近邻数量为40,当用户的聚类个数为5、10、15、20时,随着比例因子λ从0递增到1,递增间隔为0.1,MAE的变化情况如图3所示。 从图3可以看出,无论用户的聚类个数为多少,当比例因子λ在[0,0.4]范围内时,MAE随着λ的增加而减小,说明推荐效果越来越好;当比例因子λ在[0.4,1]范围内时,MAE值随着λ的增加而变大,显示推荐效果逐渐减弱。因此,本文算法的比例因子λ的最优值为0.4。 图4的横坐标表示用户的聚类数c,显示出实验中c值选取6、8、10、12、14、16时,MAE值的变化情况。实验结果表明用户聚类数c的确定对推荐算法的准确性有直接的影响,c值过大或是过小都会引起MAE值的升高,也就是误差会增加。根据图4可知,随着用户聚类数的增加,当用户聚类数在[6,10]时,MAE值相应减小;当用户聚类数在[10,16]时,MAE值相应增大。用户聚类数为10时,MAE值达到最小。所以聚类个数为10时,推荐效果最佳。 图3 MAE随比例因子λ的变化情况 图4 MAE随用户聚类个数的变化情况 图5 两种算法的聚类准确率对比图 图5 描述了FCM聚类算法和FPAFCM聚类算法在avg、low、high三种数据统计情况下的聚类准确率的变化情况。实验统计数据是将30次的实验结果取平均值,这样可以避免数据随机性造成的误差。横坐标avg表示统计数据的平均值;low表示统计最低值数据的平均值;high表示统计最高值数据的平均值。纵坐标cor表示聚类准确率,计算公式如式(21)所示。从图5中显示在avg、low、high三种数据统计的情况下,FPAFCM聚类算法与FCM聚类算法对应的聚类准确率cor相比有明显的提升。这是因为FPAFCM聚类算法利用花朵授粉算法找到了最优的初始聚类中心,有效地避免陷入局部最优值,再通过优化的模糊C均值算法对用户聚类,从而有效提高聚类的准确率。 为了验证本文算法推荐的准确性,将基于用户的协同过滤推荐算法(UserCF)[27]、基于模糊C均值聚类推荐算法(FCM)[28]、基于粒子群优化模糊均值聚类算法(PSOFCM)[25]与本文的算法进行对比实验。设置最近邻个数从10递增到35,递增间隔为5。图6反映了随着最近邻个数的增加,MAE值的变化情况。可以看出实验中UserCF、FCM、PSOFCM和文中的算法都随着目标用户最近邻个数增加而降低并且逐渐趋于稳定。本文提出算法在不同最近邻居个数下的MAE值都明显低于其他三种算法,推荐结果准确性最高。FCMCF算法是在基于用户的协同过滤推荐算法中加入模糊C均值聚类算法,PSOFCM算法则是在基于用户的协同过滤算法中加入了粒子群优化的模糊聚类算法,但是本文在预处理的用户类别偏好矩阵基础上,利用花朵授粉优化的模糊聚类算法对用户进行聚类,增强聚类的效果。计算相似度时,将用户偏好信息的相似度与项目评分矩阵的相似度加权求和,评分预测融合时间因素对用户兴趣变化的影响,改进相似度计算公式和评分预测公式,进一步提高推荐的准确性。 本文提出一种优化聚类的协同过滤推荐算法。首先根据用户评分的差异,对评分进行预处理,构造用户类别偏好矩阵,充分利用用户和项目之间的隐含信息,并通过降维有效缓解数据的稀疏性。然后在该矩阵上利用花朵授粉算法优化的模糊聚类算法对用户聚类,增强了用户的聚类效果。将项目的类别属性信息融入到传统的协同过滤推荐算法用户之间相似度的计算。最后充分考虑时间因素对用户评分预测的影响,使推荐准确性有很大的提高。在未来的工作中,对于更大数据规模,可以通过spark分布式平台实现,进而提高推荐的质量和效率。
3 本文算法

3.1 构造用户类别偏好矩阵





3.2 花朵授粉算法优化的用户模糊聚类推荐算法

3.3 生成目标用户的最近邻居
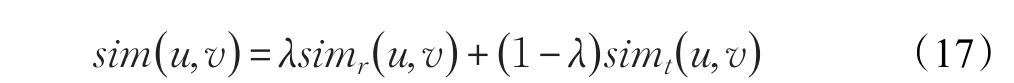
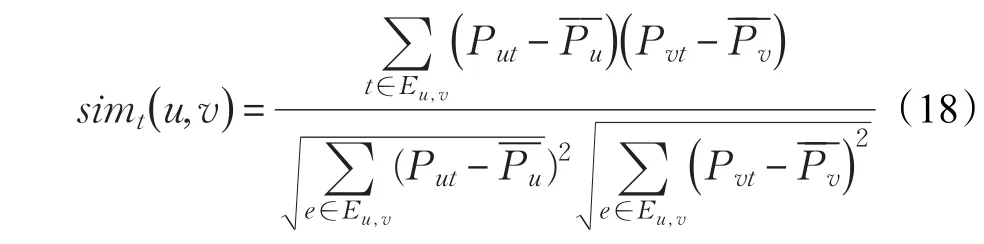
3.4 计算推荐结果


4 实验及结果分析
4.1 数据集简介
4.2 评价指标

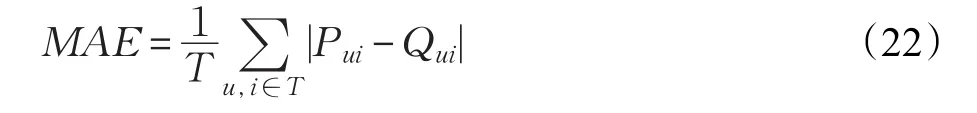
4.3 实验结果与分析



5 结束语
猜你喜欢
新高考·高二数学(2022年3期)2022-04-29新高考·高二数学(2022年3期)2022-04-29中学生数理化(高中版.高二数学)(2020年11期)2020-12-14铁道通信信号(2019年6期)2019-10-08中学生数理化·高一版(2018年6期)2018-07-09民族古籍研究(2018年1期)2018-05-21雷达学报(2017年6期)2017-03-26西夏学(2016年2期)2016-10-26互联网天地(2016年1期)2016-05-04智能系统学报(2015年4期)2015-12-27
