
多模态融合的高分遥感图像语义分割方法
2020-08-03 00:38李万琦李克俭陈少波
中南民族大学学报(自然科学版) 2020年4期
李万琦,李克俭,陈少波
(中南民族大学 电子与信息工程学院,武汉,430074)
随着遥感影像技术的飞速发展,人们可以采集、获取越来越多的高分辨率遥感影像[1](地面采样距离在5到10厘米之间),在这些影像中可以清楚的观测到如汽车、建筑物等较小的物体,这使得像素级的语义分割成为可能.遥感图像语义分割可用于环境监测、灾后重建、农业、林业和城市规划[2]等领域,例如政府机构在规划新区建设时,就可以依靠高质量的土地覆盖图像进行数据分析.
近年来,深度学习[3]方法下的卷积神经网络(CNN)在计算机视觉领域有许多重大突破,且在自然场景下的语义分割任务中也取得了很多新的技术成果.卷积神经网络模型利用卷积计算提取高级语义特征,在与标签比对的同时,利用反向传播算法[4]更新网络参数;模型通过训练得到最优解并以端到端的形式输出结果,计算效率显著提升.高分辨率遥感图像具有背景复杂,目标物存在遮挡、大小不一、分布不均衡等问题;光照条件对成像质量也有一定影响,往往表现为色彩对比度低[5].这些复杂情况往往需要一定的专业知识背景才能对图片进行分析处理,因此通过深度学习的方法实现端到端遥感图像语义分割,对海量数据实现自动化处理以获取最新的图像信息,能节省大量人力物力.
在计算机视觉语义分割任务中,有两种代表性的网络结构,分别是全卷积网络[6](Fully convolutional network, FCN)以及编码器-解码器结构的网络.2014年LONG等提出的FCN在自然场景的图像分割任务中取得了很好的效果.FCN的核心在于全连接层,它可视作感受野为整个输入图像的卷积核,而这些卷积核的计算是权值共享的,因而提升了整个网络的效率;ZHONG等提出的FCN-4s[7]用于遥感图像分割,使用跳跃连将低层特征与高层特征融合,使模型更适应遥感数据集的分割任务;ZHAO等人提出的PSPNet[8]是将金字塔池化模块嵌入至以ResNet-101[9]为基础网络的FCN模型中,该模块在池化层使用大卷积核来获得多尺度信息,得到了更好的分割效果.
BADRINARAYANAN提出的SegNet[10]是语义分割模型中另一大体系,它采用编码器对输入图像提取特征,而后使用解码器对特征图进行上采样以获得高分辨率密集特征,最后使用Softmax[11]函数对特征图进行像素级分类;NOH等提出的DeconvNet[12]与SegNet类似,它通过加深上采样来获得更精细的分割结果;2015年RONNEBERGER提出的U-Net[13]在SegNet的基础上,通过引入编码器与解码器之间的级联,融合低级与高级语义特征,在医学影像分割中获得了很好的效果; RefineNet[14]采用了类似U-Net的结构,其改进为编码解码过程中引入了残差模块来获取背景信息,并得到了更高的分割精度.
上述方法在一定程度上提高了自然场景下的图片分割精度,而在遥感图像的俯拍场景下,单独使用上述分割模型并不能达到最佳效果.由于遥感图像具有低照度、多遮挡、空间信息不足等特点,仅仅使用RGB图像作为网络输入提取到的特征无法包含必要的空间信息.为进一步加强深度学习模型在遥感图像上的分割能力,本文提出了一种多模态融合的方法,基于U-Net设计了SE-UNet(Squeeze and Excitation UNet).该模型将数值地表模型(Digital Surface Model)转化而来的DSM图像与RGB图像作为网络的双输入,通过SE(Squeeze and Excitation)模块[15]将DSM所包含的高度信息以压缩再激活的形式编码为特征向量,其元素值作为其对应的RGB图像每个通道的加权,从而构建出DSM图像与RGB图像之间的通道关联.这一结构能够利用空间信息进行自学习训练,提取到更全面更具判别性的语义特征用于最后的分割任务.
1 SE-UNet 网络模型
1.1 网络整体结构
本文提出了一种多模态融合的方法,基于U-Net设计了SE-UNet(Squeeze and Excitation UNet).网络整体框架如图1所示,包括SE模块、U-Net编码器和U-Net解码器.网络采用双输入模式,DSM图像通过SE模块编码得到特征向量与RGB图通过U-Net编码器得到特征图在通道级别(channel-level)相乘得到新的特征图,这一过程将DSM图像所包含的高度信息编码作为RGB图像每个通道的加权信息,通过学习的方式计算每个特征通道的重要程度,参考权重强调有用特征并抑制对当前任务用处不大的特征.之后将特征图通过U-Net的解码器还原为原输入大小并完成损失函数的优化,预测得到图像中每个像素点的分类.

图1 SE-UNet整体框架
1.2 U-Net
U-Net[13]于2015发表,该模型在医疗影像(CT、磁共振图片)语义分割任务中取得了很好的效果,常被用作医疗影像处理领域的基础网络.U-Net采用了对称的编码器-解码器结构,如图2所示.编码器共进行4次下采样(Max-Pooling),下采样率为16倍;对称地,其编码器也相应进行4次上采样(Up-Sampling),将特征图恢复到原图分辨率;同时在每一个水平阶段使用跳跃链接的方式将高级语义特征与浅层特征相融合,最终得到用于分割的特征图.

图2 U-Net网络结构
本文使用U-Net作为骨干网络主要考虑到医学影像与遥感影像有两个相似之处:
(1)数据集规模小.医学与遥感影像的数据获取和标签制作相对于自然场景要难,多数公开数据集的原始训练集不超过50张图片.U-Net网络结构简单,参数量级在3千万左右,这种设计对小数据集来说能更好的避免模型出现过拟合.
(2)数据具有多模态.相比自然影像,这两种影像数据除了有传统的RGB图像模式,还具有多种模态的影像类型,本文使用的是单通道32位的DSM图像和三通道8位的RGB图像.
单纯使用U-Net训练也存在一定问题,医学影像与遥感影像最大的不同在于医学影像语义较为简单、结构较为固定,分割任务多为二分类(病灶与背景)[16];而遥感影像往往具有复杂的场景,目标尺度大小不一、分布不均衡.为了更好地利用DSM图像的高度信息,本文引入SE(Squeeze and Excitation)模块单独对DSM图像进行编码,下面介绍SE模块.
1.3 SE(Squeeze and Excitation)模块
Squeeze-and-Excitation网络(SE-Net)[15]是由自动驾驶公司Momenta在2017年发表的图像识别模型.其核心在于SE模块,它可嵌入到其他分类或检测模型中,通过对特征通道间的相关性建模,把重要的特征进行强调以获得更具判别性的特征.图3所示的是一个SE模块结构.
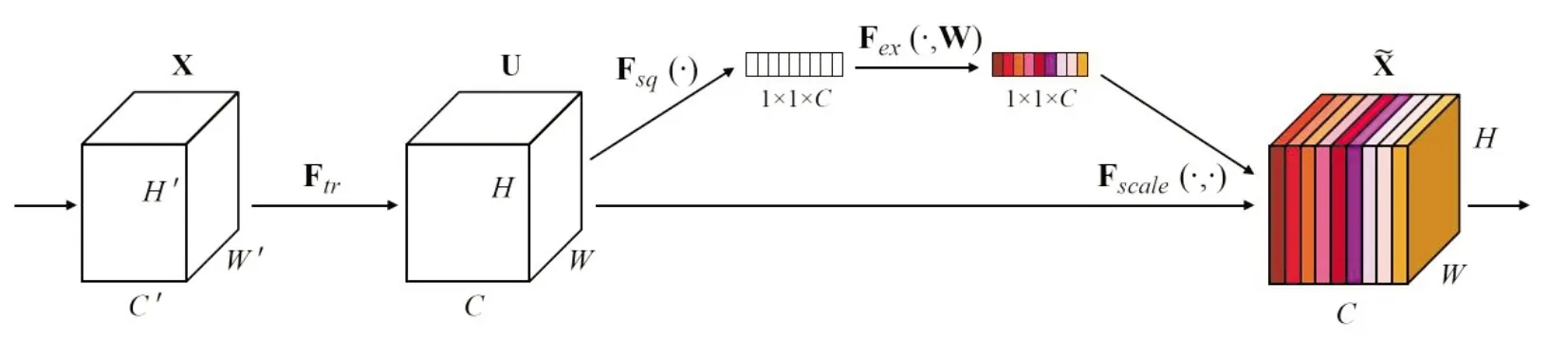
图3 SE模块
如图3所示,Ftr为普通卷积操作,X和U分别代表Ftr的输入与输出,U之后的操作为SE模块的主体部分,该模块具备可移植性.输出特征U首先会通过一次压缩(Squeeze)Fsq(·),作者采用全局平均池化算法[17]将全局信息压缩到一个通道中,算法如下:
(1)
公式(1)中Uc表示c通道(i,j)位置的像素值;H和W表示c通道长和宽;输出Zx为一个通道上的所有像素点平均值,大小为1×1×C。ZC可以理解为整个通道像素信息的统计数据集合,代表了图像在该通道的全局信息.
第二步是激活过程(Extraction)Fex(·,W),这一过程可以得到各通道与原特征图之间的关联,以此判断哪个通道的特征图需要赋予更多的权重.这一步骤需具备可学习性,即通道之间是非线性关系,同时要保证有多个通道被选中,而不是人工激活.为满足上述条件,作者采用了两个全连接层(Fully-connected)后接Relu函数[18]和Sigmoid做激活层,激活步骤的算法如公式(2);激活函数如公式(3)和(4):
s=Fex(z,W)=δ(g(z,W))=σ(W2δ(W1z)),
(2)
δ(·)=Relu(x)={x,x>00,x≤0,
(3)
(4)

(5)

经过上述三个步骤,SE模块将原本的特征图通过压缩再激活,映射为原图每个通道的权值,把重要的特征增强、不重要的特征减弱,从而让提取的特征指向性更强.且这一权值信息是通过网络自学习优化得到的,没有人为干涉.
1.4 SE-UNet
本文设计的SE-UNet完整的网络结果如图4所示,整体划分为六个阶段(Stage0-5):第0阶段为DSM图像处理过程,第1~5阶段为RGB图像经由U-Net编码、解码过程.这里DSM图像与RGB图像是成对输入网络的,模型在训练过程中使用的图像来自ISPRS公开数据集[19].

图4 SE-UNet网络结构

S1=W·D1⊗δ(W·R1),
(6)
其中W代表3×3卷积核,δ代表Relu激活函数,⊗代表对应元素通道级别相乘.每个阶段重复公式(6)的计算.需要注意的是,在进入下一阶段前,前一阶段输出的特征图会通过最大池化(Max Pooling)进行下采样,采样率为2.这一操作在DSM图像和RGB图像上同步进行,其目的在于进一步增强有效特征并缩减模型参数.因为随着网络加深,到第5阶段时,特征图的通道数会增至1024,如保持原图大小则会占用过多资源导致网络无法继续训练.
经由5个阶段的编码过程,我们得到了大小为32×32×1024的特征图。该特征图不仅具备RGB图像的高级语义特征,还融合了DSM图像高度信息.通过U-Net的解码器对其进行上采样和反卷积解码;与编码过程保持对称的同时,模型使用跳跃连接,将低阶特征和高阶特征级联,最终编码得到了一张与原输入大小一致的特征图用于分类预测.
2 实验及结果分析
2.1 数据准备与数据增广
本文使用的是ISPRS提供的遥感图像数据集[19],包含38张超高分辨率的3通道正射影像和其对应的数字地表模型转化成的单通道灰度图,图片分辨率为6000×6000。所有影像拍摄自德国历史名城波茨坦,该地区拥有大型建筑物、狭窄的街道和密集的住宅区,每张图片被标注为6种常见的土地类别:不透水面、建筑物、灌木、树木、汽车和背景.图5展示了数据集中的样张,从左至右分别是原图、DSM图和标签图.

a)RGB原图 b)DSM灰度图 c)标签图
我们使用24张图片作为训练集,剩下14张图片为测试集,测试集仅在测试时使用.由于原始图片过大无法直接输入网络,我们将训练集中的24张原图以500步长裁剪为1000×10000大小的子图像,对相应的DSM图像和标签进行了同步操作,总共得到得2096张图片.在将图片输入模型训练之前,使用OpenCV对所有训练图片和标签随机裁剪为512×512大小,同时进行了翻转、旋转、尺度变换以及HSV空间变换等随机的数据扩充操作.
2.2 网络训练及评价指标
在SE-UNet中,所有卷积核大小都为3×3,步长为1,初始卷积核数为64,每次池化操作后卷积核数加倍,训练中使用0填充保证每次卷积操作后的输入输出大小一致.前向网络得到特征图后,经由Softmax函数[20]将像素值转化为目标类别的概率值,并在反向传播更新参数时,使用二进制交叉熵函数作为损失函数,其算法如公式(7)和(8):
(7)
(8)

实验中,一批次输入为2张图片,所有图片都完成一次训练为一个迭代,共迭代50次;每5次迭代使用交叉验证对模型进行阶段性检测.我们设定的初始学习率为1×10-3,每10个迭代后依次衰减为0.5×10-3、0.1×10-3、0.05×10-3、0.01×10-3.实验使用的是Ubuntu18.04系统以及一块NVIDIA 1080 8GB显卡,程序语言为Python3.6,深度学习框架为Pytorch[20].本实验完成训练共耗时27小时.
分割结果使用常用标准进行评估,包括精准率(Precision)、召回率(Recall)以及F1值和总准确率(Overall Accuracy, OA),后两项为综合评价指标,也是最为常用的标价标准.公式(9)~(12)给出了各类评价指标的算法:
(9)
(10)
(11)
(12)
其中TP(True Positive)表示目标正确分类的像素点数;TN(True Negative)表示背景正确分类的像素点数;FN(False Negative)表示应为目标却被错分为背景的像素点数;FP(False Positive)应为背景却被错分为目标的像素点数.
2.3 实验结果分析
本文在ISPRS-Potsdam测试集[19]上进行测试,该测试集共14张图片.实验结果如表1所示,除了本文提出的SE-UNet外,我们还训练了单输入RGB图像的U-Net和E-Net模型进行对比试验.其中E-Net[21]是PASZKE于2016年提出的一种用于视频场景分割的模型,与U-Net类似,该模型整体采用了编码器-解码器结构.该模型在编码阶段使用了初始模块(initial module)来压缩输入图像的体积,这一结构与本文使用的SE模块有相似之处,虽在一定程度上牺牲了精度,但尽可能缩小了模型体积,减少总参数量,大大提升了训练和预测速度.

表1 不同模型在各分类上的分割准确率、F1值、OA值
表1中加粗数值代表最优结果,从表中可以看出,本文提出的模型在F1值和总准确率(OA)上有明显提升,F1值和OA值较U-Net分别提升了5%和3.3%,较E-Net分别提升了8.6%和5.9%.在五大类中,建筑物的高度最为突出,在该类别中SE-UNet取得了94.9%的准确率,较单输入的U-Net提升了5.8%,这说明我们提出的模型很好的利用了DSM图像的高度信息,对该类目标的识别与分割起到了很强的指导作用.图6展示了一张测试图片(裁剪为1024×1024)在不同网络中的分割结果,可以看到我们提出的模型(Fig.6-c)类间粘粘情况较少,尤其是建筑物的(深蓝色)分割结果较其它两个模型更为精准.

图6 测试结果展示
表2给出了使用SE-UNet进行测试的单张完整图片“top_potsdam_3_13_class.tif”的混淆矩阵,对角线上的数值代表预测类别与真实类别相同的概率,非对角线上的数值表示实际为纵轴类别但预测为横轴类别的概率.从表中可以看出,误判率最高的为背景、最低的为建筑物,其潜在原因可能在于图片中背景的高度信息在DSM图像中没有得到体现,所以预测准确率较低,这也从侧面验证了DSM图像的所具备的高度信息对于模型的特征提取有指导意义.

表2 单张测试图片混淆矩阵
图7为该图预测结果的视觉展示.最右侧的红绿图展示了每个像素点的预测情况,其中红色区域代表分类判断错误的像素点;绿色代表判断正确的像素.

图7 “Top_potsdam_3_13_class.tif”单张测试结果及误判图
3 结语
为了解决RGB遥感图像存在的高度信息缺失的问题,本文设计了一种融合DSM图像和RGB图像的卷积神经网络模型,在U-Net的基础上引入了SE模块对DSM图像的高度信息进行提取,并将提取到的信息与RGB图像进行融合编码以获得更具判别性的特征图.在ISPRS-Potsdam数据集中我们的模型取得了较好的分割结果,总体准确率(OA)达到了88.8%.通过实验验证,我们的模型较单输入的U-Net及E-Net精度提升了3.3%和5.9%,通过数据说明了引入DSM图像的有效性.同时我们注意到,模型在对背景的预测上表现不够优异,在后续的研究工作中,我们还要针对这一问题优化模型的训练策略.同时也应在网络模型的精简上进行进一步探索,使其具备实际应用价值.
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
