
一种视频时空特征提取算法及其应用研究
2020-07-25 07:16曾凡智
佛山科学技术学院学报(自然科学版) 2020年3期
曾凡智,程 勇,周 燕
(佛山科学技术学院电子信息工程学院,广东佛山528000)
随着互联网、多媒体技术的发展,每天都会产生海量视频,目前广泛应用于市场的搜索引擎,如百度、谷歌等都是基于文本标注的检索方法[1],该方法需要人工提前对视频进行文字描述,视频检索的结果依赖于用户的文字表述,且需要花费大量的人力,为克服上述缺陷,基于内容的视频检索[2]成为现阶段研究热点,主要目标是实现视频构建索引自动化,避免依赖人工标注,以及实现高效、高精度的检索性能。例如,张静[3]提出一种HSV颜色直方图和灰度共生矩纹理特征相融合的特征来表征图像帧,进行视频关键帧提取。Hannane R等[4]选择局部SIFT特征作为视频帧特征的描述子进行计算,该特征可以较好地表示内容丰富的图像,但算法的实现过程较为复杂。为了克服视频的底层特征与高层语义之间鸿沟,Brindha N等[5]提出了基于对象的检索算法,通过检索所包含的特定类型的对象,来实现相似度匹配。考虑到视频帧在时间维度上具有动态依赖关系,Zhang L等[6]提出结合视频帧间光流特征和帧内方向梯度特征,实现视频分类检索目的,此方法对准确率有一定提升,但算法复杂度高,检索速度较慢。
以上方法各有优点和一定局限性,大多采用颜色、纹理、形状、SIFT等底层特征来进行视频相似度匹配,这些特征都是基于统计概括的全局特征,对于完全不同的两种图像可能会有相同的颜色、纹理特征,且易受到光照、噪声影响。视频帧在时间维度上是具有动态依赖关系的,仅仅只是考虑关键帧的局部静态特征,无法捕捉视频的时序动态特征,对视频的检索精度也会有较大影响,而光流轨迹特征计算复杂,对于大规模视频检索不太适用。
近年来,深度学习在视频、图像识别领域表现优异,梁建胜等[7]通过度量小波变换的距离来提取视频关键帧,然后用卷积神经网络AlexNet来提取关键帧的深度特征进行视频检索。廖奕铖[8]提出通过卷积神经网络InceptionV3来提取图像深度特征,通过特征向量的余弦距离来提取关键帧,同时将该关键帧的深度特征保存构建索引进行视频检索。
这些基于深度学习的检索方法,具有更强的鲁棒性和泛化抽象能力,但并没有融合视频的时序特征,对于运动较大的视频,其检索准确率不太理想,为此,本文提出采用DenseNet-201卷积神经网络[1]来提取关键帧的深度特征,采用三维卷积神经网络-C3D[10]来提取关键帧附近的16帧连续图像的时空特征,在视频检索过程中通过融合视频的关键帧的深度特征和时空特征,实现高精度的视频检索系统。
1 视频的时空特征提取算法及检索设计
二维的卷积神经网络,在提取图像特征时,当输入不管是一张图像,还是多张图像,其卷积操作后输出均是二维特征,导致图像帧的时序动态信息被压缩,无法学习到视频的时空特征,三维卷积神经网络的区别在于卷积核是三维的,其输出特征仍然是三维,这样会保留图像帧的时序关联性,有利于视频的时空特征的学习。
1.1 时空特征提取算法
本文采用三维卷积神经网络C3D模型来提取关键帧附近的16帧连续图像的动态特,网络结构如图1所示。该网络有8个卷积层,5个最大池化层和2个全连接层,所有卷积层的卷积核均为3×3×3,步幅为1×1×1,所有最大池化层的卷积核均为2×2×2,步幅均为2×2×2。在标准视频数据集 UCF-101[11]上,动作识别准确率达到85.2%。在提取时空特征时,将每帧图像利用双线性插值缩放到224×224大小后输入给网络,随后将倒数第二层的全连接层的4 096维时空特征向量输出。网络训练时,网络优化采用随机梯度下降法SGD(stochastic gradient descent),损失函数采用交叉熵,即



图1 C3D网络结构图
其次,采用训练后的DenseNet-201网络模型来提取单一关键帧的图像深度特征,该模型的层数达到201层,在ImageNet大规模图像数据集上,top5达到了95%的分类准确率,鉴于该模型的优异性能,可以用来对图像进行特征提取。首先将视频图像利用双线性插值缩放到224×224大小后输入给网络,随后将倒数第2层全局平均池化层的1 920维深度特征向量输出。
1.2 视频关键帧分析
在提取视频关键帧的过程中,本文采用帧间差分析方法,此方法的思想是通过比较视频帧的深度特征之间的相似度来提取关键帧,该算法简单,代码复杂度低,可以实现海量视频快速处理,具体流程如图2所示。
step1:将第1帧作为关键帧,并将其设为基准帧;
step2:依次计算后续帧与基准帧进行余弦夹角相识度判断;
step3:若相似度D小于设定的阈值T,则将第i帧加入关键帧集合;
step4:将第i帧更新为基准帧,若没有结束,则退回到step2;
step5:输出关键帧集合,结束。
视频帧的深度特征,使用载入预训练参数的DenseNet-201网络模型,来提取视频帧的1 920维特征向量,其特征向量为网络模型倒数第2层全局平均池化层的输出。视频帧间相似度度量,采用余弦夹角距离,衡量前后帧间相似度,通过阈值T比较来达到关键帧提取目的,在本文算法中相似度阈值为0.75,相似度取值范围在(0,1]之间,即
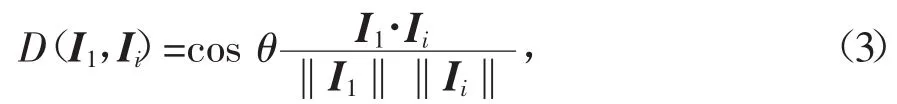
其中,I1表示基准帧的特征向量,Ii表示视频当前帧的特征向量。
1.3 基于内容的检索过程
在视频检索过程中,根据用户输入的内容,采用不同的检索策略,分为基于图像检索和基于短视频检索。
(1)基于图像检索视频。根据用户提供的图像,用DenseNet-201卷积神经网络提取图像1 920维特征,将该特征与视频特征数据库进行余弦相似度比较,每个视频中取其中最大的值代表该视频的相似度值,最后由大到小排序输出前N个最相似视频,如图3所示。
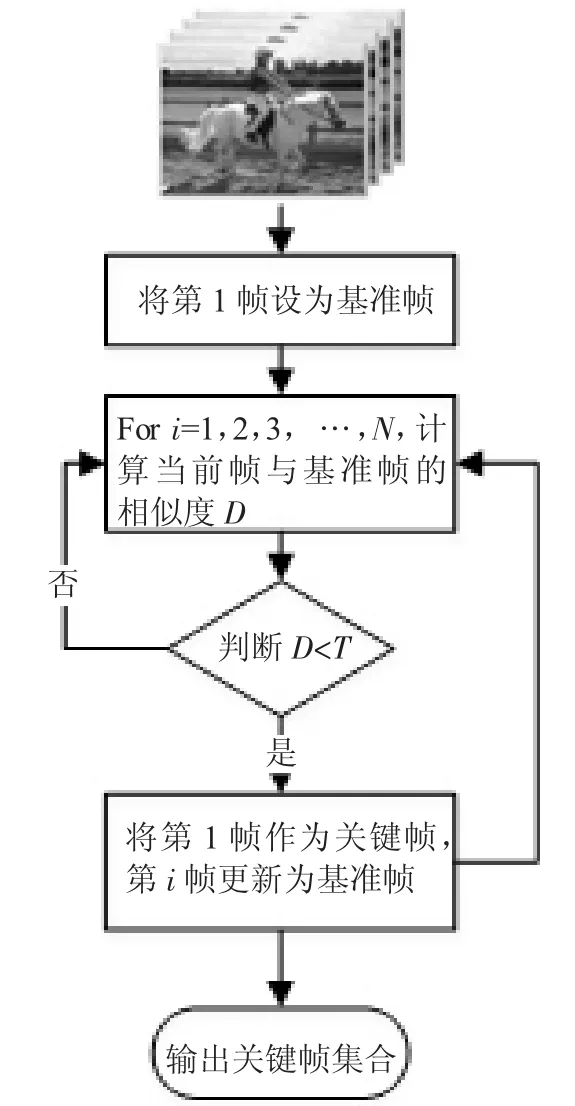
图2 视频关键帧提取流程图

图3 基于图像检索视频流程图
(2)基于短视频检索视频。用户可通过选择短视频来检索相似视频,如图4所示,首先要通过前面提到的关键帧提取算法,得到该视频的N个关键帧集合,然后分别用DenseNet-201网络和C3D网络提取其关键帧对应的N×1 920维深度特征集合a1和N×4 096维时空特征集合a2,在与视频特征数据库其中一个视频进行匹配时,采用滑动窗口的形式进行余弦相似度计算,默认输入的视频作为窗口整体,窗口滑动一次计算一次相似度,并同时融合两种特征,窗口每次计算公式为

其中,N表示输入视频关键帧数量,D1i、D2i分别表示第i个关键帧对应的深度特征余弦相似度和时空特征余弦相似度,a表示输入视频的特征集合,b表示数据库中一个视频的特征集合,a1i、b1i表示第i个关键帧的深度特征,a2i、b2i表示第i个关键帧的时空特征,ω1、ω2分别表示深度特征和时空特征融合的权值,本文中均取0.5。
每计算一次滑动一下窗口,直到数据库视频关键帧末尾,如果数据库视频关键帧集合比输入视频的关键帧短,则将数据库视频设为窗口进行滑动计算相似度,一个视频相似度匹配结束后,会有多个相似度值,本文选其中最大的值作为该视频的相似度。随后按照上述流程依次处理数据库所有视频,最后按相似度由大到小排序,输出前N个最相似视频。

图4 基于短视频检索视频流程图
2 基于时空特征的视频检索应用系统设计与实现
视频检索系统主要由视频入库、视频检索和数据库三个模块组成,如图5所示。其中,视频入库模块主要将视频数据进行关键帧提取和特征提取,并将特征序列与视频构建索引入库。然后,视频检索模块根据用户输入的图像或视频,对其提取特征后,与数据库进行余弦相似度匹配,最后,将前N个最相似的视频反馈给用户。
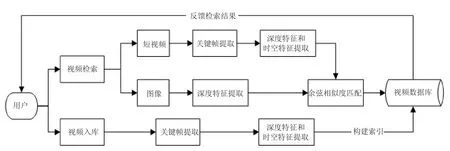
图5 基于时空特征的视频检索应用系统框架图
2.1 视频入库模块
视频入库主要将原始视频进行关键帧提取,通过关键帧序列来表达视频的内容,采用DenseNet-201卷积神经网络和C3D三维卷积神经网络对该视频的关键帧序列分别提取其深度特征和时空特征,随后将深度特征和时空特征与关键帧id和视频id建立索引关系,存入数据库,便于后期视频检索。
2.2 数据库模块
数据库主要用来存放视频信息和视频特征信息。本文采用关系型数据库mysql进行数据库开发,主要有两张表:视频信息表和关键帧信息表。
视频信息表Video主要用来存放视频相关信息,包含视频id、视频名称、视频路径和视频创建日期,如表1所示。

表1 Video视频信息表
关键帧信息表KeyFrame主要包含关键帧id、从属的视频id、关键帧路径、关键帧深度特征、关键帧相邻16帧图像的时空特征和关键帧创建日期,如表2所示。
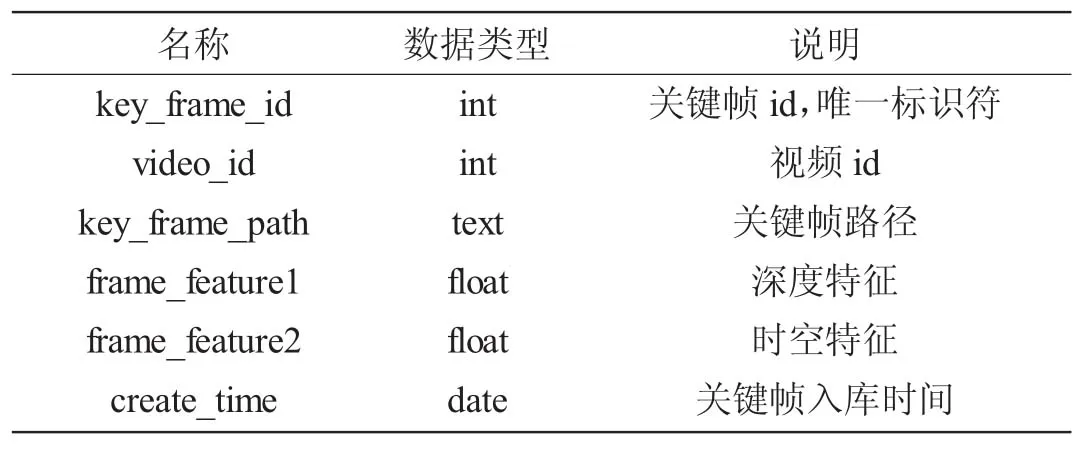
表2 KeyFrame关键帧信息表
2.3 视频检索模块
视频检索模块主要提供给用户一个可视化的检索界面,用户通过输入图片或短视频可以检索到相似视频。如果输入图片,则只需提取其深度特征,在与数据库视频关键帧进行逐一匹配过程中,只需比较其深度特征,随后输出前N个最相似的视频;若用户输入短视频,则提取其关键帧序列后,在提取关键帧深度特征的同时,还需提取其相邻16帧图像的深度特征,由于输入的短视频得到的是一个关键帧特征序列,在与数据库视频集合进行匹配的过程中,采用滑动窗口的方式进行相似度匹配,并融合深度特征和时空特征,最后输出前N个最相似的视频。
3 系统实现与性能测试
3.1 运行环境
系统运行的软件环境为:操作系统Windows 10,编译器python 3.6,深度学习框架TensorFlow 1.14,加速模块CUDA 10.0和cuDNN 7.6,图像处理库OpenCV 4.1,系统界面开发库PyQt5 5.6。系统运行的并行计算加速硬件GPU为:显卡GTX 1050 Ti。测试数据集采用国际标准动作视频数据集UCF-101,它是从YouTube上剪辑的真实世界中的人类动作视频,其中包含13 320个视频,101个人类动作类别,动作包括:眼部化妆、涂口红、射箭、骑自行车等。
3.2 系统功能
本系统的主要功能包括:视频关键帧提取、视频入库、用图像检索视频、用视频检索视频和视频播放等功能,系统的主界面如图6所示,分为功能选择区和结果展示区。
(1)视频播放和关键帧提取功能。在这个系统中,用户可以进行选择视频、播放视频,若需要快速浏览视频,用户可通过关键帧提取功能对所选择的视频,在有GPU加速的条件下,可进行关键帧快速提取,如图7所示。

图6 系统主界面
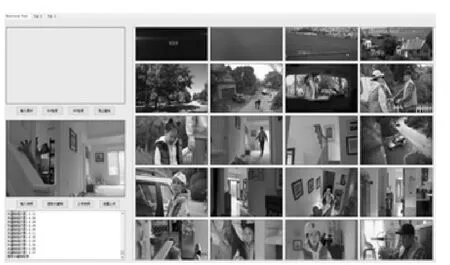
图7 视频关键帧提取效果
(2)视频入库和视频检索功能。视频入库分为单个入库和批量入库,用户选择对应的视频文件夹即可进行视频批量入库。系统的视频检索功能分为基于图像检索和基于短视频检索,用户可以选择输入图片,也可以选择短视频,来检索相似视频,检索效果如图8、9所示,每次检索会默认推送前400个最相似视频,用户可通过鼠标滚动浏览,通过单击对应视频可以进行播放。

图8 基于图片检索效果

图9 基于短视频检索效果
3.3 性能测试及分析
在对比实验中,采用本文所提出的视频深度特征和时空特征与文献[4,12]使用的SIFT特征和文献[8]基于InceptionV3网络深度特征进行对比。测试视频是从UCF-101数据集中的每个类别随机抽取10个视频,分别使用SIFT特征、InceptionV3网络深度特征、DenseNet网络深度检索和融合DenseNet网络深度特征和C3D网络时空特征,进行检索实验,然后分别绘制四种检索方法的平均P-R曲线,如图10所示。

图10 四种方法的对比P-R图
经过试验对比,本文提出的基于深度特征和时空特征的视频检索算法的效果,好于以SIFT特征为核心的传统视频检索系统,其中融合时空特征的方法相较于单独使用深度特征的方法,平均准确率提高了1.5个百分点,最终该系统在平均查准率为90%的情况下,准确率可以达到84%。通过GPU等硬件环境加速,在大规模数据集中,系统的平均检索时间不超过3 s,满足目前商用的实时处理需求,输入短视频后的检索效果如图11所示。

图11 视频检索效果图
4 结语
基于深度学习的高度抽象泛化能力,关键帧提取方面,本文采用训练后的DenseNet-201网络模型提取图像深度特征,利用帧间差分析法快速提取视频关键帧;特征提取方面,在保存关键帧的深度特征同时,通过训练后的三维卷积神经网络,获取关键帧附近连续16帧图像的时空特征,该方法可快速有效地提取视频的深度特征和时空特征;视频检索方面,通过加权融合时空特征和深度特征,实现高精度的视频检索算法。其次,本文构建一个高性能的基于内容的视频检索系统,该系统实现了视频关键提取和视频批量入库功能,用户可通过关键帧提取功能快速预览视频内容,也可以通过批量入库功能实现视频一键入库,同时也支持基于图片检索和基于短视频检索功能,在动作视频数据集UCF-101测试中,视频检索的速度和精度等方面均达到了比较理想的效果。在后续的研究中,可以考虑使用Fisher Vector[12]算法来优化非对称的视频检索算法,替换本文使用滑动窗口匹配方式,进一步提高视频检索效率,在特征提取上,可以探索提取更多连续帧的时空特征,比如64帧或者128帧,进一步提高检索准确率,另外还可以结合语音识别等技术,生成语义性的文本关键词或标签等信息,来提高检索精度。
猜你喜欢
四川党的建设(2022年8期)2022-04-28
重庆科技学院学报(自然科学版)(2022年6期)2022-02-04
房地产导刊(2021年10期)2021-11-22
中国食品(2021年4期)2021-03-22
中国食品(2021年2期)2021-02-24
微型电脑应用(2020年12期)2020-12-25
小学生学习指导(低年级)(2020年11期)2020-12-14
沈阳理工大学学报(2019年3期)2019-08-21
作文大王·低年级(2018年10期)2018-12-06
小猕猴智力画刊(2016年5期)2016-05-14
