
基于BERT-BiLSTM-CRF模型的中文实体识别①
2020-07-25 09:06杨俊安
计算机系统应用 2020年7期
谢 腾,杨俊安,刘 辉
(国防科技大学 电子对抗学院,合肥 230037)
引言
命名实体识别(Named Entity Recognition,NER)是自然语言处理的关键技术之一,同时也是作为知识抽取的一项子任务,其主要作用就是从海量文本中识别出特定类别的实体,例如人名、地名、组织机构名以及领域专有词汇等.中文命名实体识别是信息抽取、信息检索、知识图谱、机器翻译和问答系统等多种自然语言处理技术必不可少的组成部分,在自然语言处理技术走向实用化的过程中占有重要地位.因此,命名实体识别作为自然语言处理最基础的任务,对它的研究则具有非凡的意义与作用.在中文实体识别任务中,其难点主要表现在以下几个方面:(1)命名实体类型与数量众多,而且不断有新的实体涌现,如新的人名、地名等;(2)命名实体构成结构较复杂,如组织机构存在大量的嵌套、别名以及缩略词等问题,没有严格的命名规律;(3)命名实体识别常常与中文分词、浅层语法分析等相结合,而这两者的可靠性也直接决定命名实体识别的有效性,使得中文命名实体识别更加困难.因此,中文命名实体识别研究还存在很大的提升空间,有必要对其做进一步的研究.
1 相关工作
命名实体识别从最早期开始,主要是基于词典与规则的方法,它们依赖于语言学家的手工构造的规则模板,容易产生错误,不同领域间无法移植.因此,这种方法只能处理一些简单的文本数据,对于复杂非结构化的数据却无能为力.随后主要是基于统计机器学习的方法,这些方法包括隐马尔可夫模型(HMM)、最大熵模型(MEM)、支持向量机(SVM)和条件随机场(CRF)等.例如,彭春艳等人[1]就利用CRF结合单词结构特性与距离依赖性,在生物命名实体上取得较好的结果;鞠久朋等人[2]提出把CRF与规则相结合来进行地理空间命名实体识别,该算法有效地提高了地理空间命名实体识别的性能;乐娟等人[3]提出基于HMM的京剧机构命名实体识别算法,并且取得相当不错的效果.在基于机器学习的方法中,NER被当作序列标注问题,利用大规模语料来学习标注模型.但是这些方法在特征提取方面仍需要大量的人工参与,且严重依赖于语料库,识别效果并非很理想.近些年来,深度学习被应用到中文命名实体识别研究上.基于深度学习的方法,是通过获取数据的特征和分布式表示,避免繁琐的人工特征抽取,具有良好的泛化能力.最早使用神经网络应用到命名实体研究上是Hammerton 等人[4],他们使用单向的长短期记忆网络(LSTM),该网络具有良好的序列建模能力,因此LSTM-CRF成为了实体识别的基础架构;后来在该模型的基础上,Guillaume Lample 等人[5]提出双向长短期记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)和条件随机场(CRF)结合的神经网络模型,这种双向结构能够获取上下文的序列信息,因此在命名实体识别等任务中得到相当广泛的应用,并且他们利用BiLSTM-CRF模型在语料库CoNLL-2003 取得了比较高的F1值90.94%;Collobert 等人[6]就首次使用CNN与CRF结合的方式应用于命名实体识别研究中,在CoNLL-2003上取得不错的效果;Huang等人[7]在BiLSTM-CRF模型的基础上融入人工设计的拼写特征,在CoNLL-2003语料上达到了88.83%的F1值;Chiu和Nichols 等人[8]在LSTM模型前端加入CNN处理层,在CoNLL-2003语料库上达到了91.26%的F1值;在生物医学领域上,李丽双等人[9]利用CNN-BiLSTM-CRF神经网络模型在Biocreative Ⅱ GM和JNLPBA2004语料上取得了目前最好的F1值,分别为89.09%和74.40%;在化学领域上,Ling Luo 等人[10]采用基于attention 机制的BiLSTMCRF模型,在BioCreative IV数据集上取得91.14%的F1值;Fangzhao Wu 等人[11]提出联合分词与CNNBiLSTM-CRF模型共同训练,增强中文NER模型实体识别边界的能力,同时又介绍了一种从现有标记数据中生成伪标记样本的方法,进一步提高了实体识别的性能;秦娅等人[12]在深度神经网络模型的基础上,提出一种结合特征模板的CNN-BiLSTM-CRF网络安全实体识别方法,利用人工特征模板提取局部上下文特征,在大规模网络安全数据集上F1值达到86%;武惠等人[13]联合迁移学习和深度学习应用到中文NER上,也取得了较好的效果;王红斌[14]、王银瑞[15]利用迁移学习来进行实体识别,该方法相对监督学习方法很大程度上减少了人工标注语料的工作量;Dong 等[16]提出了Radical-BiLSTM-CRF模型使用双向LSTM提取字根序列的特征,然后与字向量拼接组成模型的输入;刘晓俊等人[17]利用基于attention 机制的DC-BiLSTMCRF模型在MSRA语料上F1值最高可达到92.05%;Zhang 等人[18]提出的Lattice LSTM模型,它显式地利用了词与词序列信息,避免了分词错误的传递,在MSRA语料上取得了较高的F1值93.18%;Liu 等人[19]提出WC-LSTM模型,把词信息加入到整个字符的开头或末尾,增强语义信息,在MSRA语料上取得了93.74%的F1值;王蕾等人[20]则是利用片段神经网络结构,实现特征的自动学习,并在MSRA语料上取得90.44%的F1值.
然而以上方法存在这样的一个问题:这些方法无法表征一词多义,因为它们主要注重词、字符或是词与词之间的特征提取,而忽略了词上下文的语境或语义,这样提取出来的只是一种不包含上下文语境信息的静态词向量,因而导致其实体识别能力下降.为解决该问题,谷歌团队Jacob Devlin 等人[21]所提出来一种BERT (Bidirectional Encoder Representation from Transformers)语言预处理模型来表征词向量,BERT作为一种先进的预训练词向量模型,它进一步增强词向量模型泛化能力,充分描述字符级、词级、句子级甚至句间关系特征,更好地表征不同语境中的句法与语义信息.Fábio Souza 等人[22]采用BERT-CRF模型应用到Portuguese NER上,在HAREM I上取得最佳的F1值;Jana Straková等人[23]把BERT 预处理模型应用到实体识别上,在CoNLL-2002 Dutch、Spanish和CoNLL-2003 English上取得相当理想的效果.由于BERT具有表征一词多义的能力,本文在此基础上提出一种BERTBiLSTM-CRF神经网络模型,该模型首先利用BERT预训练出词向量,再将词向量输入到BiLSTM做进一步训练,最后通过CRF解码预测最佳序列.实验结果表明,该模型在MSRA语料和人民日报语料库上分别达到了94.65%和95.67%的F1值.
本文的创新点主要有以下两点:① 将语言预训练模型BERT应用到中文实体识别中,语言预训练是作为中文实体识别的上游任务,它把预训练出来的结果作为下游任务BiLSTM-CRF的输入,这就意味着下游主要任务是对预训练出来的词向量进行分类即可,它不仅减少了下游任务的工作量,而且能够得到更好的效果;② BERT语言预训练模型不同于传统的预训练模型,BERT预训练出来的是动态词向量,能够在不同语境中表达不同的语义,相较于传统的语言预训练模型训练出来的静态词向量(无法表征一词多义),在中文实体识别中具有更大的优势.
2 BERT-BiLSTM-CRF模型
2.1 模型概述
近几年来,对于实体识别的上游任务语言预处理而言,它一直是研究的热点问题.而BERT作为先进的语言预处理模型,可以获取高质量的词向量,从而更有利于实体识别的下游任务进行实体提取和分类.本文提出的BERT-BiLSTM-CRF模型整体结构如图1所示,这个模型主要分3个模块.首先标注语料经过BERT 预训练语言模型获得相应的词向量,之后再把词向量输入到BiLSTM模块中做进一步处理,最终利用CRF模块对BiLSTM模块的输出结果进行解码,得到一个预测标注序列,然后对序列中的各个实体进行提取分类,从而完成中文实体识别的整个流程.
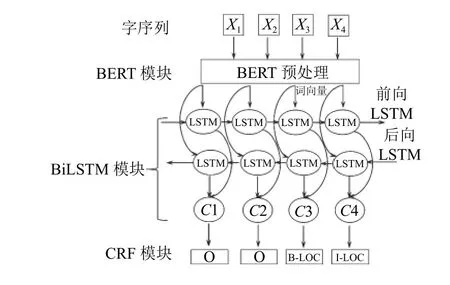
图1 BERT-BiLSTM-CRF模型框架
本文模型最大的优势在于BERT语言预处理模型的应用,它不再需要提前训练好字向量和词向量,只需要将序列直接输入到BERT中,它就会自动提取出序列中丰富的词级特征、语法结构特征和语义特征.Ganesh Jawahar 等人[24]对BERT模型的内在机理做了进一步的研究,指出对于BERT模型每一层学习到的特征是不尽相同的.BERT模型的底层主要是获取短语级别的特征信息,中层主要是学习到句法结构特征信息,顶层则是捕获整个句子的语义信息,经过BERT处理过后能够获得语境化的词向量,对处理长距离依赖信息的语句有很好的效果.而对于传统模型,它们主要集中在词语或字符级别特征信息的获取,而对于句法结构以及语义信息很少涉及.可以看出BERT模型特征抽取能力明显强于传统模型.
2.2 BERT模块
多年来,对语言模型的研究先后经历了one-hot、Word2Vec、ELMO、GPT到BERT,前几个语言模型均存在一些缺陷,如Word2Vec模型训练出来的词向量是属于静态Word Embedding,无法表示一词多义;GPT 则是单向语言模型,无法获取一个字词的上下文.而对BERT模型而言,它是综合ELMO和GPT 这两者的优势而构造出来的模型.Fábio Souza[22]利用BERT提取更强的句子语义特征来进行命名实体识别,并取得相当不错的效果.由于BERT 具有很强的语义表征优势,本文就利用BERT 获取语境化的词向量来提高实体识别的性能.但是本文采取的BERT模块与Fábio Souza[22]有不同之处:在对句子进行前期处理时,他采用的是以字符为单位进行切分句子.因此,这样的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被Mask.而本文则按照中文的分词习惯,于是将全词Mask[25]的方法应用到中文上,在全词Mask中,如果一个完整的词的部分被Mask,则同属该词的其他部分也会被Mask.具体如表1所示.

表1 全词Mask
具体BERT模型结构如图2所示.

图2 BERT模型结构
对于任意序列,首先通过分词处理得到分词文本序列;然后对分词序列的部分词进行全词Mask,再为序列的开头添加一个特殊标记[CLS],句子间用标记[SEP]分隔.此时序列的每个词的输出Embedding 由3部分组成:Token Embedding、Segment Embedding和Position Embedding.将序列向量输入到双向Transformer进行特征提取,最后得到含有丰富语义特征的序列向量.
对于BERT而言,其关键部分是Transformer结构.Transformer是个基于“自我注意力机制”的深度网络,其编码器结构图如图3所示.
该编码器的关键部分就是自注意力机制,它主要是通过同一个句子中的词与词之间的关联程度调整权重系数矩阵来获取词的表征:
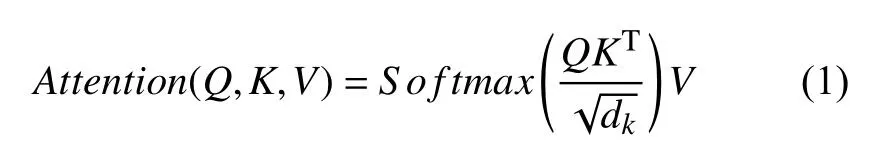
其中,Q,K,V是字向量矩阵,dk是Embedding 维度.而多头注意力机制则是通过多个不同的线性变换对Q,K,V进行投影,最后将不同的Attention结果拼接起来,公式如式(2)和式(3):
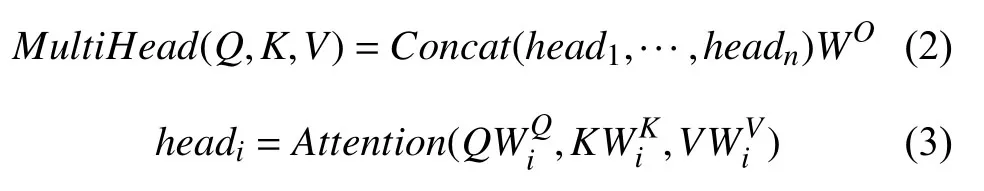
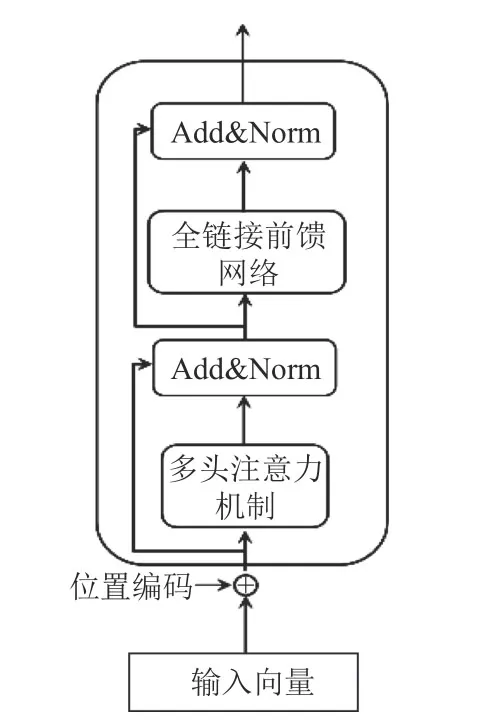
图3 Transformer编码器
因此模型就可以得到不同空间下的位置信息,其中W是权重矩阵.
由于Transformer 并没有像RNN 一样能够获取整个句子的序列能力,因此为解决这个问题,Transformer在数据预处理前加入了位置编码,并与输入向量数据进行求和,得到句子中每个字的相对位置.
而Transformer结构中的全链接前馈网络有两层dense:第一层的激活函数是ReLU,第二层是一个线性激活函数.如果多头注意力机制的输出表示为Z,b是偏置向量,则FFN(全链接前馈网络)可以表示为:
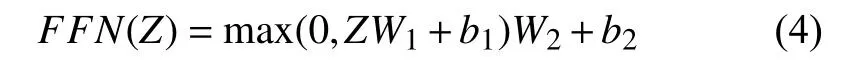
2.3 BiLSTM模块
LSTM (Long-Short Term Memory,长短期记忆网络),是循环神经网络(RNN)的一种变体.它解决了RNN 训练时所产生的梯度爆炸或梯度消失.LSTM 巧妙地运用门控概念实现长期记忆,同时它也能够捕捉序列信息.LSTM 单元结构如图4.
LSTM的核心主要是以下结构:遗忘门、输入门、输出门以及记忆Cell.输入门与遗忘门两者的共同作用就是舍弃无用的信息,把有用的信息传入到下一时刻.对于整个结构的输出,主要是记忆Cell的输出和输出门的输出相乘所得到的.其结构用公式表达如下:
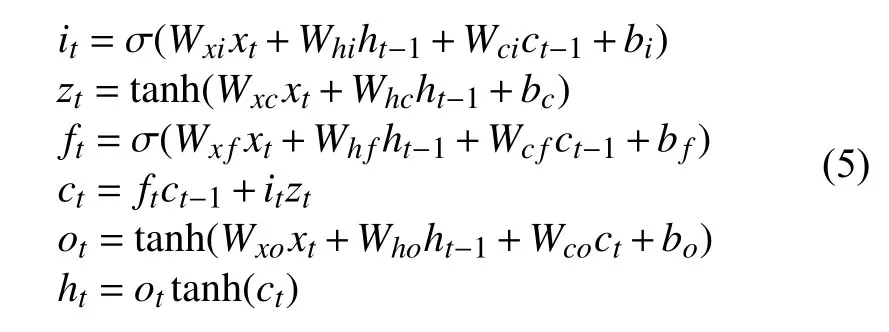
其中,σ是激活函数,W是权重矩阵,b是偏置向量,zt是待增加的内容,ct是t时刻的更新状态,it,ft,ot分别是输入门、遗忘门及输出门的输出结果,ht则是整个LSTM 单元t时刻的输出.
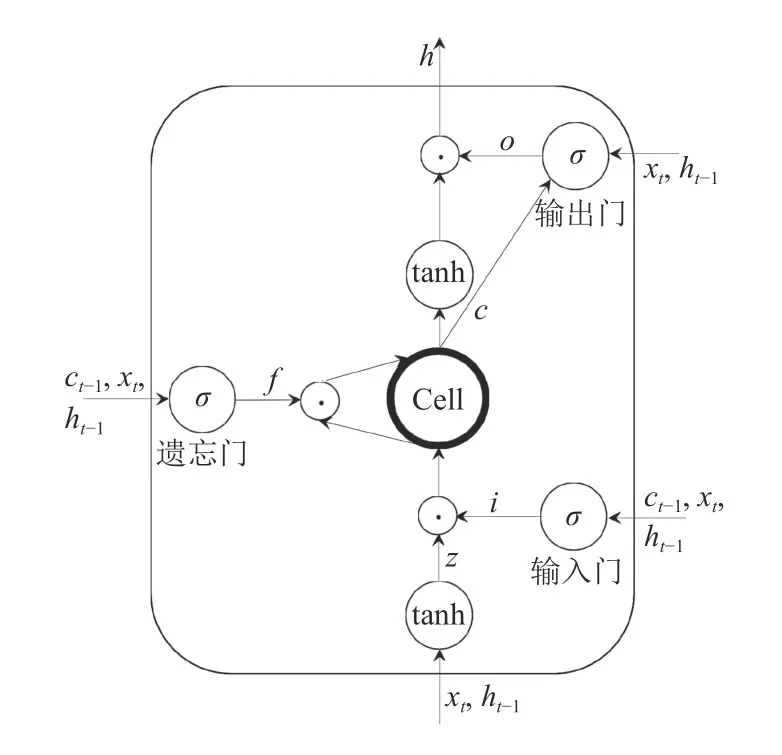
图4 LSTM 单元结构
由于单向的LSTM模型无法同时处理上下文信息,而Graves A 等人[26]提出的BiLSTM (Bidirectional Long-Short Term Memory,双向长短期记忆网络),其基本思想就是对每个词序列分别采取前向和后向LSTM,然后将同一个时刻的输出进行合并.因此对于每一个时刻而言,都对应着前向与后向的信息.具体结构如图5所示.其中输出如以下式所示:

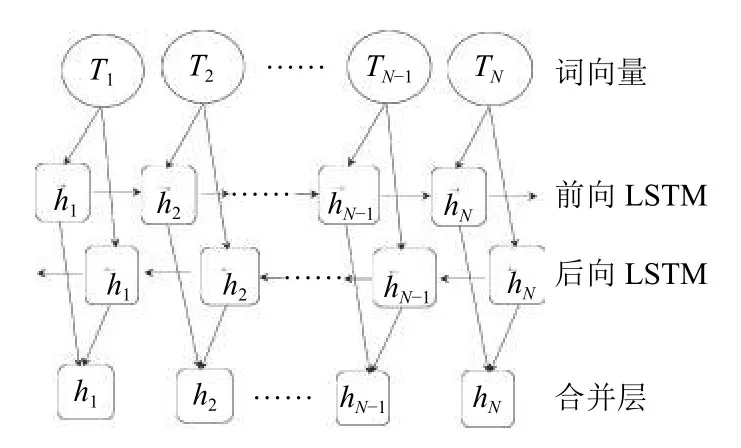
图5 BiLSTM模型结构
2.4 CRF模块
在命名实体识别任务中,BiLSTM 善于处理长距离的文本信息,但无法处理相邻标签之间的依赖关系.而CRF 能通过邻近标签的关系获得一个最优的预测序列,可以弥补BiLSTM的缺点.对于任一个序列X=(x1,x2,···,xn),在此假定P是BiLSTM的输出得分矩阵,P的大小为n×k,其中n为词的个数,k为标签个数,Pij表示第i个词的第j个标签的分数.对预测序列Y=(y1,y2,···,yn)而言,得到它的分数函数为:

A表示转移分数矩阵,Aij代表标签i转移为标签j的分数,A的大小为k+2.预测序列Y产生的概率为:
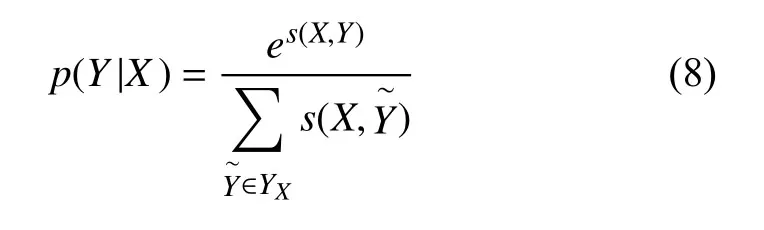
两头取对数得到预测序列的似然函数:
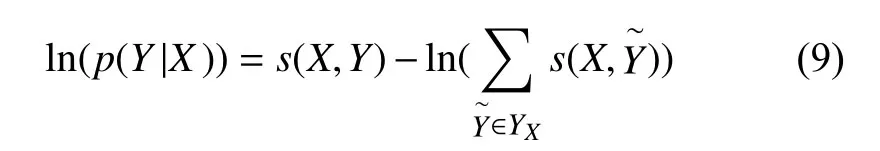
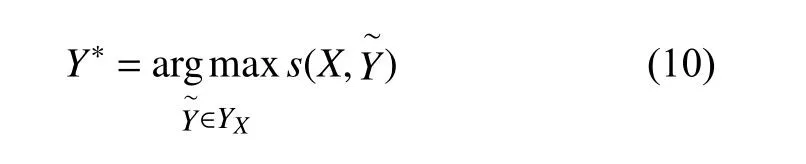
3 实验结果与分析
3.1 实验数据集
本文主要采用人民日报语料库和MSRA语料作为实验的数据集,这两个数据集是国内公开的中文评测数据集.它们包含了3种实体类型,分别是人名、地名和组织机构.本实验主要对人名、地名以及组织机构进行识别评测.语料具体规模如表2所示.

表2 语料规模介绍(单位:句)
3.2 数据集标注与评价指标
命名实体识别常用的标注体系有BIO体系、BIOE体系以及BIOES体系,本文选用的是BIO体系,该体系的标签有7个,分别是“O”、“B-PER”、“I-PER”、“B-ORG”、“I-ORG”、“B-LOC”、“I-LOC”.
本文采用召回率R、精确率P和F1值来评判模型的性能,各评价指标的计算方法如下:
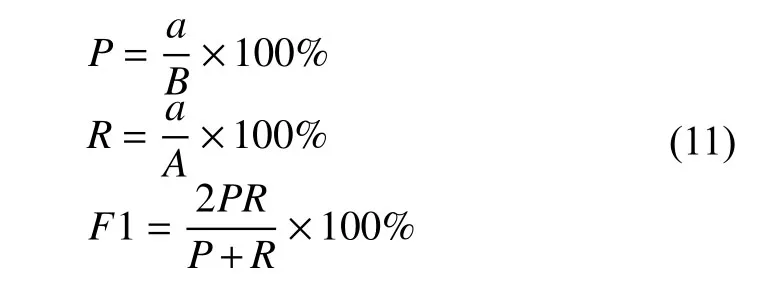
式中,a是识别正确的实体数,A是总实体个数,B是识别出的实体数.
3.3 实验环境与实验参数配置
3.3.1 实验环境配置
本实验是基于Tensorflow平台搭建,具体训练环境配置如表3所示.

表3 训练环境配置
3.3.2 实验参数配置
训练过程中,采用Adam 优化器,学习速率选取0.001.同时,还设置LSTM_dim为200,batch_size为64,max_seq_len为128.为防止过拟合问题,在BiLSTM的输入输出中使用Dropout,取值为0.5.具体超参数设定如表4所示.
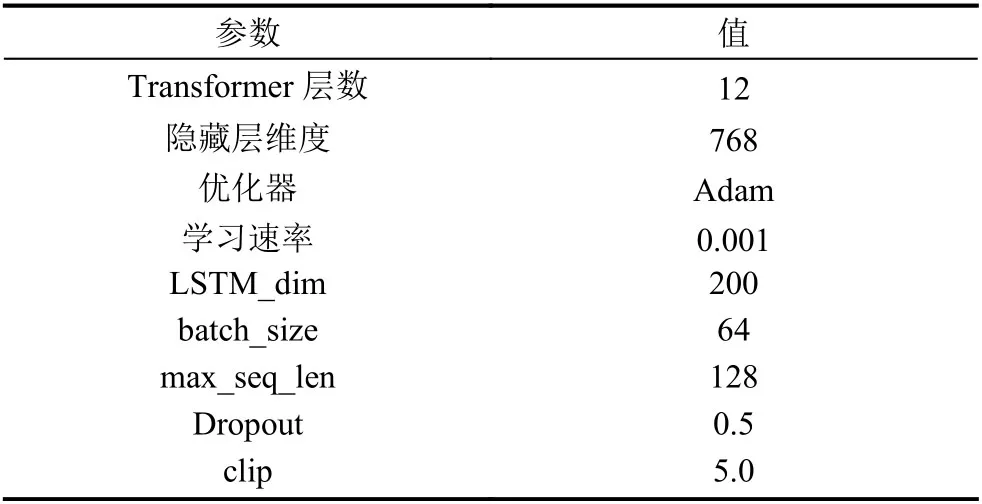
表4 参数设置
3.4 实验结果
为了对本文模型做出更加客观的评价,本文分别对人民日报语料和MSRA语料进行测评,具体实验结果如表5至表8所示(注:表中的BERT-BiLSTMCRF指的是全词Mask下的BERT-BiLSTM-CRF).
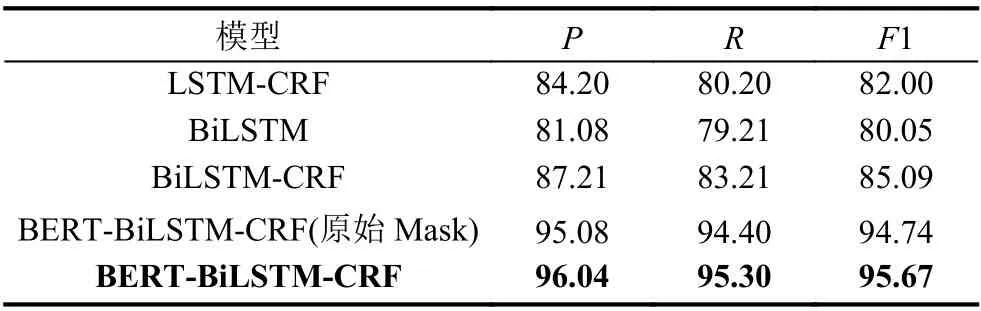
表5 人民日报语料测试结果(单位:%)
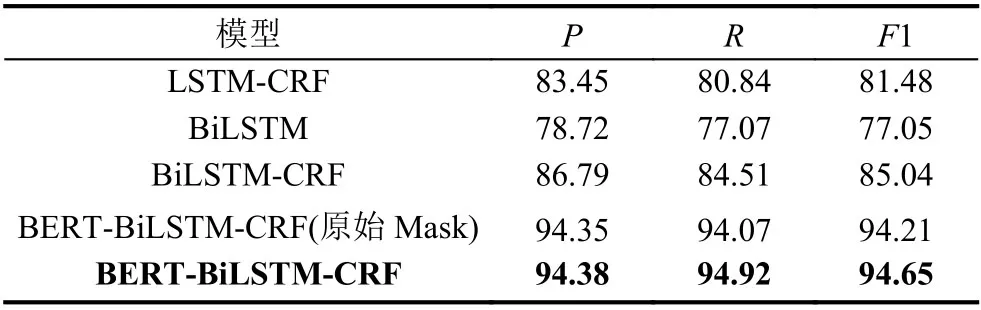
表6 MSRA语料测试结果(单位:%)

表7 训练时间(单位:s)
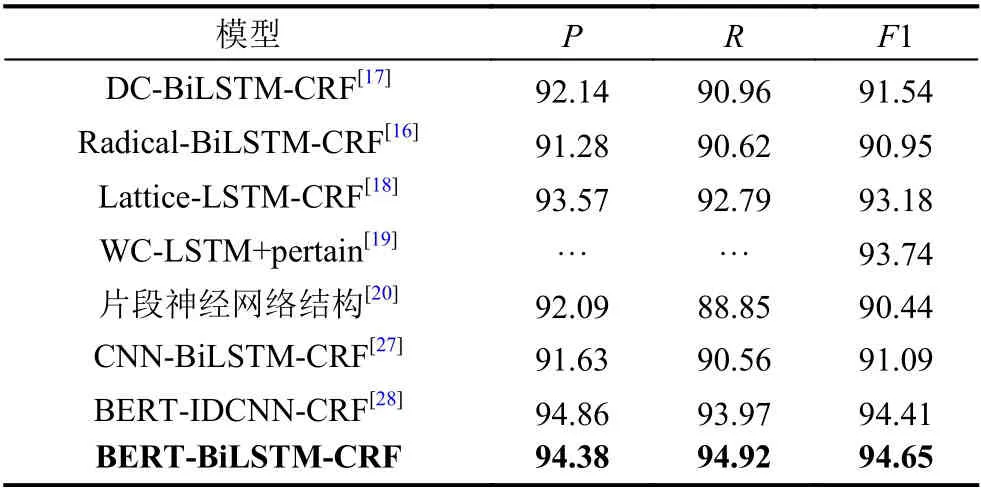
表8 在MSRA语料测试的模型对比(单位:%)
3.4.1 BERT-BiLSTM-CRF和传统经典神经网络模型的对比实验
首先,比较LSTM-CRF和BiLSTM-CRF这两者实验结果,后者的F1值在人民日报语料和MSRA语料上比前者分别高出3.09%、3.56%.从此可看出,BiLSTM能够利用双向结构获取上下文序列信息,因此效果要优于LSTM.其次,比较BiLSTM与BiLSTM-CRF的实验结果,增加CRF模块后,F1值在两者语料上分别提高了5.04%、7.99%,这主要归因于CRF模块能够充分利用彼此相邻标签的关联性,像“B-PER I-ORG ···”这样的标签序列无法有效地输出,从而可以获得全局最优的标签序列,进而能够改善实体识别性能.随后在BiLSTM-CRF的基础上,引入BERT模型(原始Mask)进行词向量预处理,从实验的各项指标来看,效果相当理想,F1值高达94.74%、94.21%,同比BiLSTMCRF模型,F1值已经提高了9.65%、9.17%.加入的BERT模型,该模型可以充分提取字符级、词级、句子级甚至句间关系的特征,从而使预训练出来的词向量能够更好地表征不同语境中的句法与语义信息,进而增强模型泛化能力,提高实体识别的性能.当全词Mask取代原始Mask的BERT时,在人民日报语料、MSRA语料上分别提高了0.93%、0.44%,说明其提取的特征能力更强.
此外,本文还对比分析了前20轮的F1值更新情况(以人民日报测试结果为例),如图6所示.在训练初期,两种BERT-BiLSTM-CRF模型就能够达到一个较高的水平,并且会持续提升,最后保持在相当高的水平上;而对于传统经典神经网络模型,在初期就处于一个相当低的水平,只有经过多次迭代更新才会上升到一个较高的水平,但还是无法超过BERT-BiLSTM-CRF模型.
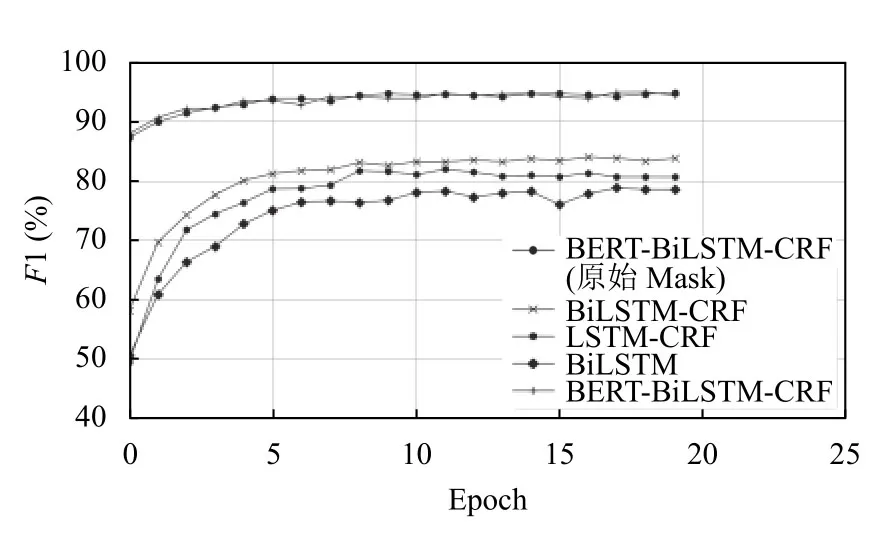
图6 F1值更新情况
同时也对比各模型训练一轮所需的时间(以人民日报测试结果为例),如表7所示.
值得比较的是后两个模型,BERT-BiLSTM-CRF(原始Mask)训练一轮的所需时间是本文模型的15倍左右,而且本文模型的训练时间在所有模型中是最少的,说明全词Mask的BERT 具有更高的训练效率.
3.4.2 BERT-BiLSTM-CRF和现有其他工作的对比
从表8中可以看出,DC-BiLSTM-CRF模型利用DC-BiLSTM来学习句子特征,应用自注意力机制来捕捉两个标注词语的关系;Radical-BiLSTM-CRF模型使用双向LSTM提取字根序列的特征,然后与字向量拼接组成模型的输入;Lattice-LSTM模型则是把传统的LSTM单元改进为网格LSTM,然后显式地利用词与词序信息,避免了分词错误的传递;对于WC-LSTM而言,则是利用词语信息加强语义信息,减少分词错误的影响;片段神经网络结构通过片段信息对片段整体进行分配标记,从而完成实体识别.这几种改进模型很大程度上提高了F1值.
但是上述的改进模型始终停留在对字符和词语特征的提取,导致这些改进模型有一定的局限性.例如,“南京市长江大桥”,这个短语可以理解为“南京市-长江大桥”,以也可以理解为“南京市长-江大桥”,然而上述的模型只能获取其中的一种意思,无法同时表征两种意思.而本文提出的BERT-BiLSTM-CRF模型能很好地解决这个问题.BERT是构建于Transformer之上的预训练语言模型,它的特点之一就是所有层都联合上下文语境进行预训练.因此BERT模型网络不仅可以学习到短语级别的信息表征以及丰富的语言学特征,而且也能够学习到丰富的语义信息特征.对于上面的“南京市长江大桥”这个例子,BERT根据上下文不同的语境信息能够准确区分出这两种意思.所以本文提出的BERT-BiLSTM-CRF与BERT-IDCNNCRF模型两者相差不大,而本文模型的F1值在MSRA语料上达到了94.65%.通过对上述多种模型的对比分析,BERT-BiLSTM-CRF模型在所有模型中都表现出最佳的效果,说明BERT相比其他模型,其特征抽取能力更强.
4 结语
针对中文实体识别任务,本文通过BERT语言预处理模型获得语境化的词向量,再结合经典神经网络模型BiLSTM-CRF,构建BERT-BiLSTM-CRF模型.在人民日报语料库和MSRA语料上分别进行评测,相比其他模型,本文的BERT-BiLSTM-CRF模型在这两者语料上都取得了最佳的结果.本文模型,其最大的优势在于BERT能够结合上下文的语义信息进行预训练,能够学习到词级别、句法结构的特征和上下文的语义信息特征,使得该模型相比其他模型,具有更优的性能.同时利用BiLSTM对词向量做进一步处理,再结合CRF的优势,进一步提高了中文实体识别的效果.下一步工作可以考虑将其应用到其他领域,进行相应的领域实体识别.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
现代计算机(2021年33期)2022-01-21
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
中国诗歌(2017年12期)2017-11-15
高中生学习·高三版(2016年9期)2016-05-14
