
基于改进K近邻算法的小型汽车号牌识别系统
2020-07-24 02:11马志远余粟
软件导刊 2020年6期
关键词:车牌识别
马志远 余粟

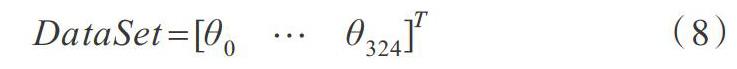

摘要:为了对现有小型汽车号牌识别系统进行优化,改善车牌字符识别系统性能,借助OpenCV图像处理开源库,在车牌图像顸处理阶段采用均值滤波方法提高图像质量,采用Sobel边缘检测算子对图像边缘进行提取,利用交替的膨胀、腐蚀操作结合车牌长宽比实现车牌轮廓定位,并根据列像素值对车牌字符进行切割,最后采用改进的K近邻算法对分割后的单个车牌字符进行识别.实验结果表明,基于改进K近邻算法的车牌识别系统处理时间为2.08s,识别正确率达91.3%。与传统的K近郃算法相比有着更高的识别率,与神经网络法相比,有着更快的识别速度。
关键词:均值滤波;Sobel边缘检测;车牌识别;改进的K近邻算法
DOI:10.11907/rjdk.192090 开放科学(资源服务)标识码(OSID):
中图分类号:TP317.4文献标识码:A 文章编号:1672-7800(2020)006-0231-04
0 引言
随着人民生活水平的不断提高,小型汽车销量稳定增长,汽车保有量不断攀升。汽车在给人们带来便利的同时也带来了交通拥挤、环境污染等一系列社会问题,这些问题随着汽车数量的增加日益严重。因此,学者们提出了智能交通系统,诞生了车牌识别LPR(License Plate Recognition)技术。该技术经过不断发展,逐渐成为智能交通系统的重要组成部分。车牌识别系统不仅可以实现车辆快速进出,减少碳排放量和车辆损耗,降低PM2.5,而且可以显著降低交通管理中的运营成本,节约人力资源,提高服务质量。
车牌字符识别算法是评判一个车牌识别系统性能的重要依据,直接影响整个系统性能。为了实现字符的智能识别,相关学者已经研究出很多识别方法,如模板匹配法、支持向量机SVM(Suppofl Vector Machine)法、神经网络法等。
(1)模板匹配法:通过建立字符模板数据库,将待检测车牌字符图像矩阵与字符模板库中标准字符矩阵进行对比,根据待检测图像与模板图像两者之间的相似程度,对输入图像进行判断。
(2)SVM法:SVM法分为训练阶段和测试阶段,训练阶段对训练集的样本进行特征提取,然后设置SVM参数并训练出SVM分类器;测试阶段将待检测的车牌字符样本进行特征提取,将特征带人已经训练好的SVM分类器,计算出决策值,根据决策值判断样本所属的类别。
(3)神经网络法:神经网络通过训练样本的输入,根据网络输出结果与期望输出调整网络内部各神经元之间的连接关系,从而构建一个分类模型,根据分类模型得到测试数据的识别结果。
为提高车牌字符识别系统准确率,在以上方法基础上学者提出了不同的改进策略,如文献[8]、文献[9]在模板匹配基础上,首先建立字符识别模板库,将分割后的车牌字符与模板库中的字符进行距离运算,以最大相关算子对应的模板为最佳匹配模板,但这种方法没有考虑相关算子大小对预测输出的影响程度;文献[10]、文献[11]中基于支持向量机的识别方法在解决多分类问题时存在固有缺点;文献[12]、文献[13]采用卷积神经网络方法,需要进行大规模数据训练,计算过程过于复杂。以上研究都没有设计出一种简洁、有效的车牌字符识别算法。
本文通过在车牌字符识别中采用改进的K近邻算法,在识别输出阶段增加了输人数据与模板数据之间距离大小对预测输出影响程度这一因素,弥补了传统K近邻算法中距离邻近的类别被认为是相同的缺点,从而对车牌识别系統中传统的K近邻算法进行了改进。
1 车牌识别系统
车牌识别系统流程有4个步骤:①车牌图像预处理;②车牌定位;③车牌字符分割;④单个车牌字符识别,系统总体设计如图l所示。本文针对车牌识别系统每个环节设计了不同算法,通过利用开源计算机视觉库OpenCV(Open Source Computer Vision Library)中提供的处理工具,对每一过程进行仿真实验。
2 车牌图像预处理
2.1 车牌图像灰度化
彩色车牌图像每个像素点由红绿蓝(RGB)3种色彩叠加构成,不同的色彩通道值不尽相同。在识别系统中,为了方便对像素数据进行处理,采用加权平均法把RGB三通道图像转换为单通道灰度图像,即对车牌图像中每个像素的R、C、B值加起来求平均值,求得每个像素点的平均值作为车牌灰度图像的像素值。
由公式(1)计算得到的所有灰度值构成新灰度图像。图2为原始车牌图像,图3为灰度化的车牌图像。
2.2 均值滤波
由于车牌图像在采集过程中所处的环境不同,以及受限于采集图像设备性能,使采集到的车牌图像存在各种各样的噪音,这些干扰信号会使图像质量降低,给车牌识别工作带来困难。因此,对采集到的图像进行滤波操作是消除干扰信号的重要措施。在车牌定位之前,要对采集到的车牌图像进行滤波操作,在保留原始车牌特征基础上,过滤掉干扰信号,尽量减少噪声带来的影响。均值滤波是低通数字滤波的一种,具有效率高、执行速度快的优点,采用3*3的均值滤波卷积核对灰度化的车牌图片进行滤波操作,以过滤掉图像中存在的噪音。均值滤波的卷积核为:
具体操作步骤为:对于卷积核锚点(带“”的位置)覆盖下的像素点,其像素值等于3*3邻域范围内所有像素值的和进行均值滤波,得到的图像如图4所示。
2.3 边缘提取
车牌图像边缘提取就是获取车牌图像中像素阶跃较大的像素群,这些像素群中包含车牌轮廓,边缘提取为接下来的车牌定位打下了基础。Sobel算子常用于获取图像的一阶梯度值,分别用3*3的水平方向卷积核和垂直方向卷积核对均值滤波后的图像进行卷积操作,求出车牌图像中每个像素值的横向梯度值和纵向梯度值。
得到图像每个像素点的梯度。设置阈值,如果该像素点的梯度值C大于Dt,就认为该点是边缘点,对该像素点予以保留;如果梯度值小于Dt,就将其舍弃。提取边缘后的图像如图5所示。
2.4 形态学车牌定位处理
2.4.1 形态学处理
数学形态学是一门建立在集合论基础上的学科,在图像处理领域应用广泛,其基本操作包括:膨胀(Dilate)、腐蚀(Erode)。膨胀操作可以连接相近的图像区域,腐蚀操作可以去除孤立区域,通过交替进行的膨胀、腐蚀操作,找到包含车牌信息的矩形轮廓结构。本文为使车牌字符区域能够连通起来,依次进行两次横向的膨胀操作,再经过4次迭代腐蚀操作,以尽可能多地去除车牌图像之外的小块碎片区域,最后再进行两次膨胀操作,以恢复由腐蚀操作造成的车牌图像不连通区域。经过形态学处理的图像如图6所示。
2.4.2 车牌轮廓查找与筛选
图6中3块白色图形其中一个包含了车牌的轮廓与位置信息,车牌轮廓查找与筛选要从这3个图形中选出正确的车牌轮廓。分别计算这3个图形水平方向与垂直方向上不为0的像素点个数,作为其长(Height)与宽(Width);根据设置车牌长宽比参数i(2.5
3 车牌字符分割
车牌字符识别是一种基于单字符的识别方法,识别的前提是对连通的车牌图像进行分割,获得单字符图像。车牌字符的正确分割直接影响到字符识别环节,因而在车牌字符分割前,对车牌图像进行预处理就显得尤为重要。
3.1 车牌字符分割预处理
首先对提取出的车牌进行灰度化、二值化等操作,便于车牌像素信息的计算和统计。车牌边框在车牌字符识别中属于无用信息,需要去除。车牌边框是一些水平排列的像素点和垂直排列的像素点,定义阈值分别为车牌图像平均每行像素值和每列像素值的1.6倍,通过依次扫描图像中的行像素值与列像素值,与阈值进行比较,对低于阈值的行和列删除,以达到去除车牌边框的目的。去除边框后的车牌图像如图8所示。
3.2 基于列像素均值的车牌字符分割法
在车牌图像中,包含车牌字符区域白色较多,相应的列像素值较高,而没有字符的区域基本为黑色,相应的列像素值就较低。车牌字符分割方法可检测车牌图像列像素值的变化。首先计算所有列像素值的和S,然后求取列像素的均值,将阈值设置为所有列像素均值的70%。对车牌图像进行逐列扫描,求其列像素值,将超过阈值对应列的值置为“l”,直到找到一个低于阈值的列,并将其值置为“0”。
从Pc=1列开始,直到出现Pc=0的n列,中间的n-j列即为车牌字符分割长度len。为了增加字符分割的准确性,在得到字符分割宽度len之后,考虑到车牌中只有7个字符,再通过判断len的值与车牌宽度的1/7作比较,如果len大于车牌宽度的1/7,即视为合理分割宽度,否则视为不合理分割宽度。最后,根据得到的合理分割寬度进行车牌字符分割。车牌字符分割效果如图9所示。
4 基于改进K-近邻算法的车牌字符识别
我国小型汽车号牌字符包含3类,分别为以“京”、“沪”、“粤”等31个汉字代表省、自治区、直辖市简称,除去字母0和I的24个从A-Z的大写英文字母,以及0-9的10个阿拉伯数字。车牌字符识别目的是从已经分割的单个车牌字符图像中识别出对应的65个字符中的一个。K-近邻算法是分类数据最简单有效的算法,在车牌字符识别方面有着广泛应用。K近邻算法在输入新的分类对象时,会与已有模板数据进行比较,根据模板数据与输人数据距离的大小,从模板数据中选出与需要分类对象最为相似的模板数据作为预测输出。本文提出改进的K近邻算法,在获得输入数据与模板数据的距离后,根据距离权值得分相加得到标签的总得分,进而判断出输人数据所属的标签。
在互联网中收集字符65*5个车牌字符图像,依次对其进行裁剪、灰度化处理,得到28*28的单通道灰度图像。定义325个784列的行向量,对每个图像的784个像素值进行储存,通过矩阵合并构成325行784列的矩阵。
定义一个标签数组Labels,标签数组中的字符(例如“沪”、“K”)对应DataSet矩阵中的行向量。将分割出来的车牌字符图像同样转换为行向量θtest存储起来。根据DataSet矩阵行的大小,复制θtest成为与行数相等且每行都为θtest的矩阵lnx。
通过欧式距离公式计算lnx每行与DataSet对应行的距离di,从而得到矩阵D。
计算矩阵D元素总和Dsum并得到权值矩阵Q,其中权值矩阵Q中每个元素Qi的大小为:
对D中元素值进行大小比较,返回K个D中最小元素所对应的行标m21.…mk,取出Label中行标m所对应的字符标签以及对应的权值得分Qi,将相同标签的不同Qi加起来得到其标签得分M。标签得分M的最大值所对应的标签字符即为车牌识别系统识别出来的车牌字符。
5 实验结果与分析
为验证改进K近邻算法在小型汽车号牌识别系统中的有效性,对互联网上下载的400张不同天气、不同角度和不同照明条件下的车牌图像,在配置为Windows 10系统AMD Ryzen 52600@3.4GHz CPU,16G内存的计算机PYthon2.7平台上进行车牌字符识别实验,图10为本文示范车牌的识别结果。与传统K近邻算法、神经网络法进行对比,对图像集进行参照实验,实验结果如表1所示。
由表1可以看出,该算法与传统K近邻算法相比有更高的识别率,与神经网络法相比,具有结构简单以及更快的识别速度等优势。
6 结语
本文借助OpenCV图像处理工具,设计了一种小型汽车号牌识别系统,对传统K近邻识别算法进行了改进。首先对包含车牌信息的图像进行灰度化、滤波、边缘提取、形态学处理等操作,获取图像中可能存在的车牌图像轮廓,根据车牌的长宽比从目标轮廓中筛选出正确的车牌轮廓。获得车牌图像后,对其进行灰度化、二值化和去边框等预处理;然后采用基于列像素均值的车牌字符分割法,分割出车牌图像中的单个字符;最后采用改进的K-近邻算法将输人数据与模板数据之间的距离通过加权得分的方式运用到车牌字符识别中,使得识别系统对车牌字符的预测相比传统K近邻算法更加准确。但是本文对车牌图像的预处理阈值均是在不断调整中得到的,并没有找到一种合理的阈值确定方法;改进的K近邻算法如何针对不同模板数据集搜索一个最优K值,这些仍需要进一步研究。
