
基于贷款人视角的互联网金融信用风险分级研究
2020-07-24 02:11林奕皓王宇森李旭东许永峰
软件导刊 2020年6期
林奕皓 王宇森 李旭东 许永峰

摘要:为提升互联网金融行业贷款人决策的直观性与层次性,提出一种信用分级模型。对历史样本的信用评价指标进行主成分分析,提取关键信息。利用Logit回归模型得到“是否违约”和“评价指标主成分”的关系,依据回归方程所得的“违约概率”对借款人进行信用分级。采用遗传模拟退火算法(GSAA)改进的BP神经网络,学习“等级”和“评价指标”间的映射规则。利用Kaggle网站信用数据集进行实验,结果表明,Logit回归结果可信度高,“依概率分级”区分度高,GSAA算法可有效提升BP神经网络的精准分级率。分级模型在测试样本上的可信度为99.02%,优于二值分类和指标赋权模型,可有效降低贷款人资金风险,推动互联网金融行业高质量发展。
关键词:互联网金融;信用等级;Logit模型;BP神经网络;遗传模拟退火算法
DOI:10.11907/rjdk.201160 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)006-0029-06
0 引言
随着普惠金融政策不断推进,互联网金融行业持续发展。在过去几年,网络借贷产业作为一种创新借贷模式,将互联网技术、电子商务技术、民间借贷资本市场和金融服务模式有机结合,突破民间借贷地域受限、市场规模小、需求难匹配等局限,提高传统金融市场效率,在一定程度上实现金融借贷民主化与公开化。
作为互联网金融借贷的代表,P2P网络借贷在发展过程中产生诸多问题,面临很大风险,不少贷款人面临巨大投资损失。征信体系不完善、披露机制不健全、监管法规不够有效等因素严重制约网络借贷产业发展。2019年9月,互联网金融风险专项整治工作领导小组发布《关于加强P2P网贷领域征信体系建设的通知》,明确互联网金融信用评估的重要性。2020年以来,全国范围持续推进网络借贷行业出清,不少P2P平台机构向小贷公司转型,申请互联网小贷牌照。当前,借贷行业风险出清呈加速趋势,其中信用风险问题始终是社会热议话题。
由此可见,建立有效的借款人信用评估模型,有利于贷款人作出合理决策,保障贷款人资金安全,也有利于网络借贷产业走出发展困境,推动互联网金融产业高质量发展。
1 文献述评
近年来,针对借款人建立信用评价模型的研究较多,主要有主客观组合赋权、回归分析和机器学习3种方法。当前,绝大多数学者将研究重心放在算法改进与创新上,追求更高的预测精度。本文从信用评价结果形式角度梳理相关文献,将其分为二值分类和得分评定两种。
基于二值分类模型针对借款人是否违约进行预测。该模型将信用评价归结为0-1二值分类问题:不违约或违约。如Altman基于二值分类提出Z-score模型,将回归分析方法应用于信用评价领域;Desai等、王春峰等通过判别分析建立信用评价模型;许艳秋等利用层次分析法计算指标权重,用支持向量机对个人信用数据分类;刘潇雅等利用C4.5信息熵增益率进行属性选择,将基于支持向量机的信用评估模型优化;杨胜刚等利用决策树方法筛选个人信用指标,结合BP神经网络建立两阶段信用评估模型;李淑锦等通过纳入宏观经济变量,提高P2P平台借款人信用评估预测精度;熊志斌通过引入混沌和小生境技术,提出一种改进粒子群算法,结合模糊神经网络预测公司信用状况。
基于得分评定的模型针对借款人信用量化得分进行预测。这种模型主要利用主客观赋权给评价指标确定权重,构建信用评价测度体系。如Che等使用数据包络法和模糊层次分析法赋权,构建台湾中小企业信用评分模型;张目等应用可变模糊集理论和相对熵指标组合赋权,构建战略性新兴产业信用评价模型;陈晓红等利用层次分析法主观赋权,利用因子分析法客观赋权,设计一种改进的模糊综合评价信用模型;李步军等采用灰区间关联分析对信用评价指标赋权,构建个人信用评估模型;李战江将Logit回归和统计抽样中的分层思想结合,构建小企业信用评价模型。
对上述模型设计进行分析发现存在以下局限:
(1)对于二值分类模型,模型预测输出是二元离散变量:违约或不违约。考虑整个借贷市场处于不同信用水平的借款人数量应满足某个概率分布,不局限于好客户或坏客户兩个极端。二值分类评价结果有局限性,评价层次感不足。
(2)对于得分评定模型,模型预测输出是连续变量:信用评分值。若贷款人是个人,由于其它借款人信息的保密性,贷款人较难通过一个具体得分值评估出借款人信用在全体人员中的相对排名。若贷款人是企业或公司,由于评分具有个体差异性,贷款公司难以开展分级管理,不利于业务精简。
综合以上分析,有必要建立基于等级划分的信用评估模型,为贷款人提供更全面的决策参考。此外,信用等级划分有利于借款人认清自身信用的相对水平,提高借款人对信用的重视程度,规范借贷行为,降低坏账风险。近年来也有少数学者构建的模型蕴含该思想,如张成虎等结合层次分析法和决策实验室法确定指标体系权重,将评级得分换算成具体的信用等级。本文基于上述研究,创新地提出用Logit回归方程所得的违约概率对历史借款人信用进行等级划分,利用BP神经网络预测借款人信用等级,为完善我国个人信用评价体系提供参考。
2 模型构建
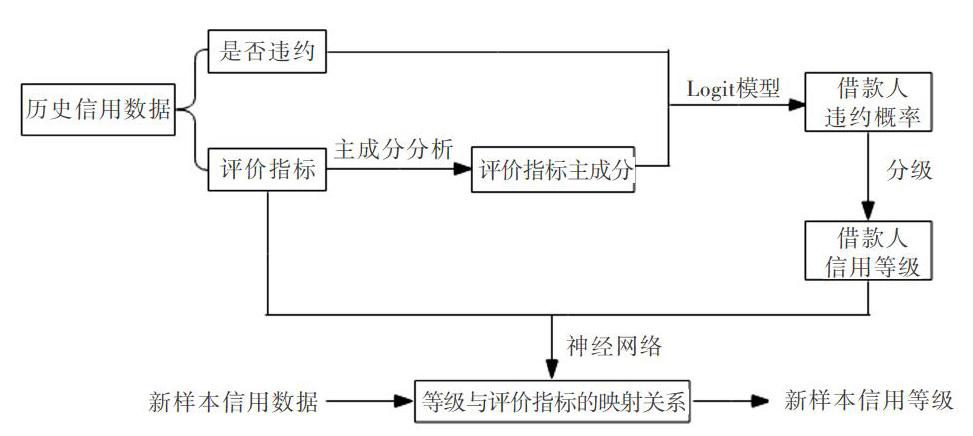
信用分级模型设计思路:提取历史样本中信用评价指标主成分,减小指标间相关程度,从而避免Logit回归出现严重的多重共线性问题;利用Logit回归构建“是否违约”和“评价指标主成分”关系;利用Logit回归方程得到的违约概率对样本划分等级;通过训练BP神经网络,获取“等级”和“评价指标”的映射规则。利用训练好的BP神经网络分析新样本的信用等级。模型构建流程如图l所示。
2.1 主成分分析
对历史样本中的信用评价指标进行主成分分析,所得主成分作为Logit模型的输入变量。若统计检验显示指标变量不适合主成分提取,则直接将各评价指标视为主成分。
主成分分析通过线性变换降维思想,在丢失很少信息的前提下把多个指标转化为若干个不相关指标。历史样本中信用评价指标主成分提取步骤如下:
(1)设数据集中样本个数为n,原始评价指标个数为p,xij为第i个样本中第j个评价指标值。根据式(1)对原始数据作标准化处理:
(2)根据标准化后的数据矩阵计算相关系数矩阵和相应的特征值λj。
(3)根据式(2)计算各特征值的贡献率η,将贡献率从大到小排序:
选择累计贡献率大于85%(有时也取80%或90%)的特征值λj所对应的主成分作为原始评价指标进行替代。
2.2 Logit回归与等级划分
利用Logit回归构建历史样本中“是否违约”和“评价指标主成分”的映射关系。设被解释变量“是否违约”为y,解释变量“评价指标主成分”为x1,x2,…xk。由于y是二分性质变量,即违约(1)或不违约(0),故选用的分类器函数形式为:
根据式(3)可得每个样本的违约概率,基于违约概率对历史样本分级。假设将样本分为M级,信用等级最高的为R1,最低的为RM,等级为i的样本占总体比例为ri,得到的分级结果如表1所示。
2.3 GSAA-BP神经网络
通过等级划分,可得每个历史样本的评价指标和对应的信用等级。利用BP神经网络学习“等级”和“评价指标”映射规则。为获得更优的神经网络,采用遗传模拟退火算法(GSAA)优化神经网络的初始阈值与权值。对于新样本,只需将评价指标输入训练好的神经网络即可得到对应的信用等级。
2.3.1 BP神经网络
BP神经网络具有自学习能力,利用梯度搜索技术学习输入到输出的非线性映射关系。三层BP神经网络具有很好的映射能力,将隐含层设定为一层。BP神经网络结构如图2所示,输人为所有信用评价指标,输出为对应的信用等级。
2.3.2 遗传模拟退火算法(GSAA)优化神经网络原理
BP神经网络收敛速度较慢,训练时容易陷入局部最优解,因此选用遗传模拟退火算法优化神经网络权值与阈值。遗传模拟退火算法是一种混合智能算法,遗传算法基于仿生思想,能有效处理目标函数和约束条件相关的优化问题,但在实际应用中存在早熟、局部范围搜索能力较差等缺点,模拟退火算法能较好地弥补这些缺陷。
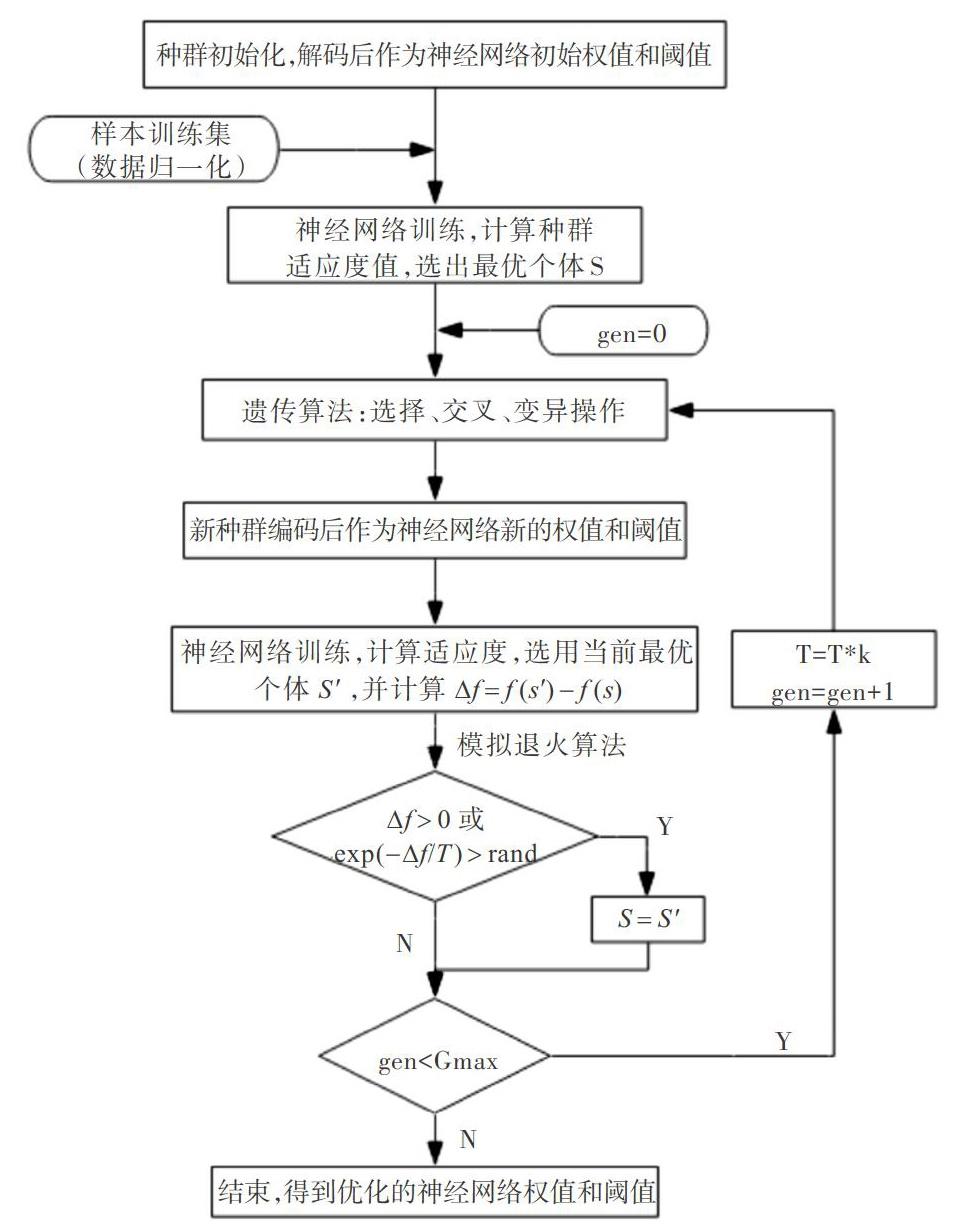
遗传模拟退火算法优化神经网络初始权值与阈值步骤如下:
(1)种群初始化。随机给定一系列神经网络初始权值与阈值称其为种群。其中每一组初始权值与阈值称为个体。优化神经网络初始权值与阈值过程就是选取最优个体过程。
(2)选取个体适应度函数。个体适应度厂取期望输出和预测输出的误差均值的倒数,即:
式(6)中,N为神经网络输出个数。实际与预测输出误差越小则适应度越大。
(3)遗传算法。遗传算法根据个体对样本数据的适应度对种群实现寻优,使问题解空间不断逼近最优解,算法分为选择、交叉、变异3部分。
选择操作:利用赌轮盘思想,设种群大小为M,个体j的适应度为fj,则个体j被选择的概率为:
个体适应度和被选择的概率成正比,可保证择优原则。
交叉操作:交叉操作指交换个体之间的遗传基因从而产生新的个体。设两个体分别为Xa和Xb,对每个基因作以下交叉运算:
式(8)中,r为[0,1]中均匀分布的随机数。
变异操作:在个体基因中随机选取一个变异元,根据变异元取值范围随机选取一个数代替原来的基因取值。
(4)模拟退火算法。假设初始适应度最高的个体为S,经过遗传算法操作后得到新的种群中适应度最高的个体为S'。若。f(S')≥f(S),则令S'为当前最优解;若f(S')T,接受S'为当前最优解。概率PT计算公式为
式(9)中,T为当前迭代温度,经过每次迭代温度都会依据冷却系数而降低。
(5)判断算法是否终止。根据设定的迭代次数判断算法是否终止。若是则计算当前所有个体适应度,选择具有最高适应度的个体作为最终取值;否则转步骤(3)。
利用遗传模拟退火算法优化BP神经网络权值与阈值步骤如图3所示。
图3中,f为适应度函数,gen为循环计数器,T为当前温度值,k为冷却系数,rand()表示[0,1]之间的随机数,Gmax为最大遗传代数。
3 实验分析
3.1 数据说明
3.1.1 样本选取
本文实验数据来自Kaggle网站Give me some credit信用数据集。该数据是当地银行开展线上贷款业务搜集的数据,共有150000条,其中违约样本点有10026个,占总样本点的6.68%;特征变量有10个,分类变量1个:0代表不违约,1代表违约。具体描述如表2所示。
3.1.2 数据处理
数据集存在缺失值和异常值。对于缺失值,由于样本数据量大,要删除缺失值所在样本。对于异常值,采用箱线图法处理。由于样本具有不平衡性,部分變量(x3、x7、x9)在处理后的取值仅有1个,根据实际经验增加可能的取值。经处理,样本共有102699条数据,其中违约样本点有6139个,占总样本点的5.98%。
随机选取80%的样本(82159个)作为训练集,剩余20%的样本作为测试集。为消除变量间量纲不同带来的影响,采用最小最大规范化方法对数据归一化处理,将变量取值映射到[0,1]区间内,转换公式如下:
式(10)中,Xmax和Xmin。分别表示变量取值的最大值和最小值。
3.2样本分级
对训练集中的信用评价指标进行KMO和Bartlett球形度检验,得KMO值为0.54。评价指标不适合做主成分分析,将各指标视作主成分,作为Logit模型的解释变量。
首先将所有评价指标引入方程,Logit回归结果显示x8的系数在10%的显著性水平下不显著,故剔除x8后再次求解,结果显示回归结果在1%的显著性水平下通过检验。各变量回归系数如表3所示。
分析回归系数符号,可知贷款数量、逾期拖欠次数、生活负担人数等指标对违约具有正向影响,月收入等指标具有负向影响,这符合实际认知,进一步说明模型结果可信。利用Logit回归方程计算得到的违约概率对训练集样本分级。不失一般性,考虑将训练样本分为5级。假设训练集中违约样本比例为a,将违约概率排名百分比位于a后的样本归人E级,其余样本平均划分,结果如表4所示。
由等级划分结果可知,随着信用等级降低,违约样本比例逐步提升,表明基于违约概率对样本等级划分的方法是科学的。
3.3 GSAA-BP神经网络建立
3.3.1 隐含层神经元个数确定
建立三层BP神经网络,输人层是信用数据集的10个原始评价指标,输出层为等级划分结果。将训练集样本分为BP神经网络训练集和BP神经网络验证集两组,其中BP神经网络训练集占80%,为65727条,用于训练含有不同隐含层的BP神经网络。令等级为A、B、C、D、E样本的网络输出分别为1,2,3,4,5。对于某样本,若网络预测输出值与实际值误差小于等于0.05,则称该样本实现精准分级。根据不同神经网络在BP神经网络验证集上的精准分级率确定隐含层神经元个数。
神经网络有关参数设定如下:训练函数为trainlm函数,隐含层传递函数为tansig函数,输出层传递函数为purelin函数,最大训练次数为10000,学习率为0.01,最大训练精度为10-3。BP神经网络训练结果如图4所示。
由图4可知设定BP神经网络隐含层神经元个数为20。
3.3.2 GSAA-BP神经网络训练
沿用前文使用的训练参数,设定BP神经网络网格结构为10-20-1。在BP神经网络训练集上训练GSAA-BP神经网络,然后在BP神经网络测试集上检验相应的精准分级率,取精准分级率最高的GSAA-BP神经网络用于新样本的信用等级评估。遗传模拟退火算法有关参数设定如下:最大遗传代数为30,种群规模为10,交叉概率为0.9,变异概率为0.05,初始温度为100,冷却系数为0.95。
为验证遗传模拟退火算法对神经网络优化的有效性,在BP神经网络训练集上分别训练GSAA-BP神经网络和普通BP神经网络,将这两种神经网络应用于神经网络验证集,通过5次重复试验对比精准分级率,结果如图5所示。
由图5可知,GSAA-BP神经网络效果更优。对于神经网络验证集,普通BP神经网络平均精准分级率为86.1%,而GSAA-BP神经网络平均精准分级率达96.0%,说明遗传模拟退火算法对神经网络的优化有效。
3.4 模型检验与分析
3.4.1 模型可信度指标
基于贷款人视角建立模型可信度指标。根据借款人信用预测结果确定可靠借款人群体,则贷款人更愿意把资金借给该群体借款人。设可靠借款人群体人数为n1,其中实际违约人数为m1,构建模型可信度指标β如下:
由式(11)可知,模型的β值越高,贷款人的资金安全越有保障,该模型在实际运用中更有优势。
3.4.2 模型可信度指标对比
计算分级模型可信度指标,利用训练好的GSAA-BP神经网络对20540个测试样本分级,将测试样本的10个信用评价指标作为神经网络输入可得到对应的信用级别。一般来说,贷款人倾向借款给信用等级为A、B的借款人,故可靠借款人群体为信用等级A、B的样本。经计算得模型可信度为99.02%,远高于测试集样本中不违约的样本比例94.02%,初步说明构建的信用分级模型有效可信。
为进一步说明分级模型优势,将该模型与二值分类模型作对比。基于二值分类的模型将借款人分为好客户和坏客户两类,故可靠借款人群体预测结果为好客户样本。针对训练集,依次选取Logit回归、BP神经网络、KNN、支持向量机(SVM、SVC)、决策树算法、随机森林算法、XGBoost算法建立二分类模型。将模型运用于测试集,所得可信度与分级模型对比并排序,结果如表5所示。
由表5可知,分级模型可信度优于主流的基准二分类器。尽管近年来在分类领域热门的RF算法和XGBoost算法性能显著优于传统的机器学习方法,但在贷款人视角下,其可信度和本文建立的分级模型仍有一定差距。
最后,將分级模型与基于指标赋权的得分评定模型作对比。主观赋权法受决策者经验影响较大,信用预测可信度难以确定,在此选用熵权法作为研究对象。参考Logit模型的回归系数判断指标正负向,在训练集中运用熵权法得到各指标权重,利用所得权重计算测试集中样本的信用得分。假设分级模型中预测信用等级为A或B的样本个数为y,则选取测试集中信用评分排名位于前y位的样本作为可靠借款人群体。经实验,基于熵权法赋权的模型可信度为98.13%,低于分级模型可信度。经分析,可能是因为熵权法赋权过于依赖评价指标的特征,没有利用好借款人是否违约的信息,而分级模型中采用的Logit模型充分利用该信息以提升预測精度。
综上,通过横向对比可论证本文信用分级模型有效可信,可显著降低贷款人资金风险,保障贷款人作出科学决策。
4 结语
针对互联网金融信用风险评估问题,本文综合运用主成分分析、Logit模型、GSAA-BP神经网络,兼顾客观数据和主观意愿,构建出一种信用分级模型。通过科学划分借款人信用等级,有效测度借款人违约风险,为贷款人提供直观的决策参考。
本研究的创新点如下:①对借款人信用评价采用等级划分,使评价结果有层次,解决了二值分类和得分评定的局限性;②提出依概率分级理念,充分利用Logit回归方程所得的违约概率进行等级划分;③使用主成分分析对评价指标进行预处理,有效避免了Logit回归可能存在的多重共线性问题。后续研究可从以下方面人手:①丰富信用评价视角,如从借款人、管理部门人手;②完善信用分级方法,使评价结果更精准可靠。随着相关研究的深入,规避金融风险手段会更有效,以推动互联网金融高质量发展。
猜你喜欢
中国军转民(2018年6期)2018-09-10
中国军转民(2018年1期)2018-02-06
商场现代化(2016年26期)2016-11-21
中国房地产业(2016年8期)2016-03-01
首都经济贸易大学学报(2013年1期)2013-03-11
