
大数据指数的再定义与新进展
2020-07-23 09:53郝淑玲米子川姜天英
统计学报 2020年4期
关键词:价格指数
郝淑玲,米子川,姜天英
(1.山西财经大学统计学院,山西太原030006;2.中国人民大学应用统计科学研究中心,北京100872)
一、引言
当前时代,大数据无所不在,人们对大数据日趋关注、认知和依赖。国民统计素养的显著提升使得大数据不仅成为了我们社会生活的稳定器,也给经济统计带来了方法论革新的新机遇。早在2016年3月李克强总理就在政府工作报告中指出,必须加快大数据的广泛应用,积极推动国家大数据战略落地实施;党的十九大提出了将互联网、大数据、人工智能与实体经济深度融合的政策导向,基本形成了“大数据+”与产业部门相结合的良好局面;2018年5月,习近平总书记在中国国际大数据产业博览会的致辞中强调,围绕网络强国、数字中国、智慧社会等概念积极推行大数据战略,推动中国经济向高质量发展。借此重大利好,众多学科领域都开展了以大数据为目标的学术探索,其中表现最为突出的当属以数据为研究对象的统计科学、计算机科学、信息科学、数学与经济管理类学科,甚至图书情报、传媒、新闻等学科也出现大量大数据相关研究文章。在此情景下,统计学发展迎来了新机遇,同时也面临着新挑战,会面临如何使统计学在大数据时代仍历久弥新、“大数据+统计”该如何发展以及大数据会给统计科学带来怎样的贡献等问题,而探讨这些问题将促使统计学发展迎来新变革。
统计学是探究数据间关系的方法论科学,以数据为对象,通过获取、分析、建模、解释等方法对所研究问题进行描述和推断,并为研究者提供依据和建议。大数据时代的到来促使统计科学面临新变革,不仅是数据本身,也包括数据分析的方法论方面。在大数据背景下进行统计研究,需要我们改变传统的统计分析视角,扩大统计建模范围,用经典的统计理论和方法指导统计研究的全过程,并在实践中不断补充、修正和完善这些方法。首先,在大数据来源的认识上要有所突破。在数据来源的认识上,大数据的数据来源更为广泛和多样,由于传统统计调查所获取的数据只占总体的一小部分,因而大量的未知数据隐藏在总体中,而基于“互联网+”的大数据会源源不断产生,是在抽样框未知的前提下进行的,属于非概率抽样,因此传统概率抽样的相关理论和方法不再适用于大数据抽样;在数据形式的认识上,大数据的数据形式更为多样化,既包括传统的结构化数据,也包括如图像、音频、视频、网页等半结构化或非结构化数据。其次,在获取大数据的方式上,传统调查会根据研究目的和实际需要在抽样框已知的前提下进行抽样,可视为“有监督”的抽样,而大数据背景下的抽样是在抽样框未知的前提下进行的,可视为“无监督”的抽样。人类认知的不断提高必将促进大数据不断发展,反之,大数据的发展又会不断补充、修正和完善人类认知,形成了大数据发展和人类认知相互促进、不断发展的局面,从而我们进行统计研究的能力和素养也在不断提高。再次,由于大数据会源源不断产生,因此应重视大数据的存储问题。由于大数据的获取成本较高、数据来源不同,从而导致数据集中存在形式各异的数据,而这些数据并不能直接为我们研究所用,因此应以传统统计调查为基础进行多数据库融合,进而提取出与我们所研究问题直接相关的数据。最后,在大数据分析方法方面,面对新的数据来源和收集方式,传统统计分析中的描述性统计分析如均值、方差、中位数等仍可做为统计分析的基础,使我们对所研究问题有比较直观的理解,但我们更应重视大数据分析中错综复杂的关系,利用专门处理大数据的算法如机器学习、深度学习和云计算等技术,充分挖掘大数据背后的深层价值,使大数据更好地服务我们的生产和生活。大数据发展给统计学带来的新变革不只包括从数据本身出发的数据收集、数据存储、数据分析等方式的变革,还包括从研究本身出发的研究思想、研究目的等方面的变革。综上所述,大数据的发展催生了统计学的新进展,给统计学方法创新和拓展提供了新动力,也给统计学发展带来了新机遇。特别是对于经济统计而言,大数据再次成为一个重要的发展机遇。
在统计学发展过程中,统计指数分析一直占据重要地位,是重要的宏观经济分析工具。指数(Index Number)从概念上有广义和狭义之分,其中广义指数是指所有用以表明经济现象总体变动的相对数,狭义指数是用来综合反映在不同空间、时间上的复杂社会经济现象的变动相对数。17世纪后期的物价指数研究中首次使用了指数,1675年英国学者赖斯·沃汉就尝试性地编制了金属货币交换价值的指数(徐国祥,2009)[1]。之后,随着经济社会的不断发展、计算技术的不断进步以及指数分析简洁性和有效性的不断提高,人们对指数的研究越来越深入、广泛,并开始在经济社会发展的各个领域重视指数的应用,不仅将指数广泛应用于经济管理领域,而且拓展到环境质量、商业管理、宏观政策分析、消费行为、社交行为等诸多领域。在大数据时代,指数研究作为统计分析的重要工具,也在不断适应新的发展,如大数据100指数(i100)、大数据 300指数(i300)、“指慧家”指数、360互联网+指数、aSPI系列指数等。i100和i300这两个指数与互联网金融相关,是将股票市场交易情况和通过社交媒体挖掘的投资者情绪结合起来选取的前100和300只股票组成的样本股,从而计算出i100和i300指数。“指慧家”是博时基金在基金行业率先推出的大数据品牌,其含义是“智慧的大数据指数专家”,它利用大数据技术即海量的互联网大数据,如搜索热度、关注度、成交额、消费笔数等多维度数据,基于数量化的统计模型、计量模型或大数据模型,尽早迅速准确预测某个行业或企业未来的发展前景。基金公司会全面考虑大数据影响因子、财务价值影响因子和市场动力影响因子,精心挑选出最有投资潜力、最具投资收益的个股,之后将其结合起来编制成大数据指数。到目前为止,“指慧家”共有四只大数据指数,是目前国内拥有产品数量最多的大数据指数品牌,这四只大数据指数分别是淘金100指数、银智100指数、雪球智选100指数、搜房网房天下指数。其中,淘金100指数的编制侧重使用线上消费数据,银智100指数的编制重点关注线下消费数据,雪球智选100指数关注社交大数据金融,而搜房网房天下指数则是依据房地产家居网络平台上的数据而编制。360互联网+指数是基于360旗下的搜索、导航、手机助手和手机卫士等大数据综合编制而成的大数据指数。aSPI系列指数是基于阿里巴巴平台交易数据编制的类似于CPI的一种反映网购商品价格变化的系列指数。
大数据时代下的指数编制思路是对传统指数编制的新突破:在数据来源上,可依托互联网和云计算数据,不再拘泥于调查数据,形式更为丰富;在计算方法上,可以结合实际问题自由选择权重、基期,但在设计计算公式时应充分考虑到大数据的动态特性。可以说,大数据系列指数是以传统统计调查指数为基础并通过不断创新和尝试而发展起来的,目前对大数据系列指数的研究尚没有形成完整的理论体系。本文以大数据给统计学带来的新变革为基础,详细阐述笔者对大数据和大数据指数的概念、性质等的理解,并提出大数据指数当前发展所面临的三大挑战,即认识论、方法论与实践论三个方面的调整。对于认识论挑战,探讨大数据系列指数与传统统计调查指数间的内在关系,并找到融合大数据指数与统计调查指数的突破口,从而促进二者共同发展;对于方法论挑战,概述大数据系列指数编制时应遵循的原则,包括如何选择计算方法、如何选择合适的基期、如何客观地计算权重等;对于实践论挑战,主要讨论关于大数据系列指数的应用范围及其公信力,探究其如何客观有效地反映某一现象的综合变动情况。
二、大数据指数的再定义
(一)大数据的本质
在对大数据指数进行定义之前,需要对大数据的定义有明确认识。随着舍恩伯格《大数据时代》的出版,学术界掀起了大数据研究的浪潮,但国内外对大数据的定义并不统一。维基百科①和Snijders等(2012)[2]将大数据定义为由大量的、错综复杂的数据构成的数据集,且需要突破传统数据处理方式对该数据集进行高效处理;Oracle②将大数据定义为高速涌现的、大量的、多样化的数据,简而言之,大数据指越来越庞大、越来越复杂的数据集,特别是来自全新数据源的数据集,虽然其规模之大使得传统数据处理软件无法处理,但却能帮助我们解决以往非常棘手的业务难题;Investopedia③给出的定义是,大数据指以不断增加的速度增长的各种大型信息;IBM④将大数据定义为,由人工智能(AI)、移动、社交和物联网(IoT)等通过新的数据形式和数据源不断产生的数据,如来自传感器、设备、视频、音频、网络、日志文件、事务性应用程序、Web和社交媒体等的数据,其中大部分是实时且大规模生成的;De Mauro等(2016)[3]在总结前人关于大数据定义研究的基础上,从资产和价值角度对大数据进行了重新定义,指出大数据的本质是一种信息资产,该信息资产具有数量庞大、形式多样、运行高速等特性,需要借助专门的分析技术和手段将这些信息资产潜在的价值挖掘出来并为人类所用;朱建平等(2012)[4]认为,大数据的本质是一种复杂多变的数据集,该数据集的研究范围远远超越了传统统计的研究范围,传统的统计分析工具在处理该数据集时也无能为力,因此为了对大数据有明确、深刻的认识,必须结合先进的技术和统计分析方法对其进行深入研究,如文本挖掘、机器学习、自然语言处理等先进技术;耿直(2014)[5]从狭义和广义两个方面对大数据的定义进行了阐述,指出狭义的大数据是一个包含大容量样本和高维度变量的数据集,广义的大数据是由来源广泛、形式复杂的多样化数据组成,重点强调数据容量巨大、数据类型多样、多个数据集错综重叠;祝丹和陈利双(2016)[6]将大数据总结为“三个统一”,即多样化的数据对象、综合性的专业技术和普遍应用的有机统一;马双鸽等(2017)[7]认为,大数据具有规模性、多样性、高速性的特点;李金昌(2014,2017,2020)[8-10]认为,大数据并不是一个具体的概念,而是一个泛称,简而言之,只要是可以记载的信息集合都可认为是大数据。大数据的“大”指数据的容量大,既包括结构化的数据,也包括半结构化和非结构化的数据,且可不断进行更新和修正;大数据的“数据”来源更为广泛,形式更为多样,包含运用先进信息技术获得的一切信息。
综合以上学者和机构对大数据的定义,本文认为大数据可描述为这样的数据集:比传统的统计数据数量规模更大,数据来源更为广泛和多样,数据结构更为复杂和多维,数据处理、分析和挖掘方法更为繁复和深刻,所包含的信息和价值更为丰富,所涉及的研究和应用领域更为宽广,所依赖的计算机软件和硬件更为高速和高效。
一般来说,大数据包含多个维度的含义,不但包含数据本身,还包含与数据分析相对应的先进的数据分析方法、存储大容量且高速的数据所需要的软件和硬件技术等。大数据的本质是一种随时产生的数据容量巨大、数据类型多样、数据用途广泛的数据集,且该数据集在不断更新和完善。为了充分利用大数据、挖掘其潜在价值,必须革新传统的统计分析技术,发展与大数据分析相匹配的数据分析方法和技术。
(二)大数据指数的新内涵
本文主要讨论以大数据为对象编制的综合统计指数,而不是以研究大数据的文献或数据集为对象编制的传统统计指数。本文讨论的大数据指数是指数体系的一个分类,但与传统的统计分析中的指数有明显不同,如在数据来源和计算方法上存在显著差异。编制大数据指数的数据主要来源于多元异构的大数据,计算方法也是随着大数据的产生而不断发展的先进计算方法。一般来说,大数据指数是指以工农业生产、科学实验、网络交易、社交媒体和一切经济社会活动中所产生的大数据为对象编制的综合反映研究总体发展变化规律和趋势的综合指数,是传统统计调查指数面向大数据的升级和创新。与传统的统计指数相比,大数据指数存在四个方面的不同。
一是数据对象不同。传统统计调查指数依靠统计报表数据或抽样调查数据编制,通常是根据一定调查目的确定抽样框后采集的数据编制,数据对象是抽样数据,可视为样本数据;大数据指数则主要依靠互联网电子商务交易数据、社交网络行为数据、物联网、云计算等多样化的数据集,数据对象是一定条件下获取的全数据,可视为一定条件下的总体数据。二是数据类型不同。传统统计调查指数的数据类型主要是通过抽样得到的结构化样本数据;大数据指数的数据类型是大数据,不仅包括结构化数据,也包括以图像、音频、视频、文字等形式存在的高维、连续且量级巨大的非结构化、半结构化或异构的数据。三是数据来源不同。传统统计调查指数的数据源自问卷调查或统计报表;大数据指数的数据主要来源于互联网用户无意识留下的行为数据、客户网络交易数据记录或通过电子终端获得的扫描数据等。四是数据采集方式不同。传统统计调查指数的数据是根据一定的调查目的和调查原则在抽样框已知的前提下确定抽样方法(包括随机抽样和非随机抽样)而收集得到,或是通过统计报表按时报送的方法采集;而大数据指数的数据可以借助扫描设备、基于现代网络信息多源整合数据库或是云计算等技术获得。
根据大数据指数的定义、计算、描述、解释、探索和应用等方面的特质,本文从三个方面描述大数据指数的基本性质。(1)数学性质。大数据指数仍然隶属于统计指数体系,具有统计指数固有的数学性质:加权可加性和平均性。如百度搜索指数,是用来分析某一关键词的搜索频次的加权和,用来反映该关键词在特定时间段内搜索情况的发展趋势和变化规律。(2)经济学性质。与传统统计调查指数相似,大数据指数也可以综合反映研究总体在一段时期内发展变化的总量变动、趋势变动以及各因素的影响程度,并对该总体进行综合评价。(3)大数据性质。大数据指数与传统统计调查指数最大的区别在于其所特有的大数据性质。首先,及时性和连续性。大数据具有连续更新的特点,通过构建某一大数据指数的分析体系,在更新数据源时可以连续实时对该大数据指数进行更新和同步呈现。其次,广泛性和细化性。基于大数据获取的多源性,大数据指数所涉及的领域更广,更具广泛性。同时,大数据时代获取数据的便捷性使得研究某一领域的细化项目成为可能,即分类细化能力更强。再次,社会性和服务性。对于大数据的使用,可以在社会各领域推动更广义的应用,提高公共管理效率,有较强的社会性。而且,由于大数据能够呈现出更强的可视化效果,可以更为简便地向受众传达某一领域的发展情况,因此服务能力更为强大。
(三)两类重要的大数据指数
基于以上对大数据指数的定义和性质的界定,本文主要介绍两类有一定代表性的大数据指数:一类是以互联网交易数据、社交网络数据等行为数据为对象编制的大数据指数,如阿里巴巴网购价格系列指数(aSPI指数和aSPI-core指数)、百度指数等;另一类是基于新的大数据来源、计算方式、编制方法等对传统调查指数进行的计算、改进和虚拟指数。
1.基于网络交易和交互数据编制的大数据指数。为了更好反映互联网电子商务交易中的价格变化情况,阿里巴巴利用零售交易平台的交易数据编制了阿里巴巴网购价格系列指数,该系列指数主要有两种:aSPI-core指数和aSPI指数。这两种指数均由食品、烟酒及用品、衣着、家庭设备及维修服务、医疗保健和个人用品、交通和通信、娱乐教育文化用品及服务、居住、办公用品及服务、爱好收藏投资10大类指数组成,且这10大类指数又细分为近500个基本分类价格指数。
aSPI-core指数是基于固定篮子理论而构建的阿里巴巴网购核心商品价格指数(alibaba Shoping Price Index,core-items)的简称,用以反映网购核心商品的价格变化水平。该指数通过特定算法筛选出阿里零售平台上近500个基本分类包含的将近100 000种核心商品,并将这些核心商品当做固定“篮子”,以此来追踪该篮子内包含的商品和服务的实际网购价格的变化情况,反映出网购核心商品和服务的价格波动的一般水平,从而揭示出网络零售平台下的宏观经济的价格变化趋势。运用该指数衡量宏观物价变化趋势存在一定的不足之处,即由于网购产品更新换代速度非常快,新产品从刚出现在网购平台到在网购平台上广泛流行会产生相应的溢价,之后会出现越来越多的替代品,降低了溢价,但实际上较长时间内的消费支出成本存在上升趋势,而基于固定篮子理论计算得到的价格指数可能会低估这一上升趋势,从而使得计算出的aSPI-core指数存在较大偏差。相比较而言,阿里巴巴全网网购价格指数(aSPI)能够弥补aSPI-core指数计算价格指数的不足,且aSPI指数在计算价格变化时还可以将收入的改变以及由收入预期改变带来的选择产品的质量上的变化也考虑进来。
aSPI指数是阿里巴巴网购(全网)价格指数(alibaba Shoping Price Index)的简称,用来刻画在阿里巴巴交易平台上发生的消费和服务的总体支出价格的变化趋势(米子川、姜天英,2016)[11]。该指数是以生活消费论为理论基础而编制,在保持消费者效用不变的条件下,该指数能够测度由产品相对价格变化而导致的消费数量上的替代效应。该指数的编制是以细化的叶子类目的上月成交额度为权重,从而计算出每月加权的成交平均价格的变动情况。它不仅可以从商品层面反映一般意义上的价格变化情况,而且可以反映细化的叶子类目下的消费者消费构成改变的一般情况。消费者消费构成变化测度的是,消费者对隶属于同一基本分类下的价格高昂商品和价格低廉商品的相对选择及其替代情况,且消费者的该选择会受到价格高昂的商品和价格低廉商品的相对价格变动、气候因素变化、宏观经济条件变化及网购群体的个人经济水平和偏好变化等因素的影响。
2.基于网络交易和交互数据虚拟的大数据指数。CPI(Consumer Price Index)是消费者价格指数,用来反映一定时期内城乡居民所购买的生活消费品和服务项目的价格变动趋势和程度,是对城市居民消费价格指数和农村居民消费价格指数进行综合汇总加权计算的结果,通过该指数可以观察和分析消费品的零售价格和服务项目价格变动对城乡居民实际生活费支出的影响程度。国家统计局定期公布年度 CPI、月度 CPI、定基 CPI、同比 CPI和环比 CPI数据。CPI是衡量通货膨胀与否的一个重要指标,也是进行宏观经济分析和决策、价格水平调控与国民经济核算的一个重要指标。但是,近些年对CPI的编制却存在较多争议,众多学者均在一定程度上对CPI提出了改进措施。而大数据时代无疑给CPI的改进和创新提供了新契机,因此基于大数据的CPI改进研究在不断深化。通过相关文献总结发现,以虚拟CPI编制的数据来源为基础可将其大致分为三种,即基于互联网搜索数据的CPI编制、基于互联网交易数据的CPI编制和基于扫描数据的CPI编制,下面对这三种方法进行简要描述。
(1)基于互联网搜索数据的虚拟CPI编制。简单来说,互联网搜索数据是在社交平台等媒体上发布的海量以文本形式存在的搜索信息,这些社交平台包括微博、论坛、贴吧、电视报道和网络媒介等。互联网搜索数据刻画的是消费者对具体某一社会经济现象、某一实施政策、某一发生事件的意见或态度倾向,近年来成为了学者们研究的焦点。利用互联网搜索数据进行科学研究的基本流程通常为:首先,确定研究对象,通常为关系到社会经济发展状况的各种统计指标,如 CPI、PPI、PMI、失业率等;其次,根据研究对象锁定要获取数据的渠道,通常的搜索数据渠道包括微博内容、豆瓣评论、百度搜索指数、微信指数、谷歌搜索等;再次,利用文本挖掘、机器学习或者统计学分析方法对搜索到的关键词进行分类并构建相关指数;最后,对通过互联网搜索到的关键词及与之相关的数据而建立的指数和根据研究对象确定的重要指标做相应的统计分析,以此来确定二者之间的关系,如因果关系、相关关系或其他随机关系。
国内学者运用多种统计模型和方法探究了互联网搜索数据和CPI之间的关系。张崇等(2012)[12]基于谷歌搜索平台数据,在对搜索到的关键词进行划分的基础上合成了宏观形势搜索指数和供求关系搜索指数,并进一步运用协整模型研究了这两种搜索指数与CPI之间的关系,发现网络搜索指数比CPI的时效性更强,可以及时反映价格水平的变化,能够对CPI起到一定的监测和预警作用;孙毅等(2014)[13]基于网络搜索数据运用协整模型对网络通货膨胀预期与通货膨胀之间的关系进行了研究,结果表明网络通货膨胀指数与实际通货膨胀之间的相关程度很高;徐映梅和高一铭(2017)[14]基于互联网大数据,分别利用门限回归与动态因子模型构建了CPI低频舆情指数与CPI高频舆情指数,并进一步利用CPI舆情指数预测了CPI;方匡南和曾武雄(2018)[15]采用交叉谱分析方法,对基于网络零售商品价格数据编制的阿里网购价格指数aSPI和基于传统编制方法的官方CPI之间的关系进行了分析,发现阿里网购价格指数对CPI有预警和预测作用;刘涛雄等(2019)[16]基于互联网在线大数据,利用格兰杰因果检验和传统通胀预测模型编制实时高频物价指数,用于实时监控宏观经济和物价的变化。
互联网搜索数据可以从一定程度上代表用户对某一特定事件或行为的看法或态度倾向。研究者们只要掌握基本的网络爬虫或文本挖掘技术就可以搜索到这些网络数据,但通常面临的一个困难是如何对搜索到的文本信息进行正确归类,从而确定与研究对象密切相关的关键词。对研究者来说,合适的关键词可以起到事半功倍的效果,因此研究者们要根据研究问题凭借自己的知识和经验水平确定恰当关键词。
(2)基于互联网交易数据的虚拟CPI编制。互联网交易数据(online data)是指运用网络爬虫或文本挖掘等专业技术手段获得的用户在互联网上交易的商品价格数据。随着科技的不断进步,越来越多的人进行网上购物,网络平台消费占据了人们日常消费的很大比重,因此这部分消费对CPI起到了举足轻重的作用。许多国家统计局都在对互联网交易数据进行测试,以期在编制CPI时可以很好地使用这部分数据。
欧盟统计局在关于互联网购买的建议中指出,在计算消费者物价调和指数(Harmonized Index of Consumer Prices,HICP)时必须重视电子商务的作用。许多欧洲国家对如何使用互联网交易数据计算价格指数做了一系列探究,如挪威统计局使用通过网络爬虫技术获得的在线交易价格编制了HICP。研究表明,由于在线商店对商品的定价策略与实体店的定价策略大不相同,使得消费者通过不同渠道购买的商品价格可能会不同,因此互联网交易数据的价格波动比较明显,计算出的HICP相当不稳定。
荷兰统计局在计算CPI时使用两种方法将Internet数据用作统计数据源:其一是使用“机器人工具”从多个网站提取特定的目标数据;其二是使用网络爬虫工具从大约10个特定的网站上收集大量数据,通常是1 000至100 000条记录。荷兰统计局使用航空公司网站上的航班信息、荷兰房地产网站上的房价信息、社交媒体上的消费者信心信息、谷歌的健康趋势统计信息等编制相应指数。选择性是大数据的数据生成所具备的最明显的特征,也就是说,大数据是针对某些特定总体产生的。如在编制服装类CPI时,首先选择互联网平台上收入最高的零售商,之后从这些收入最高的零售商中选择服装收入最高的零售商,若使用这部分零售商的数据进行指数编制,编制出来的指数可能有偏。尽管如此,同从商店收集到的数据相比,利用从互联网平台上收集到的数据编制的CPI质量更好,因为政府可以通过先进技术获得所有零售商的信息,而不是少数几个零售商的信息。荷兰统计局指出,互联网交易数据和扫描仪数据将是今后编制CPI的主要数据来源,政府将继续开发先进的算法和数据分析工具,充分挖掘互联网交易数据中的潜在价值,编制更高效的CPI。
为了减少时间延迟并在线测量价格波动,波兰中央统计局根据麻省理工学院的BPP创新项目实时收集价格数据,并结合波兰中央统计局发布的CPI指数中使用的家庭消费模型创建了波兰在线CASE CPI,该价格完全根据互联网上的价格数据计算得出。研究表明,基于在线价格的消费者价格指数可以先行于经典的消费者价格指数,这样公众可以预测政府要制定的调节价格水平的策略、政府的财政政策及公众的可能反应等。进一步,在线CASE CPI可用作通货膨胀预期指标。
与国外相比,国内学者运用网络爬虫技术获得互联网交易数据并计算价格指数的研究相对缺乏。孙易冰等(2014)[17]采用网络爬虫技术获得某零售商销售手机的价格,并编制了手机日度环比价格指数,结果发现通过爬取评论数排名靠前的手机获得的价格信息计算出的日度环比价格指数与官方公布的价格指数非常接近,且比官方公布的价格指数的时效性、可操作性更强。
通过网络爬虫技术获得互联网平台上的交易数据有诸多优点:首先,爬虫技术简单易行,不需要任何编码技能,只需要使用相关专业软件就可以获得互联网交易数据,如挪威统计局使用import.io软件进行网络爬虫,只需要输入用户名和密码登录个人账户,并设置好相应参数,然后通过简单点击操作就可以爬取到各种商品的价格信息;其次,使用网络爬虫技术可以获得大量的数据;再次,通过爬虫获得的网络交易商品价格的时效性较强,如可以获得商品的日度价格,进而编制商品的日度CPI指数。但通过爬虫技术获得互联网交易数据也存在一定缺陷:首先,通过爬虫技术只能获得网络交易商品的价格,而获取不到商品的数量信息,这样计算CPI时的加权会受到一定影响;其次:通过网络爬虫获取的商品价格波动浮动较大,这样计算出的CPI会存在一定偏差。另外,可以预见的是,爬虫技术在将来必须解决数据爬取的法律许可问题。
(3)基于扫描数据的CPI编制。20世纪70年代,柜台上条形码扫描仪的出现(1974年在美国推出了第一台条形码扫描仪)标志着商店处理商品的付款方式发生了重要变化。以电子方式记录的“扫描仪数据”的产生,不仅给零售商管理商品带来了方便,也为学术研究和统计机构编制价格指数提供了新的可能性。扫描仪数据通常是通过扫描商品的EAN码来获得,一般包含已售出的所有商品的交易信息,包括消费者实际支付的价格和每件商品的销售数量。EAN代码是用于标记产品的国际编号系统,其中前两位或三位数字标识制造商的注册国家,之后四位或五位数字标识公司号,剩下的数字标识产品。EAN编号不包含有关产品本身的信息,如品牌、重量、标签等信息将保存在网点的收银机系统中,而且不再生产的产品的EAN编号可用于其他产品。在零售商店扫描并出售的带有EAN条形码的每种产品的信息都将保存在该商店的收银机系统中。
到2016年为止,使用扫描仪数据编制CPI的欧洲国家达到了六个,分别是比利时、丹麦、荷兰、挪威、瑞典和瑞士,但是这些国家使用扫描数据编制CPI的方法却不相同。荷兰统计局在2002年6月使用两个连锁店超市的扫描数据计算CPI,到2010年又扩大了扫描数据的使用范围,愿意与荷兰统计局定期合作并提供扫描数据的连锁超市达到了七个。挪威统计局自2005年8月以来一直使用扫描数据计算食品和非酒精饮料的子指数,挪威和荷兰计算CPI的价格和支出权重数据均来自扫描数据。瑞士联邦统计局采用更务实的方法,将一些主要零售连锁店的扫描数据用作价格收集的附加来源,并将从扫描仪数据中获取的商品价格替换以前在网点中收集的价格,而不改变计算价格的基本原理。新西兰统计局(Stats NZ)与美国麻省理工学院(MIT)的“十亿价格计划”的商业对口机构PriceStats签署了一份为期一年的每天通过网络抓取在线价格数据的购买协议,这些数据可以实时捕获各种新西兰零售商的在线价格,并将在线数据与调查或扫描仪数据中的支出信息结合使用,可以提供比当前更频繁、更及时的价格指标,从而估算出CPI⑤。自2015年以来,比利时统计局均基于超市的扫描数据计算CPI,并将采用动态方法和多边方法计算的CPI进行比较,目的是到2020年切换到采用多边方法计算CPI。除使用扫描仪数据外,比利时统计局还提供了许多消费领域的网络抓取数据,如电子产品、鞋类、酒店预订、二手车、学生房间的出租等,目的是将这些数据整合到CPI的计算中⑥。
尽管国外使用扫描数据进行CPI的编制已经十分盛行,但国内对扫描数据的研究还十分缺乏。陈相成和乔晗(2013)[18]、乔晗(2013,2014,2015)[19-21]、丛雅静(2017)[22]从方法论的角度探讨了在我国利用扫描数据编制CPI的可行性,从理论上分析了数据的提取方式和编制方法,如权重的选择、链式指数的选择等,但并未从实证角度予以论证。李绍泰等(2014,2015,2020)[23-25]从理论上对计算 CPI所使用的多种指数和抽样方法进行了探讨,并运用美国的奶酪和啤酒两种分类下的扫描数据进行了实证,但没有运用中国数据进行实证,因此对于利用扫描数据计算中国的CPI是否合理仍值得探讨。李国栋和李宏宇(2015)采用会员消费者购买记录的零售扫描数据,研究了节假日需求高峰期消费者对季节性和非季节性商品的选择差异。
扫描数据具有如下优点:第一,收集成本较低,与传统的价格收集方式不同,扫描数据不需要投入大量的人力、物力和财力;第二,可以增加样本容量,减少抽样方差;第三,可以减少测量误差;第四,可以减少零售商的响应负担。但由于使用扫描数据时需要获得零售商的完全许可,加之运用扫描数据编制价格指数的相关理论还未形成完整体系,且未形成国际标准被广泛应用,因此在我国推广采用扫描数据编制价格指数任重道远。
三、大数据指数推动指数方法创新
大数据指数作为大数据时代的产物,在传统统计调查指数已经获得广泛认知和普及的情况下面临着诸多挑战,主要有以下三个方面的问题:一是大数据指数与传统统计调查指数的关系是怎样的,是融合还是替代,以及定义这种关系的关键点是什么;二是基于不同形式的数据来源,大数据指数在传统统计调查指数的编制方法上的改进与创新有哪些;三是大数据指数相比于传统统计调查指数的社会公信力有多大,是否可以与官方公布的统计调查指数相比较。
(一)大数据指数与传统统计调查指数的关系
从理论意义上讲,大数据指数作为一种综合指数体系,无论是在数据来源上还是编制方法上,其相较传统统计调查指数更多的是改进和创新,而不是简单的替代,因此大数据指数与传统统计调查指数之间更多的应该是融合关系,二者互相印证、互相补充。但在当前大数据指数发展的基础上,二者融合仍有一定难度。为了更好地描述大数据指数与传统统计调查指数之间的关系,本文选取aSPI与CPI进行代表性对比说明,具体融合难度表现在三个方面。
1.数据方面的不一致。在数据来源上,编制aSPI指数的数据源自阿里巴巴电商交易平台的互联网交易数据,而编制CPI的数据来源于通过多阶段抽样方式获得的调查数据,数据结构比aSPI的更为完整,而aSPI的数据结构更为复杂且高维。aSPI的数据几乎包含整个网络交易平台数据,而CPI仅为样本数据,故aSPI的样本量相对更大,数据获取误差小,且更新速度快。虽然aSPI和CPI的数据均为滞后数据,但aSPI中的网络价格能更真切、快速地反映通胀或紧缩程度,对于价格变动更为敏感、迅速,可以通过aSPI的变动对CPI进行及时预测和预警,而且aSPI中的网络价格数据不存在不同地区间的价格差异问题。
2.覆盖面的差异。在覆盖面上,不仅有地域覆盖面差异,而且有代表性商品覆盖面差异。在地域覆盖面上,aSPI的数据覆盖面受限于互联网发展的覆盖程度,在广大农村等互联网发展较为落后的地区以及习惯集市交易等经济发展较落后的地区所占比重较低,而CPI的样本遍及全国各地区,可克服aSPI的这一缺点;在代表性产品覆盖面上,aSPI包含近500个基本分类,CPI包含263个基本分类,aSPI的基本分类虽多于CPI,但产品类别过于集中,如衣服类、电器类等。
3.编制方法的差异。在权重上,aSPI的权重是以上月成交份额来确定,CPI的权重则依据居民家庭开支确定,二者的权重更新频率差异较大;在计算方法上,经过不断的实践探索,CPI的编制体系已经发展得相当完善,且它的计算方法是公开的,而aSPI仍处于起步阶段,计算方法尚未公开,仍在不断更新和完善。但是,CPI的计算相比aSPI汇总更困难,成本较高,耗时较长。
综合以上方面,虽然aSPI与CPI都表示价格水平变化情况,但由于数据来源不一致,从而导致连锁反应,在后续编制方法等方面也存在较多差异,由此导致了二者融合的多重难度。为了促进二者融合,需要在诸多方面进行改进:首先,统一数据形式和数据采集频率,鉴于aSPI的更新速度要快于CPI,因此为了综合反映同一时期的价格水平变化,必须将二者的采集频率进行统一;其次,对二者的覆盖面进行综合考虑,取长补短,以更好涵盖各类型、各地区的代表性产品;最后,统一编制方法,无论是基期、权重还是更新频率等,要在二者间寻求一种平衡,以更准确反映某一时期的价格水平变化。
客观上,aSPI和CPI的计算体系各有优势。互联网消费交易应属于CPI的计算范畴,而之前由于数据等方面的限制,互联网消费并未包含进CPI,但随着大数据时代的发展,将互联网消费纳入CPI的计算中指日可待。其前提是,促进二者双向改进和融合,从而扩大CPI的核算范围,以更准确表示我国物价水平的变化。因此,以二者为代表的大数据指数和传统统计调查的融合需要各取所长、互相融合、共同创新,以更好反映宏观经济的价格波动情况。
(二)大数据指数的编制方法创新与改进
大数据时代的数据来源越来越多样化,数据结构越来越丰富,如果根据传统的指数编制方法利用这些多源异构的大数据编制指数可能会存在一些困难,鉴于此必须根据实际问题不断对传统指数编制方法进行改进和修正,以探索出适合大数据的指数编制方法。
1.代表性商品的选择。在编制价格指数时,对于代表性商品的选择是否恰当在很大程度上决定了编制的价格指数是否科学、合理。选择代表性商品时需要考虑诸多因素,如选择代表性商品需要投入的人力、物力和财力以及选择过程的操作是否简单易行等,而且应根据代表性商品的数据来源、数据结构制定不同选择方案。
如果我们运用互联网搜索数据选择代表性商品,则选择的重点在于确定与研究对象密切相关的搜索关键词。通常情况下,搜索关键词要根据研究的实际问题和研究者的知识经验水平来确定,对于选择出的搜索关键词是否科学、合理并没有科学的评判标准。各国对运用扫描数据选择代表性商品的方法不尽相同。例如,BPP使用一家大型零售商作为服装的代表市场;荷兰统计局计划使用多达20至25个零售商来尽可能全面覆盖服装市场,荷兰统计局是通过提前设置阈值的大小来选择代表性商品;瑞典统计局使用4个主要零售商每年提供的扫描数据构建抽样框;比利时统计局基于扫描数据计算CPI时的思路同荷兰统计局的做法相类似,也是通过设定阈值来选择代表性商品。代表性商品的选择公式为:

其中,Sm为第m个月每种匹配商品的市场份额;Sm-1为第m-1个月每种匹配商品的市场份额;n为商品数量;λ为常数1.25。
在利用扫描数据计算市场份额时,商品的营业额必须高于最低阈值,同时还要使用两个倾销过滤器来选择代表性商品:一个过滤器用来排除价格和销量均急剧下降的商品,另一个过滤器用来排除销量急剧下降而价格保持相对稳定的商品,这就避免了库存清理的问题,如果将这些商品包括在样本中将导致价格指数的向下偏差。在样本中,在一个月到另一个月之间显示出极端价格变化的商品也被排除在外(实际上,这仅能排除可以通过会员卡免费获得的商品)。之后,使用基本总量的价格演变来估算超出样本的商品价格。使用商店专有代码(库存单位-SKU)而不是GTIN代码来定义商品,根据经验,为了计算价格指数,内部代码通常更稳定和“唯一”,它们的独特之处在于结合了多个GTIN代码,从消费者角度来看它们实际上是相同的商品(如在不同工厂生产的相同商品)。
SKU有时还有助于捕获“重新启动问题”,即同一商品获得不同的GTIN,尤其是相同数量商品的价格不同(通常是更高的价格)。通过文本挖掘或数据挖掘,价格收集器可以发掘隐藏的价格变化。如果商品价格不同,则需要将“旧”商品和“新”商品联系起来,以避免指数水平出现偏差。如有必要,可以在新旧商品之间进行数量调整。
2.权重的确定。权重代表了商品或服务在消费者日常消费中的重要程度,权重越大,说明对消费者的日常消费来说该商品或者服务越重要,反之亦然。一般计算价格指数的权重是按照消费支出的价格、数量或销售额来确定。由于通过网络爬虫获得的互联网交易数据只包含商品的价格信息而不包含数量信息,因此确定权重存在一定困难。而扫描数据中包含的商品信息比较全面,如商品的价格、数量、折扣等信息,因此对扫描数据权重的确定相对容易。新西兰在计算CPI时同时采用通过网络爬虫获得的在线数据和扫描数据,且以家庭支出覆盖率作为其权重。比利时计算价格指数时的权重是基于上一年扫描仪数据的营业额数字得到。
3.计算公式的选取。国际上编制大数据价格指数时通常使用模型匹配指数、环比周期价格指数和多边指数,如GEKS指数等。
(1)模型匹配的价格指数。假定消费者的消费支出已按销售数量和单价汇总为月度或季度数据,其中消费者购买商品的单价与其购买商品或服务所在的零售店或连锁店有关。假定S表示某商品所属类别,N表示商品数量,构建价格指数的目的是比较基期到任一时期的价格变化,如0时期到t时期的价格变化。将商品i∈S在0时期和t时期的单价分别记为。如果缺乏商品的数量信息或支出信息,则根据国际CPI手册,建议使用未加权几何平均值或Jevons价格指数的“直接”或双边比率计算CPI。Jevons价格指数的计算公式为:

与其他未加权指数相比,该指数满足更多的优良性质。由于扫描数据中包含的信息比较充分,即权重是可以获得的,这就为构造高级价格指数提供了可能。基于扫描数据编制价格指数的最常用指数是Törnqvist指数,而不是Fisher指数,因为它的几何形式简化了分解分析。通常情况下,这两种指数的计算结果非常类似。双边Törnqvist价格指数的表达式为:

(2)环比周期价格指数。假定t(t=0,1,...,T)时期的商品集合为St,商品数量为Nt。通常使用的动态指数方法可分为两类:一类是根据商品特点明确考虑到新的和流失的商品,另一类是根据商品特点未明确考虑到新的和流失的商品。一般处理这两种情况分别使用质量调整方法和模型匹配方法。
鉴于扫描数据中经常会遇到商品流失率很高的情况,至少在GTIN级别,最大化匹配数目非常有用。国际CPI手册建议使用环比匹配模型的高级价格指数,如环比周期Törnqvist价格指数,其表达式为:

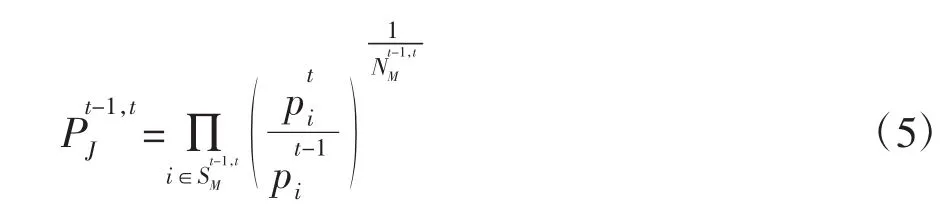
(3)链式漂移和多边方法。众所周知,如果月度指数的计算中包含可用的营业额信息,将会导致链式漂移,但这些信息会使算出来的指数更具代表性。为了使国家或地区之间的价格比较具有传递性,通常使用多边价格指数方法来比较国家或地区之间的价格水平。对于空间比较而言,传递性是非常理想的属性,因为结果将独立于基准国家或地区的选择。多边空间价格比较就很适用于一段时间内的价格比较,使用多边方法可以最大程度地提高数据中的匹配数量且不会带来引入漂移项的风险。
近年来,比利时统计局在计算CPI指数时开始进行动态方法与多边方法的比较,目的是到2020年转换为完全使用动态方法计算CPI指数。比利时政府在使用多边方法时做了一些初步尝试,目前该方法仅适用于来自一个零售商的扫描数据。经过测试的多边方法包括 Geary-Khamis、加强的 Lehr,GEKS-Törnqvist和 Time Product Dummy。
①GEKS-Törnqvist指数。GEKS-Törnqvist使用了所有可能的匹配商品计算第0个月到第t个月的价格指数,并将其作为匹配模型的双边价格指数P0l和Plt的T+1个比率的未加权几何平均,具体公式为:

其中,P0l和Plt分别代表0到l期间和l到t期间的双边Törnqvist指数。
②Geary-Khamis指数。Geary-Khamis方法基于单价的概念,一个商品i有单价和销量,如果商品不同质,则很难将它们的数量直接加总,Geary-Khamis方法建议使用质量调整因子vi来解决这一问题。质量调整因子以普通单位转换销量,且价格将成为质量调整价格,由此将得出一组商品在第t个月的质量调整单位值,其表达式为:

第0个月和第t个月之间的价格指数即Geary-Khamis指数的表达式为:

可将其看作营业额指数与加权数量指数之比。Geary-Khamis方法将权重定义为:

质量调整单位值使用第0个月到第T个月的所有可用数据,由于计算质量调整因子时需要用到价格指数,反过来,计算价格指数时又要用到质量调整因子,因此需要运用迭代算法求出价格指数和质量调整因子。
③加强的Lehr指数。Lehr方法同Geary-Khamis方法相类似,不同之处在于它的计算没有使用复杂的迭代算法。质量调整因子定义为:


将其带入式(8)便可得到增强的Lehr指数,理论上看,它仍然是个双边指数,但却隐性运用了第0到T时期的所有可用信息。
④Time Product Dummy方法。TPD是基于一个时间窗口内所有可用的数据来估计价格指数。在时间段[0,T]内具有N个不同项目的模型的表达式为:
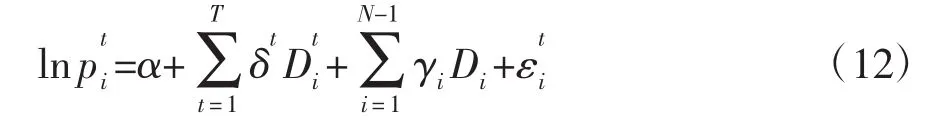
其中,δt为时间虚拟变量参数,γi为项目的固定效应。如果在t时期内可以获得商品i,则时间虚拟变量的值为1,否则为0。如果观察值同项目i相关,则Di的值为1,否则为0。第t个月一组商品Gt的质量调整价格为:
其中,价格是使用项目的固定效应vi=exp(γi)进行调整的,并将其称为质量调整因子。第t个月项目i的市场份额记为。则TPD指数可记为:
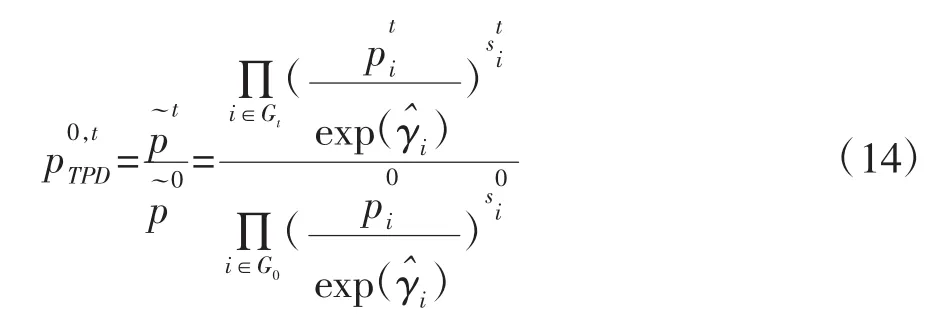
综合以上讨论,大数据指数依据不同的数据来源或不同的研究目的有不同的编制方法。也就是说,当前大数据指数仍在不断发展,其编制方法还在不断的探讨和发展中,并未形成官方的编制准则,这也是大数据指数当前面临的主要挑战之一。
(三)大数据指数的公信力
大数据指数作为指数体系的新兴组成部分,其产生目的与传统统计调查指数相一致,都是用来反映某一现象的综合变动情况,具备综合性、简便性、有效性等特点。因此,作为指数体系的新分支,对大数据指数的公信力进行探讨尤为必要。指数的公信力表示,该指标反映某一现象变化情况的准确程度以及指标受众对该指数的信赖程度等。传统统计调查指数因具有严格的数据收集过程、准确的指标编制方法、统一的编制原则等严格标准,因此有较高公信力;大数据指数由大数据衍生而来,对于数据收集过程并没有严格的质量控制,再加上大数据的数据可靠性和未形成规范化的编制原则等原因,其公信力仍有待完善。
aSPI与CPI均是反映价格变化水平的指标。其中,CPI由国家统计局定期发布,无论是在数据收集还是编制原则上均有严格完备的体系,并且CPI也是衡量物价水平、通胀程度的指标,因而在反映价格水平变化上具有绝对公信力。而aSPI衡量的是阿里巴巴交易平台的网络交易价格水平变化,核算范围仅限阿里巴巴交易平台上的网络交易数据,该指数具备灵敏性、准确性,因而在阿里巴巴交易平台该指数代表的网络价格水平有较高公信力。但若将其范围拓展至其他领域,比如其他电商数据甚至是CPI核算中,则会产生较大偏差,就需要在指数编制过程中进行相应调整,以达到不同指标的融合。
美国麻省理工学院的BPP项目所编制的CPI,是通过收集在线上和线下均有销售的大量零售商作为采价对象,爬取该零售商的网络交易价格数据,而后参照CPI计算的一篮子产品选取商品种类,进行CPI核算,并将其与官方公布的CPI进行对比,得出在美国等发达国家这两种计算方式结果相差较少,但在巴西和南非则相差较大。该项目的初步结果说明,新改进编制的CPI尚未达到官方CPI的编制要求,因此其公信力有待进一步研究。此外,官方公布的CPI指数已经有连续多年的历史数据,已形成长期稳定的时间数列,而对于新编制的非官方大数据指数,其编制和发布机构的公信力也是影响大数据指数公信力的一个重要原因。
综上所述,当前大数据指数主要依赖于互联网、物联网、云技术的发展和普及,但这些技术在我国的普及并不均匀,发展水平及经济规模均存在巨大差异,由此导致当前大数据指数的代表性较弱,故其公信力有待完善。这也从侧面反映出,大数据指数的公信力取决于大数据指数的发展程度及其与传统统计调查指数的融合程度,因此为了提高大数据指数的公信力,必须采取积极措施推进大数据指数与传统统计调查指数的有益融合。
四、结论和展望
大数据时代的数据容量巨大、数据类型多样、数据用途广泛,这就迫使统计学科必须不断改革和创新,以适应大数据发展的需要。本文从大数据带来的统计学新发展为研究起点,详细阐述了大数据指数的概念、性质等内容,同时也提出了大数据指数作为新兴产物所面临的三大挑战,并得出以下主要结论。
1.从本体论上看,大数据指数就是以某一来源和主题为核心的大数据为对象编制的综合统计指数,主要是以互联网社交和电子商务数据等大数据为数据来源的综合指数。本文总结了大数据指数的数学性质、经济学性质和大数据性质,提出了两种有代表性的大数据指数:一种是依据互联网交易大数据编制的综合统计指数,如阿里巴巴网购价格系列指数(aSPI指数和aSPI-core指数)、百度指数等;另一种是基于新的数据来源、计算方式和分析方法等对传统统计调查指数的改进和创新。
2.在认识论方面,明确了大数据指数与传统统计调查指数的互相融合关系,并提出了二者在融合过程中的三大难度:数据类型不一致、覆盖面差异和编制方法差异。为了促进二者融合,必须从这两种指数出发,互相取长补短,共同改进创新,以更好反映经济社会现象的变动情况。
3.在方法论方面,与传统统计调查指数的抽样数据不同,大数据指数依据新的数据来源和相应的编制原则及分析模型进行编制。但由于大数据本身的商业属性、机构特征和编制方法的不同,目前的大数据指数还缺乏足够的公信力,也没有建立起官方的编制标准或行业标准。要想实现大数据指数的应用,就必须从编制方法、制度、发布、应用等环节,全面革新现有的传统统计调查方法,构建升级版的大数据指数。
4.在实践论方面,大数据指数的公信力尚弱,这主要是因为,当前的大数据指数发展主要依赖于互联网商业机构、企业数据以及互联网和移动互联技术的普及,而广大中西部等经济发展较落后地区还无法达到网上交易和电子平台的完全覆盖,在一定程度上影响了大数据指数的代表性,也就削弱了其公信力。另外,大数据指数的公信力也在一定程度上依赖于大数据指数的编制方法、发布、应用等因素以及与传统统计调查指数的融合情况。
由于大数据时代的数据来源多样化、数据结构复杂化,传统的统计方法已不能适应大数据时代获取和分析数据的需要,因此必须从数据获取和数据分析两方面改革传统的统计调查方法。在数据获取方面,应加强与零售商、电商的合作,签订相应协议,获得互联网交易数据和网络爬虫数据的使用权,充分发挥这两类数据的优势,为编制大数据指数提供数据支撑;在数据分析方面,应结合实际情况不断改革传统统计调查指数的编制方法,创新大数据指数的编制方法。
大数据指数作为大数据时代指数体系的新成员,发展受到了较多挑战,而这些诸多挑战之间彼此存在相互联系和影响,只有明确了挑战是什么,逐步解决,并从大数据指数的本质上去完善,才能促进大数据指数有益发展。后续研究将会以大数据指数所面临的挑战为主要研究核心,讨论大数据指数的作用并不断完善大数据指数的知识体系。
注释:
① 来自https://en.wikipedia.org/wiki/Big_data。
② 来自https://www.oracle.com/cn/big-data/what-is-big-data.html。
③ 来自https://www.investopedia.com/terms/b/big-data.asp。
④ 来自https://www.ibm.com/big-data/us/en/。
⑤ 来自https://www.ottawagroup.org/Ottawa/ottawagroup.nsf/4a25635。
⑥来自https://www.unece.org/fileadmin/DAM/stats/documents/ece/ces/ge.22/2018/Belgium。
猜你喜欢
纺织服装周刊(2022年15期)2022-05-12
今日农业(2021年5期)2021-11-27
中国房地产·综合版(2016年12期)2017-01-17
大众理财顾问(2016年10期)2016-12-02
中国房地产·综合版(2016年10期)2016-11-18
中国房地产·综合版(2016年8期)2016-10-17
大众理财顾问(2016年9期)2016-10-11
中国房地产·综合版(2016年6期)2016-07-07
中国房地产·综合版(2016年6期)2016-07-07
中国房地产·综合版(2016年5期)2016-06-12
