
多特征融合的级联回归人脸对齐方法研究
2020-07-21 06:52:06黄树成
江苏科技大学学报(自然科学版) 2020年3期
傅 杰,黄树成
(江苏科技大学 计算机学院, 镇江 212000)
人脸对齐任务就是根据输入的人脸图像,自动运用算法,检测出面部特征点位置,如眼睛、脸部轮廓、嘴巴、眉毛和鼻尖等.该项技术应用十分广泛,如人脸识别[1-3]、人脸表情识别[4]和面部动作捕捉[5]等方面.随着深度学习技术的飞速发展,基于深度神经网络的人脸关键点检测算法[6-8]与传统的人脸关键点检测算法相比,已经展现出巨大优势,主要原因就是大量训练数据集开放以及深度神经网络对于大规模训练数据中蕴含的特征具有很强的提取和拟合能力.目前基于深度学习的人脸关键点检测算法[9-10]大多都是对输入图像的全局表观特征进行一系列计算和处理实现的,还有部分模型方法是提取人脸多个局部区域的特征[11],再分别进行关键点检测,最后得到整张人脸图像的关键点位置.这些方法虽然在人脸关键点检测任务上都取得了一定效果,但是也给模型留下了一定的提升空间[12-13],主要原因就是这些方法都没有特别考虑到人脸各部位间的结构化信息.为了表征这一信息,借用了前人在PRN[14]中提到的思想,将两两关键点对应的人脸局部特征对之间的结构关系加入到模型训练中,以此来优化模型性能,并且结合人脸图像全局表观特征和DAN[15]模型中提出的热图特征来实现多特征融合的级联回归人脸关键点检测算法.实验证明,该模型与最新的人脸对齐算法相比,进一步降低了人脸测试数据集上的错误率.
1 模型训练数据及其预处理
1.1 数据集介绍
为了训练多特征融合的级联回归人脸关键点检测模型,进行对比实验验证模型效果,选择了大多数相关领域研究者使用的通用数据集,该数据集是国际人脸关键点检测比赛中用到的300W公开测试数据集,数据集的构成主要有AFW[16]、LFPW[17]、HELEN[11]和IBUG[18]4个子数据集,每个数据集中的每张人脸图像都有其相对应的68个关键点标注信息和人脸bounding box的坐标信息.实验中将该数据集分成了训练数据和测试数据两个部分,其中训练数据包括AFW数据集、LFPW数据集中的训练集和HELEN数据集中的训练集部分,总共3 148张人脸数据.模型的测试数据部分则按照通用方法,处理成3个不同的测试数据集:① Common数据集,该测试数据集由LFPW数据集和HELEN数据集中的测试集组成,总共554张人脸图像;② Challenging数据集,该数据集是由IBUG数据集构成,总共135张人脸图片;③ 300W公开测试数据集,该测试数据集由LFPW数据集中的测试集、HELEN数据集中的测试集和IBUG数据集构成,总共689张人脸图片.
1.2 模型训练数据预处理
深度学习算法之所以能在人脸关键点检测领域获得重大突破,主要原因就是有大量的训练数据来对网络进行训练,只有通过海量数据对网络参数进行调节和优化才能使模型能够有较好的特征提取和数据拟合能力,而从训练数据的介绍来看,这个级别的数据量对于神经网络是远远不够的.所以为了缓解数据量不够充足而带来的问题,对训练数据集进行了数据增强处理,将训练数据集中每一张人脸图片通过围绕y轴镜像、随机平移、旋转和缩放操作生成对应的10张图片,这样不但增加了训练数据量而且使训练出来的模型能够获取到同一张人脸在不同角度、不同姿势下的特征信息.通过数据增强操作后的人脸图像如图1.

图1 人脸增强数据样例Fig.1 Examples of enhanced face images
2 模型方法和结构
2.1 模型框架结构与流程
如图2,整个模型结构类似DAN中的框架,采用级联回归的结构,整个模型由多个回归阶段组成,每个阶段包含一个前向传播模块和一个多特征转化模块,其中前向传播模块主要实现人脸图像深度特征的提取和人脸关键点坐标偏移量的计算.多特征转化模块则为下一个阶段生成神经网络需要的人脸特征信息.
从框架图中可知,模型第1个回归阶段的输入为人脸图像I和初始化关键点位置坐标S0,而S0是初始化在人脸检测框的正中间的.除了第1个阶段,模型的其他阶段都有转换成标准姿势形态的人脸图像T(I)、对应于关键点的人脸热力图H、两两关键点对应的局部人脸特征对关系特征P和上一阶段神经网络提取的人脸全局特征F4个特征数据输入.模型每一个阶段输出关键点位置坐标的偏移量,由于每个阶段开始的时候都对图像进行了标准姿势形态的转化,所以每次计算得到的关键点位置都要经过标准化转换的逆变换才能得到原始人脸图像上的关键点位置,具体转换公式为:
St=Tt-1(Tt(St-1)+ΔSt)
(1)
式中:t为第t个回归阶段;ΔSt为该阶段网络输出的关键点位置偏移量;T()为人脸图像转换成标准姿态的转换函数;T-1()为标准姿态转换的逆变换;St为原人脸图像中的关键点坐标.
2.1.1 前向传播模块
前向传播模块由一个神经网络构成,其主要实现对人脸图像的特征提取和关键点坐标偏移量的计算,主要结构如表1.除了表格中展示的结构,网络中每一层都采用了批归一化操作来加快模型收敛速度,网络采用Relu函数作为激活函数.每个阶段的网络结构中在fc1层之前采用了dropout层来防止模型过拟合.
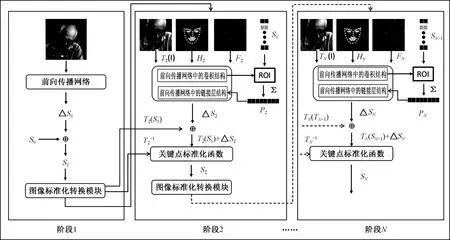
图2 模型框架图Fig.2 Framework of model
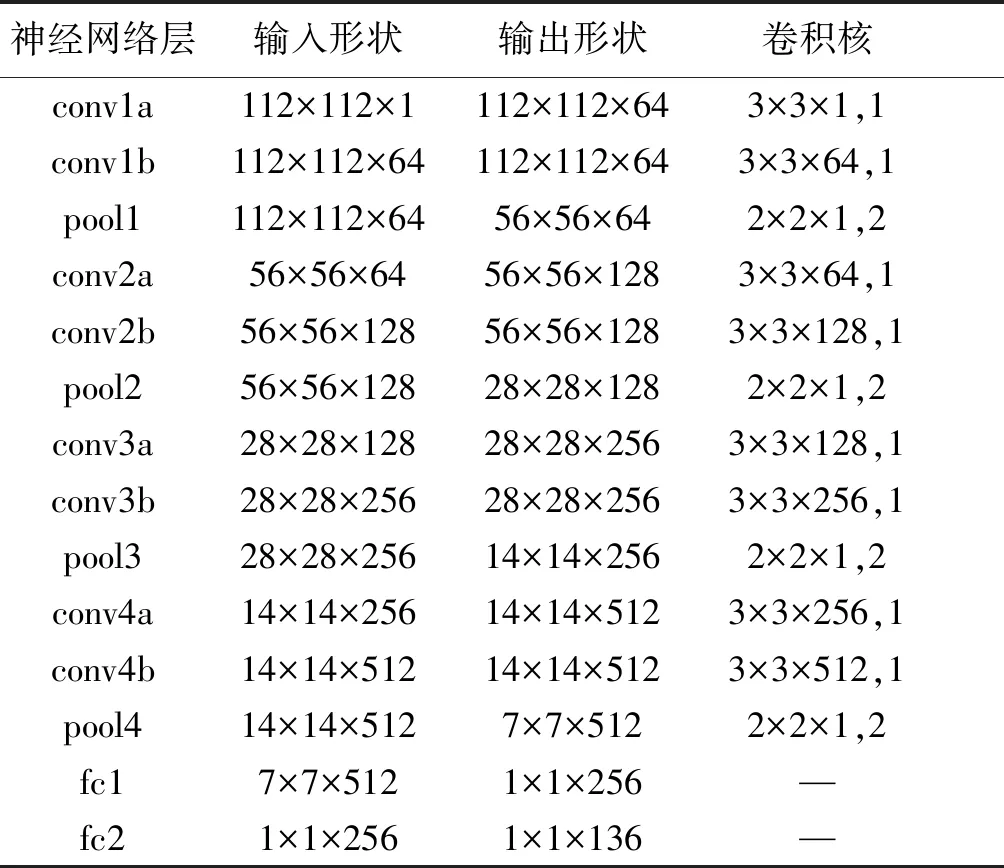
表1 前向传播模块网络结构Table 1 structure of feed forward network
2.1.2 多特征转换模块
图3为模型框架中的多特征转换模块,主要由1个参数求解函数和5个特征转换函数构成.图像标准化变换参数求解模块函数实现图像标准化变换函数的参数求解,图像标准化姿势转换模块函数实现图像的标准化姿势转换,人脸关键点逆标准化转换模块函数实现标准化人脸图像上关键点坐标到原人脸图像上的关键点坐标转化,人脸热图特征生成模块函数实现根据关键点预测生成对应的热图特征,人脸全局特征提取模块函数实现人脸全局特征的获取,人脸两两关键点对之间结构特征提取模块函数实现两两关键点对应的人脸局部图像对之间的结构特征提取.具体的模块内部各函数之间的数据流转如图3.
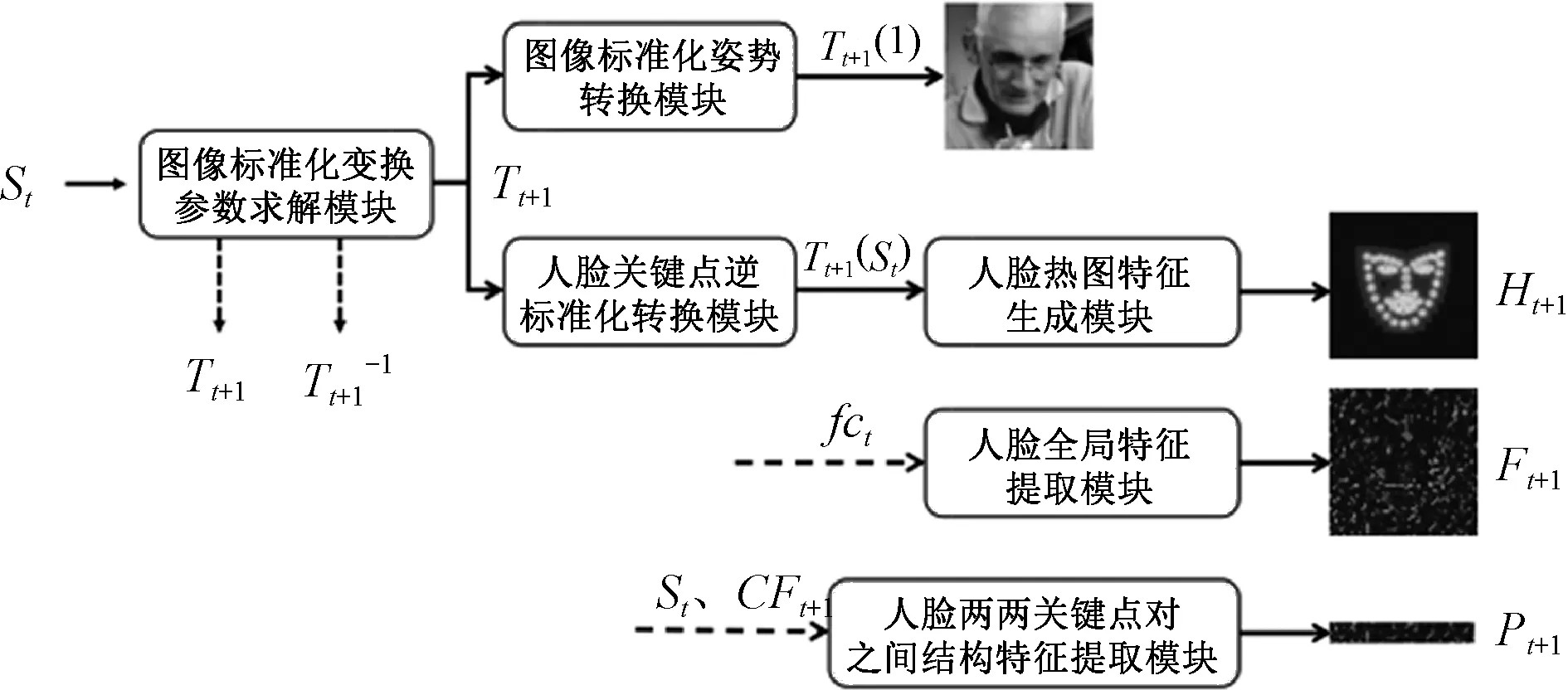
图3 多特征转换模块Fig.3 Transform module for multiple features
图像标准化变换参数求解模块函数的功能是得到人脸标准化转换的函数参数,也就是上文中函数T()的参数求解,其原理为:
M=St×Tt+1
(2)
(3)
式中:St为原人脸图像中的关键点坐标;M为标准化处理之后的关键点坐标;T()为标准化处理函数.
人脸热图特征生成模块函数具体实现原理是通过上一个回归阶段得到的标准化的人脸关键点的坐标,按照一定的热图构建规则生成关键点坐标对应的热图信息,而热图可以将上一个回归阶段得到的人脸关键点信息传递到下一个回归阶段,具体构建规则如下:
(4)
式中:si为标准化后的68个人脸关键点坐标中的第i个关键点坐标;H(x,y)为关键点坐标(x,y)对应的热图中的热值.热图值的计算只在以关键点为中心,以16为半径的圆的范围内.
人脸全局特征提取模块模块的实现原理是根据上个阶段网络中第一个全连接层提取到的人脸一维特征重新调整为56×56的二维特征矩阵,然后再上采样为112×112的特征矩阵作为人脸全局特征参与人脸关键点检测任务.
人脸两两关键点对之间结构特征提取模块函数的具体实现如图4.首先,根据上一个回归阶段得到的人脸关键点坐标,利用ROI映射,获取到各个关键点对应的人脸局部特征向量Fl={f1,f2,…,fN},其中N表示人脸关键点的个数,然后将这些向量两两组合作为关键点对应的人脸局部对之间的结构向量,将所有这样的局部对之间的结构向量组合到一起作为整张人脸的结构特征向量,最后经过一个神经网络的全连接层得到最终整个人脸图像的局部对之间的结构化关系特征PR.对应于图4,PR计算规则如下:
PR(I)=Fφ(A(Cat(fi,fj)))
(5)
式中:fi,fj分别为第i,j个人脸关键点在人脸图像的卷积特征图上对应的ROI映射向量;Cat()函数表示连接操作;函数A()表示对这些局部人脸映射向量连接后的组合和归一化操作;函数Fφ表示对最终得到的关系向量进行全连接层的特征提取操作;最终提取到的特征就是PR.

图4 成对关系结构特征生成模块Fig.4 Pairwise structural feature generation module
2.2 模型训练的优化目标函数
整个模型的优化目标函数是使模型预测得到的关键点位置坐标和实际关键点坐标之间的差异最小化,具体的优化函数为:
(6)
式中:S*为人脸原图像中的人脸关键点位置坐标.相比较于其他模型的模型优化目标函数,采用人脸图像中眼睛中心之间的距离作为分母,文中对于分母归一化项的选择有所不同,这里的D为人脸图像对应的边界框对角线的长度,这种优化函数可以一定程度上减小部分侧脸图像中人眼之间距离过小而导致的损失变化较大的问题,可以减小训练过程中的损失波动,使训练更加平稳.关于模型的训练,采用一个阶段接着一个阶段的训练模式,当前一个阶段的模型预测得到的关键点坐标的错误率不再下降时便开始下一个阶段回归模型的训练,训练下一个阶段时固定前一个阶段的模型参数.采用此模式直到整个模型的关键点检测错误率不再降低,完成模型训练,实验表明当模型经过一共两个回归阶段时可以达到最优效果.
3 实验和分析
为了全面验证上述改进方法的有效性,实验使用了3种关键点坐标预测错误率计算方法,计算方法为式(6),这3种计算方法的区别主要是分母的计算方式不同,3种分母归一化项:① 人脸图像中两个眼睛中心之间距离;② 人脸图像中两个眼睛外眼角之间距离;③ 人脸图像中人脸检测框对角线长度.
文中利用包含2个阶段的多特征人脸关键点回归检测模型来做人脸关键点标注测试,并且将结果与目前效果较好的一些人脸关键点检测算法进行了对比,实验采用了3种指标对模型效果进行测评,这3种指标分别是人脸关键点坐标预测的平均错误、AUC值和预测失败率.其中当采用上述②中分母归一化计算方式来计算模型失败率时,模型失败阈值被设置为0.08,<0.08为预测成功,>0.08为预测失败.对于AUC值计算,实验采用相同阈值,实验具体结果和数据如表2、3.

表2 模型关键点检测平均误差Table 2 Mean errors of the model key points %
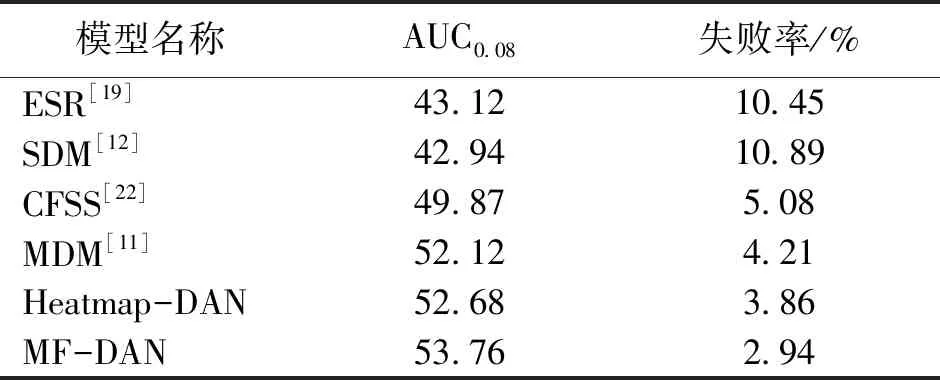
表3 模型关键点检测的AUC0.08值和失败率Table 3 AUC0.08 and failure rate of the model key points
注:实验数据来自人脸图像中眼睛外眼角之间的距离.
表2是各个模型在3种不同的关键点错误率计算方法下模型对关键点坐标预测的平均错误率,其中Heatmap-DAN模型表示只用热图特征和人脸全局表观特征来做关键点检测,MF-DAN表示在Heatmap-DAN基础上加入两两人脸关键点对应的局部人脸对之间的关系特征后的多特征级联回归人脸关键点检测模型,也就是文中提出的模型.从表2可以看出该模型在两个测试集上的效果都取得提升,尤其是在Challenging测试集上.使用两个眼睛中心之间的距离作为误差计算归一化项时得到的失败率是8.90%.使用两个眼睛外眼角之间的距离作为误差计算归一化项时得到的错误率是6.03%.使用人脸检测框对角线的长度作为误差计算归一化项时得到的错误率是2.26%.而在Common测试数据集上,除了使用两个眼睛中心之间的距离作为误差计算归一化项时没有获得最低的错误率,提出的模型在其他两种错误率计算方法中分别得到了3.31%和1.41%的失败率,相比较于未使用多特征融合的人脸关键点检测的Heatmap-DAN模型得到的检测错误率,分别降低了0.11%和0.16%,结果都显示多特征融合的模型效果优于大多数其他的人脸关键点检测模型,说明了多特征融合对于提升人脸关键点检测效果是有效的.特别是当采用人脸检测框对角线作为归一化项来计算关键点预测平均错误时,MF-DAN在平均错误率上较Heatmap-DAN降低了9.6%,由此证明了融合特征的有效性,也说明了多特征融合后的模型在性能上取得了不错的提升.
表3是模型的人脸关键点检测的失败率和AUC值,实验数据是在选用人脸图像中眼睛外眼角之间的距离作为错误率计算公式中的归一化项得到的.从表中可以看出,模型相比较于MDM和Heatmap-DAN,AUC0.08值分别提升了1.64%和1.08%.除此之外,MF-DAN在MDM模型的基础上将预测的错误率降低了30.17%,达到了1.27%.
综上所述,两两人脸关键点对应的局部人脸对之间的关系特征对于模型性能提升起到了不错的效果,实验结果表明多特征融合的级联回归人脸关键点检测模型的效果优于大多数现有的人脸关键点检测模型,结果符合预期设想.模型在Common和Challenging测试集上的预测结果如图5、6.

图5 Common数据集中样本及其对应预测结果Fig.5 Examples and their correspondingresults in the Common test set

图6 Challenging数据集中样本及其对应预测结果Fig.6 Examples and their correspondingresults in the Challenging test set
4 结论
将两两关键点对应的人脸局部特征对之间的结构关系、整张人脸图像的全局表观和关键点对应的局部热图这3种人脸特征结合,在以往模型的基础上构建了多特征的基于级联回归方法的人脸关键点检测模型,并且以300W公开数据集为数据进行模型训练和测试.
实验结果证明改进的多特征融合的级联回归人脸关键点检测模型的检测效果优于大多数现有的人脸关键点检测模型.但该研究采用的数据集样本数量少,虽然使用了数据增强方法来缓解这一问题,但是增强数据远没有原始数据效果好,在未来的工作中将探索合适的方法来克服这一缺点,并且将致力于大姿态、有遮挡的人脸图像关键点检测研究.
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
动漫星空(2018年9期)2018-10-26 01:17:14
发明与创新(2015年33期)2015-02-27 10:40:09
中国卫生(2014年2期)2014-11-12 13:00:16
