
近红外光谱技术快速鉴别北安地区大豆的研究
2020-07-20 12:27阮长青鹿保鑫梁雪梅李志江张爱武张东杰
农产品加工 2020年12期
阮长青 ,鹿保鑫 ,梁雪梅 ,李志江 ,张爱武 ,张东杰
(1.黑龙江八一农垦大学食品学院,黑龙江大庆 163319;2.黑龙江省农产品加工与质量安全重点实验室,黑龙江大庆 163319;3.北大荒现代农业产业技术省级培育协同创新中心,黑龙江大庆 163319)
黑龙江省是我国大豆主产区,而北安则是黑龙江省大豆的主产区。市场经常会出现一些以次充好和冒牌的黑龙江大豆、北安大豆。如何保护和提升黑龙江省大豆品牌优势,实现原产地溯源和种质资源保护,进而提升大豆种植业和加工业整体水平,成为农业科技者和监管机构关注的问题。
产地鉴别、溯源技术对特色名优品牌产品保护的应用日益广泛[1]。近红外光谱分析技术将样品中有机分子含氢基团的特征信息,用于对比光谱曲线趋势不同、不同地区、组成与含量不同的大豆样品,从而确定未知样品与已知样品的关系,具有样品制备简单、无污染、分析快速的特点[2]。
由于大豆中矿物元素含量在不同地域间存在差异,利用矿物元素进行的大豆产地判别是可行的[3],但检测的设备昂贵、成本高、周期长。研究表明,近红外高光谱成像技术可实现大豆非转基因亲本与转基因品种的判别分析[4],利用近红外光谱分析的理论及技术优势对非转基因大豆进行产地鉴别是一种有益的尝试。从黑龙江省不同产地和品种的大豆样品中筛选出有明显差异的光谱波段,结合化学计量手段,建立近红外光谱定性、定量分析模型并进行北安地区大豆的产地判别。
1 材料与方法
1.1 材料
随机选取北安地区地理标志的63份大豆样品,其他3个地区108份,在每个区域的9个采样点按“S”进行布点,随机采样获得共计171份样品,每500 g为一个样品。
样品经挑选、清洗、60℃下干燥、磨粉、筛分(100目),密封于-20℃条件下保存备用。
1.2 营养成分测定
采用凯氏定氮法、索氏抽提法、灼烧法、苯酚-硫酸法分别测定蛋白、油脂、总灰分、可溶性糖含量[5-8]。
1.3 光谱采集
傅立叶近红外光谱仪开机、预热,每隔1 h扫描一次背景,单通道采集光谱。漫反射镀金积分球,InGaAs检测器,分辨率8 cm-1,环境温度25±1℃,相对湿度20%~30%,光谱范围12 000~4 000 cm-1,扫描64次。
1.4 产地判别模型的建立及验证
1.4.1 建模和预测
随机选择北安和其他地区全部样品量的2/3作为训练集样品,用于模型的建立;1/3作为验证集样品,用于模型的验证。北安地区建模训练集样品个数为42个,预测集样品个数为21个;其他地区建模训练集样品个数为72个,预测集样品个数为36个。
1.4.2 基于定性分析的大豆产地判别模型
利用OPUS7.5软件选出有明显差异的波段建立定性分析模型。预处理方式分别为矢量归一化(SNV)、一阶导数(FD) /平滑、一阶导数/SNV/平滑、二阶导数(SD) /平滑、二阶导数/SNV/平滑等,平滑点数分别记为5PS、9PS、13PS、17PS、21PS、25PS,为防止外界干扰、提高模型精度,采用因子化法对光谱进行计算处理。通过比较S值来确定最优预处理方式及光谱计算方法,建立定性分析模型[9-10]。
1.4.3 基于定量分析的大豆产地判别模型
采用交叉检验以偏最小二乘法(PLS)在特征波段建立定量分析模型。将北安大豆组分值用1表示,其他地区大豆组分值用-1表示,以0作为中间值判断真伪。通过模型将计算值大于0的视为北安大豆,小于0的为其他地区大豆,系统自动优化筛选出最优波段及预处理方式,光谱的预处理方式有消除常数偏移量、减去一条直线、SNV、最小-最大归一化、多元散射矫正(MSC)、内部标准、一阶导数/平滑、二阶导数/平滑、一阶导数/减去一条直线/平滑、一阶导数/SNV/平滑、一阶导数/MSC/平滑等,通常采用检验集检验方式进行模型检验,并最终建立定量分析模型。定量分析模型判别方法选用PLS,用一个线性模型来描述独立变量Y与预测变量组X之间的关系。
1.4.4 模型验证方法
利用OPUS 7.5软件分别选择定性分析,聚类分析测试和定量分析工具栏,调入模型,调入预测样品光谱图,获得结果。
2 结果与分析
2.1 大豆营养成分差异性分析
不同产地大豆品质的差异分析见表1。
由表1可知,不同地区其营养成分含量差异较大,北安大豆中蛋白质、油脂、可溶性糖及灰分含量均高于其他地区大豆(p<0.05),可溶性糖的含量比其他地区大豆高出近10%,这可能与北安地区独有的气候和土壤环境有关[11]。试验表明,将样品大豆营养成分作为鉴别北安大豆的指标是可行的。

表1 不同产地大豆品质的差异分析
2.2 大豆近红外光谱分析结果
北安与其他地区大豆的近红外光谱图见图1。
经过不同的预处理后,对北安大豆与其他地区大豆进行红外光谱扫描(图1),在7 495.12 cm-1处有较宽吸收峰,是脂肪族烃中C-H振动所引起的;在7 945.29 cm-1处的吸收峰是脂肪烃中的-CH2的二级振动所引起的;在8 393.14 cm-1处的吸收峰与蛋白质和脂肪中的N-H键、C-H键、O-H键及C=O键的振动有关。结果表明,不同产地的近红外光谱走势大体一致,利用一阶导数对光谱预处理后进行方差分析,发现品种相同的大豆在不同的产地近红外光谱也存在显著性差异。
2.3 不同预处理方式对定性分析时建模效果的影响
大豆在经过不同的预处理之后,在波段70 00~7 500,7 900~8 400 cm-1处差异明显,出现波段特性,选取波段范围为 7 000~7 500,7 900~8 400,7 000~7 500,7 900~8 400 cm-1区域进行建模分析。
不同的预处理方式对不同波段的影响见表2。

表2 不同的预处理方式对不同波段的影响
由表2可知,根据S值的大小来评价模型的准确度,即S>1时,表示两类样品被唯一鉴别,S值越大模型准确度越高;S<1时,表示两类样品未被均匀鉴别,S值越小模型准确度越低。当采用因子化法结合二阶导数/5点平滑的预处理方式时,北安大豆和其他地区大豆样品均能被唯一鉴别,且S值为1.313,因此选取该预处理方式并建立定性分析模型。
不同地区大豆样品的因子化2D得分散点图见图2。
由图2可知,将近红外光谱技术与因子化法结合在特征波段采用二阶导数/SNV/5点平滑对大米产地进行判别,准确率大于90%以上。
2.4 不同预处理方式对定量分析建模效果的影响
建立近红外光谱与样品组分化学值相关联的模型,采用PLS法根据样品光谱波段的差异波段范围、预处理方式的选择及维数的确立,利用加互验证均方根误差(RMSECV)进行优化处理,得出最优组合。R2为定向系数,其值越大表示预测含量值越接近真值,而RMSECV越小,模型的预测性能越好[12]。大豆中蛋白质、油脂、灰分和可溶性糖的定量分析结果如下。
北安大豆中蛋白质经筛选分析处理后选择无光谱预处理方式,最优组合波段为9 400.9~6 098 cm-1和 5 450.6~4 249.8 cm-1,其 RMSECV 为 0.108,R2为99.46%,维数为10;其他地区大豆中蛋白质采用消除常数偏移量处理方式,组合波段为9 400.9~7 498.5 cm-1和 6 100.9~5 447.7 cm-1,其 RMSECV为0.305,R2为97.26%,维数为7。
大豆蛋白质预测值与参考值、RMSECV与维数的关系图见图3。
北安大豆中灰分采用多元散射校正的预处理方式,选择特征波段7 501.3~6 799.7 cm-1和4 600.6~4 249.8 cm-1为最优组合,其RMSECV为0.066 8,R2为94.16%,维数为6;其他地区大豆中灰分采用消除常数偏移量的预处理方式,特征波段为9 400.9~7 498.5 cm-1和 5 450.6~4 249.8 cm-1,其 RMSECV为0.070 5,R2为93.38%,维数为9。
大豆灰分预测值与参考值、RMSECV与维数的关系图见图4。
北安大豆中油脂采用消除常数偏移量的预处理方式,最优组合波段9 400.9~6 098 cm-1和5 450.6~4 249.8 cm-1,其 RMSECV为 0.064,R2为 99.38%,维数为8;其他地区大豆中油脂采用最小-最大归一化的预处理方式,组合波段为7 501.3~6 098和5 025.6~4 597.8,其RMSECV为0.093 1,R2为 99.48%,维数为8。
大豆油脂预测值与参考值、RMSECV与维数的关系图见图5。
北安大豆中可溶性糖采用SNV的处理方式,选择特征波段为7 501.3~5 447.7 cm-1,其RMSECV为0.010 2,R2为100.00%,维数为10;其他地区大豆中可溶性糖采用无光谱预处理的方式,选择特征波段为 5 775.7~5 447.7 cm-1,其 RMSECV为 0.046 4,R2为99.99%,维数为10。
大豆可溶性糖预测值与参考值、RMSECV与维数关系图见图6。
以大豆4种成分定量优化分析结果确定定量分析模型。PLS法较其他方法建立的回归模型更易于辨识系统信息与噪声,也能够在自变量存在严重多重相关性的条件下进行回归建模,其模型效果具有较高的精度。
2.5 大豆产地溯源模型的验证
调入已建立的定性定量分析模型,对北安大豆和其他地区大豆进行分析。
定性定量分析模型对预测集大豆样品的判定结果见表3。
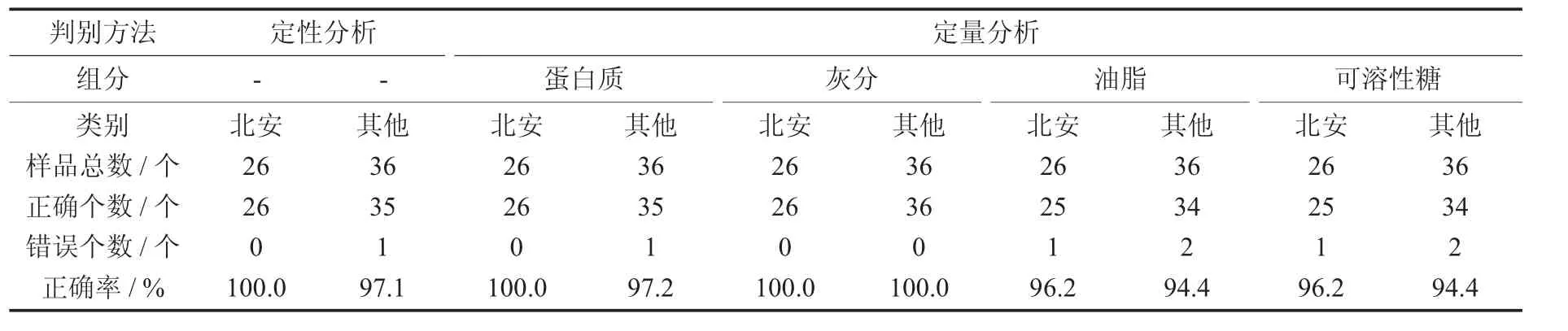
表3 定性定量分析模型对预测集大豆样品的判定结果
由表3可知,定性分析时,北安大豆和其他地区大豆的正确鉴别率分别为100.0%和97.1%。定量分析时,以灰分为基准,北安大豆和其他地区大豆的正确鉴别率均高达100.0%,这可能与北安地区特殊的地质环境,大豆对矿物质的富集能力较强有关[12];以蛋白质、油脂、可溶性糖为基准,正确鉴别率均高于94.4%。表明建立的定性、定量分析模型对北安和其他地区的大豆的产地判别是可行的。
3 结论
选取北安与其他地区大豆共171份样品进行产地鉴别研究,通过因子化法建立了定性鉴别分析模型,其S值为1.313。结果表明,北安地区、其他地区大豆正确鉴别率分别为100.0%和97.1%。采用PLS法建立的定量分析对北安大豆各组分的正确鉴别率分别为蛋白质100.0%,灰分100.0%,油脂96.2%,可溶性糖96.2%。除此之外,其他地区大豆各组分的正确鉴别率为蛋白质97.2%,灰分100.0%,油脂94.4%,可溶性糖94.4%,其中对北安和其他地区的灰分进行定量分析鉴别的正确率最高。由此可知,采用FTNIS法结合因子化法和PLS法所建立的定性分析模型和定量分析模型可以用于快速准确判别北安大豆,对于实现北安地区以及黑龙江省非转基因大豆品牌的保护提供了技术支持。
猜你喜欢
湖北大学学报(自然科学版)(2022年3期)2022-12-01
航天返回与遥感(2022年2期)2022-05-12
波谱学杂志(2022年1期)2022-03-15
火力与指挥控制(2021年10期)2021-12-29
华北理工大学学报(自然科学版)(2021年3期)2021-07-03
延安大学学报(自然科学版)(2020年4期)2021-01-15
党的生活(黑龙江)(2019年4期)2019-04-29
党的生活(黑龙江)(2019年4期)2019-04-29
制导与引信(2017年3期)2017-11-02
科技致富向导(2013年15期)2013-09-09
