
基于随机森林算法的耕地质量定级指标体系研究
2020-07-16 15:14林子聪任向宁朱阿兴胡月明
华南农业大学学报 2020年4期
林子聪,任向宁,朱阿兴,2,赵 鑫,胡月明,3,4
(1 华南农业大学 资源环境学院/华南农业大学 地理信息工程研究所/国土资源部建设用地再开发重点实验室/广东省土地利用与整治重点实验室,广东 广州 501642; 2 威斯康星大学−麦迪逊分校 地理系,威斯康星州 麦迪逊 53706;3 青海大学 农牧学院,青海 西宁 810016; 4 电子科技大学 资源与环境学院,四川 成都 610054)
耕地是特殊的公共资源和最为宝贵的自然资源,是粮食生产的载体,也是保障社会安全及社会可持续发展的物质基础[1]。目前,我国经济发展进入新常态,新型工业化、城镇化建设深入推进,耕地占多补少,占优补劣现象突出,优质耕地正大量流失;同时,由于土壤污染和不合理高强度利用,导致耕地退化,较大地影响了农业的生产力[2-4]。
面对严峻的耕地形势,为摸清耕地资源状况,及时准确地掌握耕地质量现状,把握耕地质量动态,我国开展了耕地质量定级评价工作,即对耕地进行综合评定并划分级别,从而反映因耕地自然质量、现实(或实际可能的)利用水平和效益水平的不同所造成的耕地生产力水平的差异[5]。耕地质量评价工作是保护耕地的主要途径,其有利于分析区域内耕地质量差异,能够优化耕地利用与布局,能够为耕地保护提供参考依据,对耕地的占补平衡、占优补优工作提供指导。
自20世纪80年代末开始,我国许多专家学者对耕地定级的方法不断探究,高中贵等[6]认为:定级指标体系是其定级结果准确可靠的基础,但在实际操作中存在较多困难;金东海等[7]通过对以分等成果为基础的“两层七参数法”的定级新方法研究后认为:定级指标的筛选、权重的赋值是定级方法的关键。
以往传统的定级指标筛选和赋权中,通常采用专家经验法,该方法主要通过专家根据经验对各个定级指标进行打分,累加各定级指标的分值并根据分值大小确认权重[8]。该方法完全根据专家组的经验判断,主观性较强,其选定的定级指标和确认的权重缺乏定量地分析,定级指标之间存在层级关系,相关性较强,导致定级结果不够客观准确。随着科学技术方法的发展,应用耕地产量[9]于数学统计与数学模型的客观定量法能够定量测算定级指标的权重,同时可以避免定级指标之间的相关性,降低定级结果的多重共线性问题。因此,客观定量法已经成为必然趋势[10]。随机森林算法基于分类树构建模型,利用分类树与实际值计算误差得到变量重要性,属于客观定量法。
本文以青海省共和县、都兰县及乌兰县为研究区域,应用随机森林算法,建立耕地产量与自然、社会经济、区位等影响因素的有机联系,同时结合因素的相关性分析结果,确定合理的定级指标及定级指标权重,并与传统方法结果进行比较,为耕地定级工作提供科学依据。
1 材料与方法
1.1 研究区域概况
研究区域位于青海省的共和县、都兰县和乌兰县,是国家生态保护与建设的战略要地,是国家乃至全球重要的水源地和生态屏障,是高原生物多样性基因资源的宝库。另外,青海省生态系统较为脆弱,水土流失、荒漠化、沙化面积扩大,湿地萎缩,草场退化等问题突出,而生态环境的自我恢复能力、净化能力越低的地区,越容易影响到耕地的产出水平。
研究区域地处柴达木盆地东部,山脉、盆地、平原各地貌交错,地势北低南高,平均海拔3 500 m,海拔差最大达3 076 m。位于大陆腹地,远离海洋,具有典型的高寒大陆性气候特点:年降水少、时空分布不均,蒸发强烈、干燥度大;温度低、温差大、日照长、辐射强;冬春季多大风,灾害性天气频繁。研究区域2017年辖3县12镇11乡242个行政村,土地总面积 74 187.94 km2,耕地面积 49 739.29 hm2;总人口26.27万,其中农业人口16.87万,集中分布在研究区域内气候较适宜的平原及盆地地区。耕地的主要作物为小麦、青稞及油菜。
根据研究区域耕地的空间分布特征,在研究区域共布设97个采样点,通过实地问卷调查,收集到2015—2017年耕地产量及对应分布的基础数据。对3年的产量数据取平均值,得到各调查样点的年均产量数据,其数据特征及分布如表1与图1所示。
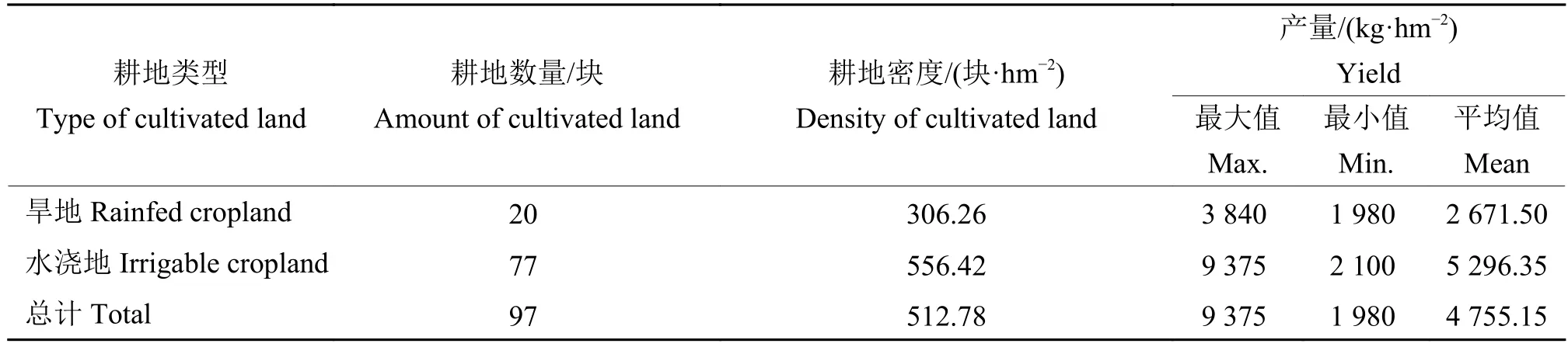
表1 研究区域调查样点产量数据Table 1 Yield information of investigation plot in research area

图1 研究区位置及采样点分布图Fig. 1 Location of the research area and spatial distribution of the sampling sites
1.2 数据来源
目前,各种类型耕地质量评价所构建的评价指标体系都以气候因素、地形自然条件因素和土壤物理化学性状因素等为主。根据耕地质量的概念和内涵,影响耕地质量的因子可分为自然因素和社会经济因素两类[11-13]。此外还有一些研究表明,随着高标准农田建设的开展,耕地工程要素对农业生产的便捷性、经济性具有重要影响[14-15]。
因此,本文收集的影响因素分为以下5类:1)自然因素:气候数据,包括温度、降水、太阳辐射等;基础地理数据,主要包括海拔、地形坡度;土壤理化数据;水资源状况数据。2)生态因素:指研究区域生态系统的脆弱程度,自然灾害等易发程度。3)社会经济因素:指基础设施、耕作便利程度、土地利用方面数据。4)区位因素:指城镇、农贸市场、道路等对耕地的影响。5)工程因素:指高标准农田建设中的土地整治工程。
气候数据是依据马昊翔等[16]制作的青海省生长季均温图、青海省生长季降水图,保广裕等[17]制作的青海省年太阳总辐射量空间分布图获得;基础地理数据是根据中国科学院计算机网络信息中心地理空间数据云平台(http://www.Gscloud.cn)获取的30 m分辨率数字高程图,在Arcgis10.2中提取海拔和坡向获得;依据2017年共和县、都兰县和乌兰县耕地质量定级成果,获取有效土层厚度、表层土壤质地、砾石含量、土壤有机质含量、土壤酸碱度、灌溉保证率、灌溉水质量、田块形状、田块大小以及利用现状等耕地质量定级指标值;生态因素依据的是全国主体功能区规划[18]中的自然灾害危险性评价图、生态脆弱性评价图及青海省国土局制作的青海省水土流失状况评价图;依据2016年共和县、都兰县和乌兰县的土地利用现状数据库,获取道路、城镇、农贸市场、耕地等分布数据,在Arcgis10.2中通过与耕地进行空间分析,获取耕作距离、农田破碎度、农田路网密度、城镇影响度、农贸市场影响度、道路通达度、对外交通便利度等状况数据;工程因素是对2012—2016年共和县,都兰县和乌兰县的高标准基本农田整理项目资料进行数据化,得到灌溉排水工程、道路工程、农田防护林工程、土地平整工程的分布及工程建设状况。
影响因素数据类别及描述如表2所示。
1.3 分析方法
1.3.1 随机森林算法 随机森林是由 Breiman 等[19]在2001年提出的一种基于分类树的算法,具有防止过拟合、模型稳定性强以及易于处理非线性回归等特点,由于其良好的性能表现,在众多领域的问题解决中都取得了不错的效果[20-26]。

表2 影响耕地质量的因素Table 2 Factors impacting the quality of cultivated land
随机森林是基于二进制分割数据解决分类和回归问题的算法[27]。随机森林算法首先采用Bootstrap抽样技术从原始数据集中抽取N个训练集,每个训练集的大小约为原始数据集的2/3; 然后,为每个训练集分别建立分类回归树,产生由n棵分类树组成的森林,在每棵树生长过程中,从全部M个特征变量中随机抽选m个(m≤M)特征变量,在这m个属性中根据Gini系数最小原则选出最优属性进行内部节点分支;最后,集合n棵分类树的预测结果,采用投票的方式决定新样本的类别,每次抽样约有1/3的数据未被抽中,利用这部分袋外数据(Out-of-bag,OOB)进行内部误差估计,产生OOB误差[28]。
随机森林算法利用OOB误差计算特征变量重要性(I):首先,根据袋外数据计算随机森林中每个分类树的袋外误差(E);然后,随机改变袋外数据第j个特征变量()的值,并计算新的袋外误差();最后,变量的重要性[I()]表示为

随机森林算法通过R语言软件平台实现,运行过程中需要至少定义2个参数:分类树的数目(n)和节点分裂时输入的特征变量个数(m)。若做分类分析,则m设定为变量个数的平方根,回归分析则设定为变量个数的1/3[31]。本研究影响因素为30个,因此,n=500,m=5,其余参数均根据模型默认值进行设定。
1.3.2 相关性分析 通过 SPSS19.0 平台,对在随机森林模型中模拟的各影响因素进行Pearson相关性分析。
1.3.3 定级方法 1)定级指标量化:根据定级指标分布类型及对定级评价单元的影响方式,对定级指标分为3类进行量化。其中:面状指标包括耕作距离、农田破碎度、林网化密度和城镇影响度;线状指标包括道路通达度和农田路网密度;点状指标包括农贸市场影响度和对外交通便利度。面状指标的量化主要通过直接指标或者间接指标进行,线状指标的量化则采用线性衰减法进行。
2)定级评价单元划分:定级单元是级别划分和质量评定的基本空间单位,单元划分的主要方法为地块法、网格法和叠置法。本文为了保持原始地类图斑的自然属性和形状,与土地利用现状图中的耕地图斑保持一致,更贴近现实耕作情况,采用地块法[32]进行定级评价单元划分,最终划定定级单元数为 9 219。
3)定级指数与级别划分:定级指数计算采用加权求和法[33]。耕地级别一般根据单元定级指数值进行划分,通常采用等间距法、数轴法或总分频率曲线法进行土地级别的划分。本文采用等间距法对单元定级指数进行级别划分。
1.3.4 特尔菲法 目前耕地质量定级评价工作中,应用特尔菲法确认定级指标体系是比较常用的方法,本文将研究成果与采用特尔菲法的定级结果进行对比分析,尝试分析随机森林算法的优势与不足。本文采用的特尔菲法的定级指标体系如表3所示,共计30个指标作为影响因素。

表3 采用特尔菲法的定级指标体系Table 3 Grading indicators system using Delphi method
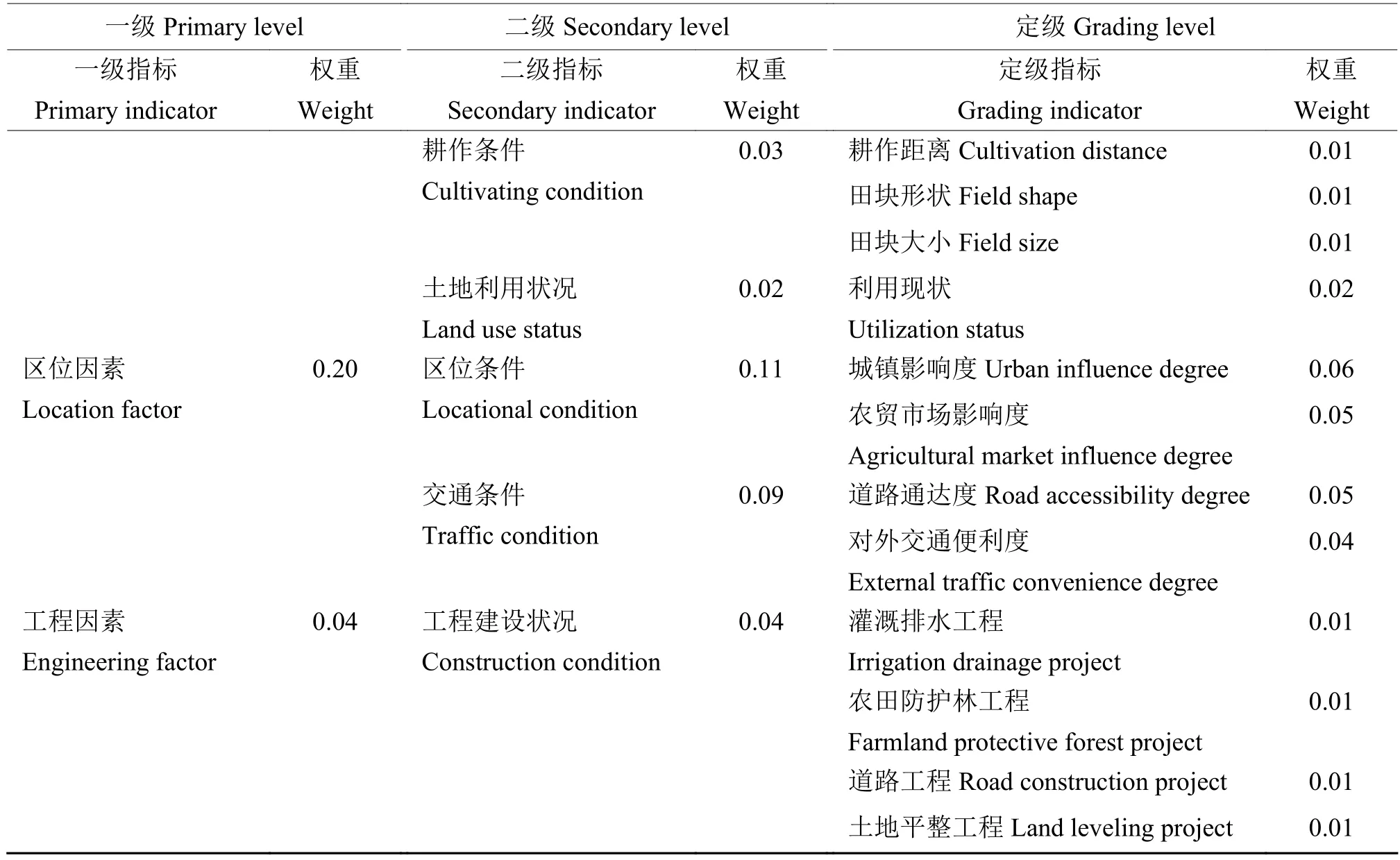
续表 3 Continued table 3
2 结果与分析
2.1 随机森林算法分析结果
以97个产量采样点2015—2017年的平均标准产量作为因变量,30个影响因素作为自变量建立随机森林回归模型,并对30个影响因素进行重要性分析。模型的预测产量与实际产量的拟合度(R2)达到79.47,反映出模型的拟合度较好。
表4列出了随机森林模型分析的变量重要性I值。30 个影响因素的变量重要性I值在 0.03~11.94,其中生态系统脆弱性、生长季平均降水和自然灾害危险性的重要性较强,I值分别为11.94、10.63和10.01。年总太阳辐射量、土壤酸碱度、灌溉水质量、对外交通便利度、地形坡度、生长季平均温度、农田破碎度、城镇影响度、农贸市场影响度、土壤有机质含量、水土流失状况和耕作距离的I值在 5.70~9.08,其他 15 个影响因素的I值在4.74以下。
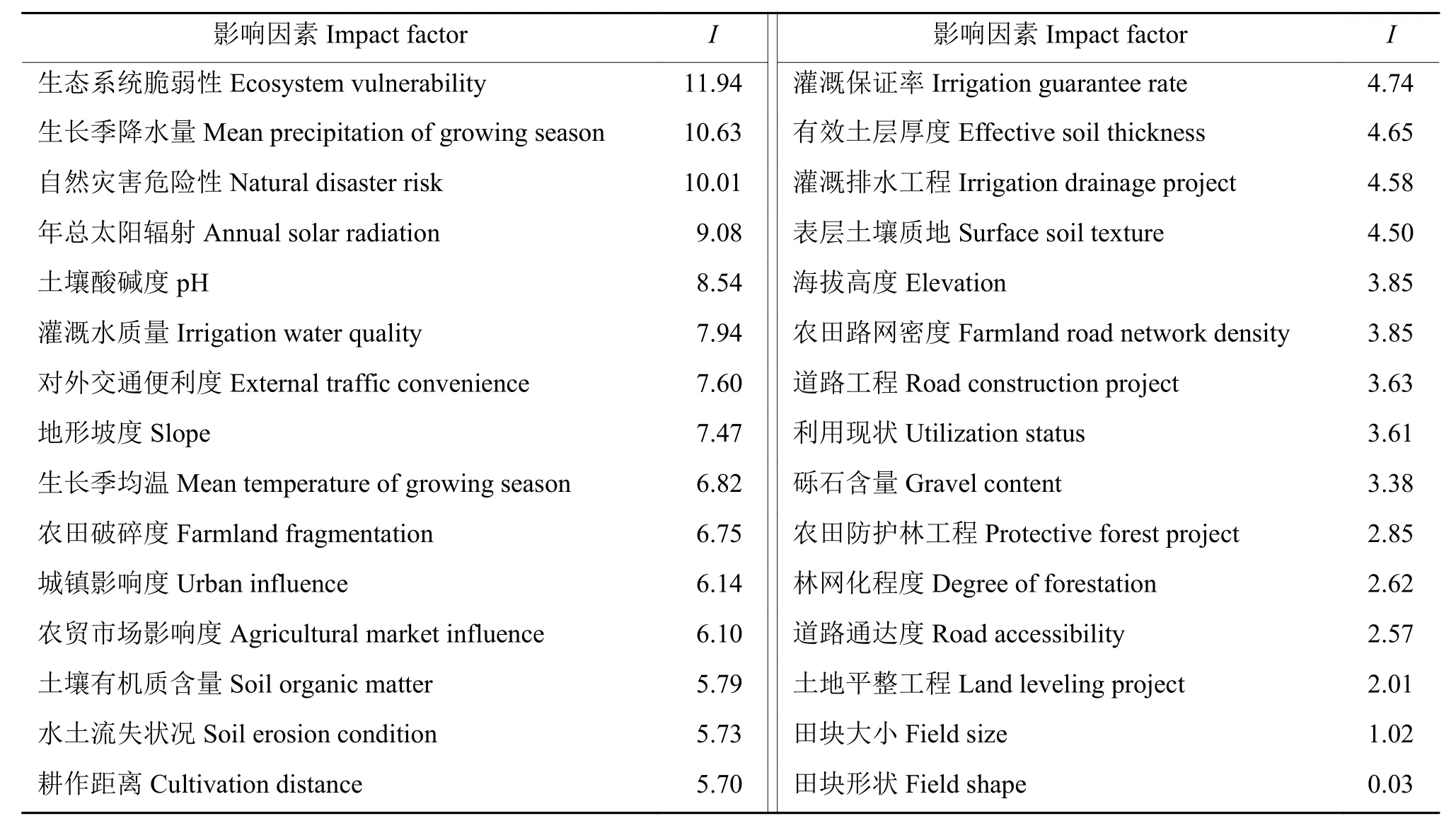
表4 随机森林算法对影响因素的变量重要性(I)排序Table 4 Variable importance (I) ranking of impact factors by random forest algorithm
2.2 相关性分析结果
对30个影响因素进行Pearson相关分析,结果显示,大部分影响因素间相关性不显著。其中有8个影响因素为显著相关(表5):自然灾害危险性与生态系统脆弱性的Pearson相关系数r=0.957,为显著正相关;表层土壤质地与砾石含量的相关系数r=0.790;灌溉排水工程、道路工程、农田防护林工程和土地平整工程之间r>0.850 ,结果表明,在该研究区域,以上影响因素之间存在较强的相关性,会对定级结果造成多重共线性的问题。
在面对多重共线性问题上,最常用做法是保留重要解释变量,去掉次要或可替代解释变量。然而,相关性分析虽然可以判断影响因素之间的相关性,但是无法识别其中重要的解释变量。因此,本文结合随机森林的变量重要性的分析结果进行了解释变量的识别。

表5 显著相关影响因素的相关系数1)Table 5 Correlation coefficients matrix of significantly related impact factors
2.3 定级指标体系
对重要性I值进行标准化后的研究区域的定级指标体系如表6所示,这套耕地质量定级指标体系的一级指标权重序列为自然因素>区位因素>生态因素>社会经济因素,其中自然因素权重最大,为0.53;区位因素和生态因素分别为0.19和0.16,社会经济因素权重最小,为0.12。该套耕地质量定级指标体系包含了生态环境状况、气候状况、地形状况、土壤条件、水资源状况、基础设施条件、耕作便利条件及区位、交通等方面,选取的指标都不同程度地对研究区域耕地质量有所影响,其权重与影响程度比较相符,能够比较合理地评价研究区域的耕地质量。
2.4 随机森林算法和特尔菲法定级结果的比较
从随机森林算法和特尔菲法定级结果(图2)可知,随机森林算法和特尔菲法计算的耕地质量定级结果具有比较相似的空间分布情况,即共和县东部及乌兰县中部耕地级别较高,共和县西部及南部比较低,但局部地区定级结果存在较大差异。由于研究区域耕地分布较为零散,难以从总体空间和数量上对比2种方法定级结果的差异,故在研究区内设置能够穿越最多耕地斑块的2条典型样带,对随机森林算法及特尔菲法的定级结果进行比较观察,即“东北−西南”样带及“西北−东南”样带,样带宽度为5 km(图3)。

表6 耕地质量定级指标体系Table 6 The index system of cultivated land quality grading

图2 研究区域2种方法的定级结果及空间分布图Fig. 2 The grading result and spatial distribution map of two methods in the research area
从对样带的定级结果(图4)可知,随机森林算法和特尔菲法的定级结果空间变化趋势基本一致的趋同性强,对同一地块的级别高低判断基本一致,都能够较好地体现出耕地级别的空间变异性。另外,随机森林算法更加稳定,级别变化程度小,更有利于构建省级空间尺度的耕地级别可比序列。

图3 研究区域2条样带位置图Fig. 3 Position of two sample belts in the study area
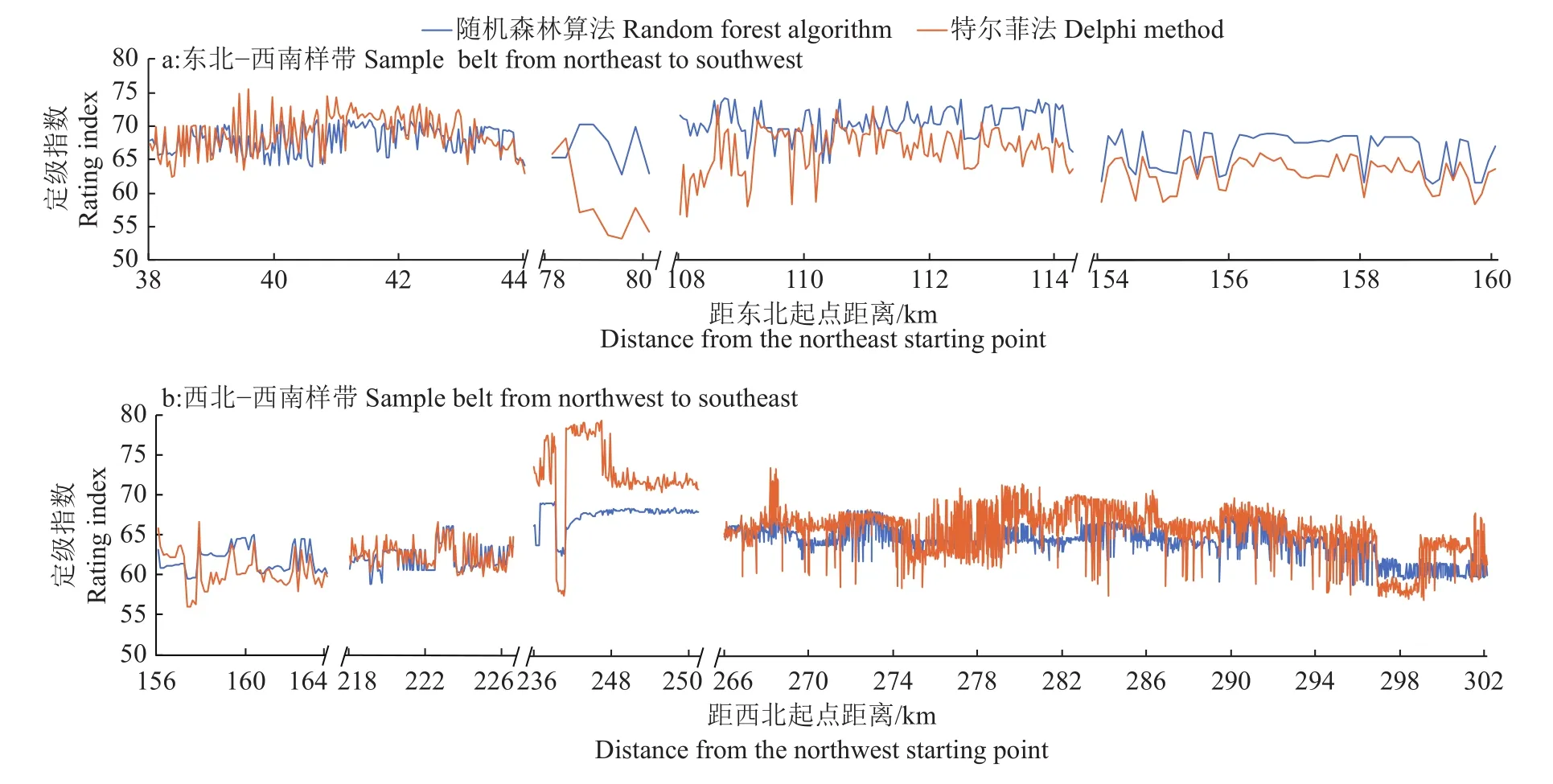
图4 随机森林算法和特尔菲法对2条样带定级结果的对比Fig. 4 Comparison of grading results of random forest method and Delphi method to two sample belts
在西北−东南样带第220 km处,随机森林算法的定级结果与特尔菲法比较相似。该位置地形平整,土壤质地为壤土,有效土层厚度大于1 m,土壤有机质含量较高,但生长季降水及温度条件较差,距离共和县城区较远,区位条件较差。表明尽管随机森林算法比特尔菲法的定级指标数量较少,但定级结果由于权重的大小调整,未影响定级结果的准确性,随机森林算法能够有效地表现研究区域耕地级别的空间变异性。
其次,在东北−西南样带第110 km处,随机森林算法的定级结果显著高于特尔菲法的定级结果。此处耕地位于柴达木盆地的东部,年总太阳辐射量为 6 735 MJ·m-2,生长季平均气温为 11~12 ℃,生态系统脆弱性类型为略脆弱型。在研究区域中该位置耕地的太阳辐射量较大,生长季气温高,生态环境比较稳定,是青海省著名的春小麦高产区。表明随机森林算法能够通过变量重要性值大小的设置,充分体现以上定级指标对耕地质量的正向影响作用,有效识别出研究区域的优质高产耕地,修正研究区域中高值低估的状况。另外,在西北−东南样带第290 km位置,随机森林算法的定级结果显著低于特尔菲法。该区域靠近城镇及国道,生长季温度为10~11 ℃,生长季温度较高,降水比较充足,区位和交通条件优越。然而该区域位于研究区域中人口总量最多的共和县,耕地开发程度较高,生态系统脆弱性类型为一般脆弱型,人与自然矛盾比较突出,脆弱的生态环境限制了耕地的耕作;另外,该地区的太阳辐射量为研究区较低的区域,较大地限制了耕地作物的产量。表明由于特尔菲法定级指标体系的定级指标过多,各定级指标权重值的差异较小,无法突出一些重要的定级指标,定级结果易受到多影响因素的综合影响,造成低值高估的现象。总之,随机森林算法稳定性更好,级别指数变幅区间更小,更有利于构建省级空间尺度的耕地级别可比序列。
3 讨论与结论
随机森林算法计算得到耕地质量定级指标体系,对该体系的研究结果表明,自然因素是对研究区域耕地影响最大的方面,本文从自然因素的定级指标分别讨论其对研究区域耕地质量的影响。
生长季平均降水和灌溉水质量这2个定级指标描述了耕地灌溉情况,也是影响研究区域耕地质量的重要因素。年降水不足,灌溉条件较差,均直接制约着青海省农作物的单产。青海省气候干燥,蒸发量远大于降水量,使农作物的需水量剧增。当降水充足、灌溉水质量高时,将直接影响作物吸收的水分、土壤养分的质量[34]。年太阳辐射量的权重为0.09,排权重的第3位,对研究区域耕地质量影响较大。青海省尤其是研究区域中位于柴达木盆地的部分,太阳辐射量仅次于西藏,是青海省发展农业的重要优势,其对于小麦的茎秆发育、扬花、灌浆的作用十分明显,直接影响耕地的产量[35]。青海地区属于高原大陆性气候,易形成土壤盐渍化[36],土壤pH也是影响耕地产量的因素之一。地形坡度对地区水热条件的能量交换起重要作用,同时直接影响土壤的形成和植被的生长发育。生长季平均温度对生物的正常发育和生长起着决定性的作用,决定农作物的耕作制度。土壤有机质提供植物生长发育所需要的养分,其含量能影响耕地的产出。
本研究首先根据研究区域相关部门的研究成果、相关文献及实地农业调查,整理出影响研究区域耕地质量的30个影响因素,并收集了研究区域近3年的耕地产量数据。其次,对影响因素进行相关性分析,并将耕地产量与该30个影响因素建立随机森林回归模型。通过综合影响因素的相关性分析结果及随机森林变量重要性结果,将30个影响因素筛选为14个定级指标,构建了本研究区域的耕地质量定级指标体系,并对研究区域的耕地进行了质量定级。最后将定级结果与定级工作常用的特尔菲法成果进行对比分析,得出以下结论:1)将随机森林算法与相关性分析结合,构建了定级指标体系。指标体系同时涵盖生态因素、自然因素、社会经济因素和区位因素共4方面,既包含了大尺度上生态、气候和区位影响因素的指标,同时又考虑精细到地块尺度的土地属性,结果可以比较全面地评价研究区域耕地的质量。2)通过对随机森林算法和特尔菲法定级结果的比较,2种方法定级结果的趋同性强,对同一地块的级别高低判断基本一致,都能够较好地体现出耕地级别的空间变异性;随机森林算法稳定性更好,级别指数变幅区间更小,更有利于构建省级空间尺度的耕地级别可比序列,为随机森林算法的应用及耕地质量定级指标体系的构建提供了新的依据。
此外,本研究的部分呈面状分布指标如生态系统脆弱性,自然灾害危险性等,无法有效表示各程度影响的渐变过程。同时,生态系统的变化比较剧烈和频繁,如何使指标精确定量化是评价耕地质量需要解决的重要问题,有待今后进一步的研究探索。
猜你喜欢
中国化肥信息(2022年8期)2022-12-05
今日农业(2022年13期)2022-11-10
今日农业(2021年14期)2021-11-25
当代陕西(2019年10期)2019-06-03
动漫界·幼教365(大班)(2018年11期)2018-05-14
疯狂英语·新悦读(2018年3期)2018-03-07
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
作文大王·笑话大王(2016年2期)2016-02-24
