
基于计量风格学的多层次特征在作者识别应用研究∗
2020-07-13 12:48钟敏汪洋
计算机与数字工程 2020年5期
钟 敏 汪 洋
(1.武汉邮电科学研究院 武汉 430074)(2.南京烽火软件科技有限公司 南京 210079)
1 引言
风格学一直以来被广泛地研究讨论,其主要内容是研究文章的特征。作为应用语言学一个分支,一般被语言学的研究人员用于分析文章风格,并用于帮助写作人员提升写作技巧[1]。作者风格可以认为是一系列风格学定义的属性,最开始风格学在作者识别领域的研究基础是基于对特定词的使用或者不使用[2],随后作者风格的研究上升到了语法等层面,以及统计学的发展与应用,风格学中引用了大量的统计学特征,风格学也发展成为了具有统计学特征的计量风格学[3~4]。作者识别问题的研究总是离不开讨论风格学,使用计量风格学来进行作者识别的原理是建立在每个作者都有一个独特并且可验证特征的假设上,并通过定义高维的特征向量空间来实现识别。
国外最早使用风格学方法分析作者的是英国逻辑学家 Augustus De Morgan[4],他提出用长短词分析作者风格,国外较为广泛的研究是对莎士比亚作品的风格研究。我国是四大文明古国之一,具有悠久的历史和灿烂的文化,但是不少脍炙人口的文学作品却因为各种原因而无法确定作者,风格学的研究,正是在这种情况在发展起来,其中对红楼梦的前80回与后60回是否为同一作者的研究最为广泛。在此基础上,中科院声学所张运良等使用概念层次网络(HNC)标注句类特征,并结合向量空间(VSM)的方式来实现对作者写作风格分类,在11个作者的文本集上最好效果达到84.0%[5]。清华大学孙晓明,金奕江等使用虚词和VSM结合的方式来实现小说的分类,在13个作者的数据集上,使用了模板匹配算法,KNN算法和SVM算法的最好准确率分别是 89.51%,91.54%,93.58%[6]。常淑惠等采用语言,结构和格式结合的方式,对5个作者共150个邮件进行识别,最好的F1值达到了98.36%[7]。
在词汇层面的基础上增加语义信息,能够增强特征的可说服性,也就增加结果的可信服性[8]。语法层面的分析有很多种,以词性为对象来研究作者特征,在英文作者识别中有较好的表现[9]。但是以词性序列结合中文语法结构分析特点的研究还不是很多,本文提出了一种以文本词性标注序列为数据集,采用关联挖掘的Apriori算法来挖掘文本中具有一定关联程度的词性序列作为特征的方法,并结合虚词词性,中文知识库HowNet的情感词库作情感映射得到文本的情感偏向[10],以及句长,词长,词语丰富程度等一些传统结构上的特征,构成多层次的丰富特征向量,采用机器学习分类方法进行分类,实现了提升作者识别问题的准确性,以及理论上的可说服性。
2 词和词性序列
2.1 实词和虚词
根据现代汉语词的语法特征,可以将词分为实词和虚词两类,实词包括名词、动词、形容词、数词、量词、代词,虚词包括副词、介词、连词、助词、叹词、拟声词[11]。汉语语法中的虚词在英语语法中也称为功能词,与国外学者使用功能词进行英文作者识别一样,使用虚词来进行中文作者识别的研究也有很多,使用实词分析的方法较少。实际上,风格学认为,作者的风格是独立于文章内容的,而实词容易带有作者的内容信息,实词是不适合作为作者识别特征的。虽然实词不适合用来作为作者识别的特征,但是实词词性可以用来研究作者写句子时不同词性的词的使用规律。
2.2 词性序列
如图1所示,现代汉语语法的几个层面分别是词、短语、句子、段落文章。短语由词组成,也是句子的组成成分,所以以短语作为研究对象相比词能够增加语义信息,相比句式,增加了灵活性。

图1 现代汉语语法层次
受到中科院声学所张运良等使用概念层次网络(HNC)标注句类特征理论基础句子有限而句类无限的理论启发[5],本文认为组成句子的短语虽然无限,但是短语的类型应该是有限的。短语的词性序列能够反映作者在写作构成句子时的用词搭配习惯,体现词性之间的距离特点,理论上能达到区分作者的写作风格差异的目的。所以本文使用词性序列作为组成文本向量特征空间(Text Vectors Space)的组成成分之一的方法,用来提升作者识别的准确性和说服性。
本文采用的是哈工大发布的开源切词工具hanlp作为切词和词性标注工具,hanlp词性共148,二项词性序列共有21904组合,三项词性序列总计有3241792组合,不是所有序列组合都能出现在文章中,且并非所有在作者文章中出现的词性序列都能作为作者的风格特征。因此需要采用一些筛选方法来选择具有可靠性或者可信度的特征。因为筛选的目的是选取作者常用且具有一定可信度的词性序列,而不是随机组成的词性序列,关联挖掘方法Apriori算法是经典的挖掘频繁项集的算法,也是挖掘关联规则算法的常用算法之一,其应用主要是通过减少项集组合的数目,来达到减少搜索空间大小以及扫描次数的目的,恰好能挖掘得到可靠的词性序列。本文以实验文本中的句子词性序列数据库作为挖掘具有关联的词性序列,其流程如图2所示。

图2 词性序列数据库生成流程
3 Apriori算法词性序列挖掘过程
3.1 Apriori算法中的支持度与置信度
Apriori算法核心思想是通过连接产生候选项及其支持度,然后通过剪枝生成频繁项集。其中项集是项的集合,包含k个项的项集称为k项集。支持度反映两个项同时出现的可能性,置信度反映了两个项集之间的关联强度[12]。项集A,B同时发生的概率为关联规则的支持度,记为Support(A⇒B)(简记为S(A⇒B)):

项集A发生的前提下,B发生的概率为关联规则的置信度,记为Confidence(A⇒B)(简记为C(A⇒B)):

项集A的支持度计数是项集的频率或者计数,记A,B项集同时发生个数为S_count(A∩B),所有项集同时发生个数为Total_count(A),则项集A,B的支持度S(A⇒B)计算方式如下:

项集A,B的置信度:

最小支持度是用户或者专家定义的衡量支持度的一个阈值,标志项集在统计意义上的最低重要性,最小置信度是用户或者专家定义的衡量置信度的一个阈值,标志关联规则的最低可靠性,同时满足最小支持度阈值和最小置信度阈值的规则称作强规则。
3.2 词性序列挖掘过程
Apriori算法主要为两个过程,一个是找出所有频繁项集,一个是由频繁项集产生强关联规则。在挖掘频繁项集合最强规则前,需要给出最小支持度和最小置信度的值。因为支持度反映项集的出现频率,本文选择了小概率事件中的临界概率0.01作为最小支持度。置信度反映的是规则的可靠程度,本文选择0-1均匀分布的期望,也就是0-1事件的任一发生概率0.5,作为最小置信度来选择词性序列的频繁项集。
词性序列挖掘的第一步,找到所有的频繁项集,首先和一项序列结合生成k+1项,再通过最小支持度和频繁项集的子集也是频繁项集这一原理进行剪枝,其过程如图3所示。第二步是在所有频繁项集的基础上,计算项集的置信度,与最小置信度为筛选条件,得到满足最强规则(最小支持度和最小置信度)的序列项集,其样例如表1所示。
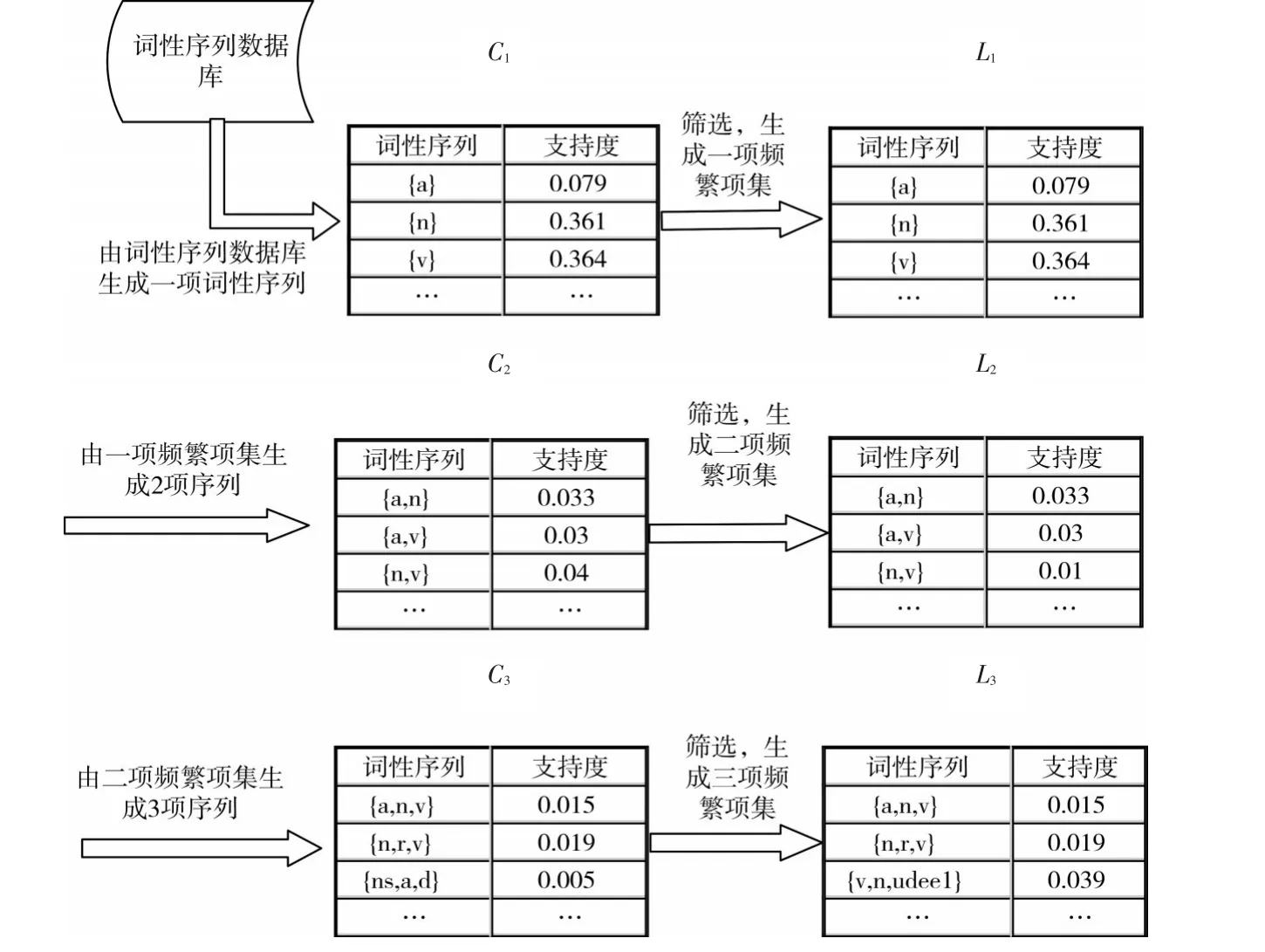
图3 频繁项集生成过程

表1 关联词性序列样例
使用以上方法挖掘得到的每位作者的频繁项集,并通过取每一位作者与其他作者差集的方式,找到每个作者独特的词性序列组合,共得到22个词性序列特征。
4 实验数据与文本向量
4.1 实验数据说明
从大众的认知基础上分析,如果作者的风格差异较大,比如鲁迅和张爱玲的风格对比来看,鲁迅是批判现实的短篇小说家,散文家,张爱玲是以描写生活风月为主的小说作家,无论是人为的根据经验,还是使用统计方法,都是比较容易区分的。武侠小说作者金庸、古龙、东方玉、梁羽生所处时代相似,都是比较有名且具有代表作品的武侠小说作者,因为创作时间和主题相似,且部分作品会受到先发表作品的作者影响而具有一定的风格相似性,如果不是有非常丰富的经验,或者是采用复杂的统计学方法,是比较难以区分的[13]。所以本文使用Python爬虫工具和解析工具从武侠小说网站清洗得到了四位作者的部分或者全部小说作品作为了本次的实验数据如表2。

表2 实验数据说明
4.2 文本向量构成
风格学研究至今,对写作风格分析的特征选取一般分为词汇特征,语法特征,结构特征,非语言特征四大模块,这四个模块分别包含一些小的可选取子模块,其子模块样例如表3所示。
其中结构特征被广泛认为是稳定可区分作者的特征,本文选取了词长平均,词长方差,句长平均,句长方差等常用的结构特征共7个。同时因为非语言模块中作者的情感倾向也能反映作者的风格,本文以知网的hownet知识库中的情感词作为映射,统计文章的消极情感词汇和积极情感词汇,以及正面评价词汇和负面评价词汇占比等8个情感偏向特征作为特征向量成分之一。

表3 风格学特征模块样例
综合以上分析,本次实验特征向量构成成分分为四个部分,总共83个:
1)通过Apriori算法挖掘得到的关联词性序列22个;
2)虚词词性特征共46个;
3)包括词长,句长等文本结构特征共7个;
4)包括情感词和评价词等情感特征共8个。
5 分类器选择与结果分析
用于分类的机器学习方法有很多,常用的有逻辑回归,随机森林,K近邻算法等等。随机森林是集成学习器,具有较好的分类能力和稳定性[14]。逻辑回归分类器是简单易懂的分类器,其缺点是其适用场景和数据有限,不如随机森林强[15]。K近邻是理论比较成熟的方法,不需要训练模型,只在测试数据中进行计算,其缺点是在在数据量小的时候容易误分,只适合样本容量比较大的数据[16]。本文使用以上三种分类器,采用F1值作为评价指标,计算十次实验结果取平均值和方差,分别用来衡量分类器的并计算十次结果的方差(分类结果后括号内)的方差作为得到三个分类器表现如下表4所示。

表4 作者识别结果
综合表现来看,东方玉、古龙、金庸三位作者使用随机森林做分类的准确率最高,梁羽生使用逻辑回归的准确率最高,但是随机森林分类结果的方差最小且最平稳,表明了随机森林作为一种集成的分类器,其本身分类能力较好且稳定,适合作为作者识别模型的分类器。
同时,采用随机森林重要程度排序的功能,对特征的重要程度排序,取前20个重要特征,排序结果如表5所示。

表5 随机森林特征排序结果
根据排序可以看出,具有关联特征的词性序列在作者在区分作者写作风格中具有一定的重要性,但是虚词明显比词性序列作用更强,因此,对虚词在在作者识别应用中的研究,可以作为下一步研究的方向之一。
此外,词性序列写作特征不仅可以用于作者识别中,结合现在十分火热的机器写作来看,因为其语法的约束性,也可以用于其中,为机器写作增加一定的语法约束,提高写作的水平。
6 结语
本文是受到HNC的句类理论启发提出的使用具有关联度的词性序列作为特征向量组成成分之一,经过实践验证,具有关联的词性序列特征确实能达到提升识别作者的效果,但是随机森林的特征排序结果显示虚词词性的统计值在分类过程中影响程度更大,为此,在下一步研究中,将从虚词特征着手,进一步通过提高特征质量来提高作者识别这一应用中的准确率和召回率。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
小型微型计算机系统(2022年4期)2022-05-09
语文周报·教研版(2021年10期)2021-05-08
中国科技纵横(2016年20期)2016-12-28
文贝:比较文学与比较文化(2016年1期)2016-11-14
环球人文地理(2014年14期)2014-08-15
