
时空轨迹相似度计算方法研究与实现∗
2020-07-13 12:48涂刚凯
计算机与数字工程 2020年5期
涂刚凯 耿 鑫
(1.南京烽火天地通信科技有限公司 南京 210019)(2.武汉邮电科学研究院 武汉 430074)
1 引言
随着卫星定位技术、无线通信、跟踪检测设备以及视频实时采集技术的日益成熟,能够方便人们低代价地获得时空轨迹数据。针对时空轨迹的的研究也是层出不穷,比如轨迹聚类、路径预测、兴趣区域推测等。如何利用时空轨迹数据,深度挖掘出时空轨迹特征属性,成为了工业界和学术界的热点问题。唐炉亮[1]等提出了一种基于车载GPS轨迹数据的路网拓扑自动变化检测新方法,魏争争[2]提出了一种加入气温影响因子的隐马尔科夫轨迹预测算法来完成鸟类迁徙运动过程中的时空轨迹预测。喻钢[3]提出了一种双向长短时记忆(Long Short-Term Memory,LSTM)和残差网络为主要结果的时空轨迹模型(Spatio-Temproal Trajectory Mod⁃el,STTM)有效根据出租车轨迹预测行程时间。邓佳[4]提出了一种基于HMM模型的轨迹聚类方法(HMM-Cluster),有效地聚合相似性轨迹,发现交通量过载情况。
传统的轨迹研究中,人们往往关注轨迹点在空间维度上的分布,没有对轨迹的时态数据进行处理,但空间和时间属性是轨迹点的基本特征,是反映轨迹状态和演变过程的重要组成部分。时空轨迹相似度计算方法有很多,在不同环境下,有各自适合的算法。本文涉及的轨迹数据是采样不均匀的,意味着两条轨迹之间的轨迹点不在时间上一一对应。针对这种情况,本文在多子空间对应相似的聚类算法中的LCSS算法的基础上,提出了LCSS+算法,改进了LCSS算法对于轨迹点比较时出现对时间阈值选取的敏感问题,由于单机在处理大数据集的局限,本文设计了分布式的LCSS+算法,进一步提升了聚类的速度,提升了系统的性能。
2 时空轨迹聚类方法介绍
两个对象之间的相似度是这两个对象相似程度的数值度量,相异度则是两个对象差异程度的数值度量,距离通常视作相异度的方面[5]两个对象相似度越高,相似度越高,相异度就越低,距离越小。依照相似度量所涉及的不同时间区间,可以将现有的时空轨迹聚类算法分为六类。主要有:1)时间全区间相似,代表的聚类方法有欧式距离[6]。2)全区间变换对应相似,代表算法有DTW[7]。3)多子区间对应相似,代表算法主要有最长公共子序列、编辑距离[8]。4)单子区间对应相似,代表算法主要有子聚类算法、时间聚焦聚类、移动微聚类、移动聚类。5)单点对应相似,代表算法主要有历史最近距离、Fréchet距离。6)无时间区间对应相似,代表算法主要单向距离、特征提取方法。现主要介绍三种常用的算法。
2.1 基于欧式距离的相似度算法
在1993年,AGRAWAL R等就提出了基于欧式距离的轨迹间相似度的标识方法[9]。该方法要求计算的两条轨迹的采样点是一一对应的。即采用间隔相同、采样点数(即轨迹长度)一致。轨迹间的距离由轨迹上对应各点间的距离通过求和或取最大/最小值得到。设P=

则轨迹之间的距离可以表示为

之后的研究对于该算法的效率方面记性了改进,利用数字信号处理的相关知识,提出利用离散傅里叶变换[10]、离散小波变换[11]、APCA[12]等方法提高运算效率。但这些方法与其基础方法一样。都对估计的采样率与采样点有严格的要求,在这种距离度量的算法之下,造成估计间的差异因素只能是噪声,因此该方法也存在这对噪声敏感等缺点。
2.2 基于Fréchet距离的相似度算法
在连续Fréchet距离的基础上,Eiter和 Mannila提出了离散Fréchet距离的定义。

上式这个组合成为链A和B的Fréchet排列。
离散Fréchet距离不足以判别曲线的相似度,因为它表示的是曲线之间关键特征点的距离,故引入定义2。

2.3 基于编辑距离的相似度算法
编辑距离是一种源于文本处理的概念,它指的是将一个文本序列通过增、删、改三种操作变成另外一个序列所需的最小操作数[13]。CHEN L等在编辑距离的基础上进行了改进,提出了ERP[14]、EDR[15]。还有另外一种运用动态规划的编辑距离,最长公共子序列距离(LCSS)。其目标是找出无需任何操作即相似的最长轨迹片段。给定两个序列X和Y,如果Z既是X的一个子序列又是Y的一个子序列。例如,如果X=(A,B,C,B,D,A,B),Y=(B,D,C,A,B,A),则序列(B,C,A)即为X和Y的一个公共子序列。但是序列(B,C,A)不是X和Y的最长的公共子序列,因为它的长度等于3,而同为X和Y的公共子序列(B,C,B,A)其长度为4,所以序列(B,C,B,A)是X和Y的一个LCSS,序列(B,D,A,B)也是,因为没有长度为5或者更大的公共子序列。求解最长公共子序列也是一个动态规划的问题,假设有两条长度分别为n和m的时间序列数据A和B,那么最长公共子序列的长度为[16]

其中,γ是成员相似度量标准,i,j分别代表序列A和序列B的点下标。基于公共子序列的相似度公式可以定义为

3 时空轨迹相似度计算
3.1 时空轨迹定义
由于时空轨迹的特殊性,以及后续算法的描述,现定义时空轨迹运算的所需要的基本定义。
定义3:时空轨迹中的轨迹点由可三元属性构成,分别是时间,经度,纬度,时空轨迹中的第i个时空轨迹点记为:Pi=(ti,logi,lati),ti代表轨迹中第i个轨迹点所处时间,logi代表第i个轨迹点的经度,lati代表第i个轨迹点的纬度。

定义7:时空轨迹Ta的时间序列tsa和时空轨迹Tb的时间序列tsb之间的交集定义为tsa∩tsb={P(ti)|MaxTa≥t≥MinTa∩MaxTb≥t≥MinTb}。
定义8:时空轨迹Ta和时空轨迹Tb之间的交集定义为Ta∩ Tb={Pi|PiϵTa||Pi∈ Tb,Pi(t)∈(tsa∩ tsb)}
定义9:若时空轨迹Ta的最小时间MinTa和最大时间MaxTa与时空轨迹Tb的最小时间MinTb和最大时间 MaxTb满足MinTb≤MinTa≤MaxTa≤MaxTb,则有 Ta∈tTb。
3.2 时空轨迹求交
在比较时空轨迹时,由于人员轨迹活动时间是不一致的,对于人员a的轨迹Ta和人员b的轨迹Tb,它们两个在时空中,会表现出三种情形:
情形一:轨迹Ta和轨迹Tb在时间上不相交;
情形二:轨迹Ta和轨迹Tb在时间上部分相交;
情形三:轨迹Ta在时间上包含轨迹Tb或者轨迹Tb在时间上包含轨迹Tb。
对于情形一,由于两条时空轨迹在时间上错过,相似度为0。

3.3 时空轨迹相似度量标准
对时空轨迹进行求交运算后,就需要来计算两条时空轨迹之间的相似度了,由于GPS定位会由于大气层、人为干扰因素的影响,GPS定位会出现定位误差,所以在比较两条轨迹上的轨迹点时需要设置一个容错阈值,轨迹Ta上轨迹点Pai和轨迹Tb上的轨迹点Pbj,经纬度转换为距离的公式为

则认为这两个轨迹点在空间上是一对空间相似点。由于要在时空轨迹点还有时间属性,那么两个轨迹点的相似度计算规则,可以定义如下:如果两个轨迹点在空间上都不相似,那么两个轨迹点就不是相似的。如果两个轨迹点在空间上相似,两个轨迹点时间上越接近,那么这两个轨迹点越相似,否则就越不相似。则两个轨迹点Pai、Pbj的相似值可以设为迹点Pai和轨迹点Pbj在时间上差距小于t时,轨迹点之间的相似性为1,而当轨迹点在时间上差距大于t时,轨迹点相似度会向0靠近,符合现实情况。
3.4 改进的LCSS算法LCSS+
对于时空轨迹来说,计算其最长公共子序列并转换为LCSS距离可以衡量轨迹之间的相似度。LCSS的计算一般通过计算状态转移矩阵获取。设LCSS(Tai,Tbj)为轨迹Tai和轨迹Tbj的之间的LCSS长度。Tai表示轨迹Ta上从位置编号0到i的轨迹点集合,同理Tbj,当 i=0 或者 j=0 时,LCSS(Tai,计算相似度时,对于轨迹点之间差距大于σ,认为其不是一个相似点,那么对于时间差值的阈值的选取非常敏感的。σ取值过大,会导致原本不相似的轨迹点变成相似点。为了方便计算,本文将每一天的时间进行划分,10min为一个时间段。例如如果时间是9点整,那么所处时间段为9*60/10=54。即9点整是处于第54个时间段。当时空轨迹中一个时间段内的轨迹点有多个的时候,则计算多个轨迹点的平均位置,即个轨迹点的平均出现时间为为时间段内的轨迹点的数目。经过时间分段后,每个时间段内只有一个平均后的轨迹点,轨迹点的属性包括时间、经、度、纬度,成了轨迹点序列。针对LCSS对轨迹点比较的时候,出现对时间差值的阈值选取的敏感性,本文提出了一种新的类似于LCSS的动态规划算法,暂命名为LCSS+。上文提到,两个时空轨迹点在空间上类似的时候,轨迹点之间的相似性为。在比较两条轨迹的时候,目标是使轨迹点相似性之和最大,LC⁃SS+算法主要的思想是以轨迹点相似性和最大为目标来进行计算的,可以发现LCSS+也是一个动态规划的问题,求解动态规划问题的关键在于求解状态转移方程。
定义dp[i][j]为轨迹Ta从1到i-1编号组成子序列,轨迹Tb从1到j-1编号组成子序列,它们所包含的最大的相似性和。当轨迹Ta的轨迹点Pai和轨迹Tb的轨迹点Pbi满足dis (Pai(lat),


图1 LCSS+算法状态转移矩阵求解过程
箭头表示两个空间轨迹在空间位置上类似的情况下,其累计相似性和的转移情况,例如在B(9:32)和B(9:50)在空间位置上都是属于B点,在时间上想差19min,那么它的累计最优相似性和就是:之间的最大值,可以算出最大值为1.22,又在B(9:40)和B(10:02)在空间置上属于B点,时间上想差为22分钟,那么从dp[]2[3]转移过来的累计最大相似性和为:1/(1+2.2*2.2)+1.22=1.39。而从dp[3][3]转移过来的累计最大相似性和为1.45。显然更大,故dp[3][4]的取值应为1.45。因为从时间上来看,虽然如果两个轨迹在行进过程中在B点可以取两个公共B,但是位于两个公共B的轨迹点时间差比较大,还不如一个公共B,即B((9:40)和B(9:51)点所带来的相似性累计。
对应的LCSS算法在求解过程中的状态转移矩阵如图2。
如上图所示LCSS算法在求解状态矩阵的时候,只有两个公共相似点,第一对相似点为A(9:25)和 A(9:30),第二对相似点为 D(10:13)和 D(10:15)。最终求解出来的最大相似性和为2,相比于LCSS+算法其因选取时间间隔敏感的问题就凸显出来,当选取10min作为间隔点的时候,LCSS算法会损失一些可能相似的公共点,比如B(9:40)和B(9:51),就因为相差11min就舍去公共点,而造成了一定的误差。
3.5 分布式LCSS+算法设计
由于人员轨迹数据量很大,某地区一天产生的人员轨迹就有970万条,若放在单机上运行,速度会比较慢,而且当一次比较的轨迹数量过多,会引起内存溢出的异常。这对指定人员的轨迹寻找与其潜在的相似轨迹,需要进行大量的计算。故本文使用了MapReduce编程模型,实现了LCSS+算法。MapReduce是在Hadoop架构里面的并行处理框架,提供了高层次的API,易于编程,对大量数据处理有很好的优势。下面描述一下主要的MR算法处理流程。1)人员轨迹的轨迹点实质上是一个4维向量(身份ID,经度,纬度,时间),将指定的人员轨迹Ta序列化存储在集群中。2)需要将一天的轨迹点规约到每一个人身上,形成完整的轨迹。3)之后要做的就是轨迹时间求交,到一个共同的时间范围内进行LCSS+算法计算出每条轨迹与Ta之间的轨迹相似性。4)选取轨迹比较中轨迹相似度比较大的n条轨迹作为输出。经过设计,这个过程需要两个有依赖关系的MapReduce即可完成。下面给出计算的伪代码。

Reduce阶段的伪代码与Map阶段类似,故不再复述。经过上述两个依赖的MapReduce任务就可以输出最大的k个轨迹相似度值的人员。
4 系统效果评估
4.1 实验环境
实验采用的集群环境由5台内存为DDR4 16GB*4的I620-G20服务器组成,机器均运行red⁃hat操作系统,装有2.60版本的Hadoop集群环境。
首先在单机环境下,比较LCSS算法和本文的LCSS+算法在比较人员相似性的准确率。南京某地区,实验人员A以及和A一起同行的人员有50人,向轨迹数据集中加入其他不相关人员9000条数据,设置比较轨迹点时空间距离的阈值为1km,选取不同的时间阈值后,LCSS算法和LCSS+算法对相同数据集的表现结果如图3。
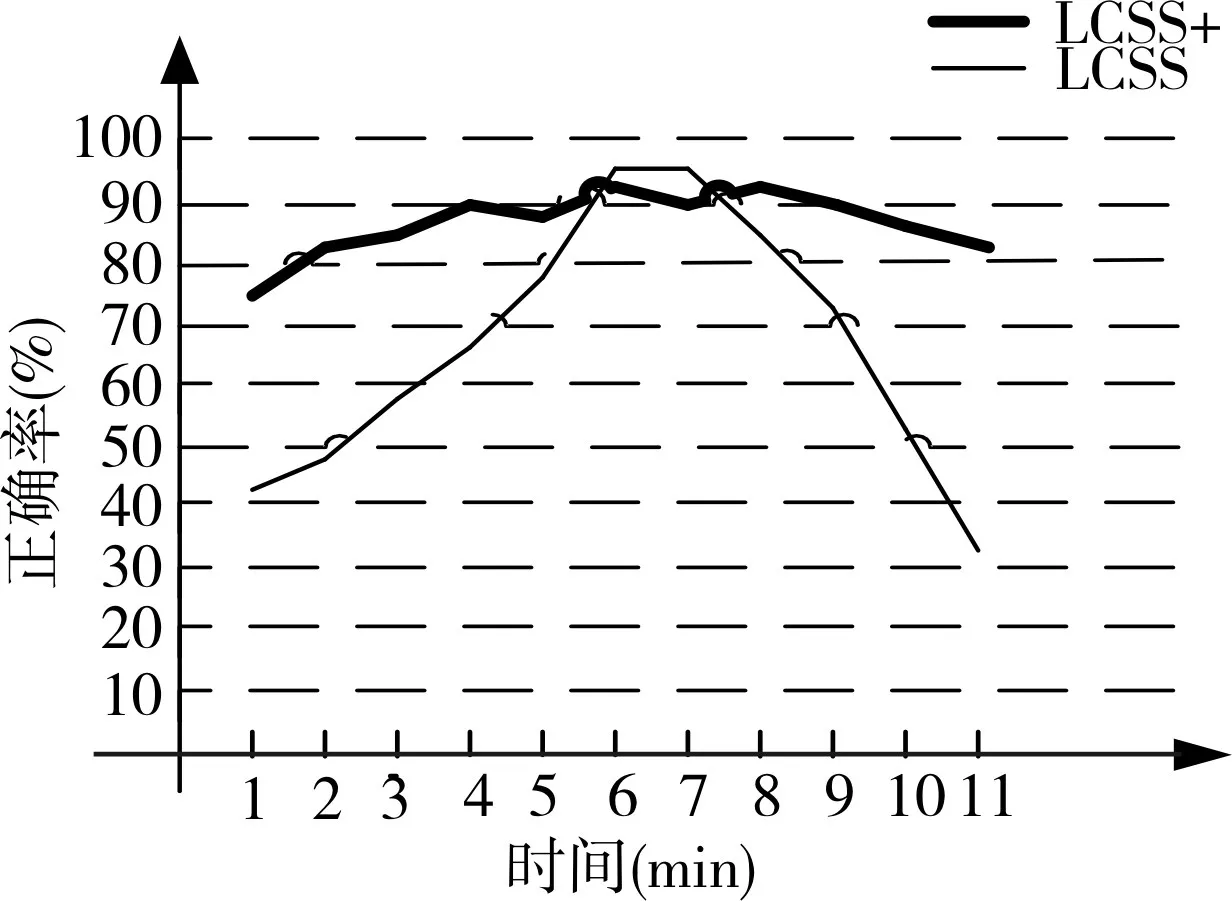
图3 LCSS与LCSS+算法对比
正确率的评价标准是,选取的相似度最高的50条数据,看有多少人是原本在实验人员A同行人员。可以看出LCSS算法是一个抛物线形的曲线,在5.5min~7.5min内正确率略高于LCSS+算法,但是在 1min~5.5min和7.5min~11min内正确率却低于LCSS+算法,说明了LCSS算法对于时间阈值的选取非常敏感,而LCSS+算法对于时间阈值的选取表现平稳,在平均情况下优于LCSS算法。
4.2 分布式LCSS+和LCSS+算法对比
在单机环境下和Hadoop集群上分别运行LC⁃SS+算法,逐步增大数据量,查看运行时间对比。实验结果如图4。

图4 分布式LCSS+与LCSS运行加速比
加速比为Hadoop集群上运行时间除以单机环境下的运行时间的结果。从图4可以看出,当逐步增大数据量时,加速比越来越大,逐渐趋向于5,说明分布式LCSS+算法的运行效率大数据集的情况下要远优于单机下的LCSS+算法。
5 结语
本文对时空轨迹数据进行离散化处理,分析传统了时空轨迹处理算法LCSS,发现它对于时间阈值取值范围的敏感性,提出了一种平均情况下表现平稳的算法LCSS+,能够对特定人员的伴随轨迹进行有效的挖掘,有较高的执行效率。在LCSS+的基础上,考虑到数据量大的问题,提出了分布式环境下的LCSS+算法,并通过实验验证了分布式LCSS+算法能够提升算法在大数据的情况下的运行效率,为后续进一步研究时空轨迹数据挖掘提供了很好的参考依据,未来可以尝试更多的相似度度量方法,并比较其在各种环境下的表现情况。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
智能计算机与应用(2020年4期)2020-08-31
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
数理化学习·高一二版(2009年2期)2009-03-30
