
一种基于并行交叉遗传算法的二维不规则排样问题求解
2020-07-13 12:56:20王静静瞿少成李科林
计算机应用与软件 2020年7期
王静静 瞿少成 李科林
(华中师范大学物理科学与技术学院电子信息工程系 湖北 武汉 430079)
0 引 言
二维不规则排样问题是指在给定的原材料板材空间上,合理放置若干不规则零件,使得零件之间互不重叠且板材利用率最大。该问题在服装裁剪[1]、印刷包装[2]、钣金零件加工[3]、玻璃切割[4]等行业应用广泛,是实际工业生产加工中的关键环节。同时,该问题可以归为一类复杂的NP完全问题[5],因此,长期以来受到国内外众多学者的关注。
二维不规则排样问题涉及运筹学、几何数学等众多学科,属于典型的组合优化问题。近年来,二维不规则排样问题常采用启发式算法或智能优化算法求解。文献[6]提出了一种多目标启发式进化算法求解考虑批量问题的二维矩形件排样问题,文献[7]提出了一种基于重心临界多边形的启发式排样算法。可以看出,启发式算法实现简单,能够快速给出求解方案,但难以取得全局最优解。因此,目前常采用模拟退火算法、遗传算法等智能优化算法解决排样优化问题。
遗传算法通过模拟自然进化过程搜索最优解,全局搜索能力优秀,适合大规模空间求解复杂问题[8],将其应用到排样问题的求解上可以取得较好的排样效果。文献[9]结合遗传算法和最低水平线算法求解矩形件排样问题,但其寻优能力有待进一步改进。文献[10]利用基于排挤机制的小生境遗传算法求解排样顺序优化问题,但是算法效率有待提高。
针对以上问题,本文提出了一种基于并行交叉遗传算法的排样优化算法。结合排样问题的特点,模拟了两个独立岛上的生物杂交进化过程,构造了一个包含零件排放顺序和旋转角度的初始编码序列,分别按照随机和零件面积降序的方式生成排样初始种群。主过程的交叉操作采用与从过程进化产生的最优个体杂交的方式,提高算法的收敛速度和寻优能力,从而优化二维不规则排样问题的求解。
1 问题描述和数学模型
二维不规则多边形排样问题的具体描述为:在生产过程中,根据相应的工艺需求,将若干不规则零件互不重叠地放置在给定的宽度固定、长度不限的矩形板材内部,各个零件可以被旋转一定的角度,使得排样后原材料的利用率最高。
约束条件:
Ri∩Rj=∅(i≠j)
(1)
Ri∈R
(2)
Oi∈O
(3)
目标函数:
minL=max{x|(x,y)∈Ri1≤i≤n}-
min{x|(x,y)∈Ri1≤i≤n}
(4)
(5)
式(1)保证各个零件之间不能重叠;式(2)保证排放后所有不规则零件都位于板材内部;式(3)中O为零件对应旋转的角度。
图1为一组二维不规则零件排样结果。假设原材料矩形R的宽度为W,需排放n个二维不规则零件{R1,R2,…,Rn},Si表示第i个零件的面积,L为排样的最短长度,ρ表示原材料利用率。
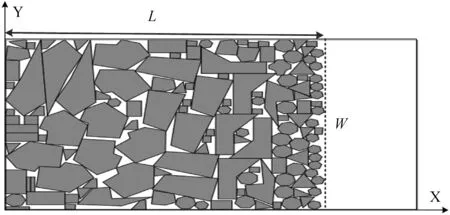
图1 二维不规则零件排样结果
2 算法设计
传统遗传算法常采用随机的方式生成初始种群,但这种方法产生的个体不一定是优秀的,且在排样问题的高维解空间进行随机搜索的效率较低,导致收敛速度变慢。此外,进化过程中的交叉操作几乎都是在大规模离散空间中随机进行的,这种搜索方式在进化初期能保证解的多样性,但在进化后期,种群中就会出现大量相似个体,容易收敛于局部极值,出现早熟现象。因此,本文基于并行交叉遗传算法求解二维不规则排样问题。
2.1 个体编码方式及构造初始种群
2.1.1个体编码方式
本文基于对象的数据结构索引对个体进行编码,对于包含n个待排放零件的排样问题,可行解是由n个对象组成的序列,序列中每个零件对象都包含排放顺序和旋转角度两个变量。
将待排放的n个零件按照排放顺序编号,构成了一个整数序列{X1,X2,…,Xn},Xi为第i个排放入板材的多边形零件编号,Oi为第i个零件排放时相应的旋转角度,1≤Xi≤n。每个可行解序列可以表示为:{(X1,O1),(X2,O2),…,(Xn,On)},其中(Xi,Oi)表示编号为Xi的零件旋转Oi度后排放。3个不规则零件排样后的一个可行解为X={(1,0),(3,90),(2,180)},其中零件的排放顺序为1、3、2。编号为1的零件旋转0°排放,编号为3的零件旋转90°后排放,编号为2的零件旋转180°排放。
2.1.2构造初始种群
在遗传算法中,初始种群的质量对算法的收敛速度和寻优能力影响较大。随机生成初始种群的方式可以保证个体的多样性,在排样问题中,这种方法产生的初始解中零件的排放顺序和旋转角度都是随机的。当零件数量较多时,解空间的规模会比较大,搜索范围很广,很难在一定时间内搜索到最优解,求解效率大大降低。
为了获得高质量的初始种群,通过构造两个独立岛上的进化过程A和B,本文提出了一种并行交叉遗传算法。主过程A的初始种群通过随机生成的方式构造,从过程B的初始种群则通过借鉴手工排样的经验,按照零件的面积从大到小排序生成,可以取得更好的排样效果。
2.2 个体定位策略及适应度计算
2.2.1个体定位策略
计算个体适应度之前,需要在板材上为待排放的多边形零件选择一个合适的排放位置。这一过程常常涉及到很多复杂的几何计算,如计算多边形之间的最佳靠接位置、重叠判断等。
在早期研究中,文献[11]采用BL准则定位零件位置,该算法实现简单,被广泛应用于排样问题的求解,但其容易造成空腔的浪费,且定位位置不一定是最优解。针对BL定位策略存在的问题,本文使用临界多边形(NFP)[12]判定零件之间的位置关系,同时结合BL定位原则,尽量选择NFP最左、最下方的顶点排放零件,可以解决BL算法定位位置不合理的问题。基于NFP和BL准则的定位策略步骤描述如下:
Step1初始化排样种群,获得零件排样序列。
Step2对于排样序列中的零件A(Xi,Oi),将其按照角度Oi旋转后,构造零件与原材料板材B的NFPAB。
Step3在NFPAB选择最左、最下的顶点作为零件A的排放位置。
Step4若零件序列中还存在待排放的零件,减去原材料B中的已排放的零件A,作为剩下的板材区域B放置待排放零件,转到Step 2;否则,结束零件排放过程。
2.2.2适应度计算
在求解二维不规则排样问题时,追求的目标就是使得原材料板材的利用率最大化。为了使适应度函数能够更好地反映排样方案的优劣,且尽可能使计算简单,本文定义适应度函数如下:
F(Xi)=Sum/(W×Lmax(Xi))
(6)
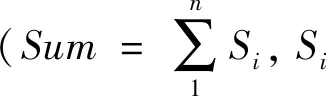
图2 最小的原材料板材长度
适应度函数值F(Xi)表示可行解Xi对应的板材利用率,F(Xi)越大,其对应可行解序列的质量越好。
2.3 并行交叉遗传算法的进化过程
2.3.1选择操作
种群经过交叉和变异之后,一部分个体将被挑选出来产生下一代群体,这个过程即为选择操作。选择过程中,通常基于个体的适应度进行优胜劣汰操作,适应度高的个体更容易进入下一代,适应度低的个体则被淘汰,这样有利于优良基因的扩展。
目前常用的选择方法有轮盘赌法、随机遍历选择法及锦标赛选择法等。本文基于保留最佳个体策略,采用轮盘赌法对执行交叉操作的两个父代个体进行选择,步骤如下:
Step1保留父代中适应度函数值最大的个体至下一代,并在父代中将其移除。
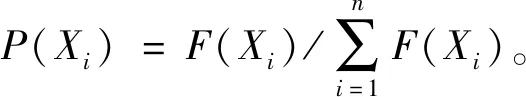
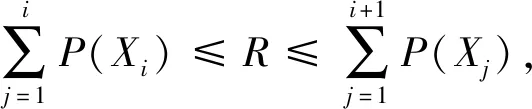
Step4重复Step 3,直至新的种群构建完成。
2.3.2交叉操作
常用的交叉操作有循环交叉法、部分匹配法、次序交叉法等方法。本文提出的并行交叉遗传算法采用顺序循环交叉法,即随机生成两个处于[1,n]之间的不同正整数作为交叉点位置Bit1和Bit2,保持两个父代染色体Bit1和Bit2之间的基因不变,其余基因按照另一条染色体上的基因位置顺序选取基因进行填充,且跳过已经出现的基因。这种交叉方法每次可产生两个子代染色体,其交叉过程如图3所示。
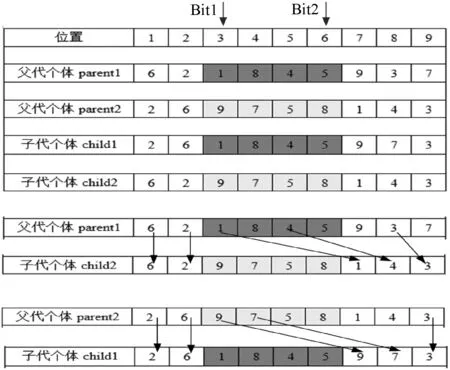
图3 交叉操作
2.3.3变异操作
根据二维不规则排样问题的具体情况和特点,我们选择交换变异法进行变异操作。在执行变异操作时,需要通过变异概率pm与在[0,1]内生成的随机数p的大小进行对比,来确定是否需要进行变异操作。当pm>p时执行变异操作;否则,不执行变异操作。
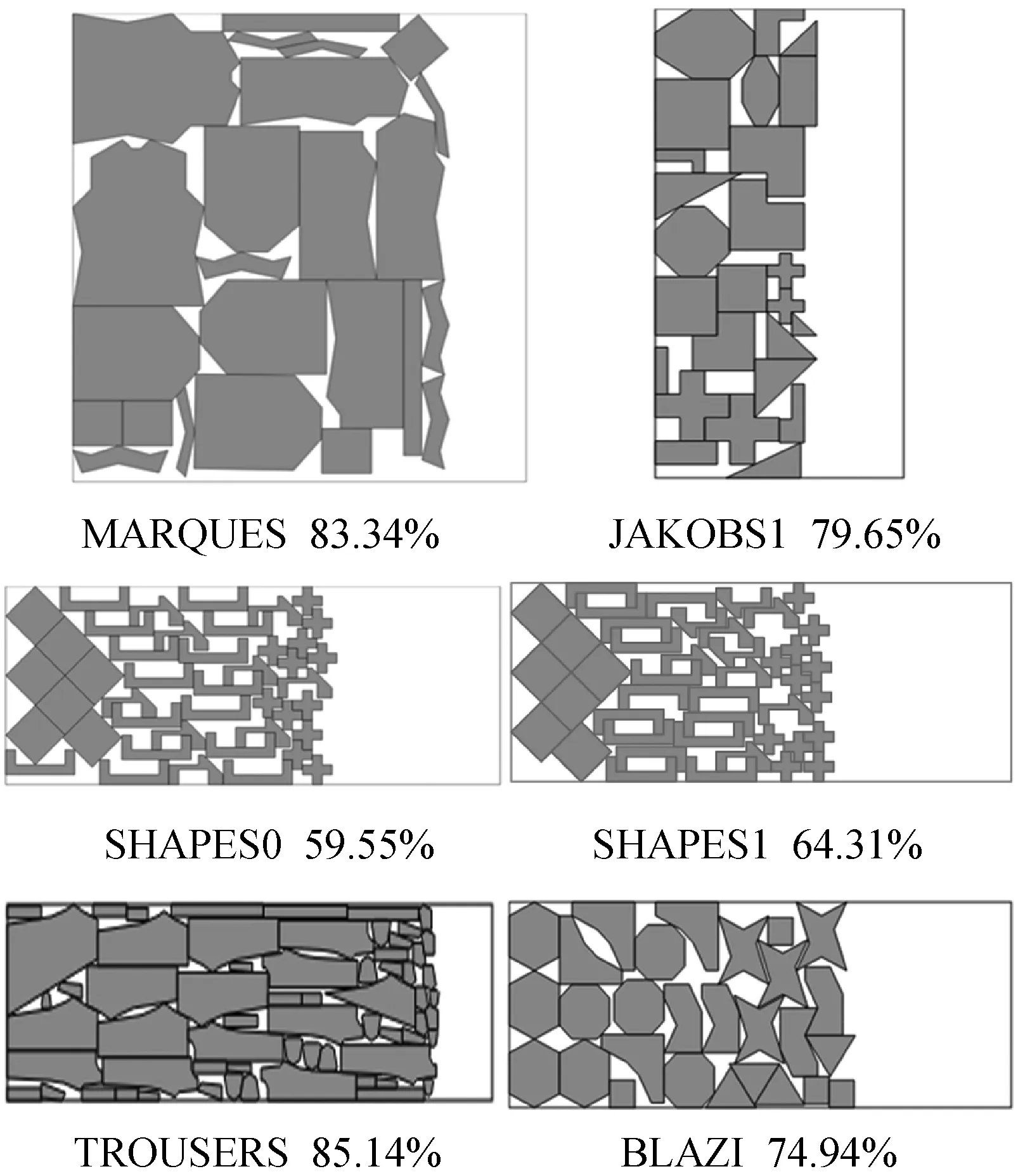
交换变异需要在[1,n]之间随机生成两个不同的正整数作为变异的位置Bit1和Bit2,其中0≤Bit1 图4 交换变异 本文基于并行交叉遗传算法求解二维不规则排样优化问题,其主要思想是模拟两个独立岛上的生物杂交进化过程。 首先,建立两个进化过程A和B。主过程A的初始种群是随机生成的,从过程B的初始种群按照零件面积从大到小排序生成。此外,A的每次进化都通过与B每次进化产生的最优个体进行杂交产生新的子代。在进化过程中,主过程A初始种群的随机性保证了种群的多样性,搜索解空间时包含了更多可能性;从过程B的初始种群借鉴了人工排样的先验知识,本身就是局部较优解,通过杂交可以为主过程的进化指导方向。这种模拟两个独立岛屿进化杂交的并行交叉遗传算法加快了全局收敛速度,在短时间内就可以搜索到更优解。 结合基于临界多边形的BL定位策略和并行交叉遗传算法的分析,本文提出的基于并行交叉遗传算法的二维不规则排样优化算法,步骤如下: Step1随机生成主过程A的初始排样种群,按面积降序生成从过程B的初始种群(种群大小均为N),分别产生N个个体。 Step2分别对种群A、B中的个体采用基于临界多边形的BL定位策略排放零件,计算所有个体的适应度函数,并按照适应度函数值的大小降序排列,保存种群B中的最优个体。 Step3对两个种群中的个体执行选择、交叉、变异操作后,分别产生N个新的个体。其中,将Step2中保存下来的种群B中的最优个体作为种群A执行交叉操作时的一个父代。 Step4对Step 3中产生的新个体继续执行Step 2。同时,种群A和种群B分别保存最好的N个个体。 Step5判断算法是否满足终止条件。若不满足,两种群分别将Step 4中各自保存的个体作为新种群,继续执行Step 3;否则,输出当前种群A的最好个体,算法结束。 并行交叉遗传算法的流程图如图5所示。 图5 并行交叉遗传算法 为了验证算法的可行性和有效性,采用Java语言实现了本文的排样优化算法,并基于ESICUP提供的几个基准用例测试了算法性能。 实验统一采用原材料板材的利用率ρ作为主要比较参数,其计算公式如下: (7) 表1为并行交叉遗传算法的相关配置参数。实验时对于每个测试用例都进行了10次实验,并从板材的最优利用率和平均利用率两方面将本文算法的实验结果与TOPOS[13]算法和传统遗传算法的结果进行了比较。采用传统遗传算法求解排样问题的实验数据来源于文献[14]。详细的实验结果对比见表2和表3。 表3 算法比较 观察表2和表3可以发现,在求解二维不规则排样问题时,本文采用的并行交叉遗传算法结果均优于传统遗传算法。与TOPOS算法相比,本文算法的排样效果明显更优,尤其是SHIRTS用例,原材料利用率明显提高。 上述测试用例的排样效果图见图6。由于SHAPES0、SHAPESl用例包含较多凹度较大的凹多边形的零件,排放时容易形成空洞和凹槽区域,且基于单一BL定位规则排放时,这种区域难以得到很好的利用。因此,本文算法对这两个用例的排样效果变差。对于MARQUES和TROUSERS这种以凸多边形为主的用例,本文排样策略与遗传算法相结合后,可以获得较高的原材料利用率。 图6 基于并行交叉遗传算法的排样结果 此外,排样结果中最优利用率和平均利用率的值比较接近,说明并行交叉遗传算法在有限的进化代数下比较稳定。因此,本文提出的排样优化算法具有很强的实用性,可以有效解决实际加工生产中的二维不规则排样问题。 图7为MARQUES测试样例的最优解进化收敛曲线,可以看出种群经过较少的进化次数就趋于收敛,说明并行交叉遗传算法具有较快的全局收敛速度。 图7 MARQUES最优解进化收敛曲线图 另外,随着进化代数的递增,曲线逐渐趋于稳定值,表明本文算法稳定可行。其中,曲线的平稳部分表示算法暂时处于局部最优状态,出现阶梯跳变则表示在解空间内搜索到了更优解。 针对工业生产加工中广泛存在的二维不规则排样问题,本文提出了一种基于并行交叉遗传算法的排样优化算法。根据排样问题的特点,基于零件的排放顺序及排样旋转角度对个体进行了编码,并通过随机和按零件面积降序的方式生成了两个进化过程的初始种群,提高了算法的搜索效率。通过模拟两个独立岛上的生物杂交进化过程,改进了遗传算法中主进化过程的交叉策略,提高了全局寻优能力。对ESICUP提供的基准用例测试结果表明,该算法可以有效处理二维不规则排样问题,是一个可行且排样性能较好的排样优化方法。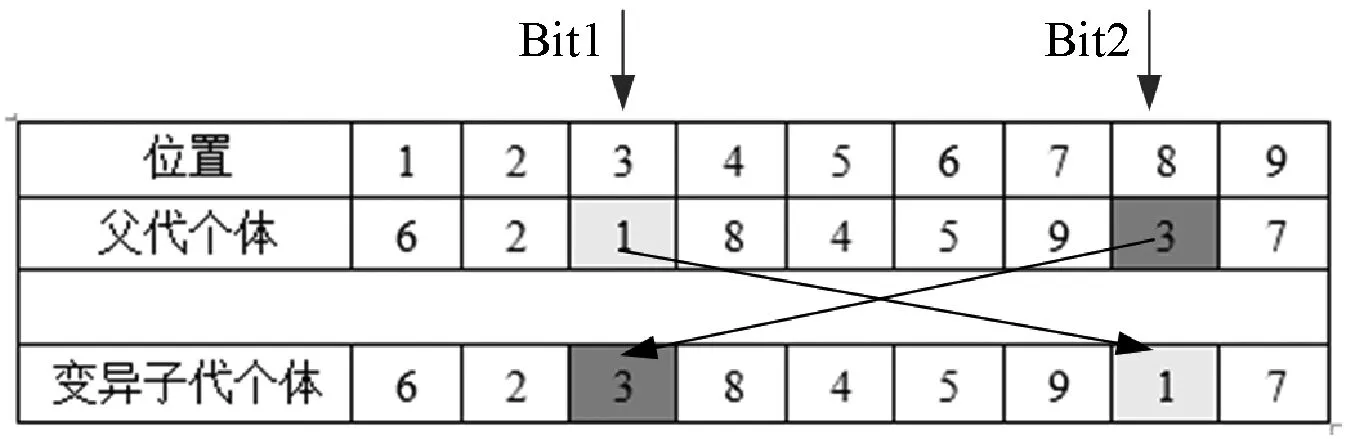
2.4 基于并行交叉遗传算法的排样优化算法
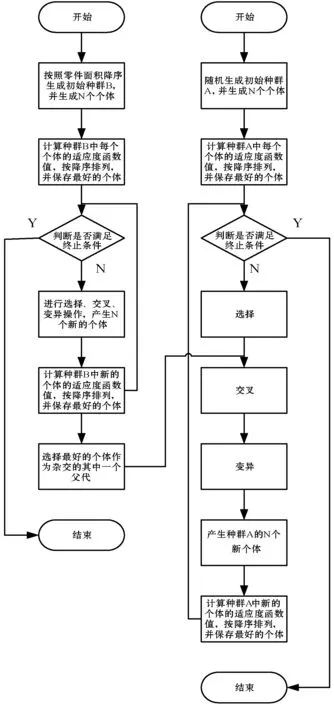
3 实 验


4 结 语
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
初中生世界·八年级(2019年6期)2019-08-13 18:41:18
浙江工业大学学报(2017年5期)2018-01-22 02:03:48
小学生导刊(低年级)(2016年6期)2016-07-02 22:17:33
中国塑料(2016年11期)2016-04-16 05:26:02
重型机械(2016年1期)2016-03-01 03:42:09
计算机工程(2015年8期)2015-07-03 12:19:54
锻压装备与制造技术(2015年2期)2015-06-26 09:00:22
锻压装备与制造技术(2015年2期)2015-06-26 09:00:21
振动、测试与诊断(2014年6期)2014-03-01 01:14:47
