
基于MSER和CNN的彝文古籍文献的字符检测方法
2020-07-08 08:09陈善雄韩旭林小渝刘云王明贵
华南理工大学学报(自然科学版) 2020年6期
陈善雄 韩旭 林小渝 刘云 王明贵
(1.西南大学计算机与信息科学学院,重庆400715;2.贵州工程应用技术学院彝学研究院,贵州毕节551700)
彝族是中国第六大少数民族,在长期的发展中逐渐形成了本民族的文化传统。彝文是彝族人民相互交流思想感情的一种语言文字符号,而彝文古籍是用古彝文书写的关于彝族历史、宗教、医学、哲学、农耕、天文等各个方面的文献资料。彝文文献载体主要有岩书、布书、皮书、纸书、瓦书、木犊、竹简、骨刻、木刻、金石铭刻、印章等,但由于历史久远都存在不同程度的损毁,整理和保护这些古籍文献是传承和发扬彝族文化的重要手段。但目前大量的彝文古籍研究还只停留在扫描、拷贝以及人工翻译的阶段。随着这些古籍的不断消失,给古彝文的数字化保护提出了迫切需求。彝文识别的研究能够使一部分彝文古籍重新焕发生机,为彝文的研究者和感兴趣的学者提供快速阅读彝文文献的途径,并促进对彝文的保护和传承,因此对彝文识别的研究十分必要。而对彝文古籍进行识别的前提是对复杂版面结构的彝文古籍中的字符进行精准的检测,只有准确定位这些古老字符在载体中的位置,才能进一步完成识别。
目前,对于复杂场景下的中英文字符检测已经有了较多的研究,大多数采用基于深度学习的方法对古籍或场景文字进行检测和识别。然而,这些方法对具有复杂噪声的彝文古籍图片并不完全适用。首先,基于深度学习的方法需要依赖大量的标注数据进行训练,在中国只有极少数的人认识古彝文,针对古彝文字符的标注工作十分困难。其次,与手写体汉字的检测相比,从复杂噪声背景下的彝文古籍中对古彝文文本进行检测将面临图像模糊、污染严重、书写格式凌乱等诸多问题,同时还存在很多字符粘连的情况。因此,需要采用一个更加有效的方法对彝文古籍字符进行检测。
近几年,也有很多关于少数民族语言文字检测和识别的研究,但大多仅停留在研究规范的印刷体字符的分割与识别层面,这主要是由于手写体相较印刷体而言,书写风格较为随意,而且采样和标注工作耗时费力,再加上一些古籍图片由于破损和严重的噪声,给采样工作带来了很大的困难。在之前的研究中,提出了一些针对少数民族文字的检测方法。Jia等[1]通过直接对彝文字库中的字符进行切分来完成初期的采样工作,这种方法较为简单且快速,但是得到的都是较为规范的印刷体字符,后期识别的难度相比手写体字符来说也较为容易。Su等[2]对蒙文古籍首先用OTSU算法进行二值化处理,然后用图像的垂直投影信息对图像进行文本列定位,最后用连通分量分析法得到单个的蒙文字符。但是该研究涉及到的蒙文古籍版面排列较为整齐,图像的污染及噪声也较少。哈力木拉提等[3]用投影法对维文扫描图片进行行列切分和基线检测后,再设定平均值阈值对粘连的维文字符进行二次分割,该方法对书面整洁且书写规范的维文字符进行了较为准确的分割。靳简明等[4]综合水平投影和连通分量的方法实现维文文本的文字行切分和单字切分,并利用规则合并过切割字符,使维文字符切割的准确率达到99%以上。Shi等[5]用基于连通分量的方法对书写在骨片上的甲骨文进行了检测和分割。此外,也有一些针对汉字和拉丁文字的手写体文档中文本检测的研究,Li等[6]通过基于条件随机场的多层感知器和卷积神经网络模型,对手写体汉字文档中的文本区域和非文本区域进行分类,取得了较理想的分类效果。Xu等[7]采用一种多任务的全卷积神经网络对拉丁文手稿文档进行了有效的文本行检测和基线检测。由此可见,以上研究都是把字符分割作为文字数字化的前提,因此,如何在复杂噪声背景下准确地定位和提取古彝文字符是古彝文识别和彝文古籍数字化等工作的基础。本文提出了一种在复杂噪声背景下的彝文古籍中彝文字符的定位和分割方法。该方法首先对图像进行预处理,将前景和背景像素进行分离。在此过程中,关键是对古籍图像噪声的处理。由于古籍的破损和污染,图像中有大量的噪声,因此对多张彝文古籍图片进行处理并对比了多种预处理方法;在经过图像的预处理之后,就得到了噪声较少的二值图像,然后用基于启发式规则的方法去除一些非文本区域;最后,用 MSER(最大极值稳定区域)和 CNN(卷积神经网络)的方法对古彝文单个字符进行检测。
1 算法描述
1.1 图像预处理
彝文古籍大都历史悠久,受到各种环境的影响,存在泛黄、褶皱、污迹等情况,图像滤波可以在保留图像特征细节的情况下对目标图像的噪声进行抑制,为后续的二值化处理奠定基础,同时也是古籍文献重新焕发活力的重要措施,有利于古籍文献的保存、传播。通过对大量彝文古籍图片进行去噪测试并分析,综合去噪能力与效率,最终采用非局部均值滤波对原始图像进行处理,然后采用一种改进的局部自适应阈值二值化的方法对上一步处理的图像进行二值化。
1.1.1 非局部均值滤波
非局部均值滤波[8]考虑到了图像的自相似性,它将相似像素定义为具有相同邻域模式的像素,利用像素周围固定大小的窗口内的信息表示该像素的特征,比利用单个像素本身的信息得到的相似性信息更加可靠。
给定一张噪声图像u(u={u(i )i为图像内任意像素点}),对于像素i,经过非局部均值滤波以后的像素值为L(i),它的值是由图像中每个像素值加权平均而求得:
权重集合 {w(i,j)}j中的每一个权重的值取决于像素i和像素j的相似性,并满足条件0≤w(i,j)≤1且w(i,j)=1。
像素i和像素j的相似性由灰度向量v(Ni)和v(Nj)的相似性来衡量,这里的Nk指的是以像素k为中心的固定大小的方形邻域,此相似性通过高斯加权的欧几里德距离来计算,即‖v(Ni)-v(Nj)‖。其中下标 “2”表示向量的第2范式,即欧几里德距离;a>0,是高斯核的标准差。在图像中添加高斯白噪声可以对邻域之间的纹理相似性进行有效的比较,在本算法中,添加高斯白噪声之后含噪邻域间的欧几里德距离满足公式 (2):

式中:u(·)和v(·)分别指原始图像的灰度向量和加噪图像的灰度向量;σ2为白噪声方差;E(·)表示数学期望。在此公式中,欧几里德距离的期望值表示了像素之间的相似程度,因此,在加噪图像中,和像素i相似性最大的像素也是原始图像中和像素i相似性最大的像素。那么,权重系数可定义为

其中,Z(i)是一个标准化系数,

这里的参数h控制着指数函数的衰减。在非局部均值滤波的实际应用中,可以将相似性邻域窗口限定在一个比它更大的搜索窗口中。在所有实验中,将搜索窗口设定为21像素×21像素,将相似性邻域窗口设定为7像素×7像素,因为7像素×7像素的相似性窗口既可以消除一定的噪声,也可以较好地保留图像中的细节。经过实验分析发现,将参数h取为12×σ能够得到较好的去噪效果。图1(a)和图1(b)分别展示了古籍原始扫描图像和经过非局部均值滤波处理以后的图像。

图1 古籍图像处理前后效果Fig.1 Image effect of ancient books before and after processing
为了采用最优的去噪算法,将一些传统的去噪算法如中值滤波、高斯滤波、最小值滤波、最大值滤波同非局部均值滤波的去噪性能进行了对比。本文采用峰值信噪比 (PSNR)作为衡量的标准,PSNR基于平均平方和均方误差 (MSE)计算去噪后的图像和真实图像的重构偏差,对噪声敏感。因为只要图像中的某个像素值发生了变化,不管是朝着哪个方向变化,也不管这种改变是否能够被主观观察到,都会改变PSNR。PSNR的取值范围不固定,最大值与图像分辨率有关,其值越高表示去除的噪声越多。
PSNR的具体计算方式如下:
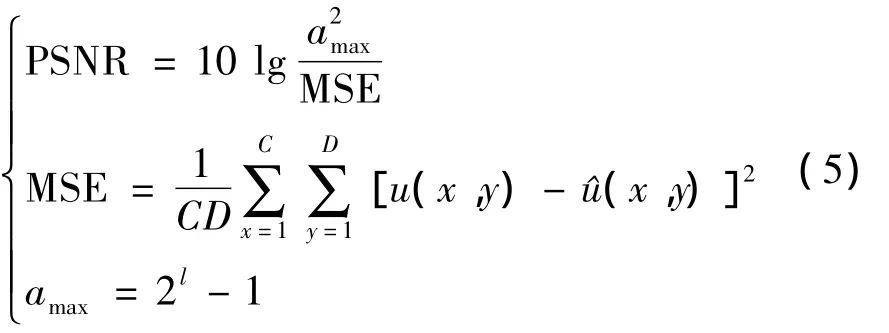
式中:l为色彩深度,表示一个像素点占用的2机制位数,常取l=8;u(x,y)为原始图像在(x,y)处所对应的灰度值;^u(x,y)为重建图像在(x,y)处所对应灰度值;C和D分别为图像的宽度值和高度值。
将中值滤波、高斯滤波、最小值滤波、最大值滤波以及本文所用的非局部均值滤波对多张古籍图像进行去噪处理,最终选取了52张具有代表性的古籍图片,测试了它们通过不同去噪算法处理后的平均PSNR值,以此来判断去噪性能的优劣。通过对比分析发现,经非局部均值滤波处理后的古籍图片和其他传统去噪方法的相比,取得了最高的PSNR值,能够最大限度去除古籍图像中的噪声,为后续的二值化处理提供最有利的条件。
1.1.2 局部自适应阈值二值化
为了进一步消除图像中的污迹,凸显文本区域的轮廓,需要对上一步经非局部均值滤波处理后的图像进行二值化处理。本文提出一种改进的局部自适应二值化算法对图像进行二值化处理。由于古籍保存时间较久,受到光照不均和严重污染等因素的影响,使得传统的全局阈值二值化方法无法较好地对古籍图像进行二值化分割,因此要用局部自适应阈值二值化的方法对灰度图像进行二值化分割。本文在传统的局部自适应阈值Bernsen算法[9]的基础上加入了高斯平滑滤波。引入高斯滤波的原因是真实图像在空间内的像素是缓慢变化的,因此临近点的像素变化不是很明显,但是任意两个点之间可能会有很大的像素差值。换言之,在空间上噪点之间没有很大的关联。正是由于这个原因,高斯滤波可以在保留中心像素信息的条件下减少噪声,为后续的文本分割操作滤除噪声。
设x、y分别为图像的水平坐标和垂直坐标,u(x,y)表示图像在坐标(x,y)处的灰度值,N(x,y)表示以坐标(x,y)为中心,大小为(2f+1)×(2f+1)的方形邻域,其中f是一个大于0的正整数,它可以使得方形邻域的边长为一个奇数。¯u(x,y)表示在(x,y)处经高斯滤波后的像素灰度值,η为平滑尺度,¯x和¯y为邻域窗口内的位置参数,b(x,y)表示在(x,y)处二值化处理以后的灰度值,改进算法的具体描述如下。
输入:图像灰度值 u(x,y)(0≤u(x,y)≤255);
输出:二值化处理以后的灰度值 b(x,y)(b(x,y)=0∨b(x,y)=255)。
步骤1 计算(x,y)处的阈值T1(x,y):

步骤2 计算(x,y)处在(2f+1)×(2f+1)窗口内经高斯滤波后的像素灰度值¯u(x,y):

步骤3 计算滤波后的阈值T2(x,y):

步骤4 设α∈(0,1),计算(x,y)处二值化处理以后的灰度值:

参数α为阈值 T1(x,y)和 T2(x,y)的权重控制系数,当α的值为0时,算法为传统的Bernsen二值化算法,当0<α≤1时,算法为改进以后的算法。f的取值影响着算法的运行速度与伪影的产生规模,f的取值越大,算法的运行时间越长,产生的伪影越少;反之亦然。参数¯x和¯y控制着运算窗口的大小,它是影响Bernsen算法运行时间的重要参数,假定¯x为水平方向的长度,¯y为垂直方向的长度。如果¯x,¯y≠0,那么算法是基于网格式扫描;如果¯x=0∨¯y=0,那么算法是基于线扫描。尽管网格式扫描可以降低二值图像的噪声,但是这样会产生更多的伪影,同时消耗更多的运行时间。由于线扫描仅仅需要从一个方向对图像进行扫描,尽管会产生少量的噪声,但是会消除掉大部分由于不均匀光照而产生的阴影,能够更好地保留图像中的细节以及字符的特征,二值化处理效果较网格式扫描更好。本文提出的改进算法就是在对灰度图像进行线扫描的同时进行高斯平滑滤波。
在传统的Bernsen线扫描二值化算法中,参数¯x和¯y总有一个为0,因此相当于只有一个参数,这个参数正是方形邻域大小的控制参数f。f的值一般取决于图像中目标信息所占像素的大小,经过对古籍图像的实验分析,f的取值在图像中字符的笔画最小宽度和最大宽度之间时二值化处理效果较好。假定图像中的目标区域为图像中的文本区域,将f取不同的值后,会产生不同的二值化效果。如图2所示,当f=1时,图像会产生大量的伪影,当f=25时,会产生大量的噪声,使得丢失掉部分文本区域的信息。在本例中,图像中的目标信息为古籍中的字符,其最小的笔画宽度为6,最大的笔画宽度为13,因此,f的值取10较合适,这样既不会丢失文本区域的关键特征,也不会消耗更多的算法运行时间。因此,在处理其他古籍图像时,可以先通过基于笔画宽度变换的方法 (SWT)[10]提取古籍中文字的平均笔画宽度来设置本算法中f的值。

图2 传统Bernsen算法中f取不同值时的二值化效果对比Fig.2 Comparison of binarization when f takes different values in traditional Bernsen algorithm
参数α的取值决定了图像中噪声平滑和目标信息保留之间的平衡关系,调整α的值既可以使图像能够较好适应光照不均的情况,同时也能去除图像中的噪声。α的取值越大,滤波的效果越明显,但同时会使图像中的目标信息也被过滤;反之亦然。图3展示了在本例图片中当f=10时,α取不同的值对二值化效果的影响。可以看出,当α的值取0.3时,不仅可以较好地保留图像中文本区域的特征,又能去除图像中的噪声。

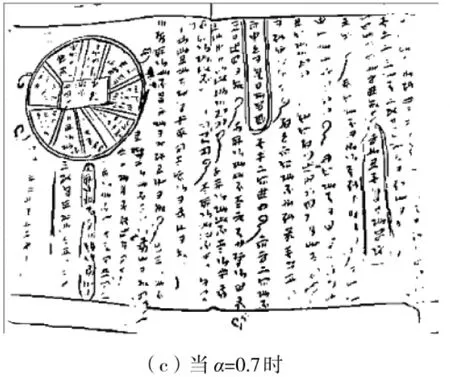
图3 改进Bernsen算法中f=10条件下α取不同值时的二值化效果对比Fig.3 Comparison of binarization when α takes different values in improved Bernsen algorithm for f=10
为了在处理其他古籍图像时能够自适应地调整α的值,本算法通过计算图像中面积较小的连通区域的数量来实现α参数的自适应调整。由图3可以看出,当α的值过大或过小时,图像中都会出现较多黑色的小噪点,而当α的值为最佳值时,黑色小噪点的数量最少。文中把特征满足式 (10)的连通区域认定为噪点并计算其数量。其中S表示连通区域的面积,即在该连通区域内黑色像素点的个数。

图4展示了在本例图片中满足条件的噪点的数量和α取值的变化关系,可以看出,当α取值最佳时,噪点的数量最少,因此可以通过这种方式自适应调整参数α的值。
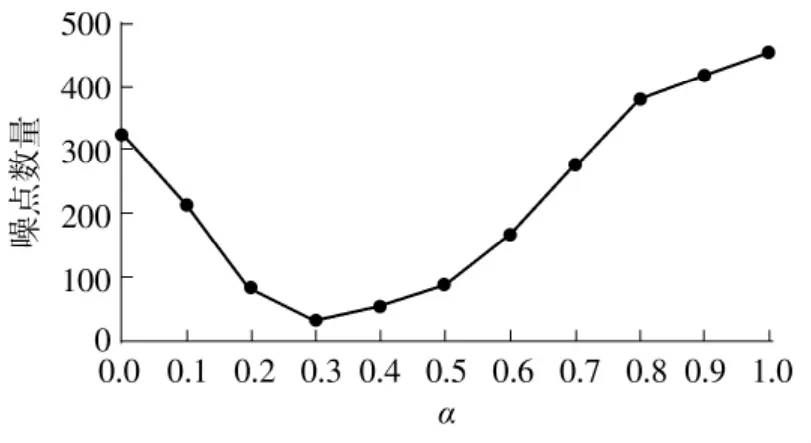
图4 α的取值与噪点数量的变化关系Fig.4 Relationship between the value of α and the number of noise points
经过实验分析可以看出,传统的Bernsen二值化算法对光照不均的古籍图像的二值化效果并不理想,但是文中改进的二值化算法能够较好地适应图像中光照不均的情况。
1.2 基于启发式规则去除非文本区域
由前文分析可知,经过预处理之后,图像中仍然有很多非文本区域 (彝文古籍中的分割线、标点符号、图画装饰等),因此,要想进一步对彝文字符进行定位和分割,还需针对这些非文本区域进行过滤。在文献 [11]中,研究者用基于启发式规则的方法对复杂背景下的图像 (门牌、指示牌、广告标等)中的非文本区域进行去除,取得了较理想的检测准确率和召回率,本文通过一些启发式规则对复杂噪声背景下的彝文古籍扫描图像中的非文本区域进行了有效的提取和消除,具体如下。
为了分析文本区域和非文本区域的连通区域特征,从32张具有代表性的古籍图像中选择了672个单字符文本区域和258个非文本区域,对它们的连通区域特征进行分析。本文主要从连通区域最小外接矩形的高度、宽度和纵横比的特征对非文本区域进行去除,分析结果如图5所示。
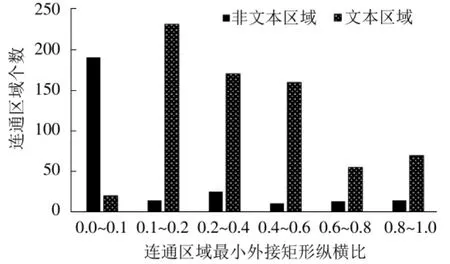
图5 连通区域特征Fig.5 Characteristics of connected components
对于古籍图片当中的分割线或图片来说,它们的长度或宽度往往占了整个图片长度或宽度的很大比重,本文将连通区域长度或宽度大于整张图片长度或宽度五分之一的区域规定为非文本区域,同时,由图5可以看出,大多数非文本区域的连通区域最小外接矩形的纵横比小于0.1,因此将满足以下特征的连通区域也认定为非文本区域:

式中,C、D分别表示连通区域最小外接矩形的宽度和高度。
测试结果表明,用该方法可以去除大多数古籍图片中的非文本区域,如图6所示,可以看到用本文的方法对非文本区域的去除具有较好的效果。
1.3 古彝文单字符检测
经过前几步的处理,有效地去除了古籍图像中的大部分噪声,实现了非文本区域的去除。接下来要对候选的文本区域进行单字符检测。本文提出一种基于MSER[12]和CNN结合的方法对古籍图像中的单个字符进行检测,具体的实现步骤如下。

图6 非文本区域去除效果Fig.6 Effect of separating text area from non-text area
步骤1 采用基于MSER的方法对文本区域进行检测,MSER算法的具体实现过程如下:
(1)灰度区间 [0,255]内的256个不同阈值对灰度图像进行二值化;令Qt表示二值化阈值t对应的二值图像中的某一连通区域,当二值化阈值由t变成t+Δ和t-Δ(Δ为变化值)时,连通区域 Qt相应变成了 Qt+Δ和 Qt-Δ。
(2)计算阈值为t时的面积比q(t)= Qt+ΔQt-Δ/Qt,当Qt的面积随二值化阈值t的变化而发生较小变化,即qt为局部极小值时,Qt为最大稳定极值区域。其中Qt表示连通区域Qt的面积。 Qt+Δ-Qt-Δ表示Qt+Δ减去Qt-Δ后的剩余区域面积。
在进行MSER检测的过程中有些大的矩形框会包含小的矩形框,因此要对这些区域进行合并,将小的矩形框去除。设连通区域1的参数为β1、1、δ1、ε1,连通区域 2 的参数为 β2、2、δ2、ε2,其中,和β分别表示连通区域最小外接矩形在y轴方向上的最小值和最大值,δ和ε分别表示连通区域最小外接矩形在x轴方向上的最小值和最大值,那么连通区域1包含连通区域2可以根据式 (12)进行判定:

通过以上步骤,对文本区域进行了初步的筛选,但是由图7可以看出,检测结果中仍然包含着一部分非文本区域。这些区域和文本区域有着相似的几何特征,因此还需要进一步将这些非文本区域排除。

图7 单字符初步检测结果Fig.7 Preliminary detection result of single character
步骤2 为了能够进一步区分文本区域和非文本区域,本文参考AlexNet[13]网络设计了一个CNN的二元分类器,其结构如图8所示,一共有两个卷积层、两个池化层,最后的全连接层是一个针对文本和非文本的二元分类器。首先输入一张32像素×32像素的彩色图像,然后再用16个3像素×3像素的卷积核提取输入图像的特征,进而得到一个32像素×32像素×16像素的卷积层,后用2像素×2像素最大池化的方法降低卷积层的数据维度,得到一个16像素×16像素×16像素的池化层,再用32个5像素×5像素的卷积核进一步提取更高层的特征,最后通过2像素×2像素最大池化的方法得到8像素×8像素×32像素的输出。将这些输出特征全部连接在一个全连接层,根据特征向量进行权重计算,输出属于两个类别的概率,进而判断输入的图像是否为文本区域。Adam作为优化算法,学习率设定为0.001,学习率下降乘数因子设定为0.1,损失函数选择交叉熵损失函数[14]。训练样本通过从原始图像上裁剪获得,其中正样本为文本区域裁剪图像,负样本为非文本区域裁剪图像。本研究选取了124张彝文古籍图像,用来构建裁剪图像数据集,如图9(a)和9(b)所示,正样本为8 471个文本区域裁剪图像,负样本为8359个非文本区域裁剪图像。导入数据时,首先打乱顺序,以8∶2的比例进行随机划分,分别作为训练集和测试集,然后对输入图像采用均值分别为0.471、0.452、0.412,方差分别为0.282、0.267、0.231的参数对导入图像进行标准化变换。

图8 CNN网络结构 (单位:像素)Fig.8 Network structure of CNN(Unit:pixel)

图9 部分训练样本Fig.9 Partial training sample
裁剪样本的大小和CNN预测的平均准确率变化情况如图10所示,实验结果表明,在训练第20到30轮次的时候预测的平均准确率趋于稳定,通过比较24像素 ×16像素、24像素 ×24像素、32像素×24像素、32像素×32像素、48像素×32像素几种不同大小的裁剪样本,本文最终选择将32像素×32像素大小的裁剪样本作为训练数据,同时将本文检测算法得到的候选区域统一调整为32像素×32像素大小的图像进行分类。
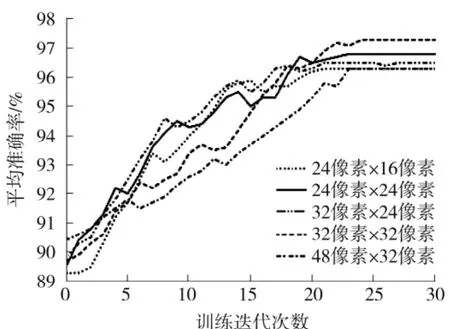
图10 裁剪图像大小与CNN预测平均准确率变化情况Fig.10 Change of cropped image size and average accuracy of CNN prediction
图11为通过CNN分类以后得到的文本区域,由此可见,本文方法能够对古籍中文本区域和非文本区域进行准确的分类。

图11 最终检测效果Fig.11 Final detection result
2 字符检测实验结果与分析
本文测试的古籍扫描图片均由贵州省毕节市贵州工程应用技术学院彝学研究院提供,实验从3052张扫描图片中选取了最具古彝文书写风格的53张背景复杂、噪声较大、最具代表性的图片,然后采用ICDAR2005年鲁棒阅读测评[15]定义的准确率和召回率来评测文本区域检测的性能。本文实验环境:Windows操作系统 (Windows10企业版)、Intel(R)Core(TM)i7-7700处理器、3.60 GHz主频、8GB内存、NVIDA GeForce GT710显卡。
准确率定义为准确检索到的文本框的数量与所有检测到文本框数量的比值;召回率定义为准确检索到的文本框的数量与需要被准确检索的文本框数量的比值。假定准确检索到的文本框的数量为m,所有检测到文本框的数量为ma,需要被准确检索的数量为mb,那么准确率p和召回率r可用以下公式表示:

然而,现实中检测出的文本框和标准的文本框并不一定完全重合,ICDAR2005鲁棒测评小组用一个匹配值来评估定位的准确性,m按照如下方式定义。
如图12所示,根据ICDAR2005规定的标准,R1表示标准的文本框,R2表示参赛者所得到的文本框,则m的表达式如式 (14)所示,其中a表示相应矩形框的面积。


图12 当两矩形框重合时m的计算方式Fig.12 Formula mode of m when two rectangles overlap
实验证明,本文提出的方法能够较好地将文本区域和复杂背景进行分离,并在单字符检测方面取得了较高的准确率和召回率,实验中对文本检测的结果如图13所示。通过检测结果可以发现,本文提出的方法可将污染严重、噪声较大的古籍图片中的大多数字符进行较准确的检测。

图13 古籍文本检测结果Fig.13 Detection result of ancient text
本文方法的测试结果如表1所示,将本文的方法分别同6种不同的传统检测方法和3种深度学习方法在总体性能上进行了对比。传统方法分别是:只采用连通分量的方法、只采用传统投影法、采用连通分量结合传统的投影法、只采用MSER的方法、只采用笔画宽度变换的方法 (SWT)和采用MSER结合SWT的方法[16]。深度学习的方法分别是:基于 Region CNN(R-CNN)[17]的方法、基于Fast R-CNN[18]的方法、基于 Faster R-CNN[19]的方法。这3种方法的训练数据都选取之前用来构建裁剪数据集的124张彝文古籍图像,并标注单个字符区域,训练时将所有图片的宽度归一化为400个像素,高度按比例进行缩放。

表1 本文方法和其他传统检测方法在总体性能上的对比Table 1 Comparison of overall performance of the proposedmethod with other traditional methods
通过对比9种不同检测方法的检测结果数据,可以发现,基于传统投影法的准确率和召回率较低,这主要是由于彝文古籍书写版面杂乱,且有较多字符区域重叠的现象;而基于连通分量的检测方法能够较好地处理字符区域重叠的问题,但是对于图文混排的图像,还是不能取得较好的检测效果;在将两种传统的方法融合以后,准确率和召回率得到了一定的提升,基于MSER和SWT结合的方法取得了较好的效果,但是由于古籍中很多非文本区域和文本区域具有相似的笔画宽度,因此准确率反而有所下降;3种深度学习的方法在总体性能上优于传统方法,但由于目前标注的训练样本仍然较少,最终的检测效果不太理想;而本文提出的方法可以较好地处理字符区域重叠和图文混排的情况,在有限的标注数据上检测的准确率和召回率取得了最好的结果。
同时,本文提出的方法在检测其他古籍图像中也具有一定的普适性,古汉字和古彝文具有相似的字体结构,如图14所示,采用本文的方法对汉字佛经图像的字符检测也取得了一定的效果。

图14 汉字佛经古籍检测结果Fig.14 Detection results of ancient Chinese characters in Buddhist scriptures
3 结语
本文实现了一种对复杂噪声背景下彝文古籍扫描图片进行预处理和文本检测的方法。首先通过非局部均值滤波和改进的局部自适应二值化方法对原始图像进行预处理,其次用启发式规则方法过滤掉非文本区域,最后用基于MSER和CNN的方法对彝文单字符进行检测。实验结果表明,本文提出的方法同其他传统的检测方法相比可以取得较高的准确率和召回率。如何从更复杂的背景下更好地提高检测性能、对彝文单字符的识别以及通过传统检测方法对古籍字符进行预标注,然后采用深度学习的方法进行训练将是下一步进行的主要工作。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
汉字汉语研究(2021年3期)2021-11-24
汉字汉语研究(2020年2期)2020-08-13
布达拉(2020年3期)2020-04-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年9期)2019-05-30
电子制作(2018年16期)2018-09-26
金桥(2017年5期)2017-07-05
