
基于TextRank 和簇过滤的林业文本关键信息抽取研究
2020-07-07 06:09:10陈志泊李钰曼冯国明师栋瑜崔晓晖
农业机械学报 2020年5期
陈志泊 李钰曼 许 福 冯国明 师栋瑜 崔晓晖
(1.北京林业大学信息学院,北京100083;2.中国联合网络通信集团有限公司,北京100033;3.中国电信系统集成有限责任公司,北京100035)
0 引言
随着互联网与人工智能技术的飞速发展,我国传统林业也逐步向“智慧林业”迈进。对于网络上数量呈爆发式增长的林业文本来说,如何节省阅读时间、从中准确获取与林业领域有关的信息具有重要的研究意义[1-2]。
文本关键信息应包含关键词和信息类型。目前大多数的林业文本并没有标注关键词,早期的关键词抽取是通过人工标注、借助人类的专业知识完成的,工作任务十分繁重。随着计算机技术的发展,借助计算机程序抽取关键词成为更好的选择[3-6]。关键词抽取主要分为有监督和无监督两类[7]。由于有监督算法标注成本高,且存在过拟合的问题,近年来,无监督关键词抽取算法得到广大科研人员的青睐。常见的无监督关键词抽取方法有3 种:基于统计特征[8-9]、基于词图模型[10-12]和基于主题模型[13]的关键词抽取。基于统计特征的关键词抽取算法[14-15]将文本词语的统计信息记为特征信息,如词频特征、逆文档频率特征、长度特征、位置特征等,再对特征信息进行相应的量化处理,最后抽取出文本关键词。其缺点是忽略了词语之间的相互关系,效果有时并不理想。基于主题模型的关键词抽取算法[16-17]认为每个文本都对应着一个或多个主题,而每个主题都会有相对应的词分布,通过分布信息得到文本与词的关联情况,进而得到文本关键词,以LDA 隐含主题模型为经典代表。其缺点是模型需要大量的数据训练,对于内容较短的文本不敏感,且计算复杂度较高,所以提取效果有时并不理想。基于词图模型的关键词抽取算法通过融合词语特征信息达到优化提取效果的目的,是目前应用最广的无监督提取方法[18]。因此,融合词语的特征信息[19-23]、优化词图模型、提高抽取效果具有重要的研究价值。仅抽取关键词不能完整且直观地表达文本内容,因而需要借助信息类型来完善。对于词语的信息类型,如果文本有严格的记述特征,则可以通过分析记述结构进而抽取到相应的属性[24-27],但大多数文本没有良好的记述结构,故采用此方法相对困难。因此,如何确定词语的信息类型具有现实意义。
本文采用合理的公式抽取关键词,通过改进TextRank 算法、归并聚类、簇过滤等,获取到高品质的词语集合,进而进行信息类型的判定,将关键词和信息类型结合,实现对林业文本的关键信息抽取。
1 实验方法
1.1 相关技术原理
1.1.1 词语特征
关键词抽取是指从文档中获取有代表性的词语,用以反映文档的主题和核心内容。衡量词语的重要性,不能从单一角度考虑。通常用词频特征、位置特征等[28-29]特征来衡量。文献[30]已对基于词频-逆文档频率特征、长度特征、词语首次出现的位置特征以及词跨度特征等4 个方面关键词抽取公式进行了相关研究,基于此,本文在该基础上加入标题特征,如果词语出现在标题中,标题特征值记为1.5,反之记为1。词语综合权重值计算公式为

式中 Wtf——词频 l——词长
Widf——逆文档频率
s——词语首次出现的位置
t——词语最后一次出现的位置
n——文本词汇总数
θ——标题特征值
其中WtfWidf为词频-逆文档频率特征,lbl 为长度特征,1+e-s为词语首次出现的位置特征,1 +(t -s)/n为词跨度特征。
1.1.2 相似性度量
将关键词用Word2Vec 向量化表征,根据向量之间的相似度聚为若干簇。相似性度量方法有:欧氏距离、曼哈顿距离、切比雪夫距离、闵可夫斯基距离、马氏距离、余弦相似度、汉明距离等。本文通过设置阈值,计算向量间的余弦相似度对向量进行归并聚类,向量余弦相似度Wcos计算公式为

式中 X、Y——任意两个不同的向量
‖X‖、‖Y‖——X、Y 向量的模
1.1.3 TextRank 算法
TextRank 算法是一种用于文本的基于图的排序算法,通过对图结构的迭代计算实现词语的重要性排序[31-33]。优点是不需要事先对文档进行相关的学习训练。基本原理如下:
设G(V,E)是由给定文本的词汇所构成的图结构,V 为图节点集合,E 是图边集合。对于文本中的任一Vi,基于TextRank 算法得到权值Wi计算式为

式中 d——阻尼系数,取值为0 ~1
In(Vi)——指向节点Vi的所有节点的集合
Out(Vj)——节点Vj指向的所有节点的集合
wji、wjk——节点Vj到节点Vi、Vk的边的权重
Wj——节点Vj的权值
但最初TextRank 算法在应用时,忽略了词语本身的特征信息,使各节点初始值均等,且节点权重均匀转移。
因此,本文在原有TextRank 算法的基础上进行改进,考虑词语特征,将由关键词抽取公式计算得到的综合权值作为节点的初始值,并用词语向量间的余弦相似度作为边的初始值,构建带权无向图结构,此时对于文本中的任一Vi,权值Wi计算公式为

式中 join(Vi)——节点Vi相连的所有节点的集合
1.1.4 簇过滤
对于向量归并聚类形成的簇来说,需要通过合理的品质评价指标对簇的品质进行过滤。本文从簇元素分布的均匀性、簇的规模、簇的普适性3 个角度考虑,设计簇品质评价公式,通过对相关参数的调整,过滤得到品质比较好的簇集合。
某核电厂取排水设计对渔业资源经济价值影响分析………………………………………………… 杨帆,傅小城(3-65)
(1)簇元素分布的均匀性(Balance)
簇中元素分布均匀性指标B 的计算公式为
式中 Av——簇中节点元素权值的平均值,反映数据的集中性特征
St——簇中节点元素权值的标准差,反映数据的波动性特征
标准差St越小,说明元素的权重分布越均匀,说明簇中有用的元素越多。标准差St相同时,需要借助平均值Av来判定。当St/Av越小,元素分布越均匀,依据取倒数且分母不为零的原则设计公式,得出B 值越大,簇元素分布越均匀。
(2)簇的规模(Scale)
簇的规模S 指簇中所含元素的数量,计算公式为

式中 μ——簇中元素的个数
(3)簇的普适性(Universality)
普适性指标U 是指簇中元素来源的文章数,计算公式为
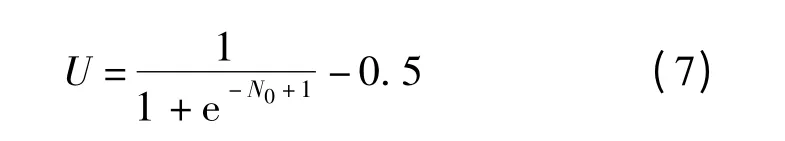
式中 N0——簇中元素来源的文章数
簇中元素来源的文章数越大,即N0越大,U 越大,说明簇的普适性越好。
(4)簇品质(Quality)评价公式
从簇元素分布的均匀性、簇的规模、簇的普适性3 个角度考虑簇的品质Q,计算公式为
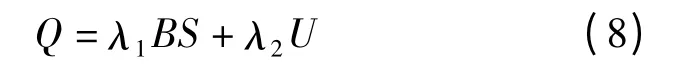
式中 λ1、λ2——参数
Q 由两部分组成:簇的总体水平和簇的普适性,通过调节参数,权衡各指标所占的权重。说明在不同规模下,均匀程度的增大对簇的品质的提升是不同的;规模越大,提升越大。所以簇品质对均匀程度的偏导为规模的单增函数,可得

式中函数f、g 均为单增函数。为方便计算,设
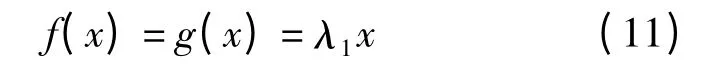
因此,簇的总体水平由簇元素分布的均匀性和簇的规模两部分组成,可记为λ1BS。
1.2 提取流程
针对数量庞大的林业文本,采用“关键词+信息类型”的表示方式,提出基于改进TextRank 和簇过滤的林业文本关键信息抽取方法,通过合理的方式对林业文本进行关键信息抽取。提取流程如图1所示,具体步骤为:
(1)林业文本预处理,包括引入领域词典对文本进行分词、引入停用词表对文本进行去停用词等操作。
(2)依据关键词抽取公式,抽取文本综合权值排名前30 的词语,部分结果如图2 所示。
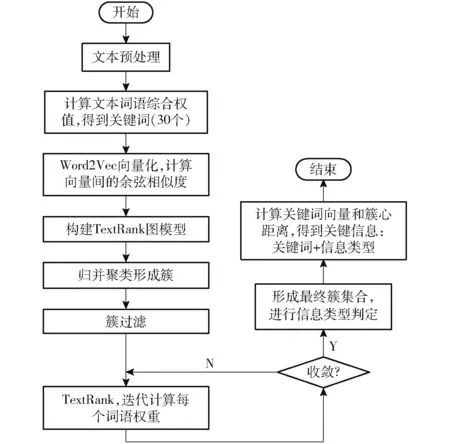
图1 关键信息提取流程Fig.1 Key information extraction process

图2 部分抽取结果Fig.2 Part of extraction results
(3)对抽取的关键词用Word2Vec 向量化表征,并计算两两向量的余弦相似度。
(4)设置阈值,向量余弦相似度大于阈值的两个词之间连线,间距小于阈值的2 个词之间不连线,以相似度为边的权值,以步骤(2)计算出的权值作为节点的初始权值,进而构造图模型,应用TextRank算法,得到了综合考虑词与词关系的关键词最终权值。
(5)利用图结构中词语的节点值和相应的词向量进行加权求和,得到图中心。计算两两图中心的余弦相似度,设置阈值,余弦相似度大于阈值的图进行合并,归并聚类得到初始簇。
(6)对簇中的节点值进行标准化处理,依据设计好的簇品质评价公式,对初始簇进行品质评价,设置阈值,进行过滤操作。
(7)对过滤后的簇应用TextRank 算法,经过迭代收敛得到最终簇集合,对最终形成的簇集合进行信息类型的判定。
(8)计算关键词向量和各簇心之间的余弦相似度,通过比较,得到关键词的信息类型。最终得到文本的关键信息:关键词+信息类型。
2 实验及方法验证
2.1 实验环境
本文所提出的算法模型采用Python 编程实现,本实验所有的模型训练计算机环境主要参数为Intel Corei5-8250U CPU @ 1.6 GHz 1.80 GHz,内存为8.00 GB。
2.2 实验数据
本文所采用的实验数据为与林业政策和新闻相关的文本,数据分别来自中国林业新闻网、林业信息网、林业产业网等林业相关网站,经数据预处理后共2 000 篇,其中400 篇文本进行了关键词人工标注。
2.3 评价指标
2.3.1 聚类评价指标
所采用的评价指标有3 个:紧密度、间隔度、聚类综合评价指标。
(1)紧密度(Compactness,CP)
每一个簇中各元素到簇心的平均距离越小,说明聚类效果越好。实验选用向量的余弦距离,因此CP 越大,说明聚类效果越好。
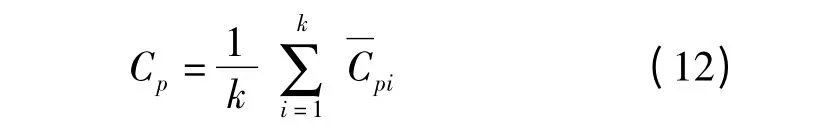
其中
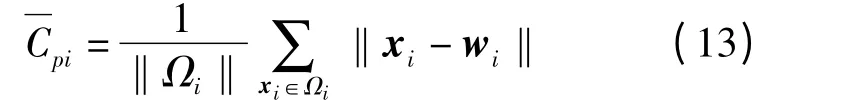
式中 Cp——紧密度
xi——簇中第i 个关键词向量
wi——第i 簇的簇心向量
Ωi——第i 簇的关键词集合
k——簇的个数
(2)间隔度(Separation,SP)
各簇中心两两之间的平均距离越远说明簇间聚类效果越好。实验选用向量的余弦距离,因此间隔度越小,说明聚类效果越好。
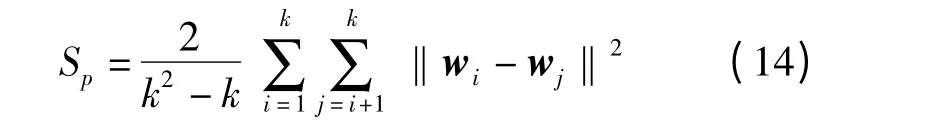
式中 Sp——间隔度
wj——第j 族的簇心向量
(3)聚类综合评价指标(F1-Measure,F1)

式中 N1——簇元素为1 的数量
N——簇的数量
2.3.2 关键词抽取效果评价指标
第1 类评价指标有3 个:准确率(Precision,P)、召回率(Recall,R)和综合评价指标(F-Measure,F),公式为

式中 X——正确抽取到的关键词数
Y——错误抽取到的关键词数
Z——属于关键词但未被抽取到的词数
第2 类评价指标为针对有序的关键词抽取结果的评价指标,包括平均倒数等级(Mean reciprocal rank,MRR)和二元偏好度量(Binary preference measure,Bpref)。其中,MRR 用来度量每个文档第1个被准确提取的关键词的排名情况,而Bpref 则用来度量提取结果中错误提取的词语的排名情况,具体的计算公式为

式中 D——所有文档的集合
rd——第1 个正确提取结果的排序
Q1——正确的关键词的集合
|F0|——排列在正确提取词r∈Q1之前提取的错误词的数目
|E|——所有提取词的数目
2.4 实验结果及分析
依据两两向量间的余弦相似度,对单个文本构建图模型时,需要设置合理的阈值。实验结果如表1 所示。此时部分指标随阈值变化趋势如图3 所示。
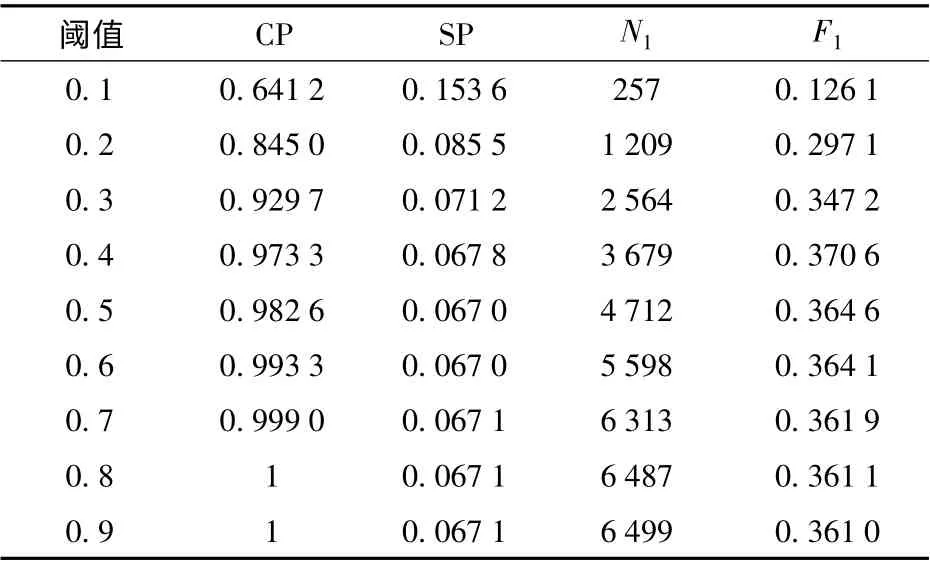
表1 单个文本构建图模型阈值参数Tab.1 Parameters of single text built graph model
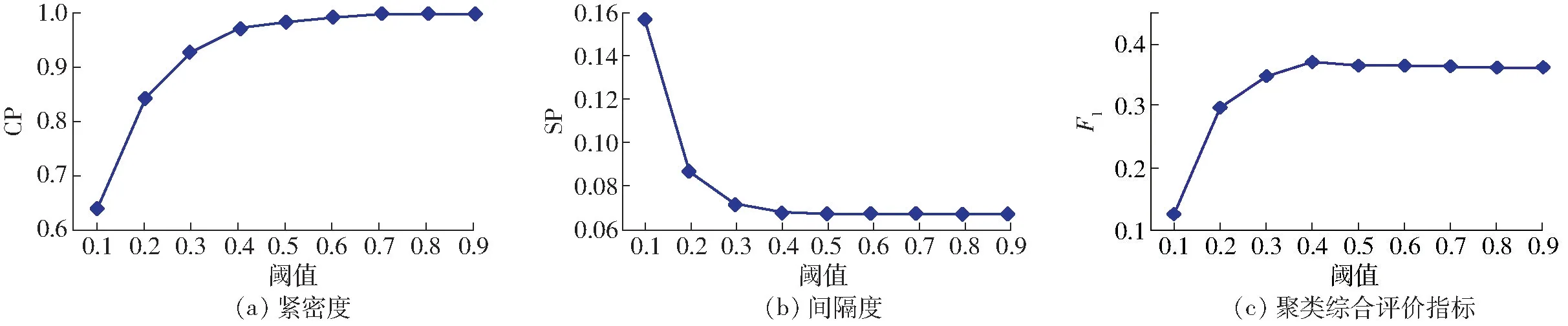
图3 各指标变化趋势(单个文本)Fig.3 Trend of each index (single text)
由表1 及图3 可以看出,当阈值大于等于0.4时,CP 和SP 逐步趋于稳定,且当阈值等于0.4,F1最大,说明聚类效果最好。因此,单个文本构建图模型阈值参数设置为0.4。
单个文本形成稳定的图结构后,要对所有的图进行归并聚类形成初始簇,需要设置合理的阈值。实验结果如表2 所示。此时部分指标随阈值变化趋势如图4 所示。
由表2 及图4 可以看出,当阈值在0.5 ~0.7 之间时,CP 趋于稳定;虽然SP 呈递增趋势,但要综合CP 来设定阈值参数。阈值为0.5 时,CP 为0.929 0,SP 为0.050 2,此时簇的数量N 为1 194,F1值最大,为0.848 0。因此,归并聚类时阈值参数设置为0.5。
对簇进行过滤时,要进行品质评价。此时需要讨论参数λ1和λ2,将λ1在0.1 ~0.9 的取值分别记为序号1 ~9,实验结果如表3 所示。

表2 图结构归并聚类阈值参数Tab.2 Parameters of merged cluster of graph structure
由表3 可以看出:当λ1为0.7,λ2为0.3 时,CP为0.968 0,SP 为0.057 2,此时簇的数量N 为234,说明能对簇进行有效过滤,此时F1为0.887 1,综合评价最好。因此,归并聚类时阈值参数λ1、λ2分别设置为0.7、0.3。

图4 各指标变化趋势Fig.4 Trend of each index

表3 品质评价公式参数Tab.3 Parameters of quality evaluation
为了验证本文过滤方法的有效性,将过滤前的状态记为状态1,采用本文过滤方法过滤后的状态记为状态2,并与文献[34]提出的基于聚类显著程度的定量过滤指标对簇进行过滤的方法作对比,并记为状态3,对比实验采用上述评价指标,结果如表4 所示,结果说明簇品质公式能有效对簇的品质进行评价,本文过滤方法是行之有效的。同时对最终簇的元素来源文章数进行了统计,来源文章数规模最大为21,最小为4。

表4 簇数量统计Tab.4 Numbers of clusters
对簇进行信息类型标注,部分标注结果如表5所示。

表5 部分标注结果Tab.5 Part of results
为了进一步验证本文方法在抽取关键词方面的有效性,将TF-IDF、TextRank 以及文献[10 - 11,35 -36]中相应的关键词抽取方法分别作为对比实验。将上述模型按提及次序分别记为模型1 ~6,将本文方法记为模型7。实验数据为已进行关键词标注的400 篇林业文本。实验结果如表6 所示。
通过实验结果可以看出,本文所提方法在MRR、Bpref、准确率和综合评价指标上均取得了最好的效果,在召回率方面取得了较好的效果,说明本文所提关键词抽取公式具有很好的关键词抽取能力。

表6 对比实验结果Tab.6 Results of comparative experiments
2.5 测试
2.5.1 测试流程
为了进一步验证本文所提出的关键信息抽取方法的有效性,开展了相关的测试实验工作,测试流程如图5 所示。
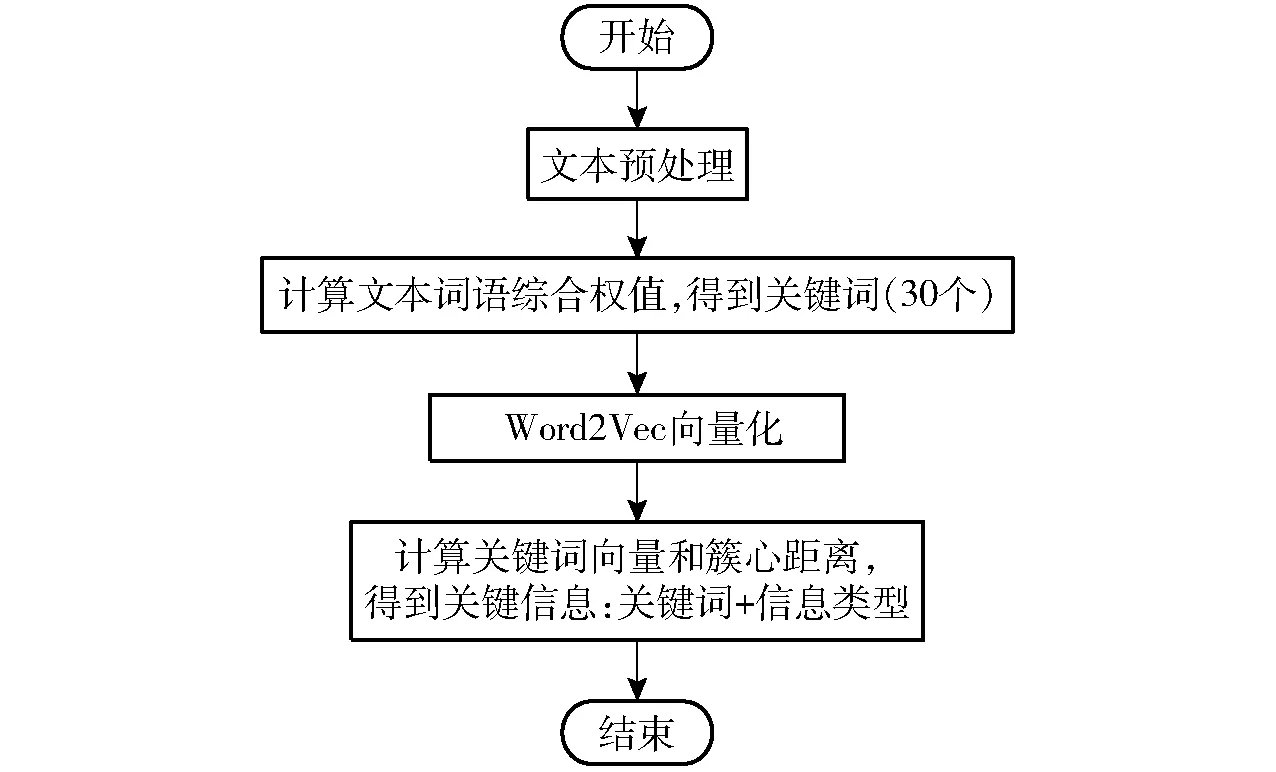
图5 测试流程图Fig.5 Test process
具体步骤如下:①文本预处理,对文本进行分词、去停用词等操作。②依据关键词抽取公式,抽取权重排名前30 的词语。③对抽取的关键词进行向量化表征。④通过计算比较关键词向量和各簇心之间的距离,得到关键词、最相似簇、最大相似度的三元组,根据最大相似度对30 个三元组进行降序排序,取前10 个。以最相似簇的标注类型作为词的信息类型,最终得到文本的关键信息:关键词+信息类型。
2.5.2 测试实例
选取一篇新的与林业政策新闻相关的文章,文章的部分内容如图6 所示。
2.5.3 测试结果抽取最大相似度排名前10 的词语,结果如表7所示。

图6 测试文章的部分内容Fig.6 Part of test article

表7 测试结果Tab.7 Test results
结果表明本文所提方法能从“关键词+信息类型”两部分表示文本关键信息,内容表述基本清晰,且具有很好的代表性和可读性。
3 结束语
为了使抽取的关键词综合特征明显,通过综合考虑词长、词跨度、标题等特征,将计算的综合权值作为词语特征值,通过构建融合词语特征、引入边权重的图模型对TextRank 算法进行改进。经迭代收敛、归并聚类得到稳定的簇集合,对其过滤得到高品质的词语信息类型集合。实验表明,本文方法相对于其他关键词抽取方法具有更高的关键词抽取能力,最终形成的信息类型集合在紧密性、间隔性、综合评价指标上均表现良好。随机针对一篇林业政策新闻类的文本进行测试,结果表明,从“关键词+信息类型”两部分考虑,本文方法能有效提取出该文本的关键信息,说明本文提出的基于改进TextRank和簇过滤的林业文本关键信息抽取方法是有效的。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
电子测试(2017年15期)2017-12-18 07:19:27
河北遥感(2017年2期)2017-08-07 14:49:00
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
智能系统学报(2015年4期)2015-12-27 09:38:39
新高考·高二数学(2015年11期)2015-12-23 18:17:44
