
智能光子处理系统:概念与研究进展
2020-07-06 03:35
中兴通讯技术 2020年2期
(上海交通大学,上海200240)
(Shanghai Jiao Tong University, Shanghai 200240, China)
随着“5G+”的业务场景不断扩大,终端数据呈现爆炸式增长[1],智能处理技术将成为未来网络发展的核心要素。未来,6G技术将具有更高的传输速率和连接密度,以及全空域全频谱通信、有线无线融合、网络一体化等关键特征[2]。智能处理技术将从3个层次与6G网络发展深度融合:第一,6G技术将带来更加多样化的应用场景。针对不同场景的数据类型、不同业务的处理需求,智能处理技术将与网络终端无缝衔接,实现定制化的“场景智能”;第二,6G环境下剧增的信息量将超出现有设备的处理极限。智能处理技术将实现宽带信号层面的有用信息提取,大大降低端-端传输压力,实现“信息智能”;第三,6G网络吞吐量高,并且呈现不同架构有机融合、处理功能一体化等重要态势。智能处理技术将实现频谱资源的动态分配、网络接口的动态切换、网络拓扑的动态调控,实现网络自治化管理的“网络智能”。因此,在5G/6G浪潮的推动下,我们对具有高速率、大带宽接口的智能处理技术展开研究至关重要。
光子具有带宽大、速率高、抗电磁干扰能力强、串扰低、传输损耗低等优点,在很多领域中被广泛研究并成功应用,如光通信、微波光子学(MWP)、光学成像、光学传感等。然而,传统光子处理系统在不断发展的过程中逐渐显现出性能瓶颈。例如,由于光电子器件的固有缺陷和并行化通道间的失配,微波光子处理系统的性能会随着复杂度和规模的增大而恶化[3]。此外,传统光子处理系统通常是为特定的应用场景开发的,灵活性相对较低。在早期的研究中,功能可切换可编程的光子处理器得到了业界诸多关注[4],这预示着功能可切换可编程的光子处理器具有极大的应用潜力;因此,未来的光子处理系统不但需要性能上的提高,而且需要更加灵活智能的任务执行方式。
AlphaGo的出现[5-6],标志着以深度学习和人工神经网络(ANN)为代表的人工智能(AI)技术开始在各领域广泛探索并纵深发展。当前,AI技术已被引入光学和光子学领域。AI赋能的光子处理系统与传统方法优化后的光子处理系统相比,具有更出众的性能和鲁棒性,并有望在实际应用场景中大大降低传统光子处理系统的成本及人工操作难度。
可以预见,智能光子处理系统(IPS)是未来复杂环境中实现宽带智能信息处理的关键。
1 IPS概念
随着光子技术和智能技术的不断融合,IPS将从AI形态逐渐演变到神经拟态智能形态,并具有更高的通用性与能量效率。如图1所示,IPS从层次上可分为AI赋能的IPS、光子辅助AI的IPS和神经拟态的IPS。在本节中,我们讨论了不同架构IPS的基本特性与实现方法。
首先,我们引入基于深度学习的AI技术来优化光子处理系统,即AI赋能的IPS。如图1(上侧)所示,IPS由光子模拟宽带前端和数字智能后端组成。在实际的光子前端硬件中,噪声积累、光电转换非线性以及并行通道间失配等缺陷成为制约其性能提升的主要瓶颈,使得信噪比(SNR)严重下降。研究人员提出了基于硬件或软件的优化方法来提高SNR[7-8]。然而,其优化效果受限于较低的灵活性和高昂的硬件成本。
引入AI技术是一种有望提高前端性能的灵活性方案。结合了深度学习的ANN擅长从参考信号(理想)和输出信号(非理想)构成的数据集中学习中间系统的系统响应与系统缺陷特征,从而构建复杂映射关系完成非理想信号的恢复。在训练成功的前提下,ANN能够以较低的成本对宽带大动态范围的前端输出信号进行优化;因此,AI赋能的IPS将可超越传统光子处理系统的性能,对射频(RF)信号进行更有效的处理。
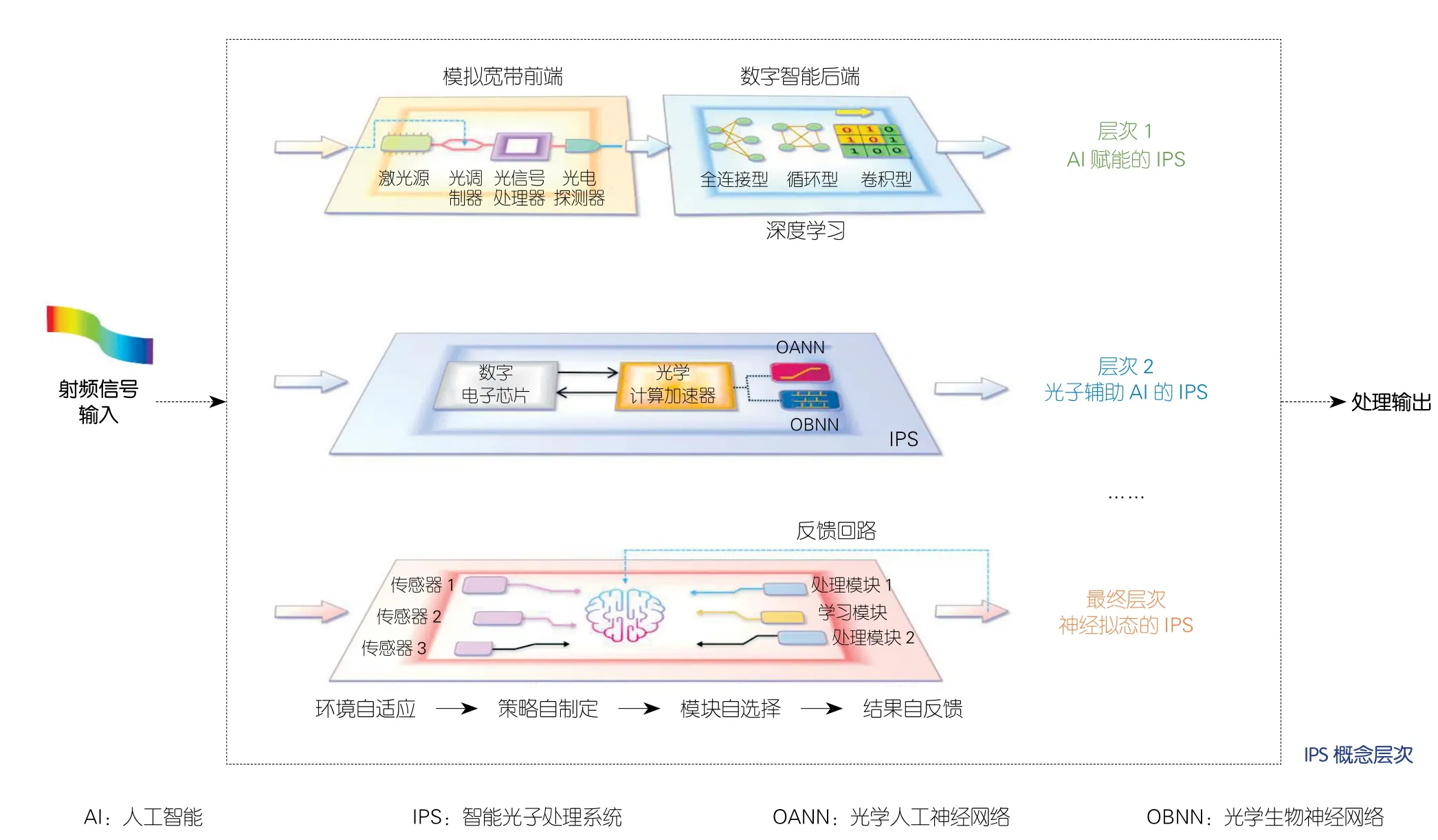
▲图1 IPS概念的不同架构示意图
其次,我们提出第2种IPS架构,即通过光子方法辅助AI计算。如图1(中部)所示,光学人工神经网络(OANN)是光学计算加速器的发展方向之一。AI中大量的计算操作(如乘法和累加、多媒体接入控制)已成为当前中央处理单元(CPU)的严重负担。随着摩尔定律不断逼近终点[9],针对计算框架的创新设计已是刻不容缓。光子因其具有高速率、高能效的特点成为极具潜力的新型技术:首先,电子时钟的速率仅为吉赫兹量级,严重影响了AI计算中的时延性能;而随着波分复用(WDM)、高速调制等技术的成熟,光学方法则能够以光速进行数据的并行化传递及处理。其次,电子AI计算方案的能耗与输入矩阵维度的平方成正比,使得能源成本和散热问题更加凸显[10];而光学无源结构则能够实现零能量消耗的超快光学计算。具体而言,光子辅助AI的IPS的调制、探测带宽可达100 GHz,高出图形处理单元(GPU)、张量处理单元(TPU)等电子AI专用计算单元两个数量级;其单位MAC操作的能耗能够达到pJ量级,甚至aJ量级,有望低于TPU的0.43 pJ/MAC水平;其时延水平更是低于100 ps,大大低于TPU的2 μs运算时延[11]。因此,通过将光学实现方法与ANN架构相结合,OANN有望为AI提供更优质的计算平台,大大提高AI的运行速度和效率,进一步拓宽潜在的实时应用场景。
采用类脑通信和计算原理的光学生物神经网络(OBNN)是超低功耗光学计算加速器的候选方案。不同于OANN辅助AI的IPS在训练过程中的高能量消耗,基于生物神经网络(BNN)的大脑只需要20 W的功率即可执行不同的任务[12]。BNN采用脉冲作为信息的表征方式[13],如图1(中部)所示。与电子学方法相比,BNN结构中单节点(即神经元)的带宽与互连密度之间的制衡突出了光子学方法的大带宽和低串扰的优势。进而,得益于高能效的特点以及高速脉冲的产生能力,光子学实现的BNN为开发超低功耗的计算框架带来了希望;因此,OBNN有望使IPS应用于更灵活的处理场景中,如移动端应用。
最后,IPS将接近神经拟态的终极形态——具有强大的感知和处理能力的“光子大脑”。大脑是高效智能信息处理系统的天然范例。神经拟态的IPS的特征如图1(下侧)所示。第一,神经拟态的IPS对环境表现出适应性。在不同的环境中,输入信号会受到自然(如温度)或人为(如干扰信号)的影响,需要通过各种“传感器”(如频率测量)实现对输入信号的多维评估,以正确理解输入信号的状态。第二,处理策略由神经拟态的IPS的“大脑”制定。这一步骤的核心在于根据不同的输入信号以最简洁高效的途径实现处理目标。第三,神经拟态的IPS选择必要的处理模块进行处理。神经拟态的IPS应当实现模块之间的协同以实现完整的处理功能,而不是简单的功能叠加。第四,神经拟态的IPS从输出结果中学习,并产生经验。一个高效的学习模块可以识别当前输出结果中的不足,并对处理策略进行修正。因此,具有光子宽带处理能力和智能学习决策能力的神经拟态IPS对未来信息处理系统至关重要。
2 IPS架构设计和关键技术的研究进展
近期,研究人员逐步利用AI解决系统实际问题并开发用于AI计算的光学加速器。根据AI赋能的IPS、OANN和OBNN的层次划分,本节中我们对IPS架构设计和关键技术的研究进展以及本课题组的相关研究进行回顾。
2.1 AI赋能的IPS
AI赋能的IPS的典型架构如图2所示。不同的光子/光学系统可以作为前端,例如光学成像系统、光学通信系统和光学传感系统等。特殊设计的ANN在经过训练后可以分析和处理前端的原始输出,从而能够实现AI赋能的IPS。
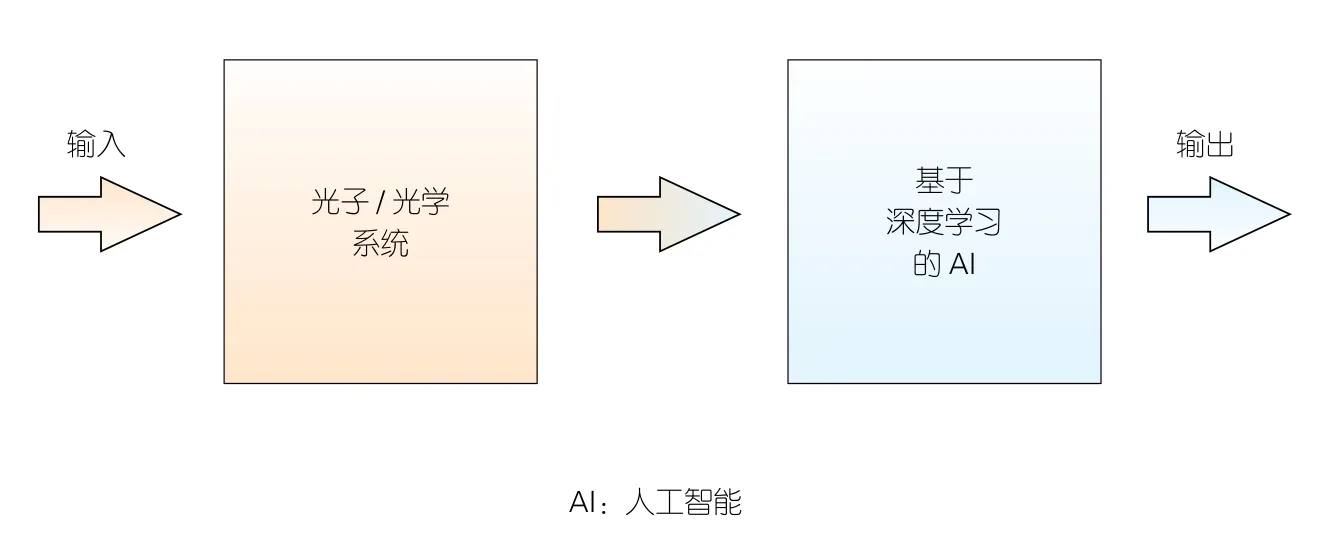
▲图2 AI赋能的智能光子处理系统(IPS)的体系结构
近年来,研究人员尝试将AI与光学成像技术相结合[14]。AI在光学成像领域的应用包括超分辨率成像[15]、端到端问题计算[16]、自动对焦[17]、光学切片[18]和降噪[19]等。在光通信和光网络领域,AI的应用场景涉及到性能监视[20]、数据分析[21]、网络路由[22]、失真改善[23]和调制识别[24]等。在传感领域,AI通常被用来开发新颖的传感方案[25],进行传感器数据处理[26]。此外,AI赋能的其他应用还包括集成光子器件设计[27]、纳米结构设计[28]、光子电路的高度并行仿真[29]和超短脉冲重建[30]。在ANN强大的映射近似能力的支撑下,更多AI赋能的IPS将会不断涌现。
本课题组取得的进展包括深度学习赋能的光子模数转换器(DLPADC)[31]和卷积神经网络(CNN)优化的布里渊瞬时频率测量技术(BIFM)[32]等。DL-PADC架构示意如图3所示,整体架构由光子前端系统、电子量化模块和深度学习数据恢复网络组成。图3的上侧给出了非线性、通道失配以及用于数据恢复的深度神经网络(DNN)的示意图[31]。实验结果表明DL-PADC的有效比特位数性能可优于先进的ADC。此外,针对宽带信号测频需求,我们提出了一种基于CNN的BIFM优化方法。实验结果显示,由CNN建立的实测瞬时频率和理论瞬时频率之间的映射可以有效减少由BIFM系统缺陷引起的误差。
对于AI赋能的IPS,其研究难点是如何根据系统的特点采用适当的ANN结构和学习方法来设计高效的IPS架构。目前,大部分相关工作中缺乏对所采用的ANN后端处理方法的有效评估,如在实际应用中的实时性、训练成本和数据集的选取等问题。随着前后端匹配程度的提高,AI赋能的IPS可以充分发挥光子技术的潜力并智能化地应用于真实场景。
2.2 OANN
OANN辅助AI的IPS体系结构如图4(a)所示。数字电子芯片(DEC)首先将AI任务分配给OANN,经过光学流水式计算后,OANN再将结果返还给DEC。全连接和卷积OANN是最典型的研究方向。图4(b)展示了采用OBNN辅助AI的IPS架构。与OANN不同,OBNN中的基本单元是神经元和突触,其研究多与神经拟态光子学相关[11]。
在文献[33]中,Y. C. SHEN课题组率先提出了一种由马赫-曾德尔干涉仪(MZI)和移相器组成的级联架构,用以实现矩阵乘法功能。X. LIN等提出了一种基于全光学衍射的OANN方案[34],在手写数字识别(MNIST)的任务测试中实现了91.75%的识别精度。最近,R. HAMERLY等研究了基于相干检测的可扩展OANN,该方案可以达到吉赫兹的速率,并且能耗水平低至亚阿焦耳[35]。

▲图3 深度学习赋能的光子模数转换器架构示意图
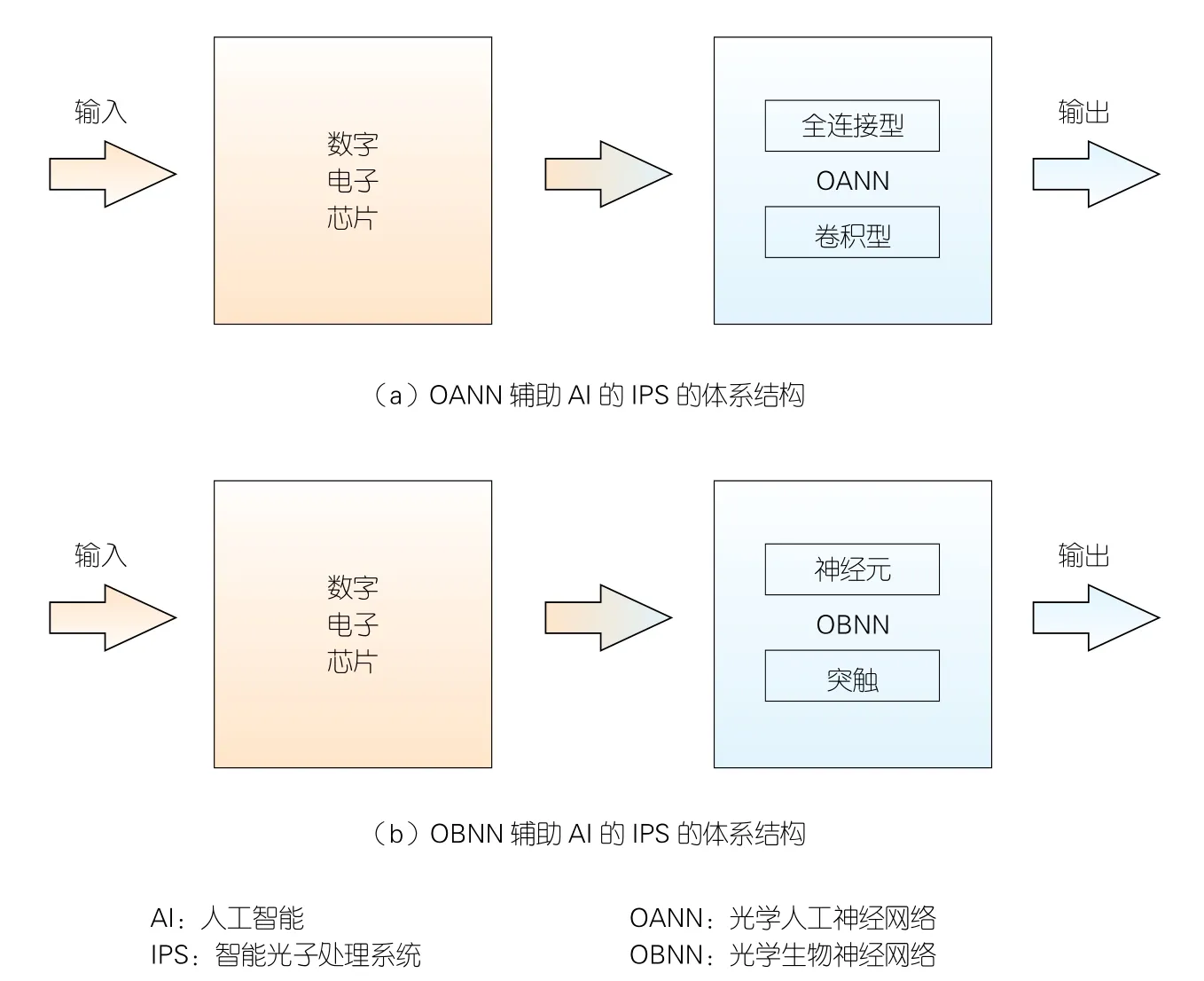
▲图4 OANN与OBNN辅助AI的IPS的体系结构
除了全连接网络之外,研究人员还专注于CNN的光学实现方法。在文献[36]中,作者描述了使用微环谐振器(MRR)和WDM的数字电子和模拟光子CNN(DEAP-CNN)架构。另外,非线性激活函数的实现[37]有助于开发更完整的OANN硬件架构。而考虑到实际硬件的缺陷,有效的训练方法[38]则成为OANN实现预期功能的关键。
本课题组在OANN方面开展了部分研究工作,其中包括高精度光学卷积单元[39]和高能效CNN的实现[40]。图5为所提出的光学卷积单元基于声光调制器阵列架构[39]。通过硬件重用方案,可以实现CNN的运算功能。在文献[40]中,我们引入了延迟线来实现具有低延迟和低功耗的卷积操作,如图6所示。通过对系统性能进行完善评估,这种新架构的能效较之前提出的集成OANN架构提升了若干倍。
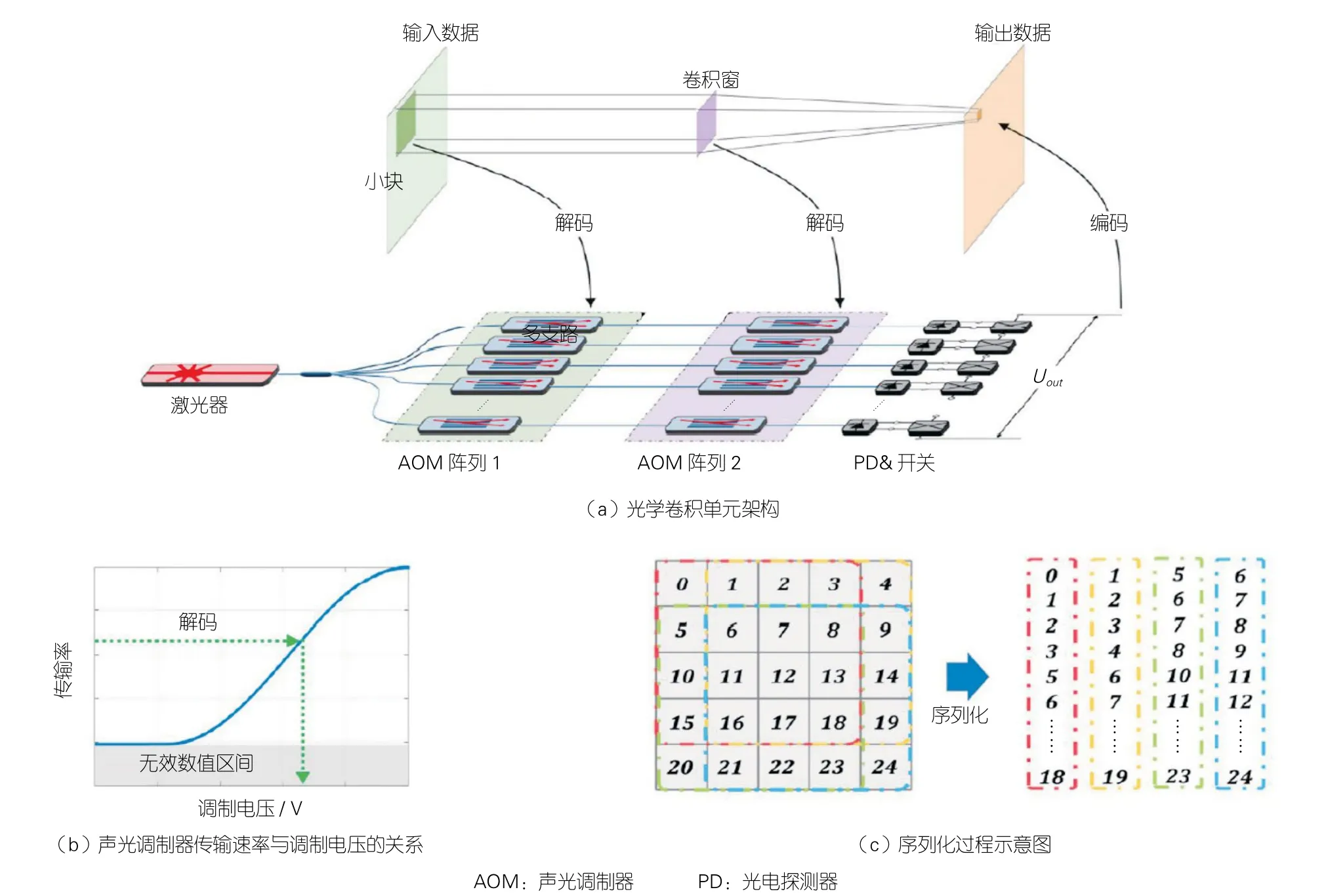
▲图5 光学卷积单元基于声光调制器阵列架构
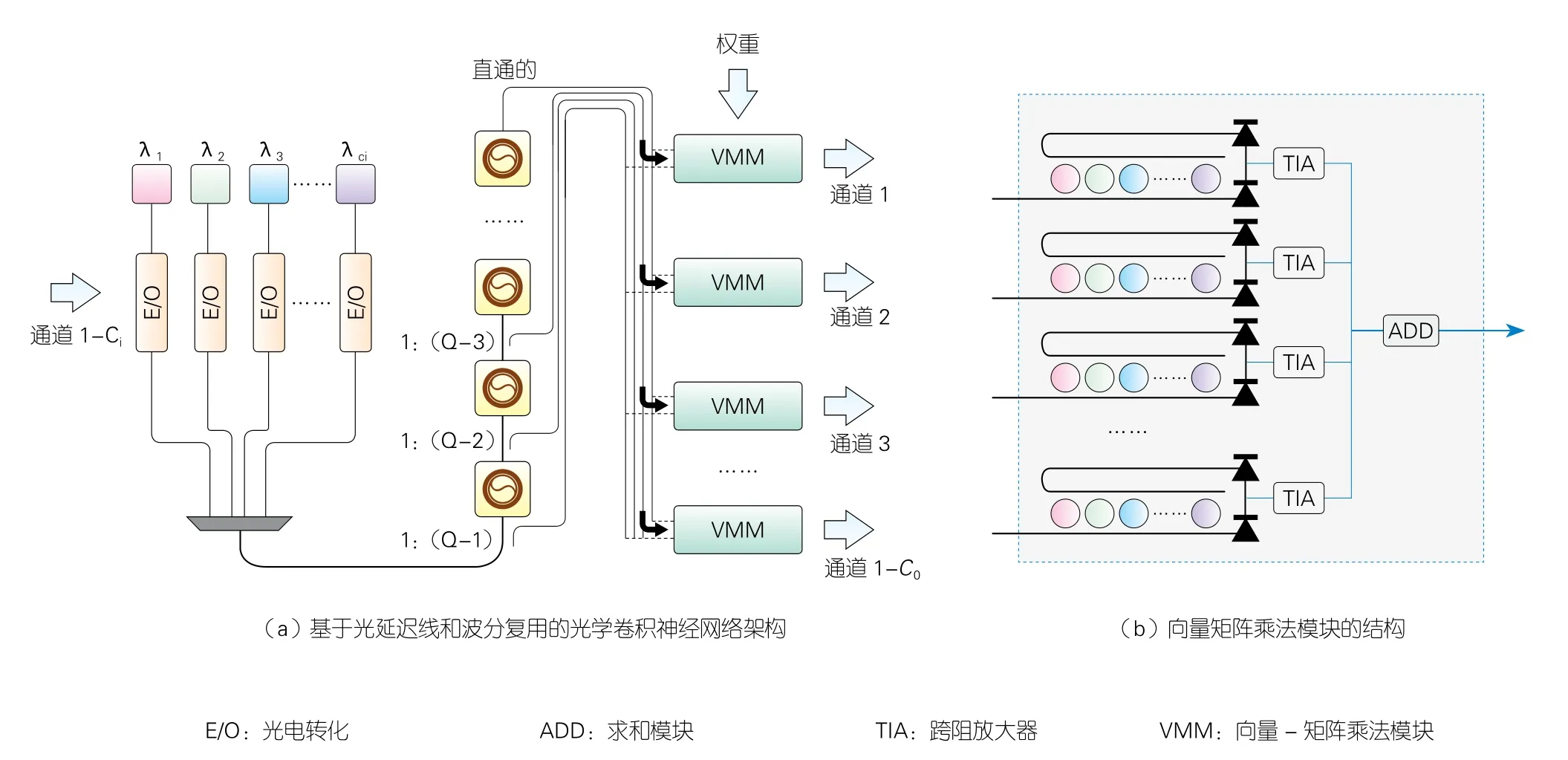
▲图6 高能效比光学卷积神经网络架构
对于OANN,高效、紧凑、可编程、低功耗的网络架构需要进一步被研究。同时,其研究重点将从概念性验证向集成化芯片转移。针对芯片化的OANN,应注意集成难度会随着网络规模的扩大而增加,因此如何平衡集成难度和所需的计算能力是一个严峻的挑战。另外,研究者还应该关注OANN的计算生态系统构建,例如开发与主流计算框架匹配的通信接口。
2.3 OBNN
光子神经元作为OBNN的关键组成部分,受到研究者的广泛关注。在文献[41]中,M. A. NAHMIAS等证明了具有腔内可饱和吸收体(SA)的垂直腔面发射激光器(VCSEL)与泄漏-积分-发放(LIF)神经元模型的行为类似。关于可兴奋激光器作为光子神经元方案的相关综述请参考文献[42]。突触在BNN中起到了动态调控网络行为的重要作用。Z. G. CHENG等利用相变材料(PCM)实现了一种全光光子突触[43]。PCM的非易失性使得光子突触不需要消耗静态能量。进一步,以脉冲时刻依赖的突触可塑性(STDP)为代表的机制被认为与BNN的学习行为密切相关。研究人员采用各种光学效应,如交叉增益调制、饱和吸收和非线性偏振旋转等[44],尝试实现光子STDP算法。光学脉冲神经网络的研究则致力于将神经元、突触等基本单元进行组合架构。在文献[45]中,A. N.TAIT等提出了一种用于可调节光脉冲处理的“广播-加权”系统架构,实现了光子神经元之间的高密度互连及加权操作。近期,J. FELDMAN等还提出了一种基于PCM的全光脉冲神经网络[46],其具有超宽带运行的潜力。
本课题组在OBNN的研究中取得了一些进展。我们证明了常规的分布式反馈激光二极管(DFB-LD)可用于神经拟态信息处理,包括模式识别、单波长STDP实现和声音方位角测量。此外,我们还提出了一种基于DFBLD的光子神经拟态网络,用于时空模式识别[47]。如图7所示,在STDP学习模块的辅助下,该网络可以学习目标模式并进行识别,且具有良好的集成潜力。
对于OBNN,各种神经元和突触的高密度互连是BNN的显著特征,因此简洁而多样的光子神经元和突触将成为研究的重点。近期的研究聚焦于光子神经元或突触功能特性的论证,而很少关注其级联和扩展特性。当前基本单元的种类远远不够丰富,因此可用的计算性质还很匮乏。值得注意的是,OBNN是实现神经拟态IPS的重要途径。
3 针对IPS的大规模混合集成技术
IPS是一个复杂的光电混合系统,包括光学有源/无源器件和射频驱动单元。大规模的光电子集成技术为IPS实现低功耗和高速率的信息处理提供了支撑。集成化的IPS拥有更加丰富的处理单元库以及更强的处理能力,能够解决更复杂的任务。

▲图7 基于DFB-LD的时空脉冲模式识别网络
按照集成器件是否使用多材料体系分类,光电集成可以分类为单片同质集成与异质集成。在单片同质集成方面,A. H. ATABAKI等首次提出了基于硅基材料构建光电集成芯片的方法[48]。J. S. FABNDINO等提出了基于磷化铟材料的微波光子滤波器的集成方法[49]。另一方面,异质集成能够发挥各种材料的优势,提升各功能器件的性能。根据是否进行异质材料生长,异质集成可分为单片异质集成与混合异质集成[50]。WANG Z. C.等通过外延生长在硅基衬底上成功制备了可以大规模集成的单片III-V族-硅基激光器[51],在此基础上,WANG Y.等制备了单片III-V族-硅基量子点激光器阵列[52]。混合集成的优势在于避免了不同材料间的晶格失配,工艺相对简单,但是集成度较低。N. LINDENMANN、P. O. WEIGEL、B. BEHROOZPOUR 等相继利用光子引线键合技术[53]、晶圆键合技术[54]、硅通孔技术[55]进行光互联与电互联实现光电混合集成。
相比于电子设备,光电集成技术为IPS 提供了更高的能量效率和处理带宽,有效突破了目前的电学瓶颈。对于单片同质集成,较为成熟的材料体系为硅基材料和磷化铟材料。其中,硅基材料难以集成光源等有源器件,磷化铟材料成本较高,难以大规模集成。混合异质集成主要面临的是实现高效光耦合与电路-光路接口的封装问题和由驱动电路带来的散热问题。单片异质集成是实现光电一体的大规模集成的关键技术途径,其避免了混合集成带来的封装问题;但单片异质集成目前有3个问题:多材料的兼容问题、由集成度提高带来的光路-电路的检测问题,以及芯片的散热问题。近年来,随着光电集成技术不断发展与探索,具有代表性的相关进展如表1所示。可以说,大规模光电集成技术的不断成熟,点亮了IPS的未来发展之路。
4 结束语
文章中,我们首先介绍了开发IPS的必要性,随后阐述了IPS概念的不同架构,即AI赋能的IPS、光子辅助AI的IPS和神经拟态的IPS,并指出其在不同层次中的潜在优势。此外,我们回顾了IPS架构设计和关键技术的研究进展,最后对IPS未来的发展前景进行了展望。我们希望在研究人员的努力下,IPS能够不断成熟,在未来智能化场景中发挥重要作用。下一步,研究人员还应关注BNN的拓扑结构、学习方案和进化机制等内容,作为实现神经拟态IPS的重要参考。
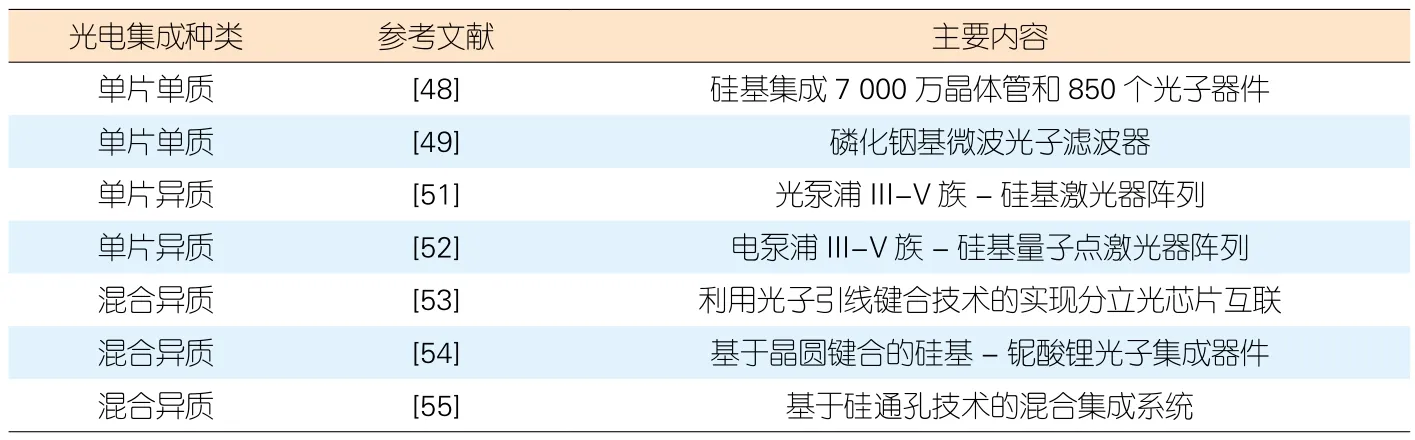
表1 大规模混合集成技术的相关进展
致谢
本文的部分研究成果和内容撰写得到了邹秀婷博士研究生和王静博士的帮助,谨致谢意!
猜你喜欢
初中生学习指导·中考版(2022年4期)2022-05-12
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
教育周报·教育论坛(2019年38期)2019-09-10
发明与创新·大科技(2019年11期)2019-03-07
学苑创造·A版(2019年12期)2019-01-10
北方文学(2018年2期)2018-01-27
百科知识(2017年3期)2017-03-17
中学生数理化·中考版(2016年2期)2016-09-10
小火炬·阅读作文(2009年8期)2009-07-14
数理化学习·高三版(2009年2期)2009-04-03
