
编程语言Julia并行计算实现模式探讨
2020-07-04 02:14庞双玉苏翔宇
电脑知识与技术 2020年14期
关键词:任务
庞双玉 苏翔宇

摘要:Julia编程语言是美国麻省理工学院MIT正式发布的面向科学计算的高性能编程语言。Julia集合c的速度,Matlab数学处理特征,Python的通用编程特性与Shen的命令行处理。Julia通过协程和远程宏调用机制实现了并行计算,是第一个编程语言级别上实现并行处理的模式的语言。本文探讨Julia并行计算实现模式并与hadoop集群分布式系统进行对比,讨论其各自的优劣。
关键词:Julia;协程;任务;并行处理;hadoop集群
中图分类号:G424 文献标识码:A
文章编号:1009-3044(2020)14-0242-02
1引言
JuliaJulia是一个面向科学计算的高性能动态高级程序设计语言.Julia是一种高级通用动态编程语言,它最初是为了满足高性能数值分析和计算科学的需要而设计的,不需要编译器,速度快,也可用于客户端和服务器的Web用途.Julia从一开始就为高性能而设计。Julia程序可通过LLVM编译为多个平台的高效本机代码。它具有如下特性。
(1)动态
Julia是动态类型的,感觉就像是一种脚本语言,并且对交互使用具有良好的支持。
(2)可选输入
Julia具有丰富的描述性数据类型语言,并且类型声明可用于阐明和巩固程序。
一般Julia使用多重调度作为范例,使表达许多面向对象和功能性编程模式变得容易。它提供异步I/O,调试,日志记录,性能分析,程序包管理器等。
(3)易于使用
Julia具有高级语法,因此对于任何背景或经验水平的程序员来说,它都是一种可访问的语言。浏览Julia的微基准测试,以了解该语言。
(4)开源的
Julia是根据MIT许可提供的,所有人免费使用。所有源代码都可以在GitHub上公开查看。
2Julia并行处理模式
并行和并发是讨论编程语言多任务处理时,经常提及的。并行和并发是两个不同的概念。
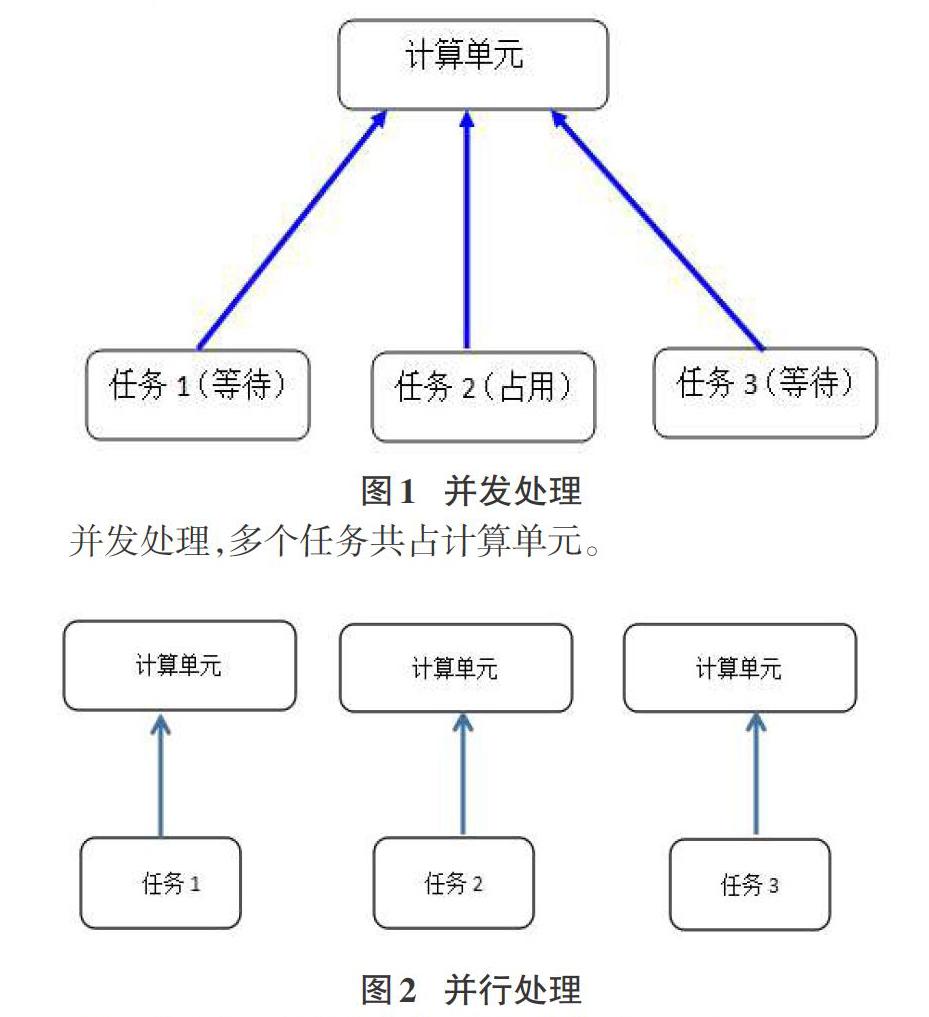
并发指的是计算处理单元同时对多个进程或者线程进行响应。并发处理时,多个进程或者线程共享计算单元。多个进程或者线程之间,依靠同步机制来协调。其中一个进程或者线程占用计算单元时,另一个必须等待。类似于信道复用,对用户来说,是同时执行的。
并行指的是多个任务同时运行,是多个任务同时运行在多个计算单元上,是真正的多任务同时执行。两者之间的区别,如下图所示。并发处理,多个任务共占计算单元。
并行处理多个任务同时在多个计算单元上运行。
Julia提供了一个基于消息传递的多重处理环境,允许程序在独立的内存域内同时控制并发多任务执行。这个内存空间由每个CPU单独控制,他们之间通过内部消息机制来通信。Julia的消息机制不同于MPI,并不是收发,而是类似于函数调用的机制。
并行程序的两个基础是远程引用(Remote Reference)和远程调用(Remote Call)远程引用是引用其他特定处理器的对象,这个引用可被其他任何处理器访问。远程调用是指的是一个处理进程,发起请求,用于以一定参数调用其他处理进程(或许是自身)中某个许可的函数。
Julia将进程称为worker,远程调用通过本地进程在远程worker中启动某一处理过程。比如启动一个函数。远程调用在启动以后,并不阻塞等待,而是执行远程调用后面的代码,远程调用启动以后返回一个Remote Reference r对象,远程调用结果,还需要用fetch0语句来获取。
Julia也提供了宏@spawnat,该宏实现了remotecall远程调用的功能,@spawnat有两个参数,@spawnat pid表达式,其中pid指明运行处理任务的worker id,表达式指明对远端worker运行处理任务后返回的结果要进行的计算。
3Julia并行计算实例
以一个在远端处理器创建并返回矩阵的实例,演示Julia远程调用过程。
julia>using Distributed//使用分布式系统
iulia>addprocs(4)//添加4个worker
Julia>r=remotecau(2,rand,2,2)//发起远程调用,调用远程worker创建一个随机矩阵
其中第一个参数2是远端worker id第二个参数rand是在远程work上启动的函数。
第三和第四个参数都是2,是传递给rand函数的参数,指明创建一个2x2的随机矩阵。
RemoteRef(2,1,5)//生成RenoteRef对象
其中第一个参数2是远端worker id第二个参数1发起远程调用的worker id第三个参数是为当前RemoteRef分配的id.
Julia>fetch(r)//捕获RemoteRef对象
生成的2x2随机矩阵
2x2Float64Array:
4julia与分布式大数据hadoop平台的比较
Julia从编程语言级别实现了并行计算,而分布式大数据平台也实现了并行计算,现在从性能和响应时间等以下几个方面把二者进行比较。
(1)二者实现基础是不一样的,hadoop构建了一个独立的分布式系统,julia是通过SSH方式无密码登陆远程特定的机器,并启动机器上的Julia工作进程。
(2)Hadoop有自己的文件系统HDFS,并行处理过程同时依赖于HDFS,从结构上分为Namenode和DateNode节点,iulia并行计算中,每个机器的地位是平等的,进程级别之间的消息通信,不涉及文件系统。
(3)Hadoop善于数据分分析任务,Julia善于数据处理和计算任务。
5结论
Julia在編程级别上实现了多核并行计算处理,从而能够进行大规模数据集上的科学计算,这是fortran语言所无法实现的,Julia这种并行模式也为构建基于Julia的并行分布式环境打下了基础。在软件级别上实现并行分布式环境会成为一种趋势。
[通联编辑:闻翔军]
猜你喜欢
建筑建材装饰(2016年10期)2017-01-03
文理导航(2016年33期)2016-12-19
考试周刊(2016年21期)2016-12-16
考试周刊(2016年21期)2016-12-16
新教育时代·教师版(2016年26期)2016-12-06
