
医学观察性研究设计讲座(连载二)
2020-07-04 12:34徐应军
现代养生·下半月 2020年6期
徐应军

1.3 偏倚控制
医学研究通常是以人为对象,由于人的心理反应和依从性在研究中是难以控制的,而且容易受到外界因素的干扰,因此研究的结果极易出现各种误差,如研究对象回答问题的真实性(是否如实回答问题)、对发生在过去的事件回忆的准确性(时间、数量记忆是否准确)等,如果不真实、不准确将会使研究结果系统地偏离其真实值,这种现象称为偏倚(bias)。偏倚是影响研究质量的重要因素,在研究中不可能做到完全没有偏倚,只有通过周密设计和科学处理尽量减少偏倚。识别、分析、控制偏倚,是研究者必须具备的基本功,是研究的关键技术之一。偏倚控制需要贯穿于研究的全过程,包括研究设计、实施过程、资料分析、结果评价等各个阶段。
由于研究的方法、对象、方案等一系列问题是设计阶段决定的,如果存在问题将会直接影响研究结果的真实性,而且一旦执行了设计方案,产生的偏倚许多是无法消除的,因此研究者在设计上严格把关是预防和控制偏倚的重要环节。
1.3.1 设计阶段可能产生的偏倚
1.3.1.1 选择偏倚(selection bias) 由于设计时选择研究对象的方法不当而引起的偏倚,例如利用非随机样本推论总体,或样本的依从性较差造成的无应答率偏高等。选择偏倚主要影响样本的代表性,常见的选择偏倚有:
1)入院率偏倚(admission bias):如果要研究某种疾病的特征,选择住院患者为研究对象时会出现入院率偏倚,因为各种疾病的入院率不同,也不会100%的患者都到一个医院住院,患者对医院有选择性,医院对患者也有选择性,因而在一个医院住院的患者必定是一个患该病的特殊群体,以他们为对象进行研究,显然结果是有偏性的,这就导致入院率偏倚。
2)现患病例偏倚(prevalence-incidence bias):同样的问题是研究某种疾病的特征,如果这种疾病早期部分患者死去(如急性心肌梗死患者),那么存活下来的患者就是一个特殊群体,选择存活的患者(现患病例)为研究对象,显然不能代表该病的总体情况,这就是现患病例偏倚,也称为奈曼氏偏倚(Neyman's bias)。
3)无应答偏倚(non-response bias):设计时被选定的样本中没有接受研究的个体为无应答者,如果无应答者较多,或无应答者是因为某种原因拒绝研究,那么仅凭应答者的研究结果产生结论是有偏性的。例如在人群健康普查中,身体状况较好者参与的比率低于健康状况较差者,如果按照这样的普查结果,人群的患病率将会高于实际水平。
1.3.1.2 信息偏倚(information bias) 设计时选择了不恰当的调查和检测方法导致获取的数据不准确而引起的偏倚,如非盲法调查、对比组间调查方式不一致、使用的仪器设施未经校正等。常见的信息偏倚有:
1)调查者偏倚(investigator bias):如果参与调查的调查员均与调查密切相关,希望获得某种调查结局,因此在调查中会不自觉地,或多或少地将个人的意愿表露出来,影响调查对象对问题答案的选择,致使调查数据不够真实,也称为诱导偏倚。
2)回忆偏倚(recall bias):来自研究对象对发生在过去事件的回忆主动性和准确性,例如在有关环境污染和职业危害对健康影响的调查中,研究對象往往回忆的比较主动,对细节问题也不放过,甚至夸大,导致调查到的数据不准确。
1.3.1.3 混杂偏倚(confounding bias) 在资料分析过程中,由于外界因素的干扰,使研究结果发生偏离的现象为混杂偏倚。虽然混杂偏倚出现在资料的分析阶段,但由于混杂因素是自然存在的,因此设计时可以采取措施对可疑的混杂因素进行控制,例如匹配设计、分层抽样等。
1.3.2 设计阶段偏倚控制措施
1.3.2.1 提高抽样技术 根据研究目的,选择适当的抽样方法是控制选择偏倚的重要措施。需要推论总体的调查,应以人群为基础,采用随机抽样;需要选择病例为调查对象时,尽量选用新发病例;对特殊目的的调查研究,如总结经验、教训等可选择典型样本,将目标人群局限性。
1.3.2.2 重视无应答 理论上无应答率不能超过5%,否则结果不可靠。如果无应答率较高,需要采取措施。首先是分析无应答的原因,制定补救措施;其次是分析无应答者的特征,估计无应答对结果的影响程度。如果确定无应答者是有偏性的,必须通过沟通,最大限度地调查无应答者。
1.3.2.3 采用盲法调查(blind survey) 调查时如果调查对象,或调查者不知道调查分组情况则为盲法调查,如果只有一方不知道为单盲,双方均不知道为双盲。盲法调查可以克服来自调查对象及调查者的主观因素的干扰,减少数据的偏性。
1.3.2.4 平衡调查 研究很多情况下需要设置对照,通过观察组与对照组的相互比较产生结论。在研究设计时,要保证每个调查员调查的观察组与对照组人数的比例接近,例如一个调查员调查暴露组的人数占全部暴露组的30%,那么这个调查员调查的对照组人数也应该占全部对照组的30%,这就是平衡调查。因为每个调查员对问题的理解、技术的掌握及工作的态度不尽相同,因此平衡调查可以减少对比组间人为的差别,使比较结果更趋合理。
1.3.2.5 匹配设计 是设计阶段控制混杂偏倚的有效方法。通常年龄、性别、种族、职业、经济文化水平等,是各类研究首选的匹配条件;疾病类型、病程、病情、并发症及治疗经过等,是临床研究中需要考虑的匹配条件,因为这些因素是最为常见的混杂因素。但采用匹配设计,应该符合以下要求:①因为条件限制,如时间、经费、人力等资源有限,不能开展大样本研究;②因为研究的疾病罕见,没有足够的研究对象;③匹配的条件不宜过多,除年龄、性别之外,其他因素需要慎重。
1.3.2.6 控制混杂因素 混杂偏倚是由混杂因素引起,可以通过分层分析、多因素分析加以调整与控制,然而前提是设计时必须将混杂因素列为调查因素,这样才能在调查中获得混杂因素的信息,才能够通过适当的统计学方法进行控制。因此在设计调查因素时不仅仅关注假设因素,而且要充分考虑潜在的混杂因素。
2 现况研究
现况研究(cross sectional study)是在特定时间内对特定人群中某种健康问题的状况进行研究的一种方法。健康问题的状况可以是疾病的表现形式、危害程度、分布规律,以及影响分布的因素等。由于现况研究揭示的是目前的状况,因此研究工作必须在一个短时间内完成,相当于描述一个时间断面上存在的事件,因此也称它为横断面研究。
2.1 原理与特性
2.1.1 基本原理
现况研究是按照预先设计好的问卷,在人群中同时收集有关疾病(或某个事件)及其相关因素分布状况的资料,比较不同因素状态下(因素的有无,或因素的多少)疾病的患病率(或事件存在的程度),如果比较结果具有统计学意义,则认为分析因素对疾病或事件有影响,由于因素和疾病(事件)在调查中同时被看到,并不能区分时间的先后顺序,因此该因素只能被认为是疾病病因的一个重要线索,或是因果关系研究的假设。
2.1.2 主要特性
2.1.2.1 观察法研究 现况研究中所有调查的因素是人群固有的或已经存在的,如年龄、性别、民族、职业、文化程度、生活习惯,以及患病状况等,无人为干预因素。
2.1.2.2“因”“果” 同时观察到 研究的因(因素)及果(事件)的资料在调查中被同时收集到,无法辨别时序关系,因此现况研究不能确定因素与事件的因果关系,只是探索性研究。
2.1.2.3 描述性研究 通过描述疾病(事件)在自然状态下(无人为干预)的分布特征,发现影响分布的因素,这些因素将是建立因果关系假设的重要线索。
2.1.2.4 不专设对照组 现况研究在设计时不专门设置对照组,而是根据研究人群内固有因素的暴露程度分组进行对比分析,实际上现况研究采用的是内对照设计。
2.2 研究类型与目的
2.2.1 研究类型
2.2.1.1 普查(census) 普查是将特定范围人群内全部成员均作为对象进行的调查,特定范围可以是某个地区、某个单位,或者是具有某种特征的人群,如患有某种疾病、具有某种症状、从事某种活动等等。例如对某市全部钢铁高温作业工人进行的健康调查。普查的优点是确定观察对象比较简单,并且不存在抽样误差,所观察到的现象来自每个个体,可以完整描述所研究内容的全貌,研究结果具有代表性。普查的缺点是需要调查的对象多,难以控制漏查,同时参与调查的人员多,工作不易做细,系统误差较大。
普查通常用于:①建立人体正常值范围或临床诊断标准,例如人群各项指标的生理常数等;②了解人群健康水平,例如儿童生长发育状况、某种疾病的人群患病状况等;③早期发现病人,许多疾病如果能够早期发现,可以使患者得到及时治疗,提高疾病的治疗效果,如对某些恶性肿瘤的普查等。
2.2.1.2 抽样调查(sampling survey) 抽样调查是通过抽样的方法,在特定范围人群内抽取一个样本进行的调查研究,多数情况下希望以样本的调查结果代表全人群的实际,即以样本推论总体。
抽样调查与普查对比,具有省时、省力,可以集中精力将调查工作做深、做细等优点。但抽样调查的设计和资料分析相对复杂,同时抽样误差是不可避免的,调查的结果能否推论总体,取决于样本的代表性和足够的样本量。
2.2.2 研究目的
2.2.2.1 描述疾病特征 認识疾病特征是疾病防治工作的基础,然而在自然状态下疾病的一些特征存在短期波动或长期变异,表现为疾病的临床特征、危害程度、患病率、人群的易感性、分布状态、影响因素等在不同时期会出现变化,例如猩红热在20世纪30年代以前,临床表现凶险,病死率高,但随后逐渐温和,现在几乎没有特征性的临床表现,也未见病死者。因此连续地在人群中进行现况研究,描述疾病特征,观察变化动态,可及时发现问题,有利于正确指导疾病的防治工作,也可以对已经采取过的防治策略、措施的效果进行评价。
2.2.2.2 探索病因线索 描述疾病的分布特征是现况研究的一项重要任务,那些影响分布的因素就是重要的病因线索。例如早期人们在描述人群肺癌分布特征时发现,吸烟人群的肺癌死亡率明显高于非吸烟人群,因此吸烟与肺癌有关的假设被提了出来。
2.2.2.3 确定高危人群 高危人群是指特别容易受到某种疾病威胁的人群,通常是具有发生某种疾病危险因素的人群。确定高危人群有利于疾病的预防控制。例如高血压是脑卒中的危险因素,可以将现况研究中发现的高血压患者确定为脑卒中的高危人群。
2.2.2.4 提供卫生决策依据 通过对社区人群的健康及卫生服务状况的现况研究,可以发现该社区人群目前存在的主要公共卫生问题,这是卫生管理和研究部门制定决策的重要依据。
2.3 研究设计与实施步骤
2.3.1 设计思路及技术要点
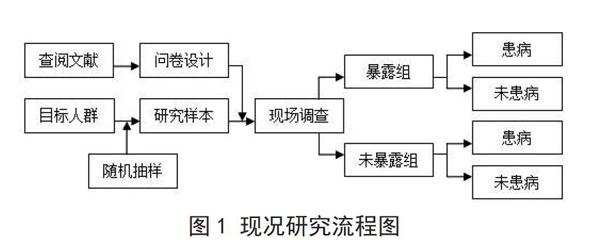
2.3.1.1 技术路线 现况研究过程的主要环节及流程见图1。
2.3.1.2 技术要点
1)抽样:现况研究的目的在于了解事物的本质,揭示客观现象和规律,是进一步深入研究的基础和方向,因此研究结果的真实性是衡量研究质量的重要指标之一。在抽样调查中,随机抽样是保证研究结果质量的一项关键技术。需要注意的是,随机抽样是非常具体的可操作的方法,而不是一句空头的口号。在设计报告中,或发表的论文中,不能简单的说用随机的方法选取样本,而应该详细说明随机的具体实施方法,如果样本不是随机抽取,而说成随机是不科学的,需要避免。非随机的样本也是可以进行研究的,但研究者必须认识到和说明这样研究的意义和局限性,实事求是是科学的态度。
2)样本量:描述客观事实,揭示自然规律是现况研究的主要目的,这不仅要求研究的样本有代表性,能够反映客观实际,而且必须有足够的样本为保障。现况研究分析的重要指标是患病率,按照大数稳定的原理,调查的样本数量越大,所得到的率就越稳定,受个体差异和偶然机会的影响就越小;另外,抽样误差是随着样本量的增加而减小,当样本量趋向无穷大时,抽样误差为0。所以大样本的研究可以降低抽样误差,提高研究结果的真实性和可靠性。在研究的设计时,必须对所需要的样本量进行严格测算,在保证统计学检验所需的样本量基础上,保留余地地增加研究的样本量。
3)时间限制:现况研究是为了揭示现时状况,发现当前的问题,为确定下一步研究方向和内容、制定工作计划和决策提供科学依据,因此研究的时间不能拖得过长,特别是对环境和社会因素敏感问题的调查,更需要在短时间内完成。
2.3.2 设计与实施步骤
2.3.2.1 选题 现况研究是对一个问题进行系统调查分析的起步阶段,通常是针对新问题,包括新出现的问题、以前没有研究过的问题,或以前研究过又出先新情况的问题。因此当实际工作中发现某个问题需要解决,或者文献报道的某个问题本地也存在,但以前对该问题了解甚少,可以立题开展调查研究。
2.3.2.2 确定研究目的和意义 如果研究的题目选定,就必须明确研究的目的和意义,包括立题的依据、拟解决的问题以及解决问题的实际意义。
2.3.2.3 选择研究对象 结合研究目的、基础条件、可行性确定研究对象的特征、范围。
2.3.2.4 样本量估计 影响抽样调查样本量的因素主要有:①研究事件的发生频率(P):发生的频率高,所需的样本量小;②研究结果的精确度(容许误差d):对研究结果的精确度要求越高,样本量越大,通常d=10%P,即容许研究误差为10%;③检验的显著性水平(α):α取值越小,需要的样本量越大,通常选择α=0.05为检验的显著性水平,如果选择α=0.01为检验的显著性水平,则需要的样本量将明显增大。
当上述各项条件确定后,样本量可以根据公式估计,例如研究目的是观察某种疾病人群中的患病率,则可利用下式估计:
n=400×q/p 式(1)
式中n是当α=0.05为检验的显著性水平,容许误差d=0.1P时,所需要的样本量;P为所要研究事件预期的发生频率,可以根据预调查结果估计,或根据文献类似研究报道的结果估计;q=1-p。
例:根据文献报道我国成年人群乙型肝炎表面抗原携带率在10%左右,为了解某人群乙型肝炎表面抗原携带情况,按照常规设计(α=0.05,d=0.1P)应抽取多少人?
此例p=0.10;q=1-p=1-0.10=0.90,代入上式得n=3600(人),即该研究应该至少抽取3600人。
研究目的和指标的性质不同选用样本量估计的公式也不同,这里所介绍的是一个特例。此外也可以查阅样本量估计专用表,或利用计算机软件估计,具体方法见本书有关章节。
2.3.2.5 抽样方法 现况研究应尽量选择随机抽样方法,增强研究结果的代表性。但在实际研究中,有时也可以采用非随机的方法,如典型抽样等,或将某年、某医院的患者作为研究对象。非随机方法具有可行性好,便于操作的优点,但研究结果的代表性较差,研究者在下结论时或使用研究结果时应慎重。
2.3.2.6 拟定问卷 现况研究中大部分因素与疾病(事件)是同时观察到的,如疾病的诊断结果和生理生化检测结果,但有些因素也需要通过回忆获得,如过去的生活习惯和经历等。虽然现况研究不能区分“因”与“果”的时间顺序,但在制定问卷时仍要考虑因素的时效性,即暴露的时间。
2.3.2.7 现场调查与资料收集 调查员在进入现场前需要经过严格训练。负责采访调查的人员需要熟悉问卷内容、调查方法、记录方法,掌握调查技术和标准等;负责临床检查的人员,需要准备好设备,熟悉操作技术和诊断标准等;负责实验室检测的人员,需要准备好采样器材、熟悉采样和样品保管、运送技术等;负责摘录历史数据的人员,需要熟悉资料的来源,摘录内容和记录方法等。
2.3.3 资料的整理与分析
2.3.3.1 资料录入与整理 将经过核实和整理过的每份问卷数据录入计算机,建立数据文件。对定量数据进行正态性分析,非正态分布的数据需要进行适当的数据转换,如对数转换等,再分析是否符合正态分布,如果转换后仍然为非正态分布,则这类数据将采用非参数分析。
2.3.3.2 列制分析表格 将计划分析的内容,根据统计学的要求列制成分析表格,现况研究最基本的分析表格形式见表1,如果数据为定量的见表2。
2.3.3.3 计算分析指标 根据研究目和数据的性质,选择恰当的统计分析指标,现况研究最常用的指标是事件的阳性率,例如疾病的患病率、现患率、阳性率、检出率或死亡率等,因此现况研究也被称为患病率研究(prevalence study)。定量的资料可以计算均数、标准差等重要参数,见表2。
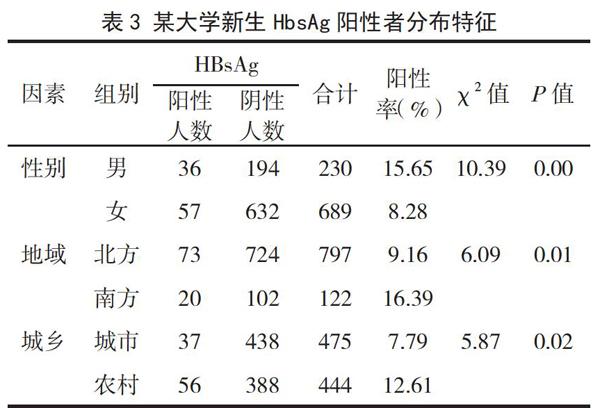
2.3.3.4 描述分析 现况研究分析的重点是描述事件的“三间分布”,即事件在人群(人间)、时间、地区(空间)的分布特征。例如某大学在新生入学时进行了HbsAg携带率的普查,分析新生中HbsAg阳性的分布特征,结果表明,HbsAg携带率男性高于女性、南方高于北方、农村高于城市,显著性检验具有统计学意义,见表3。
2.3.3.5 统计学检验 不同组间(如暴露组与非暴露组,或不同暴露程度组)比较时需要进行统计学检验方可作出有无意义的结论。通常单因素分时,率的比较采用卡方检验,均数比较采用t检验或方差分析,见表3。
2.3.3.6 其他分析 在不同地区和人群进行率的比较时,需要计算标准化率;对个别混杂因素控制可采用分层分析方法,需要同时控制多個混杂因素时可采用多因素分析方法;对定量或分等级的数据可进行量效关系或线性趋势分析。
2.4 注意事项
2.4.1 样本代表性
当无法对总体进行普查,而且需要对总体进行推测时,必须采用抽样调查。样本结果能否真实反映总体特征,能否代表总体就是样本的代表性。现况研究的样本代表性与抽样技术和样本量有关,按照随机的原则抽样,适当增加样本量均可提高样本的代表性。如果条件所限,确实无法进行随机、大样本调查,现况研究的结果就不能用来推测总体,研究的价值和意义将受到限制。
2.4.2 偏倚
控制偏倚是保证研究质量,提高结果真实性和可靠性的另一项关键技术,现况研究中偏倚主要有无应答偏倚、测量偏倚、调查者偏倚、混杂偏倚等。偏倚的控制应当从设计开始,因为一些偏倚只有提前认识到,采取措施防止其发生,才能有效控制,否则一旦发生了将无法纠正,例如样本选择不合适,或仪器设备有故障未及时校正,或操作人员技术不过关,导致测量数据不准确等。在设计时,要认真分析研究过程中的每个环节,找出可能出现偏倚的细节,并针对偏倚的特性制定出防范措施。同时,研究中要评价措施的效果,估计偏倚的控制程度。
2.4.3 患病率
患病率(prevalence)是现况研究主要的分析指标,也称为现患率。现况调查时的患病率的计算公式为:
患病率=调查时发现的患者人数/调查人数(公式2)
患病率与发病率的概念明显不同,后者的分子仅仅是调查期间新发生的患者,只有当疾病的病程很短(急性病)或病死率很高时二者比较接近,因此在使用时要注意相互区别。相对危险度是反映暴露因素与疾病之间联系强度的重要指标,是暴露组的发病率与非暴露组发病率之比,因此在现况研究中,除了极个别情况下,是不能计算相对危险度以及近似值OR。
2.5 现况研究实例
近些年来,我国社会经济的迅速发展,改变着人们的生活水平、生活习惯和生活方式,致使人群的疾病谱也出现重大变化,特别是在经济发达的城市,传染性疾病的发病率不断下降,而以肥胖、糖尿病、高血壓、高血脂为代表的代谢综合征的患病率逐渐升高。为了解新形势下,代谢综合征的人群分布特征及其影响因素,某大学医学院的在校学生,以北京市某区18岁以上常驻居民为目标人群,开展了现况调查研究。
2.5.1 设计要点
2.5.1.1 样本量估计 根据预调查可知,该地区成人代谢综合征标化患病率为32%左右,按照常规设计,取α=0.05为检验的显著性水平,容许误差d=0.1P,则:
n=400×0.68/0.32 =850(人)
因为影响分布的因素较多,以及无应答的存在,所以按照计算样本量的10倍选取样本,计划完成8500例。
2.5.1.2 抽样方法 采用多级分层整群抽样的方法选择研究样本。
1)分层:首先分为城区和郊区两个层,再在各层内分为东西南北中5个区域,以各区域内的社区卫生服务中心作为调查点。
2)多阶段分层整群随机抽样
第一阶段:将各区域内的社区卫生服务中心编码,采取抽签的方法各抽取1个服务中心为样本点,共计10个点。
第二阶段:以每个样本点所辖的居委会为单位编码,仍采用抽签的方法抽取1个居委会,如果该居委会符合调查的对象不足900人,则继续抽取下1个居委会,至达到900人为止。
2.5.2 现场调查
2.5.2.1 问卷调查 问卷调查由学生负责完成,问卷内容包括:①一般情况:包括年龄、性别、民族、文化程度、婚姻状况、职业、人均收入等内容;②家族史及既往史:包括家族史及个人既往史等;③生活方式和行为习惯:包括吸烟、饮酒、食用盐摄入量及体力活动等方面的内容;④精神及社会因素:包括生活、工作等家庭及社会方面影响因素等。
2.5.2.2 体格检查 问卷调查的同时采用标准的方法测量每个对象的身高、体重及血压。
2.5.2.3 实验室检测 由该卫生服务中心的专业人员负责采血,由该区医院体检中心负责血脂、血糖等生化指标的检测。
2.5.2.4 诊断标准 由该区医院体检中心专业医师按2004年10月中华医学会糖尿病学分会推出的适合中国人群特征的代谢综合征诊断标准来诊断。
2.5.3 结果分析
2.5.3.1 代谢综合征人群分布特征 该人群代谢综合征粗患病率为18.7%(标化患病率17.7%),男性20.7%(标化患病率22.1%),女性16.9%(标化患病率17.7%);总患病率男性高于女性(χ2=20.15,P<0.001),但65岁后,女性高出男性。男性与女性人群代谢综合征患病率均呈现随年龄增长而升高的趋势,见表4。
2.5.3.2 代谢综合征城郊分布特征 代谢综合征患病率城区人群为17.8%(标化患病率16.8%);郊区为20.4%(标化患病率20.0%),郊区高于城区,见表5。
2.5.3.3 代谢综合征影响因素分析 此次调查的代谢综合征影响因素涉及人口学及社会经济地位、生活方式及行为习惯、家族史及既往病史、家庭及社会因素、精神及心理因素5大类,30余项。
单因素分析结果发现具有家族史、过量饮酒史、既往病史、缺乏体育锻炼的人群代谢综合征的患病率升高,具有统计学意义,其他因素均无统计学意义,见表6。
2.5.4 研究结论
该人群代谢综合征患病率随年龄增加而升高,总体男性高于女性,但65岁以后女性患病率急剧升高,超过男性,这种现象应该引起重视。研究结果还提示,郊区人群患病率高于城区,与其他人群研究结果不一致,原因有待差查明。影响该人群代谢综合征的主要因素是具有家族史、过量饮酒史、既往病史、缺乏体育锻炼,是今后健康教育的重点。
3病例对照研究
病例对照研究(case control study )是分析性研究方法之一,是探索事物间相互关系和关系密切程度的重要方法,是较现况研究更深入一步的研究类型。由于病例对照研究良好的可行性和所提供研究证据的力度较高,因此在实际工作中,倍受研究者青睐。有关病因学领域,利用病例对照研究发表的论文举不胜举,经典的范例是Doll和Hill关于吸烟与肺癌关系的病例对照研究,以及Herbst关于年轻女性阴道腺癌的病例对照研究,在这个例子中,Herbst仅仅用了8例患者和32例对照为对象,得出了母亲在妊娠早期服用乙烯雌酚是年轻女性阴道腺癌的重要危险因素的结论,显示出这种方法独到的优越性。
3.1 原理与特性
3.1.1 基本原理
病例对照研究是在目标人群中选择一组已经确诊的某种疾病的患者为病例组,再在未患该病的人群中选择一组与病例组具有可比性的个体为对照组,根据回顾,调查两组过去各种可能的危险因素的暴露史,比较两组间各个危险因素的暴露比例,如果两组之间某因素的暴露比例差异具有统计学意义,则认为该因素与疾病间存在统计学联系,在排除了误差和偏倚的影响后,依据相关的专业知识,做出某因素或某些因素为该病的危险因素的推斷。
病例对照研究是从疾病开始,追溯原因,从因和果的时序性来看是由“果”到“因”的研究,故也称为回顾性研究(retrospective study)。当某个问题的基础已经调查清楚,并提出了明确假设,这时可以考虑选择病例对照研究进行假设的检验。
3.1.2 主要特性
3.1.2.1 观察法研究 研究的因素是研究对象固有的或已经存在的,通过询问、体检、实验室检测、查阅历史资料获得。
3.1.2.2 分析性研究 病例对照研究是根据病例组与对照组间某些因素的暴露程度有无差别,分析因素与疾病之间的关系类型,获取有无关系的证据,达到探索和检验病因假设的目的。
3.1.2.3 回顾性研究 病例对照研究是由“果”至“因”的,因此病例对照研究结果不能证明因与果的时序关系,这就决定了病例对照研究结果不能得出因果关系的推论,而只是危险因素的推论,是对因果假设的初步检验。
3.2 研究的类型
3.2.1 按照病例与对照是否匹配分类
3.2.1.1 不匹配设计 也称为成组设计,是在目标人群中,分别选择一定数量的病例与对照组成病例组与对照组,一般要求对照组的样本量大于或等于病例组。
这种设计的优点是相对比较简单、对照容易选择、资料便于处理、信息丢失较少,适用于病例较多,或研究成本较低的大样本研究。如果条件满足,是设计时首先考虑选择的研究方法。
3.2.1.2 匹配设计 也称为配比设计,匹配(matching)设计要求依据病例的某些特征选择对照,即对照在某些特定的因素或特征上与病例保持一致。匹配的目的是使病例与对照之间保持较好的可比性,排除某些因素对研究结果的干扰作用。例如以性别为匹配因素,可使病例组与对照组的性别构成相同,在结果分析过程中性别不再起任何作用,也就避免了由于两组间性别构成不同对结果造成影响,使结果更容易解释。根据匹配因素在资料分析中失去作用的原理,匹配设计通常也作为控制混杂因素的有效方法。另外匹配设计可以提高统计学效率,即达到同样的统计学检验结果,匹配设计所需要的样本量相对较小,这是选择匹配设计的主要目的。
(1)匹配设计类型:匹配设计可分为频率匹配和个体匹配两类。
1)频率匹配(frequency matching):按照某个特征在病例组中所占的频率,选择对照组。例如病例组中男性占65%,那么对照组中男性也必须占65%。实际上频率匹配是介于成组设计和匹配设计之间的一种类型,即按照成组设计选择病例组,按照条件选择对照组。
2)个体匹配(individual matching):按照每个病例的某些特征选择与之匹配的对照。如果每个病例均选1个与之匹配的对照,称为1:1匹配的病例对照研究,或配对研究(pair matching);如果每个病例均选2个对照称为1:2,依此类推有1:3,1:4,最多是1:4。增加对照数量是为了提高病例信息的使用效率,病例所含信息的使用效率随对照数量的增加而增加,但对照数在4个以上效率增加不明显,因此最多4个。如果在一次病例对照研究中,每个病例匹配的对照数不一致,例如有1个的,也有2个或3个、4个的,称为1:R可变匹配设计。每个病例与之匹配的对照组成对子,是匹配设计资料分析的基本单位。在Herbst关于年轻妇女阴道腺癌的经典研究中,采取的是1:4匹配设计,8个病例与32个对照组成了8个对子。
(2)匹配因素(匹配条件):是选择对照的限制因素,即要求对照与病例保持一致的因素。匹配因素在设计中一旦确定,就应该严格按照要求选择对照。理论上匹配因素越多,对照组与病例组一致性越高,两组的可比性越好,但实际操作中匹配的因素太多有如下缺点:
1)增加了研究的难度:如果匹配的条件过多,合适的对照不易找到,增加了研究的难度,甚至使研究无法进行。
2)降低研究的信息量:因为一个因素一旦被确定为匹配因素后,这个因素就不再起任何作用,由该因素所含有的任何信息均不能参与研究,也就无法分析该因素与疾病的关系,以及与其他因素的交互关系,降低了研究的效率。
3)匹配过头错误(over-matching):有些因素之间存在内在联系,如果一个因素被控制,与该因素有关联的因素实际上也被控制了,例如饮酒与吸烟习惯通常是密不可分的,如果我们拟研究吸烟与某种疾病的关系,将饮酒习惯作为匹配因素,就相当于吸烟也被匹配了,吸烟与疾病的关系就会被掩盖难以发现,即使被发现二者之间的关联程度也将被低估,这种由于过度匹配导致的掩盖或将降低研究因素的实际作用的错误称为匹配过头错误。
匹配的因素过多不行,但过少达不到匹配的目的,一般在实际操作中选4个左右为宜。那么什么样的因素可以作为匹配因素呢?应该是已知的混杂因子,或具有潜在可能的混杂因子。通常年龄、性别是必须要考虑的因素,因为在多数研究中年龄与性别均是混杂因子,其他因素的选择可依据研究的具体需要,例如在临床研究中患者的病情、病程;在职业人群研究中工种、工龄等是重要的混杂因子。
(3)匹配设计的适用范围:匹配设计较成组设计复杂、对照选择困难、资料处理繁琐(1:1配对设计除外)、容易丢失信息,因此一般多用于不易开展大样本研究的情况,如病例较少、研究成本较高、研究的投入不足等。
3.2.2 按照病例的来源分类
1)以医院为基础(hospital based)的病例对照研究在医院的门诊或住院的患者中选择病例进行的病例对照研究,这种研究病例选择简单、成本低、可行性好,是许多学生做课题时首选的研究方法。但是病例缺乏代表性,因为不是每个患者均到医院就医,容易出现选择偏倚。Herbst关于乙烯雌酚与年轻妇女阴道腺癌的关系研究,就是典型的医院为基础的病例对照研究。
2)以人群为基础(population based)的病例对照研究在社区人群中选择病例进行的病例对照研究,这种研究代表性好,但工作的难度很大、研究成本高。
3.2.3 衍生类型
是将传统的病例对照研究与其他类型研究方法结合派生出的一些新的病例对照研究类型。
3.2.3.1 巢式病例对照研究(nested case control study) 在队列研究的基础上,将随访结束时所观察到的全部发病者作为病例组,再在队列中选择一定数量的未发病者作为对照组,进行的病例对照研究。
巢式病例对照研究是将队列研究设计和病例对照研究设计结合起来进行的研究,因此同时具有两种设计的特征,其优点为:
1)前瞻性:隊列研究是由暴露开始随访至结局出现,是先“因”后“果”的研究,巢式病例对照研究应用的是队列研究的暴露与结局事件,也是先“因”后“果”的,在因果时序关系上为前瞻性的。因此,巢式病例对照研究克服了普通病例对照研究不能判断“因”与“果”时序性的缺陷,极大提高了所获得的病因学证据的力度。
2)可比性:巢式病例对照研究的病例与对照来自同一个队列人群,病例组与对照组同质性好,可以提高组间的可比性,降低选择偏倚。
3.2.3.2 病例队列研究(case-cohort study)在队列研究的起始,随机抽取一个样本作为对照组,在随访结束时将全部新发病人作为病例组,进行的病例对照研究。病例队列研究也是队列研究与病例对照研究方法的结合,与巢式病例对照研究的不同点是:①对照是随机的,巢式病例对照研究是在队列研究结束时,按照匹配条件在未发病人群中选定的,而病例队列研究的对照组是在队列研究开始随机选定的,虽然不一定与病例匹配,但能够较好地代表产生病例的源人群的特征;②对照是在病例发生前选定的,而巢式病例对照研究是在病例发生之后选定的;③对照中含有病例,因为病例队列研究的对照是在队列建立时选定的一个随机样本,随访结束时样本中也有出现病例的可能,但为了保持样本的完整性,病例是不剔除的。对照中含有病例在某种程度上会降低研究结果的灵敏度,低估暴露与疾病的关系。
(未完待续)
作者单位:063210河北省唐山市,华北理工大学
猜你喜欢
健康体检与管理(2022年2期)2022-04-15
百花洲(2018年1期)2018-02-07
智富时代(2018年12期)2018-01-12
智富时代(2018年12期)2018-01-12
瞭望东方周刊(2017年45期)2017-12-08
中学生数理化·高一版(2017年2期)2017-04-25
诗潮(2017年2期)2017-03-16
数学学习与研究(2017年3期)2017-03-09
金色年代(2016年4期)2016-10-20
中老年健康(2016年7期)2016-07-29
