
异构多核人工智能SoC芯片的低功耗设计
2020-07-01 05:44唐芳福张志国龚永红
航天控制 2020年2期
颜 军 唐芳福 张志国 韩 俊 龚永红
珠海欧比特宇航科技股份有限公司,珠海519080
0 引言
人工智能是引领未来的战略性产业,是我国科技领域重要的发展战略[1],而人工智能(AI)芯片作为整个人工智能领域的关键技术环节,是我国人工智能产业的基础,是实现人工智能突破的重要关卡。
人工智能芯片主要解决的是对深度学习算法、卷积神经网络算法、自然语言处理(NLP)等的运算加速问题,需要具备足够大的算力。对于导引头、视频处理、遥感大数据等实时应用,通常会需要芯片提供TOPS级的运算能力,以智能导引头应用常见的YOLO V3算法为例,一个416×416图形输入理论上的计算量为0.3TOPS左右,导引头应用通常需要高于每秒30帧的处理速度,可知对处理器算力的要求为:不少于9TOPS。
由于摩尔定律的限制,常规的提高主频的做法收效甚微。技术上,通常采用异构多核的架构来搭建SoC芯片,来提高整个SoC芯片的算力。
但算力的增加往往也意味着功耗的增加,而嵌入式多核处理器SoC芯片首先需要解决的就是在保证算力的情况下,功耗必须足够低。低功耗设计是一个系统工程,包含了电路级、结构级、算法级和操作系统级等多个方面的内容,需从多个方面进行综合性考虑[2]。而芯片的设计需要遵循平衡设计原则,需要在芯片的复杂度、内部结构、性能、功耗、扩展性等各个方面做一定的权衡,在设计过程中要坚持从整体结构的角度去权衡各个具体的结构问题。
1 玉龙810芯片设计指标、结构及应用
欧比特嵌入式人工智能处理器芯片玉龙810,聚焦于前端图像处理和信号处理,具有对深度学习、神经网络算法的加速处理能力,算力要求达到12TOPS、峰值功耗要求控制在5W之内。
芯片内部采用标准AMBA3.0总线协议的AXI总线,能够实现SPARC V8 CPU处理器[3]、GPU及NNA等异构多核处理器的片内集成,如图1所示。芯片采用FD-SOI生产工艺,该工艺具有对单粒子锁定(SEL)天然免疫的特点;芯片外设接口丰富,具有JPEG2000编码器、CameraLink数据接口、RapidIO总线接口、1553B总线接口[4]等航空航天专用处理单元和接口。
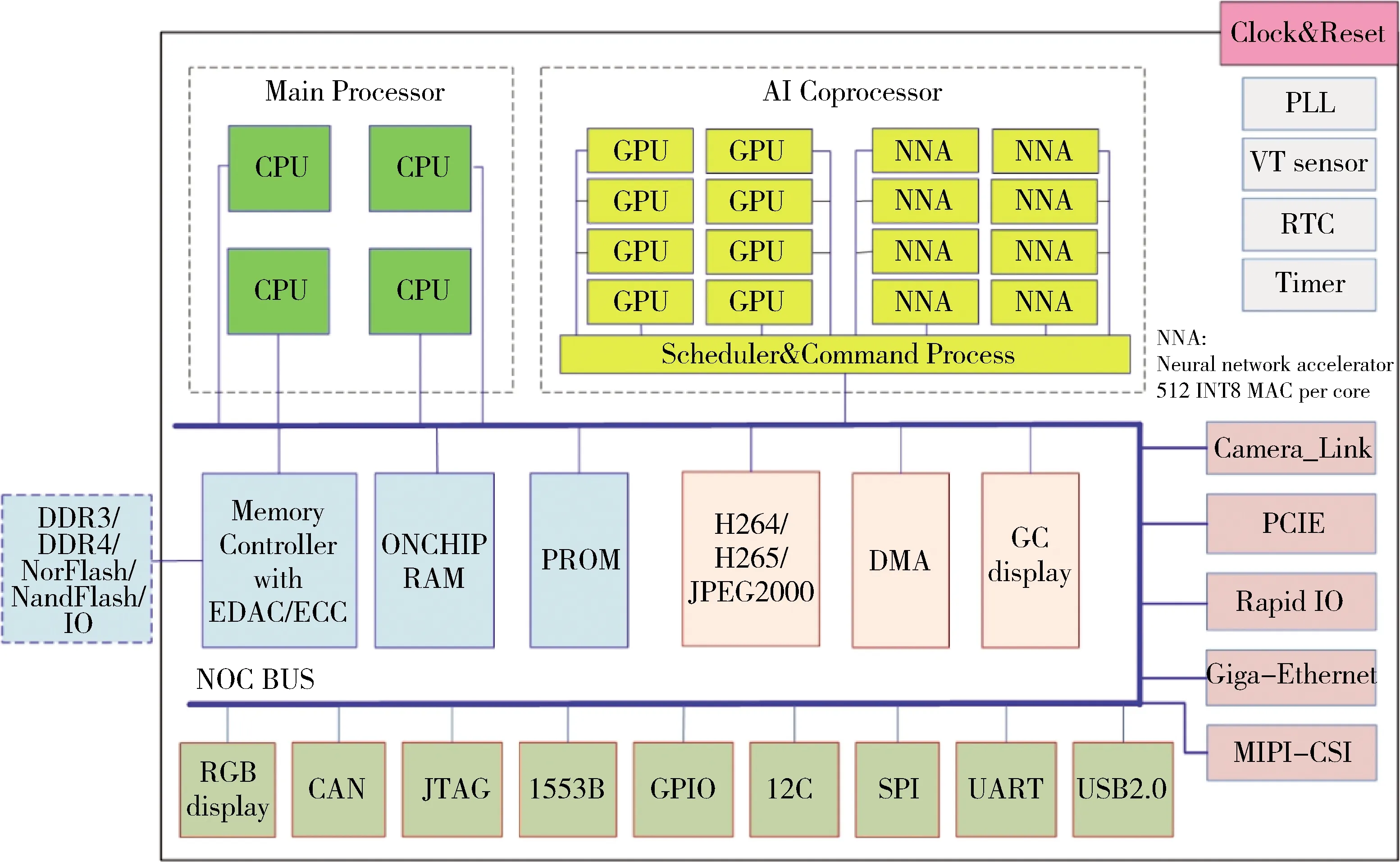
图1 玉龙810 SoC芯片结构框图
芯片配套的软件开发框架中包含模型转换工具、软件开发环境等,能够实现与TensorFlow,Caffe等主流深度学习工具软件框架的无缝对接,支持绝大多数主流的深度学习网络模型,如YOLO、SSD、RESNET、VGG、FastCNN等,同时支持用户自定义网络模型。
玉龙810人工智能芯片的典型应用包括:
1)星上在轨情报提取:卫星上运行人工智能算法,一边采集数据一边在轨实时提取情报信息,实时下传情报,大大提高情报获取的效率;
2)航天器在轨健康管理:航天器运行过程中,监测、采集运行数据,通过人工智能算法,自主完成故障分析、故障推理、故障处置以及故障预测,大大提高航天器的安全性;
3)飞行器智能制导:飞行器导引头使用人工智能芯片,运行人工智能算法,可以有效提高目标识别、目标跟踪的精度,并且通过人工智能技术有效排除诱饵干扰,提高飞行精度。
2 玉龙810芯片关键技术
2.1 适合超大数据吞吐量异构多核总线技术
玉龙810芯片内部功能模块通过片内AXI3.0总线互联。AXI3.0具备高带宽、高传输速率性能[5],其主要特点是:
1)单向通道体系结构。信息流只以单方向传输,简化时钟域间的桥接,减少门数量;当信号经过复杂的片上系统时,减少延时。
2)支持多项数据交换。通过并行执行猝发操作,提高数据吞吐能力,可在更短的时间内完成任务。
3)独立的地址和数据通道。地址和数据通道分开,能对每一个通道进行单独配置、优化,能根据需求控制时序通道,将时钟频率和效率进行最优配置。
芯片内部SPARC CPU是AXI总线上的主设备;AI协处理单元作为也是AXI总线上的主设备,可以读写任何从设备的数据,但同时受CPU内核控制。总线上的从设备为:片内外设、片上存储器、片外存储器、片外IO等,这些从设备统一编址,被各处理器核心平等共享。总线控制器负责对总线访问进行仲裁和管理,仲裁管理逻辑和算法包括:固定优先、总线锁定、定时释放等。可通过对寄存器的设置选择仲裁管理逻辑和算法。

表1 异构体系中模块分配列表
2.2 AI算法及对超大数据的运算支撑技术
芯片主要通过GPU核和NNA核来处理AI算法及超复杂数据运算,芯片内部配备了8个GPU核、8个NNA加速器核。其中GPU核由标准shader core构成,可计算半精度、单精度、双精度浮点运算,也能处理定点运算;每个NNA单元由768个乘累加器(MAC)构成,可进行8位或16位定点运算,8个NNA共同组成了6144个庞大的硬件计算阵列,在1GHZ主频的条件下可以提供12TOPS的定点运算算力。

表2 AI协处理器性能指标
卷积神经网络(CNN)一般由卷积层、池化层、全连接层等组成,卷积层参数量小,计算量大,卷积运算在整个网路中的计算量占比一般超过80%;NNA核可以在1个或几个周期内完成大规模矩阵乘运算,从而实现对卷积层的加速。GPU核使用浮点运算,可用于计算池化层、全连接层等,最大程度地保证系统精度。各层的分配由编译器事先指定,运行时GPU和NNA各自处理分配给自己的网络层,互不干扰。AI协处理器除了GPU核和NNA核之外还包括:AXI接口单元、内部RAM、Cache单元等,各部件协同工作,组成了一个完整、高效的处理子系统,也构成了对AI算法及超大数据提供高速算力的异构多核SoC架构。
2.3 低功耗优化技术
通过对各IP核的功耗参考数据的分析,可以得到芯片各IP核的理论功耗值,如表3所示。
如表3统计,如果功耗不加以控制,当主频在1GHz所有模块都通电运行的典型情况下,整个芯片的功耗将达到8.83W,芯片功耗大,其弊端是:能源消耗大、芯片温度上升快、芯片寿命短。为了满足设计指标,整个芯片的功耗最好控制在5W以内。玉龙810芯片项目试图通过时钟门控、UPF等技术来降低芯片整体功耗。

图2 AI协处理单元框架

表3 各IP核理论功耗值
3 低功耗设计及实现策略
CMOS电路中的功耗由电路翻转时产生的动态功耗、P管和N管同时导通时产生的短路功耗以及扩散区和衬底之间的反向偏置漏电路引起的静态功耗三部分组成[6]。
通常情况下静态功耗占总功耗的1%以下,系统非长时间处于休眠状态,则可以忽略不计。短路功耗在整个CMOS电路功耗中占比较小,与晶体管的转换速度有关,转换速度越快,其所占比例越小,短路功耗占总功耗的平均比例为10%左右。动态功耗占总功耗的比例约为70%~90%,而低功耗设计主要目的就是通过各种手段,实现降低动态功耗的数值[7]。
低功耗设计是一个系统的问题,需要在设计的各个层次上发展适当的技术,综合应用不同的设计策略,达到在降低功耗的同时维持系统性能的目的。研究证明在不同设计层次上的优化工作对功耗的改善程度不同,如表4所示,设计层次越高,改善效果越好[8]。

表4 设计层次与改善程度关系表
低功耗设计主要的策略有:
1)权衡面积和性能,使用并行、流水化和预计算等方法,用面积或时间换取低功耗;
2)关闭不用的逻辑和时钟;
3)使用专用电路代替可编程逻辑;
4)使用规则的算法和结构,以减少控制负荷;
5)采用新型的低功耗器件和工艺[9]。
3.1 预计算技术
预计算技术原理是:在第t个时钟周期内有选择性地预计算电路的输出逻辑值,然后在第(t+1)个周期内或其后周期中,利用预计算的结果减少电路内部的跳变行为。预计算可分为单周期和多周期2种,综合多种情况的测试结果表明2种预计算技术均可降低功耗,部分情况下可降低75%。预计算逻辑使得面积平均增加3%,所引起的延迟增加通常很小[10]。
3.2 时钟门控
时钟门控(Clock-Gating)一直以来都是降低微处理器功耗的重要手段,主要针对寄存器翻转带来的动态功耗[11]。如何更加有效地设计时钟门控,对于最大限度地降低功耗,同时保证处理器的性能至关重要。多核多线程微处理器中,多个功能部件可能不是同时工作的,对于无执行任务的功能部件就可以将其时钟关闭,减少其随时钟翻转进行多余的内部寄存器翻转,从而降低产生功耗的浪费和热量聚集。对于需要控制的寄存器,在一定情况下关闭寄存器的传输功能,阻止无用的数据进入下一级逻辑,避免引起一连串不必要的逻辑翻转,达到降低功耗的可能[12]。
芯片在设计之初,就配置了多组时钟域,每组时钟都能够单独通过独立寄存器进行PLL倍频、分频控制,同时在综合阶段,根据应用场景的不同,及各个模块布局布线不同,分别插入了一级时钟门控单元和二级模块时钟门控单元,实现了当某个模块或是模块端口信号进入静止空闲状态时,模块的时钟将自动被钳制住,从而达到降低模块内部动态功耗的目的,当然为了适应用户习惯,时钟的门控功能也可以通过软件设置为无效状态。时钟门控电路结构框图如图3所示:

图3 门控时钟树结构框图
3.3 多阈值单元库的应用
现在的工艺都会提供不同阈值Vt的单元库,同一工艺下不同阈值电压Vtcell特性不同,如表5所示[13]。

表5 Vt cell特性表
合理使用不同的Vt cell可以满足不同功耗性能需求,在使用过程中,应该优先使用SVT的cell,而后是LVT,最后万不得已的时候再使用ULVT(ULVT的leakagecurrent非常大,一般会达到SVT的四到五倍的量级)。设计工具支持mix-Vt的设计。在功耗优化的过程中,根据用户设定的Vt等价置换规则,在不影响timing的情况下,选择leakagecurrent小的cell,这样在兼顾性能的时候可以满足power的需求。
3.4 采用SEL免疫的FD-SOI工艺
芯片采用FD-SOI制造工艺,与传统的块状硅技术相较,FD-SOI能提供更好的晶体管静电特性,而埋入氧化层能降低源极(source)与汲极(drain)之间的寄生电容;此外该技术能有效限制源极与汲极之间的电子流动,大幅降低影响组件性能的泄漏电流,从而降低功耗。FD-SOI 22nm工艺功耗比28nmHKMG降低了70%,芯片面积比28nm Bulk缩小了20%,光刻层比FinFET工艺减少约50%,芯片成本比16/14nm低了20%。除了低功耗与低成本,由于FD-SOI工艺的敏感体积更小,对闩锁效应(latch-up)免疫,具备更低的软错误率,以及更好的电磁兼容性,使其更适用于高可靠应用领域[14]。
3.5 UPF技术
UPF技术是由Synopsys公司提出,基于IEEE1801标准Unified Power Format的完整低功耗实现的设计流程标准[15]。
玉龙810芯片中SPARC CPU、AI协处理器、H.264/H.265、JPEG2000以及外设的功耗较大,为了进一步降低功耗,对上述模块分别用独立电源域实现(switch-offdomain),以减小漏电,其余逻辑位于常开电源域(always domain)。采用成熟的UPF标准设计方法,如图4所示,采用不同电源给不同模块供电,插入电源开关控制,插入隔离器件,实现不同处理模块供电的单独控制方法。在某些功能不使用的时候,就把switch-offdomain关掉,这个时候,switch-offdomain里的power-gating cell的输出会呈现出一个无限接近电源(header power-gating)或者地(footer power-gating)的状态,从而理论上确保了switch-offdomain的leakagecurrent为0(由于power gating cell本身会有漏电的问题,所以0的漏电只是理论上的)[16]。
UPF原理如图4所示。

图4 UPF原理图
1)添加电源开关控制

create_power_switchPD_01_sw -domainPD_01 -output_supply_port{VDD_OUTVDD_01} -input_supply_port{VDD_INVDD} -control_port{PSW_CTRLpsw_en_01} -on_state{PSW_ONVDD_IN{PSW_CTRL}} -off_state{PSW_OFF{!PSW_CTRL}}
2)插入隔离器件

set_isolationPD_07_ISO_IN-domainPD_07-no_isolation-applies_toinputsset_isolationPD_07_ISO_OUT_LOW-domainPD_07-iso-lation_power_netVDD-isolation_ground_netVSS-clamp_value0-applies_tooutputsset_isolation_controlPD_07_ISO_OUT_LOW-domainPD_07-isolation_signalios_en_07-isolation_sensehigh-locationparent
3)综合时导入UPF文件

Load_upf top.upf
4 改进后的功耗结果
采取以上方法和策略后,采用PTPX[16]功耗分析工具,VCLP低功耗检查工具[17],并利用激励文件testbench和仿真工具VCS产生VCD波形文件,然后使用Power Compile[18]工具将VCD文件转换成SAIF文件,并设置相关参数,产生功耗报告结果如下:
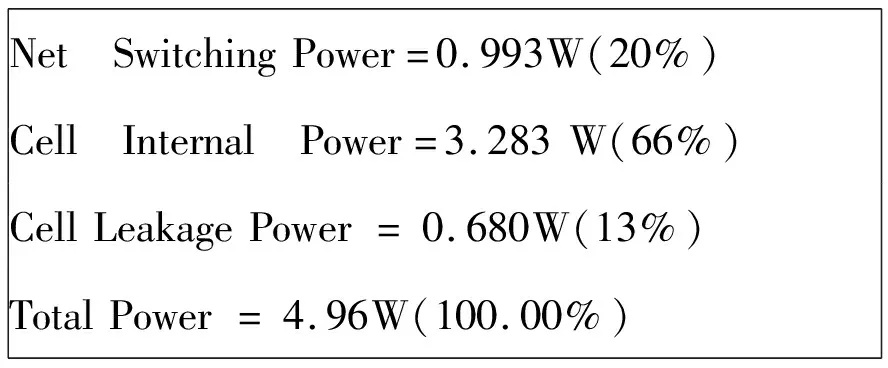
Net SwitchingPower=0.993W(20%)Cell Internal Power=3.283W(66%)CellLeakagePower=0.680W(13%)TotalPower=4.96W(100.00%)
从功耗报告可以看出,芯片整体功耗降低到了约4.96W,达到设计指标。同时通过仿真结果可以看到,芯片的处理能力没有降低,主频在1GHz,浮点处理能力64GFLOPS,定点处理能力12TOPS,芯片最关键的能耗比指标为2.4TOPS/W。
5 结论
功耗是AI SoC芯片的重要指标,功耗过高将极大地限制AI SoC芯片的应用。玉龙810人工智能芯片通过时钟门控、UPF等技术成功降低了整体功耗,使芯片在具备高可靠、高性能指标的同时,达到了功耗小于5W的指标,远低于市场同类产品。在航空、航天领域核心元器件要求完全自主、可控的大背景下,玉龙810芯片的投产能够为型号项目的人工智能算法及超大数据高速处理及应用提供一个理想的AI SoC芯片平台。
猜你喜欢
卫星应用(2023年1期)2023-02-21
数据与计算发展前沿(2022年6期)2022-12-22
现代经济信息(2022年22期)2022-11-13
北京航空航天大学学报(2022年7期)2022-08-06
中国交通信息化(2021年7期)2021-11-02
成都信息工程大学学报(2021年1期)2021-07-22
个人电脑(2016年12期)2017-02-13
电子制作(2016年19期)2016-08-24
电源技术(2015年11期)2015-08-22
电子设计工程(2014年17期)2014-02-27
