
基于LSTM的云环境异常智能检测方法研究
2020-06-30 06:56王敏红
铁路计算机应用 2020年6期
崔 峰,郭 刚,饶 伟,王敏红
(中铁信弘远(北京)软件科技有限责任公司,北京 100089)
近年来,随着铁路事业的快速发展,作为信息技术支撑的铁路云数据中心规模也不断扩大。铁路云[1-2]是由多项云计算相关技术、产品和解决方案组成的,专门为铁路行业打造的行业私有云平台,相关产品已经在中国国家铁路集团有限公司数据中心和多个铁路局集团有限公司部署实施。在铁路云的信息化建设和联网运营中,新的挑战也不断出现。随着铁路云规模的不断扩大,在运维管理过程中,运维人员需要对海量的运行指标、运行日志等进行监控、分析和检查,以便及时发现各种运行异常。目前,常用的静态阈值检测、日志人工查验分析、脚本监控、定时报表检查等方式,存在准确率不高、时效性差、人工承担工作量大等问题。因此,本文提出一种基于长短期记忆(LSTM,Long Short-Term Memory)神经网络的云环境异常智能检测方法,通过机器学习的方式,定期计算刷新各指标的合理阈值,从而实现在线异常检测。
1 云环境监控指标特征
铁路云监控从云底层物理环境和云虚拟机中采集各类监控数据,用于判断各机器设备及进程服务运行状况是否存在异常现象。监控指标包括:CPU使用率、内存使用率、硬盘IOPS、网络流量、服务进程状态等,通常具有数据量庞大、判别依据复杂和特征变化频繁的特点,并对生产应用带来了相应的影响。
1.1 数据量庞大
(1)监控指标的种类多,指标范围涵盖多种设备的多种监控指标,如针对内存的监控指标有:利用率、争用率、分配率、总容量值、具体消耗值等,所有指标类型总数量已达900 种以上。
(2)单台机器上单个指标的采集对象可能较多,如1 台服务器上硬盘可达20 块以上,而服务进程数则可达几百甚至上千个。
(3)采集频率高,为提高监控时效性,普通指标数据的采集通常为分钟级,而关键指标则更频繁。
(4)云环境中机器数量众多,物理机数量可达万台以上,而云虚拟机数量则可能达到10 万台以上。因此,在大规模云环境中,监控指标的数据量非常庞大,已无法依靠纯人工方式进行及时的分析处理。
1.2 判别依据复杂
在同规格的物理机或虚拟机上,如果所运行的应用不同,即使是同一种监控指标,其正常与否的判别标准也可能不同。此外,即使同一台机器的同一个监控指标,在不同的时段里,其正常与否的判别标准也可能不同,因此,对监控指标进行准确判别、特征抽取并不简单,需要考虑的方面较多。传统上使用固定阈值作为异常判别特征的方法,难以保证在绝大多数场景下都得到理想的结果。
1.3 特征变化频繁
在实际生产中,运行环境通常不会一成不变,因此,监控指标的特征也会随之变化。当环境变化达到一定程度后,继续沿用旧的指标特征将无法准确处理新的监控数据。因此,要保持监控分析判别的准确性,需考虑环境变化带来的影响,及时对监控指标特征进行必要的更新,而这会带来较繁重的工作量。传统人工修正的方法不仅给运维人员增加较大的工作强度,也容易在工作之中出现遗漏等情况。
因此,需要研究一种能在大规模数据量下,自动快速学习监控指标关键特征并检测其变化趋势的云环境异常检测方法。
2 LSTM神经网络原理
2.1 循环神经网络
神经网络通过对大脑内部的运作模式进行模拟,采用梯度下降算法进行参数优化,具有强大的自学习能力和非线性映射能力。神经网络可用于解决分类、回归等问题,已在图像、视频、文本处理等众多领域得到了应用。
在铁路云环境中,按固定频率采集到的指标数据为时间序列数据,其当前时刻的数值和之前时刻的数值是有关联的。传统神经网络从输入层经过隐含层到输出层,层与层之间采用全连接的方式,基本无法对序列数据进行预测。循环神经网络(RNN,Recurrent Neural Network)对传统神经网络进行了改进,包含了一个反馈输入,将神经元的输出在下一时刻传递给自身,从而保留前一时刻的信息,达到保留之前学习内容的目的。图1a 为t时刻的单个RNN,A为一个RNN 单元,xt为输入,ht为输出。
2.2 LSTM神经网络
由于RNN 的权重共享和前向反馈机制,容易发生梯度爆炸、梯度消失和长期记忆能力不足的问题,使得RNN 对时间序列的预测结果不尽人意。LSTM是一种改进的循环神经网络[3],已广泛应用于自然语言处理[4]、语音识别[5]、机器翻译、序列预测[6]等方面,相对于RNN 主要有2 点改进:
(1)设置变量C(单元状态),解决无法长期记忆的问题;
(2)引入多个“门”,解决梯度消失和梯度爆炸的问题。
LSTM 神经网络在时间序列拟合和预测上整体性能较好,主要得益于模型的架构。LSTM 神经网络中定义了“遗忘门”,可以忘记不必要的信息,减小误差;定义了“输入门”,能够决定并存储记忆单元新的输入信息;定义了“输出门”,决定要输出的内容;tanh 层可以根据新的输入创建所有可能的值的向量;Sigmoid 函数输出0 到1 之间的值,决定遗忘或保留信息的百分比。
图1b 是以t时刻为例的LSTM 单元运算,左侧输入为t-1 时刻的单元状态Ct-1和输出ht-1,输出为当前时刻t的单元状态Ct和输出ht,Wf,Wi,Wc,Wo分别为不同的权重系数矩阵,σ和tanh分别为sigmoid 和tanh 激活函数。
使用LSTM 神经网络的时间序列预测能够自主学习曲线中的特征,通过不断迭代训练集来适应曲线的不断变化,目前已在用电量预测[7]、飞机故障时间[3]、金融分析[8]等方面有了广泛研究与应用。

图1 RNN和 LSTM结构
3 云环境异常智能检测模型设计
3.1 数据预处理
铁路云监测应用通过Kafka 将所有指标数据保存到Hadoop 节点的HDFS 中,以1 min 为周期,包含指标的通用唯一识别码(UUID,Universally UniqueIdentifier)、时间戳、指标名、时间步长等。由于短采样周期的时间序列波动性大、规律性不明显等缺陷,需要先对数据进行平滑处理,消除“毛刺”。本文将时间序列进行重新采样,取5 min 内的平均值,将源数据转化为以5 min 为采样周期的数据。
时间序列可以认为是趋势、周期性波动和残差的叠加。趋势描述的是时间序列的整体走势,周期性波动是时间序列的循环变动,在忽略残差的情况下,可将时间序列分解为趋势线和周期线。本文采用经典的时间序列分解算法,使用m阶的移动平均,提取趋势线,并使用加性模型分解,取平均值即得到周期线,公式为:

其中,ts表示时间序列;Tt为趋势线在t时刻的值;k是周期长度;m通常取2k+1,此时Tt是时间序列t时刻向前k个值和向后k个值的均值;Pt为周期线在t时刻的值,l为任意个周期长度。
图2 是对铁路云中某物理机内存指标时间序列的分解结果,周期长度为288,即以一天为周期。

图2 某物理机内存指标时间序列分解
分解后的趋势线较为平滑,并且过滤出了序列的增长趋势,周期线则过滤出了序列平稳的周期性。合适的特征可以缩短模型从数据中的自我学习过程和训练时长,得到更好的预测效果。本文选取了2个重要特征:

其中,f1和f2表示序列ts在t时刻的特征,f1是序列在上一周期相同时间的值,f2是按15 min 划分得到的时刻编号;(tst)hour表示序列在当前时刻的小时值,(tst)minute表示序列在当前时刻的分钟值。
分解后的特征通过z-score 标准化映射为均值为0,方差为1 的标准序列,以消除特征范围不均造成的权重偏差的影响。
3.2 模型构建
本文以LSTM 神经网络为基础,建立自身模型。模型使用Encoder-Decoder 结构,对时间序列先进行编码,再进行解码,分为趋势模型和周期模型2 种。
趋势模型采用较简单的模型结构,通过全连接层进行编码,再连接一个128 单元的LSTM 层进行解码。周期模型使用双向LSTM 层进行编码,编码后的序列通过一个128 单元的LSTM 层和多个全连接层进行解码。图3 为本文构建的LSTM 模型图,时间步长为24,预测长度为30。
在构建模型时,考虑到序列的复杂度,较为简单的模型便能很好地拟合趋势线,同时缩短训练时间;而略复杂的模型能从周期线中学习到更多的特性。模型使用l1、l2 正则化技术,并添加Early Stop方法、Dropout 方法来防止过拟合的发生,其中,l1正则化会让尽可能多的权重系数为0,l2 正则化会让所有权重系数尽可能的小。模型损失函数使用绝对误差(AE,Absolute Error)函数,激活函数选用SELU 函数,优化算法选用Adam 算法。

图3 本文构建的LSTM模型
3.3 阈值定义
预测值是对未来一段时间内曲线走势的刻画,当真实值同预测值的差距过大时,说明曲线的走势发生了变化,便可认为是发生了异常。本文的预测值为趋势模型和周期模型预测结果的叠加,并通过2种阈值设定方式进行异常联合判定。
(1)假设数据的变化符合正态分布,并且下一个点的变化范围符合上一周期的分布,可将预测值加减上一周期数据的标准差:

其中,lstd是上一周期的标准差,lupper和llower分别是上、下界,tslast_period表示上一周期的序列,tspre表示预测得到的序列,i表示倍数,默认取3,使用时会根据实际生产要求自定义。
(2)通过贝叶斯推理,在每层网络层之后添加Dropout 方法,在神经网络进行训练或预测时,会随机丢弃一部分神经元及其连接,使得预测结果符合预期的分布。
只有当真实值同时超出2 种方法的阈值时,才会被判定为异常。预测结果和上下阈值通过逐点实时运算,记录到HBase 中,rowkey 格式为:指标名+UUID+设备名+时间戳。
4 云环境下的模型验证
4.1 数据集
本文使用的指标数据取自铁路云武清环境的部分物理机,选取CPU、内存、网络3 种指标共12 条时间序列,每条序列中选取10 天的数据,初始粒度为1 min。将前3 天的数据作为训练集,后7 天的数据作为测试集。
4.2 平台和环境
本文使用的虚拟机配置为:处理器为Intel(R)Xeon(R) CPU E5-2609 v4 @ 1.70 GHz;内存为16 G;操作系统为Red Hat。程序设计语言为Python 3.5,模型设计和结果比较过程中用到的程序包有Tensor Flow、Statsmodel、Sklearn。
4.3 对比模型
将本文设计的模型同以下几种时间序列预测方法进行比较:
(1)Holt-Winter 方法:3 次指数平滑方法,考虑了趋势性、季节性和残差;
(2)ARIMA 方法:自回归移动平均,将差分、自回归和移动平均相结合的方法;
(3)XGBoost 方 法:基 于CART 回 归 树 的Boosting 算法,可用于分类和回归;
(4)single-LSTM 方法:使用单层LSTM 神经网络模型进行训练,相较于本文所用方案少了序列分解和Encoder-Decoder 过程。
4.4 验证结果
表1 为4.3 中各模型基于相同数据的预测结果,其中Holt-Winter 模型、ARIMA 模型参数与文献[3]相同。
查准率为检测到的异常与真实异常的比率,查全率为检测到的异常数占异常总数的比率。本文方案的查准率和查全率平均值分别为76.6%和77.3%,在所有模型中效果最好。某些用时短的方法,在某项指标上的预测效果不尽人意,如ARMIA 方法在CPU 和网络指标上的准确率不到20%。
根据查准率和查全率,选取single-LSTM 同本文方案进行预测结果及阈值区间的比较。如图4、图5 所示,红线为预测结果,蓝虚线为真实值,绿色范围为阈值区间。可以看到本文方案同真实值曲线更贴合,阈值区间也更接近,即具有更高的拟合度和更准确的阈值区间,可有效减少异常的漏判和误判。

表1 多种方法预测结果比较

图4 某物理机内存指标的预测结果比较
5 结束语
本文研究了一种基于LSTM 的云环境监控指标异常智能检测方法,相比传统异常检测方法实现了准确性、适用性等方面的提升。本方法提出了将时间序列分解同LSTM 神经网络相结合并应用到监控指标判别的方法,以及以正态分布和贝叶斯推理定义预测波动范围的方法,能避免纯时间序列预测方法不同指标间精度不一、需要调参的缺陷,更有效地捕捉指标变化趋势。测试结果表明,相比常用的传统监控异常检测方法,本文方法具有更高的准确率,可以在大规模铁路云环境上实施,为运维人员提供一种有效的异常智能检测方法。本方法对计算资源的要求较高,在后续的研究工作中,将通过优化模型结构、提升算法实现效率等途径继续改进本方法。
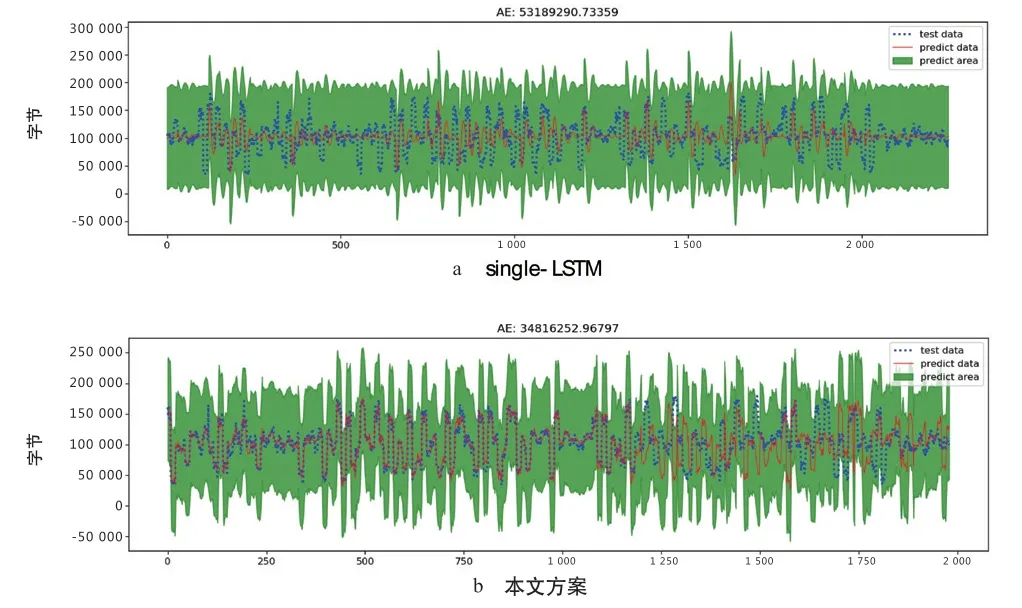
图5 某物理机网络指标的预测结果比较
猜你喜欢
现代电力(2022年2期)2022-05-23
环球人物(2022年4期)2022-02-22
建材发展导向(2021年19期)2021-12-06
小资CHIC!ELEGANCE(2021年32期)2021-09-18
临床骨科杂志(2020年1期)2020-12-12
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
小学阅读指南·高年级版(2014年2期)2014-05-27
科技视界(2014年25期)2014-04-27
