
面向铁路客运大数据的客流分析研究及应用
2020-06-29 13:29罗明
中国铁路 2020年4期
罗明
(中国铁路武汉局集团有限公司信息技术所,湖北武汉 430071)
0 引言
信息技术在铁路运输生产、经营管理和客户服务等领域广泛应用,系统规模越来越大,承载的关键业务越来越多[1]。从客运角度看,海量的客运数据存储在关键系统中,而关键系统的数据大多采用小型机上安装大型商用数据库的方式存储,当前数据库在面对海量数据场景下,对吞吐量、可扩展性和可用性等关键特征提出更高要求。如何利用虚拟化和分布式等技术提升大数据的存储速率和分析能力,以解决传统数据库的性能瓶颈、昂贵的产品价格和售后服务、扩展性有限等问题[2],是相关部门面临的重要课题。在此,从铁路客运业务产生的海量数据入手,研究如何从客运大数据中深度挖掘客流数据主要指标,提出构建分布式客运数据存储平台的方案,并利用该平台建立数据的多维度关联,实时分析中国铁路武汉局集团有限公司(简称武汉局集团公司)和九大方向的客座率、列车密度表等指标,为客流预测提供依据。
1 铁路信息系统数据库现状分析
在铁路行业,其核心的关键信息系统数据库解决方案大多采用小型机上安装大型商用数据库的方式,例如客票系统采用Sybase 数据库,调度管理系统采用Oracle数据库。武汉局集团公司为了更高效、更稳定地管理信息系统,将重要信息系统数据库整合并集中管理,例如确报、车号和18 点统计等系统会共有1 套小型机加Oracle数据库。目前这些关键信息系统采用中间件+数据库的传统“烟囱式”架构,随着数据量的猛增,其响应速度和可靠性下降,在业务应用时存在多种问题[3]。有些系统为了提高响应时速,将历史数据删除或转存到其他位置,造成数据丢失。数据是信息化的核心,上述做法既对本系统日后数据分析造成困难,也给数据间的共享和融合带来困难。
对比其他行业,例如银行业,已经开始探索微服务和分布式技术架构。微服务体系的拆分对数据库存储提出了极大挑战,如果还使用传统数据库,其存储与计算能力均会因为微服务容器数量的上升而受到较大影响[4]。因此,无论是从单个信息系统的发展还是构建数据中心,分布式的数据库架构都是发展方向,铁路行业也必将会经历从传统数据库向分布式数据库转型的过程。
2 铁路客运数据现状分析
2.1 客运相关信息系统
客运数据存在于多个业务系统,每个系统的存储方式、侧重角度及基础字典均不同,其中客运营销库的数据内容最全,客运精密统计数据最为准确,财务部门使用的运营成本核算数据也是客运分析重要组成部分。
在客运营销库中,客票数据种类多、涵盖范围广,可以查询或计算得到列车的全车次、始发站车次、定员等信息,但是列车售票信息不全,不含退票和车补信息,所以票价收入和发送人均有一定误差。
计划统计部(简称计统部)有列车票价收入的精密数据,包含退票和车补信息。与计统部交接可获取列车售票的精密数据,包含详细售票记录表和站名字典表。但在售票记录表中,存储的是列车票面车次,没有与全车次或者始发车次进行关联,而且站名字典和营销库中也不尽相同。
列车成本数据则需从财务部获取,列车成本由中国国家铁路集团有限公司按月分类别清算到铁路局集团公司,每趟车还需要对所有成本进行合并计算,财务部按月提供指定列车本月成本数据。
2.2 客运多业务系统数据关联
针对上述3个数据来源,首先在营销库中获取列车的详细基础信息,使用存储过程分析计统部的精密数据,将票面车次与全车次、始发站车次建立起关联。对于列车成本数据,同样适用存储过程,将按月的列车成本按照始发站车次匹配到每日开行的趟车上,将3种数据有效关联后实现任意时间段内列车开行收入分析。客运多业务系统的数据关联,可打通客票数据间的壁垒。
2.3 传统数据库存储问题
营销库中的日常列车开行数据表均为标准的结构化数据,使用Oracle进行存储。但该表数据量庞大,售票信息从2017年6月开始,数据量就达到2亿多条,存在查询速度慢、可靠性不高等问题。针对此问题,使用Oracle分区表技术,将数据按时间自动分区,同时建立分区索引,数据的查询性能提高了20倍以上。
计统部的精密数据使用txt 文档进行接口,通过专门安全的FTP 服务器传递。采用Sql Loader 技术将该数据加载到Oracle 数据库中,一次可对多个表进行装入,而且提供了加载日志,便于分析。辅助技术为Windows脚本工具和Windows的定时任务。
财务部的成本数据使用excel 进行传递,数据量较小,且交互频率较低,使用手工导入方式。
可以看出,在面对大数据量的统计分析计算时,传统数据库可以利用分区表、索引等方式提高查询效率,但仍存在查询速度慢、对复杂查询处理需提前计算等问题,同时在硬件投入方面,将数据存储在小型机上,如果想进一步提高计算性能已不太可能,或者代价非常高。如果存储时间超过5年,在数据统计分析时,基本就无法进行实时分析了。
在进行客运大数据分析项目时,采用传统数据库,遇到爆发的海量请求时系统不能迅速响应,例如节假日旅客按客流方向按车次实时分析等。另外,设备采购和运维成本高昂,小型机设备与中间件分别采购、运维分开,导致整体费用高。因此在进行大数据分析等项目时,应逐步将数据库从传统Oracle数据库向分布式数据库进行转型。
3 构建分布式客运数据存储平台
分布式数据库不同于小型机架构体系,是基于X86服务器为底层架构设计的,系统在设计时充分考虑高可用、分布式、容灾等问题。基于X86 的服务器集群,随着数据量的增加可以实现无缝扩容,拥有强大的扩展能力[5]。构建分布式客运数据存储平台,重点解决如何使用虚拟化平台合理规划资源,降低硬件开销,提高数据库利用率和数据存储速率:一是利用既有设备构建基于X86服务器的虚拟化平台;二是安装Greenplum 数据库(DB),完成分布式数据库安装;三是将核心系统Oracle数据迁移至Greenplum DB,建立数据清洗规则,定时导入;四是通过数据钻取将粗粒度数据向细粒度数据转换,数据在维度的不同层次间变化,从上层降到下一层,将汇总数据拆分到更细节的数据,加快查询与存储速率。
3.1 构建基于Vmware的虚拟化平台
在安装Vmware 虚拟化平台前,先准备硬件环境。利用机房闲置的4台惠普DL580 G7服务器,2台万兆交换机,每台服务器增加1 块960 GB SSD 固态硬盘作为数据缓存,每台服务器配6块2 TB HDD硬盘做数据盘,配1 块600 GB HDD 硬盘做系统盘,每台服务器增加2个光纤通道HBA卡,满足搭建环境需要。
Vmware 的虚拟化平台采用Vmware vSphere+vSAN的解决方案。首先利用vSAN 软件对存储进行分布式处理,在vSphere 集群主机中构建vSAN 存储层,同时存储通过vSAN 进行管理。再利用vSphere 搭建虚拟化平台,可以最大程度地利用服务器的资源,降低数据中心的硬件成本。平台搭建完成后可通过管理软件进行配置管理(见图1)。
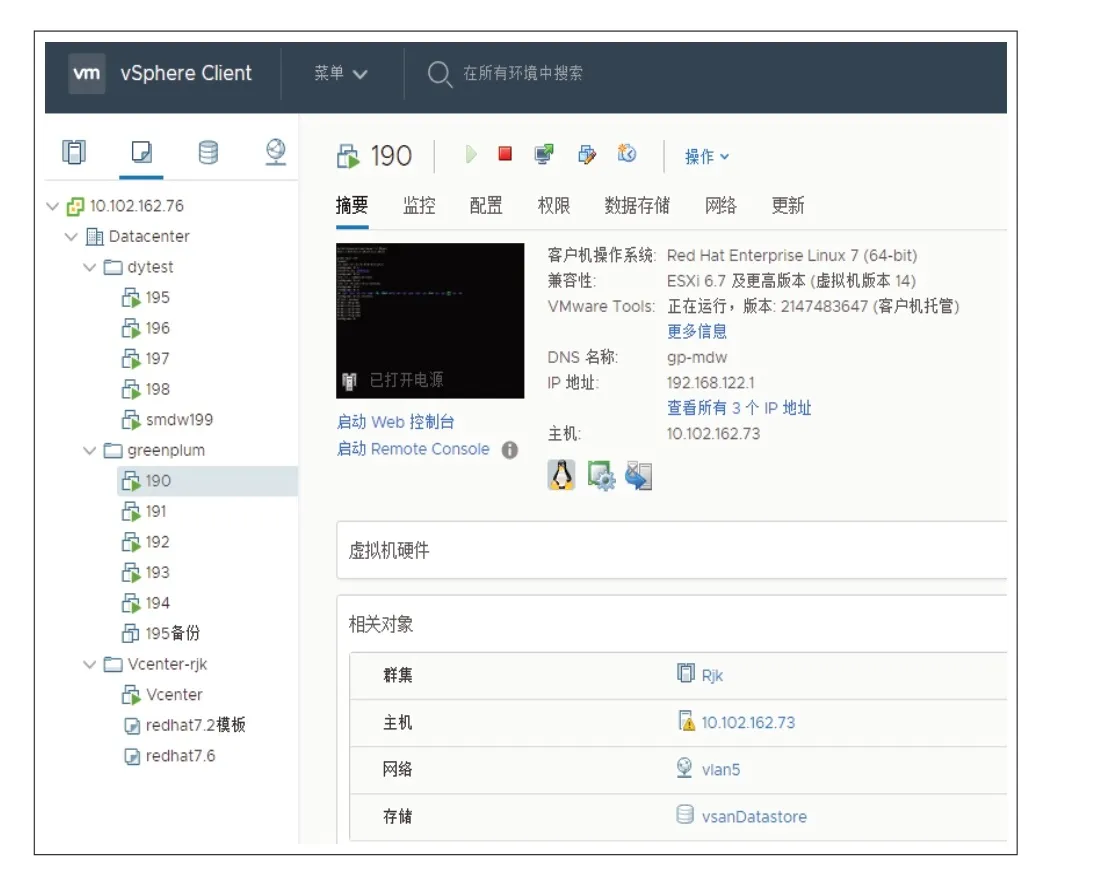
图1 Vmware虚拟化平台管理界面
3.2 搭建分布式数据库
在分布式数据库的选型上,项目组在最早阶段也搭建了1 套Hadoop 数据存储系统,Hadoop 是一个生态系统,泛指使用这种基础平台进行分布式计算和海量数据分析处理的一组项目[6]。但因需要接入的信息系统全部是结构化数据,导入到Hadoop 系统中实际计算效率还不及Oracle数据库,尽管它也能很方便地扩展计算单元和存储单元。经过讨论和对比,最终选择了大规模并行处理(MPP)数据库,考虑到开源和易用性等多方面因素,并参考了阿里巴巴使用Greenplum 替换之前Oracle RAC 的成功经验,选择Greenplum DB 作为分布式数据库的技术选型。
MPP 数据库本质上依然是一个关系型数据库,其原理是将任务并行地分散到多个工作节点,每个节点的磁盘存储系统和内存系统均不与其他节点共享,属于Share-Nothing 模式[7],而Oracle RAC 数 据 库属 于Share-Everything 模式。Greenplum 是一种基于PostgreSQL 的分布式数据库,采用Share-Nothing 模式,其中主机、操作系统、存储、内存都是属于独占模式,不存在共享。Greenplum 属于关系型数据库集群方式,由多个独立的数据库服务组合而成,因为其基于X86服务器,所以价格低廉,在开放平台的同时,可提供强大的海量数据处理能力和并行数据计算能力。MPP数据库主要是为了解决大问题而提出的并行计算,而不是对高并发的请求。其特点总结如下:(1)支持海量数据存储和计算;(2) 支持主流的SQL 语法;(3)有方便的维护工具,学习方便;(4)扩展性好,提供分布式事务处理能力。
在搭建好的虚拟化平台上安装10 台虚拟机,安装Red Hat Linux 操作系统,每5 台虚拟机搭建1 个Greenplum 集群,共建立2 个Greenplum 集群。其中1 个集群对应IP 地 址10.102.5.195-199,其中10.102.5.195 为Master 主机,剩余4 个为Segment 主机。通过PgAdmin对Greenplum 数据库进行访问,PgAdmin 管理界面见图2。

图2 PgAdmin管理界面
3.3 数据迁移与清洗
在安装完Greenplum 后,需要将以前存储在Oracle的数据存储在Greenplum 数据库中。对数据管理所采取的方案为:从生产系统、消息队列(MQ)报文或文件传输协议(FTP)文件中提取的数据先存储在Oracle 数据库中,Oracle存储近期和未来时间的数据,近期的时间段根据各业务系统产生数据量的大小决定,Greenplum 数据库定义为存储历史和分析后数据,增加入库时间戳,保证数据的回溯性。
Greenplum 数据加载主要包括insert、copy、外部表、gpload、web external table 等5 种方式。其中insert和copy 是串行,外部表gpfdist 和gpload 工具是并行方式。
(1)Insert 这种加载方式和其他数据库SQL 语法一样,但是效率最差,只适合加载极少数数据,需要通过master 节点操作。Copy 方式比SQL 方式效率大大提升,但是数据依然需要通过master节点,无法实现并发高效数据加载。
(2)为了提高数据导入效率,Greenplum 引入外部表。外部表基于gpfdist 工具(类似于Oracle 的sqlldr 工具),其最突出的优势是支持数据并发加载。所谓外部表,就是在数据库中只有表定义、没有数据,数据都存放在数据库之外的数据文件。Greenplum 利用外部表执行正常的增删改操作,而外部表支持在节点上并发执行gpfdist 的导入程序。外部表需要指定gpfdist 的IP和端口,还要有详细的目录地址,文件名支持通配符匹配,可以编写多个gpfdist 地址,但是总数不能超过总的segment 数量,否则会报错,因此Greenplum 执行效率高。
(3)gpload是Greenplum使用可读外部表和GP并行文件服务gpfdist装载数据的1个命令包装,其允许通过使用配置文件的方式设置数据格式等来创建外部表定义。通过按照YAML 格式定义的装载说明配置文件,然后执行insert、update、merger操作,将数据装载到目标数据库表中。
项目组使用gpload方式成功上传pt_history的1个月数据(1300万行记录),下载30 s左右,上传120 s。
3.4 数据钻取
客票系统的售票信息在不断地发生变化,更新频率非常高,对数据库的更新也会非常频繁,而客票系统的历史售票记录则不会再发生变化,更新基本上不会发生,数据操作需求很低。面对这种情况,采用实时数据和历史数据分开处理,当天及以后的客票数据存储在实时表中,昨天及以前的客票数据存储在历史表中。实时表的数据量基本上是固定的(最多30 d),并且不受历史数据的影响,可以进行快速的增删改查等操作。历史表的数据量非常大(目前存储了3年),并且会不断累积,利用分布式数据库可进行快速查询、统计。在历史数据分析中,通过数据钻取将粗粒度数据向细粒度数据转换,数据在维度的不同层次间变化,从上层降到下一层,将汇总数据拆分到更细节的数据,以加快查询与存储速率。将售票信息通过车次、方向、线路、客座率等多个维度进行分析并存储,每个统计分析的结果都会加上时间戳,为之后的客流分析和预测打好基础。
4 客流分析研究及应用
在分布式客运数据存储平台上开展客运数据分析研究,可实现数据的展示、查询功能以及节假日客流情况分析,客流分析系统界面见图3。在终端展示方面,可同时采用大屏显示和电脑版分析2种形式。按照车次、列车交路、发行方向等方面进行客座率统计、分析,形成一定的决策分析结果,为客车的加开、加挂、缩编等工作提供信息支持;通过对清明节、劳动节、暑期、端午节、中秋节、国庆和元旦等节假日的客流进行统计、分析,以大屏形式展示武汉局集团公司的客流情况;通过掌握集团公司、车务段、车站在各时间段的发送和到达信息,为客运高峰期的预警提供信息支持;通过掌握集团公司发往各省的客流情况和从各省到达集团公司的客流情况,进一步了解旅客的出行方向,为客运方向的规划提供信息支持[8]。其主要分析指标和功能如下:
(1)列车密度表:对列车的上车、下车、车内人数做到精确掌握,为调整席位的预售区间提供信息支持。
(2)列车客座率:对列车的定员、里程、编组做到精确掌握。
(3)列车正晚点:对列车的正晚点情况可全面掌握。
(4)九大方向的客座率:对武广、汉宜、汉十等重点线路进行分析,挖掘出上座率高和上座率低的车次,为客运运营提供信息支持,例如:如果后面的区间客座率低,是否应提前返程。
(5)担当交路客座率:挖掘出客座率高的交路,分析是否重联以进一步提高客运能力;挖掘出客座率低的交路,分析是否用单组的方式,以减小客运成本。
(6)车站发送、到达预警:对车站的发送、到达情况,按照时段、车次进行预警,武汉站已初步实现了站台预警。
(7)集团公司发送、到达分析:各省之间的客流情况、每日发送人统计、担当列车的对数。
(8)客流预测:根据历史数据,采用ARIMA 乘积季节模型对节假日的客流进行预测。
(9)实现部分大屏展示:驾驶舱界面汇总客运的关键数据,已在调度所大屏进行展示;大屏轮播界面可展示客运的重要指标,已在客运部的大屏进行展示。
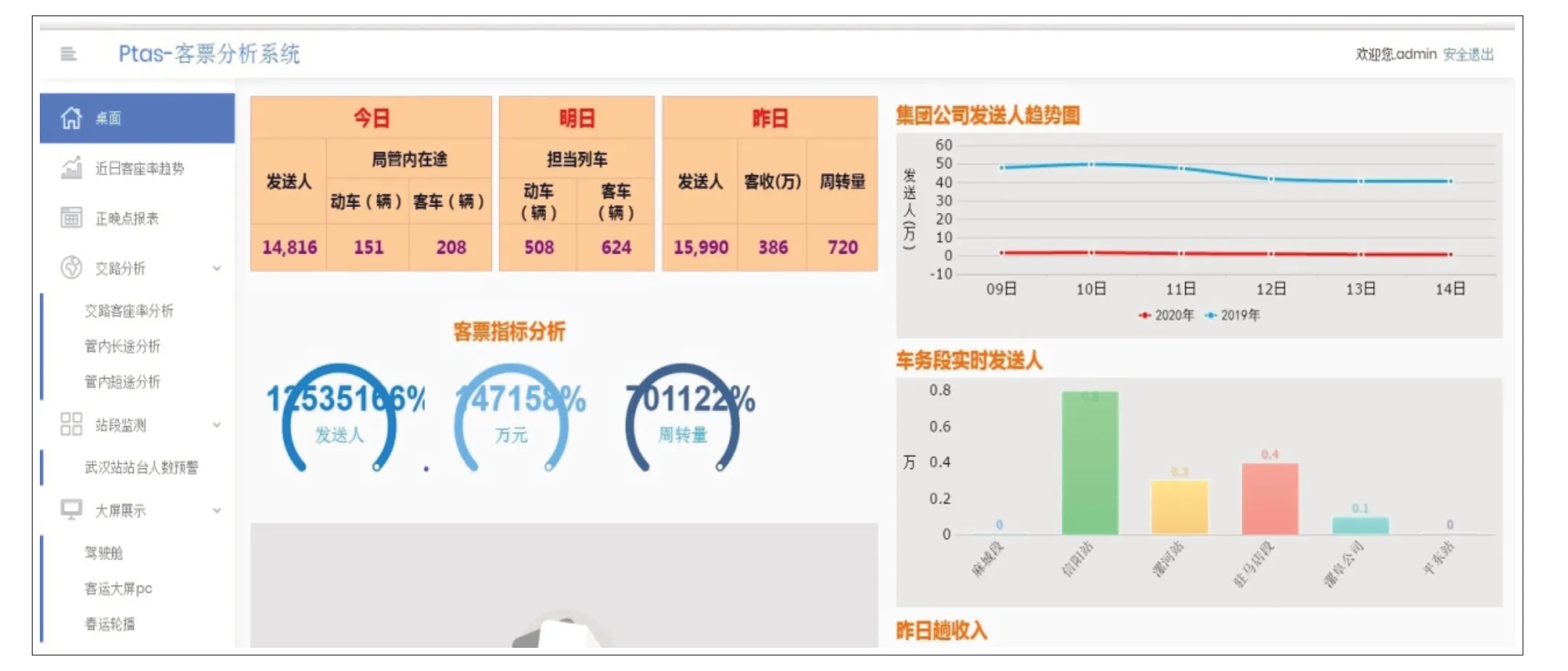
图3 客流分析系统界面
5 结束语
面对海量客运数据,找到与客流相关的关键指标,形成一定的决策分析结果,用于指导客运组织是本项目研究的初衷。通过构建分布式数据存储平台,实现了在有限硬件条件下大数据量的实时分析,为数据的预测提供基本计算来源[9]。利用大数据技术,在客流数据分析和挖掘方面进行研究,通过数据钻取将粗粒度数据向细粒度数据转换,数据在多个维度上进行分析和存储,并在此基础上研究客流相关的9 类关键指标[10-11]。随着历史数据的增长和系统功能的增加,尚有许多内容需要研究。目前该平台系统还处于验证和完善阶段,分布式数据存储平台的稳定性也需进一步验证。

猜你喜欢
环球时报(2022-12-12)2022-12-12
铁路通信信号工程技术(2022年6期)2022-06-27
北京大学学报(自然科学版)(2021年3期)2021-07-16
科学家(2021年24期)2021-04-25
电脑爱好者(2020年19期)2020-10-20
大连交通大学学报(2020年5期)2020-10-17
铁道运营技术(2020年4期)2020-10-13
电子制作(2019年13期)2020-01-14
岷峨诗稿(2016年1期)2016-11-26
