
科研档案管理知识图谱构建研究
2020-06-29 02:42:54赵瑞雪李思经鲜国建寇远涛
科技管理研究 2020年11期
雷 洁,赵瑞雪,3,李思经,鲜国建,3,寇远涛,3
(1.中国农业科学院农业信息研究所,北京 100081;2.中国农业科学院农业经济与发展研究所,北京 100081;3.农业部农业大数据重点实验室,北京 100081)
科研档案日益成为国家基础性战略资源,科研档案管理工作内容也更加丰富、需求更加多样,地位和作用日益重要。随着科学技术以及社会生产力的发展与变化,档案管理方式与流程、档案利用思想等在不同时期有不同的表现。我国档案管理的发展可分为3 个阶段:档案实体管理、档案信息管理和档案知识管理阶段。2016 年国家档案局发布的“十三五”规划纲要中[1],阐明了当前档案管理面临的主要挑战:电子政务系统的建设极大地促进了电子档案资源的形成;档案的信息化与网络化成为主要的发展趋势;大数据等技术的发展给档案数据安全与存储、隐私保护等带来挑战。掌握科研档案的管理现状、发现目前科研档案管理中存在的问题与需求,对开展科研档案管理研究具有重要影响。随着数字档案急剧增加,大数据、云计算、语义网等信息技术正在推动档案管理方法的创新。传统的档案收集、管理与利用过程随着信息技术的快速发展和广泛应用发生了改变。但在现有的档案系统内资源的加工粒度依然按照传统的“卷”和“件”进行,标引按照档案著录格式开展,档案数据关联度与利用率都较低,对档案资源的管理依旧处于“仅保存”状态。如何充分发掘科研档案资源这座“沉睡的宝藏”,改变传统的科研档案管理模式,实现档案资源以及档案与外部知识库之间知识关联、集成与共享,构建一个语义化、智能化的科研档案管理系统是目前科研档案管理迫切需要解决的问题。
1 相关研究
随着语义技术的发展,档案管理逐渐向关联数据、语义组织方向发展,档案管理语义知识组织标准化日益重要与紧迫。档案语义知识组织标准化涉及知识组织系统、本体、语义网(关联数据)等标准化。语义网是一种数据组织方式,能够在数据之间建立链接,从而形成关联数据[2],而知识图谱技术则是实现语义网络连接与展示的基础和桥梁。知识图谱(Knowledge Graph)由谷歌在2012 年提出,旨在实现更智能的搜索引擎。目前知识图谱在智能问答、情报分析等应用中也发挥了重要作用[3]。通用知识图谱一般面向多领域资源,突出知识的广度。如国外公开可获取的知识库资源Freebase 由美国Metaweb 公司开发,旨在创建一个全球资源允许人与机器更有效地访问公共信息[4]。在DBpedia 知识库中,用户可基于语义查询维基百科资源的关系和属性,还包括指向其他相关数据集的链接[5]。FABIAN[6]从维基百科、Word Net、Geo Names 中提取数据,到2019 年已经拥有超过1 000 万个实体。CN-DBpedia 是由复旦大学研发的结构化百科,主要从中文百科类网站的纯文本页面中提取信息,形成高质量的结构化数据,包含900 万+的百科实体以及6 700 万+的三元组关系,目前提供Dump 数据下载[7]。上海交通大学发布的百科数据的zhishi.me 融合百度百科、互动百科、维基百科,抽取结构化数据,提供SPARQL 查询,以HTML 的形式给出反馈结果[8]。另外还有百度的知心、搜狗的搜立方,等等。这些知识图谱具有语义领域覆盖面广、规模大、结构良好等特点。垂直领域知识图谱针对具体领域资源,注重知识的深度和完备性,对知识的展示粒度更细。Linked Life Data是生物医学领域的知识图谱,涵盖了医学领域几乎所有的重要对象。全球地理领域Geo Names 免费数据库由美国国家测绘等部门收集数据,地名数据覆盖性强,包含近200 种语言的1 100 多万个地名[9]。
我国在20 世纪90 年代初开始针对档案的电子形式资源进行研究,提出多位一体的电子数据管理模式和多重管控的思想[10]。在信息技术广泛运用的背景下提出了文件管理流程重组,有利于文档一体化管理[11]。许多学者就我国电子文件管理国家战略开展了深入的研究[12-14]。国外在语义关联方面的研究主要集中在基于已有元数据如EAD、Dublin Core 等,探讨元数据语义互操作以及映射关系。在各个领域开展了语义技术的应用研究,如从语义网的角度出发,探讨了图书馆、档案馆以及博物馆之间的数据关联[15]。还有研究采用了本体技术构建知识库模式应用于电子政务,对数据和服务的描述进行了改进[16]。在目前的国内外关于档案的语义化研究中,国外更加注重元数据的语义融合以及泛在化的档案资源与图书等资源的整合。国内研究更多聚焦在档案资源体系语义互操作与档案系统资源挖掘、档案数据整合与集成等。从档案管理前端出发,关注档案采集、加工与管理等过程中语义技术的应用较少。本研究利用知识图谱开展科研档案资源管理研究,通过构建一种计算机可识别、具有较强操作性以及富含语义关系的科研档案知识图谱模型,以揭示、组织和关联科研档案资源。通过科研档案知识图谱数据层实例的填充和聚合,基于知识抽取与知识融合等技术,实现科研档案的碎片化与精细化加工。基于知识图谱的科研档案管理实现科研档案资源知识关联以及科研档案资源更广的集成、共享与利用。
2 科研档案知识图谱构建
2.1 总体构建思路
在科研档案管理需求分析基础上,明确科研档案知识图谱功能并确定数据源。结合科研档案特点,设计科研档案管理知识图谱构建框架,选取构建语言、构建工具以及构建过程,进行图谱模式层构建,包括定义科研档案知识图谱所包含的实体类型及类的属性、实体类之间的语义关系等。之后,根据构建的科研知识图谱模式,匹配档案数据特点,选取合适的命名实体识别和语义关系抽取方法对档案数据开展知识抽取,构建科研档案知识图谱数据层。通过实体消歧、实体对齐等过程进行知识融合,并与科研档案知识图谱模式互相映射。经过知识融合过程,科研档案数据资源形成标准的数据表示,经过一定的质量评估,最终根据科研档案图谱构建目的选取适合方式进行知识存储,完成科研档案知识的绘制和管理(见图1)。

图1 科研档案知识图谱构建思路
2.2 科研档案知识图谱模式层构建
构建科研知识图谱模式的目的主要有两方面:一是对科研档案知识抽取结果进行明确且规范、客观的描述,使其可以被计算机理解和处理;二是将抽取的实体、关系进行有效地组织、管理,以便于后期科研档案管理模式扩展。科研档案知识图谱的构建过程可分为两个阶段:一是描述体系设计;二是知识图谱模型构建(见图2)。

图2 科研档案知识图谱具体构建过程
描述体系设计过程,面向科研机构档案管理智能化、精细化与关联化的需求,制定采集策略与范围遴选档案资源,对科研档案核心要素进行分析,参考CERIF、Nanopublication 等模型框架[17-18],进行科研档案语义描述体系设计。
知识图谱模型构建过程,利用本体编辑工具Protégé,使用资源描述框架RDF 和WEB 本体表示语言OWL,继承利用EAD、DCMI、VIVO、SWRC、VIVO、Schema.org 等现有较为通用的本体模型,结合科研档案语义描述体系,构建科研档案的知识图谱模型,形成档案资源之间以及档案资源与外部知识库的语义关联,为档案资源精细化加工与智能组织提供语义框架支持。
2.2.1 描述体系设计
当前,科研档案主要涉及与科研活动相关以通知类规定类为主的综合政务文件,与科研项目相关的科研项目材料,科研活动中形成的科研成果文件,与科研人员相关的人事档案以及与科研项目经费相关的财务档案等。在科研档案形成过程中,数据处理的相关工作变得更加复杂。本研究对象的界定是机构在开展科学研究活动中形成的具有保存价值的文字、图表、数据、声像等各种载体的文件材料。具体包括课题立项阶段、课题研究阶段、课题结项阶段、课题申报阶段产生的立项文件、研究文件、结题文件、采购合同等科研课题档案以及论文、著作、专利、软件、数据集、研究报告等科研成果档案、科技成果转化档案以及开展科研活动的主体如科研人员、管理人员、科研团队形成的档案资源。针对科研档案的属性也作了细分。科研档案包含了一般档案具有的属性如与人员相关的责任者等属性,与组织机构相关的团队名称、研究方向等,与来源相关的档号等,与支持信息相关的题名、主题词等。科研课题档案在继承了科研档案属性的基础上还增加看课题编号、课题来源以及课题级别等特殊属性。在开展知识图谱构建中会将各类档案的一般属性和特殊属性统筹考虑。
科研档案知识图谱模型构建主要是基于科研档案实体及语义关系两个构建要素,借助粒度原理、围绕语义网标准设计知识组织的逻辑和物理结构,实现科研档案知识的获取、关联、复用、发现和增值等需求。在本研究中,将实体作为科研档案资源中最小粒度的单元。为保证数据的规范性与系统性,将结合《中国档案主题词表》(第二版)、EAD(Encoded Archival Description,编码档案著录,参考CERIF 及Nanopublication 模型,定义档案实体,如档案、科研课题、机构、团队、人员等。在后续研究中,将对科研档案语料定义句的句法-语义剖析,借助语义技术进行实体识别,提取关键词进一步充实科研档案的实体。科研档案的语义关系是在科研档案的采集、管理以及利用过程中各知识单元间的显性与隐性联系。如科研档案实体分类与子类的层次关系,是is_a 或is part of 的关系;科研课题档案中课题立项档案、课题研究档案、课题结项档案、课题申报档案、课题推广档案的产生时间存在先后顺序,因此它们之间的关系可定义为prior-next 关系。科研档案的语义关系还包含机构与档案、科研人员与科研成果的隶属关系、科研人员间的合作关系、科研成果间的引用关系、科研人员间的合作关系等。通过对科研档案实体的获取、序化以及关联,设计并建立科研档案知识图谱描述框架,进一步规范描述和精细揭示各实体间的语义关联关系,为科研档案领域本体的汇聚和融合奠定重要基础。
科研档案知识图谱概念模型指在科研档案知识领域内具体或抽象的事物及其关系的规范。本体构建的基础是概念模型。在科研档案概念模型构建时,应遵循本体独立性与共享性原则。独立性即本体类别不依赖领域而独立存在。共享性指本体具有可复用性。在构建过程中,要充分理解构建目的,并借鉴已有模型,尽可能减少类别间的冗余和重叠,最小化类别数。借鉴国际档案理事会(ICA)档案著录ISAAR、ISDF、ISDIAH 标准,国际图书馆协会联合会(IFLA)著录标准以及RIC-CM 文件著录概念模型,本研究的科研档案本体概念模型将科研档案及档案自身属性,结合科研机构、科研人员开展项目研究,产出研究成果,形成档案并管理与利用的过程融合在一起进行构建。
2.2.2 模型设计
在前期研究中[19],作者参考CERIF 定义核心实体、成果实体、二级实体以及链接实体的思路,在科研档案本体构建中,需定义档案为最基本的实体,将科研活动产生的科研成果单独设为一个实体,后续将设置二级实体以及实体属性对科研成果进行详细描述。在开展科研档案管理过程中,管理人员主要负责档案的收集、整理和管理工作,而科研人员主要负责开展科研活动、产出科研成果等,两类人员分工差异性较大,故将人员实体细分为科研人员和管理人员两类;依据研究对象的特殊性,将CERIF 中项目实体细化为本研究的科研项目。参照Nanopublication 模型功能性的特色设置,科研档案不同于其他类型的文件,对于立档时间、查询时间以及保管期限有不同的设置方式与控制措施,如从立档时间反映科研项目材料归档及时性,通过监控档案的查询时间状况可侧面映证某领域研究的活跃度,从保管期限来推断科研档案的价值性等,故将“时间”作为模型一项功能性实体。另外,随着信息化的发展以及档案资源共享与利用率的提升,档案数据来源越来越丰富,包含实体档案馆共享资源以及各业务系统推送资源等,因此,将“来源”也作为一项实体纳入档案概念模型中,作为档案管理的功能性的标识。由此,本文设计的档案概念模型的实体主要有:档案(Archives)、科研机构(Organization)、科研团队(Research team)、科研人员(Faculty Member)、管理人员(Administrator)、科研项目(Research Project)、科研成果(Achievement);按照档案的特性,将来源(Origination)和时间(Date)也作为实体进行设计。结合科研活动的过程,在科研档案的概念模型中,通过产出将科研项目、科研人员、科研成果建立关联,通过ead:Creation 将科研机构、科研项目、档案关联等。基于科研档案语义词典进一步规范知识图谱实体与关系,与外部知识库(如Wiki data)进行连接,丰富档案资源的关联关系(见图3)。

图3 科研档案知识图谱模型设计
在科研档案知识图谱模型构建过程中,采用专家咨询的方法,邀请知识构建领域专家2 名、档案管理专家2 名对科研档案知识图谱模式的结构合理性和可扩展性两方面开展了质量评估。知识图谱概念模型的构建是动态循环的。在进行科研档案知识图谱模型时利用Protégé 构建科研档案本体,结合知识抽取阶段实体识别、关系抽取以及属性抽取的实例数据,筛选高频词统计以及语义关系抽取结果,实现科研档案知识图谱语义层面的关联。
2.2.3 模型构建
科研档案本体模型的构建应完整定义其形式化要素:科研档案资源中的类(classes)、对象属性(object properties)、数据属性(data properties)以及档案资源大类或属性间的层级(hierarchy(ies)),以及档案资源的类和属性等的使用规则(rules)。对于科研档案本体,主要遵循ISO 30300 系列以及ISAD(G)、ISAAR(CPF)等档案著录的相关法规标准。
科研档案的本体共定义了7 个一级核心类。其中复用一个VIVO 本体:科研机构(VIVO:Organization);复用一个SWRC 本体:科研项目(SWRC:Research Project);复用了2 个EAD 本体:来源(EAD:Origination)、时间(EAD:Date);参考DBpedia 等知识库,自定义档案(Archives)、人员(Person)、科研成果(Achievement)3 个类。科研档案所涉及的关系层次复杂,内容繁多。按核心扩展法,档案类(Archives)作为研究主体,分为科研项目档案(Project Archives)、综合文书档案(Official Documents)、财务档案(Financial Archives)、人事档案(Personnel Archives)4 个子类。本文重点针对科研课题档案(Project Archives)展开研究,按照课题研究过程可分为立项档案(Project Establishment Archives)、研究档案(Project Research Archives)、结项档案(Project Completion Archives)、成果档案(Project Achievement Archives)以及成果转化档案(Project Achievement Conversion Archives)5 个 子类。立项档案(Project Establishment Archives)按内容又分为立项任务书(Project Assignments)、立项合同书(Project Contracts)和实施方案(Project Implementation Plan)3 个 子 类(见 图4)。通 过Protégé 处理后的核心类别展示见图5。

图4 科研课题档案分类

图5 科研档案核心类定义
通过部分继承EAD、VIVO 本体模型,共定义了8 个一级核心对象属性:复用两个EAD 本体:档案生成(EAD:Creation)来描述由科研项目中产生的材料生成档案;复用EAD:Subject 描述来源和时间与档案、科研项目的关系。复用了VIVO:Current Member Of 来描述科研人员、管理人员与科研机构间的隶属关系。复用了SWRC:works At Project 描述科研人员与科研项目的关系。根据科研档案资源的特殊性,自定义4 个一级对象属性:人员合作(Has Cooperation With)来描述科研人员间的合作关系;自定义产出成果(Output Achievements),并定义了3 个子类:团队产出(Team Achievements)、个人产出(Person Achievements)、项目产出(Project Achievements);自定义拥有管理权限(Has Management),下设两个子类:项目管理(Has Project Management)、人员管理(Has Staff Management);自定义档案使用权限(Has Archives Authority),下设两个子类:查阅档案权限(Access Permission)、下载档案权限(Download Authority),在这两个子类下设置全机构、部门及责任者共六个子类来描述档案管理的权限:即可查阅/下载全部机构档案;可查阅/下载本部门档案;仅可查阅/下载本责任者档案。还可针对科研档案其他对象属性的取值做更多更详细的约束定义,以增强科研档案资源的语义性和逻辑性。
数据属性用于描述类的基本信息,本研究主要针对科研档案进行了数据属性的描述,取值为XML Schema 数据类型值或者RDF Archives。通过部分继承EAD、AGRIDATA、VIVO 本体模型,复用并自定义了21 个一级数据属性,其中复用了5 个EAD 本体,包括责任者(EAD:Author)、层级(EAD:Level)、主题(EAD:Subject)、正题名(EAD:Title proper)、副题名(EAD:Subtitle),主要描述档案外部属性。复用AGRIDATA:post 描述科研人员职称属性;复用VIVO:has Research Area 描述机构、团队及个人的研究范围;自定义了档号(Archives ID),另外自定义的一级对象属性包括:关于时间的属性:立档时间(Setting Time)、查询时间(Query Time)、保管期限(Retention Period);关于来源(EAD:Origination)的属性:档案馆代号(Code of Archives)和数据库地址(Database Address)。关于学生的属性:导师姓名(Tutor's Name)、论文题目(Thesis Title);关于科研团队的属性:团队首席(Team Leader)、团队成员(Team Member);关于科研课题档案的属性:课题编号(Project Number)、课题来源(Project Source)、课题级别(Project Level)、课题经费(Project Funds)(见图6)。
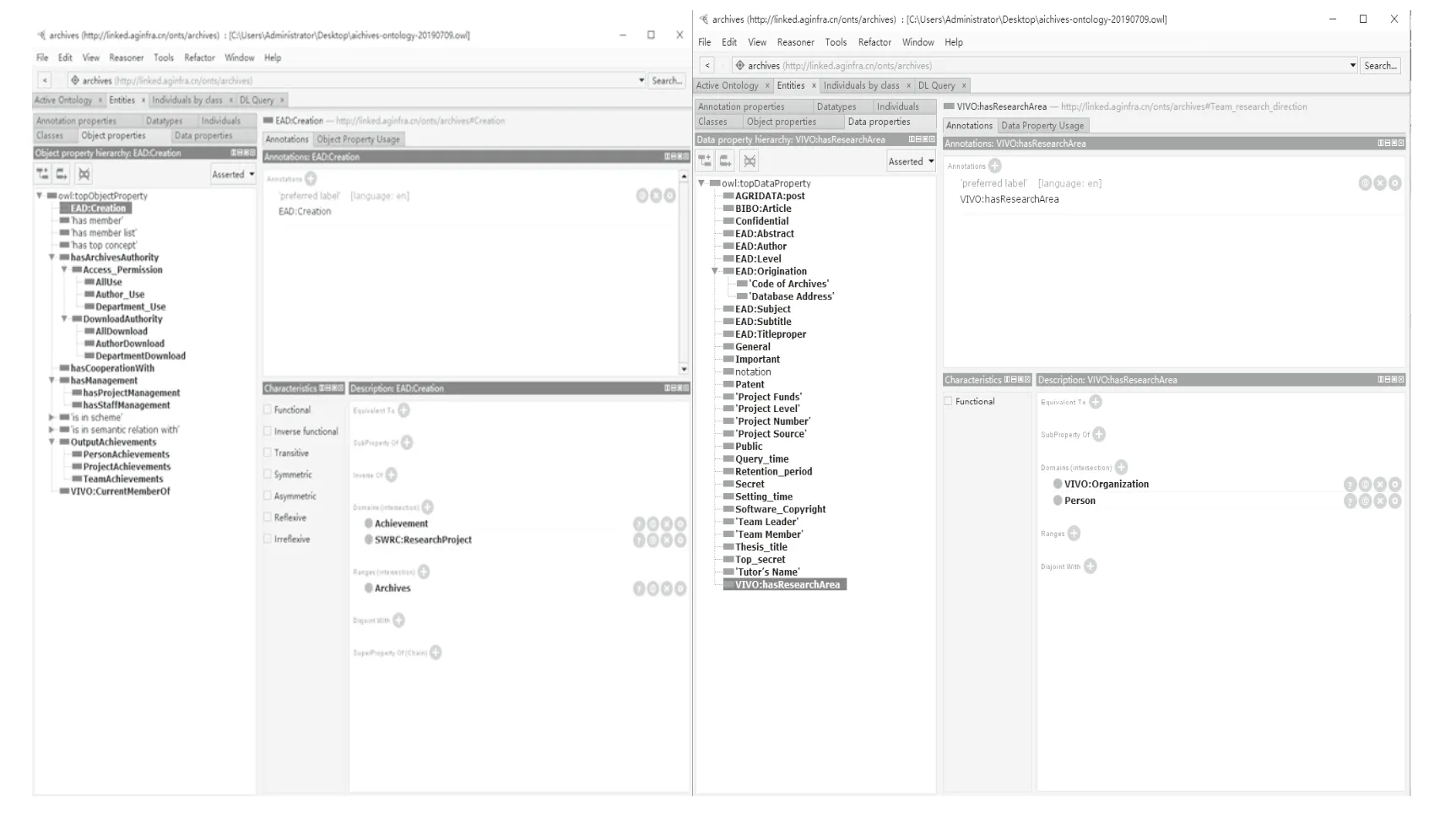
图6 科研档案对象属性与数据属性定义
2.3 科研档案知识图谱数据层构建
本研究数据层的实例数据来源于某研究所2013—2019 年期间125 项国家级科研项目生成的科研档案。其他数据源如CN-DBpedia、维基百科以及DOI、ISSN、ISBN、ORCID 等唯一标识符用于科研档案知识图谱构建中的实体去重以及实体对齐等过程。
2.3.1 科研档案知识抽取
前一节通过构建科研档案知识图谱模式层,定义了档案实体的分类和层级关系,应用编辑工具Protégé、建模语言OWL 建立了计算机可理解的科研档案知识图谱语义模型。在科研档案资源分类以及属性定义的基础上,开展科研档案的知识抽取,包括实体识别、关系抽取两大部分。其中,实体识别主要是通过数据解析从科研档案资源中辨别和析出已定义实体的实例数据,关系的抽取是要分析两个实体之间是否存在关联以及分析实体之间关联关系的属性。根据科研档案资源的数据结构和特点,为提高科研档案资源知识抽取的性能,可引入科技类相关字典,结合词性特征等要素,建立基于科研档案的知识抽取规则。目前常用的知识抽取模型有CRF 模型、BiLSTM 模型等[20]。
基于科研档案特点,结合科研档案语义词典,在科研档案知识图谱数据层构建中通过知识抽取的实体识别、关系抽取等技术可获得科研档案资源语义层面的关键词或高频词,如研究任务(Research Mission)、实施方案(Implementation Plan)、考核指标(Target)、经费预算(Budget)等实体。由于数据资源的不同,在知识抽取时获得的实体也会有变化,这4 个实体仅为知识抽取的通用实体,在具体到某个科研档案的抽取时,需要根据数据特点进一步细化实体。
2.3.2 科研档案知识融合与推理
档案管理长久以来重藏轻用的意识限制了档案资源中真正有价值的信息流动和传播。语义技术能促进档案数据的关联与利用。现有的科研档案资源多样化,包括档案元数据以及从各类业务系统中采集的电子文件、图片等数据,且档案资源间存在着明显的异构性,需借鉴DOI、ISSN、ISBN、ORCID等标准进一步完善科研档案数据格式,并将现有知识组织系统通过语义转换等方式,发布RDF 序列化格式,构建语义链接,最大限度地与档案领域知识或其他外部知识库(如CN-Dbpedia、Wiki data 等)相关联,增强档案资源语义性,形成高质量的科研档案知识图谱。通过前面章节科研知识图谱模式层构建,定义并抽取了科研档案知识层面的实体、关系、属性以及实例数据。由于科研档案知识图谱要连接外部标准的知识库或知识图谱(如Wiki data 等),进一步丰富语义资源,增强数据关联性,提高科研档案数据内在逻辑性和表达能力,需开展知识融合工作。本研究主要采用实体对齐相关技术,判断科研档案各类异构数据源中的实体是否指向同一对象,对同一指称的实体进行唯一标识标注,并进行实体合并。
科研档案知识推理是根据已构建的数据模型和档案数据,依据一定的推理规则,获取满足语义的新的档案知识。目前知识库的推理分为基于符号和基于统计的推理两类。基于符号的推理在人工智能研究方向主要是通过一阶谓词逻辑、命题逻辑或者缺省逻辑等,利用已知的知识图谱(如Freebase 等),使用已建立的规则推断实体之间的新关系,或者针对科研档案知识图谱进行逻辑冲突检测。基于统计的方法一般是通过统计规则,利用关系机器学习的技术,从科研档案知识图谱中学习新的实体关系。
通过科研档案知识图谱模式层及数据层的构建,可针对科研档案资源中的实体开展语义关联。在以某类课题为主体进行查询时,科研档案知识图谱能够链接到与该科研项目有关的所有档案信息,包括该项目任务书、结题报告、管理人员信息、研究成员信息、项目成果等等数据。这些数据再关联到其他相关信息,如此连接则可实现所有科研档案资源的聚合。图7 为“农产品质量安全采集作业场景下的语音识别鲁棒性研究”这一科研项目档案的知识图谱示例图。该项目产出了档案的子类科研课题档案中的研究报告(农产品质量安全采集语音识别)等档案材料、产出了著作、论文、专利等科研成果;该项目的管理机构、管理人员以及研究人员都可从图谱中获得。从研究报告中抽取的高频词经筛选后识别“隐马尔可夫模型”“HTK”与该项目产生了关联,进一步丰富了语义关系(见图7)。

图7 科研档案知识图谱示意图
2.4 应用展望
随着语义网、大数据及人工智能等技术的快速发展,为科研档案的精细化管理与智能化服务应用提供了契机。面向档案资源碎片化加工与语义化组织的需求,传统档案管理模式亟需变革。基于知识图谱驱动的新型科研档案管理系统可大大提升档案深层语义关联与信息挖掘能力。基于本研究构建的科研档案知识图谱语义框架模型,将为科研档案的数字化、碎片化、精细化地加工、揭示、组织和关联,以及科研档案知识图谱数据层实例的填充和聚合提供标准规范,可有效整合纵向垂直、横向跨档案、科研、人事系统以及跨领域之间的资源,推进科研档案语义化知识组织。基于科研档案知识图谱形成科研机构知识全景图,并研发科研档案管理智能关联与发现,科研人员个人档案馆、科研热点领域分析等功能,实现档案知识增值,创新档案知识管理服务模式,满足科研机构对知识的深层次需求,增强我国科技核心竞争力。
3 总结
本文收集与整理了科研档案各方面的数据信息,基于已有的档案本体系统和标准,继承VIVO、SWRC 等现有较为通用的本体模型,初步形成了科研档案知识图谱框架,利用Protégé 构建了一个计算机可理解与计算的科研档案本体,支持以科研档案为中心的知识单元的集成、关联和融合,丰富了科研档案的语义关系,为科研档案的精细化加工与智能化查询提供了思路。在下一步研究中,将进一步充实和完善科研档案本体,基于文本挖掘、自然语言理解等技术实现知识单元语义标注,构建RDF 三元组,建立科研档案与人事、科研、财务等外部系统中的数据映射关联,对知识单元进行归类合并与挖掘推理,形成科研机构知识全景图,实现科研档案知识智能关联与检索,推动科研档案智能管理与应用,促进科学研究创新与发展。
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
少先队活动(2020年12期)2021-01-14 01:47:40
中国音乐学(2020年4期)2020-12-25 02:58:06
中国外汇(2019年18期)2019-11-25 01:41:54
哲学评论(2017年1期)2017-07-31 18:04:00
中成药(2017年3期)2017-05-17 06:09:01
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
领导科学论坛(2016年9期)2016-06-05 14:59:58
文学教育(2016年27期)2016-02-28 02:35:15
